CV论文速递:覆盖医疗与生物医学影像、觉定位与多智能体轨迹预测、多模态与视觉-语言模型优化等方向(11.10-11.14)
本周精选10篇CV领域前沿论文,覆盖医疗与生物医学影像、觉定位与多智能体轨迹预测、多模态与视觉-语言模型优化、生成模型与域自适应等方向。全部300多篇论文皆可自取。
本周精选10篇CV领域前沿论文,覆盖医疗与生物医学影像、觉定位与多智能体轨迹预测、多模态与视觉-语言模型优化、生成模型与域自适应等方向。全部300多篇论文皆可自取。

一、医疗与生物医学影像方向
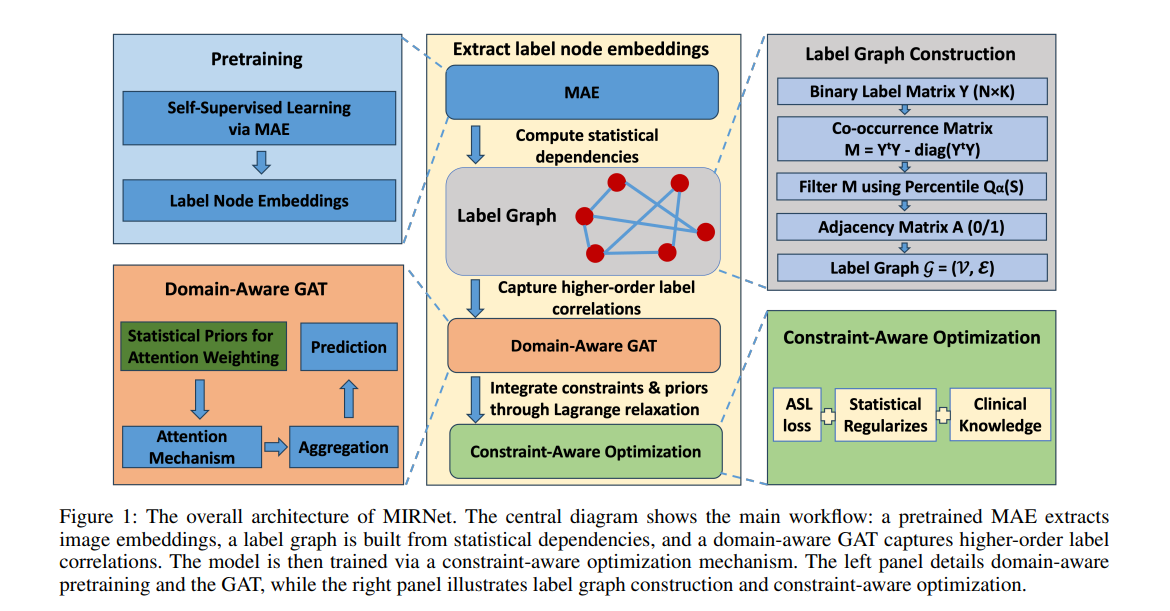
1、MIRNet: Integrating Constrained Graph-Based Reasoning with Pre-training for Diagnostic Medical Imaging
作者:Shufeng Kong, Zijie Wang, Nuan Cui, Hao Tang, Yihan Meng, Yuanyuan Wei, Feifan Chen, Yingheng Wang, Zhuo Cai, Yaonan Wang, Yulong Zhang, Yuzheng Li, Zibin Zheng, Caihua Liu
亮点:针对医疗影像自动解读中存在的标注稀缺、标签不平衡、临床合理性约束难满足等核心痛点,提出融合自监督预训练与约束图推理的MIRNet框架。核心创新包括:1)采用自监督掩码自编码器(MAE)从无标签数据中学习可迁移视觉表征,缓解标注依赖;2)通过图注意力网络(GAT)建模专家定义的结构化图中的标签相关性,捕捉诊断逻辑关联;3)利用KL散度和正则化损失实现临床先验约束感知优化,确保预测结果符合医学常识;4)结合非对称损失(ASL)和集成提升策略,有效缓解标签不平衡问题。同时,为解决舌诊分析领域数据匮乏问题,构建并公开了包含4000张图像、22个诊断标签的TongueAtlas-4K基准数据集(目前最大规模舌诊公开数据集)。实验验证该框架在舌诊任务上达到SOTA性能,且可轻松迁移至更广泛的医疗影像诊断场景,为临床辅助诊断提供了高效且可靠的解决方案。
论文:https://arxiv.org/pdf/2511.10013
Comments:To appear at AAAI-26;MSC Class: 68T07
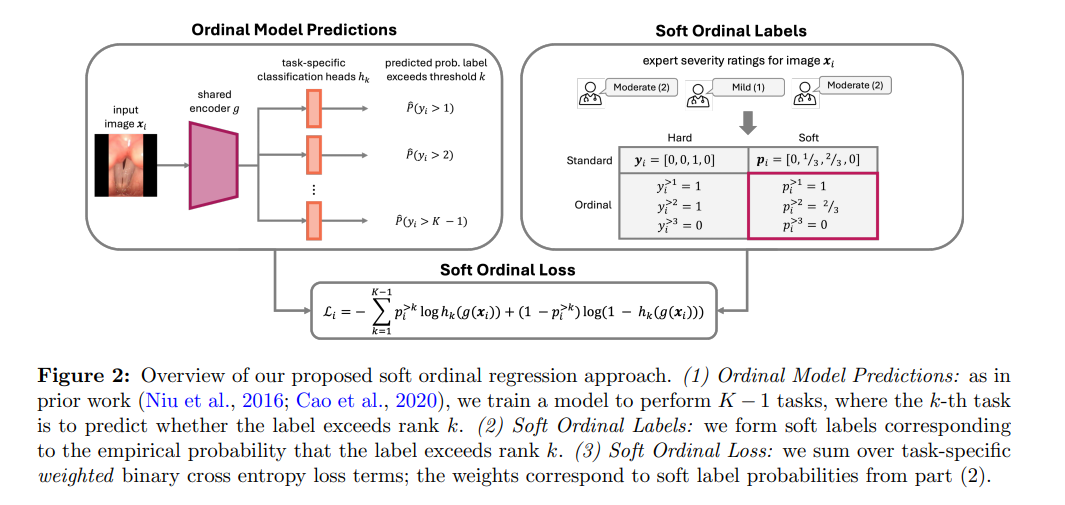
2、Classifying Phonotrauma Severity from Vocal Fold Images with Soft Ordinal Regression
作者:Katie Matton, Purvaja Balaji, Hamzeh Ghasemzadeh, Jameson C. Cooper, Daryush D. Mehta, Jarrad H. Van Stan, Robert E. Hillman, Rosalind Picard, John Guttag, S. Mazdak Abulnaga
亮点:首次提出基于声带图像的语音创伤(phonotrauma)严重程度自动分类方法,解决临床评估中人工判断成本高、可靠性差异大的问题。针对语音创伤严重程度的序数特性(从轻度到重度连续分布),采用序数回归框架,并创新性地提出软序数回归损失函数改进,可直接处理反映标注者评分分布的软标签,有效建模标注不确定性。实验表明,该方法的预测性能接近临床专家水平,且能生成校准良好的不确定性估计,为语音创伤的客观评估提供了自动化工具。该成果可支持大规模语音创伤相关研究,助力提升临床对疾病的理解和患者诊疗效果。
论文:https://arxiv.org/pdf/2511.09702
Comments:16 pages, 9 figures, 5 tables; ML4H 2025; Proceedings of Machine Learning Research 297, 2025
二、视觉定位与多智能体轨迹预测方向
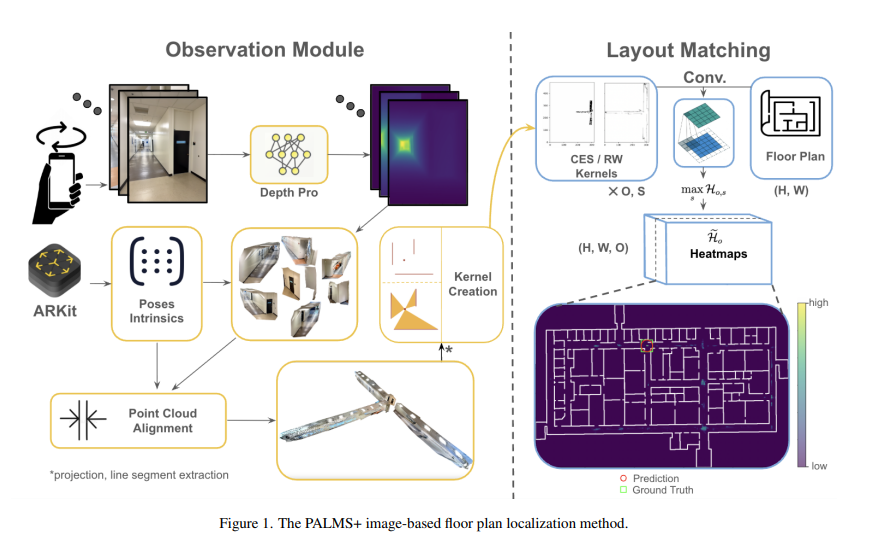
1、PALMS+: Modular Image-Based Floor Plan Localization Leveraging Depth Foundation Model
作者:Yunqian Cheng, Benjamin Princen, Roberto Manduchi
亮点:针对GPS缺失环境下室内定位的核心需求,突破传统视觉定位方法依赖LiDAR短测距、室内布局模糊性的局限,提出模块化图像基定位系统PALMS+。核心创新在于:1)无需训练即可实现定位,利用深度基础模型(Depth Pro)从带姿态的RGB图像中重建尺度对齐的3D点云,摆脱对专用传感器的依赖;2)通过与平面图的卷积操作进行几何布局匹配,输出位置和姿态的后验分布,支持静态直接定位和序列定位两种场景;3)采用模块化设计,兼顾灵活性与实用性。在Structured3D数据集和包含4栋校园建筑80个观测值的自定义数据集上,静态定位精度超越PALMS和F3Loc;集成粒子滤波用于33条真实世界轨迹的序列定位时,定位误差显著降低,为应急响应、辅助导航等无基础设施依赖的室内定位场景提供了高性能解决方案。
论文:https://arxiv.org/pdf/2511.09724
开源代码:https://github.com/Head-inthe-Cloud/PALMS-Plane-based-Accessible-Indoor-Localization-Using-Mobile-Smartphones
Comments:Accepted to IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2026, Application Track. Main paper: 8 pages, 5 figures. Supplementary material included
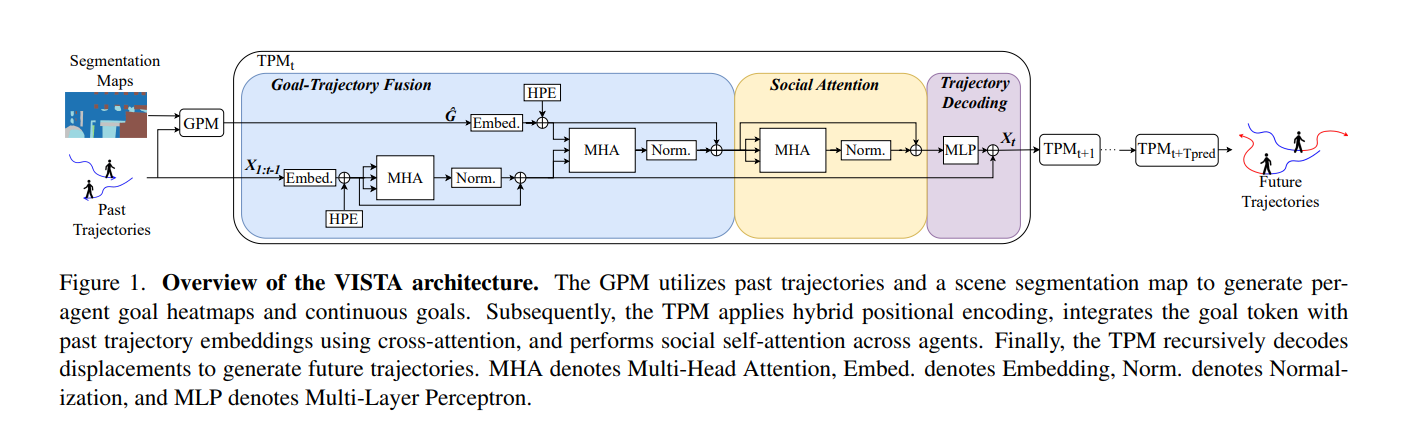
2、VISTA: A Vision and Intent-Aware Social Attention Framework for Multi-Agent Trajectory Prediction
作者:Stephane Da Silva Martins, Emanuel Aldea, Sylvie Le Hégarat-Mascle
亮点:聚焦密集交互环境下多智能体轨迹预测的核心挑战——难以同时捕捉智能体长期目标与细粒度社交交互,导致预测轨迹不真实。提出递归目标条件Transformer框架VISTA,三大核心设计:1)跨注意力融合模块,将长视野意图与历史运动状态有效集成,确保轨迹预测的目标一致性;2)社交令牌注意力机制,灵活建模智能体间的动态交互关系;3)成对注意力图,使推理时的社交影响模式具备可解释性。创新地将单智能体目标条件预测扩展为连贯的多智能体预测框架,并引入碰撞率作为轨迹联合真实性的评估指标。在高密度MADRAS基准和SDD数据集上,不仅实现ADE、FDE、minFDE等指标的SOTA,还大幅降低碰撞率:MADRAS上从2.14%降至0.03%,SDD上实现零碰撞,为自动驾驶等安全关键型自主系统提供了社交合规、目标感知且可解释的轨迹预测方案。
论文:https://arxiv.org/pdf/2511.10203
Comments:Paper accepted at WACV 2026
三、多模态与视觉-语言模型优化方向
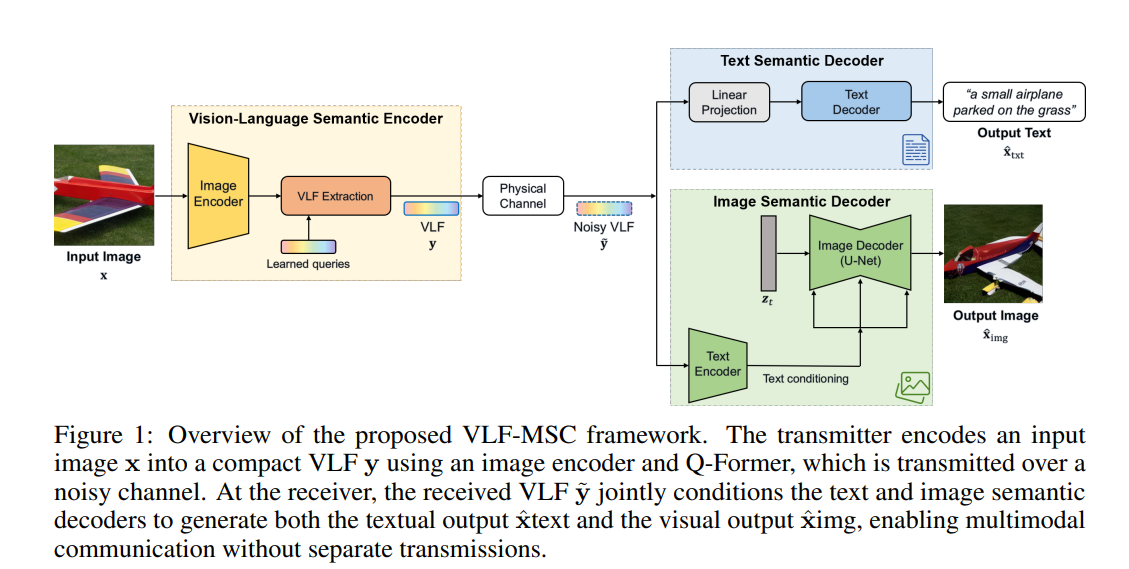
1、VLF-MSC: Vision-Language Feature-Based Multimodal Semantic Communication System
作者:Gwangyeon Ahn, Jiwan Seo, Joonhyuk Kang
亮点:突破传统语义通信技术中图像与文本模态分离处理的局限,提出视觉-语言特征多模态语义通信系统VLF-MSC。核心创新在于采用预训练视觉-语言模型(VLM)将源图像编码为统一的视觉-语言语义特征(VLF),通过无线信道单次传输该紧凑特征,接收端基于VLF分别驱动解码器语言模型生成描述文本、扩散模型生成语义对齐图像。该设计消除了模态专用流和重传需求,显著提升频谱效率和适应性;同时借助基础模型的强大能力,实现对信道噪声的鲁棒性和语义保真度的兼顾。实验表明,在低信噪比(SNR)条件下,VLF-MSC在文本和图像两种模态的语义准确性上均超越纯文本、纯图像基线方法,且带宽需求大幅降低,为多模态语义通信提供了高效统一的新范式。
论文:https://arxiv.org/pdf/2511.10074
Comments:To appear in the AI4NextG Workshop at NeurIPS 2025
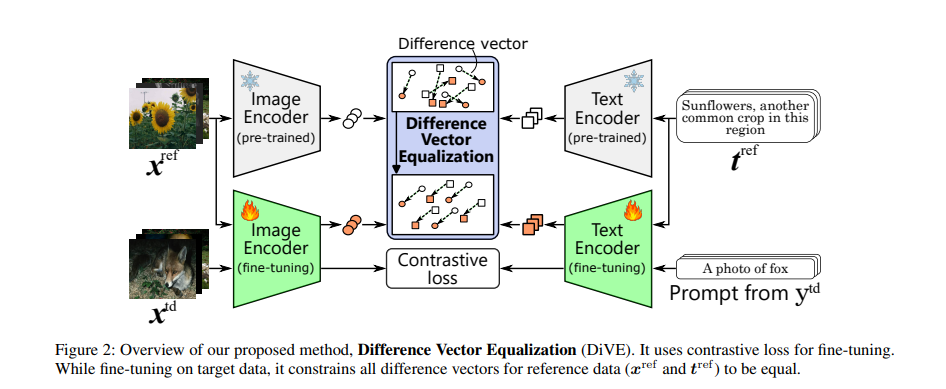
2、Difference Vector Equalization for Robust Fine-tuning of Vision-Language Models
作者:Satoshi Suzuki, Shin’ya Yamaguchi, Shoichiro Takeda, Taiga Yamane, Naoki Makishima, Naotaka Kawata, Mana Ihori, Tomohiro Tanaka, Shota Orihashi, Ryo Masumura
亮点:针对对比预训练视觉-语言模型(如CLIP)在分布内(ID)数据微调时,易丢失分布外(OOD)和零样本泛化能力的核心问题,提出差异向量均衡(DiVE)方法。关键洞察在于:现有鲁棒微调方法复用预训练的对比学习范式,会破坏对泛化至关重要的嵌入几何结构。DiVE通过约束“预训练模型嵌入与微调模型嵌入的差异向量”在不同样本间保持一致性,实现几何结构的有效保留。具体设计两种损失:1)平均向量损失(AVL),将所有差异向量约束为其加权平均,全局保留几何结构;2)成对向量损失(PVL),确保多模态对齐的一致性,局部维护结构特性。实验验证,DiVE在不损害ID任务性能的前提下,显著提升了模型的OOD泛化能力和零样本分类性能,为视觉-语言模型的鲁棒微调提供了新思路。
论文:https://arxiv.org/pdf/2511.09973
Comments:Accepted by AAAI 2026
四、生成模型与域自适应方向
1、Right Looks, Wrong Reasons: Compositional Fidelity in Text-to-Image Generation
作者:Mayank Vatsa, Aparna Bharati, Richa Singh
亮点:系统性揭示当前主流文本到图像生成模型的核心缺陷——组合逻辑处理能力缺失,并通过全面调研分析其根本原因。聚焦否定、计数、空间关系三大核心组合原语,发现模型在单一原语任务上表现尚可,但在组合任务中性能急剧下降,存在严重的干扰问题。深入追溯问题根源:1)训练数据中几乎缺乏显式否定表达;2)连续注意力架构本质上不适合处理离散逻辑;3)现有评估指标侧重视觉合理性而非约束满足。通过分析最新基准和方法,明确指出简单的模型缩放或增量调整无法弥补这一差距,强调实现真正的组合性需要在表示学习和推理机制上进行根本性创新。该研究为文本到图像生成模型的未来发展指明了关键方向,对推动生成模型的逻辑一致性提升具有重要指导意义。

论文:https://arxiv.org/pdf/2511.10136
Comments:Accepted in AAAI 2026
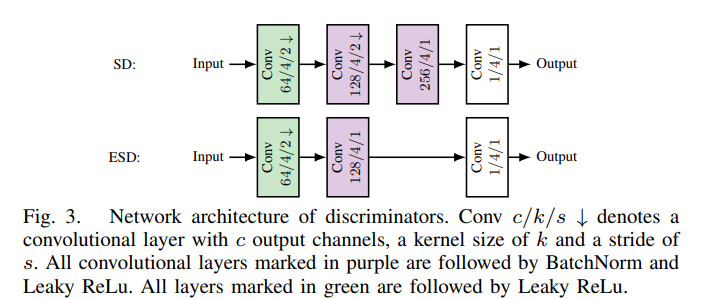
2、Domain Adaptation for Camera-Specific Image Characteristics using Shallow Discriminators
作者:Maximiliane Gruber, Jürgen Seiler, André Kaup
亮点:针对不同相机采集图像存在的特异性特征导致的域间隙问题(训练数据中无该特征时,感知算法性能下降),提出基于浅层判别器的像素级域自适应方法。核心创新在于:通过减小判别器的感受野尺寸,在低网络复杂度下更精准地复现局部失真特征,从而高效学习“纯净图像到失真图像”的映射关系。在实例分割的域自适应场景中,针对单一失真类型,平均精度较现有方法提升高达0.15;针对简化相机模型中的相机特异性特征,平均精度提升高达0.16。在模型复杂度方面,该方法与某SOTA方法参数数量相当,同时较另一SOTA方法参数减少20倍,实现了效率与性能的完美平衡,为相机特异性图像特征的域自适应问题提供了轻量化解决方案。
论文:https://arxiv.org/pdf/2511.10424
Comments:5 pages, 7 figures, accepted for International Conference on Visual Communications and Image Processing (VCIP) 2025
五、模型优化与高效推理方向
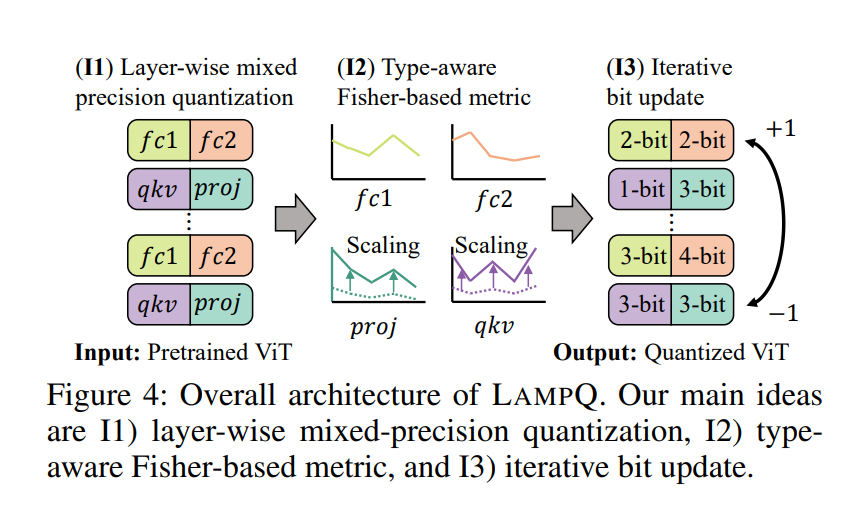
1、LampQ: Towards Accurate Layer-wise Mixed Precision Quantization for Vision Transformers
作者:Minjun Kim, Jaeri Lee, Jongjin Kim, Jeongin Yun, Yongmo Kwon, U Kang
亮点:针对视觉Transformer(ViT)量化中现有方法存在的精度均匀分配、跨组件度量尺度不匹配、量化无关比特分配三大缺陷,提出分层混合精度量化方法LampQ。核心创新包括:1)采用分层量化策略,兼顾细粒度控制与高效加速;2)引入类型感知Fisher度量,精准衡量ViT不同组件(如注意力层、MLP层)的量化敏感性,解决度量尺度不匹配问题;3)通过整数线性规划实现最优比特分配,并结合迭代更新机制进一步优化,确保比特分配与量化过程紧密耦合。在图像分类、目标检测、零样本量化等多种任务的预训练ViT模型上进行广泛实验,结果表明LampQ实现了SOTA的量化性能,在降低模型存储和计算成本的同时,最大限度保留原始模型精度。
论文:https://arxiv.org/pdf/2511.10004
Comments:AAAI 2026
2、AdaptViG: Adaptive Vision GNN with Exponential Decay Gating
作者:Mustafa Munir, Md Mostafijur Rahman, Radu Marculescu
亮点:针对视觉图神经网络(ViG)在图构建阶段存在的计算开销大、效率低的问题,提出高效混合视觉GNN架构AdaptViG。核心创新包括:1)提出自适应图卷积机制,基于高效静态轴向支架和内容感知的指数衰减门控策略,根据特征相似度选择性加权长距离连接,实现动态且高效的图构建;2)采用混合特征聚合策略,早期阶段利用高效门控机制降低计算成本,最终阶段通过全局注意力块实现最大化特征聚合。性能与效率trade-off达到SOTA:AdaptViG-M实现82.6%的Top-1准确率,较ViG-B提升0.3%,同时参数减少80%、GMACs降低84%;下游任务中,AdaptViG-M在语义分割(45.8 mIoU)、目标检测(44.8 APbox)、实例分割(41.1 APmask)任务上均超越参数多78%的EfficientFormer-L7,为视觉GNN的高效部署提供了新方案。
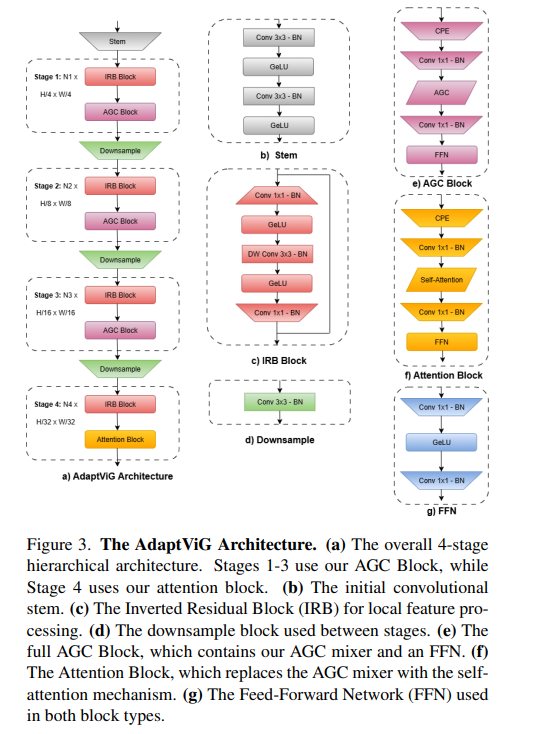
论文:https://arxiv.org/pdf/2511.09942
Comments:Accepted in 2026 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV 2026)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)