【ComfyUI】NextSceneDirector 连续镜头递推分镜生成
本文介绍了一个基于 ComfyUI 的电影级分镜生成工作流 next-scene-qwen,结合 Qwen 多模态大模型,实现图文驱动下的镜头延续生成。通过参考图像与剧本提示输入,系统能自动生成下一幕镜头描述,并还原为风格一致的高质量分镜图,支持镜头构图、光影节奏、角色外观的全流程可控。适用于电影预演、动画设计、广告脚本等场景,提升分镜制作效率与视觉表达能力,是创作者实现故事可视化的强大工具。
今天给大家演示一个电影级分镜生成工作流 —— next-scene-qwen,基于 ComfyUI 搭建,结合强大的 Qwen 多模态模型,实现图像参考+文本描述驱动下的镜头连贯生成。从构图光影到动作延续,全流程可控,可广泛应用于影视预演、漫画草图、分镜头台本等创意场景。
本工作流支持从参考图片出发,调用大语言模型生成「下一幕」的镜头描述,再将其通过 Qwen-Image 模型精准还原成高质量分镜图像。无论是动态场景、复杂打斗,还是细腻情绪,都能通过 prompt 控制、风格延续、多图连贯等能力,完成富有节奏和故事感的影像表达。
文章目录
工作流介绍
本工作流围绕“生成连贯电影分镜”的目标构建,由三个核心模块构成:文生文(描述生成)、文生图(图像生成)、风格承接(图像一致性)。整体流程从输入参考图像与剧本提示出发,经由 Qwen 多模态大模型完成延续性镜头描述,再由 Qwen Image Edit 模型完成图像生成,并通过 Lora 精调模块保持角色外观、色调一致,最终输出高清、高一致性电影分镜图。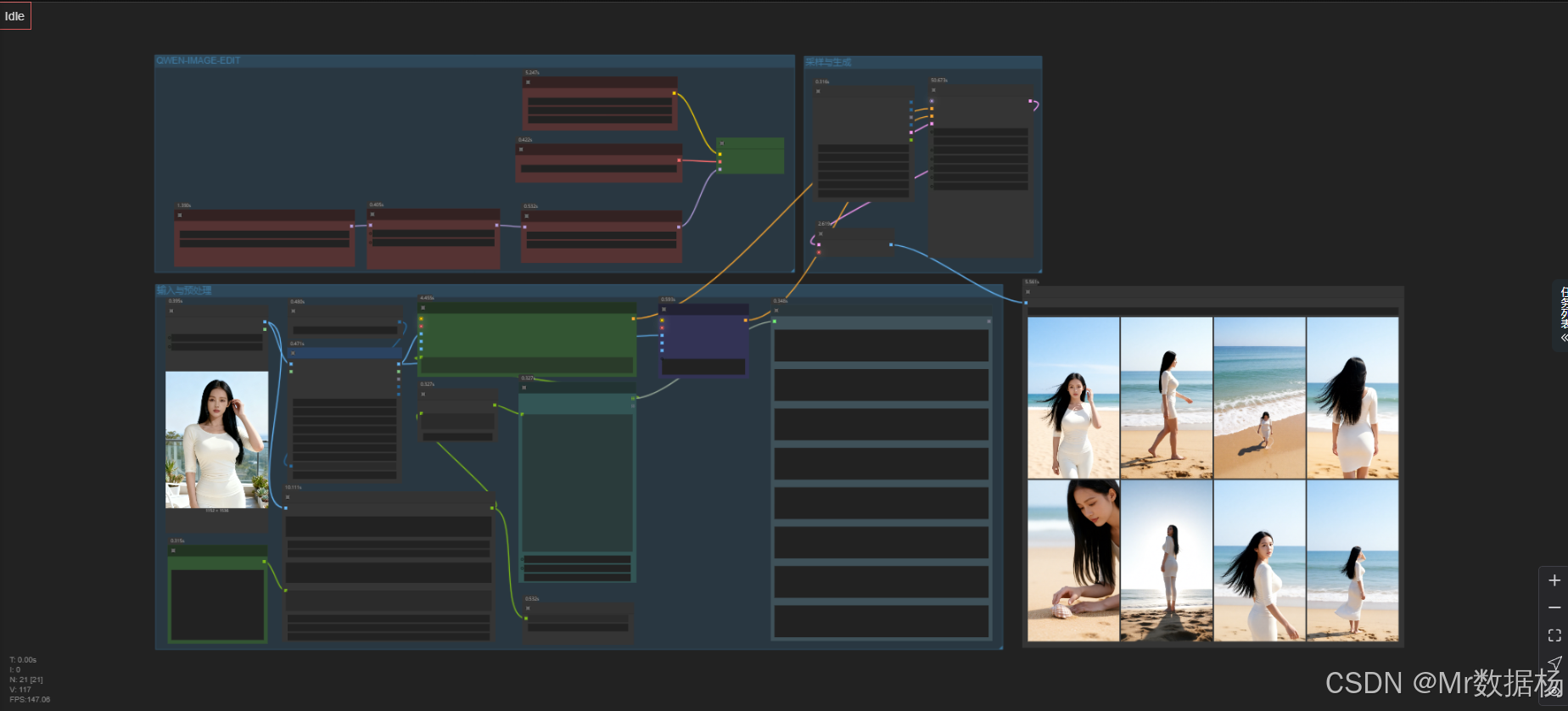
在模型配置方面,核心使用了 Qwen-Image-Edit 与 Qwen-2.5-VL 模型组合,前者负责高保真的图像编辑生成,后者用于理解上下文并生成连贯文本描述。配合两个 LoRA 模型(Qwen-Image-Lightning 和 next-scene_lora_v1)进一步细化输出风格与一致性表现。

在 Node 节点层面,通过 easy promptLine 控制逐帧描述输入,TextEncodeQwenImageEditPlus 模块进行提示编码,采样与图像生成交由 KSampler 执行,并通过 SaveImage 输出最终图片。同时结合图像比例处理、图文融合、模型加载等工具节点,实现完整的高质量图像分镜生成工作链路。
核心模型
整个工作流依赖于多种高性能模型的协同工作,实现从文本到图像、从图像到文本的双向闭环。模型组合经过精心选型与参数调试,以保证风格统一、逻辑连贯、输出稳定。
| 模型名称 | 说明 |
|---|---|
| Qwen-2.5-VL-7B | 多模态语言模型,生成镜头描述文本 |
| Qwen-Image-Edit-2509 | 高质量图像编辑模型,支持输入图片与描述生成图像 |
| qwen_image_vae | 图像解码器,用于将 latent 输出转化为可视图像 |
| Qwen-Image-Lightning-4steps | 快速推理专用 LoRA,提升生成速度与清晰度 |
| next-scene_lora_v1 | 风格保持 LoRA,用于角色、场景、光影延续 |
Node节点
以下是工作流中关键 Node 节点的功能概述,涵盖从文本处理、模型加载、图像变换到最终输出的完整链条:
| 节点名称 | 说明 |
|---|---|
JjkText |
输入剧本提示,用于指导大模型生成分镜描述 |
RH_LLMAPI_NODE |
请求大模型生成“Next Scene”镜头描述 |
ProcessString |
清洗文本内容,去除多余格式 |
easy promptLine |
将多段 prompt 分行,按序控制生成流程 |
TextEncodeQwenImageEditPlus |
多图融合提示编码,支持上下文图像与文本输入 |
LoadImage |
读取参考图像作为输入 |
ImageScaleByAspectRatio |
按比例缩放图像以适配生成输入尺寸 |
CR SDXL Aspect Ratio |
创建符合 SDXL 比例的 latent 空间 |
KSampler |
图像生成采样器,控制生成的细节与随机性 |
VAEDecode |
将 latent 图像解码为可视图 |
SaveImage |
最终图像输出 |
easy showAnything |
预览分镜描述内容,便于对齐生成内容与期望 |
工作流程
整个工作流程从输入剧本提示和参考图像开始,经由文生文模块生成镜头描述,随后驱动图像生成模型逐帧完成分镜图构建。每一个流程节点之间紧密衔接,确保人物、构图、光影的连贯性和统一性。通过合理划分流程阶段,工作流不仅提升了操作效率,也极大增强了画面输出的可控性。
工作流主要分为五个阶段:文本构思 → 多模态生成 → Prompt清洗与分发 → 图像生成与采样 → 最终输出。在此过程中,结合 LoRA 模型保持角色风格不变,结合 Aspect Ratio 工具优化构图比例,结合多图提示融合实现复杂动作与镜头切换,确保生成结果具备专业级的电影感。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 文本输入 | 用户输入电影剧情简述或目标镜头构想文本,作为镜头生成基础 | JjkText |
| 2 | 镜头描述生成 | 通过大模型生成多个“Next Scene”镜头描述,衔接前后镜头 | RH_LLMAPI_NODE |
| 3 | 文本清洗与切分 | 将镜头描述清洗为标准格式,并逐条拆分生成任务流 | ProcessString / easy promptLine |
| 4 | 图像预处理 | 载入参考图像并按比例缩放,统一风格和光影设定 | LoadImage / ImageScaleByAspectRatio |
| 5 | 图文融合编码 | 将参考图像与文字编码成提示向量,作为图像生成的条件输入 | TextEncodeQwenImageEditPlus |
| 6 | 图像生成采样 | 控制图像生成参数(采样步数、CFG值、调度器等)进行高质量图像生成 | KSampler / CR SDXL Aspect Ratio |
| 7 | 解码与输出 | 将 latent 图像解码为可视图并保存为文件 | VAEDecode / SaveImage |
大模型应用
RH_LLMAPI_NODE 连续镜头递推的叙事生成核心
这个节点负责根据参考图与用户输入的剧情文本,自动生成“Next Scene:”格式的连续分镜描述。它不参与图像生成,只承担语言规划任务。Prompt 在这里用来控制人物外观稳定、色调光影统一、背景连续、镜头语言合理推进。每条输出都是递推式的下一镜头叙事,是整个分镜链条的语义起点。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| RH_LLMAPI_NODE | Prompt 内容示例: 保持人物外观一致 光影、色调统一 背景连续不突变 镜头类型(特写、中景、俯拍、跟拍等) 动作表情自然推进 画面真实高清、电影光影 输出格式必须以 “Next Scene:” 开头,每段约100字 |
生成连续镜头的文本描述,为后续分镜画面提供叙事链条,让每张图在语义上连贯推进。 |
TextEncodeQwenImageEditPlus(正向) 分镜画面内容语义编码
该节点接收已拆分好的“Next Scene:”文本,同时结合参考图的视觉特征,将文字描述编码为图像生成模型可理解的正向语义。Prompt 在这里直接决定:构图方式、镜头景别、人物动作、场景张力与电影级光影如何呈现。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| TextEncodeQwenImageEditPlus | Prompt: 来自 easy promptLine 自动拆段后的单条 “Next Scene:” 文本 |
把一段分镜描述转为图像编辑语义,引导模型按叙事内容生成对应镜头画面。 |
TextEncodeQwenImageEditPlus(负向) 画面干净度与结构稳定语义
此节点用于编码负向 Prompt,用来压制多余纹理、错肢、畸形、构图杂点等不良视觉。它不改变故事方向,只确保每个镜头的画面稳定、真实、干净。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| TextEncodeQwenImageEditPlus | Prompt: (内部负向提示,用于保持细节稳定) |
抑制错误结构与噪点,让连续分镜在视觉质量上保持一致。 |
CLIPLoader(语言模型加载器) Prompt 理解能力基础
此节点加载 Qwen 的文本模型,使所有 TextEncodeQwenImageEditPlus 节点具备语言理解能力。它本身不包含 Prompt,但决定了 Prompt 在转换成语义向量时的准确性。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIPLoader | 无 Prompt | 为文字编码提供语言理解能力,使生成的镜头画面更贴合叙事文本。 |
使用方法
整个工作流围绕“参考图 → 生成连续分镜文本 → 拆分各镜头 → 按镜头生成图像”的自动链路展开。用户上传一张参考图,并输入剧情说明,RH_LLMAPI_NODE 会依据图像风格与文本目标生成一系列连续的分镜叙事,每段都以 “Next Scene:” 开头。
随后 ProcessString 清理文本,easy promptLine 按行拆分成独立镜头指令。每一段指令被送入 TextEncodeQwenImageEditPlus,与参考图的视觉特征一同编码,生成对应镜头的画面。用户更换参考图或剧情文本后,完整链路自动更新,从叙事到画面全部重新生成。
参考图用于确保人物外观一致;Prompt 用于决定镜头动作、构图方式、光影氛围;拆分后的文本则保证镜头推进的连续性;负向 Prompt 执行质量稳定任务,保证画面干净。
| 注意点 | 说明 |
|---|---|
| 分镜文本必须以 Next Scene 开头 | 是拆分与递推逻辑的关键格式 |
| 参考图越清晰越好 | 直接影响人物外观与风格一致性 |
| Prompt 内容要具体 | 镜头类型、动作推进、构图要写清楚 |
| 负向 Prompt 不可删除 | 用于维持画面干净与结构稳定 |
| 大批量分镜建议控制字数 | 避免叙事过长导致画面失真 |
| 替换任何素材都会触发全流程重算 | 无需手动调整其他节点 |
应用场景
该工作流具备高度可扩展性和跨领域适配能力,适用于电影前期筹备、动画设计、分镜草图绘制、广告创意提案等多个场景。其生成内容具备“连续性强”、“构图专业”、“风格统一”三大优势,特别适合需要批量输出、风格一致、情节连贯的视觉内容需求。
对于内容创作者来说,它能大幅度节省分镜设计时间,快速验证故事设想。对于影视导演和制片人,它能在拍摄前预览镜头效果,辅助故事板决策。对于AI艺术家,它能作为素材生产线的中枢,实现从文本到图像的全自动视觉生产流程。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 电影分镜绘制 | 高效生成剧情连贯的镜头草图 | 导演、编剧 | 连续镜头图、场景过渡图 | 加速电影前期筹备,提升剧本可视化能力 |
| 动画设计 | 快速验证角色动作、景别运镜 | 动画导演、原画 | 动作演出、分镜变化预演 | 降低设计试错成本,增强视觉表现力 |
| 广告脚本提案 | 可视化广告创意、展现画面节奏 | 广告公司、策划 | 快剪风格视觉草图 | 快速提案视觉形式,节奏鲜明、风格统一 |
| AI影像创作 | 文本驱动生成高质量视觉故事 | AI艺术家 | 剧情图集、角色动态演示 | 从提示词到画面全流程一键生成 |
| 教学训练 | 教授分镜设计、镜头语言的专业工具 | 影像教学机构 | 示例镜头、结构范例 | 提供镜头语言与镜头逻辑教学素材 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 30
30 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)