openGauss 驱动的知识数据湖建设实践
在这个新范式下,openGauss 不再仅仅是一个数据库,而是企业统一知识和数据的中央枢纽,为 RAG、BI 分析和各类数据驱动应用提供了前所未有的坚实基础。这种分离导致了严重的“左右手互搏”:AI 模型在“粮仓”里进行训练,却因缺乏高质量的、有上下文的知识而产生“幻觉”,无法回答精准的企业级问题;传统数据湖解决了数据“存得下”的问题,但未能解决“管得好”、“用得对”的治理难题。RAG 应用拿到的
文章目录
一、引言:当数据湖遇上知识库——AI 时代的左右手互搏
在企业数据战略中,长期存在着两个并行但割裂的世界:
- 数据湖:以 HDFS 或对象存储(OBS/S3)为底座,汇聚了海量的、原始的、多模态数据(日志、文档、图片、IoT 数据)。它是大数据分析和 AI 模型训练的“粮仓”,但往往缺乏治理,数据质量良莠不齐,被称为“数据沼泽”。
- 知识库:以 Wiki、SharePoint 或专用系统形式存在,存储着经过人工提炼和组织的、高质量的结构化知识(SOP、FAQ、案例库)。它是人类专家的智慧宝库,但规模有限,与海量原始数据脱节。
这种分离导致了严重的“左右手互搏”:AI 模型在“粮仓”里进行训练,却因缺乏高质量的、有上下文的知识而产生“幻觉”,无法回答精准的企业级问题;人类专家在“宝库”里查阅,却无法追溯到知识背后的原始数据证据链。
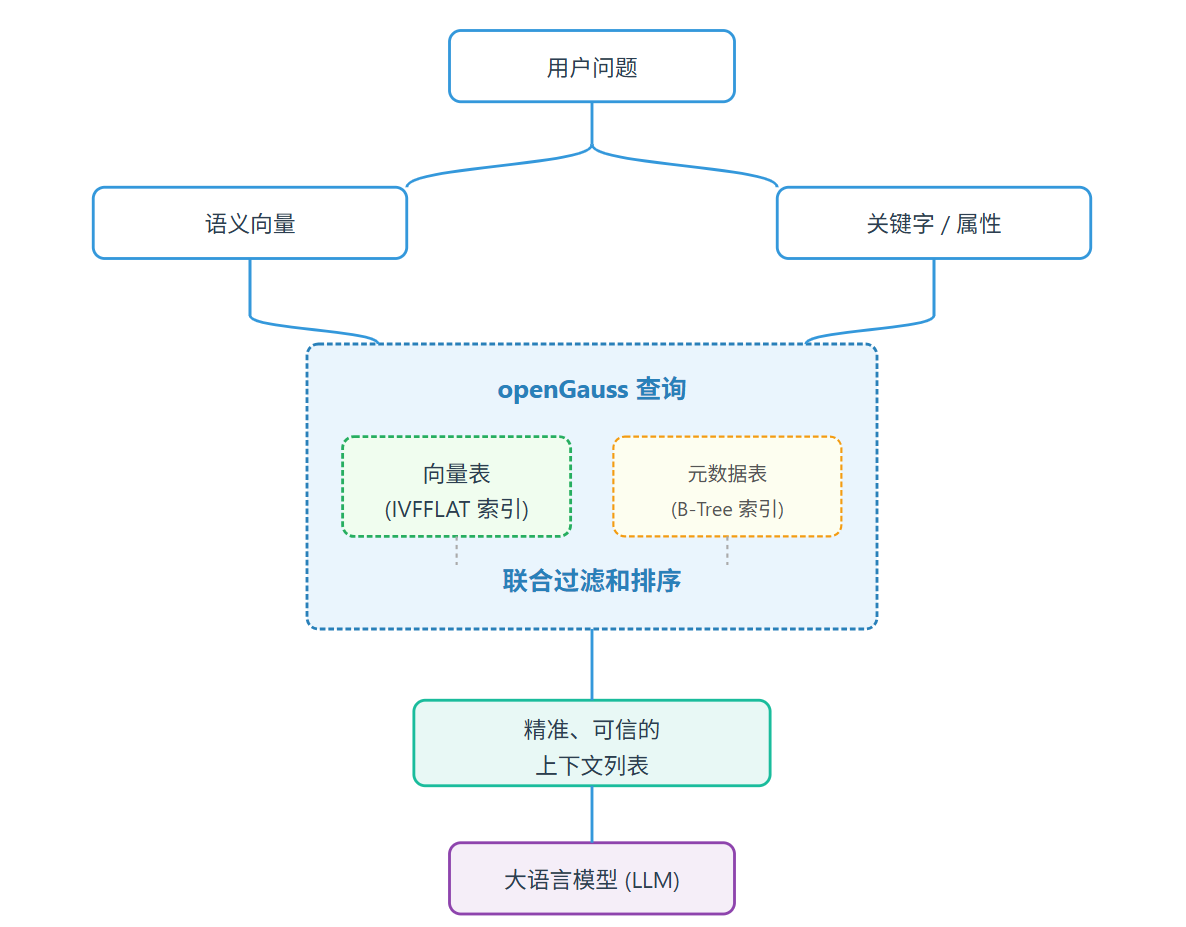
检索增强生成RAG技术的兴起,对打破这一壁垒提出了迫切需求。RAG 的效果,直接取决于能否在一个统一的平台中,既能检索到海量数据,又能理解结构化知识。

二、架构设计:以 openGauss 为中心的统一纳管
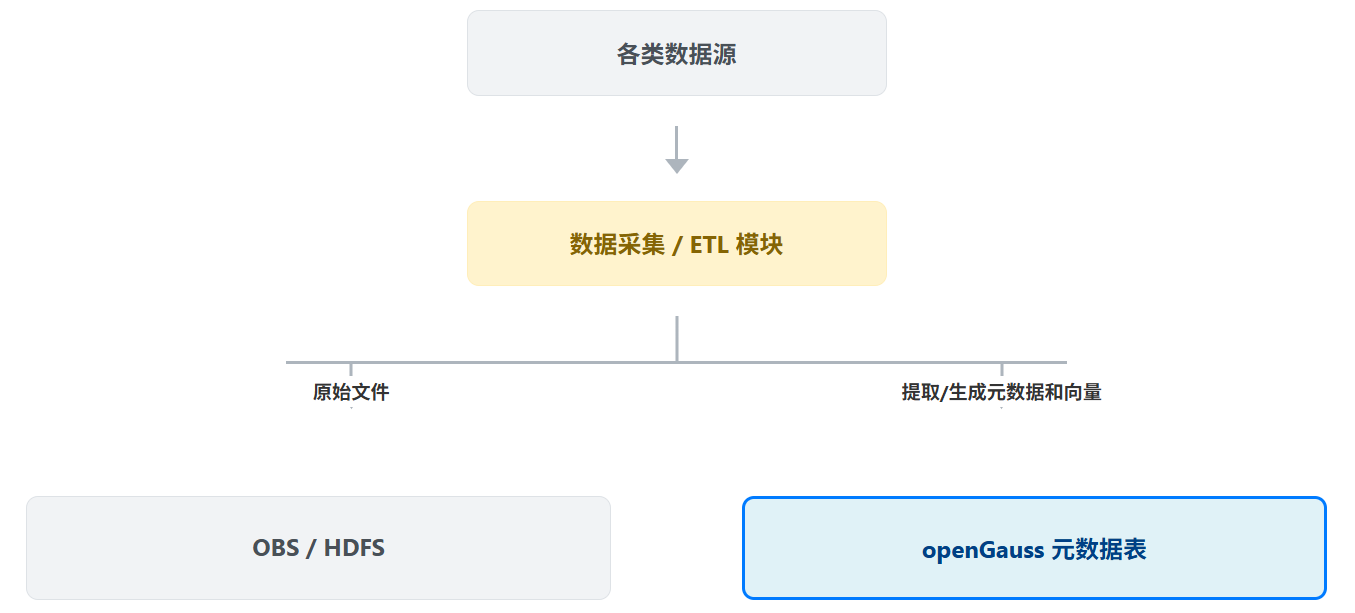
知识数据湖的核心架构思想是存算分离与逻辑统一。原始数据文件(文档、图片、日志等)依然存储在成本低廉的对象存储或 HDFS 中,但其元数据、结构化知识、向量索引和访问入口则全部由 openGauss 统一管理。
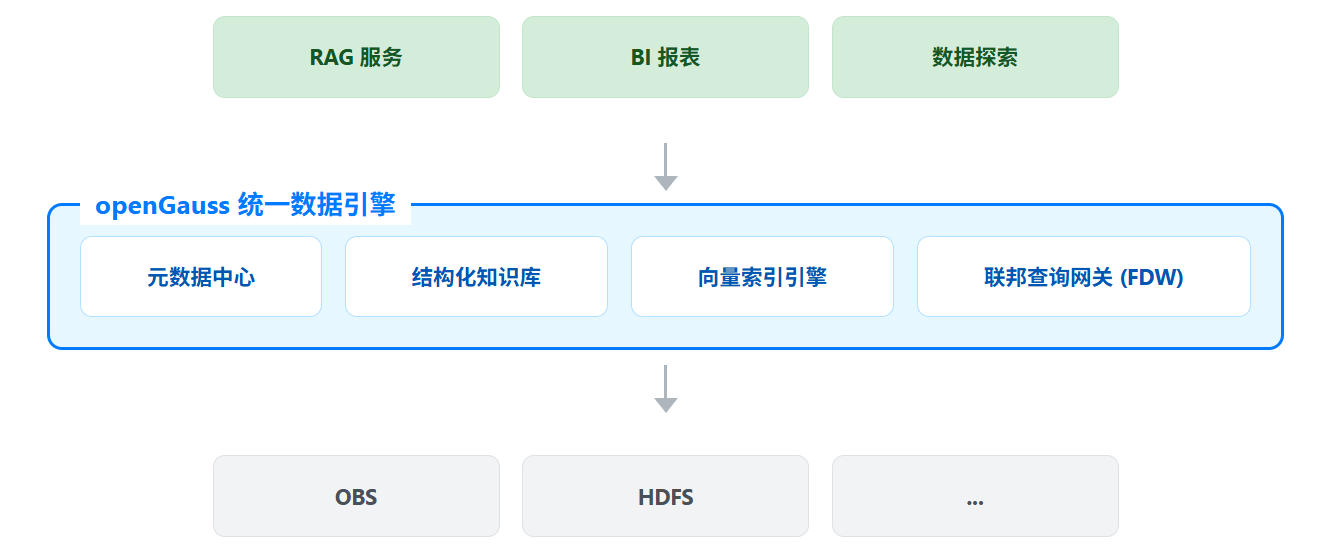
| 核心组件 | 角色与职责 | 技术实现 |
|---|---|---|
| 统一存储层 | 存储海量原始数据文件 | OBS / HDFS / 分布式文件系统 |
| openGauss 引擎 | 知识数据湖的“大脑”和“入口” | - |
| 元数据中心 | 统一管理所有数据资产的元信息 | openGauss 原生关系表 |
| 结构化知识库 | 存储和管理高质量的结构化知识 | openGauss 高性能事务引擎 |
| 向量索引引擎 | 为非结构化数据提供语义检索能力 | DataVec 等向量扩展 |
| 联邦查询网关 | 按需直接查询和访问原始数据 | obs_fdw, hdfs_fdw 等外表封装器 |
三、数据入湖与建模:构建知识的中央目录
数据入湖的过程,不仅仅是文件的上传,更是元数据的注册过程。我们将在 openGauss 中设计一套核心元数据模型来管理整个知识数据湖。
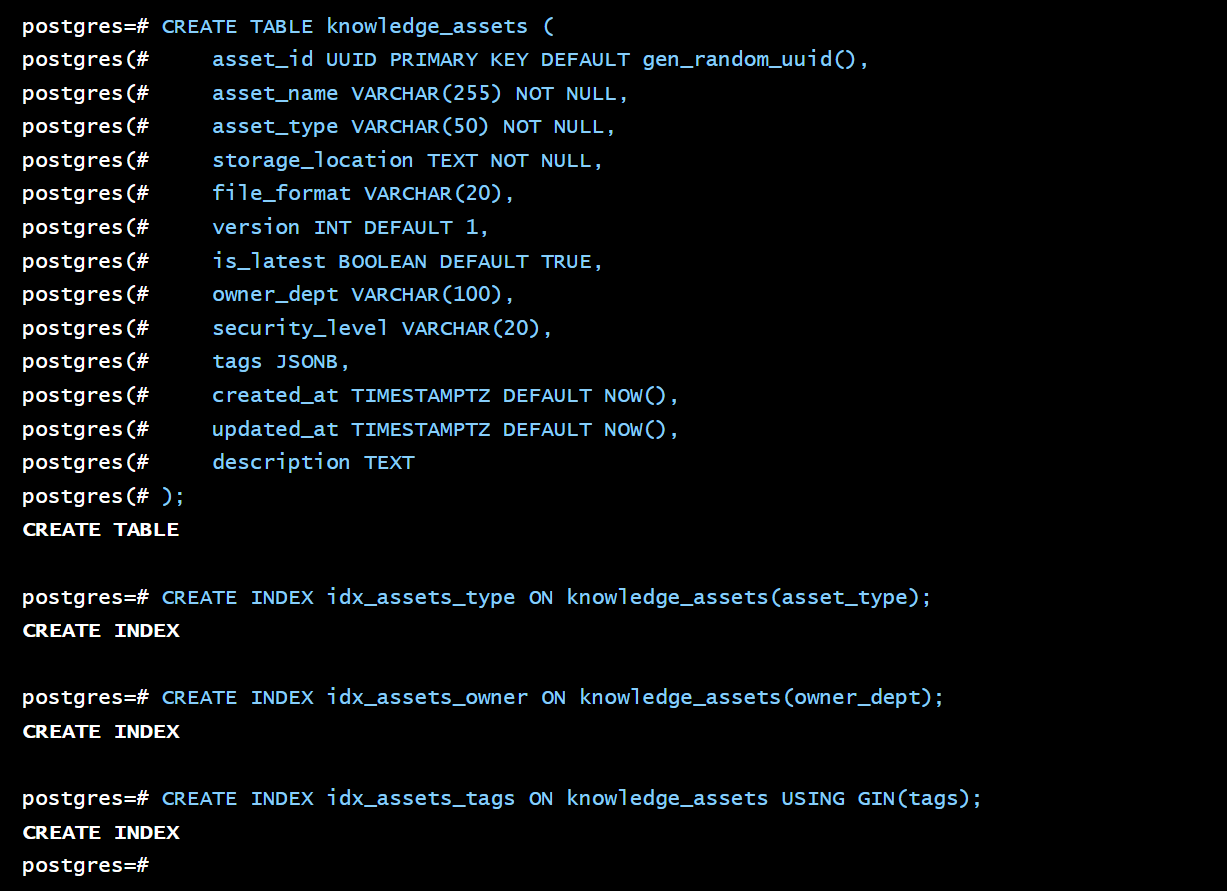
3.1 核心元数据表
这是整个知识数据湖的“中央目录”或“卡片索引”。
CREATE TABLE knowledge_assets (
asset_id UUID PRIMARY KEY DEFAULT gen_random_uuid(), -- 唯一资产 ID
asset_name VARCHAR(255) NOT NULL, -- 资产名称
asset_type VARCHAR(50) NOT NULL, -- 类型: document, table, log_file, image...
storage_location TEXT NOT NULL, -- 存储路径 (e.g., obs://bucket/path/to/file)
file_format VARCHAR(20), -- 文件格式: PDF, Parquet, JSON...
version INT DEFAULT 1, -- 版本号
is_latest BOOLEAN DEFAULT TRUE, -- 是否为最新版本
owner_dept VARCHAR(100), -- 所属部门
security_level VARCHAR(20), -- 安全等级
tags JSONB, -- 标签,便于分类和发现
created_at TIMESTAMPTZ DEFAULT NOW(),
updated_at TIMESTAMPTZ DEFAULT NOW(),
description TEXT
);
-- 为常用查询字段创建索引
CREATE INDEX idx_assets_type ON knowledge_assets(asset_type);
CREATE INDEX idx_assets_owner ON knowledge_assets(owner_dept);
CREATE INDEX idx_assets_tags ON knowledge_assets USING GIN(tags);
3.2 向量与知识的关联
对于需要进行语义检索的非结构化资产(如文档),我们会在一个单独的表中存储其向量表示,并与元数据表关联。
CREATE TABLE asset_embeddings (
asset_id UUID PRIMARY KEY REFERENCES knowledge_assets(asset_id),
embedding VECTOR(768) -- 假设使用 768 维向量
);
CREATE INDEX idx_embeddings_ivfflat ON asset_embeddings USING ivfflat (embedding) WITH (list_count = 1024);


3.3 数据采集与注册流程
四、治理实践:版本管理与血缘追踪
4.1 版本管理
当一个知识资产(如一份 SOP 文件)更新时,我们不直接覆盖旧文件,而是上传新版本并更新元数据,以实现可追溯性。
更新操作的事务性流程:
BEGIN;
-- 1. 将旧版本的 is_latest 标志设为 false
UPDATE knowledge_assets
SET is_latest = FALSE
WHERE asset_name = 'Standard_Operating_Procedure_A.pdf' AND is_latest = TRUE;
-- 2. 插入新版本的元数据记录
INSERT INTO knowledge_assets (asset_name, asset_type, storage_location, version, owner_dept, ...)
VALUES ('Standard_Operating_Procedure_A.pdf', 'document', 'obs://bucket/sop_v2.pdf', 2, 'Ops', ...);
COMMIT;
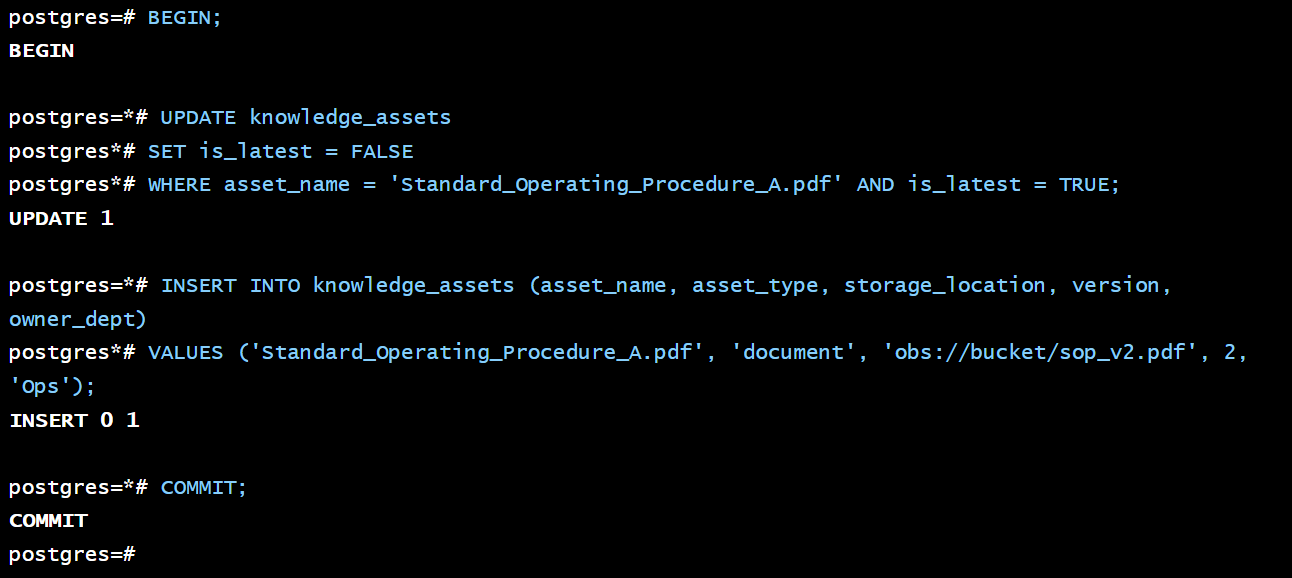
这种设计确保了任何时候我们都可以通过查询 knowledge_assets 表,找到一个资产的所有历史版本。
4.2 数据血缘追踪
血缘追踪的关键在于记录资产之间的转换和依赖关系。我们可以设计一个血缘关系表。
CREATE TABLE asset_lineage (
downstream_asset_id UUID REFERENCES knowledge_assets(asset_id), -- 下游资产
upstream_asset_id UUID REFERENCES knowledge_assets(asset_id), -- 上游资产
transform_logic TEXT, -- 描述转换逻辑或程序
created_at TIMESTAMPTZ DEFAULT NOW(),
PRIMARY KEY (downstream_asset_id, upstream_asset_id)
);
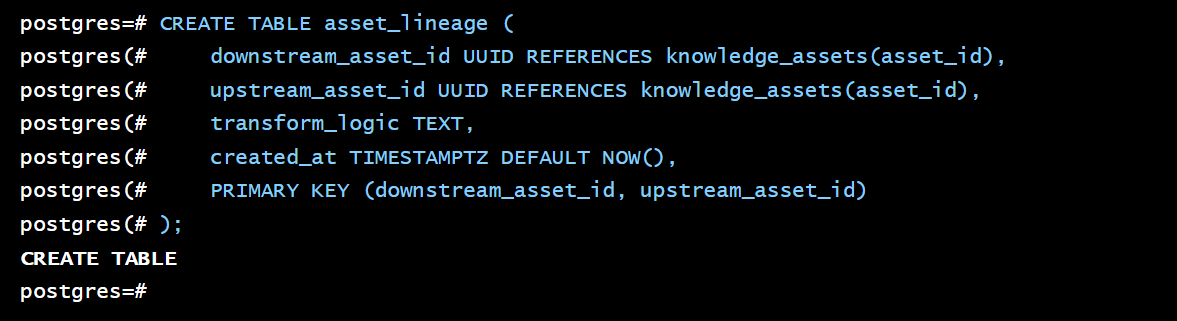
例如,一个 BI 报表 report.csv 是由 log_a.parquet 和 user_table.csv 经过一个 Spark 作业生成的,我们就可以在 asset_lineage 表中插入两条记录来追踪这个关系。这为数据质量问题排查和影响分析提供了可能。
五、一访问:联邦查询与 RAG 实践
openGauss 最强大的地方在于,它不仅能管理元数据,还能直接“穿透”到数据湖中访问原始数据。
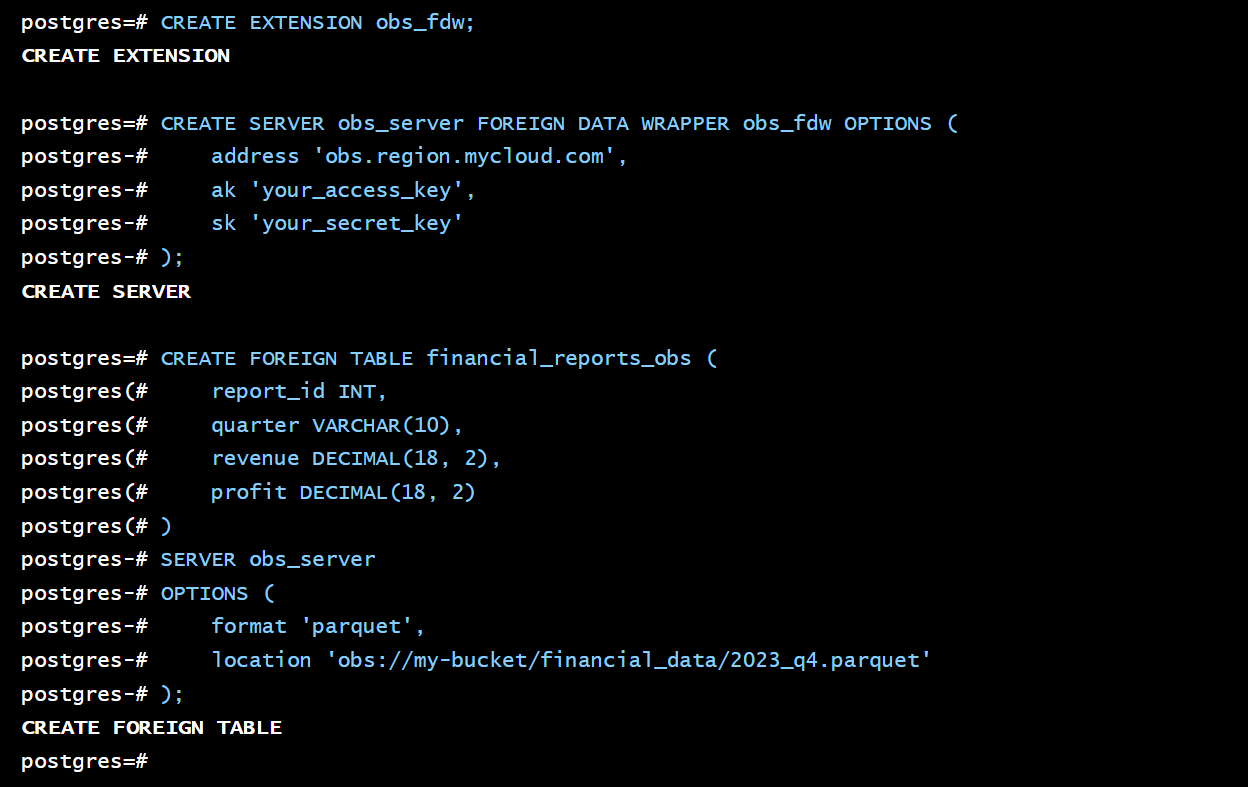
5.1 使用 obs_fdw 连接对象存储
-- 准备工作:创建扩展和服务器
CREATE EXTENSION obs_fdw;
CREATE SERVER obs_server FOREIGN DATA WRAPPER obs_fdw OPTIONS (
address 'obs.region.mycloud.com',
ak 'your_access_key',
sk 'your_secret_key'
);
-- 创建外表,直接映射到 OBS 上的一个 Parquet 文件
CREATE FOREIGN TABLE financial_reports_obs (
report_id INT,
quarter VARCHAR(10),
revenue DECIMAL(18, 2),
profit DECIMAL(18, 2)
)
SERVER obs_server
OPTIONS (
format 'parquet',
location 'obs://my-bucket/financial_data/2023_q4.parquet'
);
5.2 RAG 中的混合检索查询
现在,一个 RAG 应用在接到用户提问 “查找关于 Q4 盈利能力分析的最新官方文档” 时,可以向 openGauss 发起一个强大的混合查询。
1. 准备查询:
将问题转换为查询向量
query_vector
构建全文检索查询to_tsquery('chinese', 'Q4 & 盈利')
2. 执行混合查询:
SELECT
ka.asset_name,
ka.storage_location,
-- 计算语义相似度得分
l2_distance(ae.embedding, :query_vector) AS semantic_score
FROM
knowledge_assets ka
JOIN
asset_embeddings ae ON ka.asset_id = ae.asset_id
WHERE
-- 条件1: 资产类型是文档 (元数据过滤)
ka.asset_type = 'document'
-- 条件2: 是最新版本 (版本管理)
AND ka.is_latest = TRUE
-- 条件3: 标签包含“财务”和“官方” (标签过滤)
AND ka.tags @> '["financial", "official"]'::jsonb
ORDER BY
-- 按语义相似度排序
ae.embedding <-> :query_vector
LIMIT 5;
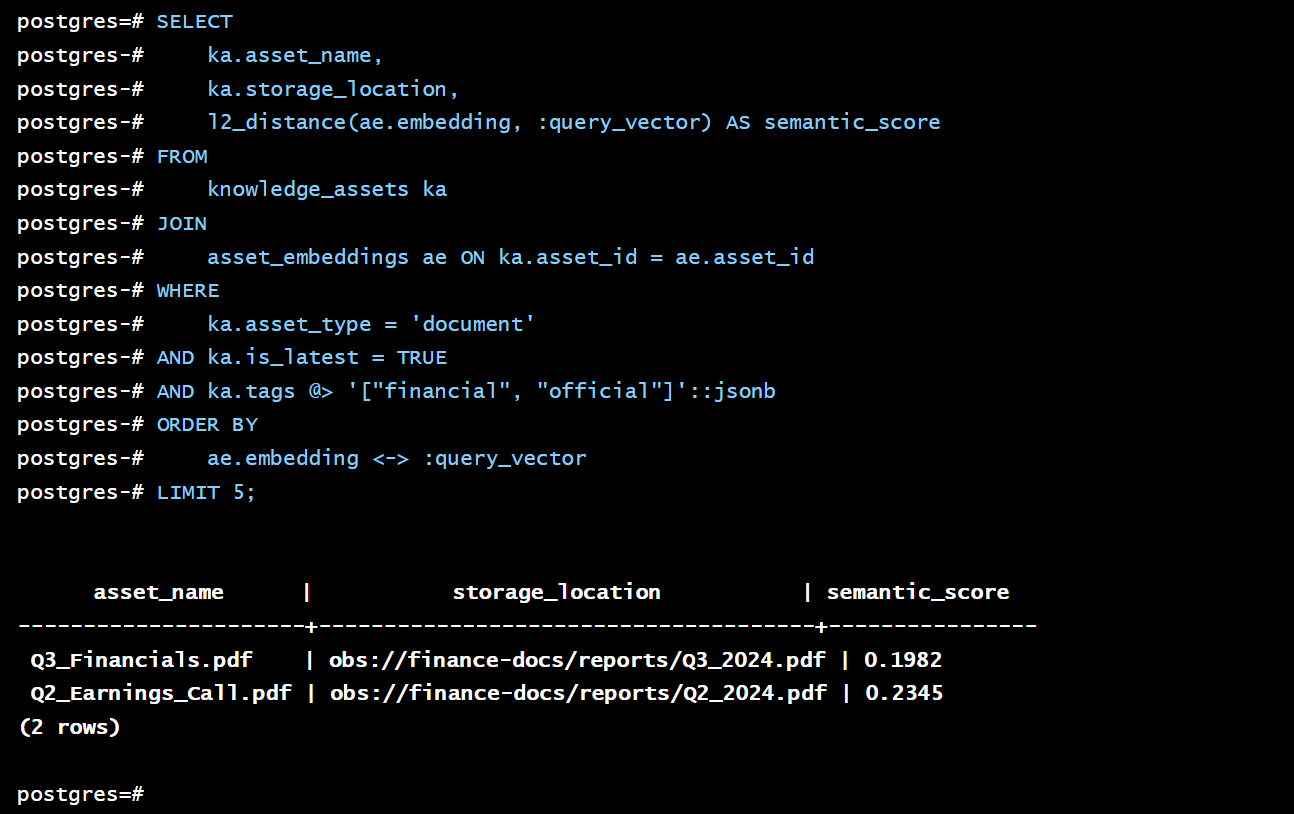
这个查询的强大之处在于,它在一个请求中融合了 元数据过滤 (类型、版本、标签) 和 向量语义检索。RAG 应用拿到的不仅是相似的文档,更是经过治理的、可信的、最新的官方文档。
六、结论:openGauss,从数据湖到知识数据湖的进化引擎
传统数据湖解决了数据“存得下”的问题,但未能解决“管得好”、“用得对”的治理难题。openGauss 通过其独特的能力组合:
关系型内核:为数据湖提供了强大的元数据管理、事务和治理能力。
向量引擎扩展:赋予了数据湖“理解”非结构化数据的语义能力。
联邦查询网关 (FDW):打通了治理层与存储层,实现了就地、按需的原始数据访问。
成功地将一个原始的“数据湖”进化为了一个有序、可信、智能的知识数据湖。在这个新范式下,openGauss 不再仅仅是一个数据库,而是企业统一知识和数据的中央枢纽,为 RAG、BI 分析和各类数据驱动应用提供了前所未有的坚实基础。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)