Kubernetes(一):安装与集群构建
本文详细介绍了Kubernetes v1.34.1集群的安装与配置过程。主要内容包括:环境准备(服务器配置、网段规划)、安装Containerd容器运行时和Kubernetes软件(kubeadm、kubectl、kubelet)、构建集群(初始化控制平面、加入工作节点)、部署Calico网络插件等关键步骤。特别强调了使用最新版本、规范安装的重要性,并提供了国内镜像源配置、节点DNS设置等实用技巧
目录
序:
Kubernetes 简称K8s,其Cluster集群由控制平面(也称为Control Plane主控或者主节点)和一个或多个Node工作节点共同组成,Kubernetes Cluster集群结构如下两张图(均来自官网):
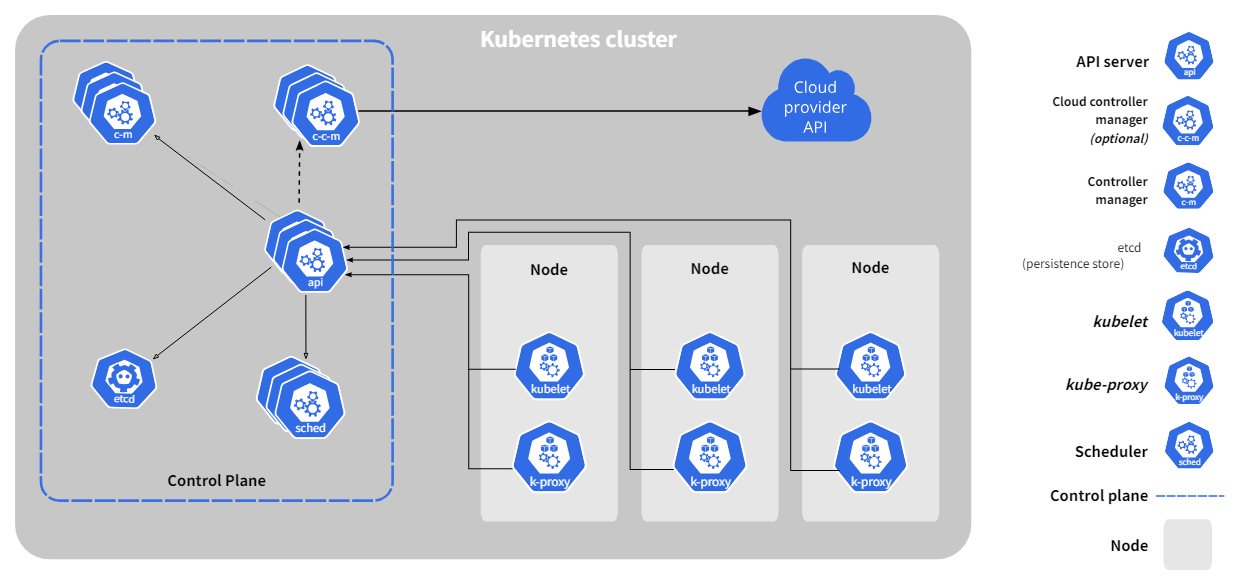
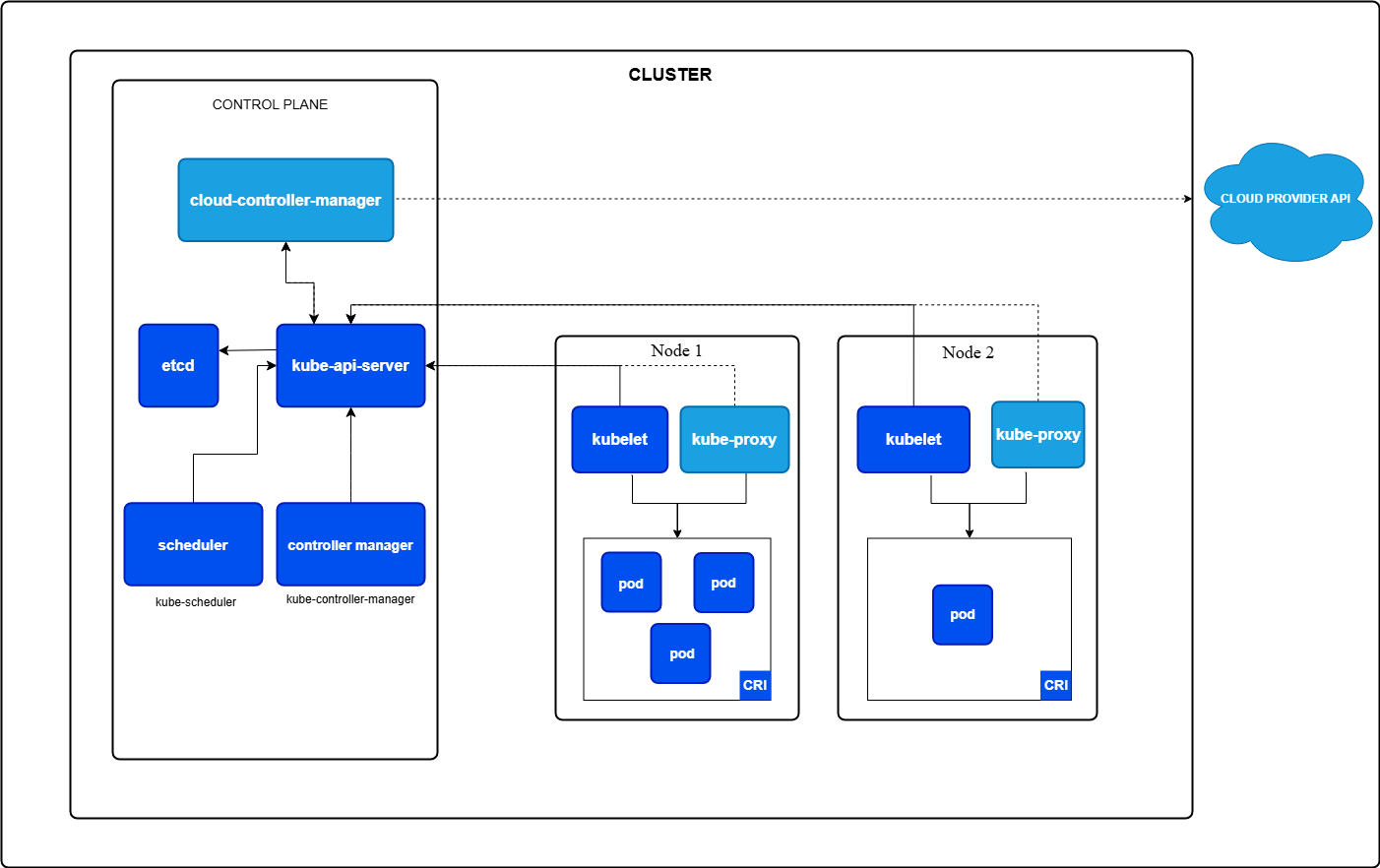
由于网上文章存在安装Kubernetes不够规范情况,例如有些文章作者安装了不必要的docker ce导致与其存在依赖耦合(主要是作者相关概念不清),或者有些文章所用Kubernetes版本老旧;或者命令选项没有参考最新的官网文档建议而不规范。
本文以2025年12月最新发布Kubernetes v1.35.0为例,完整展示安装与集群构建过程。
一、环境准备
1、服务器准备
| 机器实际IP及hostname | 硬件配置及操作系统 | 机器用途 | 备注 |
|---|---|---|---|
|
192.168.43.221 k8s-cp1 |
CPU2核;内存3GB CentOS 7.9 64bit 内核:已升至5.4.278 |
Kubernetes Control控制平面 |
也称主控(之前称Master主节点) 最低要求:CPU≥2核,MEM≥2GB 生产环境推荐3、5、7台等奇数 |
|
192.168.43.241 k8s-wn01 |
CPU1核;内存3GB CentOS 7.9 64bit 内核:已升至5.4.278 |
Kubernetes Node工作节点 |
Work Node工作节点也称为Node节点 最低要求:CPU≥1核,MEM≥2GB |
|
192.168.43.242 k8s-wn02 |
CPU1核;内存3GB CentOS 7.9 64bit 内核:已升至5.4.278 |
Kubernetes Node工作节点 |
Work Node工作节点也称为Node节点 最低要求:CPU≥1核,MEM≥2GB |
注①:Linux内核升级方法参见:CentOS Linux升级内核kernel方法及启用cgroup v2
注②:务必确保IP、hostname、MAC地址、/sys/class/dmi/id/product_uuid值在各机器均是不同的。
2、网段规划
| 网段 | 用途 | 备注 |
|---|---|---|
| 192.168.43.0/24 |
集群Cluster节点间网段 Kubernetes的Control控制平面与Node工作节点之间的通讯网段 |
各个节点机器实际IP范围 |
| 10.244.0.0/16 |
Pod网段 Kubernetes的Pod地址段 |
在kubeadm init命令中通过选项--pod-network-cidr设定。 |
| 172.17.0.0/16 |
Service网段 Kubernetes的Service的虚拟IP段 |
在kubeadm init命令中通过选项--service-cidr设定,该选项默认"10.96.0.0/12" |
二、安装Kubernetes软件
1、操作系统设置
1、检查各Linux机器的IP地址与主机名是否正确(所有机器均需执行)
#检查操作系统
hostname; hostname -i
#若hostname不正确,可以通过以下命令设置。注意:每个节点的名字须不同
sudo hostnamectl set-hostname k8s-cp12、(推荐)在各节点机器上/etc/hosts文件中增加Kubernetes集群的各节点信息(所有机器均需执行)
192.168.43.221 k8s-cp1
192.168.43.241 k8s-wn01
192.168.43.242 k8s-wn02如不配置以上/etc/hosts,Kubernetes命令执行时有可能会报: [WARNING Hostname]: hostname "xxx" could not be reached。该警告不影响使用。
2、关闭SELinux(所有机器均需执行)
#将SELinux设置为permissive模式(相当于将其禁用),但重启后会恢复原状
sudo setenforce 0
#永久关闭
sudo sed -i 's/^SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config3、关闭Linux防火墙(所有机器均需执行)
#立即关闭Linux防火墙,并禁止下次开启自启
sudo systemctl disable --now firewalld4、禁用Linux的swap交换区(所有机器均需执行)
因为:若节点开启了swap交换区,默认情况kubelet会启动失败(如希望保持swap开启,则可通过在kubelet 配置文件中添加 failSwapOn: false,或在命令行选项--fail-swap-on设置为false 来为了允许 Pod 使用交换区,避免kubelet启动失败)。
#第一步:永久禁用swap交换区(重启后生效)。以root用户编辑vim /etc/fstab文件。将带swap的那行进行注释
/dev/mapper/vg_centos-swap swap swap defaults 0 0
#第二步:立即禁用swap交换区(本次生效)
sudo swapoff -a
#第三步:确认是否已无swap交换区
free -m5、(可选)配置时间同步(所有机器均需执行)
#手工时间同步一次。 也可另配置为自动同步
sudo ntpdate ntp.aliyun.com6、查看当前Linux使用cgroup版本(所有机器均需执行)
cgroup是Linux内核提供的重要机制。在Linux中,各类容器化技术均使用cgroup实现资源限制。 cgroup有两个版本v1和v2。
#查看当前操作系统内核支持的cgroup版本范围
# 若输出为包含“cgroup”字样的一行,则表示只支持cgroup v1
# 若输出为既又“cgroup”和“cgroup2”字样的两行,则表示既支持cgroup v1也支持v2
grep cgroup /proc/filesystems
#查看当前已挂载的cgroup文件系统
# 若输出仅包括tmpfs、cgroup,则表示已挂载v1版文件系统。
# 若输出还包括cgroup2,则表示已挂载v2版文件系统。
mount | grep cgroup
#查看操作内核当前正使用的cgroup版本
# 若输出为tmpfs,则表示当前正使用v1版。
# 若输出为cgroup2fs,则表示当前正使用v2版。
stat -fc %T /sys/fs/cgroup/7、将当前Linux启用cgroup v2版本(所有机器均需执行)
Kubernetes v1.34及以下,对cgroup的v1和v2均能适配,因此v1和v2任选一种即可。对于cgroup v1时,部分Kubernetes运行会提示建议please migrate to cgroups v2,可忽略警告提示。 但推荐使用cgroup v2。
Kubernetes v1.35开始,只不再支持cgroup v1,只支持cgroup v2。因此必须启用cgroup v2。
启用cgroup v2方法参见:CentOS Linux升级内核kernel方法及启用cgroup v2
2、安装Containerd容器运行时
Kubernetes自身的软件包不包含容器运行时。因此需要提前安装容器运行时。容器运行时有多款具体实现,通常常选择Containerd作为容器运行时。本文选择Containerd,安装containerd可有两类方式:
- (推荐)新方式:无需docker,直接安装containerd容器运行时;
- (已作废,不推荐)老方式:
通过安装Docker Engine和cri-dockerd垫片
下文以直接安装containerd容器运行时为例进行说明。对于需运行containerd的机器需安装三个组件:containerd、runc、CNI plugins。其中containerd是高级运行时、runc是低级运行时、CNI plugins是容器网络接口插件。
具体安装方式:
- 通过手工方式。 从官网:https://containerd.io/downloads/ 直接下载tar.gz直接安装。可以选择版本,可依次安装containerd、runc、CNI plugins。 具体见官网安装说明:https://github.com/containerd/containerd/blob/main/docs/getting-started.md
- 通过yum repo仓安装。通过yum repo仓安装containerd.io包,该containerd.io包不是containerd官方提供的,而是由Docker制作的DEB/RPM包,通常版本较低。该containerd.io包含有containerd本身及runc,但不含CNI plugin。
本文采用yum repo仓安装containerd.io包(containerd、runc),然后后文再通过kubectl apply方式安装CNI plugin。
1、配置安装containerd需的yum repo仓(所有机器均需执行)
# containerd.io包是由Docker制作的DEB/RPM包,因此repo仓使用docker-ce的仓
# 因官方提供https://download.docker.com/linux/centos/docker-ce.repo的比较慢,因此以下改配置为国内阿里源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo2、安装containerd及runc,并查看结果(所有机器均需执行)
#安装containerd(会自动安装runc)
yum install -y containerd
#查看安装结果
containerd --help
runc --help3、生成并修改containerd配置文件(所有机器均需执行)
#在安装containerd时会自动生成/etc/containerd/config.toml配置文件
#但安装时自动生成该文件中:配置了disabled_plugins = ["cri"],禁用cri方式访问,使得Kubernetes无法访问该运行时。
#因此通过以下命令重新生成配置(命令生成的配置不禁用cri)并覆盖该文件
containerd config default > /etc/containerd/config.toml3、containerd配置文件的国内源(所有机器均需执行)
在/etc/containerd/config.toml配置文件中找到sandbox_image = "registry.k8s.io/pause:3.6"。因国内无法访问所以需要修改为国内源,而且高Kubernetes版本推荐使用高版本所以提高版本。修改该行内容后结果如下:
| sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.10.1" |
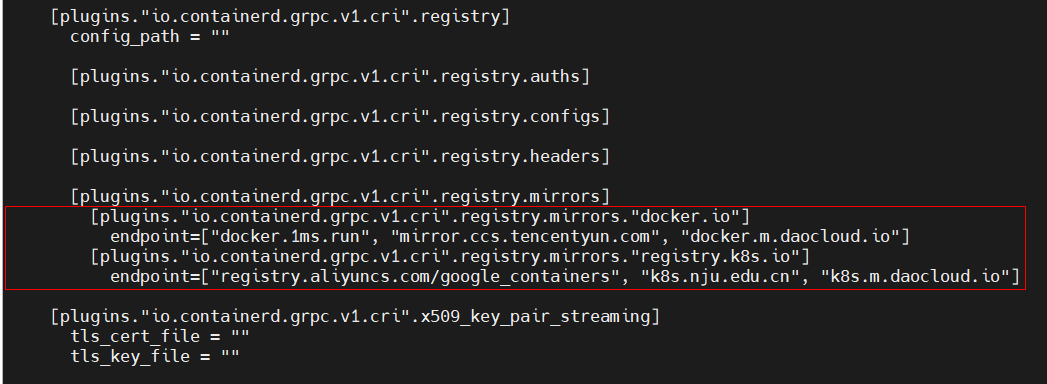
在/etc/containerd/config.toml配置文件中搜索plugins."io.containerd.grpc.v1.cri".registry.mirrors并在这行内容下,增加四行国内源mirrors配置:
|
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"] |
增加四行配置后的结果如下红框(注意toml文件格式,每行前必须是空格,否则无法解析):
4、启动containerd容器运行时(所有机器均需执行)
#立即运行容器运行时,并允许下次开启自启
systemctl enable --now containerd
#检查启动结果,应当是“active (running)”。
#若不是此状态,则通过命令sudo journalctl -u containerd查看启动日志定位原因
systemctl status containerd

3、安装Kubernetes软件
Kubernetes的Control控制平面与各个Node工作节点共同组成Kubernetes集群。Kubernetes主要有三类软件包:
| 软件包 | 用途简介 | 安装目标机器 |
|---|---|---|
kubectl |
用于Kubernetes各个资源管理和控制,功能非常丰富。 是日常操作的主要工具 |
仅控制平面节点 |
kubelet |
它作为 “节点代理”部署在每个工作节点上。 在集群中每个工作节点上用来启动 Pod 和容器等 |
各节点均安装 |
kubeadm |
一个便捷的集群构建工具。 例如:初始化控制平面、节点并加入集群、升级Kubernetes版本等 |
各节点均安装 |
注:也可以每台机器(无论控制平面和工作节点)都安装以上三类软件包。
1、添加 Kubernetes 的yum仓(所有机器均需执行)
# 此操作会覆盖/etc/yum.repos.d/kubernetes.repo中现存的所有配置
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.35/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.35/rpm/repodata/repomd.xml.key
EOF特别注意:官网文档提供yum仓repo配置文件中还有exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni。 若repo文件中存在此设置,则后续在执行yum命令行时则必须带上--disableexcludes=kubernetes选项。
以上repo配置中,已去掉exclude设置。
2、查看kubeadm可用版本列表:
sudo yum list --showduplicates --disableexcludes=kubernetes | grep kubeadm3、在Control控制平面节点上,安装 kubeadm、kubectl和kubelet,并启用 kubelet 以确保它随Linux自动启动 :
sudo yum install -y kubeadm kubectl kubelet --disableexcludes=kubernetes
#安装完毕后,查看软件版本号
kubeadm version
kubectl version
kubelet --version
#立即运行kubelet,并允许下次开启自启
sudo systemctl enable --now kubelet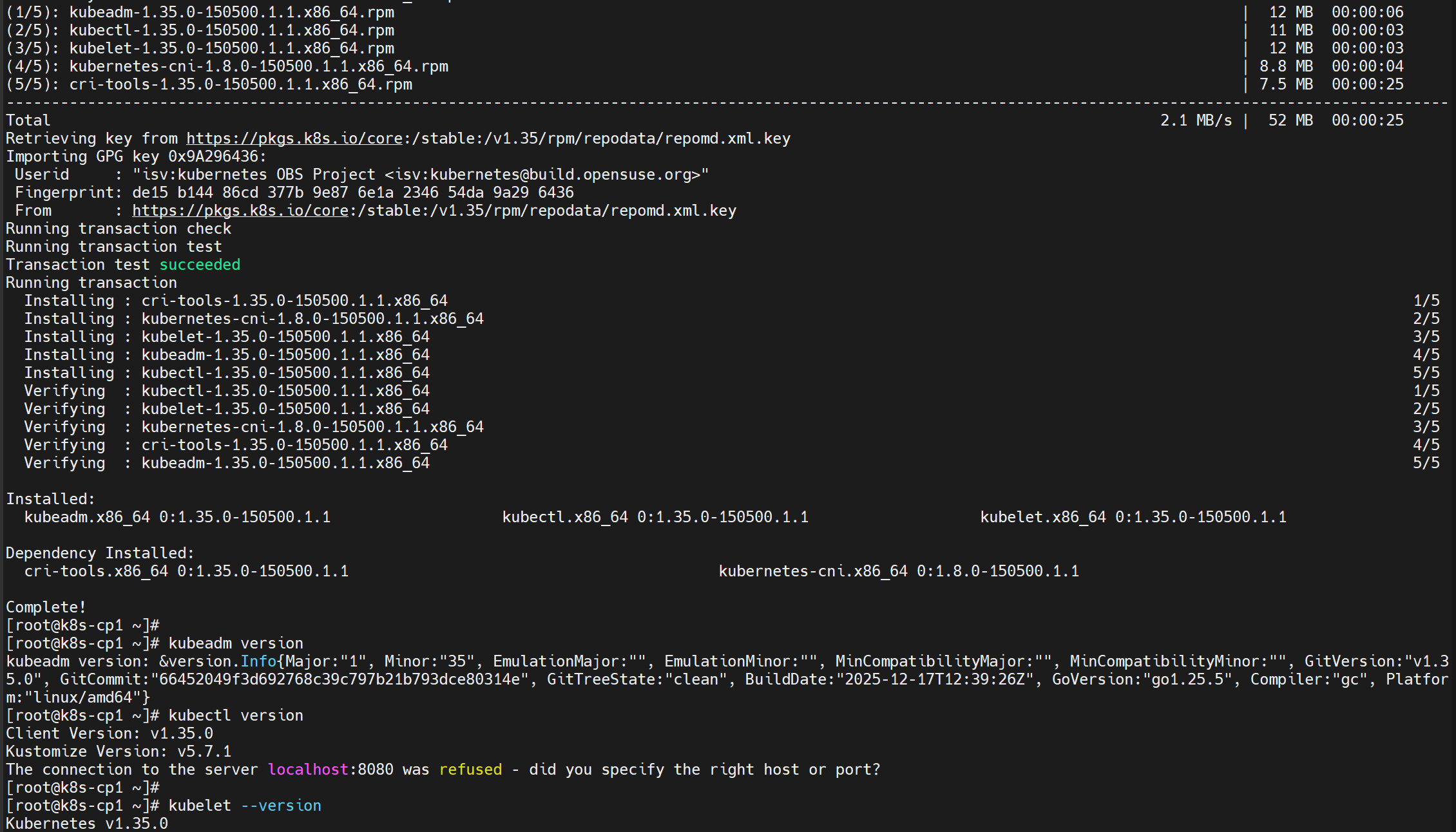
注:kubelet 现在每隔几秒就会重启,因为它陷入了一个等待 kubeadm 指令的死循环。通过命令journalctl -xefu kubelet查看kubelet服务日志,此时会报:读取kubelet的config.yaml文件错误,这是正常的,待本节点加入集群后就不会再报此错误。
4、在各个Node工作节点上,安装 kubeadm 和 kubelet,并启用 kubelet 以确保它随Linux自动启动(在两台工作节点机器上均需执行):
sudo yum install -y kubeadm kubelet --disableexcludes=kubernetes
#安装完毕后,查看软件版本号
kubeadm version
kubelet --version
#立即运行kubelet,并允许下次开启自启
sudo systemctl enable --now kubelet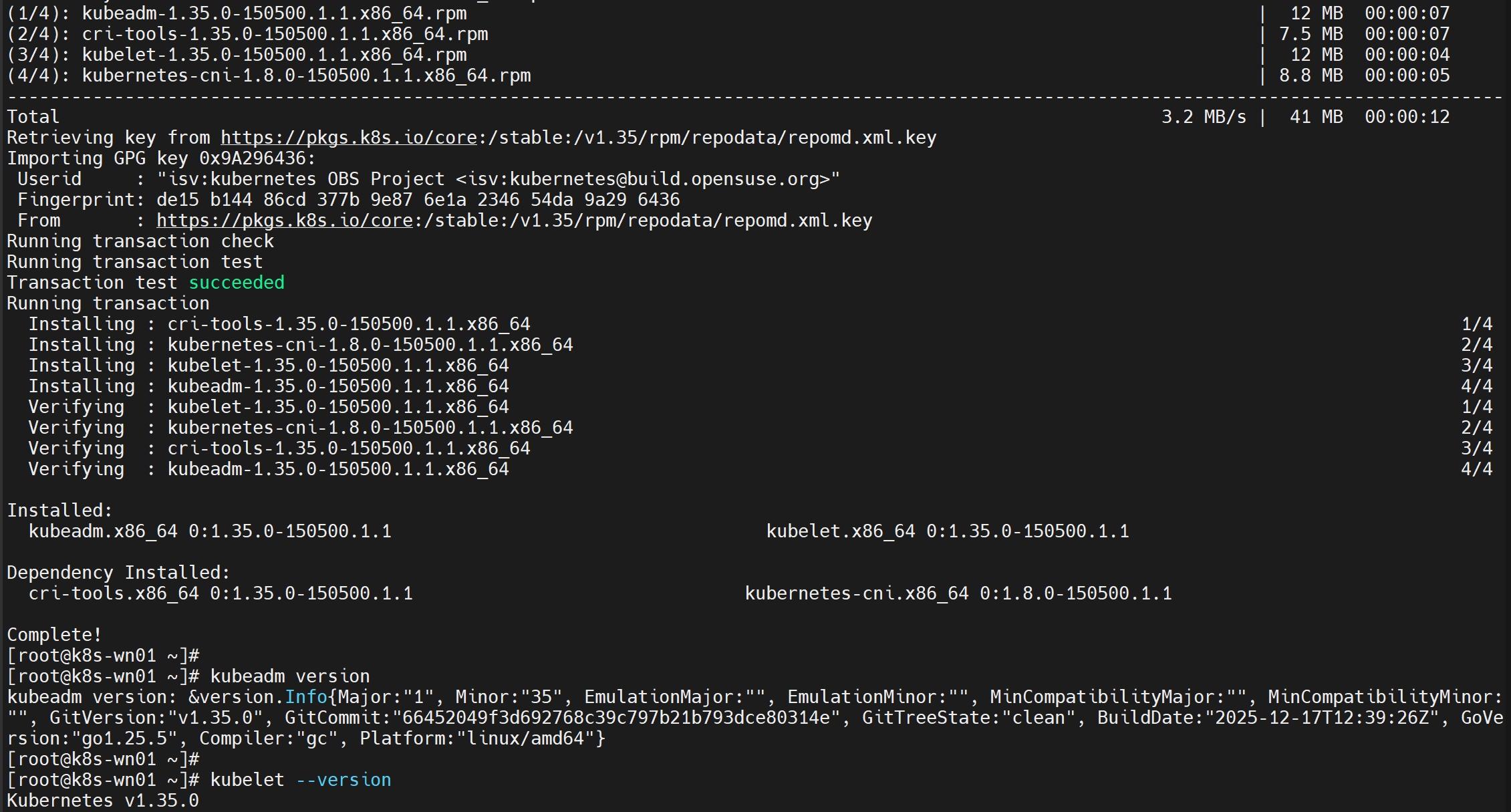
注:kubelet 现在每隔几秒就会重启,因为它陷入了一个等待 kubeadm 指令的死循环。通过命令journalctl -xefu kubelet查看kubelet服务日志,此时会报:读取kubelet的config.yaml文件错误,这是正常的,待本节点加入集群后就不会再报此错误。
三、构建Kubernetes集群
1、Control Plane控制平面
通过kubeadm命令构建集群,kubeadm其他常见功能:
- kubeadm config print init-defaults 输出默认的init配置,可供kubeadm init命令使用
- kubeadm config images list 列出kubeadm init控制平面时所需image。可通过--image-repository指定源仓,--kubernetes-version指定特定的Kubernetes版本(既Kubernetes版本对应的image)
- kubeadm config images pull 将kubeadm init控制平面时所需image拉取到本地。可通过--image-repository指定源仓,--kubernetes-version指定特定的Kubernetes版本(既Kubernetes版本对应的image)
- kubeadm init 初始化控制平面
- kubeadm join 将新机器已工作节点身份加入到控制平面,共同作为集群
- kubeadm reset 对已init或join过的当前节点进行重置,以便重新init或join。
1、在Kubernetes的Control控制平面上,执行初始化Kubernetes 控制平面节点:
# 初始化控制平面
# --apiserver-advertise-address:API服务器所公布的其正在监听的IP地址。既控制平面节点IP。
# --control-plane-endpoint:适合控制平面有多个节点场景,指定控制平面的负载均衡器IP地址或DNS名称。
# --image-repository:拉取kubeadm init控制平面时所需image的源仓。默认值:"registry.k8s.io"。若中国无法访问时才需指定为国内源(也可先通过kubeadm config images pull提前拉取至本地)。
# --kubernetes-version:为控制平面选择特定的Kubernetes版本(既Kubernetes版本对应image)。默认值:"stable-1"
# --pod-network-cidr: 指定Pod网段。如果设置了这个参数,控制平面将会为每一个工作节点自动分配CIDR,以对工作节点上Pod分配IP。
# --service-cidr:指定Service网段,Service的虚拟IP段。默认值:"10.96.0.0/12"
# --service-dns-domain:服务的根域名既Kubernetes集群的域名。默认值:"cluster.local"
# --cri-socket:要连接的CRI Unix套接字的路径。如果为空,则kubeadm将尝试自动检测此值;仅当安装了多个CRI或具有非标准CRI套接字时,才显示通过此选项指定
kubeadm init \
--apiserver-advertise-address=192.168.43.221 \
--image-repository=registry.aliyuncs.com/google_containers \
--kubernetes-version=v1.35.0 \
--pod-network-cidr=10.244.0.0/16 \
--service-cidr=172.17.0.0/16出现内容中含有“Your Kubernetes control-plane has initialized successfully!”这句话,则表示初始化成功:
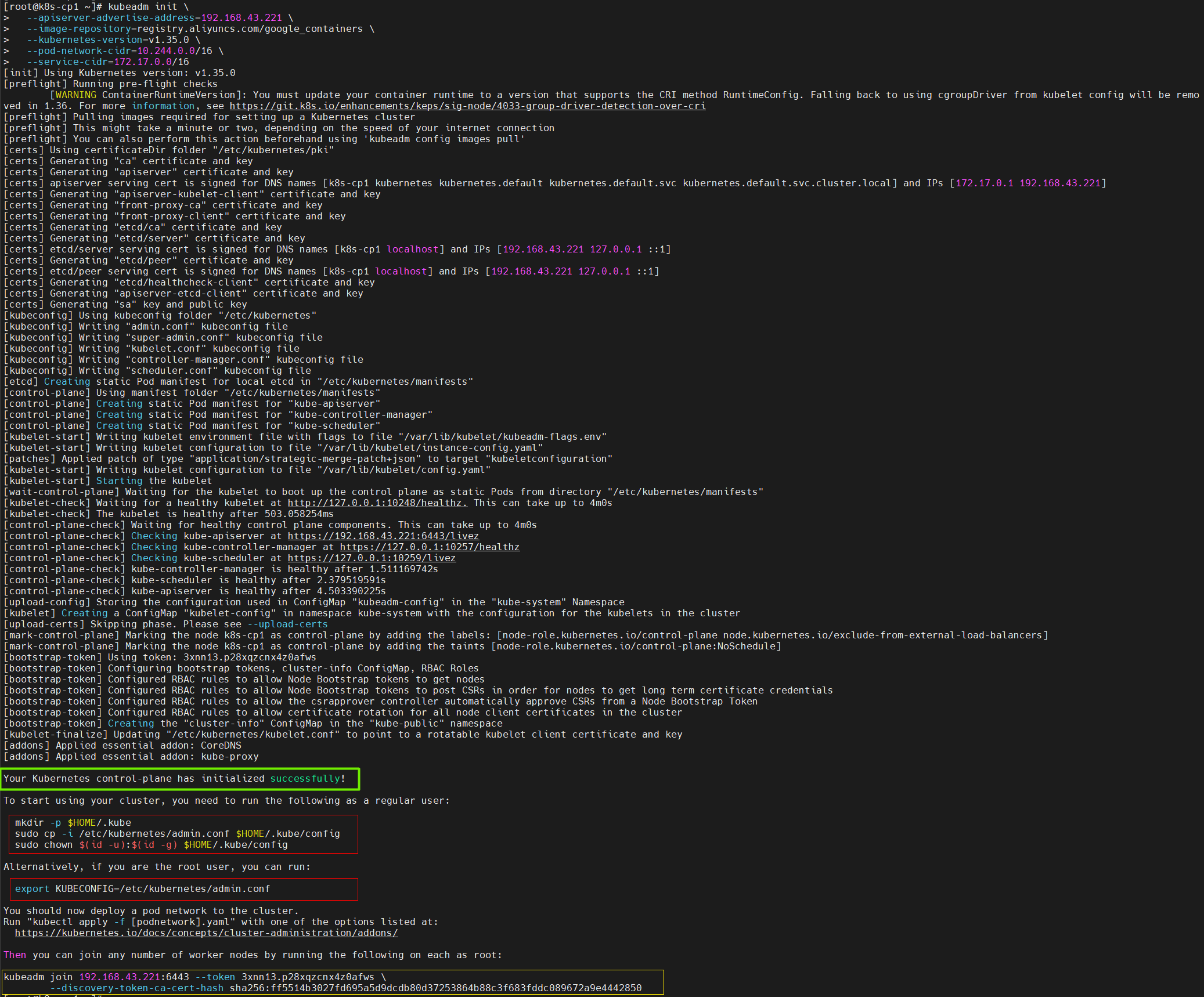
注:若希望再次打印join命令。可在Kubernetes的Control控制平面上执行:kubeadm token create --print-join-command
2、在Kubernetes的Control控制平面上,根据初始化控制平面时输出日志的提示命令执行:
# 场景A:在控制平面节点上,若需普通用户也可以执行kubernetes相关命令。
# 则以该普通用户执行以下命令:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 场景B:在控制平面节点上,需以root用户执行kubernetes相关命令。
# 则以root用户执行以下命令:
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
执行完毕后,才能成功使用例如kubectl get nodes等命令。
备注:以上init初始化会自动将控制平面节点以ROLES=control-plane的身份加入至集群中,因此,初始化后在控制平面节点机器上通过命令journalctl -xefu kubelet查看kubelet服务日志:不再报读取kubelet的config.yaml文件错误。
3、(强烈推荐)配置命令行自动补全,便于日常操作:
# 利用kubectl completion生成Shell补全脚本内容,加载至用户Shell环境,实现自动补全
echo "source <(kubectl completion bash)" >> ~/.bashrc
source ~/.bashrc2、Node工作节点
4、在各个Node工作节点上执行以下命令,根据初始化控制平面时的输出日志的提示的命令,以root用户在工作节点上分别执行,将其加入至集群中(在两台工作节点机器上执行):
# 此命令来源于init控制平面时的输出日志(若希望再次生成join命令。可在Kubernetes的Control控制平面上执行:kubeadm token create --print-join-command)
# join默认以工作节点身份加入集群。如指定选项--control-plane则表示以控制平面身份加入集群
# 以root用户,在工作节点上分别执行:
kubeadm join 192.168.43.221:6443 --token 3xnn13.p28xqzcnx4z0afws \
--discovery-token-ca-cert-hash sha256:ff5514b3027fd695a5d9dcdb80d37253864b88c3f683fddc089672a9e4442850
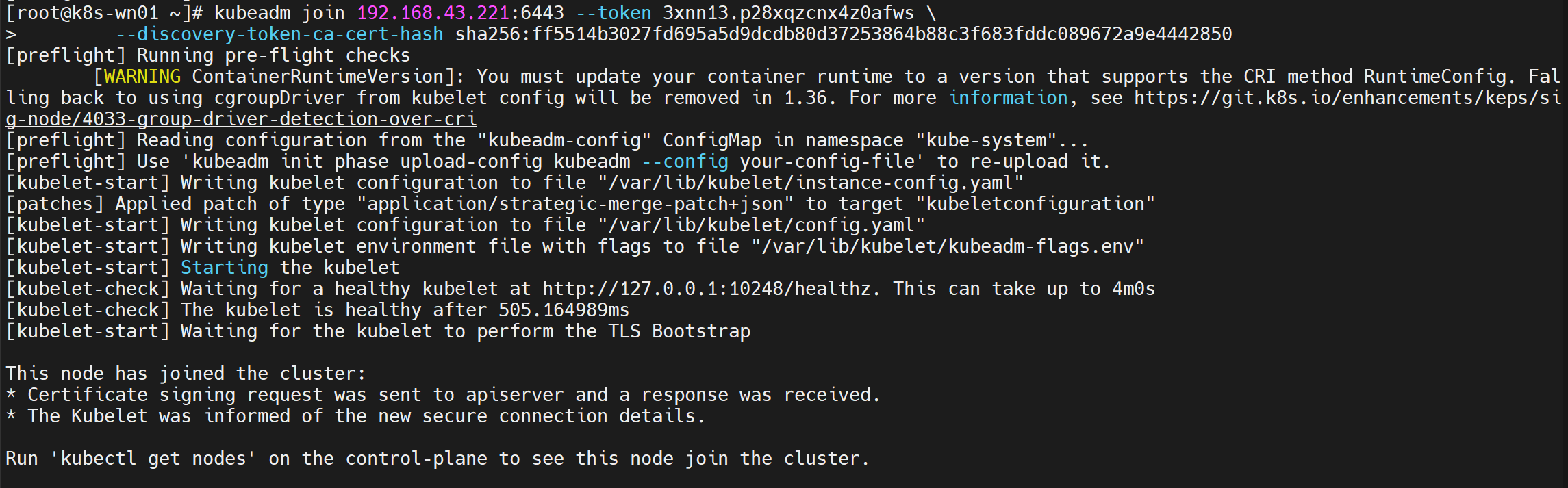
5、在Kubernetes的Control控制平面上,执行以下命令获取集群种当前各节点信息:
# 查看工作节点。其中-o选项指定wide,以显示更多信息列
kubectl get nodes -o wide
# 查看集群当前已有的资源对象
kubectl get all -A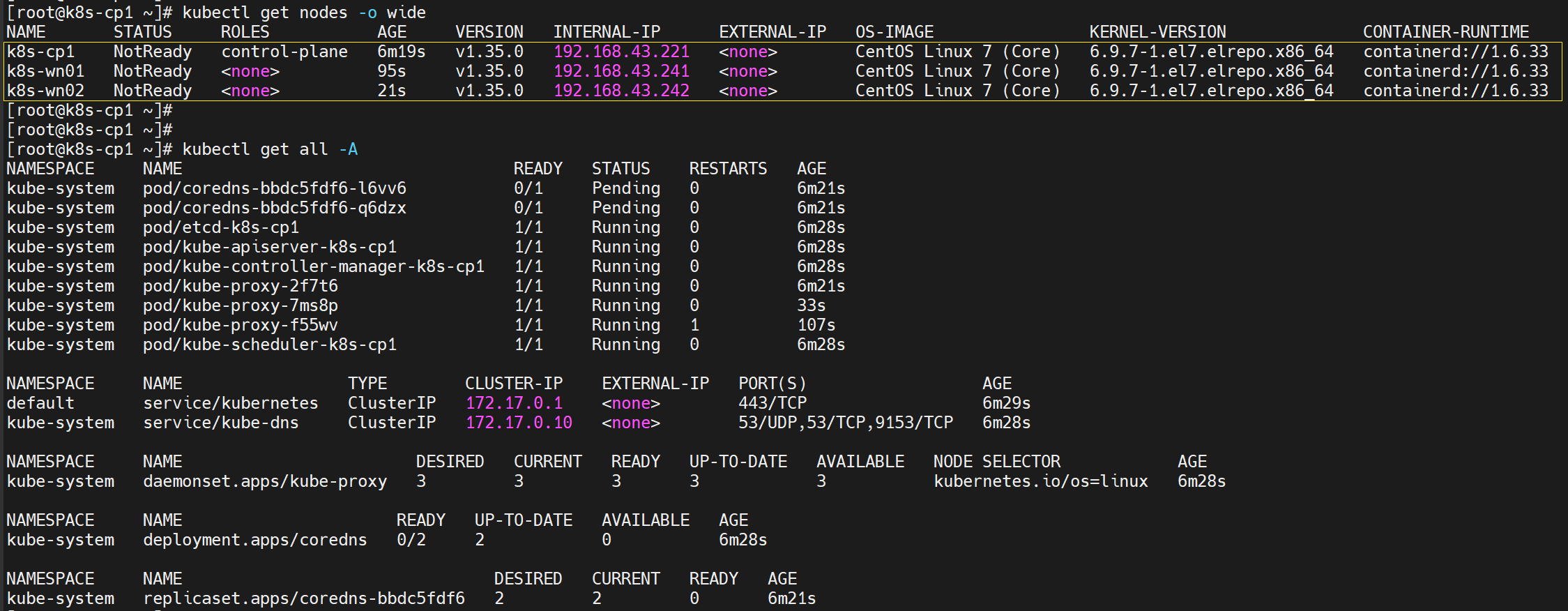
注意:此时集群已经建立完毕,并能看到各个节点。但各节点STATUS的为NotReady。因为Kubernetes不会自动安装CNI网络插件,且在前文安装Containerd时也未安装CNI插件。此时通过kubeadm构建的集群目前还不具备网络功能。在安装CNI网络插件之前,任何Pod(包括Kubernetes自带的CoreDNS)都无法正常工作。
3、部署CNI网络插件Calico
Container Network Interface (CNI)主要用于容器之间的网络通信(对于Kubernetes则为Pod之间网络通信)。由于前文还未CNI插件,所以需要安装。CNI有多种实现提供者,例如Flannel、Calico等。由于Calico比较出色,功能丰富,使用广泛。因此这里选择Calico作为CNI网络插件。
Calico是一个基于BGP的纯三层的网络方案,Calico在每个工作节点上利用Linux Kernel实现了一个高效的vRouter来负责数据转发。其官方文档:https://docs.tigera.io/calico/latest/about/
安装Calico的方式有多种:Operator方式、Manifests方式(官网文档网页中目录子标题Installing on on-premises deployments)、helm方式等,任选一种即可。 下面以Manifest方式为例进行安装过程说明。
1、在Kubernetes的Control控制平面上,下载清单文件calico.yaml,并将文件中镜像源改为国内源:
#下载清单文件
curl -O https://raw.githubusercontent.com/projectcalico/calico/v3.31.3/manifests/calico.yaml
#将清单文件中默认的镜像源修改为国内源(若该国内源不行,则换其他源)
sed -i 's/docker.io/docker.m.daocloud.io/' calico.yaml2、在Kubernetes的Control控制平面上,编辑清单文件vim calico.yaml,将其中CALICO_IPV4POOL_CIDR配置注释放开,且该网段值需要Kubernetes集群的pod-network-cid网段保持一致,修改后如下图:

Calico的配置项CALICO_IPV4POOL_CIDR表示可分配给Pod的IPv4的总池范围,在这个总池范围中,Calico会再划分为子网段(pool block),以便于确定各工作节点上可分配的Pod IP范围。Calico划分子网段(pool block)的默认掩码如下(分为IPv4和IPv6):
- IPv4 (/26) 既每个工作节点上的各个Pod的IPv4掩码为/26。对于本例的中IPv4的总池范围为10.244.0.0/16,则默认情况下:①每个工作节点上最多可分配Pod IP数为 2^6=64个(实际应该再减去2,既62个可用),②最多支持2^10=1024个子网段,在本例中最多可有1024个工作节点。
- IPv6 (/122) 既每个节点上的多个Pod的IPv6掩码为/122。
若希望调整Calico划分默认网段掩码,可在calico.yaml文件中通过增加CALICO_IPV4POOL_BLOCK_SIZE设置掩码。
3、在Kubernetes的Control控制平面上,apply清单文件calico.yaml:
kubectl apply -f calico.yaml注:如果重装Calico,则需先kubectl delete -f calico.yaml 然后清理环境:sudo rm -rf /etc/cni/net.d /var/lib/calico
执行完apply会自动下载容器镜像进行部署,约几分钟后,可以看到以下pods情况,不仅新部署了calico开头的Pod,而且Kubernetes自带coredns也已从最初的Pending变为Running状态。

注意:其中Pod名字以calico-node-XXX开头的,其kind=DaemonSet,所以每个节点有且只有一个。
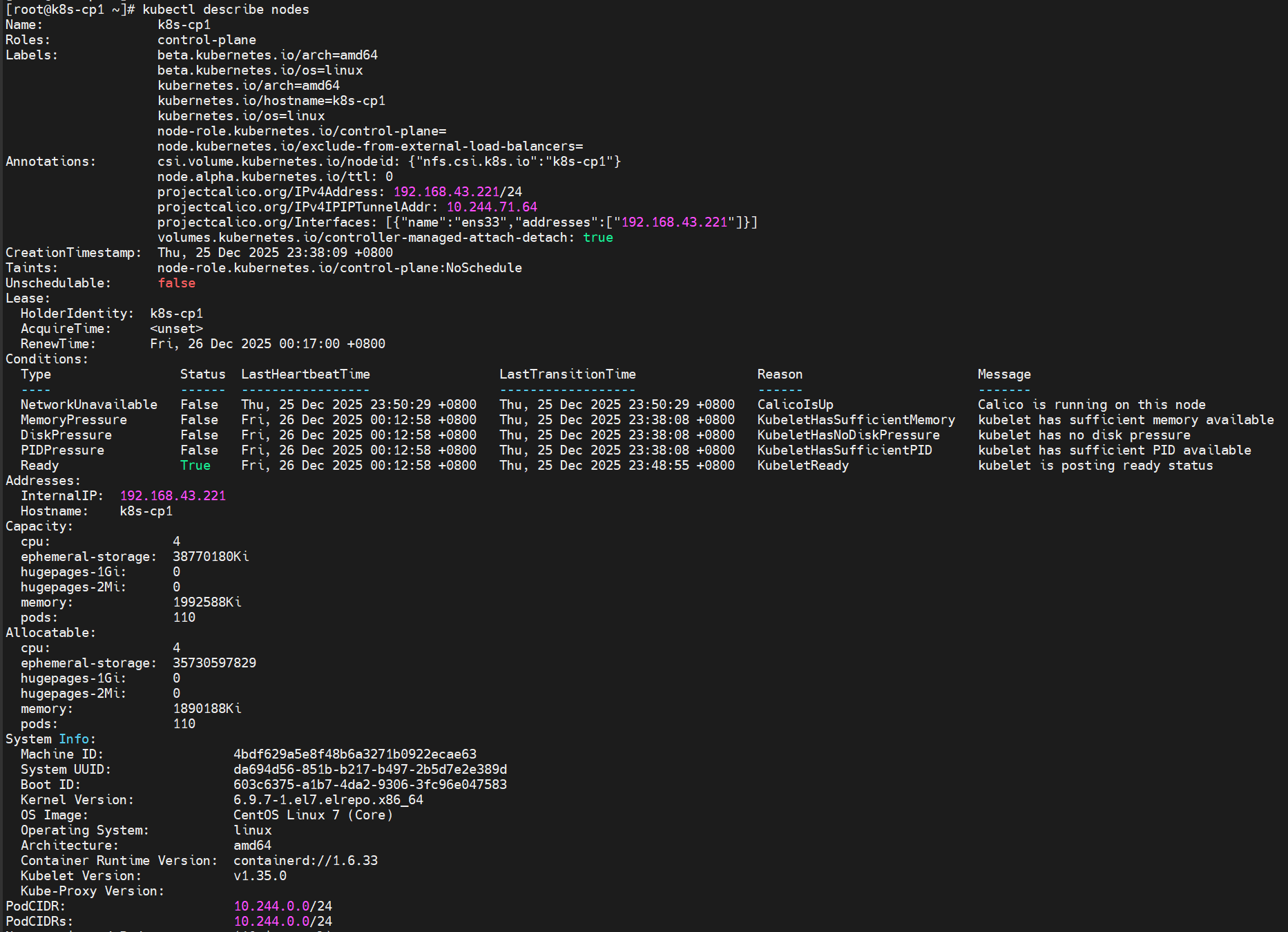
再看集群种当前各节点信息,此时各节点STATUS的为:Ready。

或者通过kubectl describe nodes命令查看各个节点的详细信息。
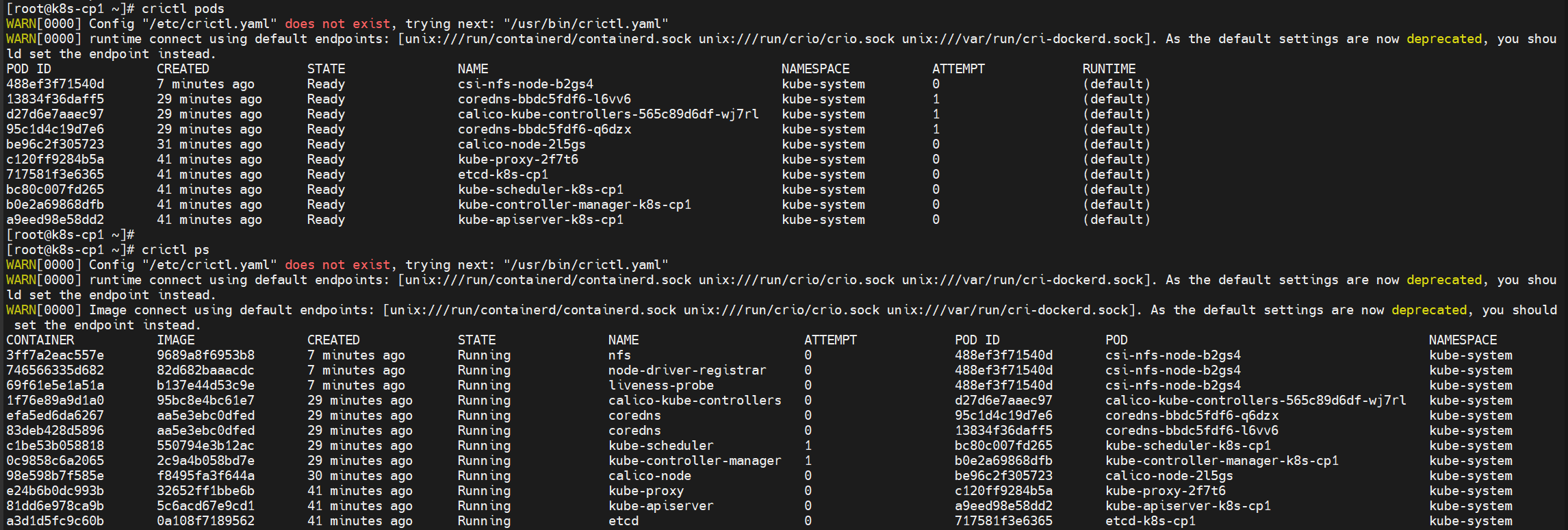
附A:crictl与ctr客户端工具
crictl 是k8s中CRI(容器运行时接口)的客户端命令行工具,k8s使用该客户端和containerd或其他类型容器运行时进行交互,crictl命令运行的默认 命名空间是:k8s.io。
随着kubelet安装时一起安装cri-tools,其中包含crictl客户端工具。
ctr 是 containerd 自带的客户端命令行工具,ctr命令运行的默认 命名空间是:default(containerd 相比于docker , 多了 namespace 概念,每个 image 和 container 都会在各自的namespace下可见)。 ctr通常随着Containerd 安装时一起安装。
这两个命令一定程度上可类似于docker客户端命令。命令差异可参考:https://www.cnblogs.com/no-heart/p/17413919.html
在Kubernetes集群中通常都是在控制平面上进行管理,一般无需再某个工作节点机器上手工执行crictl或ctr。当然若需要,也可以在工作节点机器上通过命令查看pod、容器等信息:
附B:节点机器Node上配置resolv.conf
Kubernetes自带的CoreDNS服务,在Kubernetes集群内部(例如Pod的容器内)可使用该DNS解析。但节点机器Node无法使用该DNS解析,因为节点机器Node上未配置该CoreDNS服务地址,无法查询该CoreDNS来查询和解析。
如果希望在某个(某些)节点机器Node上也能使用CoreDNS服务进行域名解析,则需要在这个(这些)节点机器Node上配置resolv.conf文件。步骤如下:
# 先查看获得Kubernetes当前提供解析域名的DNS服务IP
kubectl get service -n kube-system -l k8s-app=kube-dns
# 对于CentOS操作系统,打开Network Manager字符界面
sudo nmtui在节点机器Node上,如下Network Manager的界面中,DNS servers可以有多个,将其中第一个地址设置为上个命令获得的:DNS服务IP(在本环境中为172.17.0.10)。
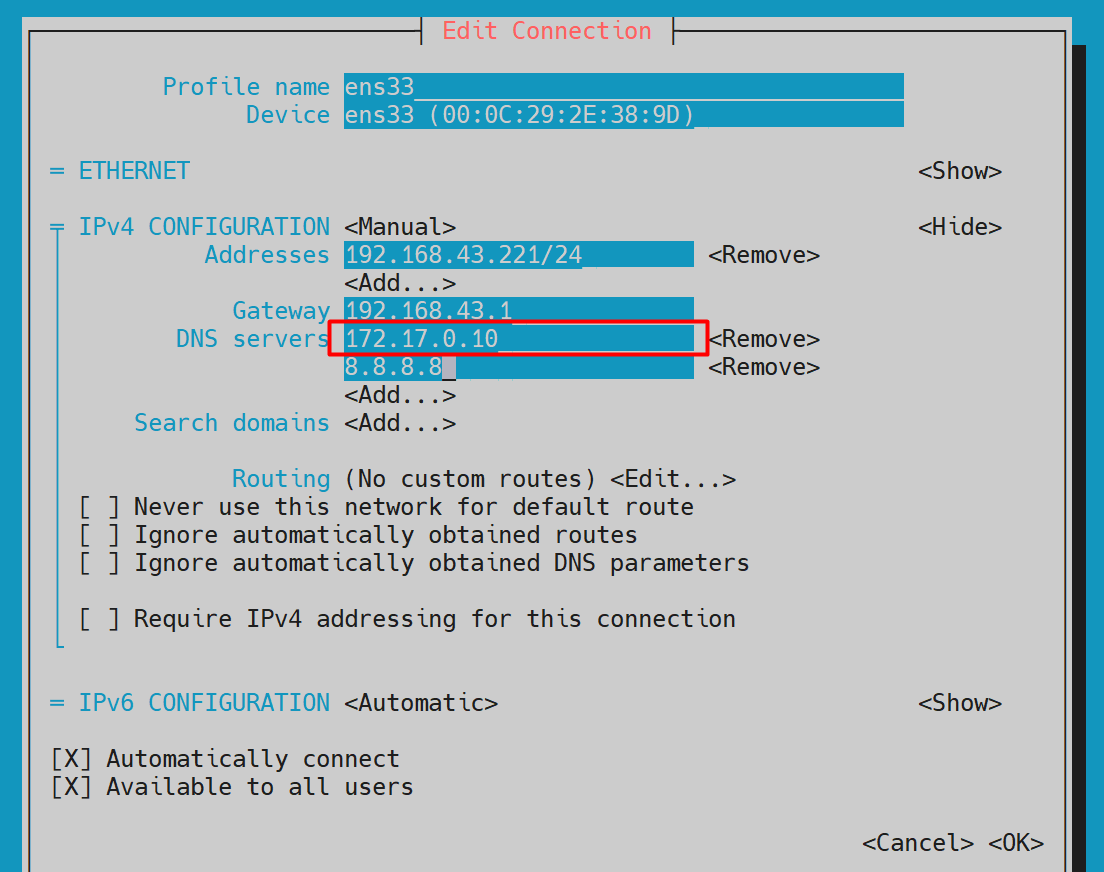
在节点机器Node上,然后通过以下命令使该网卡配置生效:
# 按实际情况,填写最后一个参数网络接口名
sudo nmcli connection up ens33
附C:安装NFS CSI驱动
因Kubernetes 不自带 NFS 驱动,若后续涉及使用NFS作为存储源,则可按需安装相关驱动。对于Kubernetes,常见的NFS驱动可以有:
- NFS CSI driver for Kubernetes
- NFS Ganesha server and external provisioner
- NFS subdir external provisioner
下面选择NFS CSI driver为例进行说明。NFS CSI driver可①在线联网安装 或 ②通过clone git仓后本地安装,具体安装见csi-driver-nfs官网:https://github.com/kubernetes-csi/csi-driver-nfs/blob/master/docs/install-nfs-csi-driver.md
下面演示以clone git仓方式安装。在Kubernetes的Control控制平面上执行:
# 确保可直接访问github 或者 手工下载zip后再解压也可以
git clone https://github.com/kubernetes-csi/csi-driver-nfs.git
#若国内无法直接访问registry.k8s.io和gcr.io,可替换为国内源
cd csi-driver-nfs
sed -i 's#registry.k8s.io#k8s.nju.edu.cn#' deploy/csi*.yaml
sed -i 's#registry.k8s.io#k8s.nju.edu.cn#' deploy/*/csi*.yaml
sed -i 's#gcr.io#gcr.nju.edu.cn#' deploy/csi*.yaml
#然后执行安装(指定最新版本即可)
./deploy/install-driver.sh v4.12.1 local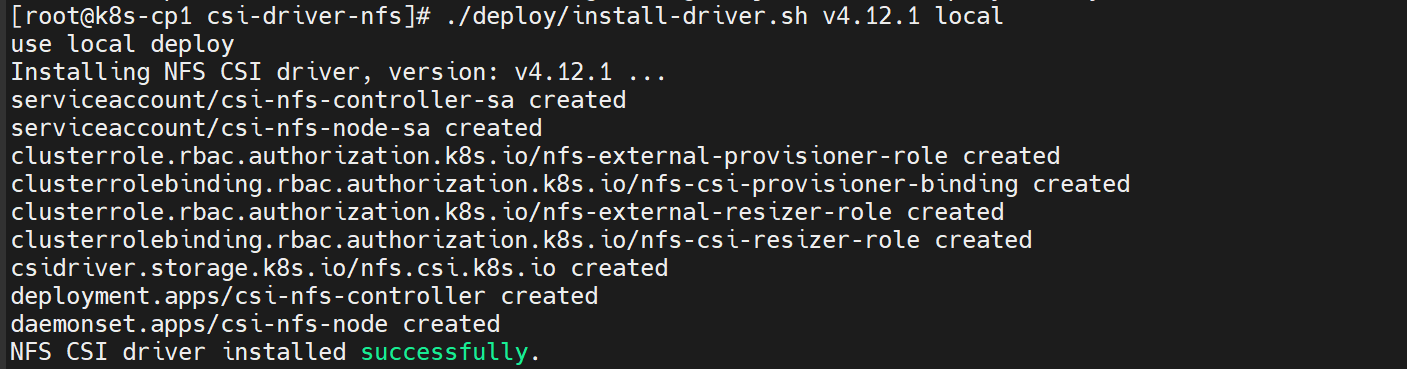
然后在Kubernetes的Control控制平面上查看安装结果,稍等片刻,名字以csi-nfs开头的Pod都应当处于Running状态:
kubectl -n kube-system get pod -o wide -l app=csi-nfs-controller
kubectl -n kube-system get pod -o wide -l app=csi-nfs-node
另外:若需卸载NFS CSI driver,则在Kubernetes的Control控制平面上执行:
cd csi-driver-nfs
./deploy/uninstall-driver.sh v4.12.0 local
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)