Agent论文阅读笔记——分层工作记忆管理框架
HIAGENT的核心思想是利用子目标对工作记忆进行分层管理。更具体地说,如图2所示,HIAGENT的流程可描述如下:(1)在生成特定的落地动作(grounded actions)之前,我们先引导大型语言模型(LLM)构建一个子目标gᵢ。每个子目标都是整个任务中的一个里程碑。(2)随后,LLM生成实现该子目标所需的精准动作。(3)当LLM判定某个子目标已完成时,我们会将该子目标对应的“动作-观测”对
摘要
基于大型语言模型(LLM)的智能体在多个领域展现出巨大潜力,它们作为交互式系统,通过处理环境中的观察结果来生成目标任务所需的可执行动作。这类智能体的性能在很大程度上受到其记忆机制的影响,记忆机制会将历史经验记录为一系列动作-观察(action-observation)对。
我们将记忆分为两类:跨轮次记忆(cross-trial memory),即通过多次尝试积累的记忆;以及单轮次记忆(in-trial memory,又称工作记忆),即在单次尝试中积累的记忆。
尽管已有大量研究通过优化跨轮次记忆来提升性能,但通过更好地利用工作记忆来增强智能体表现的研究仍较为欠缺。现有方法通常是将完整的历史动作-观察(action-observation)对直接输入到LLM中,这在长任务序列中容易导致冗余。
受到人类解决问题策略的启发,本文提出了HIAGENT框架,它通过将子目标(subgoals)作为记忆块,分层管理基于LLM的智能体的工作记忆。具体而言,HIAGENT首先提示LLM在生成可执行动作之前先制定子目标,并允许LLM主动决定何时用总结后的观察内容替换之前的子目标,仅保留与当前子目标相关的动作-观察对。
在五个长任务场景中的实验结果表明,HIAGENT使任务成功率提高了两倍,并将平均所需步骤减少了3.8步。此外,我们的分析显示,HIAGENT在多个步骤中均能稳定提升表现,展示出其鲁棒性与泛化能力。
1 引言
近年来,得益于大型语言模型(LLM)强大推理能力的发展(OpenAI,2022,2023;Meta AI,2024;Touvron 等人,2023;Jiang 等人,2023),基于LLM的智能体已在各类应用中展现出显著潜力(Xie 等人,2023;Wang 等人,2024;Xi 等人,2023),例如软件开发(Hong 等人,2023;Bairi 等人,2024)、机器人规划(Yao 等人,2022b;Puig 等人,2018;Singh 等人,2023;Huang 等人,2022a)、人类行为模拟(Park 等人,2023)等领域。
通常而言,基于LLM的智能体是一种交互式系统,它能够处理环境观测信息、在多轮对话中维持上下文连贯性,并输出为完成特定任务量身定制的可执行动作。
记忆是基于大型语言模型(LLM)的智能体的核心组件之一,关乎智能体如何存储和利用过往经验。在处理特定任务时,智能体的记忆可分为跨尝试记忆(cross-trial memory)和尝试内记忆(in-trial memory,又称工作记忆)。其中,跨尝试记忆通常包含在当前任务的多次尝试过程中积累的历史轨迹信息;与之相反,尝试内记忆则仅涉及与当前单次尝试相关的信息。
尽管已有大量研究探索通过利用跨尝试记忆(cross-trial memory)来优化智能体性能(Shinn 等人,2024;Zhao 等人,2024;Guo 等人,2023),但针对如何更好地利用工作记忆的研究仍较为匮乏。现有关于基于LLM的智能体的研究文献,主要采用图1所示的“STANDARD(标准)”策略:在向LLM输入提示词(prompt)时,会将工作记忆中所有的“动作-观测”对直接纳入上下文(Liu 等人,2023c;Ma 等人,2024;Yao 等人,2022b)。
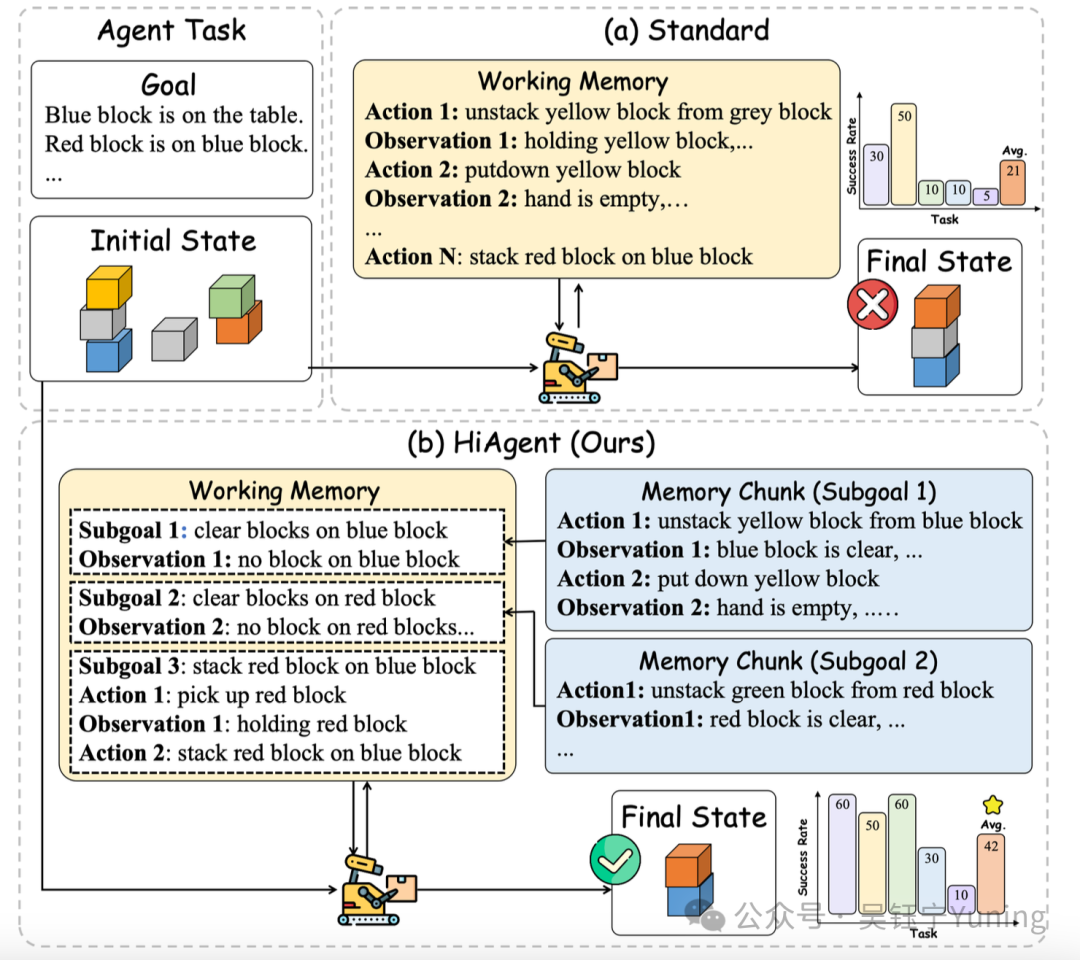
图 1 说明译文
右上角:基于大型语言模型(LLM)的智能体普遍采用的 “STANDARD(标准)” 范式包含以下步骤:i)向 LLM 输入提示词以生成一个动作;ii)执行生成的动作,并将获取到的观测结果添加到 LLM 的上下文(即工作记忆)中;iii)生成下一个动作。
下方:与将所有历史 “动作 - 观测” 对纳入工作记忆的做法不同,HIAGENT 以子目标作为记忆块(memory chunks),每个记忆块的观测信息均为总结后的观测结果(summarized observation)。在五项长时程任务中,HIAGENT 将平均成功率提升了一倍(成功率分别为 42% 和 21%)。
尽管这种方法能尽可能全面地将历史信息传递给LLM,但在长时程智能体任务(long-horizon agent tasks)中会暴露出问题。这类任务通常需要智能体执行大量动作才能完成,导致工作记忆规模庞大。而冗长的工作记忆会产生冗余上下文,阻碍LLM在长时间内维持连贯的策略并做出准确预测。
借鉴认知科学原理(Newell 等人,1972;Anderson,2013),人类在解决复杂问题时,通常会将其分解为多个子问题,再逐一处理。每个子问题会被视为一个记忆“块”(chunk),从而减轻工作记忆的认知负荷(Miller,1956)。通过聚焦已完成子问题的结果而非其详细执行过程,人类能够高效管理认知资源,提升解决复杂长时程任务的效率。
受人类认知与问题解决策略的启发,我们提出了一种精密的分层工作记忆管理框架HIAGENT,该框架专门针对长时程智能体任务设计。HIAGENT的核心思想是触发大型语言模型(LLM)生成子目标,每个子目标都充当工作记忆的一个“块”。
具体而言,如图2所示,我们首先引导LLM生成一个子目标,随后生成实现该子目标所需的动作,并将对应的“动作-观测”对存储在一个记忆块中。当子目标完成后,我们会对该记忆块进行总结,并将“子目标-总结观测”对添加到工作记忆中。
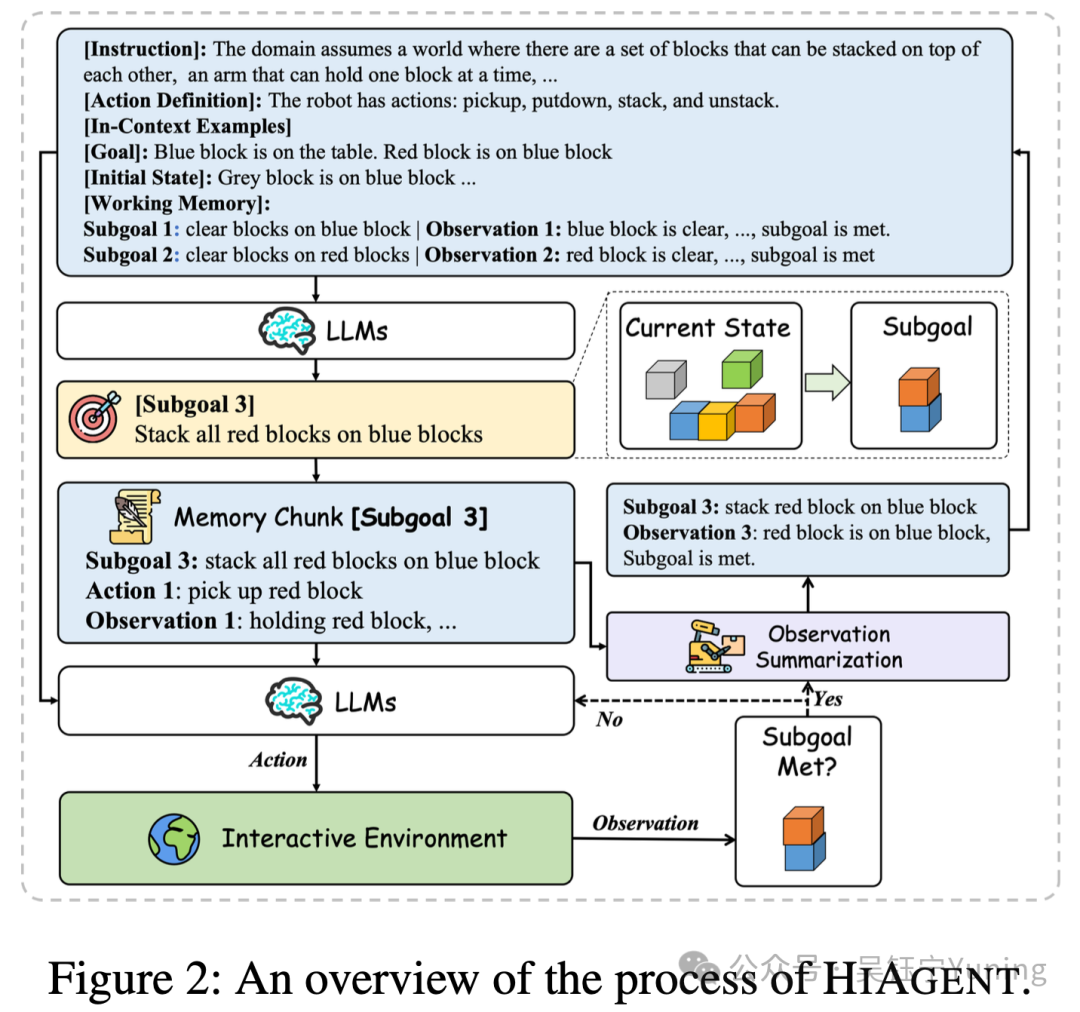
简而言之,HIAGENT会触发LLM主动决策,用总结后的观测信息替代之前的子目标相关记忆,同时仅保留与当前子目标相关的“动作-观测”对。为实现更灵活的工作记忆管理,我们还引入了轨迹检索模块,该模块可在需要时检索特定过往子目标的详细轨迹信息。
为验证HIAGENT的有效性与效率,我们在来自AgentBoard(Ma等人,2024)的五项长时程智能体任务上开展了实验。实验结果显示,HIAGENT的成功率是STANDARD(标准)策略的两倍,其进度率(progress rate)较STANDARD策略提升了23.94%。此外,HIAGENT的效率同样优于STANDARD策略:完成任务所需的平均步骤数减少了3.8步,上下文长度缩短了35.02%,运行时间减少了19.42%。
进一步地,为证明冗余上下文会损害基于大型语言模型(LLM)的智能体在长时程任务中的性能,我们将HIAGENT与另一种“生成子目标但不忽略过往子目标详细轨迹信息”的方法进行了对比。实验结果表明,HIAGENT在将成功率提升20%的同时,还缩短了运行时间并减少了任务步骤。通过分析模型在不同步骤数量下的性能,我们发现:HIAGENT不仅在进度率上持续优于STANDARD策略,而且随着步骤数量的增加,其生成可执行动作的概率也更高。
2 预备知识
2.1 基于大型语言模型(LLM)的智能体
基于大型语言模型(LLM)的智能体是为执行复杂任务而设计的智能自主系统。这类任务可形式化为部分可观测马尔可夫决策过程(Partially Observable Markov Decision Process, POMDP),其特征可通过元组(S, O, A, T, R)描述,各元素含义如下:
-
S 表示状态空间(state space);
-
O 表示观测空间(observation space);
-
A 表示动作空间(action space);
-
T: S × A → S 代表状态转移函数(transition function);
-
R: S × A → R 包含奖励函数(reward function)。
基于LLM的智能体以策略π(at|I, ot, at−1, ot−1, . . . , a0, o0) 运行:在给定历史“动作-观测”对以及指令 I(包括上下文示例、环境描述等)的情况下,生成可执行动作 at ∈ A。每个动作都会触发一个新状态 st+1 ∈ S,并产生后续观测 ot+1 ∈ O。这种迭代式交互会持续进行,直至任务完成,或智能体达到预设的最大步骤数为止。
2.2 工作记忆
从认知科学视角来看,工作记忆能够让个体实时持有并处理信息,为推理、理解、学习等复杂认知任务提供支持(Newell 等人,1972;Anderson,2013)。在基于大型语言模型(LLM)的智能体中,我们将工作记忆定义为:在特定时刻 t,LLM 完成当前任务所需的关键历史信息。
有效的工作记忆管理有助于更好地整合过往经验与当前刺激,进而做出更充分、准确的决策。这一过程可类比于人类的注意力控制与认知更新机制——即选择性聚焦相关信息、过滤干扰内容,并持续用新的关键数据更新“心理工作空间”。
图1中的“STANDARD(标准)”方法会将所有历史“动作-观测”对存储在工作记忆中,其形式可表示为 mₜ^std = (oₜ, aₜ₋₁, oₜ₋₁, …, a₀, o₀)。尽管这种方式能为LLM提供全面的信息,但也会引入冗余内容,增加LLM的处理难度。
3 方法
3.1 概述
HIAGENT的核心思想是利用子目标对工作记忆进行分层管理。更具体地说,如图2所示,HIAGENT的流程可描述如下:
(1)在生成特定的落地动作(grounded actions)之前,我们先引导大型语言模型(LLM)构建一个子目标gᵢ。每个子目标都是整个任务中的一个里程碑。
(2)随后,LLM生成实现该子目标所需的精准动作。
(3)当LLM判定某个子目标已完成时,我们会将该子目标对应的“动作-观测”对合成为一个总结后的观测结果sᵢ(详见3.3节)。之后,我们会隐藏上下文中该子目标对应的原始“动作-观测”对,并用sᵢ替代它们。因此,HIAGENT的工作记忆可形式化为mₜ = (g₀, s₀, …, gₙ₋₁, sₙ₋₁, gₙ, aₙ₀, oₙ₁, …)。
(4)此外,我们还集成了一个检索模块,以实现更灵活的记忆管理(详见3.4节)。例如,若检索第q个(qth)子目标,我们会将该子目标的详细“动作-观测”对输入上下文,而非使用总结后的观测结果,即m'ₜ = (g₀, s₀, …, g_q, a_q₀, a_q₀, …, gₙ, aₙ₀, oₙ₀, …) 。
3.2 基于子目标的分层工作记忆
如图2所示,在每个时间步,大型语言模型(LLM)既可以为当前子目标生成下一个动作,也可以在判定现有子目标已完成时生成新的子目标。对于当前子目标,智能体会保留所有“动作-观测”对,为即时决策提供详细上下文;而对于过往子目标,仅保留观测结果的总结版本。
HIAGENT中这种基于子目标的分层管理方法,深受认知科学原理的启发,与人类的认知及问题解决策略存在相似之处(Newell 等人,1972;Anderson,2013)。将子目标用于划分“动作-观测”对的做法,可被理解为一种“分块”(chunking)方法。在人类认知中,“分块”能让个体将相关信息归类为有意义的单元,从而突破工作记忆的限制(Miller,1956)。
与之类似,HIAGENT将子目标作为认知“块”,封装相关的动作与观测信息。这种分块机制使系统能更高效地处理复杂的信息序列,减轻认知负荷并提升整体性能。此外,通过在生成具体动作前先构建子目标,该系统模拟了人类将宏大目标拆解为更易处理的组件的倾向——这种方法不仅提高了计算效率,也与已确立的人类信息处理理论相契合。
3.3 观测总结
观测总结过程可形式化为si =S(gi,o0,a0,...,ot) ,其中函数S 既可以通过大型语言模型(LLM)实现,也可借助其他文本总结模型实现。该函数会以当前子目标为上下文,对历史观测与动作信息进行整合,生成智能体状态的简洁表示。此外,总结后观测结果的一个关键作用是判断当前子目标是否已达成。这一判断结果将作为后续子目标生成的重要依据,助力智能体在决策过程中展现出适应性与目标导向性的行为。通过这种方式,智能体能够维持精简且信息完备的上下文,在保留历史信息需求与提升效率之间实现平衡。提示词示例可参见附录。
3.4 轨迹检索
尽管已进行观测总结,但在某些场景下,过往轨迹的详细信息对即时决策仍至关重要。例如,当某个过往子目标执行失败时,需要借助详细轨迹信息定位失败原因;此外,在面对全新挑战与场景时,回顾过往成功经验也能提高任务成功的概率。为应对这一需求,本文引入轨迹检索模块。当LLM判定需要某个过往子目标的详细信息时,会生成一个检索函数,调取该子目标对应的完整“动作-观测”对——这一过程与LLM生成动作的方式类似。这种选择性检索机制使智能体能够按需获取详细历史数据,而无需持续携带完整上下文。
4 实验
4.1 实验设置
评估任务
我们在五项长时程智能体任务上开展实验,这些任务通常需要执行20步以上的动作,具体如下:
(1)积木世界(Blocksworld):要求模型通过执行一系列移动动作,将积木排列成指定的目标构型;
(2)抓取器任务(Gripper):需在不同房间之间转移物体;
(3)轮胎世界(Tyreworld):模拟更换汽车轮胎的过程,包括拆卸瘪胎、更换备胎以及安装新轮胎等步骤;
(4)调酒师任务(Barman):模拟调酒师的鸡尾酒调制工作,涵盖混合各类原料、使用摇杯以及为饮品装饰点缀等操作;
(5)Jericho任务(Hausknecht等人,2020):一套基于文本的冒险游戏环境,用于评估智能体在虚拟世界中的导航与交互能力。
更多详细信息可参见附录A。
评估指标
(1)进度率(Progress Rate):用于评估任务完成的推进程度。具体而言,一项任务包含多个目标条件,进度率即模型已完成的目标条件数量占总目标条件数量的比例。
(2)成功率(Success Rate):衡量任务成功完成的百分比。当进度率为1(即所有目标条件均完成)时,成功率为1。
(3)平均步骤数(Average Steps):统计完成任务所需的动作步骤数量。
(4)上下文效率(Context Efficiency):定义为完成特定任务所需的所有步骤中,尝试内上下文(in-trial context)的平均Token数量。
(5)运行时间(Run Time):评估完成任务所需的时间。
基线方法
“STANDARD(标准)”提示策略是当前基于大型语言模型(LLM)的智能体相关文献中广泛使用的方法(Yao等人,2022b;Ma等人,2024;Liu等人,2023c)。该策略遵循“执行一个动作→获取一个观测”的流程,为评估HIAGENT的性能提供了对比基线。
实现细节
评估任务的实现基于AgentBoard平台(Ma等人,2024)。在任务配置中,我们将最大步骤限制设为30,并为每项任务提供1个上下文示例。实验采用GPT-4(gpt-4-turbo)¹作为LLM基础模型,既充当智能体策略模型,也作为观测总结模型。LLM推理的温度(temperature)超参数设为0,topp超参数设为1。详细的提示词示例可参见附录B。
4.2 主要结果
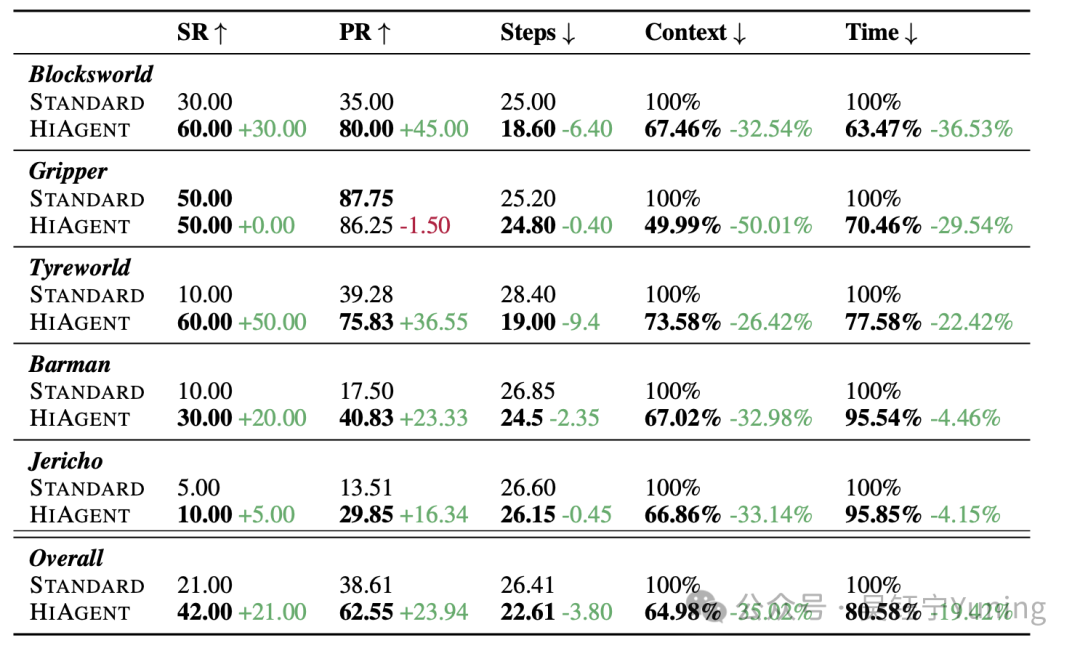
表1:STANDARD(标准)策略与HIAGENT在5项长时程智能体任务上的性能对比
本表格报告了四项关键指标(原文提及四项,实际列出五项,按表格内容完整呈现):成功率(Success Rate, SR)、进度率(Progress Rate, PR)、平均步骤数(Average Steps, Steps)、上下文效率(Context Efficiency, Context)以及运行时间(Run Time, Time)。其中,符号“↑”表示该指标数值越高越好,符号“↓”表示该指标数值越低越好。“Overall(整体)”部分的结果通过计算某一指标在所有任务中的平均值得出。
如表1所示,HIAGENT相较于STANDARD(标准)策略展现出显著优势。总体而言,在有效性方面,HIAGENT将成功率提升了21%,进度率提升了23.94%;在任务执行效率方面,其将完成任务的平均步骤数减少了3.8步,上下文Token消耗量降低了35%,运行时间缩短了19.42%。
此外,在部分任务(积木世界Blocksworld、调酒师任务Barman、Jericho任务)中,HIAGENT在保持效率的同时,进度率提升幅度甚至超过两倍。在轮胎世界(Tyreworld)任务中,该模型不仅将成功率提升了50%,还将平均步骤数减少了9.4步。尽管在抓取器(Gripper)任务中,进度率略有下降(降低1.5%),但其上下文Token用量减少了50%以上。
从上述结果中,我们可得出以下结论:
(1)HIAGENT的有效性优于STANDARD策略,在成功率和进度率两项指标上均实现了大幅提升;
(2)HIAGENT的效率同样优于STANDARD策略,完成任务所需步骤更少、上下文长度更短,且运行速度更快。
5 分析
为更深入地理解我们提出的方法,我们围绕以下研究问题展开探讨:
(1)HIAGENT的所有模块是否均具有有效性?
(2)在不同步骤阶段,HIAGENT是否始终优于基线方法?
(3)HIAGENT的性能提升是否仅源于任务分解?
(4)该框架在生成可执行动作方面的效果如何?
(5)与STANDARD(标准)策略相比,HIAGENT所展现的性能提升是否具有统计显著性?
5.1 问题1:HIAGENT的所有模块均具有有效性
在本节中,我们通过消融实验(ablation study)探究了“观测总结(Observation Summarization)”与“轨迹检索(Trajectory Retrieval)”两个模块的有效性。
观测总结模块具有有效性。当移除该模块时,我们采用启发式方法,将最后一个动作对应的观测结果作为总结后的观测信息。如表2中“无观测总结(w/o OS)”组所示,所有指标的性能均出现显著下降:其中成功率和进度率受到的影响尤为明显,分别下降了30%和7.6%。这一结果表明,观测总结模块能够全面整合轨迹中的详细信息,进而为基于大型语言模型(LLM)的智能体的推理过程提供支持。
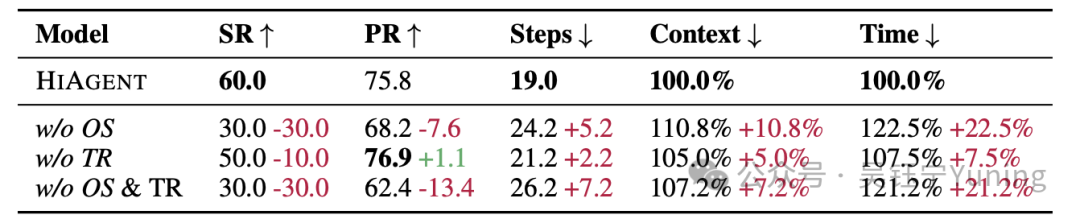
表2:HIAGENT在轮胎世界(Tyreworld)任务上的消融实验结果
“w/o OS”表示移除3.3节介绍的“观测总结(Observation Summarization)”模块;“w/o TR”表示移除3.4节介绍的“轨迹检索(Trajectory Retrieval)”模块;“w/o TR & OS”表示同时移除上述两个模块。
轨迹检索模块对性能提升同样至关重要。为验证该模块的有效性,我们在每个时间步都隐藏了过往子目标的所有详细轨迹信息。根据表2中“无轨迹检索(w/o TR)”组的结果,此时成功率下降了10%,平均步骤数增加了2.2步。这是因为,尽管轨迹检索会延长LLM的推理步骤,但它能让智能体在特定子目标下灵活调取过往轨迹,这对于识别先前动作中的错误更具帮助。
观测总结与轨迹检索模块的组合能带来显著的性能提升。为验证这两个模块组合使用的功能与有效性,我们开展了同时移除两个模块的实验。如表2中“无观测总结与轨迹检索(w/o OS & TR)”组所示,与完整的HIAGENT相比,其性能出现明显下降,成功率降低了20%。即便与单独移除观测总结模块或轨迹检索模块的消融实验结果相比,这种性能下降也十分显著——尤其体现在进度率的大幅降低上,进一步凸显了两个模块协同作用的重要性。
5.2 问题2的答案:在不同步骤阶段,HIAGENT始终优于STANDARD策略
为更细致地研究HIAGENT的性能,我们在图3中展示了其在不同步骤数(以5步为间隔)下的进度率。实验结果表明,总体而言,HIAGENT在每个步骤阶段的进度率均高于STANDARD策略(图f)。此外,值得注意的是,HIAGENT能从步骤数的增加中获得更多收益,而STANDARD策略则无法做到这一点。例如,在积木世界任务(图a)和调酒师任务(图d)中,STANDARD策略在15-25步之间的进度率未出现增长,而HIAGENT的进度率则呈现持续上升趋势。这一结果进一步证明了HIAGENT在处理长时程智能体任务时的优势。
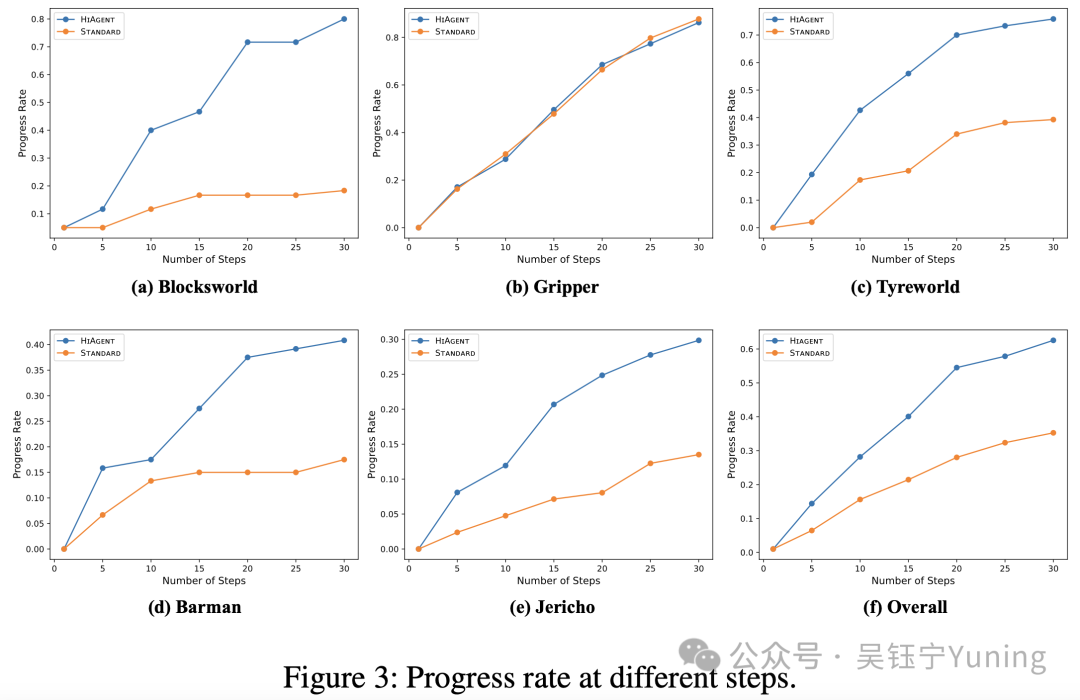
5.3 问题3的答案:HIAGENT的性能提升并非仅源于任务分解
利用大型语言模型(LLM)生成子目标的方法已在众多研究中得到应用,并展现出显著的性能优势(Zhou等人,2022;Yin等人,2023)。因此,一个相关问题随之产生:“HIAGENT的性能提升是否仅与任务分解相关,而非得益于高效的工作记忆管理?”为解答这一问题,我们设计了一种新方法:该方法同样引导LLM在生成可执行动作前先生成子目标,再生成实现该子目标的动作,但与HIAGENT不同的是,它不会隐藏过往子目标的详细轨迹信息。表3中的详细实验结果显示,尽管任务分解本身能带来性能提升(成功率提高30%),但其成功率仍比HIAGENT低20%。此外,仅依靠任务分解还会导致效率下降,使运行时间增加5.7%,上下文长度增加12.8%。综上,HIAGENT相较于单纯的任务分解,在效率和有效性上均更具优势。

表3:轮胎世界(Tyreworld)任务的实验结果
“w. TD”代表任务分解(Task Decomposition),具体指让大型语言模型(LLM)生成子目标,但不隐藏过往子目标的详细轨迹信息。
5.4 问题4的答案:即便在长步骤下,HIAGENT生成可执行动作的效果依然良好
基于大型语言模型(LLM)的智能体有时会生成无法执行的动作,例如试图从密闭容器中获取物体——这通常是由于LLM的推理能力不足所致。为探究这一问题,我们计算了模型在每个时间步生成可执行动作的比例(该比例被称为“可执行性”)。
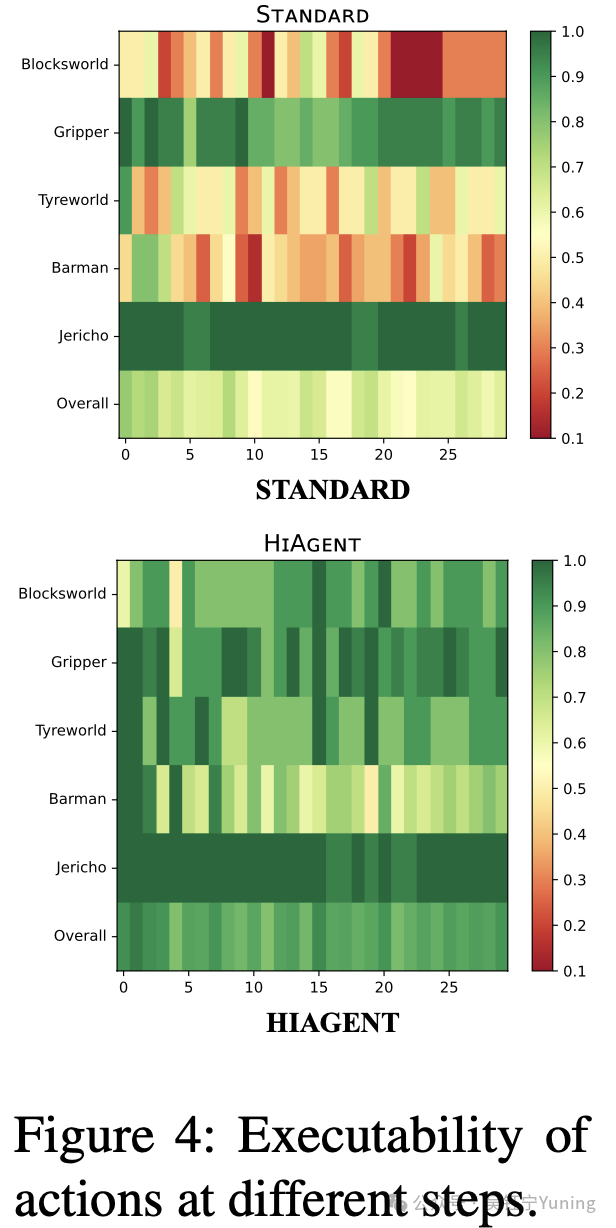
如图4所示,HIAGENT生成可执行动作的概率高于STANDARD(标准)策略,这进一步证明了HIAGENT的有效性。此外,我们观察到,当步骤数较多时,STANDARD策略更易生成不可执行的动作(例如在积木世界任务中,当步骤数超过20步时,其可执行性降至10%以下)。这是因为随着工作记忆内容的增加,LLM生成可执行动作的能力会随之下降。
与之相反,即便在步骤数较多的情况下,HIAGENT的可执行性仍能维持在80%以上。这表明,对长步骤的鲁棒性是HIAGENT在长时程任务中展现出优异性能的关键因素。
5.5 问题5的答案:与STANDARD(标准)策略相比,HIAGENT所展现的性能提升具有统计显著性
为验证HIAGENT在有效性和效率两方面性能提升的统计显著性,我们选取了进度率(Progress Rate)和平均步骤数(Average Steps)两项指标进行分析。由于威尔科克森符号秩检验(Wilcoxon signed-rank test,Woolson,2005)适用于配对样本的比较,我们采用该检验方法开展分析。这种非参数检验有助于判断观测到的差异是由随机因素导致,还是代表了真实存在的效应。
我们的分析结果如下:(1)在进度率指标上,检验统计量为144.0,p值为2.38×10⁻⁵,表明HIAGENT与STANDARD策略之间存在统计显著差异;(2)在平均步骤数指标上,检验统计量为112.5,p值为0.0016,同样表明两者存在统计显著差异。这些结果证实,HIAGENT在有效性和效率上观测到的提升并非由随机波动造成,进一步凸显了HIAGENT的优越性。
6 相关工作
基于大型语言模型的智能体
大型语言模型(LLMs)为语言智能体领域带来了变革,使其具备通过符合逻辑的动作序列应对复杂挑战的能力(Xie等人,2023;Xi等人,2023;Wang等人,2024)。已有一系列研究探索了基于LLM的智能体的各类应用场景,例如代码生成(Wang等人,2023b;Lin等人,2018)、网页浏览(Yao等人,2022a;Zhou等人,2023a;Pan等人,2024;Li和Waldo,2024)、机器人技术(Shridhar等人,2020;Mu等人,2024a,b)、工具使用(Li等人,2023b;Wu等人,2024;Qin等人,2023)、推理(Yang等人,2024;Chen等人,2025)、规划(Xie等人,2024)、开展研究(Kang和Xiong,2024)、芯片设计等。此外,大量研究还探索了基于LLM的智能体在多智能体系统领域的应用(Hong等人,2023;Zhang等人,2023a;Wu等人,2023;Li等人,2023a;Chen等人,2023)。
本文提出了一种工作记忆管理框架HIAGENT,该框架具有通用性,可用于提升其他智能体框架的性能。例如,ReAct(Yao等人,2022b)提出让LLM在生成动作前先生成思维链(Wei等人,2022),而通过“(思维、动作、观测)”三元组形成的轨迹可借助HIAGENT进行管理。此外,HIAGENT还有潜力缓解多智能体框架中的信息管理难题(Hong等人,2023)。
规划
规划是人类智能的核心要素(Chen等人,2024b,2025),指通过一系列有意识的动作实现目标的系统性方法(Yao等人,2024;Zhang等人,2023b;Song等人,2023;Huang等人,2023,2022b;Liu等人,2023a;Hu等人,2023b;Ruan等人,2023;Aghzal等人,2023;Hu等人,2024)。规划过程包括将复杂任务分解为可管理的子任务、寻找潜在解决方案,以及达成预期目标。Least-to-most(Zhou等人,2022)和Plan-and-solve(Wang等人,2023a)提出将复杂问题分解为一系列子问题;Lumos(Yin等人,2023)和XAgent(Team,2023)则引入独立的规划模块生成子目标,并在落地模块中使用完整上下文完成每个子目标。
HIAGENT与现有研究的区别在于,它不仅利用规划提升任务性能,还将子目标作为记忆块,对工作记忆进行分层管理。如5.3节所述,这种方法提升了上下文效率,且优于仅依赖规划的方法。
记忆模块
基于大型语言模型(LLM)的智能体中的记忆模块,类似于人类的记忆系统,负责信息的编码、存储与检索(Zhang等人,2024)。记忆模块通常分为长期记忆和短期记忆:长期记忆一般可存储在外部数据库中,而短期记忆(也称为工作记忆)则通常直接作为LLM的上下文输入使用。
目前大多数研究论文主要聚焦于长期记忆的管理(Alonso等人,2024;Maharana等人,2024;Chen等人,2024a;Xiao等人,2024;Yuan等人,2023;Wang等人,2023c;Majumder等人,2023;Hu等人,2023a;Hao等人,2024;Tu等人,2023;Liang等人,2023;Kagaya等人,2024)。该领域的开创性研究包括Memorybank(Zhong等人,2024),其通过全局层面的总结,在将对话提炼为连贯叙事方面取得了显著进展;其他研究如Think-in-memory(Liu等人,2023b)和Retroformer(Yao等人,2023),则集成了总结模块以管理长期记忆。与这些研究不同,本文探究的是如何通过优化工作记忆管理来提升智能体性能。
另一类研究方向则涉及修改Transformer的结构,使LLM能够处理更长的上下文,从而扩展其工作记忆能力(Zhou等人,2023b;Chevalier等人,2023;Bertsch等人,2024;Ruoss等人,2023;Beltyagy等人,2020;An等人,2023)。然而,现有研究已发现,LLM在处理长文本时会面临注意力丢失的问题(Liu等人,2024)。因此,我们认为,探索更高效的工作记忆管理方式仍是一项具有价值的研究方向。
7 结论
本文提出了HIAGENT——一种灵活的框架,该框架利用子目标对基于大型语言模型(LLM)的智能体的工作记忆进行管理。在五项长时程智能体任务上的实验结果表明,HIAGENT在所有任务中均优于基线模型,整体成功率是基线模型的两倍多。此外,HIAGENT的效率更高,能够以更少的步骤、更短的运行时间和更简洁的上下文完成任务。未来,我们期望HIAGENT能为探索“如何有效管理基于LLM的智能体工作记忆”带来更多创新性思路。
局限性
尽管HIAGENT减少了冗余上下文,但在内存约束依然存在的极长时程任务中,它可能仍面临挑战。未来的研究可探索更先进的检索策略,以进一步优化内存效率。此外,本文的实验主要聚焦于基准任务;将评估范围扩展到更多样化的现实应用场景,将有助于更深入地了解该方法的泛化能力。
论文全称:《HiAgent: Hierarchical Working Memory Management for Solving Long-Horizon Agent Tasks with Large Language Model》

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)