生成式AI双雄:Diffusion Model 与 GAN 全面对比
Diffusion Model通过渐进式加噪/去噪过程生成图像,训练稳定、质量高但速度慢;GAN采用对抗训练,生成快但训练不稳定。当前Diffusion Model已成为AIGC主流,正解决速度瓶颈,未来可能与GAN技术融合。
一、 Diffusion Model and GAN
简介
Diffusion Model(扩散模型)和 GAN(生成对抗网络)是当今生成式人工智能领域两大最主流的模型。它们的目标相同——生成高质量的数据(如图像、音频),但实现路径和特性却截然不同。
下图清晰地对比了两者在工作原理上的核心差异: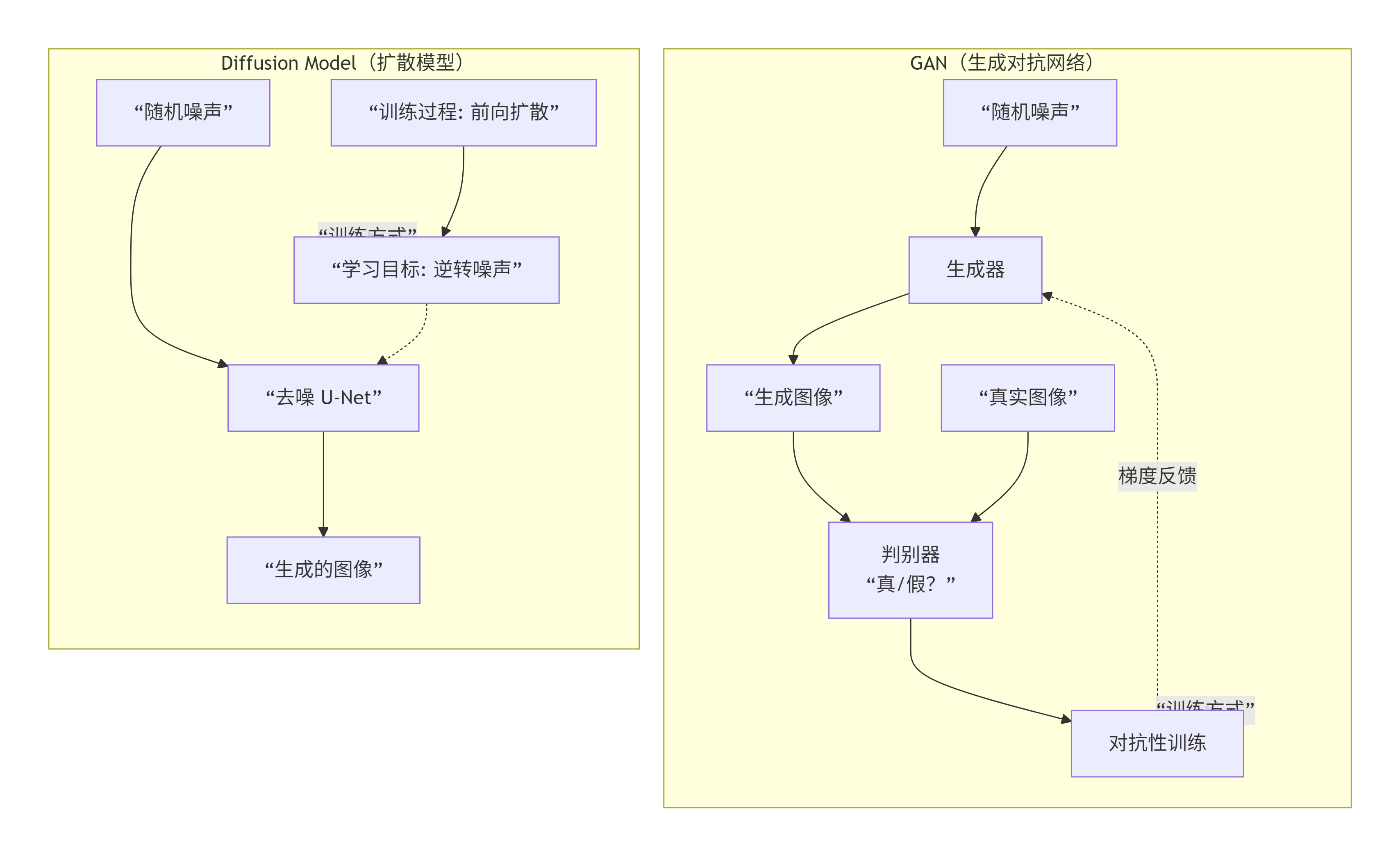
核心原理对比
GAN:
- 核心角色:
- 生成器:一个“伪造者”,接收随机噪声,目标是生成以假乱真的图像来欺骗判别器。
- 判别器:一个“鉴定专家”,接收真实图像和生成器生成的图像,目标是准确区分它们是“真实的”还是“伪造的”。
- 训练过程:如上图所示,这是一个对抗性的最小最大博弈。生成器和判别器在动态竞争中共同进化,直到生成器能产生足以骗过判别器的高质量图像。
Diffusion Model:一个“渐进去噪”的过程
- 核心过程:
- 前向扩散:在训练阶段,对一张真实图像逐步添加高斯噪声,经过数百步后,最终将其完全破坏成一个纯粹的随机噪声。这个过程是固定的,无需学习。
- 反向去噪:如上图所示,模型(通常是一个U-Net)需要学习如何将这个过程逆转。它从随机噪声开始,一步步地、循序渐进地预测并去除噪声,最终还原出一张清晰的图像。
优劣对比
| 特性 | GAN | Diffusion Model |
|---|---|---|
| 训练稳定性 | 差。著名的“模式崩溃”问题,即生成器只学会生成有限的几种样本,多样性不足。训练过程容易失衡。 | 高。训练目标明确且稳定,就是预测噪声。没有对抗博弈,不易崩溃。 |
| 生成质量 | 非常高。在相当长的时间里,GAN生成的图像在清晰度和逼真度上都是标杆。 | 极高。目前SOTA,尤其在细节、纹理和创造性方面表现惊人,作品往往更具“艺术感”。 |
| 生成速度 | 快。前向传播一次,即可生成一张图像。 | 慢。需要多次(通常50-1000步)迭代去噪,采样速度慢。 |
| 多样性 | 一般(尤其是有模式崩溃时)。 | 非常好。能产生非常多样化和富有创造性的结果。 |
| 控制性 | 通过条件GAN、StyleGAN等可以实现较好控制。 | 极强。非常适合基于文本提示词、草图等条件的生成,是当前文生图主流。 |
代表模型与应用场景
GAN
- StyleGAN:由NVIDIA推出,在人脸生成等领域达到惊人效果,能精细控制图像风格。
- CycleGAN:用于无配对数据的图像到图像的转换(如将马变成斑马)。
- 应用:人脸生成、图像风格迁移、图像超分辨率、数据增强。
Diffusion Model
- Stable Diffusion:当前最流行的开源文生图模型,通过在潜在空间进行扩散,大幅降低了计算成本。
- DALL-E 2/3:OpenAI的文生图模型,核心也是扩散模型。
- Midjourney:其背后技术也基于扩散模型。
- 应用:文生图、图生图、图像编辑、3D生成、分子结构生成。
总结与关系
| 模型 | 优势 | 劣势 |
|---|---|---|
| GAN | 生成速度快,图像锐利 | 训练不稳定,多样性可能不足 |
| Diffusion Model | 训练稳定,生成质量高,多样性好,控制性强 | 生成速度慢,计算开销大 |
发展趋势:
Diffusion Model 凭借其卓越的生成质量和训练稳定性,在2022年后成为了生成式AI的主流,尤其是在需要与自然语言紧密结合的创意生成领域。然而,其生成速度慢是亟待解决的瓶颈。因此,当前的研究热点之一就是 “蒸馏” 和更快的采样器,旨在用更少的步数生成高质量的图像,甚至出现了将 Diffusion 思想与 GAN 结合的研究,取长补短。
简单来说,GAN是闪电般迅速但难以驾驭的赛马,而Diffusion Model则是稳定可靠、精雕细琢的工匠。 目前,后者正推动着AIGC浪潮的蓬勃发展。
二、Diffusion Model 中的Classifier-Free Guidance(CFG)的核心机制。
Classifier-Free Guidance(分类器自由引导)是作用于【从噪声还原到图片】的“去噪过程”中的一种引导技术。
它不是一个前向的“图片加噪”过程。
详细解释
为了理解CFG,我们首先需要理解标准的扩散模型在做什么。
1. 标准扩散模型的去噪过程:
在反向扩散(从噪声生成图像)的每一步,模型(U-Net)会接收以下输入:
x_t:当前时间步t的带噪图像t:当前时间步(时间嵌入)c:条件信息(如文本提示词 “a photo of an astronaut”)
模型的任务是预测噪声 ε,或者直接预测去噪后的图像 x_{t-1}。这个过程是条件性的,因为它依赖于你的文本提示 c。
2. Classifier-Free Guidance 的巧妙之处:
CFG的核心思想是:为了更好地遵循条件,我们先要理解“无条件”是什么样子。
它在训练时要求模型同时学习两个任务:
- 条件预测:
ε_c = model(x_t, t, c)→ 给定提示词,图像应该是什么样的。 - 无条件预测:
ε_∅ = model(x_t, t, ∅)→ 随机的“空”提示(如[PAD]token),代表“无条件的”或“平均的”图像应该是什么样的。
3. 在采样(生成)时如何工作:
在从噪声生成图像的每一步,CFG并不直接使用条件预测 ε_c。而是计算一个**“引导后的预测噪声”**:
ε_guided = ε_∅ + guidance_scale * (ε_c - ε_∅)
让我们来拆解这个公式:
(ε_c - ε_∅):这部分是 “条件信息带来的方向” 。它代表了“因为你的提示词,图像应该朝哪个方向改变”。guidance_scale:引导尺度,是一个超参数(通常为7.5)。- 当
guidance_scale = 1时,ε_guided = ε_c,就是标准的条件生成。 - 当
guidance_scale > 1时,模型会被强烈地推向提示词c所描述的方向,远离那种“平均的、模糊的”图像。
- 当
ε_∅ + ...:最终,我们在无条件预测的基础上,加上一个放大的“条件方向”,得到引导后的噪声预测。
一个生动的比喻
想象一位画家(扩散模型)在根据你的描述(提示词 c)作画。
- 没有CFG:画家直接画他理解的“宇航员”。
- 有CFG:
- 画家首先在脑子里想象一个随机的、平均的、没有任何特点的人(这就是无条件预测
ε_∅)。 - 然后,他再想象一个具体的宇航员(条件预测
ε_c)。 - 最后,他画的是:那个普通人 + 一个被放大的“宇航员特质”(比如更明显的宇航服、头盔、太空背景)。
- 画家首先在脑子里想象一个随机的、平均的、没有任何特点的人(这就是无条件预测
这个“放大特质”的过程,使得最终生成的“宇航员”更像一个宇航员,细节更清晰,与提示词的关联性更强。
总结
| 过程 | 作用阶段 | 目标 |
|---|---|---|
| 前向扩散(加噪) | 训练阶段 | 将真实图像破坏成噪声,为训练提供数据。 |
| 反向去噪(图像生成) | 推理/生成阶段 | 从噪声一步步重建图像。 |
| Classifier-Free Guidance | 反向去噪过程的每一步 | 引导去噪的方向,使生成的结果与条件(如文本提示)更匹配,质量更高。 |
所以,CFG是一个在生成过程中使用的、通过结合条件与无条件预测来增强生成效果的先进技术。它是当今Stable Diffusion、DALL-E 2/3等顶级文生图模型高质量输出的关键所在。
三、 Diffusion Model 中的加噪过程
好的,我们来详细讲解扩散模型中的加噪过程。这个过程在学术上被称为 “前向扩散过程”。
首先,请理解一个核心概念:加噪过程是一个固定的、预先定义好的数学过程,它不包含任何需要学习的模型参数。 它发生在训练阶段,其唯一目的是为模型制造训练数据。
核心思想:渐进式破坏
加噪过程的目标是,通过一系列步骤 t = 1, 2, ..., T(T通常是1000步),将一张清晰的原始图像 x₀ 逐步破坏,最终变成一个完全随机的、符合高斯分布的噪声 x_T。
这个过程是确定的,意味着对于同一张 x₀,在每一步 t 加噪后的结果 x_t 都是可以精确计算出来的。
数学实现:重参数化技巧
加噪过程最经典的实现方式是使用一个线性插值公式,它巧妙地融合了原始图像和随机噪声。这个过程可以通过下图来直观理解:
flowchart TD
A[“原始图像 x₀”] --> B[“采样一步噪声 ε<br>从标准高斯分布”]
C[“从0到T的<br>噪声调度表”] --> D[“根据步骤t<br>计算α_bar_t”]
B & D --> E[“应用加噪公式<br>x_t = √ᾱ_t * x₀ + √(1-ᾱ_t) * ε”]
E --> F[“第t步的<br>带噪图像 x_t”]
这个流程中的关键因素是 噪声调度表,它决定了在每一步 t 时,图像和噪声的混合比例。具体公式为:
x_t = √ᾱ_t * x₀ + √(1 - ᾱ_t) * ε
让我们来拆解这个公式的每个部分:
x₀:原始清晰的图像。ε:从标准高斯分布(均值为0,方差为1)中随机采样的一份噪声。ε ~ N(0, I)。ᾱ_t:这是噪声调度表在步骤t的值,它是一个介于0和1之间的数。它代表了原始图像信号的权重。- 当
t=0时,ᾱ_0 ≈ 1,这意味着x₀的权重为1,噪声权重为0。 - 当
t=T时,ᾱ_T ≈ 0,这意味着x₀的权重为0,噪声权重为1。
- 当
√ᾱ_t和√(1 - ᾱ_t):分别是原始图像和噪声的系数。它们的平方和为1,这是为了保持x_t的方差稳定。
这个公式的妙处在于: 它允许我们一步到位地计算出任何步骤 t 的加噪结果 x_t,而无需真正地从第1步、第2步……一步步地模拟过来。这极大地提高了训练数据准备的效率。
一个具体的数值例子
假设:
- 原始图像
x₀的某个像素值为1.0。 - 随机噪声
ε的对应值为0.5。 - 在步骤
t=500时,调度表给出ᾱ_500 = 0.4。
那么,在 t=500 步的加噪结果计算如下:x_500 = √0.4 * 1.0 + √(1-0.4) * 0.5x_500 = 0.632 * 1.0 + 0.775 * 0.5x_500 = 0.632 + 0.387 = 1.019
可以看到,原始的像素值 1.0 被噪声 0.5 “污染”了,变成了 1.019。
加噪过程的最终目的
你可能会问,这个看似破坏性的过程有什么用?它的目的是为去噪模型制造训练样本。
在训练时,我们会:
- 随机选择一个时间步
t(例如,在1到1000之间随机选一个数)。 - 对一张训练图像
x₀应用加噪公式,得到x_t。 - 将
(x_t, t, ε)作为一个训练样本喂给模型(U-Net)。 - 模型的任务:根据带噪图像
x_t和时间步t,去预测我们当初加入的噪声ε。
通过在海量数据上重复这个过程,模型就学会了如何从任何程度的噪声中,一步步地还原出清晰的图像。而这个“还原”的过程,就是神奇的图像生成过程。
总结
| 特性 | 描述 |
|---|---|
| 阶段 | 训练阶段 |
| 目的 | 为去噪模型制造训练数据 (x_t, t, ε) |
| 可学习性 | 否,这是一个固定的数学公式 |
| 关键公式 | x_t = √ᾱ_t * x₀ + √(1 - ᾱ_t) * ε |
| 关键超参数 | 噪声调度表(决定了 ᾱ_t 如何从1衰减到0) |
简单来说,加噪过程就是一位“老师”,它负责制造出各种难度的“考题”(带噪图像 x_t),而模型则是“学生”,通过学习来练习如何解这些题(预测噪声 ε)。 当这个学生学成之后,我们就可以给它一份纯粹的噪声(x_T),让它自己一步步地“解”出一张全新的图像。
四、Diffusion Model 中的反向去噪过程核心 U-Net
在扩散模型中,反向去噪过程的核心是一个名为 U-Net 的神经网络。
这个U-Net并不是凭空产生的,它是一个在计算机视觉领域,尤其是在图像分割任务中久经考验的经典架构。扩散模型(如Stable Diffusion、DALL-E)对其进行了精心的改造和利用。
核心网络:U-Net
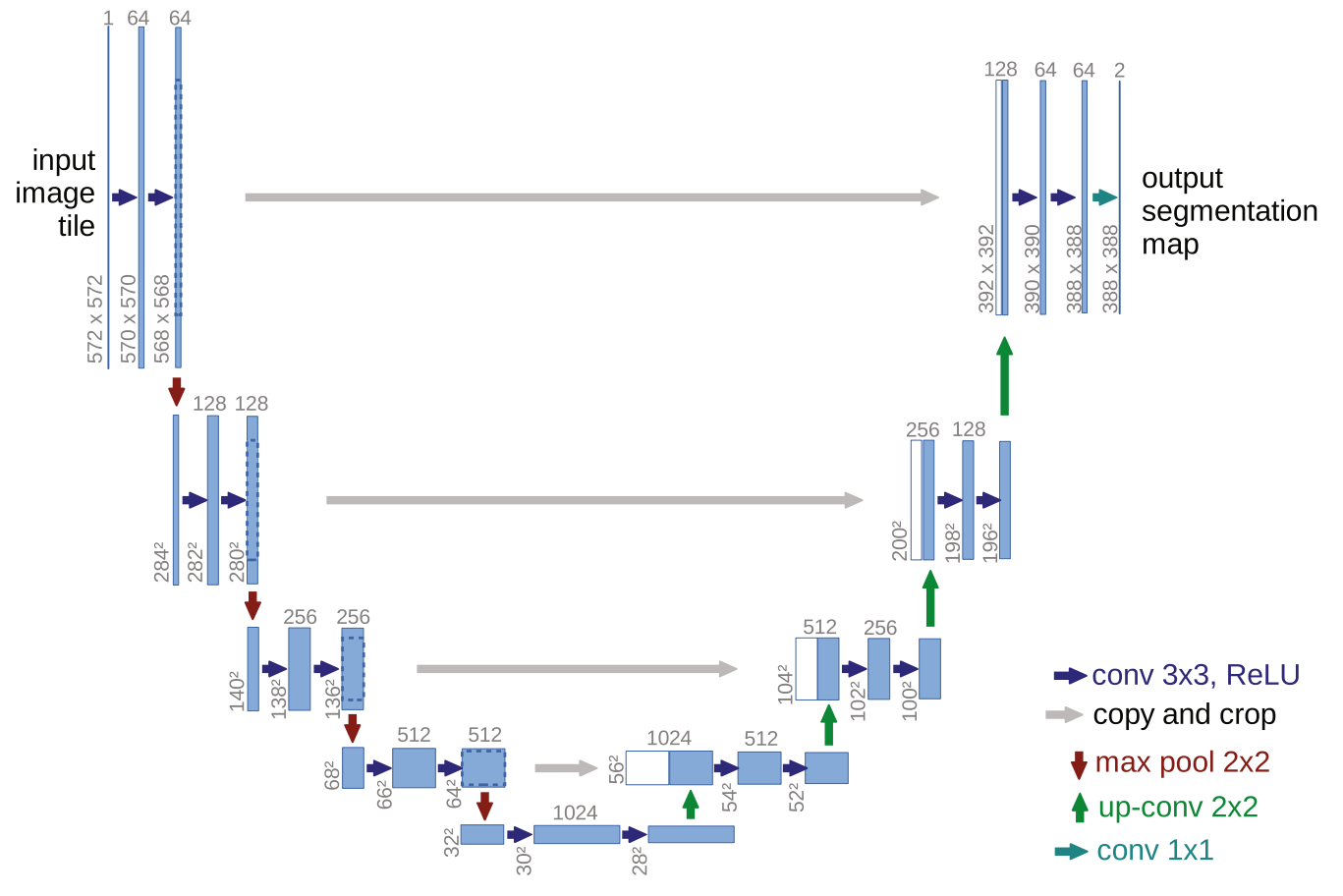
我们可以通过上图来理解这个U-Net在反向去噪过程中的工作原理:
U-Net 在扩散模型中的关键设计
为了完成去噪任务,这个U-Net具备以下几个关键设计:
1. 输入与输出
- 输入:
- 带噪图像
x_t:当前时间步的噪声图片。 - 时间步
t:告诉模型当前处于去噪过程的哪一步。这是通过正弦位置编码或可学习的位置嵌入来实现的,然后被投影并融入到网络的各个部分(例如,通过加法或注意力机制)。 - 条件信息
c(可选):对于文生图等任务,这是文本提示词。它通过交叉注意力机制被注入到U-Net中。
- 带噪图像
- 输出:
- 预测出的、应该从
x_t中减去的噪声ε_θ。 - 或者,直接预测去噪后的图像
x_{t-1}。这两种目标是等价的。
- 预测出的、应该从
2. 架构特点为何适合去噪
- 编码器-解码器结构 with 跳跃连接:
- 编码器(下采样):通过卷积和池化层,逐步压缩图像尺寸,增加通道数,以捕捉图像的全局上下文和语义信息(例如,图片中有一个“物体”)。
- 解码器(上采样):通过转置卷积或插值,逐步恢复图像尺寸和细节,以生成清晰的像素。
- 跳跃连接:这是U-Net的灵魂。它将编码器对应层的特征图直接拼接到解码器。这确保了在恢复细节时,网络不会丢失在编码器中学到的低级特征(如边缘、纹理),从而能生成高质量、高分辨率的输出。
3. 核心组件:注意力机制
现代扩散模型的U-Net通常集成了自注意力层和交叉注意力层,通常以 Transformer Block 的形式存在。
- 自注意力层:让图像的不同区域之间进行信息交互。这使得模型能够理解图像的全局结构,例如,为了正确生成一只猫,它需要知道猫头应该在猫身的上方。
- 交叉注意力层:这是条件生成的关键。它将文本条件(如 “a cute cat” 的文本嵌入)注入到U-Net中。在解码器的某些层,U-Net的特征会作为 Query,而文本嵌入作为 Key 和 Value。这使得模型在生成图像时,能够“关注”相关的文本描述,从而确保生成的图片与提示词一致。
总结
| 特性 | 描述 |
|---|---|
| 网络类型 | U-Net,一种编码器-解码器架构,带有跳跃连接。 |
| 主要输入 | 带噪图像 x_t,时间步 t。 |
| 条件输入 | 文本提示词(通过交叉注意力机制注入)。 |
| 主要输出 | 预测的噪声 ε_θ。 |
| 核心能力 | 多尺度特征融合(得益于跳跃连接)和全局上下文理解(得益于注意力机制)。 |
可以这样理解:这个U-Net是一个**“智能去噪滤波器”**。它不仅仅是一个简单的滤波器,而是一个能够理解时间步(知道该去除多少噪声)、理解图像内容(知道在生成什么物体)、并能听从文本指令(条件生成)的、极其强大的神经网络。正是它的存在,才使得从随机噪声中一步步“幻化”出逼真图像成为可能。
五、基于PyTorch U-Net实现代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class DoubleConv(nn.Module):
"""(卷积 => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
"""下采样模块:最大池化 + DoubleConv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
"""上采样模块"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# 计算填充差异
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
"""输出卷积层"""
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
class UNet(nn.Module):
"""完整的U-Net架构"""
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
# 编码器 (下采样路径)
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
# 解码器 (上采样路径)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
# 编码器
x1 = self.inc(x) # 64 channels
x2 = self.down1(x1) # 128 channels
x3 = self.down2(x2) # 256 channels
x4 = self.down3(x3) # 512 channels
x5 = self.down4(x4) # 1024 channels
# 解码器 (包含跳跃连接)
x = self.up1(x5, x4) # 512 channels
x = self.up2(x, x3) # 256 channels
x = self.up3(x, x2) # 128 channels
x = self.up4(x, x1) # 64 channels
# 输出层
logits = self.outc(x)
return logits
# 扩散模型专用的U-Net(包含时间步和条件输入)
class DiffusionUNet(nn.Module):
"""用于扩散模型的U-Net,支持时间步和条件输入"""
def __init__(self, n_channels, n_classes, time_emb_dim=256, cond_emb_dim=512, bilinear=True):
super(DiffusionUNet, self).__init__()
# 时间步嵌入
self.time_mlp = nn.Sequential(
nn.Linear(time_emb_dim, time_emb_dim),
nn.SiLU(),
nn.Linear(time_emb_dim, time_emb_dim)
)
# 条件嵌入(用于文本提示等)
self.cond_mlp = nn.Sequential(
nn.Linear(cond_emb_dim, cond_emb_dim),
nn.SiLU(),
nn.Linear(cond_emb_dim, cond_emb_dim)
)
# 基础的U-Net
self.unet = UNet(n_channels, n_classes, bilinear)
def forward(self, x, time_emb, cond_emb=None):
# 处理时间步嵌入
t = self.time_mlp(time_emb)
# 处理条件嵌入(如果有)
if cond_emb is not None:
c = self.cond_mlp(cond_emb)
# 将条件信息融入到时间步嵌入中
t = t + c
# 将时间步信息添加到每个特征图中
# 这里需要将时间步嵌入扩展到与特征图相同的空间维度
batch_size, channels, height, width = x.shape
t_expanded = t.unsqueeze(-1).unsqueeze(-1).repeat(1, 1, height, width)
# 将时间步信息与输入连接
x_with_time = torch.cat([x, t_expanded], dim=1)
# 通过U-Net
return self.unet(x_with_time)
# 测试代码
if __name__ == "__main__":
# 基本U-Net测试
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 创建基本U-Net
unet = UNet(n_channels=3, n_classes=1).to(device)
# 创建扩散模型专用的U-Net
diffusion_unet = DiffusionUNet(
n_channels=3 + 256, # 额外通道用于时间步嵌入
n_classes=3, # 输出RGB图像
time_emb_dim=256,
cond_emb_dim=512
).to(device)
# 测试输入
batch_size = 2
x = torch.randn(batch_size, 3, 256, 256).to(device)
time_emb = torch.randn(batch_size, 256).to(device)
cond_emb = torch.randn(batch_size, 512).to(device)
# 测试基本U-Net
with torch.no_grad():
output_basic = unet(x)
print(f"Basic U-Net input shape: {x.shape}")
print(f"Basic U-Net output shape: {output_basic.shape}")
# 测试扩散U-Net
output_diffusion = diffusion_unet(x, time_emb, cond_emb)
print(f"Diffusion U-Net input shape: {x.shape}")
print(f"Diffusion U-Net output shape: {output_diffusion.shape}")
# 计算参数量
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Basic U-Net parameters: {count_parameters(unet):,}")
print(f"Diffusion U-Net parameters: {count_parameters(diffusion_unet):,}")
这个U-Net实现包含以下关键特性:
主要组件:
- DoubleConv:双重卷积模块,包含卷积、批归一化和ReLU激活
- Down:下采样模块,使用最大池化减少空间维度
- Up:上采样模块,支持双线性插值或转置卷积
- OutConv:输出卷积层,将特征映射到目标类别数
架构特点:
- 编码器-解码器结构:经典的U-Net对称架构
- 跳跃连接:将编码器的特征与解码器对应层连接,保留空间信息
- 渐进式下采样/上采样:逐步提取和恢复特征
扩散模型专用版本:
- 时间步嵌入:将扩散过程的时间步信息融入网络
- 条件嵌入:支持文本提示等条件输入
- 灵活的输入输出:适应扩散模型的训练需求
使用示例:
# 基本用法
model = UNet(n_channels=3, n_classes=1)
output = model(input_tensor)
# 扩散模型用法
diffusion_model = DiffusionUNet(n_channels=3+256, n_classes=3)
output = diffusion_model(noisy_image, time_embedding, condition_embedding)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)