RAIDAR:通过「重写」来识别生成式 AI——ICLR 2024 论文《RAIDAR: Generative AI Detection via Rewriting》解读
这篇工作想解决的核心问题很直接:在只有「黑盒 API」的前提下,如何可靠地检测一段文本是不是由大模型生成的?传统检测方法高歌猛进了一阵,到了 GPT-3.5 / GPT-4 这一代,效果就开始明显掉队,尤其是面对短文本、不同模型、甚至有对抗意识的生成者时。不用看概率分布、不用访问模型内部,只是让另一个 LLM 去“重写”这段文本,然后量一量前后差了多少字。他们发现:对同一个重写指令,LLM 对自己
1. 论文基本信息
- 标题:RAIDAR: Generative AI Detection via Rewriting
- 作者:Chengzhi Mao, Carl Vondrick, Hao Wang, Junfeng Yang
- 机构:Columbia University, Rutgers University
- 年份:ICLR 2024
- 论文链接:https://arxiv.org/abs/2401.12970
- 领域关键词:
- Large Language Models(LLMs)
- AI-generated Text Detection
- Editing Distance / Levenshtein Distance
- Prompt-based Rewriting
- Invariance / Equivariance
2. 前言:为什么读这篇论文?
这篇工作想解决的核心问题很直接:在只有「黑盒 API」的前提下,如何可靠地检测一段文本是不是由大模型生成的? 传统检测方法高歌猛进了一阵,到了 GPT-3.5 / GPT-4 这一代,效果就开始明显掉队,尤其是面对短文本、不同模型、甚至有对抗意识的生成者时。
作者提出的 RAIDAR,有点「借刀杀人」的味道:不用看概率分布、不用访问模型内部,只是让另一个 LLM 去“重写”这段文本,然后量一量前后差了多少字。 他们发现:对同一个重写指令,LLM 对自己写的东西通常改得很少,对人类写的东西改得很多。这个差异被系统性地量化之后,就变成了一个相当稳定的检测信号。
从结果上看,RAIDAR 在六个数据集(新闻、创意写作、学生作文、代码、Yelp 评论、arXiv 摘要)上,相比当前最强的 Ghostbuster 等方法,F1 分数最高能提升约 29 个点,而且还在跨模型、对抗性改写等场景下保持了不错的鲁棒性。
我觉得这篇论文值得单独写一篇解读,主要有三个原因:
第一,它把一个非常“直觉化”的想法做到了极致:只看“改动量”就能做检测,而且不接触任何高维特征。
第二,它把「不变性 / 等变性 / 不确定性」这些看似抽象的概念,落在了非常具体的重写行为上。
第三,这个方法天然兼容未来的新模型——只要能调一个会重写的 LLM,就可以直接用。
3. 基础概念铺垫
大语言模型(LLM):可以把它理解成一个“预测下一个词”的超级自动补全系统。给它一段文字,它会按照自己学到的统计模式,一步步往后接。GPT-3.5、GPT-4、Claude、LLaMA 等都属于这一类。
AI 文本检测:就是把一段文本丢给一个判别器,让它判断“更像是人写的”还是“更像是模型写的”。传统方法一般会看:这段文本在某个语言模型下的概率有多高、熵有多低、是否存在某些「过于平滑」的统计模式等等。问题是:很多商用 API 根本不给你这些概率,只给你纯文本。
编辑距离(Editing Distance):这是本文的主角之一。最常见的是 Levenshtein 距离,它定义为:把字符串 A 变成字符串 B,最少需要多少次单字符的增删改。 距离越大,改动越多;如果我们把它反向归一化成一个“相似度分数”,那就是距离越小、相似度越高。
Bag-of-words(词袋):不看语序,只看“有哪些词出现过、各出现了几次”。在 RAIDAR 里,作者不仅看字符级的改动量,也看词级的变化,因为有些重写在字符层面不大变,但会替换同义词。
不变性 / 等变性 / 不确定性:
- 不变性(Invariance):给你一个操作,比如“帮我润色这段话”,如果文本重写前后几乎没变,可以说对这个操作是“不变”的。
- 等变性(Equivariance):如果我先让模型把句子改成“反义”,再让它改回来,然后再润色一下;和直接润色原句相比,如果结果几乎一样,可以说模型对这组「变换 + 逆变换」是“等变”的。
- 不确定性(Uncertainty):同样的重写指令,跑好多次,如果每次改得都差不多,那就稳定;如果改来改去都不一样,那就不稳定。
RAIDAR 做的事情,就是:把这些“改动的程度”和“改动的一致性”量化成特征,然后丢给一个简单的分类器去判别 AI 文本。
4. 历史背景与前置技术
如果把“AI 文本检测”这条线从早到晚串一下,大致会看到这么一条技术脉络。
最早的一批工作,大多是针对 GPT 之前的生成模型,它们的文本质量比较一般,于是检测方法也偏「粗暴」:看句子长度、词频分布、罕见 n-gram 的比例等等。Bakhtin、Fagni、Gehrmann、Ippolito 等人的工作都属于这个阶段。
随着 GPT 系列的出现,一种更精细的思路成了主流:直接用语言模型的 token log-probability 作为特征。 比如:
- 有的工作看某个 token 的概率曲线是不是过于“平滑”;
- 有的工作引入「curvature」的概念,比如 DetectGPT,用多个扰动版本的句子算 loss 曲面;
- Ghostbuster 等方法会把整段文本的概率向量喂进另一个分类模型。
但这条路有两个现实问题:
第一,大部分商用 LLM(GPT-3.5、GPT-4 等)只提供文本输出,不给概率。 这意味着很多检测方法没法直接用在这些模型上。
第二,高维的连续特征里,往往混了大量「伪特征」和「扰动敏感特征」,很容易被对抗攻击或者简单的 paraphrase(改写)打穿。 近年来不少工作都表明,只要对文本做几轮改写,不少检测器的表现会严重下滑,甚至接近随机。
另一个方向是水印(watermarking):在生成时刻意调整采样策略,让生成文本里有某种统计上的“暗号”,以后检测时再把它读出来。问题是:一旦文本被二次改写,水印就会被严重破坏,现实场景中的鲁棒性并不乐观。
还有一种直觉式方法是直接问 LLM:「这段是不是你写的?」 论文里称为 GPT Zero-shot。这种方式简单粗暴,但 LLM 本身并没有被系统地训练过这个任务,表现也比较不稳定。
在这样的背景下,RAIDAR 做了一个很有意思的转向:既然拿不到内部概率,不如只把 LLM 当成“重写器”,只根据输入和重写后的输出之间的差异来做判别。
5. 论文核心贡献
从整体上看,RAIDAR 的贡献可以概括成一句话:把「让模型自己改文」这件事变成了一个高效、鲁棒、可泛化的 AI 文本检测器。
更细一点地说:
首先,作者提出了一个非常清晰的假设:LLM 对自己生成的文本更“满意”,因此在被要求重写时,改动会更小;而对人类文本,它会更“挑剔”,改得更多。 论文在多个数据集上用直方图和统计检验验证了这一点——在人类文本和 GPT 文本上,重写前后相似度的分布明显不同,p-value 远小于 0.05。
其次,作者围绕这个现象,构造了三类特征:不变性、等变性、不确定性,全部基于重写前后编辑距离和词袋变化,不涉及任何连续的神经特征。
然后,作者把这些特征喂进一个非常朴素的分类器(Logistic Regression 或 XGBoost),在六个数据集上和 GPTZero、DetectGPT、Ghostbuster 等方法系统对比,在段落级别的 F1 上普遍领先,尤其是在代码、Yelp 评论、arXiv 摘要等任务上优势极其明显。
最后,论文还花了大量篇幅在分析上:研究不同生成模型(Ada、Text-Davinci-002、GPT-3.5、GPT-4、LLaMA2)、不同重写模型、不同 prompt 设计、对抗性 paraphrase、输入长度等因素的影响,并且探讨了非母语写作者场景、模型持续微调之后的鲁棒性等问题。整体观感是:方法本身很简单,但实验和分析非常扎实。
6. 方法详解
6.1 整体架构
可以先用一条流水线把 RAIDAR 的思路串起来:
1. 给定一段待检测文本 (x)。
2. 选择一个「重写模型」 (F),比如 GPT-3.5-Turbo。
3. 给 (F) 一条固定的重写指令 (p),例如:“Help me polish this:”、“Rewrite this for me:” 等。
4. 让模型在指令 (p) 下重写文本,得到输出 。
5. 对比 (x) 和 () 之间的差异:字符级编辑距离、词袋差异等,得到一组数值特征。
6. 换不同的 prompt,或者加入变换 / 逆变换、多次重写等,构造更多特征。
7. 把这些特征丢进一个简单的二分类器 (C),输出。
整张流程图在论文第 3 页的算法框架和第 3 节算法描述里可以找到,对应的直观例子则出现在第 2 页的 Yelp 评论示意图。
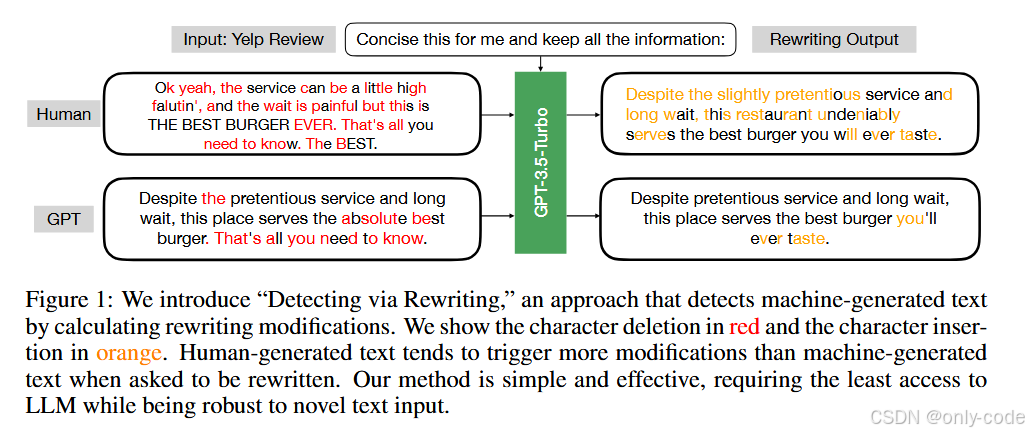
在 Figure 1 中,作者把一段 Yelp 评论交给 GPT-3.5-Turbo:「帮我简洁地改写」。对人类写的评论,模型会大量合并、删减、替换表述;对 GPT 写的评论,改动就明显小得多。图中用红色标注删除的字符、橙色标注插入的字符,一眼就能看出改写幅度的差异。
6.2 不变性:看「改了多少」
不变性的核心问题是:在给定重写指令下,输出和输入有多相似。
形式上,给定文本 (x) 和一个重写 prompt (p),模型输出
作者用一个归一化的编辑距离来度量不变性:
这里 是最小字符编辑步数,分母用两者长度的较大值做归一化。(D) 越接近 1,说明改动越少,越“不变”;越接近 0,说明改动很大。
除了字符级的 (D),作者也计算了词袋重叠率:把输入和输出都拆成 n-gram 词袋,统计二者共有的 n-gram 数目,再除以输入长度,得到一个类似的相似度。
在不变性版本的 RAIDAR 中,整段流程可以用伪代码概括(对应论文附录的 Algorithm 1):

【插图:论文 Algorithm 1「Detecting LLM Generated Content via Output Invariance」伪代码】
直觉是:如果一段文本本来就是模型自己写的,那在“润色一下”这种 prompt 下,它会认为已经够好了,于是只做一些非常轻微的修改;而人类文本往往有自己的风格和结构,更可能偏离模型学到的惯常模式,因此会被改得更狠。 Figure 2(a) 的直方图就展示了这一点:红色(GPT 文本)的相似度分布整体右移,说明更加“不变”。
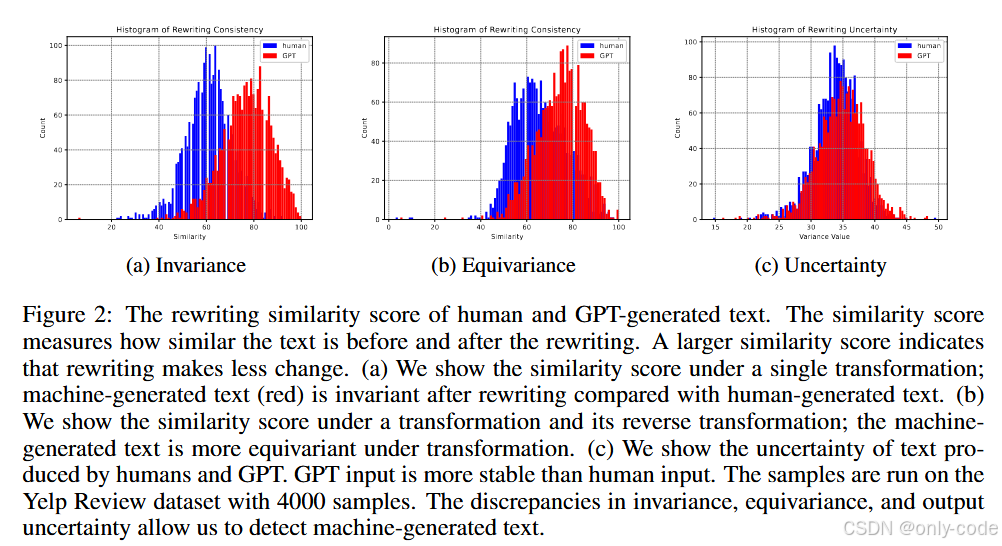
【插图:论文 Figure 2(a),不变性得分直方图】
6.3 等变性:看「绕一圈回来是否一致」
等变性的想法更有点“玩花活”:先对输入做一个可逆变换,再重写,然后再把变换逆回来,看看结果是否和直接重写差不多。
论文里的具体做法是:
1. 构造一个变换 prompt (T),比如:“Write this in the opposite meaning:”,让模型把句子改成“反义版”;
2. 再构造一个逆变换 prompt ,同样可以是“Write this in the opposite meaning:”,因为反义的反义通常就是原意;
3. 先用 (T) 变换输入:;
4. 再用重写 prompt (p) 去润色这个变换后的文本:;
5. 最后用 把
拉回原意:
;
6. 同时也直接对原始输入做一次润色:;
7. 比较 和 (s) 的编辑距离:
如果模型对某类文本具有更强的「结构一贯性」,那么在“反义—再反义”这条绕路上,最后会回到和“直接润色”很相近的地方。作者的实验发现,这种等变性在 GPT 文本上更强。Figure 4 给出了 Yelp 评论上的示例:原句 → 反义 → 润色 → 反义回来,和直接润色的结果风格高度一致。

【插图:论文 Figure 4,等变性示例(Yelp Review,反义变换与逆变换)】
对应的整体流程,在论文附录的 Algorithm 2 中有详细伪代码。
6.4 不确定性:看「多次改写是否稳定」
不确定性这一支线,关注的是:同样的重写指令,多次生成会不会飘。
做法是:
1. 固定一个重写 prompt (p),比如“Rewrite this for me”;
2. 用同一个模型对输入 (x) 重写 (K) 次,得到一组输出 ;
3. 对每一对输出 计算编辑距离
;
4. 把所有对的距离加总,得到一个总的不确定性分数:
思路是:如果一段输入在模型空间里“位置很稳”,那每次重写都会在一个很小的局部附近晃动,互相之间改动不大;反之,如果模型对这段文本“不太有把握”,多次重写就会跑出很多不同版本。 Figure 2(c) 的直方图显示,GPT 文本的重写结果更集中,人类文本更发散。
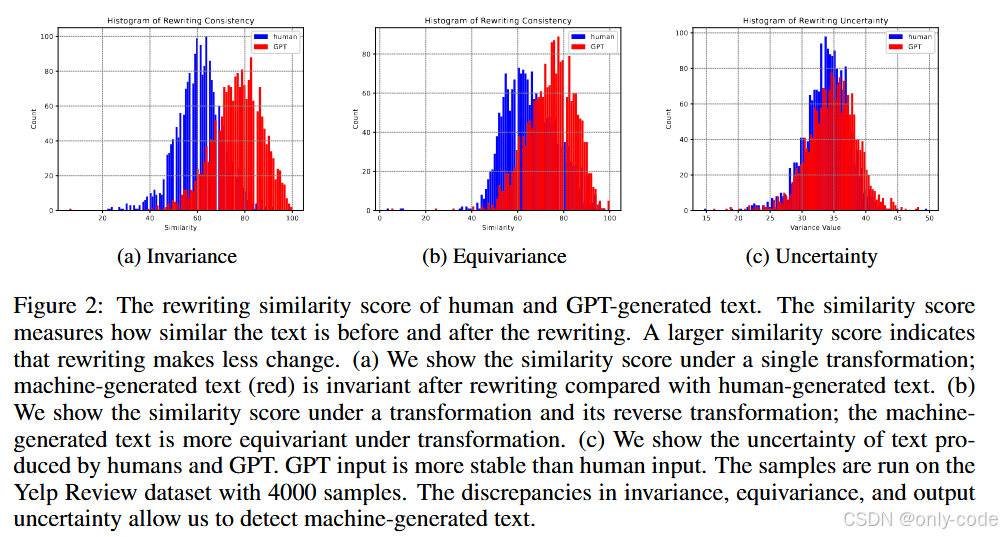
【插图:论文 Figure 2(c),不确定性直方图】
对应的伪代码在附录 Algorithm 3 中,核心步骤就是多次重写 + 成对距离统计。
6.5 特征与分类器
无论是不变性、等变性还是不确定性,最后都会得到若干数值特征:
- 对不变性,特征包括多个 prompt 下的词袋变化和 Levenshtein 相似度 ;
- 对等变性,特征是“绕一圈”和“直接重写”之间的相似度;
- 对不确定性,特征则是所有输出对之间的相似度集合。
作者把这些特征丢进一个简单的分类器 (C):在大多数数据集上用 Logistic Regression,在学生作文数据集上发现 XGBoost 表现更好。表 15 列出了每种特征在各个数据集上对应的最佳分类器选择。
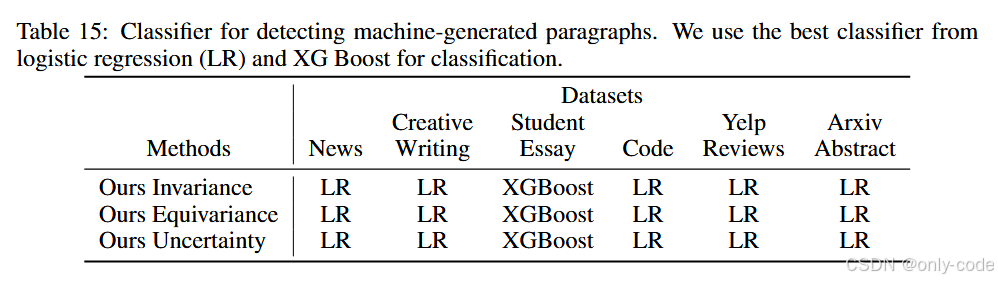
【插图:论文 Table 15,RAIDAR 不同特征的分类器配置】
这里有个有趣的点:整个检测器并不依赖神经网络本身的向量表示,而只是在重写之后做了一次“文本层面的统计”。 这让方法天然适配各种黑盒 API,也让后续对抗者想通过梯度来攻击变得很难——因为损失函数对输入几乎是不可导的。
7. 实验结果与性能分析
7.1 实验设置
论文一共选用了六个相当有代表性的数据集:
- Creative Writing:来自 subreddit WritingPrompts,以创意故事为主,人类部分来自社区帖子,机器部分由 text-davinci-003 续写生成。
- News:基于 Reuters 50-50 authorship 数据集,机器部分同样由 text-davinci-003 生成。
- Student Essay:来自 British Academic Written English 语料库,机器部分由 text-davinci-003 生成学生作文版本。
- Code:人类部分来自 HumanEval,机器部分由 GPT-3.5-Turbo 生成同一题目的 Python 代码。
- Yelp Review:从 Yelp Review 数据集中取出 2000 条人类评论,再让 GPT-3.5-Turbo 在相似长度下写“简洁版”评价。
- arXiv Abstract:选取 ICLR 2015–2021 的 350 篇论文摘要(那时基本没 LLM 参与),再让 GPT-3.5-Turbo 根据标题 + 摘要前 15 个词生成一个简洁版本。
文本长度大多在几十到一百多词之间,属于典型的“段落级”检测场景。
重写模型默认是 GPT-3.5-Turbo,特征提取完后,用 Logistic Regression / XGBoost 做二分类。评价指标使用 F1 分数。对比基线包括 GPT Zero-shot、GPTZero、DetectGPT、Ghostbuster 等。
7.2 主结果:在各个数据集上的 F1 表现
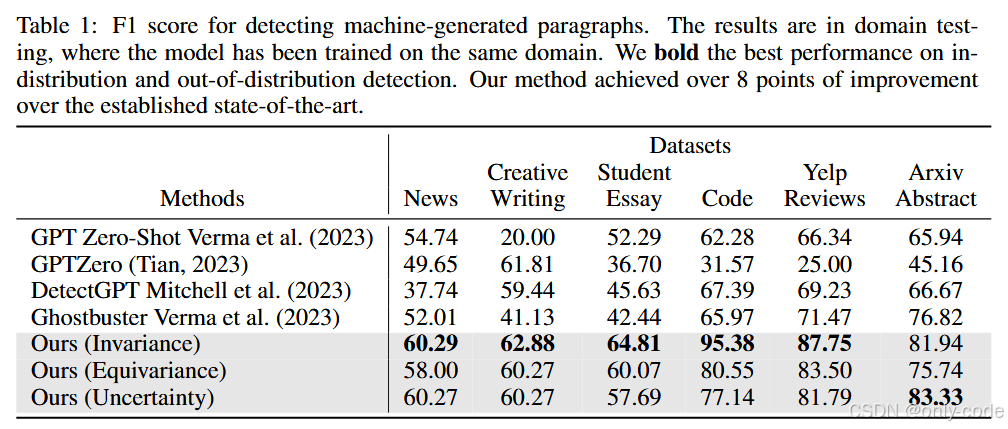
【插图:论文 Table 1,各数据集 in-domain F1 对比】
在「同分布」设置下(检测模型在某个数据集上训练,又在该数据集上测试),RAIDAR 的表现非常醒目:
- 在 Code 上,基于不变性特征的 RAIDAR F1 达到 95.38,远超 Ghostbuster 的 65.97 和 DetectGPT 的 67.39;
- 在 Yelp 评论 上,RAIDAR 不变性版本 F1 达到 87.75,依然明显优于 Ghostbuster(71.47)和 GPTZero(25.00);
- 在 arXiv 摘要 上,RAIDAR 不变性 F1 为 81.94,Ghostbuster 为 76.82;
- 在 新闻 / 创意写作 / 学生作文 三个数据集上,RAIDAR 三种特征(不变性、等变性、不确定性)也都稳定领先,整体提升在 8 分以上。
值得一提的是:不变性特征通常是最强的一支,但等变性和不确定性在某些场景下也会补充信息。
Figure 2 对应的直方图很直观地解释了这些结果背后的统计基础:
- 在不变性维度上,GPT 文本的相似度分布明显右移;
- 在等变性维度上,GPT 文本在“变换—逆变换”流程下更加稳定;
- 在不确定性维度上,GPT 文本的多次重写更加一致。
附录里的 t-test(表 14)也表明,这些差异在统计上高度显著,p-value 都在 (10^{-7}) 量级甚至更低。

【插图:论文 Table 14,统计显著性检验结果】
7.3 跨数据集(OOD)检测
接下来是更苛刻的 out-of-distribution 场景:在一个数据集上训练,在另一个数据集上测试。这里作者主要跟 Ghostbuster 对比:
- 在 News 上,Ghostbuster F1 为 34.01,RAIDAR(等变性特征)能做到 56.87;
- 在 Creative Writing 上,Ghostbuster 为 49.53,RAIDAR 等变性为 59.47;
- 在 Student Essay 上,两者差距较小,但 RAIDAR 不变性仍略高一点。
作者总结:RAIDAR 在 OOD 设置下能带来约 22 分左右的平均提升,说明“重写差异”这个信号有一定的跨领域稳定性。
7.4 对抗性 paraphrase:专门为了绕过检测的生成
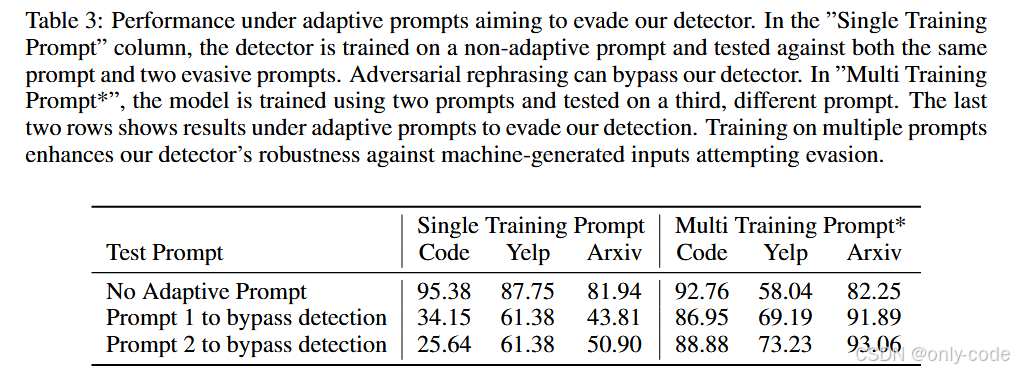
【插图:论文 Table 3,对抗性 prompt 下的鲁棒性实验】
既然大家都知道“改写可以绕过检测”,那 RAIDAR 自己在这方面表现如何?
作者专门设计了两种“恶意 prompt”,在生成 GPT 文本时就加入:
1. “Help me rephrase it in human style”(改写得更像人);
2. “Help me rephrase it, so that another GPT rewriting will cause a lot of modifications”(刻意让后续重写改动变大)。
在只用单一训练 prompt 的情况下,这种对抗性生成确实能严重拉低检测效果,例如在代码数据集上 F1 直接掉到 25–34。但当作者在训练阶段使用多种 prompt 混合训练,再对完全没见过的新对抗 prompt 进行测试时,F1 又能拉回到:
- 代码:86–89;
- Yelp:69–73;
- arXiv 摘要:最高 93.06。
这说明:只要训练阶段把各种可能的重写风格“见得够多”,RAIDAR 对有意识的规避行为依然有一定的抵抗力。
7.5 跨生成模型:训练在 A,检测 B
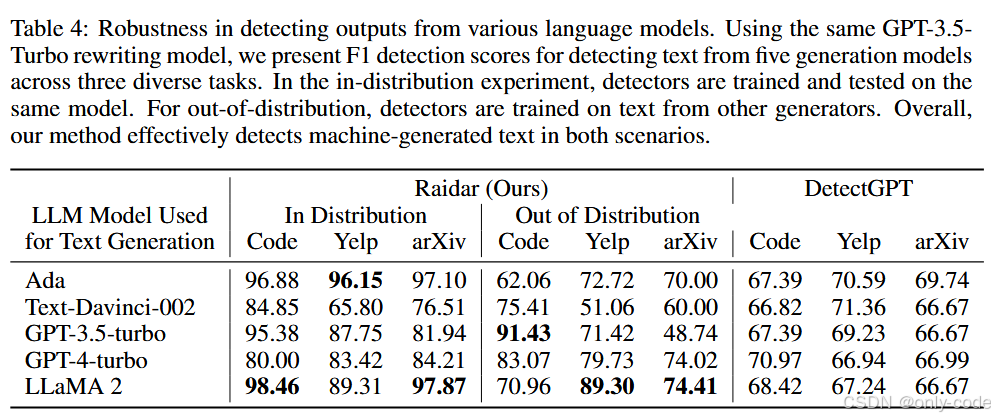
【插图:论文 Table 4,不同生成模型上的表现】
作者还测试了一个很现实的问题:如果训练数据来自 GPT-3.5,但测试时生成模型换成了 Ada、Text-Davinci-002、GPT-4、LLaMA2 等,RAIDAR 还能不能用?
实验分两种:
- in-distribution:训练和测试都用同一个生成模型;
- out-of-distribution:训练时用其中两个模型,测试时换成第三个没见过的模型。
结果很乐观:
- 在 in-distribution 下,F1 往往在 80–98 之间,例如 LLaMA2 代码检测能到 98.46;
- 在 out-of-distribution 下,虽然有明显下降,但不少场景仍然能达到 70–90 分;
- 对 Claude 生成的学生作文,作者也额外测了一下,F1 为 57.8,在完全没专门训练的情况下还算可用。
这说明 RAIDAR 抓到的并不是某个具体模型的“口音”,而更像是一种泛化的“机器口音”。
7.6 重写模型的选择
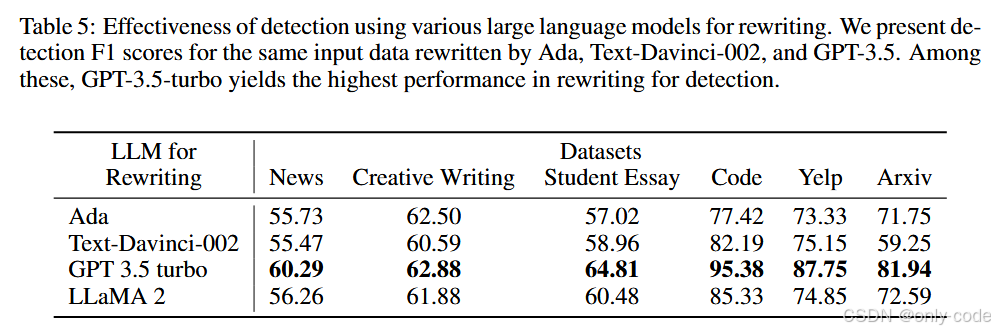
【插图:论文 Table 5,不同重写 LLM 的效果对比】
重写这一步一定要用 GPT-3.5 吗?作者试了几种替代方案:Ada、Text-Davinci-002、GPT-3.5-Turbo、LLaMA2。结果很清楚:
- GPT-3.5-Turbo 作为重写器时表现最好,在所有数据集上都拿到最高或接近最高的 F1;
- Ada、Davinci、LLaMA2 也都能做出还不错的检测器,只是整体略逊一筹。
可以理解为:重写器本身越强,对文本质量的“偏好”越稳定,改动模式就越有区分度。
7.7 输入长度的影响
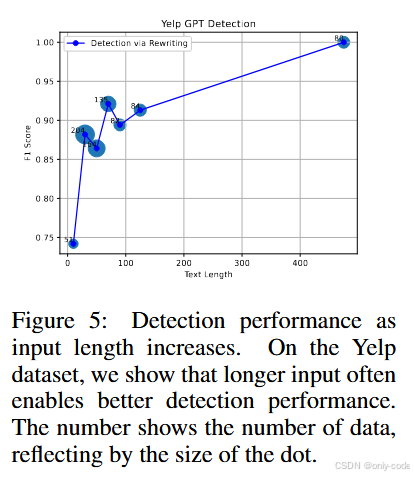
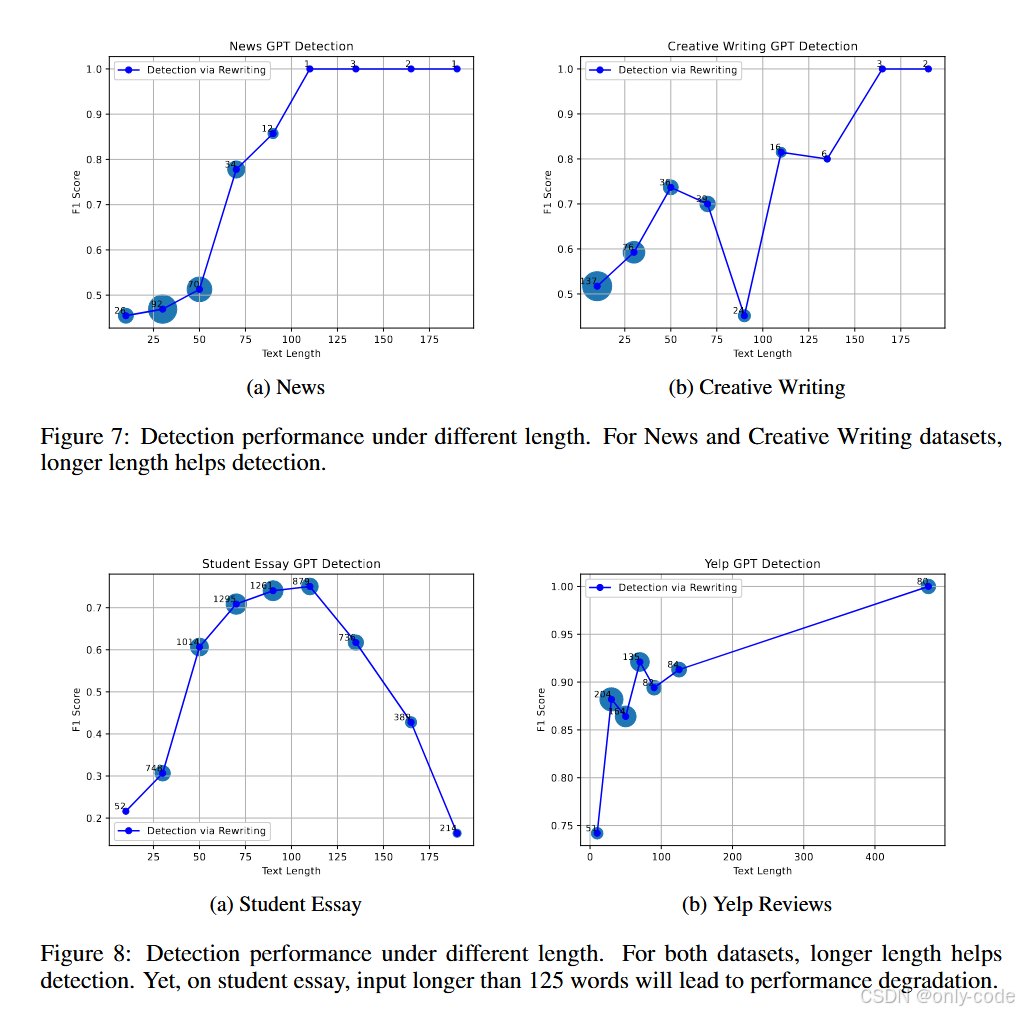
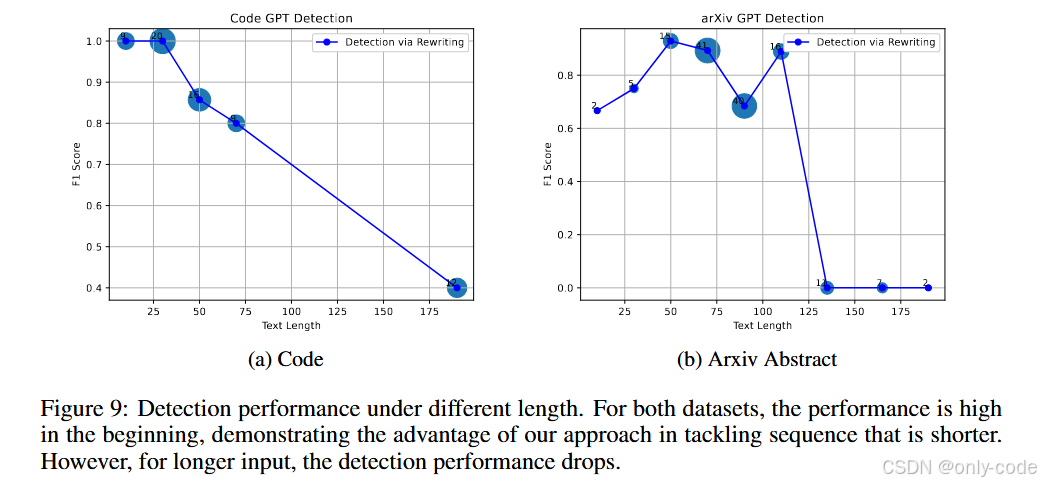
【插图:论文 Figure 5 & Figure 7–9,长度 vs F1 曲线】
作者还画了不少「输入长度—F1」的曲线,结论大致有两点:
- 在 Yelp、News、Creative Writing 等数据集上,文本越长,检测越容易,F1 曲线整体是上升的。 在 Yelp 上,即便只有 10 个词左右的输入,RAIDAR 也能刷到 74 左右的 F1,这点尤其难得。
- 在学生作文、代码等数据集上,长度过长时反而会有一点性能下降,比如学生作文超过 125 词后,F1 会从峰值往下掉。这可能和训练数据、重写器的行为模式有关:太长的输入会让模型倾向于做更局部的修改,从而拉近人类和 GPT 文本的“重写幅度”。
8. 亮点与创新点总结
如果只用叙述的方式回顾一下这篇论文最打动我的点,大概有这么几条。
首先是视角的转换。 以往的检测方法多半盯着“原始文本在模型里的概率”,而 RAIDAR 把注意力转向了「重写」这个过程:不看模型“怎么想”,只看它“怎么改”。 这种「行为分析」式的思路非常适合黑盒 API。
其次是对不变性 / 等变性 / 不确定性这套语言的落地。 这些概念原本听起来很理论,RAIDAR 把它们具体化为:改动多少、绕一圈回来是否一致、多次改写是否稳定,并且都通过编辑距离就能量化。这种把抽象概念嫁接到非常具体操作上的做法,很有启发性。
第三,是完全依赖离散符号特征的选择。 不用任何 embedding,不必担心「某个语义维度被对抗攻击放大」,甚至对梯度攻击来说几乎是“黑箱中的黑箱”。同时,它也绕开了很多 fairness / bias 方面的既有问题——论文在非母语写作实验里也说明,RAIDAR 并不会明显地把非母语作文误判成机器文本。
最后,是可扩展性。 在实验部分可以看到:换生成模型、换重写模型、换 prompt,RAIDAR 都能平稳地适应。多 prompt 训练甚至可以增强对对抗性文本的鲁棒性。这让它更像一套“框架”,而不是绑定在某个具体模型上的小技巧。
9. 局限性与不足
尽管 RAIDAR 的表现相当亮眼,但认真看完实验和附录之后,其实也能看到不少值得警惕的地方。
第一,强依赖「重写模型」这一外部组件。 在论文中,重写器通常是 GPT-3.5-Turbo。一旦将来 API 的采样策略、对齐方式大幅更新,或者换成了完全不同风格的模型(比如极端偏保守 / 偏简化),RAIDAR 的特征分布可能会发生漂移,需要重新标注数据、重新训练分类器。
第二,对抗性 paraphrase 的问题只能缓解,难以彻底解决。 虽然多 prompt 训练显著提高了鲁棒性,但表 3 中我们也看到,在某些数据集(例如 Yelp)上,多 prompt 训练反而让「无攻击场景」的表现有所下降。这意味着:在防御对抗攻击和保证日常性能之间,仍然存在一个 trade-off。 真正恶意的攻击者还可以叠加更多手段,比如先用另一个模型重写,再手工微调等。
第三,文本长度和类型对表现有时会产生比较诡异的影响。 在学生作文和代码数据集上,输入过长会导致 F1 下降,这背后可能牵涉到很多复杂因素:段内话题切换、局部改写策略、代码结构的刚性等等。目前 RAIDAR 还没有给出针对此类场景的专门设计。
第四,假设本身可能会随着人类写作风格的变化而失效。 论文的核心假设是“模型写的文本更接近模型偏好的结构”,但随着越来越多人用 LLM 辅助写作,人类文本本身可能变得越来越“模型化”。这会让**“重写改动量”这个信号在未来逐渐减弱**,需要更多维度的补充。
第五,从社会层面看,检测结果如何使用是个难题。 虽然 RAIDAR 在非母语作文上的结果不错,但实验规模还有限;一旦被大规模用于考试或审核场景,误判带来的后果会非常具体,而且可能和语言背景、文体习惯等因素纠缠在一起。
10. 全文总结(关键点回顾)
回头看这篇论文,其实可以用一句话概括:让语言模型自己重写文本,然后用“改了多少、改得多一致”来判断它是不是机器写的。
更展开一点:作者从一个非常直观的观察出发——LLM 会对自己生成的文本更“手下留情”,对人类文本则批改得更猛——把这种差异形式化为不变性、等变性、不确定性三类特征,全部基于编辑距离和词袋变化。然后用一个简单的线性 / 树模型分类器,就在六个数据集上,把 GPTZero、DetectGPT、Ghostbuster 等一众方法拉开了一个相当可观的 F1 差距。
实验也说明,这种“通过重写看本质”的办法,不仅在 in-domain 场景很强,在跨领域、跨模型甚至对抗性改写场景下都有不错的表现;更重要的是,它完全兼容黑盒 API,不需要任何内部概率信息。
对我个人来说,这篇论文带来的最大观念变化是:在和生成式模型打交道时,不必执着于模型内部的概率世界,观察它在各种 prompt 下“如何修改输入”本身,就已经是一种很有力量的信号。 未来不管是文本检测,还是风格迁移、质量评估、甚至人机协作写作,这种「围绕重写行为做文章」的思路,可能都会成为一条重要的分支。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)