(AAAI-2026_Oral)通过自回归表示对齐释放大型语言模型在文本到图像生成中的潜力
本文提出了一种新颖的自回归表示对齐(ARRA)训练框架,旨在无需架构修改的情况下提升大型语言模型(LLMs)在文本到图像生成任务中的表现。ARRA通过引入混合token <HYBNEXT>,将局部下一token预测与外部视觉基础模型的全局语义对齐相结合,同时保留了原始自回归范式的优势。实验结果表明,ARRA在自然图像和医学图像生成任务中均取得显著改进:在ImageNet上FID降低16
通过自回归表示对齐释放大型语言模型在文本到图像生成中的潜力
paper是中科院发表在AAAI 2026 Oral的工作
paper title:Unleashing the Potential of Large Language Models for Text-to-Image Generation through Autoregressive Representation Alignment
Code:链接
Abstract
我们提出了自回归表示对齐(Autoregressive Representation Alignment,ARRA),这是一种新的训练框架,无需架构修改即可在自回归大型语言模型(LLMs)中实现全局一致的文本到图像生成。不同于以往需要复杂架构重设计的工作,ARRA 通过全局视觉对齐损失以及一种混合 token —— <HYBNEXT> —— 将 LLM 的隐藏状态与外部视觉基础模型的视觉表示对齐。该 token 施加了双重约束:局部的下一 token 预测与全局的语义蒸馏,使 LLM 能够在保持原有自回归范式的同时,隐式学习空间与上下文一致性。大量实验验证了 ARRA 的即插即用的通用性。在从零训练文本到图像生成的 LLM 时,ARRA 在不修改原始架构和推理机制的前提下,使自回归模型(如 LlamaGen)在 ImageNet 上的 FID 降低 16.6%,在 LAION-COCO 上降低 12.0%。对于仅经过文本生成训练的 LLM,ARRA 在先进模型(如 Chameleon)上,使 MIMIC-CXR 的 FID 降低 25.5%,DeepEyeNet 的 FID 降低 8.8%。在领域自适应方面,ARRA 将通用 LLM 与专用模型(如 BioMedCLIP)对齐,在医学影像(MIMIC-CXR)任务上比直接微调降低 18.6% 的 FID。这些结果表明,训练目标的重新设计而非架构修改即可解决跨模态全局一致性的挑战。ARRA 为推进自回归模型提供了一种互补范式。
1 Introduction
大型语言模型(LLMs)(Achiam et al. 2023;Yang et al. 2025;Guo et al. 2025)以及后续的多模态大型语言模型(MLLMs)(Team et al. 2023;Wang et al. 2024;Liu et al. 2024b;Zhu et al. 2025)已经彻底革新了生成式人工智能领域。这些模型基于自回归(AR)范式,通过一个简单但强大的下一词预测框架,在复杂理解任务中展现出卓越的可扩展性和泛化能力。受 LLM 成功的启发,一些研究者试图将自回归的“下一词预测”范式复刻到文本生成图像任务中。该范式被直接应用于 DALL·E(Ramesh et al. 2021)、Parti(Yu et al. 2022)和 LlamaGen(Sun et al. 2024a)等模型中,在这些模型中,图像被视为离散 token 序列。
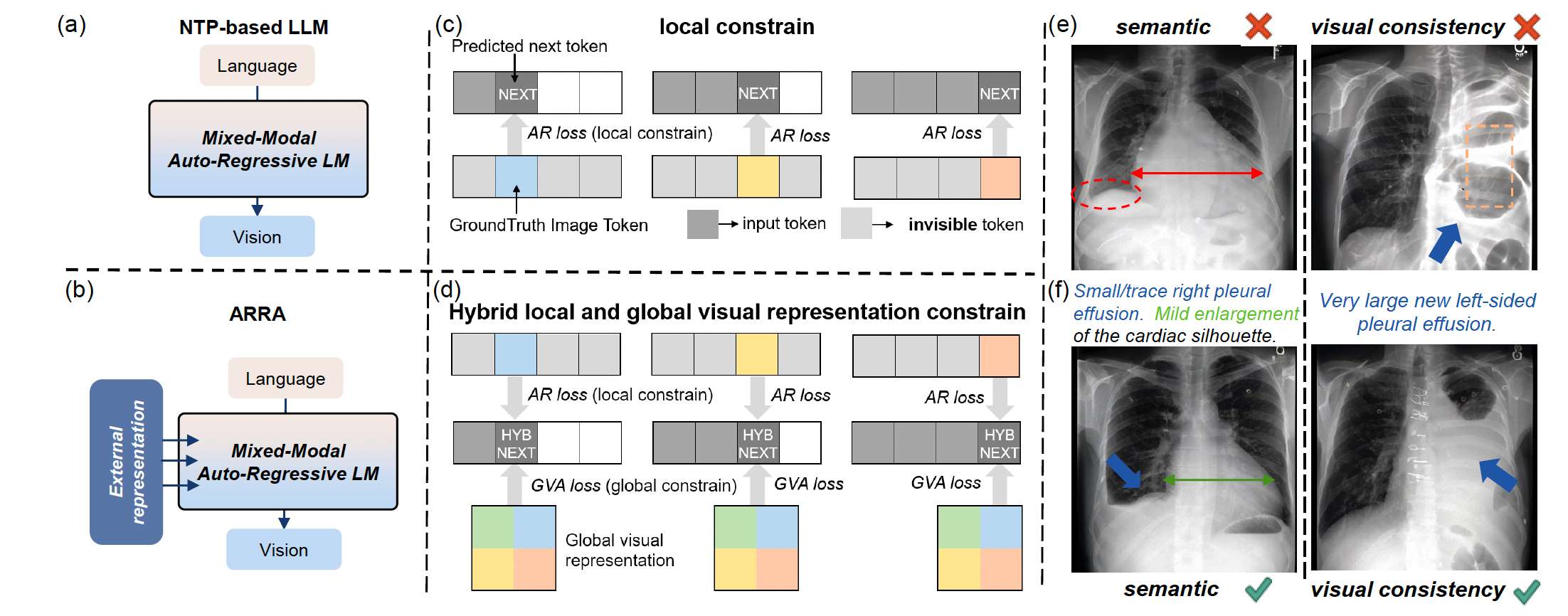
图 1:ARRA 通过重新定义训练目标以促进全局一致性,从而实现高质量的文本生成图像。(a)© 传统基于下一词预测(NTP)的 LLM 仅依赖下一 token <NEXT> 的自回归损失(AR loss)来提供局部约束。(b)(d) ARRA 构建了混合 token <HYBNEXT>,通过引入外部全局视觉表示对其进行对齐,使 <HYBNEXT> 同时受到局部 AR loss 与全局视觉对齐损失(GVA loss)的共同约束。(e)(f) ARRA 在语义一致性和视觉连续性方面展现出显著优势。
然而,尽管“下一词预测”范式在语言任务中表现出色(因为局部依赖关系与序列结构天然对齐),它在弥合语言与图像之间显著的跨模态差距方面却表现不佳。如 Fig. 1© 所示,仅优化局部下一 token 预测会使模型过度关注孤立的 token 级特征,从而忽略视觉内容所需的全局一致性。这有时会导致生成图像出现碎片化部分,例如 X 光片中肋骨错位,细粒度细节无法与整体结构协调;也会引发语义不匹配,如 Fig. 1(e) 所示,全局信息无法保持,导致生成图像出现不一致性。
意识到这一局限性后,近期研究开始探索将全局约束注入自回归框架,以充分释放 LLM 在图像生成中的潜力(Zhou et al. 2024;Xie et al. 2024;Tian et al. 2024)。Transfusion(Zhou et al. 2024)和 Show-O(Xie et al. 2024)引入了双向注意力机制,分别通过 patch diffusion 和 mask token 建模来学习全局图像结构。这些方法在高质量图像生成方面取得了有前景的效果,并展示了 LLM 在多模态生成中的潜力。然而,它们依赖于架构上的修改,例如跨模态注意力层或 grafted diffusion 模块。尽管有效,这类修改往往偏离标准 LLM 框架,从而限制了它们与在纯自回归范式下表现卓越的预训练 LLM 的兼容性。例如,将一个现成的 LLM 改造为文本生成图像模型需要重新训练这些改动组件,从而失去既有 scaling laws 和泛化能力带来的优势。这一实际限制引出了一个关键问题:是否可以在不修改原始架构或推理机制的情况下,释放 LLM 在文本生成图像中的全部潜力?
为了解决这个问题,我们提出了 Autoregressive Representation Alignment(ARRA),这是一种重新定义 LLM 学习文本生成图像方式的新训练框架。不同于以往通过修改架构(如添加注意力层或扩散模块)的方法,ARRA 保留了原始 LLM 框架,同时将全局约束直接注入训练目标。我们的核心洞察很简单:全局一致性并不需要架构复杂性;它可以通过重新设计训练范式来实现。具体而言,ARRA 在标准自回归损失上增加了一个全局视觉对齐损失,该损失将 LLM 的潜在表示与来自预训练基础模型的语义指导进行对齐(Fig. 2)。
为了连接局部与全局学习,我们引入了一种混合 token <HYBNEXT>,它作为一个双向锚点。在局部层面,它通过标准 codebook 索引预测下一个 token;在全局层面,其潜在 embedding 与外部模型(如 BioMedCLIP(Zhang et al. 2023)或 MedSAM(Ma et al. 2024))提取的压缩视觉特征进行对齐,通过我们提出的全局视觉对齐损失实现。通过在训练过程中将外部模型中丰富的语义特征(例如空间关系、对象一致性)蒸馏进 <HYBNEXT> token,ARRA 使自回归序列能够隐式学习全局结构。更重要的是,这种对齐仅发生在训练阶段,模型的推理过程保持不变,从而保留其推理阶段的高效率。
我们的实验表明,ARRA 框架在自然图像与医学图像生成任务中都具有高度的通用性,无需进行架构修改即可取得性能提升。ARRA 在自回归 LLM 上支持三项关键能力:(1) ARRA 增强了从零开始训练 T2I LLM 的效果。将其应用于具有不同参数规模的 LlamaGen(Sun et al. 2024a)时,它能够持续提升生成性能并展现出强大的可扩展性。(2) ARRA 能够有效地将仅具备文本生成能力的预训练 LLM 转换为 T2I 生成器。当应用于不具备图像生成能力的 LLM(如 Chameleon(Team 2024))时,ARRA 能带来稳定的性能提升。(3) ARRA 促进了通用生成模型向特定领域的适配。通过将领域特定的先验(如 BioMedCLIP、MedSAM)引入具备图像生成能力的 LLM(如 Lumina-mGPT(Liu et al. 2024a))中,ARRA 的表现显著优于直接微调。这些能力证明了 ARRA 框架的即插即用灵活性。
主要贡献总结如下:
(i) 我们提出了 Autoregressive Representation Alignment,这是一种重新定义 LLM 如何学习文本生成图像任务的新训练框架。通过将训练目标与外部表示对齐,ARRA 在保留原始架构与推理效率的前提下,解决了 LLM 的局部依赖限制。
(ii) 我们提出了 <HYBNEXT> token,这是一种新机制,通过外部模型(如 BioMedCLIP 或 MedSAM)的蒸馏,将局部的下一 token 预测与全局语义对齐相结合,使模型能够隐式学习空间和上下文关系。
(iii) 我们提供了详细的实验分析,深入探讨了对齐 token 的选择、特征聚合策略以及外部表示的使用。这些发现为有效利用表示对齐提供了实用指导。
(iv) ARRA 提供了即插即用的灵活性,使得从零训练 T2I LLM、将预训练文本生成模型转变为 T2I 生成器、以及将通用生成模型适配到特定领域成为可能,且全部无需架构修改。这些能力在自然图像和医学图像生成任务中使用先进的自回归模型得到验证。
2 Related Work
2.1 Visual Generation Models
扩散模型。扩散模型的成功彻底革新了图像生成范式(Qu et al. 2015, 2019;Rombach et al. 2022a;Liu et al. 2024c;Xie et al. 2025)。DiTs(Peebles and Xie 2023)通过用 Transformer 替代或融合 U-Net 展现出强大的可扩展性。这进一步启发了后续模型,如 SD3(Esser et al. 2024)、Imagen3(Baldridge et al. 2024),在图像生成中取得新的最先进水平。近期研究 REPA(Yu et al. 2025)探索利用外部表示增强扩散模型。它采用基于 patch 的表示对齐机制,将扩散 Transformer 的每个 patch 级隐藏状态与来自外部编码器的相应 patch token 对齐。这种对齐在不修改架构的情况下提升了生成质量。然而,REPA 的策略无法直接兼容 AR 模型。AR 模型按序列方式生成图像 token,在训练期间不会同时产生全部 patch token,因此无法进行 patch 级对齐。与此不同,ARRA 引入了一种新颖的混合 token,用于连接局部的下一 token 预测与全局对齐机制,使得对齐机制能够有效整合进 AR 架构中。更多讨论请参考附录 2。
自回归模型。早期的开创性工作,如 VQ-VAE(Van Den Oord, Vinyals et al. 2017)、VQ-GAN(Esser, Rombach, and Ommer 2021)和 DALL-E(Ramesh et al. 2021),展示了自回归模型在图像生成中的潜力。后续工作如 RQ-Transformer(Lee et al. 2022)也采用逐行扫描(raster-scan)的生成方式,并通过引入多尺度或堆叠编码提升图像生成性能。近期研究通过使用尺度建模(Tian et al. 2024)和去除向量量化(Li et al. 2024a;Fan et al. 2025),达到了可与扩散模型媲美的生成性能。此外,基于 Masked Prediction 的自回归模型(Chang et al. 2022;Li et al. 2024b)采用类似 BERT(Devlin et al. 2019)的掩码预测建模,显著提升了生成效率与质量。
2.2 LLMs for Text-to-Image Generation
目前,研究者将注意力集中在基于 LLM 的文本生成图像模型上,旨在复刻 LLM 在语言任务中的成功。早期工作利用扩散模型作为工具来扩展 LLM(Dong et al. 2024;Ge et al. 2024;Sun et al. 2024b)。这些方法将 LLM 作为特征提取器,引导扩散模型进行视觉生成。然而,这类模型设计复杂,且无法充分发挥 LLM 在视觉生成方面的潜在能力。近期研究(Sun et al. 2024a;Team 2024;Lu et al. 2024;Liu et al. 2024a)尝试在单一 LLM 内统一文本与图像建模,通过 tokenizer 优化(Sun et al. 2024a)、早期融合建模(Team 2024)、灵活分辨率建模(Liu et al. 2024a)等方式提升生成性能。这些方法将文本与图像统一离散化为 token,再输入 LLM 进行基于下一 token 预测的序列建模。然而,由下一 token 预测提供的局部约束难以弥合语言与图像之间的跨模态鸿沟。
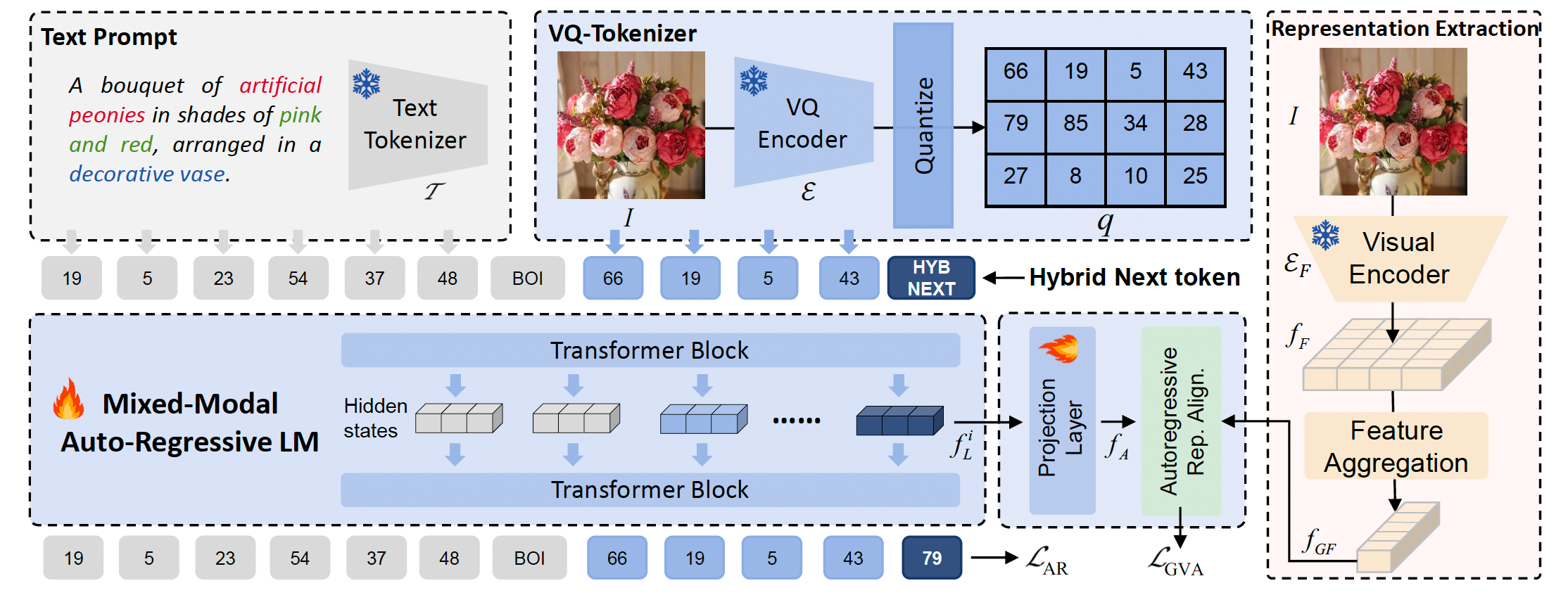
图 2:提出的 ARRA 框架。我们将自回归序列中所预测的下一个 token 定义为“混合下一 token”,记为 <HYBNEXT>。在训练过程中,<HYBNEXT> 不仅通过来自下一 token 预测与 LLM codebook 匹配的自回归损失 L A R \mathcal{L}_{AR} LAR 在局部受到约束,同时也通过视觉对齐损失 L G V A \mathcal{L}_{GVA} LGVA 在全局受到约束,该损失利用外部训练良好的表示来调节其隐藏状态。我们从预训练的基础模型中提取视觉表示,并进一步聚合这些特征以获得语义丰富的表示用于对齐。
3 Proposed Method
我们的目标是在不改变 LLM 的下一 token 预测范式的前提下,实现高质量的图像生成。我们认为,当模型缺乏学习全局特征的能力时,LLM 内在的跨域差异会对图像生成任务造成显著挑战。为解决这一问题,我们提出了自回归表示对齐(Autoregressive Representation Alignment, ARRA)框架(见 Fig. 2),该框架利用经过良好预训练的基础模型的表示能力,来促进复杂文本到图像自回归生成的训练。我们的框架仅在训练阶段使用,不会影响推理过程。它能够以高性价比的方式帮助生成具有卓越语义一致性的高质量图像。
3.1 Overview
我们的目标是利用来自外部基础视觉编码器 E F \mathcal{E}_F EF 的表示来训练一个自回归模型 M θ \mathcal{M}_\theta Mθ。 M θ \mathcal{M}_\theta Mθ 接收文本提示 T T T 作为输入,并生成目标图像 I I I。在训练过程中, T T T 和 I I I 会首先被分别标记化为 token 序列 s T s_T sT 和 s I s_I sI。这些 token 序列随后被用于训练基于 Transformer 的自回归模型 M θ \mathcal{M}_\theta Mθ。同时,基础视觉编码器 E F \mathcal{E}_F EF 将图像 I I I 编码为全局视觉表示 f G F f_{GF} fGF,该表示用于与 M θ \mathcal{M}_\theta Mθ 从 x t x_t xt 提取的特征 f A f_A fA 进行对齐。在图像生成阶段,对齐模块会被移除,图像 token 由 M θ \mathcal{M}_\theta Mθ 通过下一 token 预测方式生成。最后,输出的图像 token 会通过图像解码器解码回像素空间,以生成目标图像 I I I。我们在第 3.2 节描述自回归建模过程,并在第 3.3 节详细介绍我们的自回归表示对齐框架。
3.2 Modeling via Next-Token Prediction
自回归架构包含两个核心组件:(1) 一个基于 Transformer 的自回归模型 M θ \mathcal{M}_\theta Mθ,用于对 token 序列进行概率建模。(2) 一个基于 VQ 的模型(Esser, Rombach, and Ommer 2021),包含编码器 E \mathcal{E} E、量化器 Q \mathcal{Q} Q 和解码器 D \mathcal{D} D,用于实现图像像素与离散 token 序列之间的转换。其形式化过程包含以下两部分:
Tokenization(标记化)。为了在图像域中应用下一 token 预测建模,首先需要将连续的二维图像像素转换为离散序列。该过程包含两个步骤:(1) 将 2D 图像像素转换为 2D 图像 tokens;(2) 将 2D 图像 tokens 转换为 1D token 序列。具体而言,给定图像 I ∈ R H × W × 3 I \in \mathbb{R}^{H \times W \times 3} I∈RH×W×3,我们首先获得图像特征图 f = E ( I ) ∈ R h × w × d f = \mathcal{E}(I) \in \mathbb{R}^{h \times w \times d} f=E(I)∈Rh×w×d,其中 h = H / c , w = W / c , d h = H/c, w = W/c, d h=H/c,w=W/c,d 是 code 的维度, c c c 表示压缩因子。随后,我们将 f f f 转换为离散 tokens: q = Q ( f ) ∈ Z h × w q = \mathcal{Q}(f) \in \mathbb{Z}^{h \times w} q=Q(f)∈Zh×w,其中量化器 Q ( ⋅ ) \mathcal{Q}(\cdot) Q(⋅) 将图像特征图中每个向量 f ( i , j ) f^{(i,j)} f(i,j) 映射到其最近的 codebook 向量 z ( i , j ) z^{(i,j)} z(i,j) 的索引 q ( i , j ) q^{(i,j)} q(i,j)。图像 tokens 被进一步重排为 1D token 序列 s I = { x 1 I , x 2 I , x 3 I , … , x n I } s_I = \{x_1^I, x_2^I, x_3^I, \ldots, x_n^I\} sI={x1I,x2I,x3I,…,xnI},长度为 h ⋅ w h \cdot w h⋅w,按逐行扫描顺序排列。
对于文本提示 T T T,我们得到离散序列 s T = T ( T ) = { x 1 T , x 2 T , x 3 T , … , x m T } s_T = \mathcal{T}(T) = \{x_1^T, x_2^T, x_3^T, \ldots, x_m^T\} sT=T(T)={x1T,x2T,x3T,…,xmT},其中 T ( ⋅ ) \mathcal{T}(\cdot) T(⋅) 表示文本 tokenizer。
Next token prediction modeling(下一 token 预测建模)。我们将文本序列 s T s_T sT 与图像序列 s I s_I sI 组合成离散 tokens 序列 x = { x 1 , x 2 , x 3 , … , x n } x = \{x_1, x_2, x_3, \ldots, x_n\} x={x1,x2,x3,…,xn},其中 x n x_n xn 是 tokenizer 词表 V V V 中的整数。下一 token 预测范式假设当前 token x t x_t xt 的概率仅依赖其前缀 ( x 1 , x 2 , x 3 , … , x t − 1 ) (x_1, x_2, x_3, \ldots, x_{t-1}) (x1,x2,x3,…,xt−1)。序列建模的似然可表示为:
p ( x ) = ∏ t = 1 n p ( x t ∣ x 1 , x 2 , . . . , x t − 1 ) . (1) p(x) = \prod_{t=1}^n p(x_t \mid x_1, x_2, ..., x_{t-1}). \tag{1} p(x)=t=1∏np(xt∣x1,x2,...,xt−1).(1)
自回归模型 M θ \mathcal{M}_\theta Mθ 将生成任务定义为预测下一 token 的分布,并通过交叉熵损失最大化似然 p θ ( x ) p_\theta(x) pθ(x):
L A R ( θ ) = E x t [ − log p θ ( x t ∣ x < t ) ] . (2) \mathcal{L}_{AR}(\theta) = \mathbb{E}_{x_t}[-\log p_\theta(x_t \mid x_{< t })]. \tag{2} LAR(θ)=Ext[−logpθ(xt∣x<t)].(2)
在训练过程中,自回归模型 M θ \mathcal{M}_\theta Mθ 根据前序 tokens x < t x_{< t} x<t 来预测下一个 token x t x_t xt,其中 M θ \mathcal{M}_\theta Mθ 第 i i i 层中 x t x_t xt 的隐藏状态记为 f L i f_L^i fLi。在最后一层,隐藏状态 f L − 1 f_L^{-1} fL−1 会传递到 LLM 的输出头以计算 x t x_t xt 的概率分布 p θ p_\theta pθ。
在原始自回归模型中, p θ p_\theta pθ 仅受单个 token(即 x t x_t xt)的局部上下文约束,缺乏捕获全局信息的能力。这一限制使模型无法充分建模复杂的跨模态关系。为了解决这一问题,我们提出了自回归表示对齐(Autoregressive Representation Alignment)。
3.3 Autoregressive Representation Alignment
我们将预训练基础模型提取的视觉表征与LLM的隐藏状态对齐,并研究不同对齐策略的影响。对齐的目标是使自回归 Transformer 的隐藏状态能够获得外部的全局表征,从而为图像重建提供有意义的指导。
预训练视觉表征提取。设 E F \mathcal{E}_F EF 为一个预训练基础模型的视觉编码器, I I I 为目标图像。我们将 I I I 编码为视觉表征 f F = E F ( I ) ∈ R N × D f_F = \mathcal{E}_F(I) \in \mathbb{R}^{N \times D} fF=EF(I)∈RN×D,其中 N , D N, D N,D 分别表示 f F f_F fF 的嵌入长度和维度。 f F f_F fF 被聚合成全局视觉表征 f G F f_{GF} fGF,即 f G F = agg ( f F ) ∈ R 1 × D f_{GF} = \text{agg}(f_F) \in \mathbb{R}^{1 \times D} fGF=agg(fF)∈R1×D,其中 agg(·) 表示特征聚合操作。该聚合操作能够充分提取特征中的全局信息,并便于与自回归模型的隐藏状态进行对齐。对于 CLIP 系列,我们参考(Raghu et al. 2021),使用来自 Transformer 视觉编码器的 <CLS> token 表征作为全局视觉表征。对于没有 <CLS> token 的 SAM 系列,我们改为对所有 patch 特征进行平均池化以完成特征聚合。
混合下一 token。我们将 LLM 序列中预测的下一 token 定义为 “HYBRID next token”,记作 <HYBNEXT>。不同于以往自回归模型中仅受 LLM codebook 约束的“局部受限 token”,我们的 <HYBNEXT> 能够充分融合外部、预训练良好的全局视觉表征,使其成为一个“全局且局部同时受约束的 token”。
全局视觉表征对齐。我们从自回归模型 M θ \mathcal{M}_\theta Mθ 中获得 <HYBNEXT> 的隐藏状态 f L i f_L^i fLi。该隐藏状态 f L i f_L^i fLi 经由一个投影层 A ϕ \mathcal{A}_\phi Aϕ 转换为 f A ∈ R 1 × D f_A \in \mathbb{R}^{1 \times D} fA∈R1×D,以与全局视觉表征 f G F ∈ R 1 × D f_{GF} \in \mathbb{R}^{1 \times D} fGF∈R1×D 对齐,即 f A = A ϕ ( f L i ) f_A = \mathcal{A}_\phi(f_L^i) fA=Aϕ(fLi),其中 A ϕ \mathcal{A}_\phi Aϕ 是一个两层 MLP。表征对齐通过一个“全局视觉对齐损失” L G V A \mathcal{L}_{GVA} LGVA 来完成,该损失最大化投影特征 f A f_A fA 与全局视觉表征 f G F f_{GF} fGF 的相似度:
L G V A ( θ , ϕ ) = sim ( f A , f G F ) . \mathcal{L}_{GVA}(\theta, \phi) = \text{sim}(f_A, f_{GF}). LGVA(θ,ϕ)=sim(fA,fGF).
其中 sim(·, ·) 表示余弦相似度损失。该对齐机制使得 <HYBNEXT> token 能够学习全局视觉表征,从而缩小跨模态差距,并使 token 预测过程更加可靠。
因此,自回归模型可通过以下复合损失进行联合优化:
L A R R A ( θ , ϕ ) = L A R ( θ ) + λ L G V A ( θ , ϕ ) . \mathcal{L}_{ARRA}(\theta, \phi) = \mathcal{L}_{AR}(\theta) + \lambda \mathcal{L}_{GVA}(\theta, \phi). LARRA(θ,ϕ)=LAR(θ)+λLGVA(θ,ϕ).
其中 λ \lambda λ 作为平衡超参数,用于控制对齐目标的相对重要性。在实验中我们设置 λ = 1 \lambda = 1 λ=1。
3.4 Versatile ARRA for Diverse Scenarios
我们的 ARRA 框架具有灵活且即插即用的特性,能够支持不同的训练场景和不同的 LLM 框架。因此,我们提供了三种具有代表性的模型变体:
(1) ARRA-Base。它从随机初始化开始训练一个 LLM,适用于没有可用预训练模型的场景,展示了 ARRA 从零开始学习多模态对齐的能力。
(2) ARRA。它使用一个具有强大文本生成能力的预训练 LLM 进行初始化,使得仅具备文本生成能力的 LLM 能够高效扩展到文本生成图像任务。
(3) ARRA-Adapt。它基于同时具备文本和图像生成能力的预训练 LLM,通过利用特定领域先验,使模型能够适应如医学影像等专业领域。
Discussion with related work
与 REPA(Yu et al. 2025)的讨论:尽管两个工作都利用了特征对齐的理念,但 ARRA 相较于 REPA 具有本质上的不同贡献:
不同的动机:REPA 通过将外部干净图像的表示注入扩散模型,解决其在学习高质量内部表示时面临的挑战。相比之下,ARRA 针对的是自回归 LLM 在文本生成图像任务中的一个根本性局限:缺乏捕获全局一致性的能力。不同于以往需要复杂架构重设计来施加全局约束的方法,ARRA 表明,全局一致性可以通过对齐驱动的训练范式自然涌现,而该训练范式通过将 LLM 的隐藏状态与外部视觉编码器的视觉表示对齐来实现。
REPA 不兼容自回归模型(AR):REPA 使用 patch 级对齐方式,将扩散 Transformer 的每个补丁级隐藏状态与外部编码器的补丁 token 匹配,即 DiTs 的所有补丁 ⇔ 外部编码器的所有补丁。但 AR 模型在训练期间不会输出所有图像补丁对应的 token,即 AR 无法提供 “所有补丁” ⇎ 外部编码器 “所有补丁”。因此,REPA 与 AR 是不兼容的。为了使特征对齐理念与 AR 的设计相兼容,我们设计了一个新的混合 token ,它作为双向锚点:在局部通过标准码本进行下一 token 预测,在全局通过特征对齐损失注入全局信息。第 4.2.1 节的结果验证了我们 设计的优越性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 27
27 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)