收藏必备:大模型量化与低精度训练全攻略 - 从原理到典型案例解析
本文系统介绍了模型量化的原理与方法,详细阐述了混合精度训练、后训练量化和量化感知训练三种方案,并通过DeepSeek、Kimi和InfiR2等案例展示最新进展。文章分析了量化挑战及应对策略,为读者提供从理论到实践的完整指南,帮助理解大模型低精度训练的全貌。
本文的逻辑如下:
- 问题(为什么要模型量化和低精度训练)
- 量化的基础知识
- 主要解决方案(如何进行低精度训练)
- 典型案例(DeepSeek、K2-Thinking、InfiR2)
一、问题
深度学习模型训练主要包括前向计算、后向传播进行梯度计算、权重更新,均为各种数学计算。早期的模型训练,使用单精度FP32进行计算,FP32精度表示每个用于计算的数据使用32位表示,精度高,会导致三个方面的问题:
- 计算:计算量大,计算速度慢。
- 存储:占用存储空间大。
- 带宽:数据量大,数据通信带宽需求大。
要解决这些问题,核心就是在模型训练和推理阶段,在保证模型效果前提下,降低计算数据的精度。首先我们要了解下数据量化的基础知识。
二、量化基础知识
量化是把高精度数据映射到低精度的过程。如下图1,上面r表示原始高精度值,例如FP32,下面表示量化映射到INT8精度,范围是[-128,127]。
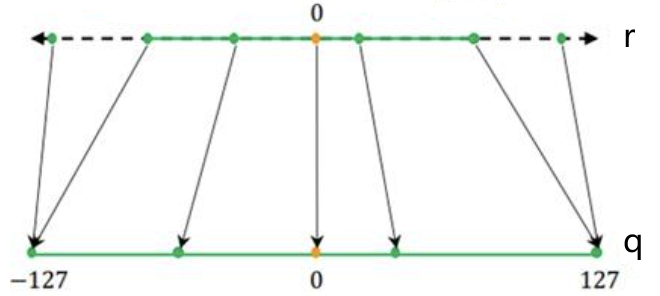
图1. 量化过程,来源[2]
理论上,量化可分为线性量化和非线性量化,我们介绍主流的线性量化。公式如下:
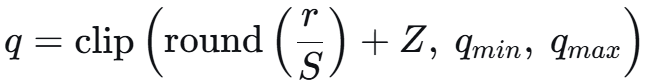
其中,
解释:
r:浮点输入,例如FP32精度。
q:量化后输出,例如INT8、INT4精度。
S(Scale):缩放因子,量化的间隔,表示一个整数单位对应的浮点数值范围。
Z(Zero Point):零点,一个整数,精确地对应浮点数中的0.0值,这是处理偏移的核心。如果Z=0,表示对称量化,上图浮点0.0量化后对应在整型的0点,就是对称量化;如果Z不取0,就是非对称量化。
 :量化后的整数最小值和最大值,例如有符号INT8范围[-128,127]。
:量化后的整数最小值和最大值,例如有符号INT8范围[-128,127]。
round:取整函数,例如round(3.2)=3。
clip:钳位函数/裁剪函数,clip(x, a, b)将x限制在[a, b]之间,是为了避免量化后的整数超出其表示范围,例如clip(200, -128, 127)=127。
量化后,经常还要反量化回浮点值,公式:
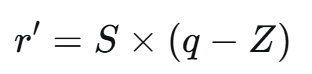
反量化后的值与原值r可能有误差,这就是量化后模型准确率可能降低的原因。
举个实际例子,我们把向量[1.2, −0.5, 2.8, −1.7, 0.0, 3.1, −2.3, 1.9]量化到INT8精度,范围[-128,127],使用对称量化,Z取0:
第一步:计算缩放因子S,最大值3.1,最小值-2.3, S=(3.1-(-2.3))/(127-(-128))=5.4/255=0.021176;
第二步:r/S后,保留两位小数,向量变为[56.67, -23.61, 132.23, -80.28, 0.0, 146.39, -108.61, 89.72]
第三步:取整,向量变为
[57, -24, 132, -80, 0.0, 146, -109, 90]
第四步:裁剪到[-128, 127],大于127的取127,最终量化结果为:
[57, -24, 127, -80, 0.0, 127, -109, 90]
反量化,S*q,保留一位小数,结果为:
[1.2, -0.5, 2.7, -1.7, 0.0, 2.7, -2.3, 1.9]
可见,2.8和3.1因为量化时被裁剪了,反量化后均变为了2.7,产生了误差。
量化的一大挑战是特征异常值(Outliers),这些极端值在特征分布中远离大部分数据,如果使用全局的量化参数(例如最大值),这些异常值可能会导致大部分数据的量化精度下降。其中一个方法是细粒度量化,使用更精细的量化粒度,更好地适应数据的局部特征,减少异常值的影响。
三、低精度训练方案
在训练阶段,主要有混合精度训练、量化感知训练,训练完后,对浮点模型可以进行后训练量化,目的都是要么降低训练过程中的数据精度以减少计算量,要么降低模型参数精度以减少推理阶段计算量,下面分别详细说明。
1、混合精度训练(Mixed-Precision Training)
混合精度训练至少十年前就有了,在RNN、LSTM模型流行的时候,大家都已经开始使用。资料[3]是2018年百度和英伟达发表的论文,使用FP32和FP16进行混合精度训练。
使用BF16精度进行混合精度训练,在过去一段长时间内是主流,我们先以一个经典的Linear层训练过程描述图,仔细理解整个过程。理解了这个,对其他各种混合精度训练图就都能看懂了,例如后面我们会看到的DeepSeek、InfiR2模型。
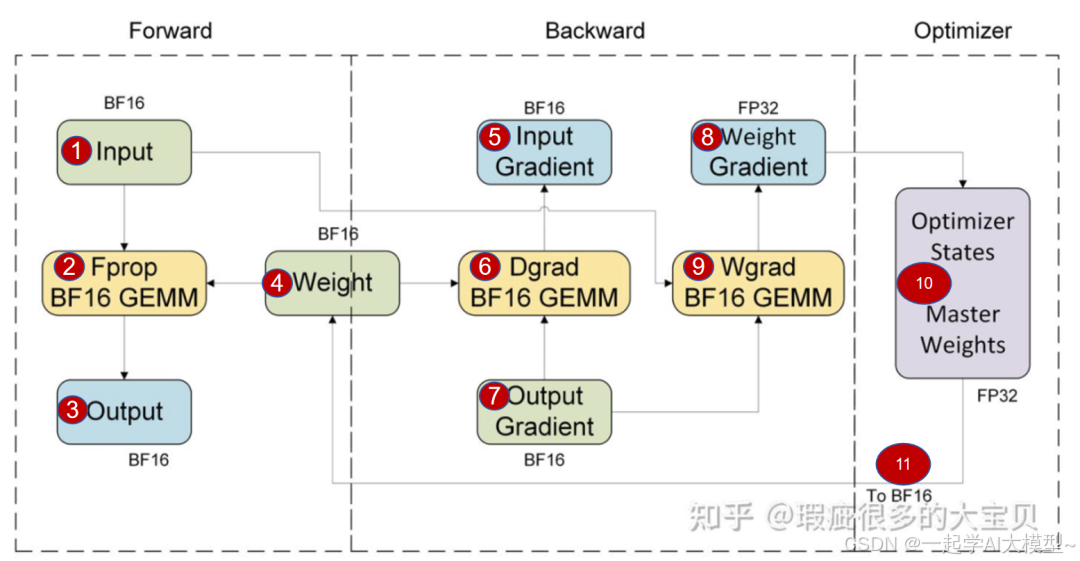
图2. BF16混合精度训练过程,来源[4]
我们先定义输入为X(Input),权重W(Weight),输出Y(Output),损失函数L。
复习下深度学习模型训练的过程:
1)前向计算Fprop:Y=X*W
2)后向传播计算梯度
Dgrad:先计算输入梯度(Input Gradient),用当前层的输出梯度(Output Gradient)计算其输入梯度,作为前一层的输出梯度,不断往前传播:
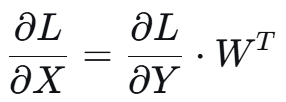
Wgrad:权重梯度(Weight Gradient)计算,根据输入和输出梯度相乘:
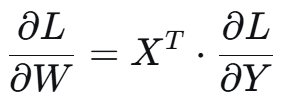
对上述推导公式感兴趣的请自行查找。
3)模型权重更新,使用优化器,对于优化器的前世今生
再回到图2就好理解了,GEMM表示通用矩阵乘法,第一个虚线框表示前向计算,包括标号1、2、3、4部分,全使用BF16精度计算。
第二个虚线框部分,反向传播,先4、7、6、5计算输入梯度,均使用BF16精度计算,从后往前一层层传播,有了输入梯度,就是前一层的输出梯度7,结合1,进行9的权重梯度计算Wgrad,使用BF16 GEMM,得到权重梯度8。注意,权重梯度是以FP32的高精度保存的。
第三个虚线框,用优化器进行权重梯度更新,维护一份 FP32 精度的主权重,精度更高,避免累积误差。然后权重转化为BF16精度,进行下一轮前后向计算。
整个过程只有权重梯度的结果和主权重使用了FP32精度进行保存。
注意:过程中权重梯度计算结果由BF16升高到FB32,只是精度扩展,主权重由FB32到BF16,只是简单的精度截断,这两个过程都不是量化。
2、后训练量化(Post-Training Quantization, PTQ)
PTQ是指在模型已经完成全精度训练后,再对其进行量化转换的过程 。量化包括对权重参数和激活值的量化,激活值是指每一层的输出值。这种方法无需重新训练模型,成本低,开发周期短,因此被广泛应用于模型的快速部署。
量化分为静态量化和动态量化两种。
静态量化需要一个小的、有代表性的校准数据集来统计模型中权重和激活值的分布范围,从而确定最优的量化缩放因子和零点,优点是推理速度快,计算效率高。一般权重参数使用静态量化。
动态量化在推理时动态计算量化参数,适合激活值的量化,当数据流经每个隐藏层时,收集并分析激活值,动态确定缩放因子和零点。优点是量化更准确,也不需要额外的校准数据集,缺点是增加计算量,推理变慢。
3、量化感知训练 (Quantization-Aware Training, QAT)
为了弥补PTQ在低比特下的精度损失,QAT在模型训练或微调的过程中引入伪量化(Fake Quantization)节点,模拟量化过程,让模型“提前感知”到量化会带来的精度损失,并通过训练来适应和修正这种损失,从而使得模型在真正被量化部署时,性能下降最小。
在前向传播时,模型参数和激活值被量化后再进行计算;在反向传播时,由于量化函数(如round)的导数处处为零或不存在,没法直接计算梯度,使用直通估计器(Straight-Through Estimator, STE)来近似梯度,即将伪量化节点的梯度直接拷贝给其输入。通过这种方式,模型可以在训练中逐渐适应量化带来的误差,从而学习到对量化更鲁棒的参数。
第一步:以在一个目标任务上已经训练好的高精度预训练模型作为起点,因为这远比从头开始训练一个模型要高效和稳定。
第二步:插入伪量化节点。通常在模型的输入、线性层权重前、激活函数如Relu之后。伪量化节点包含量化和反量化操作,来达到模拟量化过程。
第三步:训练或微调。
前向计算:经过每个伪量化节点时,权重和激活值都被量化再反量化成高精度值,正常参与计算。损失函数是基于这些模拟量化后的值计算的。
反向传播:由于伪量化节点中的量化使用了round()函数,其导数几乎处处为零,梯度无法传播,使用STE来解决:
直接视round()为一个恒等函数,直接将上游的输出梯度原封不动地传递下去,所以叫直通估计器。伪量化节点只是在训练过程中增加了一个“噪声”,让权重学会抵抗这种噪声,包括适应STE。
第四步:确定量化参数缩放因子S和零点Z,包括训练中学习和训练中统计两种方法。
训练中学习将S和Z作为可训练的参数,让模型在训练过程中自己学习出最适合的值,这种方法可能找到更优的值,但训练可能不稳定。
训练中统计更常见,通过观察张量的数据分布来动态计算S和Z。权重可直接使用其最大最小值计算,激活值可用一批数据来统计其移动平均的最大最小值。
第五步:导出量化模型。
当QAT训练完成后,得到了一个对量化友好的高精度模型,最后需将其转换为量化模型。
权重和激活值都通过各自最终的S和Z进行量化,然后移除所有伪量化节点,替换为真正量化后的值,得到最终的量化模型。
四、典型案例
最新的大模型都流行FP8训练,例如DeepSeek V3,Minimax-M2,而Kimi 的K2-Thinking直接使用INT4的QAT方法,本节我们介绍三个案例,看看业界最近使用的技术。
1、DeepSeek V3
细节都在年初的DeekSeek V3报告中[5],混合精度核心见图3。
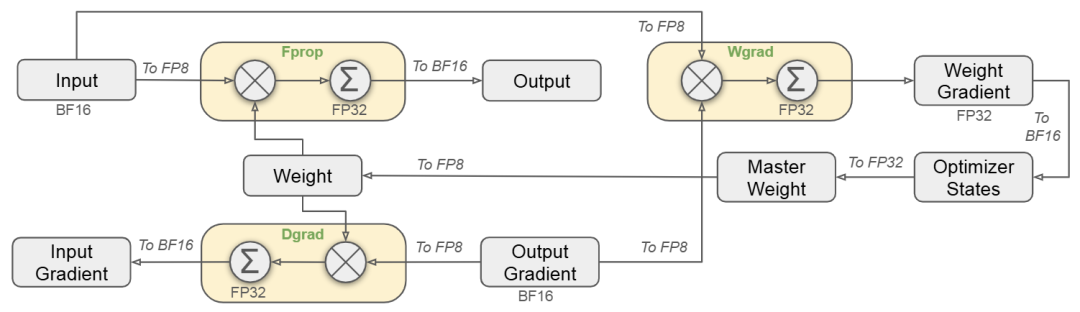
图3. DeekSeek V3 FP8混合精度训练
图的逻辑和本文上面混合精度训练图类似,在不同的地方分别用到了BF16、FP32、FP8。
其混合精度中的量化主要用了细粒度量化思想,针对权重和激活值分别设计了不同的量化策略。
权重:Block-wise量化,以128x128的块为基础对元素进行分组和缩放(每128个输入通道每128个输出通道),采用静态离线量化。
激活:Per-token-group量化,以1x128的组为基础对元素进行分组和缩放(每个token每128个通道),采用动态在线量化。
其FP8量化矩阵的乘法运算DeepGEMM,是 DeepSeek-V3低成本、高性能推理的核心。DeepSeek在后来的开源周公开了其代码。
2、Kimi K2-Thinking模型
K2-Thinking模型刚发布10天(2025年11月7日),关于其低比特训练的信息主要来源于其团队成员的知乎文章[1]。下面内容是文章的主要摘要。
“本次我们weight-only QAT采用的就是常见的fake-quantization+STE(直通估计器)方案。保存原始的bf16权重,通过量化-反量化得到模拟精度损失后的权重,进行矩阵乘,反向传播时再将梯度直接更新到原始的bf16中。。。这套QAT方案可以在整个post-training阶段不改变任何训练配方,不增加任何训练token数的前提下实现近乎无损。”
使用QAT而不用PTQ的原因,在之前的K2模型上,使用PTQ进行量化可以近乎无损,但在K2-Thinking推理模型上失效了。“随着模型的生成长度变得越来越长,我们原本的block FP8推理精度和INT4 PTQ的结果呈现出了统计意义上的明显差别。一个可能的原因是随着decoding计算次数的增加,量化产生的误差被不断累积了。。。此外,我们还观察到了INT4 PTQ的另一个劣势:依赖校准集。我们测试了一些在训练集中出现过,但未在PTQ校准集中出现的case,发现FP8模型可以很好地背诵下这些训练数据,而量化后的模型则会换一种表述方式甚至遗忘相关的内容。关于这个问题目前的大致猜测是当moe非常稀疏时,尽管我们已经用了较大规模的校准数据,仍然会有部分专家只被路由到了少量token,进而导致这些专家的量化结果产生明显的“失真”。”
3、InfiR2
这个就是我文章开头说的杨红霞团队最近完全开源的FP8训练方案。DeepSeek虽然开源了模型权重和部分技术代码,但是训练代码没有完全开源,InfiR2开源了模型和代码[7],目前看github星还很少。
训练流程和精度情况见下图,流程逻辑和本文开始的混合精度介绍时一致。把FP8方案和标准BF16方案放在上、下一起进行对比,可主要关注BF16变为FP8的地方。
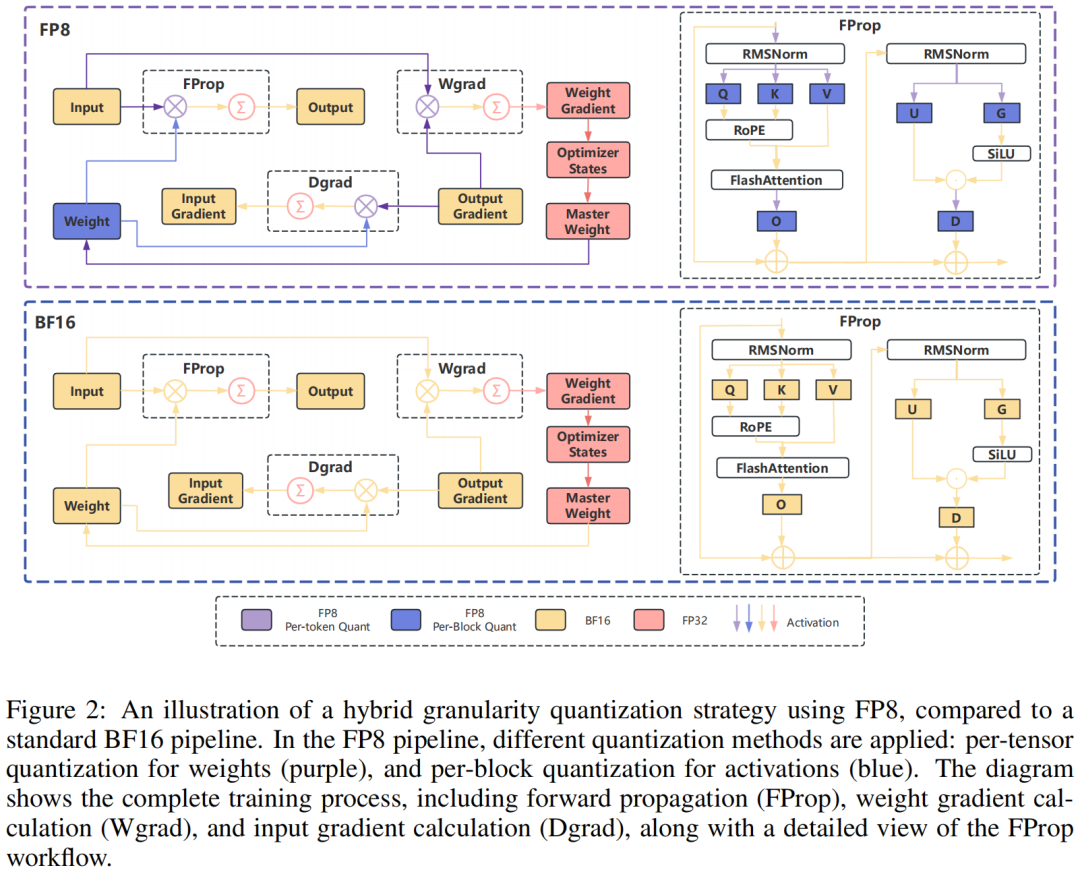
图4. InfiR2 混合精度训练
权重:使用分块量化方案(Block wise)。
激活:使用更细粒度的基于token的量化(Token wise)。
不同粒度的量化,下图5能比较形象地看出区别。
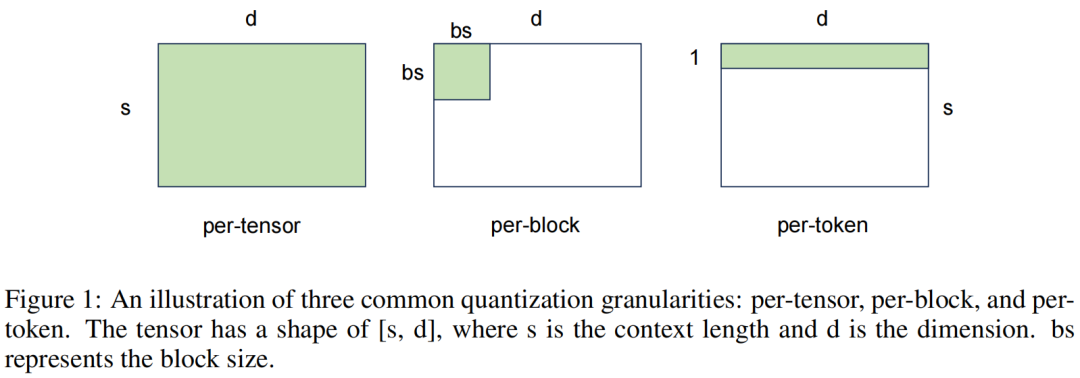
图5. 三种不同粒度的量化示意图
论文中该方案的实验结论是,对比BF16训练,训练速度提高22%,内存使用减少14%,吞吐量提高19%。
One More Thing
除了这些不同的量化方案,硬件对量化的计算支持也不可忽视,英伟达最新的Balckwell平台已经原生支持FP4、FP6、FP8的计算,包括低精度量化、通用矩阵计算GEMM等,以后的量化计算会越来越方便。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献256条内容
已为社区贡献256条内容

所有评论(0)