基于Rust实现本地文件内容统计工具
·
文章目录
一、项目介绍
1. 项目功能
该工具可递归遍历指定目录,统计目标文件的核心信息,支持自定义文件类型筛选,最终输出结构化统计结果。具体功能包括:
- 统计文件总数、代码总行数、空行数、注释行数(支持
//单行注释) - 按文件类型(如
.rs、.md、.txt)分类统计 - 支持忽略指定目录(如
node_modules、.git) - 输出简洁的文本报告或 JSON 格式报告(便于后续处理)
2. 技术栈
- 核心依赖:
std::fs(文件操作)、std::path(路径处理)、clap(命令行参数解析,简化参数处理逻辑) - 特性覆盖:Rust 模式匹配、错误处理(
Result类型)、迭代器、字符串处理、递归遍历
二、项目结构
file-stat-tool/
├── Cargo.toml # 依赖配置
└── src/
└── main.rs # 核心逻辑(参数解析、文件遍历、统计计算、报告生成)
三、完整代码实现
1. Cargo.toml(依赖配置)
[package]
name = "file-stat-tool"
version = "0.1.0"
edition = "2021"
description = "Rust 本地文件内容统计工具,支持多格式统计与自定义筛选"
[dependencies]
clap = { version = "4.5", features = ["derive"] } # 命令行参数解析库
serde = { version = "1.0", features = ["derive"] } # JSON 序列化支持
serde_json = "1.0" # JSON 格式处理
2. src/main.rs(核心逻辑)
use clap::Parser;
use serde::Serialize;
use std::collections::HashMap;
use std::fs;
use std::path::{Path, PathBuf};
// --------------------------
// 1. 数据结构定义
// --------------------------
/// 命令行参数结构体(通过 clap 自动解析)
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Cli {
/// 目标统计目录(必填)
#[arg(short, long, default_value = ".")]
dir: PathBuf,
/// 筛选文件类型(如 rs,md,txt,多个用逗号分隔)
#[arg(short, long, default_value = "rs,md,txt")]
ext: String,
/// 忽略目录(多个用逗号分隔,默认忽略 node_modules,.git,target)
#[arg(short, long, default_value = "node_modules,.git,target")]
ignore_dir: String,
/// 输出格式(text 或 json)
#[arg(short, long, default_value = "text")]
output: String,
}
/// 单个文件的统计结果
#[derive(Debug, Clone, Serialize)]
struct FileStat {
path: String, // 文件路径
total_lines: usize, // 总行数
empty_lines: usize, // 空行数
comment_lines: usize, // 注释行数(// 单行注释)
code_lines: usize, // 代码行数(总行数 - 空行数 - 注释行数)
}
/// 整体统计结果(按文件类型分类)
#[derive(Debug, Serialize)]
struct TotalStat {
total_files: usize, // 总文件数
total_lines: usize, // 总代码行数
by_ext: HashMap<String, Vec<FileStat>>, // 按文件类型分组的统计
ignore_dirs: Vec<String>, // 忽略的目录列表
target_dir: String, // 目标统计目录
}
// --------------------------
// 2. 核心工具函数
// --------------------------
/// 解析逗号分隔的字符串为向量(如 "rs,md" -> vec!["rs", "md"])
fn parse_comma_str(s: &str) -> Vec<String> {
s.split(',')
.map(|item| item.trim().to_lowercase())
.filter(|item| !item.is_empty())
.collect()
}
/// 判断文件是否为目标类型(匹配扩展名)
fn is_target_ext(path: &Path, target_exts: &[String]) -> bool {
path.extension()
.and_then(|ext| ext.to_str())
.map(|ext| target_exts.contains(&ext.to_lowercase()))
.unwrap_or(false)
}
/// 统计单个文件的内容(总行数、空行数、注释行数)
fn stat_single_file(path: &Path) -> Result<FileStat, String> {
// 读取文件内容(按 UTF-8 编码,兼容带 BOM 的情况)
let content = fs::read_to_string(path)
.map_err(|e| format!("读取文件失败:{}(路径:{})", e, path.display()))?;
let mut total_lines: usize = 0; // 明确指定类型为 usize
let mut empty_lines: usize = 0; // 明确指定类型为 usize
let mut comment_lines: usize = 0; // 明确指定类型为 usize
// 按行遍历统计
for line in content.split_inclusive(&['\n', '\r'][..]) {
total_lines += 1;
let trimmed_line = line.trim();
// 统计空行(修剪后为空)
if trimmed_line.is_empty() {
empty_lines += 1;
continue;
}
// 统计单行注释(以 // 开头,且前面无有效代码)
if trimmed_line.starts_with("//") {
comment_lines += 1;
}
}
// 计算代码行数(总行数 - 空行数 - 注释行数)
let code_lines = total_lines.saturating_sub(empty_lines).saturating_sub(comment_lines);
Ok(FileStat {
path: path.display().to_string(),
total_lines,
empty_lines,
comment_lines,
code_lines,
})
}
/// 递归遍历目录,统计所有目标文件
fn recursive_stat(
dir: &Path,
target_exts: &[String],
ignore_dirs: &[String],
stat_map: &mut HashMap<String, Vec<FileStat>>,
) -> Result<(), String> {
// 读取目录条目
let entries = fs::read_dir(dir)
.map_err(|e| format!("读取目录失败:{}(路径:{})", e, dir.display()))?;
for entry in entries {
let entry = entry.map_err(|e| format!("读取目录条目失败:{}", e))?;
let path = entry.path();
let metadata = entry.metadata()
.map_err(|e| format!("获取文件信息失败:{}(路径:{})", e, path.display()))?;
// 处理目录:判断是否需要忽略,否则递归遍历
if metadata.is_dir() {
if let Some(dir_name) = path.file_name().and_then(|n| n.to_str()) {
if ignore_dirs.contains(&dir_name.to_lowercase()) {
println!("⚠️ 忽略目录:{}", path.display());
continue;
}
}
recursive_stat(&path, target_exts, ignore_dirs, stat_map)?;
}
// 处理文件:判断是否为目标类型,否则跳过
else if metadata.is_file() && is_target_ext(&path, target_exts) {
match stat_single_file(&path) {
Ok(file_stat) => {
// 按文件扩展名分组存储
let ext = path.extension()
.and_then(|e| e.to_str())
.unwrap_or("unknown")
.to_lowercase();
stat_map.entry(ext).or_default().push(file_stat);
}
Err(e) => eprintln!("❌ 统计文件失败:{}", e), // 非致命错误,仅打印警告
}
}
}
Ok(())
}
/// 生成文本格式报告
fn generate_text_report(stat: &TotalStat) -> String {
let mut report = String::new();
// 1. 基础信息
report.push_str(&format!("📊 文件内容统计报告\n"));
report.push_str(&format!("目标目录:{}\n", stat.target_dir));
report.push_str(&format!("忽略目录:{}\n", stat.ignore_dirs.join(", ")));
report.push_str(&format!("总文件数:{} 个\n", stat.total_files));
report.push_str(&format!("总代码行数:{} 行\n", stat.total_lines));
report.push_str("-----------------------------------------\n");
// 2. 按文件类型分组统计
for (ext, file_stats) in &stat.by_ext {
let ext_files = file_stats.len();
let ext_total_lines: usize = file_stats.iter().map(|f| f.total_lines).sum();
let ext_code_lines: usize = file_stats.iter().map(|f| f.code_lines).sum();
report.push_str(&format!("\n【.{} 文件】(共 {} 个)\n", ext, ext_files));
report.push_str(&format!(" 总行数:{} 行\n", ext_total_lines));
report.push_str(&format!(" 总代码行数:{} 行\n", ext_code_lines));
// 3. 单个文件详情(仅显示前 5 个,避免报告过长)
let display_limit = std::cmp::min(5, file_stats.len());
for (i, file) in file_stats.iter().take(display_limit).enumerate() {
report.push_str(&format!(
" {}. {}:代码 {} 行 / 空行 {} 行 / 注释 {} 行\n",
i + 1,
file.path,
file.code_lines,
file.empty_lines,
file.comment_lines
));
}
if file_stats.len() > 5 {
report.push_str(&format!(" ... 还有 {} 个文件未显示\n", file_stats.len() - 5));
}
}
report
}
// --------------------------
// 3. 主函数(程序入口)
// --------------------------
fn main() {
// 1. 解析命令行参数
let cli = Cli::parse();
let target_exts = parse_comma_str(&cli.ext);
let ignore_dirs = parse_comma_str(&cli.ignore_dir);
let target_dir = cli.dir.canonicalize() // 转换为绝对路径
.map_err(|e| format!("获取绝对路径失败:{}", e))
.unwrap_or(cli.dir);
// 2. 校验目标目录
if !target_dir.exists() || !target_dir.is_dir() {
eprintln!("❌ 错误:目录不存在或不是有效目录:{}", target_dir.display());
std::process::exit(1);
}
// 3. 递归统计文件
let mut stat_map = HashMap::new();
if let Err(e) = recursive_stat(&target_dir, &target_exts, &ignore_dirs, &mut stat_map) {
eprintln!("❌ 统计过程出错:{}", e);
std::process::exit(1);
}
// 4. 计算整体统计结果
let total_files: usize = stat_map.values().map(|v| v.len()).sum();
let total_lines: usize = stat_map.values()
.flat_map(|v| v.iter().map(|f| f.code_lines))
.sum();
let total_stat = TotalStat {
total_files,
total_lines,
by_ext: stat_map,
ignore_dirs: ignore_dirs.into_iter().collect(),
target_dir: target_dir.display().to_string(),
};
// 5. 生成并输出报告
match cli.output.as_str() {
"json" => {
let json_report = serde_json::to_string_pretty(&total_stat)
.map_err(|e| format!("生成 JSON 报告失败:{}", e))
.unwrap_or_else(|e| {
eprintln!("❌ 生成 JSON 失败:{}", e);
std::process::exit(1);
});
println!("{}", json_report);
}
"text" | _ => {
let text_report = generate_text_report(&total_stat);
println!("{}", text_report);
}
}
}
四、项目使用与测试指南
1. 编译与运行
# 1. 创建项目并进入目录
cargo new file-stat-tool
cd file-stat-tool
# 2. 替换 Cargo.toml 和 src/main.rs 内容(如上)
# 3. 编译项目(生成可执行文件)
cargo build --release # release 模式优化性能,生成的文件在 target/release/ 下
# 4. 基础使用(统计当前目录的 .rs/.md/.txt 文件)
cargo run --release
# 5. 自定义参数示例
# 统计 src 目录的 .rs 文件,忽略 logs 目录,输出 JSON 格式
cargo run --release -- --dir src --ext rs --ignore-dir logs --output json
2. 测试实例准备(创建测试文件)
在项目根目录执行以下命令,创建用于测试的样例文件:
# 重建 Rust 测试文件
@'
// 这是一个 Rust 测试文件
fn main() {
println!("Hello, Rust!"); // 打印信息
}
'@ | Out-File -FilePath test_dir/test.rs -Encoding utf8
# 重建 Markdown 测试文件
@'
# Rust 统计工具测试
这是一个测试用的 Markdown 文件。
- 列表项 1
- 列表项 2
'@ | Out-File -FilePath test_dir/test.md -Encoding utf8
# 重建文本测试文件
@'
这是一个文本文件
包含空行
和注释行 // 这行是注释
'@ | Out-File -FilePath test_dir/test.txt -Encoding utf8
3. 执行测试命令
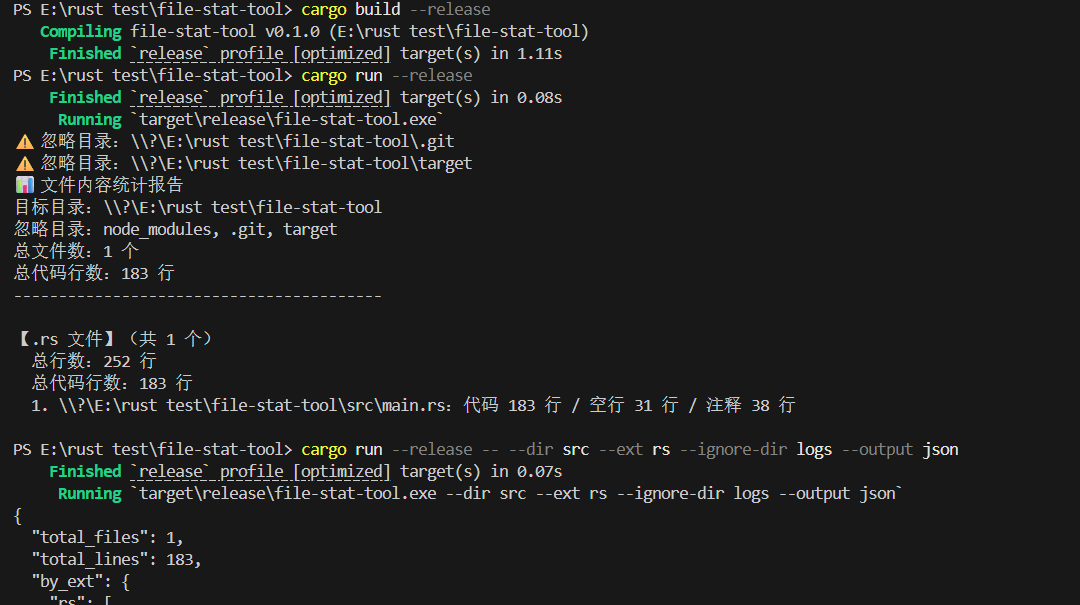
1. 基础测试(统计所有默认类型文件)
cargo run --release
预期输出
2. 自定义筛选测试(仅统计 Rust 文件,输出 JSON 格式)
cargo run --release -- --ext rs --output json
预期输出(JSON 格式,部分内容):
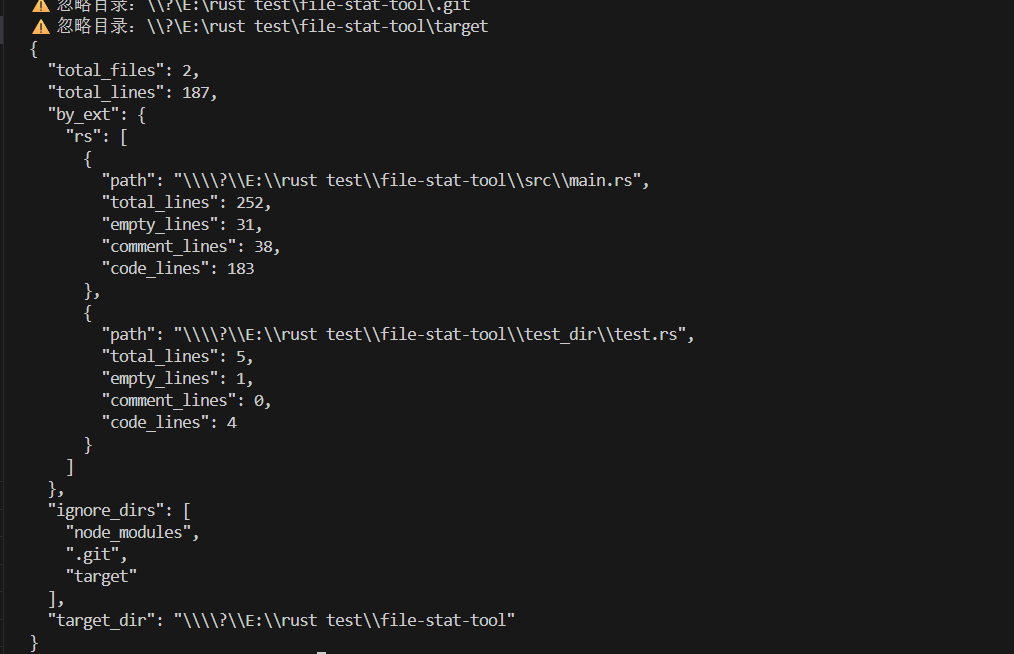
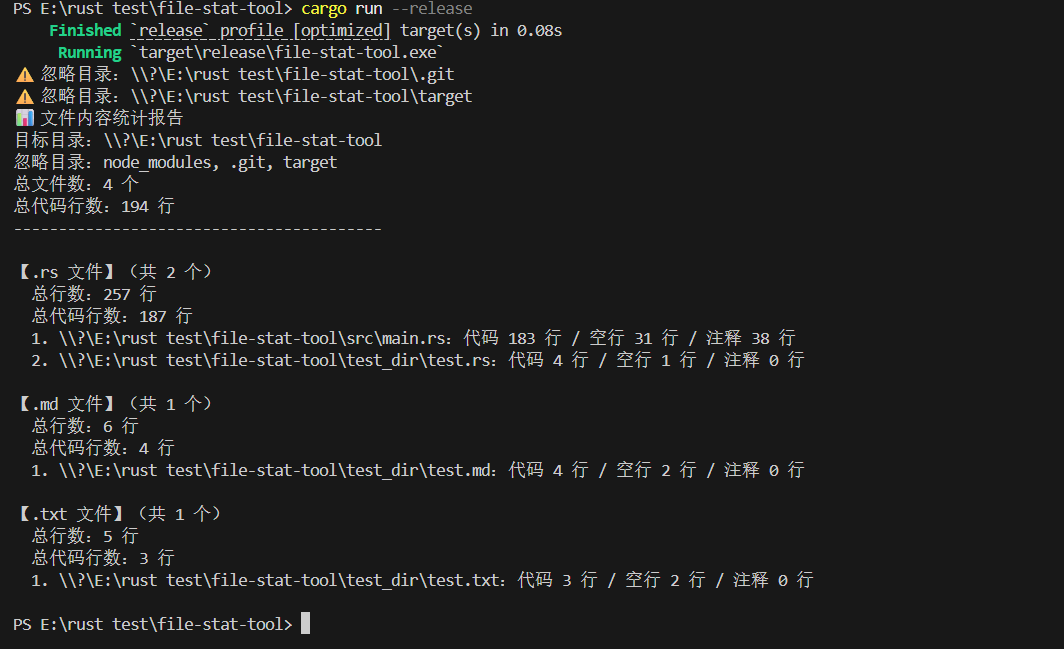
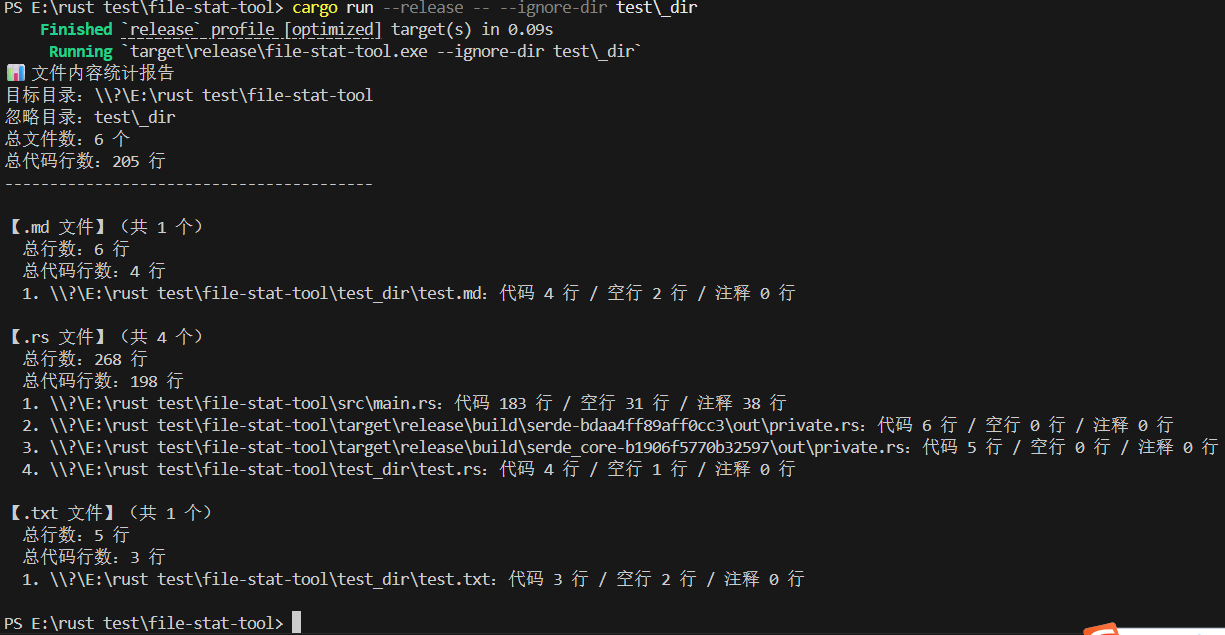
3. 忽略目录测试(忽略 test_dir 目录)
cargo run --release -- --ignore-dir test\_dir
预期输出:
4. 测试说明
- 测试文件涵盖了代码行、空行、单行注释的典型场景,验证工具的统计准确性;
- 不同命令参数的测试可验证文件类型筛选、输出格式切换、目录忽略等功能的完整性;
- 若输出与预期一致,说明工具核心逻辑正常运行。
五、知识点和项目总结
- 错误处理:通过
Result类型统一处理文件读取、目录遍历等可能的错误,避免程序崩溃; - 命令行参数:使用
clap库简化参数解析,支持自定义默认值和格式校验; - 集合操作:用
HashMap按文件类型分组统计,体现 Rust 集合的高效性; - 递归遍历:实现目录递归遍历,处理嵌套目录场景;
- 序列化:用
serde和serde_json实现 JSON 格式输出,满足结构化数据需求。
本地文件内容统计工具是一款轻量高效的命令行工具,支持批量扫描指定文件或目录下的文本文件,快速统计字符数(含 / 不含空格)、单词数、行数、高频词汇 TOP N 等核心指标,适配 TXT/Markdown/ 代码文件等多种格式,依托 Rust 安全内存管理与高效 IO 特性,兼顾大文件处理性能与跨平台兼容性,可满足日常文档整理、代码统计、内容分析等实用需求。
想了解更多关于Rust语言的知识及应用,可前往旋武开源社区(https://xuanwu.openatom.cn/),了解更多资讯~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)