使用LangGraph构建自主RAG(1)
其中一个轻量级路由代理在多个检索源(问答数据集、设备手册或网络搜索)中进行选择,检查检索到的上下文的相关性,然后才使用大语言模型生成答案。在构建RAG(检索增强生成)系统时,用户不可避免地会提出“超出大纲”的问题,即这些问题不在系统的知识库覆盖范围内。我们如何设计一个检索增强生成系统,使其能够动态选择最合适的知识源,验证检索到的信息,并在医疗保健和医疗设备等高风险领域中生成有依据、具备上下文感知能
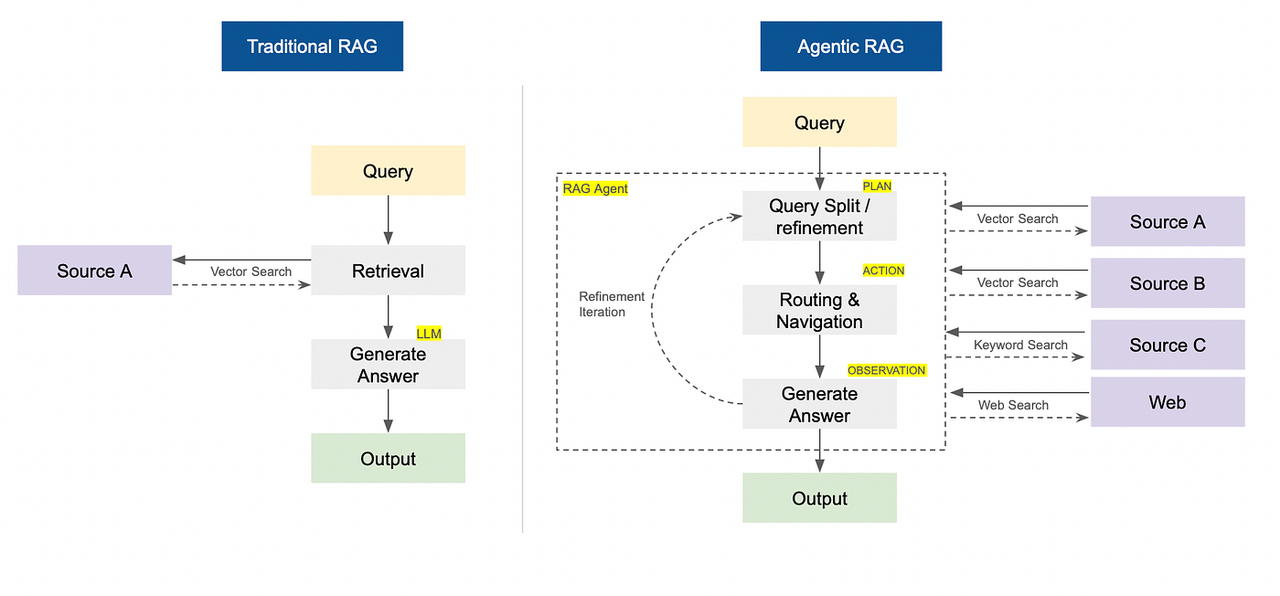
传统检索增强生成(RAG)与智能体检索增强生成(RAG)对比(图片由作者提供)
非会员:阅读此处
类比
我记得七年级英语考试时的一个情况。有一道题超出了教学大纲,所有学生都慌了。考试结束后,一些学生要求老师给那道题打分,老师同意了。每个人都很高兴能“免费”拿到分数。
在现实世界中,这种情况不会发生。在构建RAG(检索增强生成)系统时,用户不可避免地会提出“超出大纲”的问题,即这些问题不在系统的知识库覆盖范围内。你不能要求用户不提出这类问题。
为了应对这种情况,你可以构建一个自主RAG系统——该系统能够识别问题是否不在知识库中,并自主进行网络搜索或采取其他行动来提供可靠答案。
引言
检索增强生成(RAG)通过结合信息检索和大语言模型(LLMs)的优势,改变了我们构建AI应用程序的方式。在RAG系统中,模型不会将整个大型数据集直接输入到大语言模型(LLM)中,而是从外部知识库或文档存储中检索最相关的信息片段(上下文),以响应用户查询。然后,这些检索到的信息片段会被提供给大语言模型,以生成有依据且考虑上下文的响应。
检索增强生成(RAG)系统的有效性主要取决于两个关键因素:速度和准确性。嵌入维度、索引方法和系统架构的复杂性等变量都会对这两个因素产生影响。
在本文中,我们将探讨一种新兴的检索增强生成(RAG)架构,即智能体RAG,并将其与传统(或“普通”)RAG系统进行比较。我们还将通过实际代码示例展示它们之间的差异。
传统RAG系统与智能体RAG对比
传统的RAG(检索增强生成)遵循固定的“先检索再生成”流程——它只是从特定来源获取信息并给出答案。
自主式RAG使用自主AI智能体,这些智能体主动决定检索内容、检索方式、检索时间以及检索来源(如网络、向量数据库)。它会规划多步骤搜索,即时调整查询,并以迭代方式得出更优答案。
按回车键或点击以查看全尺寸图像
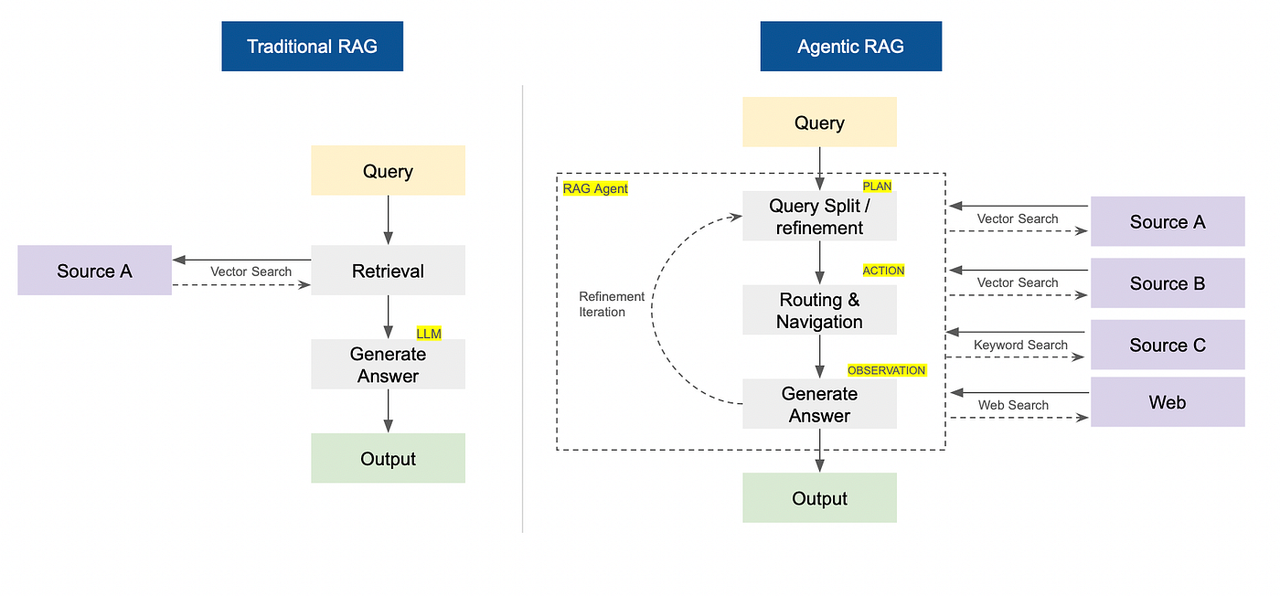
传统检索增强生成(RAG)与智能体检索增强生成(RAG)对比(图片由作者提供)
传统的检索增强生成(RAG)在哪些方面会失败?
传统的检索增强生成(RAG)在需要适应性和跨多个知识库源进行深度推理的领域表现不佳。以下是传统RAG系统的主要局限性:
-
单次检索:执行一次性检索,缺少多跳推理和更深层次的上下文关联。
-
不相关检索与幻觉:检索到语义相似但上下文错误的数据,导致事实性错误。
-
静态和非自适应:缺乏基于用户意图、反馈或不断变化的上下文的动态检索或优化。
-
可扩展性限制:受上下文窗口、大规模聚合能力差和高计算开销的限制。
现在,让我们开始使用LangGraph、ChromaDB和SerperAPI(网络搜索)来实现代理式RAG。
问题陈述
问题:我们如何设计一个检索增强生成系统,使其能够动态选择最合适的知识源,验证检索到的信息,并在医疗保健和医疗设备等高风险领域中生成有依据、具备上下文感知能力的响应?
建议的解决方案:引入一个智能RAG管道,其中一个轻量级路由代理在多个检索源(问答数据集、设备手册或网络搜索)中进行选择,检查检索到的上下文的相关性,然后才使用大语言模型生成答案。与传统的RAG系统相比,这种方法旨在提高准确性、灵活性和可靠性。
请参考端到端的github笔记本此处。
技术栈
-
Python
-
语言图
-
LangChain
-
Chroma DB
-
SerperAPI(网络搜索)
-
OpenAI API (大语言模型)
导入所需模块
import pandas as pd
import numpy as np
import json
import re
from typing import List, Dict, Any, Tuple
import faiss
from sentence_transformers import SentenceTransformer
from openai import OpenAI
import time
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
import seaborn as sns
from dotenv import load_dotenv
import openai
import os
from langchain_community.utilities import GoogleSerperAPIWrapper
# ✅ Load environment variables
load_dotenv()
openai_api_key = os.getenv("OPEN_AI_KEY")
SERPER_API_KEY = os.getenv("SERPER_API_KEY")加载数据
实验中使用了两个CSV数据集(为了快速迭代,两个数据集均下采样至500行):
医疗问答数据集
一个全面的医学问答数据集。我们抽取500行,并将每行合并到一个单独的`combined_text`字段中,格式如下:`问题:… 答案:… 类型:…`。
来源: Kaggle
## Data 1: reading the Comprehensive Medical Q&A Dataset
df_qa = pd.read_csv("medical_q_n_a.csv")
## Data has 16407 rows, hence we will sample 500 rows for experimentation
df_qa = df_qa.sample(500, random_state=0).reset_index(drop=True)
print(df_qa.shape)
df_qa.head()
# Preparing the Dataframe for Vector DB by combining the Text
df_qa['combined_text'] = (
"Question: " + df_qa['Question'].astype(str) + ". " +
"Answer: " + df_qa['Answer'].astype(str) + ". " +
"Type: " + df_qa['qtype'].astype(str) + ". "
)
df_qa.head()按回车键或点击以查看全尺寸图像

医学问答数据集的前5行
医疗器械手册数据集
此包含医疗设备手册和元数据。我们抽取500行并创建 `combined_text`,格式如下:`设备名称:… 型号:… 制造商:… 适应症:… 禁忌症:…`。
来源: Kaggle
## Data 2: reading the Medical Device Manuals Dataset
df_medical_device = pd.read_csv("medical_device_manuals_dataset.csv")
print(df_medical_device.shape)
## Data has 2694 rows, hence we will sample 500 rows for experimentation
df_medical_device = df_medical_device.sample(500, random_state=0).reset_index(drop=True)
print(df_medical_device.shape)
# Preparing the Dataframe for Vector DB by combining the Text
df_medical_device['combined_text'] = (
"Device Name: " + df_medical_device['Device_Name'].astype(str) + ". " +
"Model: " + df_medical_device['Model_Number'].astype(str) + ". " +
"Manufacturer: " + df_medical_device['Manufacturer'].astype(str) + ". " +
"Indications: " + df_medical_device['Indications_for_Use'].astype(str) + ". " +
"Contraindications: " + df_medical_device['Contraindications'].fillna('None').astype(str)
)
df_medical_device.head()按回车键或点击以查看全尺寸图像
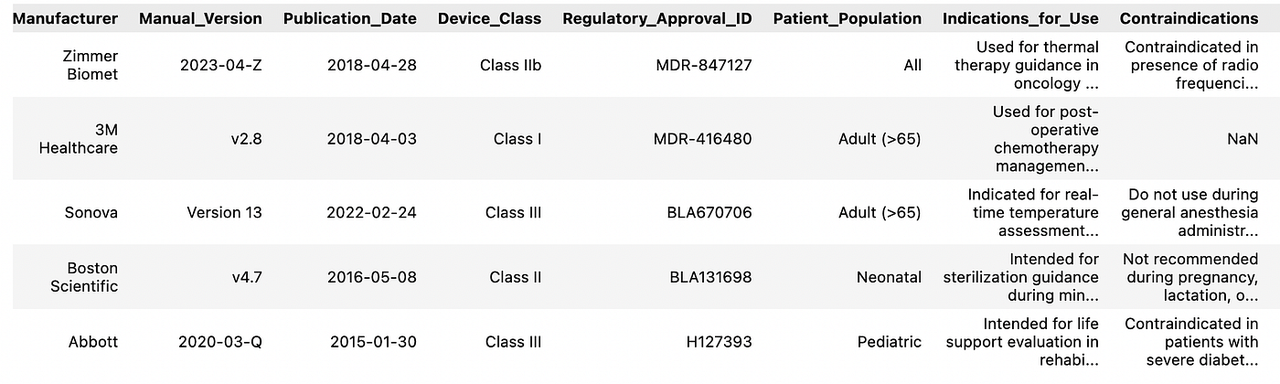
医疗器械手册数据集的前5行

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)