【AAAI 2026 Oral】告别单一路径,即插即用LWGA模型,提出四种注意力并行新机制,多尺度特征捕捉能力拉满
遥感(RS)图像分析的效率受到两大冗余问题的制约:一是广阔同质背景导致的(spatial redundancy),二是目标尺度极端变化导致的现有的轻量化网络模型多为自然图像设计,难以同时应对遥感图像的这两个挑战,常常在保留局部细节和捕捉全局上下文之间顾此失彼。为解决此问题,本文提出了一个专为遥感视觉任务设计的轻量级骨干网络——LWGANet。该网络通过两个核心创新应对上述挑战:1)Top-K全局特
遥感(RS)图像分析的效率受到两大冗余问题的制约:一是广阔同质背景导致的空间冗余(spatial redundancy),二是目标尺度极端变化导致的通道冗余(channel redundancy)。现有的轻量化网络模型多为自然图像设计,难以同时应对遥感图像的这两个挑战,常常在保留局部细节和捕捉全局上下文之间顾此失彼。为解决此问题,本文提出了一个专为遥感视觉任务设计的轻量级骨干网络——LWGANet。该网络通过两个核心创新应对上述挑战:
1)Top-K全局特征交互(TGFI)模块,通过聚焦于显著区域进行计算,有效缓解了空间冗余;
2)轻量化分组注意力(LWGA)模块,它将通道划分为针对不同尺度的专门化路径,解决了通道冗余问题。通过这两种机制的协同作用,LWGANet在特征表征质量与计算成本之间实现了卓越的平衡,并在场景分类、目标检测等四类遥感任务的12个数据集上验证了其先进性。
01 论文基本信息

- 标题: LWGANet: Addressing Spatial and Channel Redundancy in Remote Sensing Visual Tasks with Light-Weight Grouped Attention
- 核心模块: 轻量化分组注意力 (Light-Weight Grouped Attention, LWGA), Top-K全局特征交互 (Top-K Global Feature Interaction, TGFI)
02 算法框架与核心模块
2.1 算法框架
LWGANet采用了一个包含四个阶段的层级化架构,逐级降低空间分辨率(4x, 8x, 16x, 32x)并加深通道。网络以一个步长为4的卷积层(Stem)开始,快速进行初始降维。每个阶段由一系列LWGA Block堆叠而成,阶段之间则使用DRFD模块进行下采样。LWGA Block是网络的核心,其内部先通过LWGA模块进行多尺度特征提取,再由一个通道多层感知机(CMLP)进行特征提炼,并通过残差连接完成整个处理流程。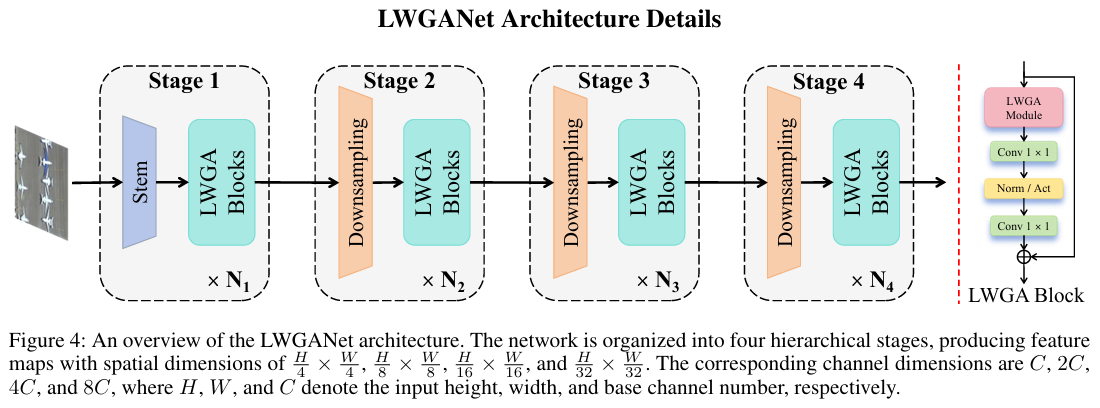
CMLP ( Y ) = Conv ( Act ( BN ( Conv ( Y ) ) ) ) \text{CMLP}(Y) = \text{Conv}(\text{Act}(\text{BN}(\text{Conv}(Y)))) CMLP(Y)=Conv(Act(BN(Conv(Y))))
out = X + BN ( drop ( CMLP ( Y ) ) ) \text{out} = X + \text{BN}(\text{drop}(\text{CMLP}(Y))) out=X+BN(drop(CMLP(Y)))
2.2 核心模块
模块一:轻量化分组注意力 (LWGA)
- 核心功能: 旨在解决遥感图像中的通道冗余问题。传统的同构分组(homogeneous grouping)策略对所有通道分区应用相同算子,效率低下。LWGA通过将特征通道解耦到专门处理不同尺度信息的路径中,从而最大化表征效率。
- 实现逻辑: LWGA采用异构分组(heterogeneous grouping)策略。它将输入特征图的通道划分为四个非重叠的专门化路径,每个路径都由一个针对特定尺度优化的子模块处理:
- 门控点注意力 (GPA): 捕捉点级别细节,用于小目标识别。
- 常规局部注意力 (RLA): 利用标准卷积的归纳偏置,高效提取局部纹理和模式。
- 稀疏中程注意力 (SMA): 为不规则形状的对象捕获中距离的上下文信息。
- 稀疏全局注意力 (SGA): 为理解整体场景建模长距离依赖关系。
最后,将这四条路径的输出特征拼接(Concat)起来,融合成一个全面的多尺度特征图。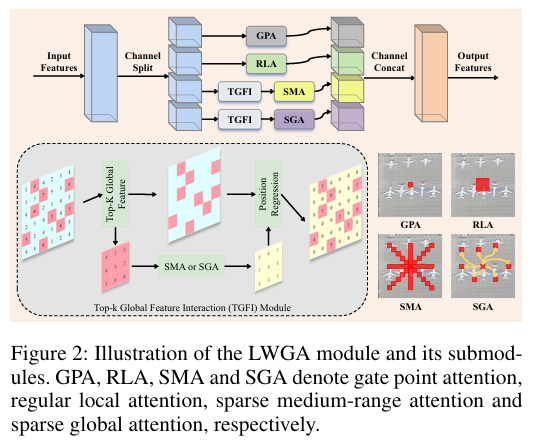
- 优势: 相比于“一刀切”的同构方法,LWGA为每个尺度分配了专门且计算高效的算子,避免了在单一特征空间中处理多尺度目标时的性能妥协,实现了对多尺度特征的同步高效表征,减少了通道浪费。
模块二:Top-K全局特征交互 (TGFI)
- 核心功能: 旨在缓解遥感图像中的空间冗余问题,为长距离依赖建模提供一种高效的计算机制。它避免了在广阔、无信息的背景区域上浪费大量计算资源。
- 实现逻辑: TGFI实现了一种稀疏交互策略,其工作流程如下:
- 稀疏特征采样: 将输入特征分割为多个不重叠的区域,并从每个区域中选择一个最显著的特征(如激活值最高的token),同时保留其空间坐标。
- 子空间交互: 仅在这个被缩减的稀疏特征集合上执行计算密集型操作(如自注意力或卷积),从而在高效的子空间中建立全局关系。
- 特征恢复: 利用已保存的坐标将增强后的稀疏特征恢复到其在原始特征图中的位置,而未被采样的位置则通过插值或恒等映射填充。
- 优势: TGFI作为一个智能采样和交互机制,显著降低了全局上下文建模的计算成本。同时,它通过聚焦于高信息量的区域,最大限度地减少了来自无关背景的噪声干扰,实现了更鲁棒和高效的全局信息整合。
03 模块适用任务
- 核心应用场景: 本方法主要面向**遥感(RS)**图像的轻量化视觉分析,尤其适用于资源受限的边缘设备。具体任务包括:场景分类、旋转目标检测、语义分割和变化检测。
- 方法论核心: 其最本质的思想是通过解耦和专门化来解决特征冗余。它将复杂的多尺度特征学习问题分解为四个并行的、针对特定尺度的子任务,并通过稀疏交互机制降低空间计算复杂度,从而实现了高效与高性能的统一。
- 启发性拓展:
- 架构自适应性: 当前设计中通道划分和超参数是固定的。未来可以引入神经架构搜索(NAS)等技术,动态学习最优的通道分配策略,以增强模型对不同数据分布的自适应能力。
- 极致的部署效率: 进一步通过算子融合、自定义CUDA核心等工程优化手段,解决异构算子带来的执行开销,最大化模型在边缘设备上的推理速度。
04 实验结果与可视化分析
核心实验与结论
本文选择旋转目标检测作为核心实验之一,因为它能严苛地检验模型在极端尺度变化下的多尺度表征能力。
- 实验目的: 验证LWGANet在处理遥感图像中普遍存在的小物体(如车辆)与大物体(如港口)共存场景时的有效性和鲁棒性。
- 关键结果: 如论文表2所示,在极具挑战性的DOTA-v1.0、DOTA-v1.5和DIOR-R数据集上,以LWGANet-L2为骨干的检测器取得了全面的SOTA(State-of-the-Art)性能。具体在DOTA-v1.0上,mAP达到79.02%,超越了包括专门为该任务设计的PKINet-S等更重型的模型。同时,表3的数据显示,LWGANet-L2在达到更高精度的同时,其计算量(FLOPs)和推理速度(FPS)也显著优于PKINet-S(38.8G vs. 70.2G FLOPs, 19.4 vs. 5.4 FPS),展现了卓越的效率。

- 作者结论: 实验结果有力地证明,通过LWGA模块解耦通道冗余的策略是应对遥感多尺度挑战的有效途径。同时,TGFI模块的空间冗余缓解机制也为模型在广阔场景中实现精准目标定位提供了支持。LWGANet不仅在理论上高效,更在实践中取得了精度与速度的最佳平衡,为遥感视觉任务设立了新的轻量化基准。
05 即插即用模块
class LWGA_Block(nn.Module):
def __init__(self,
dim,
stage,
att_kernel,
mlp_ratio,
drop_path,
act_layer,
norm_layer
):
super().__init__()
self.stage = stage
self.dim_split = dim // 4
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
mlp_hidden_dim = int(dim * mlp_ratio)
mlp_layer: List[nn.Module] = [
nn.Conv2d(dim, mlp_hidden_dim, 1, bias=False),
norm_layer(mlp_hidden_dim),
act_layer(),
nn.Conv2d(mlp_hidden_dim, dim, 1, bias=False)
]
self.mlp = nn.Sequential(*mlp_layer)
self.PA = PA(self.dim_split, norm_layer, act_layer) # PA is point attention
self.LA = LA(self.dim_split, norm_layer, act_layer) # LA is local attention
self.MRA = MRA(self.dim_split, att_kernel, norm_layer) # MRA is medium-range attention
if stage == 2:
self.GA3 = D_GA(self.dim_split, norm_layer) # GA3 is global attention (stage of 3)
elif stage == 3:
self.GA4 = GA(self.dim_split) # GA4 is global attention (stage of 4)
self.norm = norm_layer(self.dim_split)
else:
self.GA12 = GA12(self.dim_split, act_layer) # GA12 is global attention (stages of 1 and 2)
self.norm = norm_layer(self.dim_split)
self.norm1 = norm_layer(dim)
self.drop_path = DropPath(drop_path)
def forward(self, x: Tensor) -> Tensor:
# for training/inference
shortcut = x.clone()
x1, x2, x3, x4 = torch.split(x, [self.dim_split, self.dim_split, self.dim_split, self.dim_split], dim=1)
x1 = x1 + self.PA(x1)
x2 = self.LA(x2)
x3 = self.MRA(x3)
if self.stage == 2:
x4 = x4 + self.GA3(x4)
elif self.stage == 3:
x4 = self.norm(x4 + self.GA4(x4))
else:
x4 = self.norm(x4 + self.GA12(x4))
x_att = torch.cat((x1, x2, x3, x4), 1)
x = shortcut + self.norm1(self.drop_path(self.mlp(x_att)))
return x

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)