openGauss 与行业数据治理:从数据孤岛到统一分析底座
openGauss 与行业数据治理:从数据孤岛到统一分析底座
一、引言:数字化转型的数据孤岛
在数字化浪潮中,数据已成为新的生产要素。金融、能源、制造等行业正加速数字化转型,期望以数据驱动创新与效率。但几乎所有企业都面临共同难题——数据孤岛
企业数据往往分散在不同系统:
交易数据存于 Oracle、DB2;
行为日志与传感器数据在 Hadoop/HDFS 或 S3;
各部门自建 MySQL、PostgreSQL;
时序数据写入 InfluxDB。
这种碎片化导致:
分析低效:分析师将大量时间耗在数据清洗与整合上;
决策滞后:缺乏实时、全局视角;
合规风险:标准不一、血缘不清;
AI 受限:模型训练数据难以统一获取。
打破数据孤岛,构建统一分析平台,已成为数字化转型的关键。本文将探讨 openGauss 如何凭借联邦查询、生态协同与企业级安全特性,构建企业的统一数据底座。
二、解决方案:以 openGauss 为核心的统一数据分析底座
传统的解决方案,如构建一个庞大的数据仓库,需要通过 ETL 过程将所有数据定期抽取到中央存储。这种方式不仅成本高昂、周期长,而且数据时效性差。
openGauss 提出了一种更现代、更敏捷的逻辑数据湖 方案。其核心思想是:让数据保留在原地,通过 openGauss 的联邦查询能力实现虚拟化的数据统一。
2.1 架构设计
该架构以 openGauss 为中心,通过其强大的外表 机制和丰富的外部数据封装器,逻辑上连接并统一访问各类异构数据源。
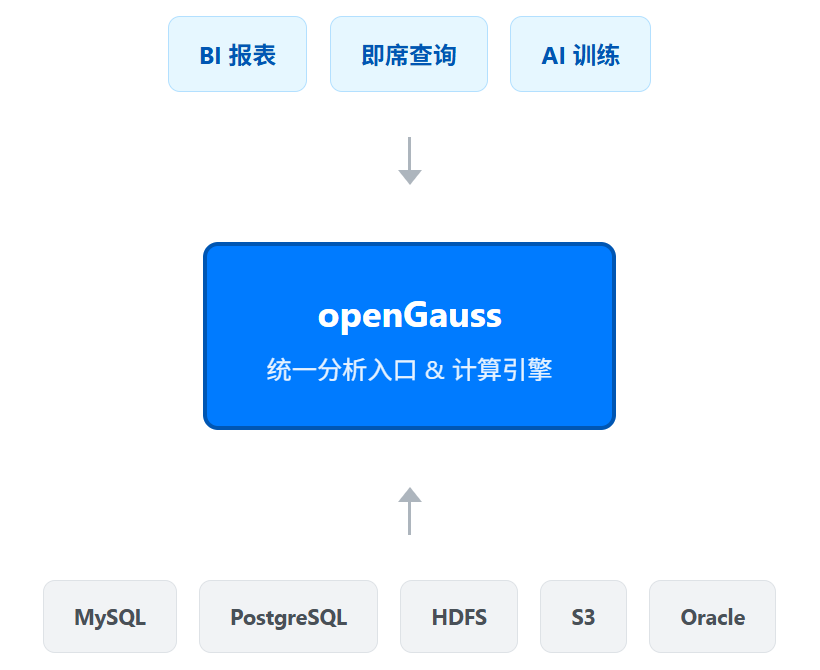
2.2 核心组件与生态协同
| 组件 | 在架构中的角色 | 协同优势 |
|---|---|---|
| openGauss | 统一查询入口、元数据中心、计算与安全引擎 | 提供标准 SQL 接口,负责查询解析、优化、下推和执行。 |
| FDW (外部数据封装器) | 数据源翻译官 | 将对 openGauss 外表的查询,翻译成对应外部数据源的原生查询语言。 |
| openLooKeng/Presto | 高性能联邦查询引擎 | 对于海量、超大规模的 HDFS/Hive 数据查询,可与 openGauss 协同,发挥其大规模并行处理 (MPP) 的优势。 |
| Apache Spark/Flink | 批处理与流处理引擎 | 可通过 JDBC/ODBC 连接 openGauss,将治理好的统一数据作为其计算任务的数据源。 |
| openEuler | 高性能、高安全的基础设施底座 | 为 openGauss 提供稳定、高效、安全的运行环境,其内核级优化能进一步提升数据库性能。 |
三、实战一:使用 Foreign Table 打破 MySQL 数据孤岛
假设我们的订单数据存储在 MySQL 中,而用户数据存储在 openGauss 中。现在我们需要进行一次关联查询,分析每个用户的总订单金额。
3.1 准备工作
- 已安装并运行 openGauss 和 MySQL。
- 在 openGauss 中安装
mysql_fdw扩展。
-- 在 openGauss 中执行
CREATE EXTENSION mysql_fdw;

3.2 配置连接
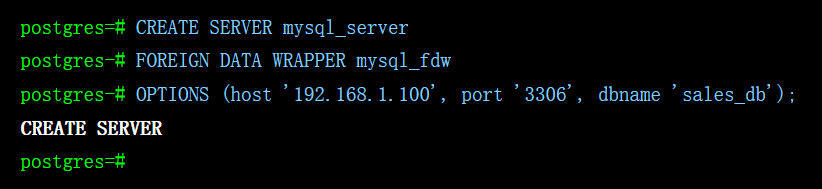
1. 创建服务器对象 (Server):定义如何连接到远程 MySQL 数据库。
CREATE SERVER mysql_server
FOREIGN DATA WRAPPER mysql_fdw
OPTIONS (host '192.168.1.100', port '3306', dbname 'sales_db');
2. 创建用户映射 (User Mapping):定义 openGauss 用户以哪个 MySQL 用户的身份去连接。
CREATE USER MAPPING FOR opengauss_user
SERVER mysql_server
OPTIONS (username 'mysql_readonly_user', password 'your_password');

3.3 创建外表 (Foreign Table)
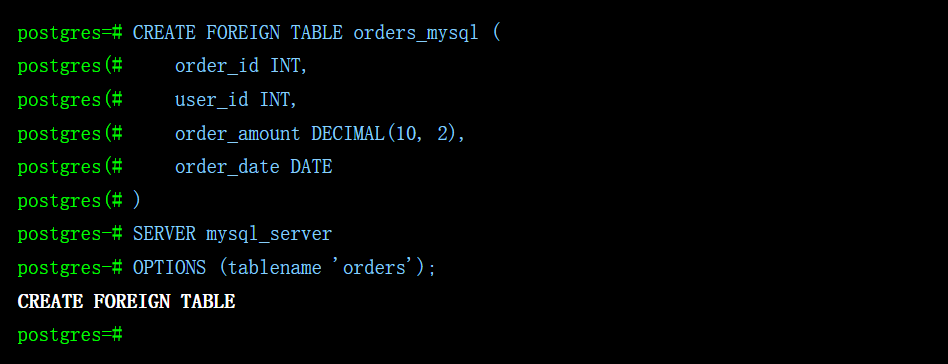
在 openGauss 中创建一个“虚拟表”,其结构与远程 MySQL 中的 orders 表完全对应。openGauss 只存储该表的元数据,不存储实际数据。
CREATE FOREIGN TABLE orders_mysql (
order_id INT,
user_id INT,
order_amount DECIMAL(10, 2),
order_date DATE
)
SERVER mysql_server
OPTIONS (tablename 'orders');
3.4 实现跨源关联查询
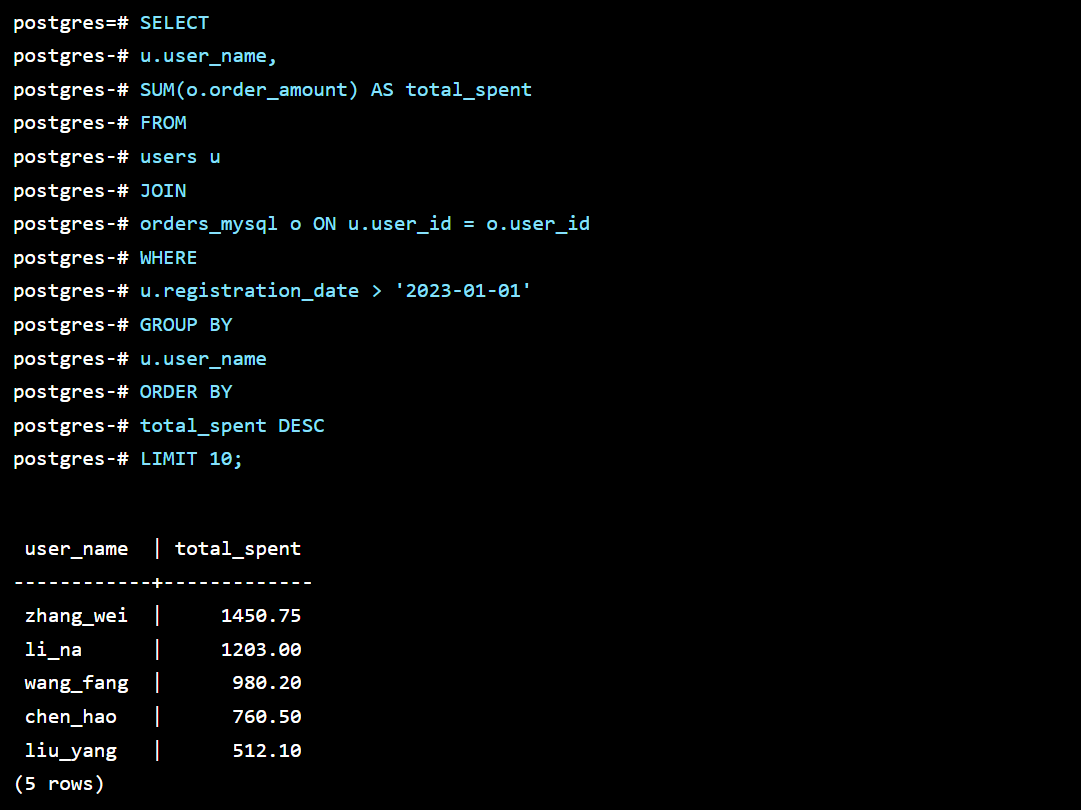
现在,我们可以在 openGauss 中像查询本地表一样,对 orders_mysql 和本地的 users 表进行关联查询。
-- 在 openGauss 中执行,这一个查询,同时访问了 openGauss 和 MySQL 的数据!
SELECT
u.user_name,
SUM(o.order_amount) AS total_spent
FROM
users u -- 本地 openGauss 表
JOIN
orders_mysql o ON u.user_id = o.user_id -- 远程 MySQL 外表
WHERE
u.registration_date > '2023-01-01'
GROUP BY
u.user_name
ORDER BY
total_spent DESC
LIMIT 10;
背后发生了什么? openGauss 的查询优化器会智能地将 WHERE 和 JOIN 条件尽可能地下推 (Predicate Pushdown) 到 MySQL 端执行,只将必要的结果集返回 openGauss 进行最终的聚合和计算,从而最大化地利用了源端数据库的计算能力,减少了网络传输。

四、实战二:统一纳管 HDFS 中的大数据
对于存储在 HDFS 上的海量日志数据(通常为 Parquet 或 ORC 格式),我们可以使用 hdfs_fdw 实现就地分析。
4.1 配置与创建 HDFS 外表
配置过程与 mysql_fdw 类似,需要创建 SERVER 和 USER MAPPING。
CREATE EXTENSION hdfs_fdw;
CREATE SERVER hdfs_server
FOREIGN DATA WRAPPER hdfs_fdw
OPTIONS (host 'namenode_host', port '9000');
CREATE FOREIGN TABLE user_logs_hdfs (
user_id BIGINT,
event_type VARCHAR(50),
event_timestamp TIMESTAMP,
ip_address VARCHAR(45)
)
SERVER hdfs_server
OPTIONS (
format 'parquet',
path '/data/logs/user_events/'
);
4.2 HDFS 与本地表混合分析
现在,我们可以将 HDFS 上的用户行为日志与 openGauss 中的业务数据进行复杂分析,例如,分析高消费用户的登录行为模式。
SELECT
l.ip_address,
COUNT(DISTINCT l.user_id) AS high_value_users_count
FROM
user_logs_hdfs l -- HDFS 上的 Parquet 文件
WHERE
l.event_type = 'login'
AND l.user_id IN (
-- 子查询,从 openGauss 本地表中筛选出高价值用户
SELECT user_id FROM user_value_segments WHERE segment = 'high_value'
)
GROUP BY
l.ip_address
ORDER BY
high_value_users_count DESC;
通过这种方式,openGauss 成为了一个强大的数据虚拟化引擎,为上层应用屏蔽了底层数据存储的复杂性和异构性。
五、数据治理:从混乱到有序
统一查询入口只是第一步。真正的数据治理还需要解决元数据、安全和合规问题。
5.1 统一元数据管理
通过创建外表,openGauss 实际上成为了一个逻辑上的统一元数据中心。所有数据资产的定义(表结构、字段类型、注释)都集中在 openGauss 的系统表中。
数据发现: 分析师只需连接 openGauss,就能发现和理解所有已纳管的数据源。
影响分析: 可以通过查询 openGauss 的依赖关系视图,轻松地进行数据血缘和影响分析。

5.2 统一的安全与权限管控
在数据孤岛模式下,为每个用户在每个系统上单独配置权限是一场噩梦。以 openGauss 为中心,可以实现统一的、基于角色的访问控制 (RBAC)。
权限集中化: 可以在 openGauss 中为用户或角色(如
analyst_role)授权对外表的SELECT权限。
行列级安全 (RLS/CLS): openGauss 强大的行列级安全策略同样适用于外表。例如,可以定义一个策略,使得销售经理只能看到自己区域的订单数据,即使这些数据物理上存储在 MySQL 中。
-- 示例:为外表创建行级安全策略
CREATE POLICY sales_region_policy ON orders_mysql
FOR SELECT
USING (get_user_region(current_user) = region_id);
5.3 数据脱敏与合规
openGauss 内置了数据脱敏 (Data Masking) 功能,可以在查询时对敏感数据(如身份证、手机号)进行动态脱敏,而无需修改源端数据。
-- 示例:为外表中的敏感字段应用脱敏函数
CREATE MASKING POLICY phone_masking_policy
ON orders_mysql(customer_phone)
USING (masking.default_masking(customer_phone));

六、行业案例延展:金融风控场景
在一个典型的金融风控场景中,数据可能分散在:
Oracle: 核心交易系统。
HBase: 用户画像标签。
Elasticsearch: 用户行为日志。
通过 openGauss 的 oracle_fdw、hbase_fdw 等,风控分析师可以在一个 SQL 查询中,实时地将用户的当前交易请求(来自 Kafka 流)、历史交易记录(来自 Oracle)、用户画像(来自 HBase)和近期行为(来自 ES)进行关联分析,构建一个高维度的实时风控模型,这在过去是难以想象的。
七、结论:openGauss,企业数据治理的坚实基石
数据孤岛是企业迈向数据驱动的巨大障碍。openGauss 凭借其:
- 强大的联邦查询能力 (FDW): 实现了对异构数据的无缝、高效、就地分析。
- 企业级的治理特性: 提供了统一的元数据、安全、权限和合规管控能力。
- 开放的生态协同: 与 openEuler、openLooKeng、Spark 等大数据组件无缝集成。
成功地从一个高性能的事务型数据库,演进为了企业统一数据分析底座的核心引擎。它不仅打破了数据的物理壁垒,更构建了一套有序、可控、安全的数据治理体系,为上层的 BI、Ad-hoc 查询乃至 AI/ML 应用,提供了坚实、可靠的数据地基,最终加速企业的数字化转型进程。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)