OmniVTLA论文学习
欢迎交流。
项目链接:OmniVTLA: Vision-Tactile-Language-Action Model
1.引言
触觉感知是人类灵巧操作能力的基础,使我们能够以惊人的精确性和适应性完成从穿针到处理易碎物品等复杂任务。尽管视觉能够提供整体的空间信息,但触觉感知具有互补优势:可直接测量接触动态(如压力分布、纹理),在视觉遮挡情况下依然可靠,并提供可用于实时控制的高频反馈(Dahiya et al., 2009)。这些生物学证据凸显了视觉—触觉融合在涉及物理交互的复杂操作任务中的关键作用。
在机器人领域,视觉与触觉感知的融合已成为提升操作能力的一个有前景的方向(Cui and Trinkle, 2021)。早期研究(Calandra et al., 2018;Li et al., 2018;Qi et al., 2023;Huang et al., 2024)主要关注小规模模型,通过结合视觉和触觉特征来解决特定任务,例如滑动检测或抓取稳定性预测。尽管这些方法证明了多模态感知的价值,但其适用范围有限,通常面向高度专用的应用,且难以在多样化的场景中实现泛化。
近年来,视觉-语言-动作(Vision-Language-Action, VLA)模型的发展(Brohan et al., 2023a; Kim et al., 2024a; Black et al., 2024; Team et al., 2025)极大推动了机器人操作能力的提升。这类模型利用大规模预训练视觉语言模型(VLMs)(Liu et al., 2023; Li et al., 2024; Zhang et al., 2025a; Bai et al., 2025)来理解自然语言指令和视觉观测,展现出很强的泛化潜力与智能性。然而,这些模型主要依赖视觉和语言,忽略了触觉所提供的丰富语义和物理反馈。现有尝试(Zhang et al., 2025b; Huang et al., 2025; Yu et al., 2025)在将触觉融入VLA框架时,大多将触觉数据视作低层信号,未能在语义层面将其与视觉与语言信息对齐。
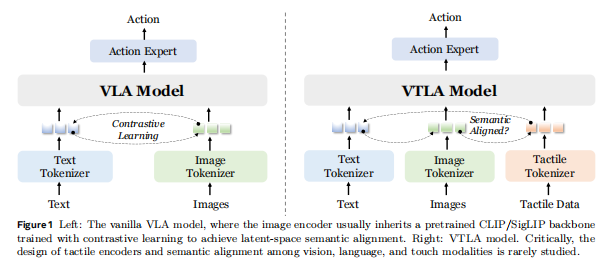
为弥补这一缺口,我们提出 OmniVTLA(Vision-Tactile-Language-Action Model),一种将视觉、触觉与语言统一到共享语义空间中的新型架构,如图1所示。VTLA 利用对比学习将高分辨率触觉信号与视觉和语言概念进行对齐,使机器人能够在“看到什么”和“被要求做什么”的语境下“理解自己触摸到了什么”。具体来说,我们提出了一条用于触觉数据的双编码器路径,以应对模态异质性,其中包括一个预训练视觉 Transformer(ViT)以及一个语义对齐的触觉 ViT(SA-ViT)。其次,我们构建了 ObjTac 数据集,涵盖 10 类共 56 个物体的文本、视觉与基于力的触觉数据,总计 135K 三模态样本。第三,我们利用跨传感器数据训练了一个语义对齐的触觉编码器,以学习统一的触觉表示,并作为 OmniVTLA 的更优初始化。
大量实验表明,VTLA 在性能上显著优于 VLA 基线方法。在搬取与放置任务中,VTLA 在夹爪执行中将成功率提高了 21.9%(达到 96.9%),在灵巧手执行中提高了 6.2%(达到 100%)。此外,VTLA 生成的轨迹更加平滑,符合直觉上的运动原则:“在环境开阔时快速移动,接触物体前才放慢速度。”
我们的贡献总结如下:
-
我们提出了 OmniVTLA,一个用于端到端高接触操作任务的全新框架,将视觉、触觉与语言统一建模。OmniVTLA 使用双编码器路径来克服不同触觉传感器之间的异质性问题。
-
我们构建了 ObjTac 数据集,一个全面的触觉数据集,包含 10 个类别、56 个物体的 135K 三模态样本。在此基础上,我们为 OmniVTLA 训练了一个语义对齐的触觉编码器。
-
真实世界实验表明,OmniVTLA 的性能显著优于典型的 VLA 模型,成功率最高提升 21.9%。此外,它还能减少任务完成时间,并使生成的轨迹更加平滑。
2.相关工作
触觉感知在感知任务中的应用
早期的触觉感知研究主要聚焦于处理低层物理信号(如力、振动、形变),以解决特定的感知任务,例如抓取稳定性预测(Calandra et al., 2018; Cui et al., 2020)和滑动检测(Li et al., 2018)。近期的工作逐渐转向学习更具泛化性的触觉表示,使其能够在任务、传感器和模态之间迁移。这些工作通过构建数据集(Fu et al., 2024; Cheng et al., 2025)、建立共享嵌入空间(Yang et al., 2024)、开发可迁移架构(Zhao et al., 2024)以及提出统一建模框架(Feng et al., 2025),展示了跨模态对齐和可泛化表示在触觉感知中的重要性。尽管这些方法提升了触觉感知能力,但它们仍然与动作策略的生成脱节,从而限制了其在机器人实时控制中的应用。此外,现有大多数研究使用基于视觉的触觉数据(如 GelSight(Yuan et al., 2017; Johnson and Adelson, 2009)),而对在机器人策略学习中同样常用的基于力的触觉数据关注较少。
视觉-触觉融合在操作任务中的研究
近年来,视觉-触觉策略学习在高接触操作中取得了显著进展。强化学习框架已被有效应用于将视觉与触觉输入结合用于装配任务(Lee et al., 2020; Hansen et al., 2022)以及灵巧手的手内操控(Hu et al., 2025)。更近期的趋势则倾向采用模仿学习范式(Yu et al., 2023; Lin et al., 2024; Huang et al., 2024; Xue et al., 2025; Liu et al., 2025),研究用于精细操作的视觉-触觉表示和系统架构。尽管这些方法在特定任务中获得了令人印象深刻的表现,但与视觉-语言-动作模型相比,它们在语义推理和泛化能力方面仍然存在局限。这一领域的不足正是我们的工作希望通过视觉-触觉语义融合来弥补的。
视觉-语言-动作模型
视觉-语言-动作(VLA)模型近年来成为构建通用机器人策略的重要范式。Brohan et al. (2023b) 率先提出将机器人动作表示为语言 token,从而实现来自网络规模预训练知识的迁移。Kim et al. (2024b) 通过 LoRA 微调提出了高效迁移的开源替代方案。随后的一系列研究(Team et al., 2024; Black et al., 2024; Liu et al., 2024; Bjorck et al., 2025)进一步扩展了该能力,引入基于 flow 或 diffusion 的动作生成方法(Chi et al., 2023)。在可扩展性(Wen et al., 2025; Team et al., 2025; Shukor et al., 2025)、推理机制(Zhao et al., 2025; Lin et al., 2025)以及三维扩展(Zhen et al., 2024; Qu et al., 2025)等方面的努力进一步增强了其适用性。
尽管 VLA 模型在开放世界泛化方面表现卓越,但其仅依赖视觉与语言,使其在需要高精度物理交互的高接触任务中表现受限。新兴的触觉增强方法尝试缓解这些限制,包括基于语言的传感器融合(Jones et al., 2025)、触觉参与的 VLA 学习(Hao et al., 2025; Zhang et al., 2025b)以及低维度力觉增强控制(Huang et al., 2025; Yu et al., 2025)。然而,这些方法尚未充分探索触觉编码器的设计。
我们的 OmniVTLA 框架在这一范式上实现了重要突破,通过统一的跨模态表示学习,为触觉建立了双编码器路径,从根本上推进了触觉在 VLA 系统中的融合方式。
3.方法
3.1 问题表述(Problem Formulation)
形式上,动作模型的目标是对分布进行建模(应该指的是对数据进行建模),其中
表示对应的动作序列(H为动作块的长度),而
表示当前时刻的观测。
对于典型的 VLA 模型,观测通常包括若干 RGB 图像、语言提示以及机器人自身状态(proprioceptive state)。此时模型可形式化表示为:
其中表示第
个图像(例如第三视角图像或机械臂腕部相机图像),
是语言 token 序列。通常,图像
会使用对比式图像编码器
(如 CLIP、SigLIP)编码,该编码器一般基于 Vision Transformer(ViT)(Dosovitskiy et al., 2020),并投射至与文本 token 共享的潜在嵌入空间。
(MVLA(⋅)表示整个 VLA 模型)
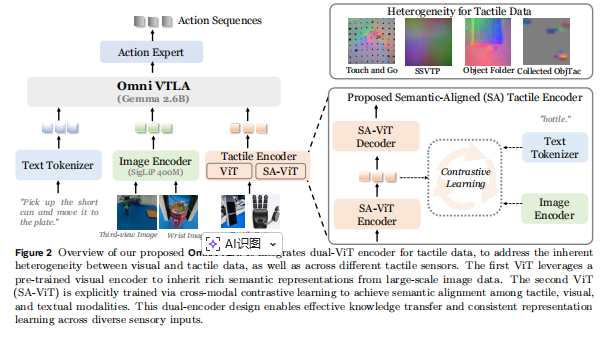
(“我们提出的OmniVTLA概述。它集成了用于触觉数据的双ViT编码器,以解决固有的视觉和触觉数据之间以及不同触觉传感器之间的异质性。第一个ViT利用了预训练的视觉编码器,从大规模图像数据中继承丰富的语义表示。第二个ViT(SA-ViT)通过跨模态对比学习进行显式训练,以及文本形式。这种双编码器设计实现了有效的知识传递和一致的表示跨多种感官输入进行学习”
图片中所述的两个vit编码器,第一个指VTLA-Pre,第二个为VTLA-SA(见3.3))
相比之下,我们的 VTLA 模型目标是将触觉数据也纳入输入,如图 2 所示。其模型形式为:
其中 表示第
个触觉数据源,例如安装在双指夹爪指尖的触觉传感器,或灵巧手多个手指与手掌的触觉传感器。
表示触觉编码器。
直观来看,可以将触觉数据重新映射为张量,并借用类似 ViT 的结构按“图像方式”进行编码,但触觉数据的特性与视觉数据显著不同。因此,本研究的目标是探索不同的触觉编码器及其训练策略,以确定 VTLA 的最佳架构。
3.2 具有双编码器路径的整体架构
如图 2 所示,所提出的 OmniVTLA 架构构建于 π0(Black et al., 2024)的基础之上。它由三个核心组件组成:tokenizer(分词器)、**backbone(骨干网络)**以及 action head(动作头)。
分词器负责处理三类输入:
-
使用 PaliGemma tokenizer(词表大小:257,152)对语言指令
进行处理;
-
使用 SigLIP 模型(Zhai et al., 2023)编码图像观测
;
-
对触觉观测
进行编码,将所有模态映射到潜在 token 空间。
具体而言,对于图像(包括第三视角和腕部视角),我们将原始图像调整为 224 × 224 的分辨率,每张图像生成 256 个 token。对于触觉数据,我们将值域归一化到 int8,并将多个触觉传感器的输出拼接成单张图像,再通过 ViT 类似的编码器处理为 224 × 224 的输入,生成 256 个 token。(把触觉信号“仿照图像格式”组织起来,方便使用 ViT 进行编码,触觉数据 → 拼接图像 → ViT → token)
之后,Gemma-2B 的 backbone 处理拼接后的多模态 token,生成动作 token,再由 action head 通过 flow matching 损失(与 π0 一致)解码为最终动作。
动作表示依执行器类型而异:
-
对于双指夹爪,用 10 个 token 表示(3 个相对位置、6 个相对角度、1 个夹爪状态);
-
对于四指机械手,用 25 个 token 表示(3 个相对位置、6 个相对角度、16 个绝对关节角)。
触觉编码器设计中的关键挑战
现有工作未充分重视触觉编码器的设计,主要由于触觉数据存在两类异质性:
-
触觉与视觉数据之间的差异
-
不同触觉传感器之间的差异(图 2 左上角给出了示例)
此外,不同触觉数据集(如 TAG (Yang et al., 2022)、SSVTP (Kerr et al., 2023)、ObjectFolder (Gao et al., 2021))之间的数据形式差异很大,使得统一的触觉编码器设计更加困难。
因此,我们探索了四种不同的触觉编码器,其详细实验结果在 Sec. 4.2 中给出:
-
VTLA-FS:从零开始训练触觉编码器,仅依赖有限的遥操作触觉数据。
-
VTLA-Pre:用大规模视觉数据预训练模型初始化触觉编码器,并在少量遥操作数据上微调。
-
VTLA-SA:先基于跨模态对比学习进行语义对齐训练(见 Sec. 3.3),再在少量数据上微调。
-
OmniVTLA:使用双编码器路径,其中一条为 VTLA-Pre,另一条为 VTLA-SA。
触觉传感器异质性的原因
触觉传感器因原理不同而产生明显差异:
-
视觉型触觉传感器(如 GelSight (Yuan et al., 2017; Johnson & Adelson, 2009))
→ 捕获高分辨率的表面形貌,但时间分辨率较低(最多约 30Hz) -
基于力的触觉传感器(如 Paxini Gen2 (Paxini, 2025))
→ 空间分辨率较低,但时间分辨率高(适合捕捉快速接触事件)
因此,力类触觉传感器能够有效补充视觉模态的信息。
为了处理不同触觉传感器之间的异质性,我们提出了双 ViT 编码器(dual-encoder path),通过拼接其输出 token,使模型能够实现跨传感器理解。这构成了 OmniVTLA 中触觉编码器的重要组成部分。

3.3 语义对齐触觉编码器(Semantic-Aligned Tactile Encoder)
尽管已有工作(Feng et al., 2025)探索了视觉-触觉传感器的统一表示,但其方法难以推广到基于力的触觉感知。如表 2 所示,预训练的 AnyTouch 编码器在基于力的数据集上仅取得 40.21% 的材质分类准确率,显示出严重的跨传感器迁移限制。
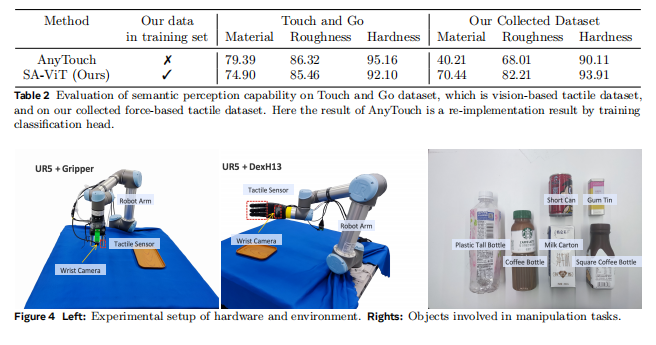
为解决这一问题,我们构建了自有数据集 ObjTac,其中包含对齐的文本、视频和力觉触觉数据。我们为 56 个不同物体收集了触觉-视觉配对数据,如图 3 所示。最终数据集包含 10 种物体类型(塑料、玻璃、木材、砖块、金属、织物、皮革、陶瓷、纸张及其他),并按表面粗糙度(粗糙 vs 光滑)和材料硬度(刚性 vs 柔软)进行分类。我们收集的数据集将于近期公开发布。
数据采集与处理流程
-
交互实验:
每个物体进行 2–5 次交互试验,每次 10–60 秒(采样率 60 Hz),共获得 270,000 条力觉数据记录。
同时采集第一视角视频,分辨率 720P,帧率 30 FPS,共得到 252 条视频序列,平均时长 18 秒。
最终收集 135K 样本,每个样本包含配对的触觉与视觉数据。 -
语言注释:
对每个物体添加对象级别的注释,包括:物体名称、材料类型、粗糙度类别、硬度类别、视频级元数据以及文本描述。 -
时间同步:
使用时间戳对视觉和触觉模态进行同步对齐。
语义对齐编码器训练
为了训练更优的语义对齐触觉编码器,我们将 ObjTac 数据集与现有数据集合并,并采用 AnyTouch 的二阶段训练流程(Feng et al., 2025),实现多模态和跨传感器对齐。
由于我们的数据集包含三模态数据对,对于新增数据,我们直接使用总对齐损失:
其中:
-
表示单批次内从视觉到语言的损失(参考 CLIP (Radford et al., 2021))
-
,
,
为超参数
-
另外,还将 跨传感器匹配损失(binary cross-entropy) 纳入总损失
效果与意义
通过加入 ObjTac 数据集,这个语义对齐触觉编码器能够更好地适应实际使用的触觉传感器,并在视觉与语言语境中对触觉信号(如材质、粗糙度、硬度)进行语义对齐。
如表 2 所示,SA-ViT 在基于力的触觉数据集上实现了显著更高的分类准确率,同时在视觉触觉数据集(Touch and Go)上保持了接近基线的性能。
4.实验
4.1基线模型与训练细节
我们将 VTLA 模型与两个基线模型进行了比较:Diffusion Policy(DP)(Chi 等,2023)作为非 VLM 基线,以及 π0(Black 等,2024)作为 VLA 基线。我们按照代码库中默认设置训练 DP 和 π0 模型,但将 DP 的 chunk 动作大小设置为 64。对于我们的 OmniVTLA 模型,我们增加了触觉图像输入。更多训练细节可见附录。
实现与任务设置
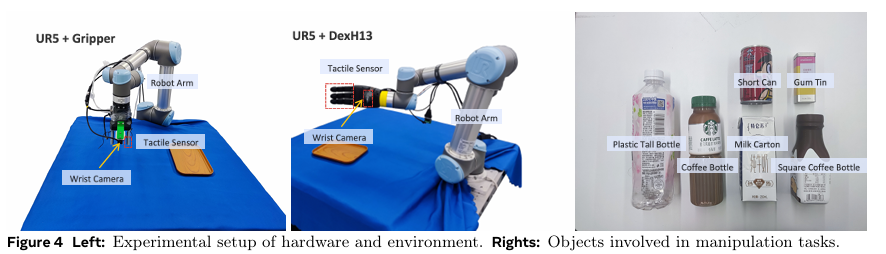
我们的机器人系统包括一台 UR5 机械臂、一个配备两个触觉传感器和手腕摄像头的爪式夹持器、一个配备 11 个触觉传感器及手腕摄像头的灵巧手,以及一个底座摄像头(见图 4)。我们使用爪式夹持器完成四个物体(短罐、方形咖啡瓶、口香糖罐、牛奶盒)的抓取-搬运任务,使用灵巧手完成两个物体(咖啡瓶和牛奶盒)的抓取-搬运任务(见图 4),每个物体收集 40 个远程操控示范回合,采样频率为 30 Hz。塑料瓶和方形瓶被作为未见物体用于泛化评估。我们通过最大-最小力归一化处理触觉数据,并将其重塑为 3 通道张量,从而得到 3 通道图像表示。
为了研究触觉反馈在任务执行中的作用,我们设计了多阶段抓取协议。不同于传统方法,我们的方法允许最多三次递进式抓取尝试。具体而言,当夹持器接近目标物体时,它在三个阶段逐步闭合,在第三次尝试时实现成功抓取。抓取完成后,机械臂将物体抬起并运输到预设目标位置。为了公平评估,我们使用网格地图标准化初始物体姿态,并对每个模型进行了 32 次爪式夹持器测试回合和 16 次灵巧手测试回合(每个初始状态执行 2 次试验,每个物体覆盖 4 个网格位置)。每次试验的最大评估步数设为 1500。
评估指标
我们通过两种互补的方法评估了所提出的方法:离线验证和真实环境实验。对于离线验证,我们计算离线预测状态与真实远程操控数据之间的均方误差(MSE):
其中 表示总时间步数,
(真实值)和
(预测值)分别表示由末端执行器位置(xyz)、6 维旋转表示(Zhou 等,2018)以及爪式夹持器开度或灵巧手的 16 个绝对关节组成的 10 维或 25 维状态向量。
对于真实环境评估,我们采用三项指标:
-
成功率(Success Rate, SR):衡量在最终时间步成功放置物体的比例;
-
完成时间(Completion Time, CT):从任务开始到夹持器成功打开并完成物体放置的时间;
-
运动平滑度(Motion Smoothness):沿轨迹计算末端执行器运动的方差,以衡量运动的平滑程度。
4.2 评估结果
验证结果
在离线验证中,基于远程操控的数据验证显示 OmniVTLA 在多种物体上的预测性能优越。如图 5 所示,OmniVTLA 在所有模型中获得了最低的均方误差(MSE),平均为 。这一趋势在大多数物体上都成立:对于短罐,OmniVTLA 相比 VLA 将 MSE 降低了 7.8%;对于瓶子,该降幅达到 23.3%。VTLA-FS 的异常结果可能源于过拟合,这也说明了使用大规模触觉数据的重要性,而不仅仅依赖远程操控数据。结果表明,语义对齐(Semantic-Aligned, SA)触觉编码器能够有效将触觉信号与视觉和语言线索融合,实现更精确的状态预测——这是高精度操作的关键。
真实环境结果
真实环境实验验证了 OmniVTLA 在抓取与搬运任务中优于 π0 和 DP 的性能。对于使用爪式夹持器的 π0(表 3),VTLA-SA 在最多一个触觉解码器的情况下超越了其他设计,平均成功率(SR)达到 87.5%,比从零训练(From-Scratch, FS)编码器高 6.3%,比预训练(Pretrained, Pre)编码器高 3.1%。当 Pre 和 SA 编码器结合成所提出的 OmniVTLA 时,平均 SR 达到卓越的 96.9%,显示了双触觉解码器设计的优势。在完成时间(Completion Time, CT)方面,SA 编码器将平均步数比 VLA 基线减少 26.3%(从 657 步降至 484 步),证明触觉反馈能够优化操作。我们提出的 OmniVTLA 实现了第二佳表现,将 CT 降低 24.2%(从 657 步降至 498 步)。
对于使用四指灵巧手的 π0(表 4),OmniVTLA 将 SR 提升 6.2%(从 93.8% 提升至 100%),并将 CT 减少 6%(从 343 步降至 322 步)。特别是对于未见物体 Plastic 和 Square,我们的方法 SR 达到 100%,而 VLA 仅为 87.5%。
对于 DP 基线(表 5),整合触觉感知将平均 SR 提升 18.7%(从 59.4% 提升至 78.1%),并将平均 CT 缩短 19.9%(从 851 步降至 682 步)。这验证了触觉信号能够普遍提升性能,无论基线如何。
轨迹平滑度
触觉感知显著改善了运动平滑度,如表 6 所示。SA 编码器实现了最低的平均平滑度指标(1.04×10−41.04 \times 10^{-4}1.04×10−4),比 VLA 基线低 89.6%。这一结果与直观原则一致:“在路径清晰时快速移动,接近接触时减速。”语义对齐的触觉反馈使机器人能够更智能、更细腻地调整夹持器动作,在减少完成时间的同时避免接触过程中的突然运动——这对操作易碎物体至关重要。
6 附录
6.1 数据集与训练细节
数据集对象列表
表 7 提供了我们 ObjTac 数据集的完整对象清单,该数据集包含 10 个类别的 56 个物体。
数据采集流程
数据采集包括两个过程:触觉采集(Touch)和抓取采集(Grasp)。
-
触觉采集过程(Touch Process)
每个物体被触碰 2–5 次,每次交互持续 10–60 秒(采样频率为 60 Hz)。Python 脚本记录手指触觉传感器数据及精确时间戳,同时 Intel RealSense2 摄像头以 720p 分辨率(30 FPS)同步捕获第一人称 RGB 视频。在 56 个物体上,该过程总共生成 252 段视频(平均每段 18 秒)、135,000 帧视频以及 270,000 条力传感数据。 -
抓取采集过程(Grasp Process)
抓取采集旨在研究物体操作动力学。在继续执行时,将系统性地测试抓取成功/失败条件及抓取后的稳定性(滑动检测)。计划的实验包括成功抓取、失败尝试、稳定保持阶段以及导致滑动事件的受控释放动作。所有实验将保持与触觉过程一致的数据格式,包括同步的 720p 视频和传感器记录。
训练细节
表 8 列出了各模型的训练细节。
6.2 更多结果
动作片段长度消融研究
图 7 左侧展示了动作片段长度(10 到 50 步)对不同模型均方误差(MSE)的影响。在所有片段长度下,OmniVTLA 始终表现出最低的 MSE,凸显其在处理序列动作依赖时的稳健性。整体趋势表明,对更长动作序列的建模使 VTLA 能够更好地预测接触动力学,这与 VLA 不同——VLA 在片段长度增加(从 30 步到 50 步)时性能略有下降。
动作轨迹比较
图 7 右侧展示了 OmniVTLA 与 VLA 的动作轨迹对比。结果表明,OmniVTLA 在触觉丰富的操作任务中具有明显的性能优势。具体而言,OmniVTLA 完成抓取与搬运任务所需的动作步数比基线 VLA 少约 50%,显示出显著更高的操作效率。更重要的是,OmniVTLA 在整个过程中表现出更优的运动平滑度,能够一次成功完成任务,无需额外的修正动作。相比之下,VLA 的轨迹更为不稳定,存在明显的抖动,有时还会发生掉落。这些结果表明,引入触觉反馈能够显著提升 VLA 在触觉丰富任务中的性能,从而实现更稳定、更可靠的抓取行为。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)