面向动态环境的多目标优化智能体自学习调参的演进模型【附代码】
在真实业务或自主决策型 Agent 系统中,智能体往往并非只追求单一目标。例如:无人机需要兼顾任务收益、能源消耗、安全风险;推荐系统需要平衡用户体验、商业转化、内容多样性;智能客服需要同时满足响应速度、答案准确度、用户情绪稳定性。这些目标之间往往存在天然冲突,导致无法单纯依赖固定的权重体系来求解最优策略。
面向动态环境的多目标优化智能体自学习调参的演进模型【附代码】
在真实业务或自主决策型 Agent 系统中,智能体往往并非只追求单一目标。例如:无人机需要兼顾任务收益、能源消耗、安全风险;推荐系统需要平衡用户体验、商业转化、内容多样性;智能客服需要同时满足响应速度、答案准确度、用户情绪稳定性。这些目标之间往往存在天然冲突,导致无法单纯依赖固定的权重体系来求解最优策略。
我个人认为,多目标优化的难点不在于目标数量的增加,而在于权衡关系的动态性和上下文依赖性。因此,本篇文章讨论的是一种更贴近实际工程的解决方法:动态权重调整策略(Dynamic Weight Adjustment, DWA)。
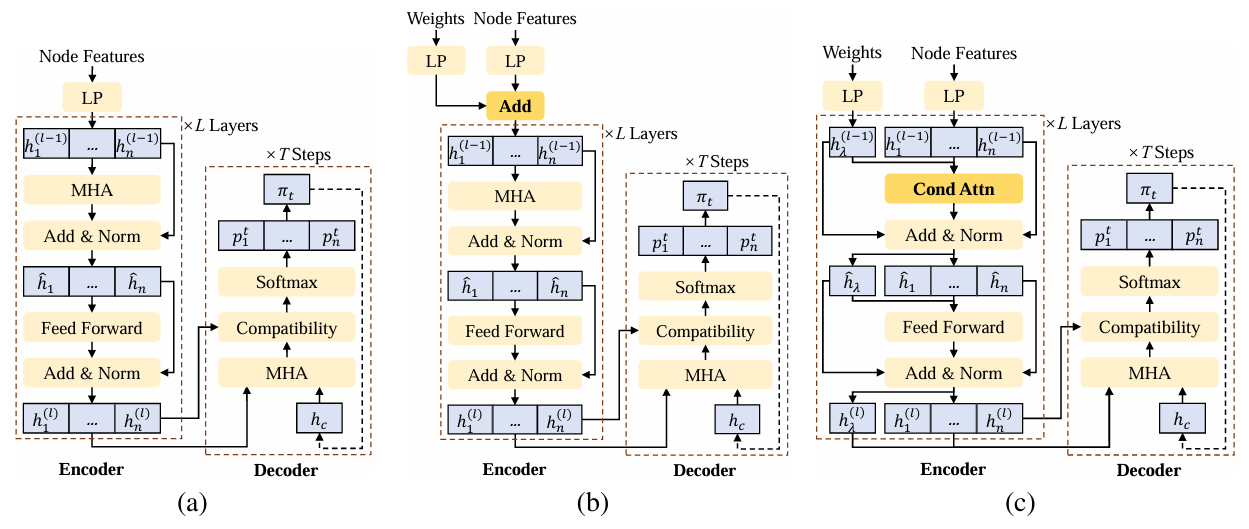
一、为什么固定权重不可行?
传统多目标方法通常采用线性加权方式:
总目标 = w1 * A + w2 * B + w3 * C
但在真实系统中可能出现以下问题:
- 场景变化快:用户状态、环境信息、风险等级随时变化,固定权重无法适配。
- 目标间存在阶段性主次关系:如节能优先还是性能优先取决于电量是否充足。
- 实时反馈信息必须进入优化循环:策略效果应该影响下一轮权重,而不是独立存在。
换句话说,智能体真正需要的不是一个公式,而是动态博弈式权衡机制。
二、动态权重调整的常用策略(工程实践视角)
我把它总结为以下三类,可独立使用或混合使用:
| 策略类型 | 核心思路 | 适用场景 |
|---|---|---|
| 性能变化驱动 | 根据每轮目标达成率调整权重 | 训练/迭代型智能体(RL、AutoML) |
| 环境与状态驱动 | 根据上下文环境动态切换权重 | 真实物理环境或实时系统 |
| 用户或业务策略驱动 | 根据 KPI 和 SLA 自动调整 | 企业级平台与推荐系统 |
在实际落地中,我比较推荐状态驱动 + 性能驱动的混合方案,既兼顾系统稳定性,又能具备自适应能力。
三、基于性能反馈的动态权重示例
思路:每一轮优化后,如果某个目标表现不佳,则适当提升其权重;反之降低。
实战代码示例(Python)
以下示例使用一个简单任务:智能体需要同时最小化时间消耗和成本支出,并对权重进行动态反馈调整。
import random
class MultiObjectiveAgent:
def __init__(self, w_time=0.5, w_cost=0.5, lr=0.1):
self.weights = {"time": w_time, "cost": w_cost}
self.lr = lr
def evaluate(self):
# 模拟性能结果(越小越好)
result = {
"time": random.uniform(0.1, 1.0),
"cost": random.uniform(0.1, 1.0)
}
return result
def adjust_weights(self, result):
total = sum(result.values())
normalized = {k: v / total for k, v in result.items()}
# 根据表现动态调整(表现越差权重越高)
for k in self.weights:
adjustment = self.lr * normalized[k]
self.weights[k] += adjustment
# 归一化
total_w = sum(self.weights.values())
for k in self.weights:
self.weights[k] /= total_w
def run(self, rounds=10):
for step in range(rounds):
result = self.evaluate()
self.adjust_weights(result)
print(f"Step {step+1}")
print(f" Performance: {result}")
print(f" Adjusted Weights: {self.weights}")
print("-"*40)
if __name__ == "__main__":
agent = MultiObjectiveAgent()
agent.run(10)
输出分析思路
当某个目标表现持续较差时,其权重会逐渐提高,促使智能体系统在下一轮更倾向于优化此目标,从而形成自适应的目标平衡机制。
虽然示例为简化模型,但和企业级调参逻辑一致:用反馈信息驱动资源配置优先级变动。
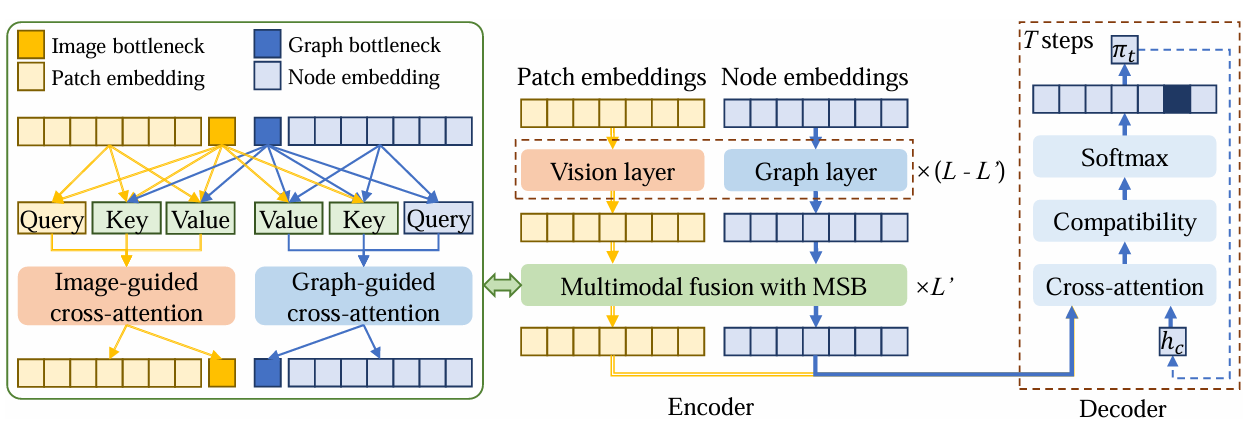
四、工程化落地的思考与建议
我在经验中发现,动态权重策略在实际项目部署时需要注意以下几点:
- 不要过度追求实时性
权重每次变化过大可能导致智能体策略震荡,可增加滑动平均或模糊逻辑。 - 可以设置硬约束区间
一些安全性目标不能被下降到过低,可以设最小阈值。 - 考虑用户感知权重,而非纯数学最优
用户体验是非线性的,稍微偏差也可能导致满意度骤降。 - 权重可以成为模型训练的超参数,而非固定参数
把它当作学习目标的一部分,而不是外部设定值。
五、动态权重策略的系统化设计框架(从策略走向架构)
如果把动态权重调整看作一个功能点,往往只停留在代码层面;但如果把它视作智能体核心决策模块之一,我们需要构建更完整的架构。我的经验是,可以将其抽象为四层结构:
┌──────────────────────┐
│ 4. 策略执行层 (Policy Layer) │ ← 基于动态权重输出最终策略
├──────────────────────┤
│ 3. 评估反馈层 (Evaluation Layer) │ ← 收集任务表现、环境状态、风险指数
├──────────────────────┤
│ 2. 权重调控层 (Weight Adaptation) │ ← 动态调整并归一化权重
├──────────────────────┤
│ 1. 目标定义层 (Objective Layer) │ ← 明确目标、约束与优先级底线
└──────────────────────┘
这个框架能确保系统不是“凭感觉地调权重”,而是有输入、有计算、有反馈、有验证的闭环结构。
推荐的工程化实践规则
| 规则 | 含义 | 实践建议 |
|---|---|---|
| R1 | 所有目标必须可指标化 | 转化为可测量、可量化结果值 |
| R2 | 权重变化必须可解释 | 保存变更日志用于审计分析 |
| R3 | 调整不超过安全区间 | 避免短期波动导致策略漂移 |
| R4 | 权重 ≠ 优先级 | 可再引入元优先级做兜底 |
尤其是 R4,这是许多人忽视的 —— 两个目标权重相同,不代表优先级相同,比如安全永远高于收益。
六、引入环境驱动的权重切换机制(状态机建模)
在许多实时系统中,权重不仅需要动态变化,还要根据状态进行阶段性切换。一种有效方法是将其设计成有限状态机(Finite State Machine, FSM)。
示例:无人机任务状态权重模型
| 状态 | 描述 | 主目标 | 次级目标 | 权重策略 |
|---|---|---|---|---|
| 起飞阶段 | 系统初始上升 | 安全 | 稳定性 | 安全最大化 |
| 任务巡航 | 执行路径规划 | 能耗 / 时间 | 稳定性 | 反馈驱动动态权重 |
| 电量告警 | < 30% 电量 | 能源 | 安全返回 | 能耗权重急速上升 |
| 紧急状况 | 风险触发 | 安全 | 其他全部放弃 | 强制切换策略 |
这种结合状态机的动态权重策略,本质上是让系统从“自动拟合”进化到自主决策策略切换”。
状态驱动代码
class WeightManager:
def __init__(self):
self.weights = {"safety": 0.4, "efficiency": 0.4, "energy": 0.2}
def update_state(self, battery, risk):
if risk > 0.7:
return "emergency"
if battery < 0.3:
return "low_power"
return "normal"
def adjust_by_state(self, state):
if state == "emergency":
self.weights = {"safety": 1.0, "efficiency": 0.0, "energy": 0.0}
elif state == "low_power":
self.weights = {"safety": 0.3, "efficiency": 0.1, "energy": 0.6}
else: # normal
pass # 沿用动态调整权重流程
return self.weights
核心思想:动态策略 ≠ 全局连续变化,而是分阶段精准控制。
七、如何为动态权重引入“学习能力”:元策略思想
目前很多动态权重方案依然是手动规则 + 简单反馈,未真正智能化。更进一步的方向是引入Meta-Policy(元策略),让权重不仅影响智能体行为,还能被学习、被优化。
可能的学习机制包括:
- 强化学习(RL)驱动的权重自适应
- 基于奖励差异的反向调节机制
- 使用策略梯度更新权重区间
- 利用历史轨迹拟合权重演变模型
Python 简易元学习代码
history = []
def meta_update(weights, performance):
history.append((weights.copy(), performance))
if len(history) > 5:
recent = history[-5:]
trend = sum([p["reward"] for _, p in recent]) / 5
if trend < benchmark:
# 自动提升探索性
for k in weights:
weights[k] += random.uniform(-0.05, 0.05)
# 归一化
total = sum(weights.values())
for k in weights:
weights[k] /= total
return weights
这段逻辑虽然简化,但体现了核心思想:
不仅优化目标,更优化目标之间的关系。
八、从单体智能体到协同智能体(Multi-Agent)
在分布式智能体系统中,不同Agent之间可能目标不同,甚至互斥,例如:
- 能源调度系统:发电方与调度方目标冲突
- 联盟推荐系统:商业方与用户方指标冲突
- 机器人协同:局部最优与全局最优冲突
此时,动态权重不仅作用于单体智能体,还可能上升为群体协商协议,可采用:
| 方法 | 核心思想 | 工程价值 |
|---|---|---|
| 博弈论 | 均衡点决策 | 严谨但复杂 |
| 协同 RL | 学习群体最优策略 | 自适应性强 |
| 共识协议 | 限定可接受区间 | 工程成本低 |
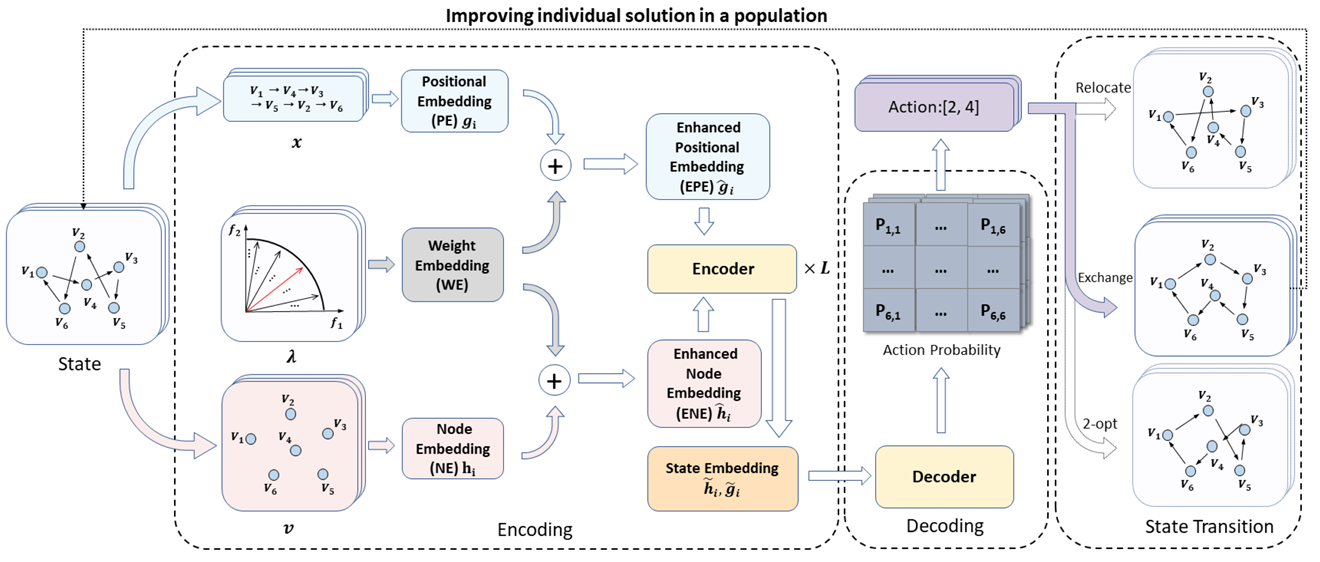
总结
在智能体从“执行式自动化”向“自主性决策体”演进的过程中,多目标冲突是绕不过的核心挑战。真正的难点并不是目标数量、优化方法或计算能力,而是如何让智能体在动态环境中持续保持合理的目标平衡感,并具备自适应调整能力。
本文所讨论的动态权重策略,本质是一种面向现实复杂性的工程思路:不再把目标关系视为静态参数,而是让系统具备“权衡-反馈-再平衡”的智能循环机制。通过性能反馈、环境状态、策略阶段与元学习,将权重从配置项提升为可学习、可解释且可演化的决策变量,让智能体的行为更像一个成熟决策者,而不是被动执行器。
我个人认为,这一方向的最终落点不会停留在权重本身,而是指向以下三个未来能力:
-
目标理解能力(Goal Reasoning)
智能体不仅知道要做什么,还能判断“什么时候该重视什么”。 -
策略弹性能力(Policy Adaptiveness)
面对变化不是“固守”,而是“策略性调整”。 -
价值观一致性(Value Alignment)
在复杂目标下坚持底线原则与长期目标,而非短期最优。
当智能体能自洽地处理目标冲突,它才真正迈向具备智能性、稳健性与可信度的下一层级。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)