深入浅出:反向传播算法(Backpropagation)核心原理
具体来说,反向传播能够有效地计算每一层的梯度,并通过梯度下降法更新每一层的权重。通过链式法则和梯度计算,反向传播算法能够有效地传递误差,计算每一层的梯度,并通过梯度下降法更新权重,使得神经网络逐渐收敛,达到最优解。反向传播的本质是通过链式法则(Chain Rule),把最终输出的误差“反向”地传递到每一层网络中,逐层计算梯度,从而调整权重,达到减少误差的目的。使得深度神经网络的训练变得更加高效和可
反向传播算法(Backpropagation,简称 BP)是神经网络训练中最重要的算法之一,它在深度学习的革命中起到了决定性作用。简单来说,反向传播的目的是通过计算网络中每个参数的梯度,来更新权重并最小化误差。
那么,反向传播算法到底是怎么工作的?为什么它能够在深度神经网络中有效地计算梯度并优化参数?本文将为你详细解释反向传播的核心原理。
1. 反向传播的核心思想
反向传播的本质是通过链式法则(Chain Rule),把最终输出的误差“反向”地传递到每一层网络中,逐层计算梯度,从而调整权重,达到减少误差的目的。
用一句话总结:
反向传播的核心 = 链式法则 + 梯度计算 + 参数更新
2. 反向传播的工作流程
反向传播主要分为两个阶段:前向传播和反向传播。
前向传播:计算输出与误差
在开始反向传播之前,首先进行前向传播:
- 输入层数据进入网络。
- 数据通过一层一层的神经网络(隐藏层)传递,直到输出层,得到预测值 ( \hat{y} )。
- 使用损失函数计算预测值 ( \hat{y} ) 与真实标签 ( y ) 之间的误差。
例如,对于回归问题,损失函数可能是均方误差(MSE):
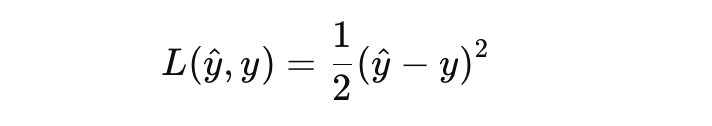
反向传播:计算梯度与更新权重
反向传播的目标是通过梯度下降(Gradient Descent)来调整网络中的权重。反向传播的步骤如下:
-
计算输出层的梯度:
反向传播从输出层开始,首先计算损失函数对输出的梯度,即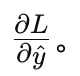
-
通过链式法则将梯度传递到每一层:
反向传播的核心思想就是链式法则。对于每一层的权重,计算它对损失函数的贡献,然后通过链式法则将误差传递到前一层。公式如下: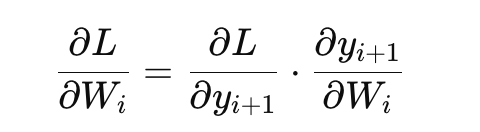
对于每一层,你需要继续使用链式法则,直到回到输入层。
-
更新权重:
计算出每个参数(权重)的梯度之后,使用梯度下降法来更新权重: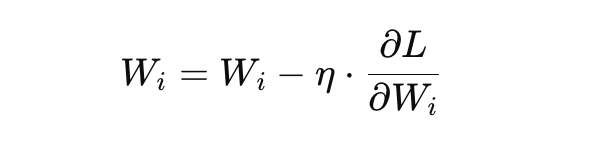
其中,η 是学习率,控制着每次参数更新的步长。
3. 为什么仅使用梯度下降不行?
单独使用梯度下降法处理深度神经网络时,存在一个非常严重的问题,那就是当网络的层数增加,参数数量急剧增多时,求解的复杂度也随之大幅度增加。具体来说,当神经网络的层数增多时,每一层的参数与前一层、后一层都存在复杂的非线性关系,因此很难直接计算出每个参数的梯度。
问题的根源:
-
梯度计算困难:
对于一个深度神经网络来说,假设网络有很多层(如几百层),每一层的权重和激活函数之间的关系非常复杂。如果直接对这些权重进行求导,计算起来非常麻烦,特别是在没有有效方法处理层间依赖关系时,计算的复杂度极其高。 -
梯度消失或爆炸:
随着层数的增加,梯度在传递过程中可能会出现梯度消失或梯度爆炸的情况。具体来说,随着梯度逐层传递,某些层的梯度可能会变得非常小(消失),导致权重更新非常缓慢;而在某些情况下,梯度可能会变得非常大(爆炸),使得网络参数不稳定,导致训练无法收敛。 -
难以调整到最佳权重:
当模型足够复杂(即层数非常多)时,如果没有有效的梯度传递机制,计算每一层的梯度变得非常困难,权重的更新无法正确反映出模型在各个维度上的误差。模型越复杂,越难调整到最优权重,模型的“聪明”也无法发挥出来,从而极大限制了人工智能技术的发展。
反向传播解决了这些问题:
反向传播通过链式法则将误差层层反向传递到每一层,极大地简化了梯度计算。具体来说,反向传播能够有效地计算每一层的梯度,并通过梯度下降法更新每一层的权重。这样,即使神经网络有很多层,反向传播也能够有效地将误差反向传递,确保每一层的权重都能正确更新,从而让整个模型逐渐逼近最优解。
总结来说,反向传播算法使得深度神经网络的训练变得更加高效和可行,它能够帮助我们在复杂的多层网络中计算出每一层权重的梯度,并通过梯度下降法更新这些权重,最终实现模型的优化。
4. 反向传播示例:链式法则的应用
为了更直观地理解反向传播的计算过程,下面通过一个简单的例子来说明如何应用链式法则。
考虑一个两层神经网络: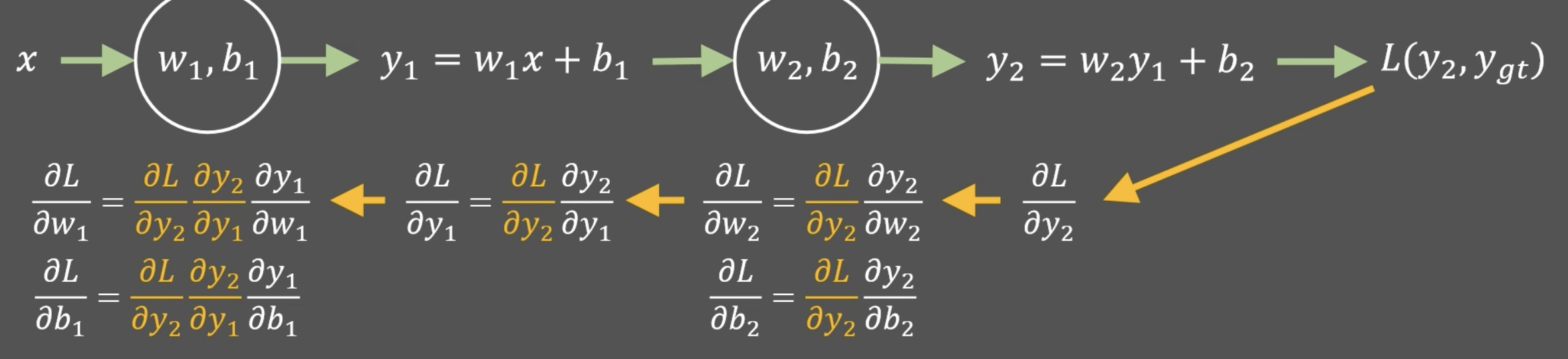
-
第一层的输入 ( x ) 通过权重 ( w1 ) 和偏置 ( b1 ) 计算得到输出 ( y1 ):
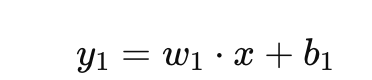
-
第二层的输入 ( y1 ) 通过权重 ( w2 ) 和偏置 ( b2 ) 计算得到输出 ( y2 ):
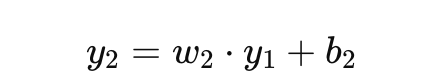
-
最终的损失函数 ( L ) 计算了预测输出 ( y2 ) 与真实标签 ( ygt) 的差异。
在反向传播中,我们首先计算损失函数相对于 ( y_2 ) 的导数,然后使用链式法则逐步计算损失函数相对于每一层权重和偏置的导数。例如: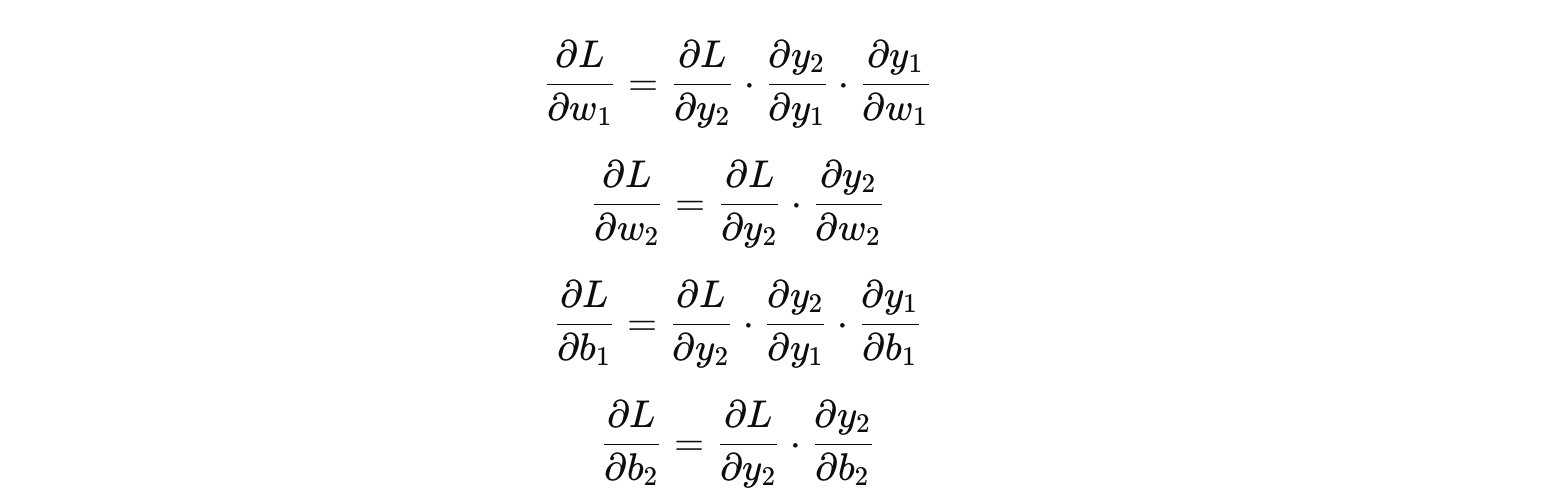
你可以看到,每一层的梯度通过链式法则计算出来,然后使用这些梯度来更新权重和偏置。
通过这种方法,反向传播使得多层网络的训练变得更加可行,极大地提高了模型优化的效率。
5. 总结
反向传播算法是深度学习的基础之一,它让我们能够训练复杂的神经网络。通过链式法则和梯度计算,反向传播算法能够有效地传递误差,计算每一层的梯度,并通过梯度下降法更新权重,使得神经网络逐渐收敛,达到最优解。
如果你能理解链式法则和梯度更新的过程,反向传播就不再是一个复杂的黑盒,而是一个可以解释和优化的数学过程。
在这篇博客中,我们通过链式法则的图示和详细的解释,帮助读者理解了反向传播算法如何解决深度神经网络中的梯度计算问题,并通过实际例子来讲解反向传播的计算过程。这不仅能帮助读者理解反向传播的原理,也能更好地应用它来训练神经网络。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)