深度学习本质被看透!何恺明团队2025年以“简化+结构沟“为核心,五大方向突破,推动AI从工程优化到理论可解释
2025年,何恺明团队以“简化、结构、泛化、物理性、重构”为关键词,完成了一场对深度学习核心范式的系统性反思与重塑。在生成领域,团队通过去除噪声条件、引入分形结构、设计单步流场等创新,剥离冗余组件,揭示了生成建模的本质机制;在表征学习中,以“解构退化”的反向思维,证明了简洁架构的强大潜力;在物理推理方向,融合经典力学与神经算子,实现了可解释、多任务的物理建模;在理论层面,重审数据集偏差问题,为行业
导读
何恺明(Kaiming He),麻省理工学院电气工程与计算机科学系(EECS)终身副教授、Google DeepMind杰出科学家,是深度学习领域的“系统设计师”。他提出的ResNet彻底改变了深度网络训练范式,后续在目标检测(Mask/Faster R-CNN)、自监督学习(MoCo、MAE)等方向的持续创新,奠定了现代视觉智能的技术基石。

2025年,何恺明团队延续“以极简结构实现极致性能”的核心追求,围绕生成建模、自监督学习、物理推理与数据理论等方向展开系统性探索。团队以“解构经典框架、重构核心逻辑”为脉络,用结构化创新打破经验主义瓶颈,推动深度学习从“性能迭代”迈向“本质理解”,再次定义了人工智能的核心发展路径。
本文聚焦何恺明教授担任大通讯作者的核心论文,呈现其团队2025年的前沿研究脉络。
一、生成建模范式重构:简化结构,释放本质能力
何恺明团队2025年在生成领域的研究直指核心矛盾——如何剥离冗余组件、聚焦本质机制,实现更高效、更通用的生成能力。五篇核心论文从噪声建模、结构设计、生成效率等维度,重构了生成建模的基本范式。
Is Noise Conditioning Necessary for Denoising Generative Models [ICML2025]
核心问题:扩散模型是否必须依赖显式噪声条件(如σₜ)才能实现有效生成,这一行业共识是否存在冗余?
核心方法:首先通过理论推导建立误差边界,证明无噪声条件下模型的退化过程仍可保持稳定性。提出uEDM变体模型,去除传统扩散模型的噪声水平输入,仅通过网络隐式学习噪声分布特征。系统验证了DDIM、EDM等主流模型在无噪声条件下的表现,揭示了不同模型对噪声条件的依赖差异。
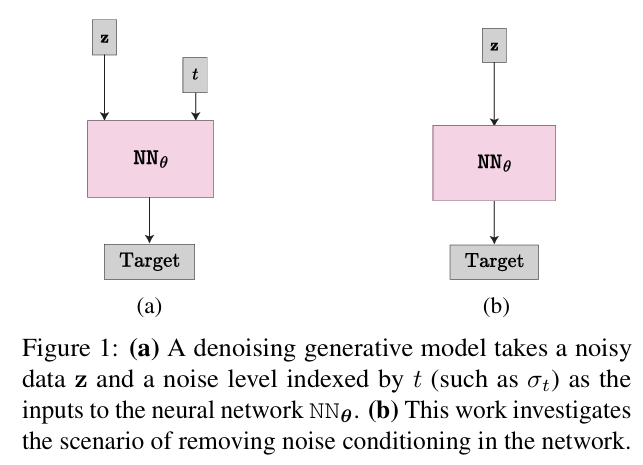
关键优势:在CIFAR-10数据集上实现FID 2.23,逼近最优噪声条件模型(EDM FID 1.97)。简化了扩散模型结构,为基于物理学的朗格文动力学等新方向开辟了空间。
论文地址:https://arxiv.org/pdf/2502.13129
Mean Flows for One-step Generative Modeling [NeurIPS2025]
核心问题:扩散模型与流匹配模型长期面临“效率与精度”矛盾,多步采样导致生成速度受限。
核心方法:创新性引入“平均速度”(mean velocity)概念,刻画数据从先验分布到真实分布的整体流动趋势,替代传统流匹配的瞬时速度场建模。构建完全自洽的单步生成框架,无需预训练或蒸馏,通过单次网络前向传播即可完成生成。

关键优势:在ImageNet 256×256任务上实现FID 3.43,显著优于现有单步生成方法。从理论上连接了扩散建模与流场建模,为统一生成框架提供了数学基础。
论文地址:https://arxiv.org/pdf/2505.13447
Fractal Generative Models
核心问题:高分辨率生成面临计算成本指数级增长,传统架构难以平衡效率与细节质量。
核心方法:受分形数学启发,提出“原子生成模块+递归调用”的架构设计。将自回归模型作为基础原子模块,通过分而治之策略递归构建跨层级自相似结构,将N=kⁿ个变量的联合分布拆解为n级子模块建模。在最后一级用轻量级Transformer逐像素预测RGB通道,通过动态调整模块复杂度适配不同尺度patch。
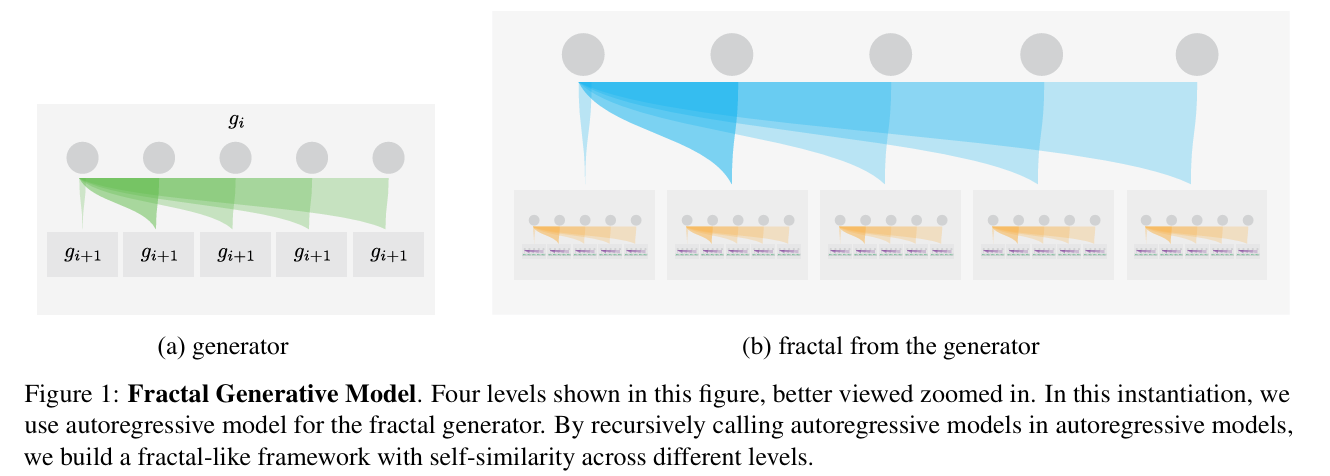
关键优势:计算效率提升4000倍,可逐像素生成256×256高分辨率图像,同时保持高精度似然估计与生成质量。
论文地址:https://arxiv.org/pdf/2502.17437
Highly Compressed Tokenizer Can Generate Without Training [ICML2025]
核心问题:生成模型依赖大量训练数据与计算资源,轻量级生成路径缺乏有效方案。
核心方法:设计一维高压缩tokenizer,将图像编码为仅32个token的离散序列,在保留语义与外观信息的同时实现极致压缩。提出“测试时梯度优化”方案,通过token替换、拷贝等启发式操作,结合可插拔损失函数(重建损失/CLIP相似度),无需训练生成模型即可完成任务。
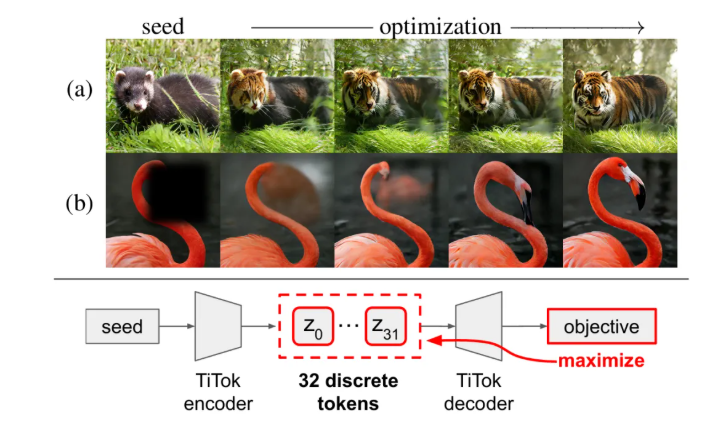
关键优势:打破“生成必须训练”的固有认知,在文本引导编辑、图像修复任务中实现高真实感与多样性,为轻量化生成提供全新思路。
论文地址:https://arxiv.org/pdf/2506.08257
Diffuse and Disperse: Image Generation with Representation Regularization
核心问题:扩散模型目标函数以回归为核心,缺乏对隐空间结构的显式约束,导致生成多样性不足。
核心方法:提出分散正则化损失(Dispersive Loss),通过促进模型中间层表征在隐空间的离散化分布,实现特征分离。该损失无需正样本对、额外预训练或外部数据,直接作用于同一批噪声输入,仅增加微小计算开销。
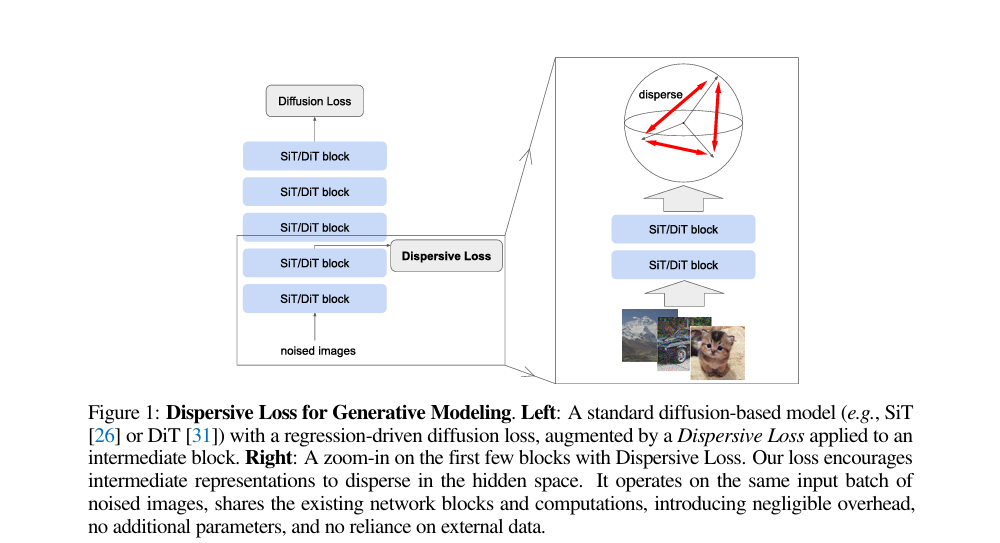
关键优势:适配SiT、DiT等主流扩散模型,在ImageNet数据集上显著提升生成质量与多样性,建立了生成建模与表征学习的简洁融合路径。
论文地址:https://arxiv.org/pdf/2506.09027
二、自监督与表征学习解构:回归本质,简化有效机制
团队以“反向拆解”的研究思路,重新审视现代扩散模型的表征学习能力,剥离冗余组件,回归经典自编码思想的核心价值。
Deconstructing Denoising Diffusion Models for Self-Supervised Learning [ICLR]
核心问题:现代扩散模型(DDM)结构复杂,哪些组件是自监督表征学习的关键?
核心方法:设计“逐步退化”实验,将扩散模型逐步简化为传统去噪自编码器(DAE)。通过移除调度策略、条件结构等组件,验证核心机制的必要性,最终得到潜空间去噪自编码器(l-DAE)。该框架将图像经patch-PCA投影至潜空间并添加噪声,再通过反向PCA投影回像素域完成重建。
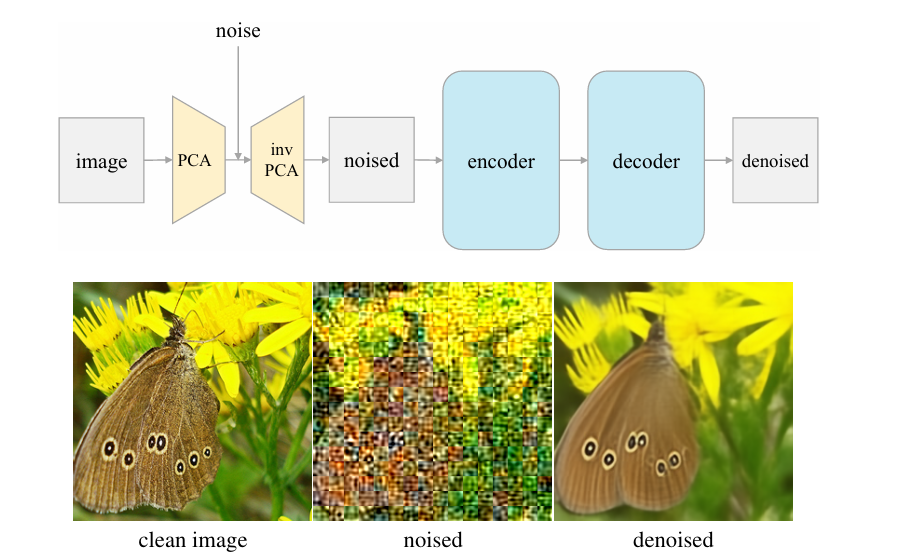
关键优势:结构极简却保持与现代扩散架构相当的表征质量,证明噪声建模与重建目标是表征学习的核心,为自监督学习提供了“去繁就简”的新范式。
论文地址:https://arxiv.org/pdf/2401.14404
三、物理推理与神经算子创新:融合约束,实现可解释建模
针对传统物理建模的局部依赖与任务局限,团队提出融合哈密顿力学与神经算子的新框架,赋予模型真实物理推理能力。
Denoising Hamiltonian Network for Physical Reasoning
核心问题:传统物理建模依赖局部时序更新,难以捕获长时依赖与系统级交互,且局限于前向模拟任务。
核心方法:将哈密顿力学算子泛化为可学习的神经算子,通过三项关键创新突破局限:一是将系统状态视为token,捕获非局部时间关系;二是引入去噪目标,通过迭代细化预测抵消数值积分误差;三是设计全局潜码,支持多物理系统联合建模。采用纯解码器Transformer架构,通过自解码框架优化轨迹专属潜码。
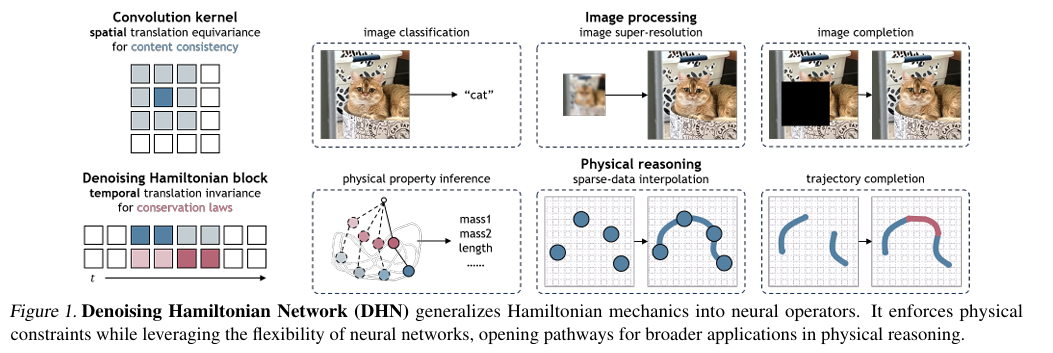
关键优势:统一支持轨迹预测、参数推断、轨迹超分辨率等多任务,在单摆、双摆系统中保持能量守恒,兼顾物理可解释性与神经网络灵活性。
论文地址:https://arxiv.org/pdf/2503.07596
四、数据集偏差的深度反思:重审现状,揭示结构性难题
团队重访十年经典实验,系统性检验大数据时代的数据集偏差问题,为行业敲响“仅靠数据规模无法根除偏差”的警钟。
A Decade’s Battle on Dataset Bias: Are We There Yet? [ICLR]
核心问题:大规模、高多样性数据集是否真正解决了数据集偏差问题?
核心方法:复刻“Name That Dataset”经典实验,使用现代神经网络在YFCC、CC、DataComp等主流开放数据集上进行分类测试。通过分析模型判别图像来源的准确率,评估数据集间的分布差异。

关键发现:模型判别数据集来源的准确率达84.7%,证明偏差依然显著存在。模型学习到的是具有可迁移性的语义表示偏差,而非简单记忆特征,揭示了偏差的深层结构性本质。
论文价值:呼吁社区重新思考数据公正性与泛化能力的关系,证明仅依赖数据规模扩张无法根除偏差,为数据集构建与模型泛化研究提供重要参考。
论文地址:https://arxiv.org/pdf/2403.08632
五、基础架构优化:挑战归一化层必要性,极简操作重塑Transformer
何恺明团队在基础架构层面持续探索“极简设计驱动极致性能”的可能性。最新研究《Transformers without Normalization》从神经网络中“公认必需”的归一化层入手,以一种简单到极致的元素级操作,实现了无归一化Transformer的性能突破,再次刷新了学界对深度网络组件必要性的认知。
Transformers without Normalization
核心问题:归一化层(如LayerNorm)在现代神经网络中无处不在,长期被视为Transformer的核心必需组件。但它们是否真的不可替代?
核心方法:提出Dynamic Tanh(DyT),一种元素级操作 DyT ( x ) = tanh ( α x ) \text{DyT}(x) = \tanh(\alpha x) DyT(x)=tanh(αx),作为归一化层的“即插即用”替代方案。该设计灵感源于关键观察:Transformer中的层归一化会天然产生类似tanh的S形输入-输出映射。通过引入DyT,无需归一化层的Transformer可在多任务场景中匹配甚至超越有归一化层的模型。
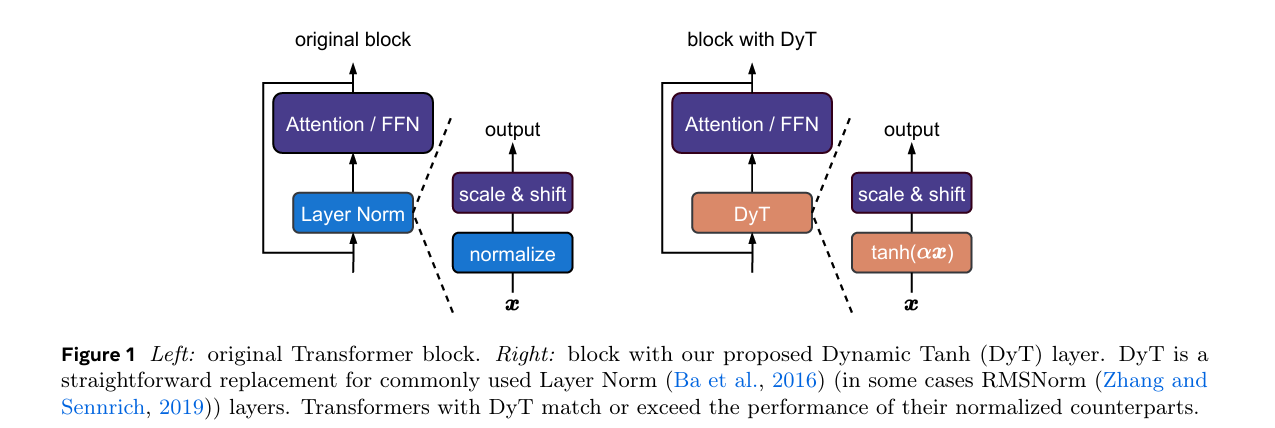
关键优势:在识别、生成、监督/自监督学习、计算机视觉与语言模型等多样化设置中验证有效性,且大多无需超参数调优即可实现性能持平或超越。彻底挑战了“归一化层在现代神经网络中不可或缺”的传统认知,为重新理解深度网络组件的作用提供了全新视角。
论文地址:https://arxiv.org/pdf/2503.10622
总结:以结构重构引领深度学习回归本质
2025年,何恺明团队以“简化、结构、泛化、物理性、重构”为关键词,完成了一场对深度学习核心范式的系统性反思与重塑。
在生成领域,团队通过去除噪声条件、引入分形结构、设计单步流场等创新,剥离冗余组件,揭示了生成建模的本质机制;在表征学习中,以“解构退化”的反向思维,证明了简洁架构的强大潜力;在物理推理方向,融合经典力学与神经算子,实现了可解释、多任务的物理建模;在理论层面,重审数据集偏差问题,为行业发展提供了理性视角。
这些研究不再局限于性能指标的突破,而是聚焦“深度学习为何有效”的本质追问,以结构化创新替代经验主义迭代,推动人工智能从“工程优化”迈向“理论可解释”的新阶段。何恺明团队用实践证明,“简单”并非落后,而是对核心规律的深刻把握——这正是深度学习下一阶段的核心发展方向。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)