一系列带你学会Spring AI
自从Transformer诞生以来,LLM(Large Language Model)大模型技术就开始蓬勃发展,从ChatGPT系列到国内的DeepSeek、通义千问系列,大模型技术不断迭代,一次次突破性能指标上限。但是,大模型的落地应用成为行业难题,诸如智能体、RAG等技术不断解决落地难和应用难的问题。繁多的技术规范不统一,学习起来极为困难,而Spring AI、LangChain等技术正是统一
目录
0 前言
自从Transformer诞生以来,LLM(Large Language Model)大模型技术就开始蓬勃发展,从ChatGPT系列到国内的DeepSeek、通义千问系列,大模型技术不断迭代,一次次突破性能指标上限。但是,大模型的落地应用成为行业难题,诸如智能体、RAG等技术不断解决落地难和应用难的问题。
繁多的技术规范不统一,学习起来极为困难,而Spring AI、LangChain等技术正是统一大模型应用落地的框架,也是传统开发编程融入人工智能发展的新机遇。
1 Spring AI介绍
1.1 简介
2025年5月20日,Spring AI官方宣布1.0 GA (General Availability)版本正式发布,这是Spring官方推出的首个稳定版人工智能(AI)集成框架。旨在帮助Java/Spring开发者更便捷地在企业级应用中集成AI能力(如大语言模型、机器学习、向量数据库、图像生成等)。它的发布标志着Spring生态正式进入AI时代,为Java开发者提供了标准化的AI开发工具链,AI技术正式进入Spring生态的核心工具链。
因为是Spring官网开源的AI框架,因此和SpringBoot家族的项目天然的兼容。并且框架封装集成了多个流行LLM的厂商的接口开发规范,因此开发人员学习一个框架便可自由替换LLM从而学会其它LLM的接入和使用。
1.2 名词解释
Token(词元):大模型所能理解的最小语义单元,一个词、一个数字、一个字母和一个标点符号都可以算作是一个Token。但是由于词的划分通常是由分词器处理,不同分词器的划分词的方式不同,因此可能一句话的Tokens计算结果不一定完全一样。
提示词:用户/系统提供给大模型的文本/指令,简而言之就是告诉大模型你要它干什么。由于提示词的优劣影响大模型的输出指令,因此提示词的设计也有学问。从专业角度分类,提示词分为系统提示词和用户提示词。
系统提示词:大模型应用系统内嵌,全局共享,定义了大模型的角色、行为、知识库边界等规范。比如“你是一名精通编程的开发者”,这句提示词就定义了大模型的角色,从而用户每次输入的提示词都会携带系统提示词,输出和编程开发相关的内容。
用户提示词:由用户直接输入,比如“请帮我总结这篇文章的思想”。
1.3 环境需求
SpringBoot最低需求:3.2版本以上(Spring AI强制要求),推荐3.4版本以上。
JDK最低需求:JDK 17以上(SpringBoot 3.x版本要求),推荐JDK 21以上。
2 接入DeepSeek
2.1 DeepSeek API Keys
我们选择接入国内著名的LLM DeepSeek,更方便学习使用。DeepSeek的网页版和客户端是免费使用的,但是DeepSeek的API需要收费,因此需要首先开通DeepSeek API:
DeepSeek官网![]() https://www.deepseek.com/
https://www.deepseek.com/

点击右上角API开放平台,进入后点击充值按钮(需要先实名)。由于是学习阶段,几块钱足够使用了:

然后创建API keys(记得复制保存):
2.2 引入依赖
Spring AI提供了一个bom,该bom负责依赖的版本兼容管理,可以让开发人员直接引入相关依赖,不用手动管理版本:
<!-- Spring AI 相关依赖版本管理 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-M6</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>由于Spring AI便于大模型的管理,设计了Open AI以及兼容风格的依赖,提供统一的接口管理不同的LLM。该依赖兼容DeepSeek,因此需要引入如下依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>2.3 配置文件
配置文件需要定义相关客户端的配置项,比如访问地址、api key(上述申请的DeepSeek API Keys)和相关模型选择:
spring:
application:
name: spring-ai-deepseek
ai:
openai:
# api key需要去LLM官网申请
api-key: 你的api key
# LLM的API调用官网
base-url: https://api.deepseek.com
# 聊天属性的设置
chat:
options:
# 模型
model: deepseek-chat
# 输出随机值([0,2]之间,值越高越随机)
temperature: 0.7deepseek-chat模型对接DeepSeek官网最新版本的无深度思考功能的模型。
注意:temperature选项通常不要和topP选项同时使用。topP是采样温度的一种替代方法,称为核采样 (nucleus sampling),模型会考虑具有 top_p 概率质量的 token 的结果。因此,0.1 表示仅考虑构成前 10% 概率质量的 token。通常建议修改此项或 temperature,但不要同时修改两者,否则会导致大模型输出超出预期范围。
2.4 编写接口
通过注入OpenAiChatModel对象,该对象将配置文件的ai相关配置设置到属性中,从而可以通过该对象的call方法进行发送消息等待回复结果:
@RestController
@RequestMapping("/deepseek")
public class DeepSeekController {
/**
* 通过配置文件注册的大模型客户端对象
*/
@Autowired
private OpenAiChatModel openAiChatModel;
@GetMapping("/chat")
public String generate(String message) {
return openAiChatModel.call(message);
}
}2.5 测试
由于接口是等DeepSeek完全回复结束再返回响应结果,因此这个等待的过程比较慢:

3 核心API
Spring AI提供了两种核心的API:ChatClient和ChatModel。ChatModel是上述演示的,更底层,直接与大模型交互。ChatClient是对ChatModel的进一步封装,更加简便。
3.1 ChatClient
ChatClient是Spring AI封装的更高级的API,将复杂的交互流程封装为简洁的使用方式,采用与大模型通信的Fluent API(链式调用的思想,更容易理解调用流程),支持同步和反应式(Reactive)编程。
3.1.1 基本使用
基本使用方式如下:
@RestController
@RequestMapping("/chatclient")
public class ChatClientController {
/**
* ChatClient聊天客户端
*/
private final ChatClient chatClient;
/**
* 通过构造方法完成对象注入
*
* @param chatClientBuilder chatClient对象建造器
*/
public ChatClientController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@GetMapping("/call")
public String generation(String userInput) {
return this.chatClient.prompt()
//用户输入的提示词
.user(userInput)
//请求大模型
.call()
//返回文本
.content();
}
}发送消息结果如下:

3.1.2 角色预设
除了简单的使用方式,ChatClient还支持角色预设,在建造对象的时候,使用defaultSystem()方法可以添加系统提示词,为大模型预设角色。该提示词全局生效,每次的用户提示词都会结合系统提示词进行回复:
/**
* 通过构造方法完成对象注入
*
* @param chatClientBuilder chatClient对象建造器
*/
public ChatClientController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder
.defaultSystem("你是一个精通Java的工程师,专注于Java领域的前沿技术。")
.build();
}运行结果如下:

3.1.3 结构化输出
如果想要大模型的输出结构化,可以使用entity()来将大模型的输出转为自定义结构的输出:
/**
* record关键词(JDK16新特性):定义学习清单实体类
* @param time 学习周期
* @param knowledge 技术
*/
record StudyList(String time, List<String> knowledge) {}
@GetMapping("/entity")
public String entity(String userInput) {
StudyList studyList =this.chatClient.prompt()
//用户输入的提示词
.user(userInput)
//请求大模型
.call()
//返回文本,并将输出转为StudyList实体
.entity(StudyList.class);
return studyList.toString();
}结果如下:

3.1.4 SSE协议
上述等待输出的方式都是等大模型将所以回复生成后再统一返回,而大模型的输出需要一定的时间,用户等待时间过长不太友好。现在普遍的AI平台都是采用流式输出的方式,即数据流,每生成一个字就从服务器推送到客户端进行显示。
要实现流式输出,首先需要了解一下SSE协议。
(1)SSE协议
由于http协议的请求响应模式,客户端向服务器发送请求,服务器向客户端返回响应,而服务器无法主动向客户端发送请求。有时候需要服务器主动将数据推送到客户端,SSE协议核心思想正是如此。
SSE(Server-Sent Events,服务器发送事件)协议是基于http协议设计的轻量级实时通信协议,浏览器通过EventSource API接收处理实时传输的事件。
其具有如下特点:
1.单向通信,只能由服务器向浏览器单向推送,浏览器无法向服务器发送。
2.自动重连:如果浏览器和服务器的连接断开,浏览器会尝试自动重连。
开启SSE协议,需要在请求头设置:
Content-Type: text/event-stream;charset=utf-8
Connection: keep-aliveSSE协议数据格式如下:
data: 消息内容(可多行传输)
id: 事件ID(用于断线重连时定位)
event: 自定义事件类型(如message、end等)
retry: 重连时间(毫秒)该数据格式遵循如下规则:
1.一条消息中,data字段是必须存在的,其它字段是可选字段。
2.消息与消息之间以/n/n分隔,一条消息中可以有多行,每行以/n分隔。
比如:
// 消息1
data: 消息内容\n\n
// 消息2
retry: 5000\n
data: 消息内容\n\n
// 消息3
event: 自定义消息名称\n
data: 消息内容\n\n(2)实现SSE协议
下面四段代码分别实现了:发送消息、发送自定义事件的消息、指定重试时间、发送结束事件(也是自定义事件)的消息。这些消息的内容是当前时间:
@RestController
@RequestMapping("/sse")
public class SSEController {
@RequestMapping("/data")
public void data(HttpServletResponse response) throws IOException, InterruptedException {
// 声明SSE事件流
response.setContentType("text/event-stream;charset=utf-8");
PrintWriter writer = response.getWriter();
String s = "";
// 5个message(只有data)
for (int i = 0; i < 5; i++) {
s = "data: " + new Date() + "\n\n";
writer.write(s);
writer.flush();
Thread.sleep(1000);
}
}
@RequestMapping("/event")
public void event(HttpServletResponse response) throws IOException, InterruptedException {
// 声明SSE事件流
response.setContentType("text/event-stream;charset=utf-8");
PrintWriter writer = response.getWriter();
String s = "";
// 自定义事件的message
for (int i = 0; i < 5; i++) {
s = "event: MyEvent\n" + "data: " + new Date() + "\n\n";
writer.write(s);
writer.flush();
Thread.sleep(1000);
}
}
@RequestMapping("/retry")
public void retry(HttpServletResponse response) throws IOException, InterruptedException {
// 声明SSE事件流
response.setContentType("text/event-stream;charset=utf-8");
PrintWriter writer = response.getWriter();
String s = "";
// 重试功能(5s重试)
s = "retry: 5000\n" + "data: " + new Date() + "\n\n";
writer.write(s);
writer.flush();
}
@RequestMapping("/end")
public void end(HttpServletResponse response) throws IOException, InterruptedException {
// 声明SSE事件流
response.setContentType("text/event-stream;charset=utf-8");
PrintWriter writer = response.getWriter();
String s = "";
// 5个message(只有data)
for (int i = 0; i < 5; i++) {
s = "data: " + new Date() + "\n\n";
writer.write(s);
writer.flush();
Thread.sleep(1000);
}
// 自定义事件实现数据流结束功能
s = "event: end\n" + "data: " + "end-message\n\n";
writer.write(s);
writer.flush();
}
}
对应的前端代码如下:
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>SSE</title>
</head>
<body>
<div id="sse"></div>
<script>
let eventSource = new EventSource("/sse/data");
eventSource.onmessage = function(event){
document.getElementById("sse").innerHTML = event.data;
}
<!-- eventSource.addEventListener("MyEvent", (event)=>{-->
<!-- document.getElementById("sse").innerHTML = event.data;-->
<!-- });-->
<!-- eventSource.addEventListener('end', function() {-->
<!-- eventSource.close();-->
<!-- });-->
</script>
</body>
</html>想监听哪种事件,就需要修改EventSource监听的接口url,同时自定义事件需要添加事件监听对应名称的自定义事件。
注意:由于浏览器的自动重连,即使消息发送完毕,也会重新连接后重新发送消息。想要消息发送结束就终止发送,需要自定义end事件,并在前端监听,如果接收到end事件,就主动调用事件监听器的关闭函数。
访问前端页面,可以显示消息:
3.1.5 流式输出
3.1.4部分已经了解了SSE协议,Spring 5开始支持WebFlux,这可以更高效的实现SSE协议。
(1)流式编程
Flux是流式编程的核心API,也是WebFlux的核心。Flux类似物流中心的传送带,不用等包裹一起打包运输到分类装置,而是由传送带一个一个包裹像水流一样传输。并且,其支持中途修改数据。
FLux的流程如下:
1.创建FLux并设置数据源。
2.使用操作符处理数据。
3.订阅FLux来触发数据流动并消费数据。
public static void main(String[] args) throws InterruptedException {
//创建Flux
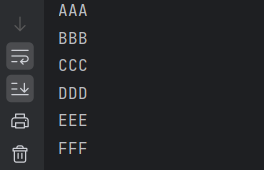
Flux<String> flux = Flux.just("aaa", "bbb", "ccc", "ddd", "eee", "fff")
.delayElements(Duration.ofSeconds(1));
//处理数据
flux.map(String::toUpperCase)
// 订阅数据
.subscribe(System.out::println);
//防止程序处理完之前结束
Thread.sleep(7000);
}FLux创建方式有多种,上述just()是创建了包含7个元素的Flux流,并每延迟1s输出一个数据。
处理数据采用map()将小写字母转为大写字母。
不对flux流进行订阅subscribe,就不会触发数据流动。
由于Flux默认是异步执行方式,启动非阻塞线程执行,因此在主线程需要sleep防止Flux数据流还未处理结束程序就结束。
常见的操作符如下:
| 操作符 | 作用 | 作用示例 | 示例含义 |
| map() | 元素一对一映射 | map(String::toUpperCase) | 元素小写字母转大写 |
| filter() | 条件过滤 | filter(str -> str.length > 10) | 过滤字符串长度小于等于10的元素 |
| take() | 限制元素数量 | take(5) | 获取前5个元素 |
| merge() | 合并Flux(无顺序) |
Flux.merge(Flux.just("aaa"), Flux.just("bbb")) |
合并两个Flux流,如果订阅合并后的Flux流,相当于同时订阅合并前的两个Flux,因此输出顺序不确定。 |
| concat() | 按顺序拼接多个Flux |
Flux.concat(Flux.just("aaa"), Flux.just("bbb")) |
拼接两个Flux流,订阅拼接后的Flux流,相当于先订阅第一个Flux流,待其输出结束后再订阅第二个Flux流。 |
| delayElements() | 元素延迟发射 |
delayElements(Duration.ofSeconds(1)) |
Flux中的元素每延迟1秒流动1个 |
(2)流式输出
在ChatClient中,如果想要开启流式输出,使用stream()方法可以生成流式输出Flux<String>流,效果就是每生成一个数据流就由服务器推送到客户端(这里必须设置编码类型,否则中文就会乱码):
@GetMapping(value = "/stream", produces = "text/html;charset=utf-8")
public Flux<String> stream(String userInput) {
return this.chatClient.prompt()
//用户输入的提示词
.user(userInput)
//请求大模型
.stream()
//返回文本
.content();
}
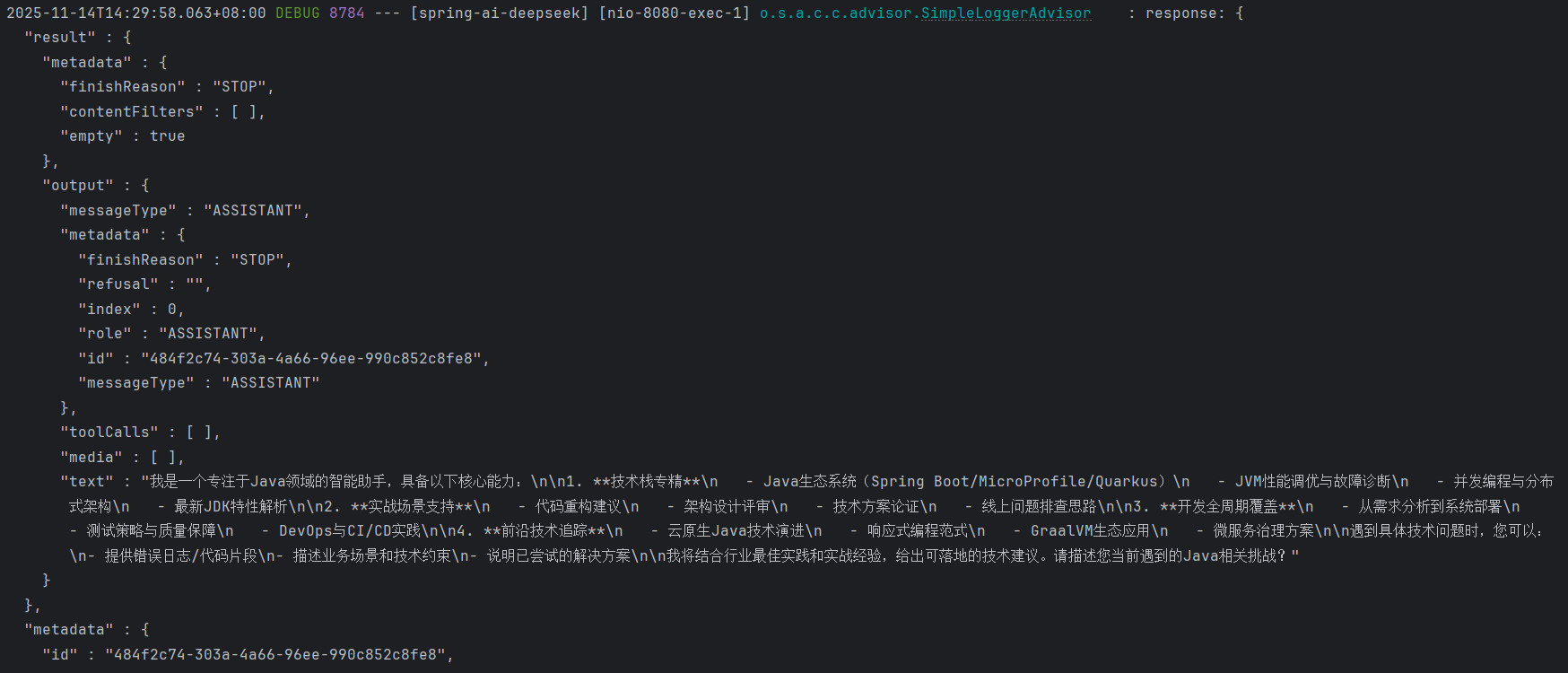
3.1.6 日志打印
如果需要打印与大模型交互的日志信息,就需要用到SimpleLoggerAdvisor(这是Spring AI内置的Advisor之一)。
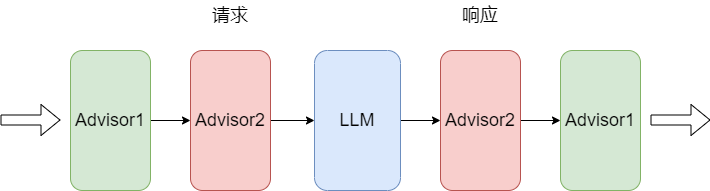
(1)Advisor
Spring AI内置的Advisor是用户请求和大模型之间的中间件组件,主要用于对用户请求和响应进行拦截、过滤和增强。
比如,用户请求发送大模型前,可以对提示词进行敏感词过滤。
Advisor借助AOP思想实现,以链式结构运行,如果有多个advisor,执行顺序如下图所示:
(2)全局日志打印
使用defaultAdvisors()在注册Bean时配置Advisor,这种方式配置的Advisor会在所有使用该chatClient的对话中都执行相同的Advisor:
public ChatClientController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder
//系统提示词
.defaultSystem("你是一个精通Java的工程师,专注于Java领域的前沿技术。")
//系统日志打印(每个使用chatClient都会打印)
.defaultAdvisors(new SimpleLoggerAdvisor())
.build();
}(3)对话日志打印
使用advisors()可以为当前对话配置Advisor,则这种方式只会对该接口发起的对话执行该Advisor:
@GetMapping("/advisor")
public String advisor(String userInput) {
return this.chatClient.prompt()
//用户输入的提示词
.user(userInput)
//对话日志打印(只有当前对话会打印日志)
.advisors(new SimpleLoggerAdvisor())
//请求大模型
.call()
//返回文本
.content();
}注意:如果同时配置defaultAdvisors()和advisors()为相同的Advisor,则advisors()配置的优先执行,defaultAdvisors()配置的后执行。即对话配置优先级更高。
还需配置日志级别,才能看到打印的日志:
logging:
level:
org.springframework.ai.chat.client.advisor: debug
3.2 ChatModel
在接入DeepSeek的案例中,我们已经使用了ChatModel,ChatModel更接近与大模型的直接交互,核心方法是call。
3.2.1 call()
在ChatModel的call方法实现中主要有两种:
default String call(String message) {
Prompt prompt = new Prompt(new UserMessage(message));
Generation generation = this.call(prompt).getResult();
return generation != null ? generation.getOutput().getText() : "";
}
default String call(Message... messages) {
Prompt prompt = new Prompt(Arrays.asList(messages));
Generation generation = this.call(prompt).getResult();
return generation != null ? generation.getOutput().getText() : "";
}
ChatResponse call(Prompt prompt);String call(String message):接收String类型的提示词,对提示词封装为Prompt对象,然后调用 ChatResponse call(Prompt prompt)方法将提示词发送给大模型并等待响应结果,获取结果后会手动将结果转为String类型。
ChatResponse call(Prompt prompt):接收提示词对象Prompt,返回响应ChatResponse,该方法更加底层。
@GetMapping("/callByPrompt")
public String callByPrompt(String message) {
ChatResponse response = openAiChatModel.call(new Prompt(message));
return response.getResult().getOutput().getText();
}
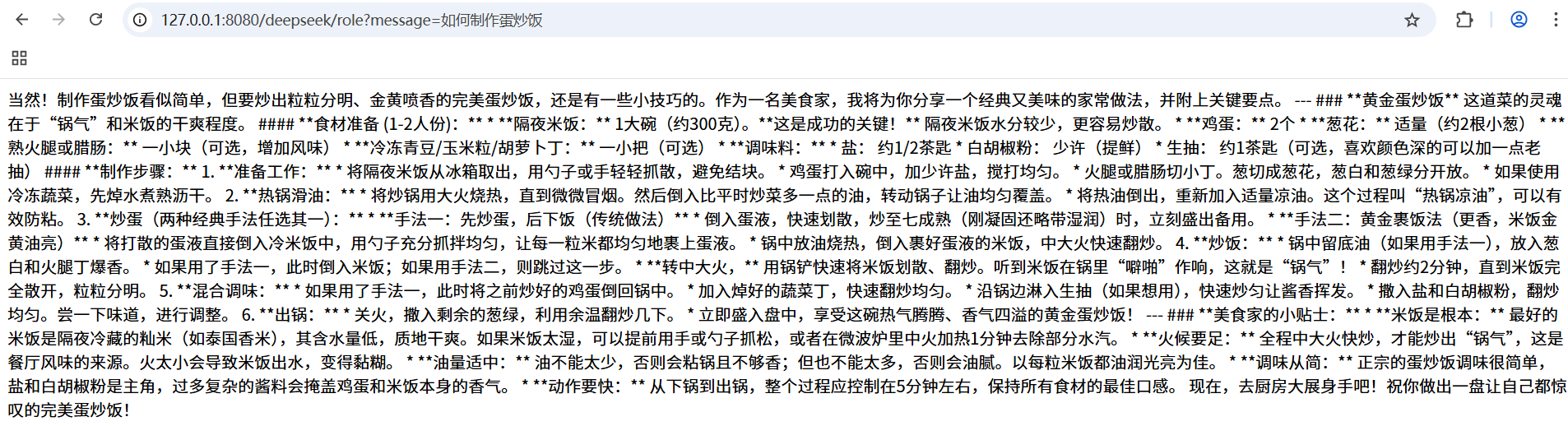
3.2.2 角色预设
ChatModel的角色预设更加复杂,需要自定义系统提示词对象SystemMessage和用户提示词对象UserMessage,并将两个提示词合并为Prompt:
@GetMapping(value = "/role")
public String role(String message) {
SystemMessage systemMsg = new SystemMessage("你是一名专业的美食家,会制作各种菜肴");
UserMessage userMsg = new UserMessage(message);
Prompt prompt = new Prompt(List.of(systemMsg, userMsg));
ChatResponse response = openAiChatModel.call(prompt);
return response.getResult().getOutput().getText();
}
3.2.3 流式输出
流式输出使用ChatModel提供的stream方法:
@GetMapping(value = "/stream", produces = "text/html;charset=utf-8")
public Flux<String> callByStream(String message) {
Flux<ChatResponse> response = openAiChatModel.stream(new Prompt(message));
return response.map(x->x.getResult().getOutput().getText());
}可以看到,每生成一个字,就会在浏览器进行显示:

3.3 ChatClient VS ChatModel
观察ChatClient的构建方法,发现其需要传入ChatModel对象,因此ChatClient对ChatModel进行了进一步的封装和增强:
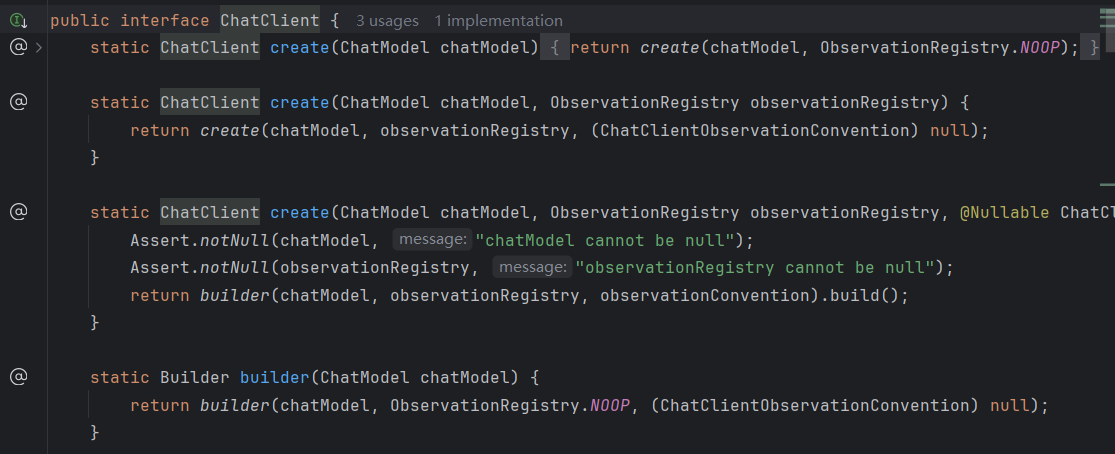
ChatClient和ChatModel的区别如下:
| 对比方面 | ChatModel | ChatClient |
| 交互方式 | 手动构建Prompt对象、增强请求、解析响应 | 链式调用,自动封装请求和解析响应 |
| 输出 | 只能手动解析输出文本 | 支持结构化输出(entity()) |
| 扩展 | 依赖外部组件 | 内置Advisor对象,支持上下文记忆、RAG技术等 |
| 场景 | 依赖模型本身对模型进行微调等场景 | 快速构建AI应用的场景 |
4 Spring AI Alibaba
Spring AI Alibaba 定位开源 AI Agent 开发框架,提供从 Agent 构建到 workflow 编排、RAG 检索、模型适配等能力,帮助开发者轻松构建生成式 AI 应用。并且该框架由于也是阿里系的,与Spring Cloud Alibaba等组件集成也比较方便。
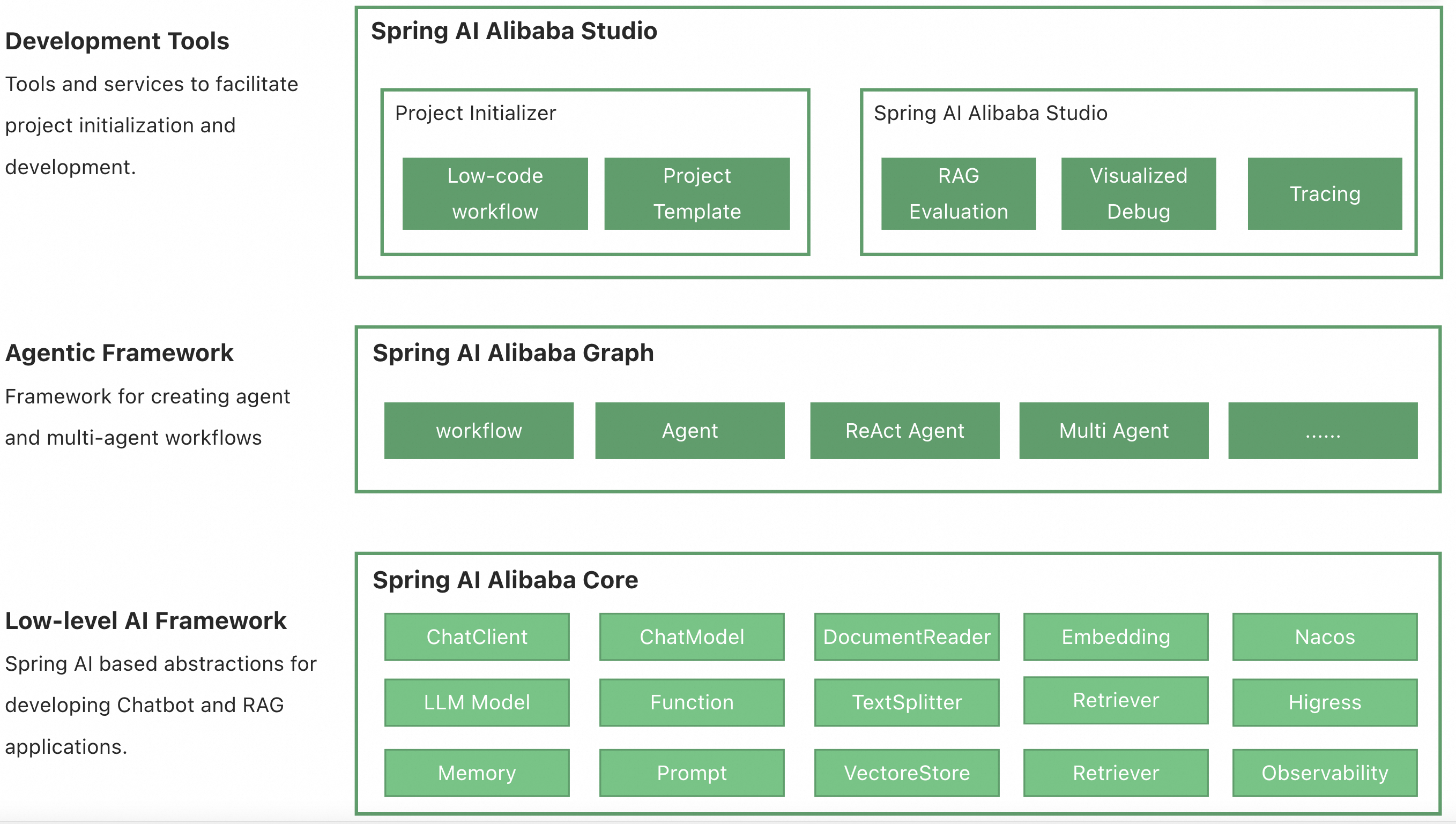
框架提供了如下的功能:
- 提供多种大模型服务对接能力,包括 OpenAI、Ollama、阿里云 Qwen 等
- 支持的模型类型包括聊天、文生图、音频转录、文生语音等
- 支持同步和流式 API,在保持应用层 API 不变的情况下支持灵活切换底层模型服务,支持特定模型的定制化能力(参数传递)
- 支持 Structured Output,即将 AI 模型输出映射到 POJOs
- 支持矢量数据库存储与检索
- 支持函数调用 Function Calling
- 支持构建 AI Agent 所需要的工具调用和对话内存记忆能力
- 支持 RAG 开发模式,包括离线文档处理如 DocumentReader、Splitter、Embedding、VectorStore 等,支持 Retrieve 检索
4.1 快速上手
4.1.1 获取API key
首先需要前往阿里云百炼平台获取API key:
阿里云百炼![]() https://bailian.console.aliyun.com 登录后开通大模型服务,在左侧点击密钥管理:
https://bailian.console.aliyun.com 登录后开通大模型服务,在左侧点击密钥管理:
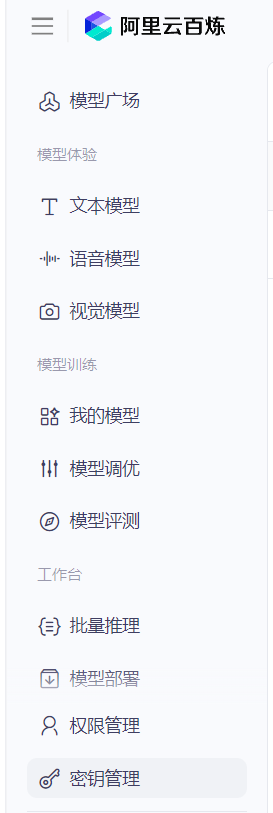
然后创建API key并保存。
4.1.2 引入依赖
需要引入的核心依赖是spring-ai-alibaba-starter:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter</artifactId>
<version>1.0.0-M6.1</version>
</dependency>
</dependencies>4.1.3 配置文件
在配置文件中添加api-key的配置项:
server:
port: 8081
spring:
application:
name: spring-ai-alibaba
ai:
dashscope:
api-key: 百炼平台的API key
logging:
pattern:
console: "%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n"
file: "%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n"4.1.4 代码实现
由于百炼平台已经部署好了大模型,因此我们可以直接调用。调用方式同Spring AI(Spring AI Alibaba是基于Spring AI实现的):
@RequestMapping("/ai/alibaba")
@RestController
public class AlibabaController {
private static final String DEFAULT_PROMPT = "你是一个精通AI算法的工程师,请结合角色进行回答";
private final ChatClient chatClient;
public AlibabaController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder
.defaultSystem(DEFAULT_PROMPT)
.defaultAdvisors(new SimpleLoggerAdvisor())
.build();
}
@GetMapping("/chat")
public String chat(String message) {
return chatClient.prompt(message).call().content();
}
}
ChatClient用法和Spring AI一致,不再赘述。
4.2 多模态
多模态是指模型能接收多种模态的数据的能力,比如图片、音频、文本等等。模型的多模态能力体现了综合能力,因为依靠多种模态的数据,更能全面分析、处理和解决用户问题。
如果想要应用层实现多模态的AI应用,就需要使用有多模态能力的大模型。
4.2.1 引入依赖
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
<version>1.0.0.2</version>
</dependency>注意:该依赖与spring-ai-alibaba-starter包(版本更老)存在依赖冲突,因此需要排除spring-ai-alibaba-starter包。
4.2.2 配置文件
需要在配置文件添加具有多模态功能的大模型,具体可以去百炼平台查询:
spring:
application:
name: spring-ai-alibaba
ai:
dashscope:
api-key: 阿里云百炼平台api key
chat:
options:
model: qwen-vl-max-latest #模型名称
multi-model: true #是否启用多模型4.2.3 代码实现
下面使用如下图片进行测试:

将图片转化为List<Media>对象,并与用户提示词拼接得到输入的数据,然后输入模型得到返回响应:
@GetMapping("/image")
public String image(String prompt) throws Exception {
// 图片的网络路径
String url = 图片路径;
// 将图片网络路径转化并放到list中
List<Media> mediaList = List.of(new Media(MimeTypeUtils.IMAGE_PNG, new URI(url).toURL().toURI()));
// 用户提示词和图片拼接
UserMessage message = UserMessage.builder().text(prompt).media(mediaList).build();
ChatResponse response = chatClient
.prompt(new Prompt(message))
.call()
.chatResponse();
return response.getResult().getOutput().getText();
}可以看到,模型能结合用户的输入文本和图片综合分析图片内容,结果如下:


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)