基于LORA微调的Qwen2.5-vl多模态大模型智能解析系统框图
本文档详细阐述基于LORA微调的Qwen2.5-vl多模态大模型智能解析系统框图。该系统针对电子工程领域文档自动分析中的数据稀缺与模型低效问题,通过数据收集优化、逻辑解析数据集创建、LORA微调等核心技术,实现系统框图的智能识别分析、逻辑拓扑重构及结果结构化输出,为电子工程领域文档自动化处理提供高效解决方案。
摘要
本文档详细阐述基于LORA微调的Qwen2.5-vl多模态大模型智能解析系统框图。该系统针对电子工程领域文档自动分析中的数据稀缺与模型低效问题,通过数据收集优化、逻辑解析数据集创建、LORA微调等核心技术,实现系统框图的智能识别分析、逻辑拓扑重构及结果结构化输出,为电子工程领域文档自动化处理提供高效解决方案。
项目背景
电子工程领域飞速发展,文档数量呈爆炸式增长,但领域内大模型应用仍面临显著瓶颈。大模型训练所需的海量开源专业文档稀缺,标注数据不足且人工标注难度高、成本大。现有模型存在图文理解割裂问题,大语言模型无法识别图像信息,视觉模型难以理解文本内容,多模态大模型则在特定领域泛化能力和推理能力上表现不足。
项目目标
构建一套基于Qwen2.5-vl多模态大模型,通过LORA微调技术优化的智能解析系统,实现电子工程领域系统框图的精准识别、逻辑拓扑重构、智能逻辑解析,输出计算机可直接调用的结构化数据,降低模型训练与部署成本,提升电子工程文档自动分析效率与精度。
系统总体流程
数据收集:从专业论文及领域官网采集1000+涵盖不同绘图风格与细分领域的系统框图,保障数据多样性与丰富性。
逻辑拓扑:使用Label-Studio标注工具,对系统框图的组件位置、连接关系等进行精准标注,构建完整拓扑结构。
LORA微调:基于Qwen2.5-vl预训练模型,采用LORA微调技术,在保留模型原有推理能力的前提下,针对性适配系统框图分析任务。
逻辑解析:结合蒸馏构建的问答数据集,对模型进行指令监督微调,提升模型对图文逻辑的分析推理能力。
结果转化:将模型输出的自然语言结果转化为JSON格式,便于后续计算机系统识别、调用与二次开发。
模型量化:将微调后的Adapter参数与原始大模型参数量化合并,简化部署流程,降低部署成本。
数据层优化
原始系统框图数据存在明显不足:图像像素过大导致冗余信息过多,增加训练负担且影响模型性能;组件坐标绝对值不符合Qwen2.5-vl模型28×28像素的读取逻辑,qwen2.5处理图片会将图片调整至28*28的倍数(参考qwen官方github库中微调工具中的process_bbox.ipynb处理方式)。
通过分类筛选策略对原始数据进行精炼处理,将图片总像素调整至784×784以下,大幅减少冗余信息;统一调整组件坐标值以适配模型读取逻辑,消除坐标干扰。优化后的数据集可实现小数据量训练,模型精度部分指标甚至超越基于原始数据集训练的模型。
问答集创建
借鉴知识蒸馏技术,通过API调用ChatGPT、DeepSeek等超大模型构建30万+字专业问答集,同时抓取大模型解题的思考过程。
通过多个大模型交叉验证蒸馏数据集,确保数据正确性;建立数据集质量判断机制,采用多重清洗策略,保障数据与图片高度相关、难度适中且题型多样。
LORA微调优势
在Qwen2.5-vl预训练模型的权重矩阵之间插入低秩适配器,通过训练适配器参数实现模型的领域适配。该技术无需训练整个模型参数,仅更新少量适配器参数,大幅降低训练计算成本与显存占用,同时保留预训练模型的强大推理能力。
实验结果
系统可精准实现系统框图的逻辑拓扑重构:可视化拓扑图清晰展示组件位置分布与连接关系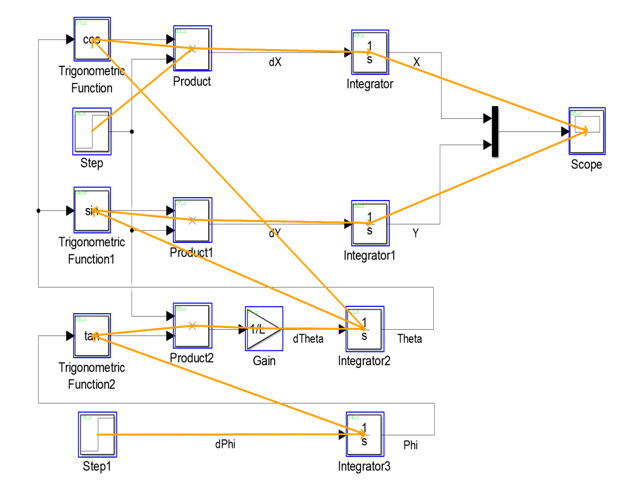
JSON格式文件结构化记录组件标识、坐标信息、输入输出连接关系
针对电子工程领域专业问题:
- 回答专业问题仅仅是微调难以保证准确性,后续我将尝试知识库等其他方向,同时也是求助大家能够提供一些建议。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)