【AI 学习】AI Agent 开发进阶:架构、规划、记忆与工具编排
本文介绍了AI Agent的参考架构与实现方法。文章首先阐述了AI Agent的核心概念,将大语言模型与工具、记忆、规划系统结合,可应用于代码助理、数据分析、客服等场景。然后提出了分层的参考架构,包括表达层、决策层、执行层和记忆层,并强调了解耦设计原则。文章详细展示了工具注册与函数调用的实现代码,包括统一的工具描述模型和决策循环。在记忆系统方面,提供了会话窗口管理和轻量级向量检索的实现方案。最后,
文章目录
1. 导读与目标
1.1 背景与主题
1.1.1 为什么是 AI Agent
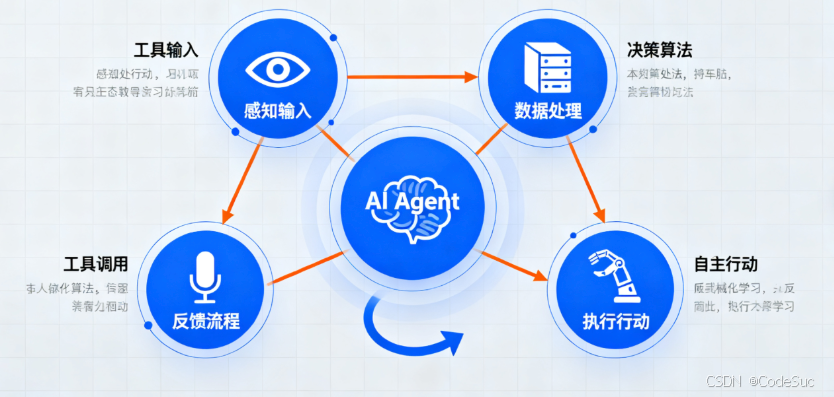
AI Agent 将大语言模型与外部工具、记忆系统、规划器结合,形成可执行的智能体。它能理解复杂任务、主动调用工具、跨多步达成目标,在研发、数据、客服与自动化场景中显著提升效率与质量。
1.1.2 典型应用场景
- 代码助理:阅读代码、搜索、修改与测试联动。
- 数据分析:检索、清洗、分析与可视化流水线。
- 运营与客服:诊断、执行工具操作与闭环处理。
1.2 目标与受众
1.2.1 本文目标
- 构建 AI Agent 的参考架构与能力边界。
- 实现工具调用、记忆管理、规划执行与多代理协作的原型代码。
- 提供部署、可观察性、安全治理与评测的工程化建议。
1.2.2 适用读者
- 希望落地 Agent 能力的工程师与架构师。
- 评估与改造开源框架的技术负责人。
2. 总览:参考架构与设计原则
2.1 架构分层
2.1.1 表达层
系统提示词、角色约束与模板管理,决定 Agent 的目标与边界。
2.1.2 决策层
规划器与策略选择,决定是否调用工具、如何分解与执行任务。
2.1.3 执行层
工具路由与调用、结果解析与持久化,保障事实与行动的可用性。
2.1.4 记忆层
短期会话上下文与长期知识库,提供跨轮与跨任务的持续性。
2.2 能力边界
2.2.1 原则
- 事实优先:用工具或检索获取事实,避免臆测。
- 安全先行:白名单、沙箱与审计贯穿始终。
- 可观察性:日志与指标可追踪每个决策与行动。
2.3 设计原则
2.3.1 最小耦合与可替换
各层之间通过清晰接口解耦,支持替换模型、工具或存储实现。
3. 工具与函数调用接口
3.1 统一工具描述
3.1.1 工具模型与注册
from typing import Dict, Any, Callable
class Tool:
def __init__(self, name: str, description: str, schema: Dict[str, Any], func: Callable[[Dict[str, Any]], Dict[str, Any]]):
self.name = name
self.description = description
self.schema = schema
self.func = func
class ToolRegistry:
def __init__(self):
self._tools: Dict[str, Tool] = {}
def register(self, tool: Tool):
self._tools[tool.name] = tool
def list(self) -> Dict[str, Dict[str, Any]]:
return {k: v.schema for k, v in self._tools.items()}
def call(self, name: str, args: Dict[str, Any]) -> Dict[str, Any]:
if name not in self._tools:
return {"error": f"unknown tool {name}"}
return self._tools[name].func(args)
search_tool = Tool(
name="web_search",
description="Search the web",
schema={"type": "object", "properties": {"query": {"type": "string"}}, "required": ["query"]},
func=lambda args: {"results": [f"Result for {args['query']}"]}
)
calc_tool = Tool(
name="calculator",
description="Evaluate arithmetic expression",
schema={"type": "object", "properties": {"expr": {"type": "string"}}, "required": ["expr"]},
func=lambda args: {"value": eval(args["expr"])}
)
registry = ToolRegistry()
registry.register(search_tool)
registry.register(calc_tool)
3.2 函数调用协议
3.2.1 模型输出结构与解析
from typing import Optional
class ModelOutput:
def __init__(self, content: str, tool_name: Optional[str] = None, tool_args: Optional[Dict[str, Any]] = None):
self.content = content
self.tool_name = tool_name
self.tool_args = tool_args
class SimpleDecider:
def decide(self, prompt: str) -> ModelOutput:
if "search:" in prompt:
q = prompt.split("search:")[-1].strip()
return ModelOutput(content="use_tool", tool_name="web_search", tool_args={"query": q})
if "calc:" in prompt:
e = prompt.split("calc:")[-1].strip()
return ModelOutput(content="use_tool", tool_name="calculator", tool_args={"expr": e})
return ModelOutput(content="answer")
3.2.2 决策循环与工具执行
class Executor:
def __init__(self, registry: ToolRegistry):
self.registry = registry
def step(self, decision: ModelOutput) -> str:
if decision.tool_name:
result = self.registry.call(decision.tool_name, decision.tool_args or {})
return str(result)
return "no_tool"
4. 记忆系统与上下文管理
4.1 会话与短期记忆
4.1.1 会话窗口管理
class Memory:
def __init__(self, max_turns: int = 12):
self.turns = []
self.max_turns = max_turns
def add(self, role: str, content: str):
self.turns.append({"role": role, "content": content})
if len(self.turns) > self.max_turns:
self.turns = self.turns[-self.max_turns:]
def to_prompt(self) -> str:
return "\n".join([f"{t['role']}: {t['content']}" for t in self.turns])
4.2 长期记忆与向量检索
4.2.1 轻量向量索引
import math
class VectorStore:
def __init__(self):
self.items = []
def embed(self, text: str) -> list:
return [float(len(text) % 7), float(sum(ord(c) for c in text) % 11), float(text.count(' '))]
def add(self, text: str):
self.items.append((text, self.embed(text)))
def search(self, query: str, top_k: int = 3):
q = self.embed(query)
scored = []
for t, v in self.items:
dot = sum(a*b for a, b in zip(q, v))
qa = math.sqrt(sum(a*a for a in q))
va = math.sqrt(sum(a*a for a in v))
s = dot / (qa*va + 1e-9)
scored.append((s, t))
scored.sort(reverse=True)
return [t for _, t in scored[:top_k]]
4.3 记忆策略
4.3.1 摘要与优先级
针对长对话,采用摘要与优先级保留策略,将事实与决策保留、细枝末节压缩,控制窗口占用。
5. 规划与多步执行
5.1 ReAct 循环
5.1.1 计划与执行
class PlannerExecutor:
def __init__(self, decider: SimpleDecider, registry: ToolRegistry, memory: Memory):
self.decider = decider
self.registry = registry
self.memory = memory
def run(self, goal: str, max_steps: int = 6) -> str:
self.memory.add("system", "You are a helpful agent.")
self.memory.add("user", goal)
for _ in range(max_steps):
decision = self.decider.decide(self.memory.to_prompt())
if decision.tool_name:
result = self.registry.call(decision.tool_name, decision.tool_args or {})
self.memory.add("tool", str(result))
continue
return "Final: " + goal
return "Incomplete"
5.2 任务分解与合并
5.2.1 简易分解器
class Decomposer:
def split(self, goal: str) -> list:
parts = goal.split(";")
return [p.strip() for p in parts if p.strip()]
5.2.2 汇总器
class Aggregator:
def combine(self, results: list) -> str:
return " | ".join(results)
5.3 策略选择与路由
5.3.1 路由器
根据任务类型选择不同策略或工具组合,形成策略路由与执行路径。
6. 多代理协作与角色分工
6.1 角色
6.1.1 搜索员与分析员
class SearchAgent:
def __init__(self, registry: ToolRegistry):
self.registry = registry
def act(self, query: str) -> str:
return str(self.registry.call("web_search", {"query": query}))
class AnalystAgent:
def synthesize(self, facts: str) -> str:
return "Summary: " + facts
6.2 协作管道
6.2.1 管道执行
class Pipeline:
def __init__(self, searcher: SearchAgent, analyst: AnalystAgent):
self.searcher = searcher
self.analyst = analyst
def run(self, query: str) -> str:
facts = self.searcher.act(query)
return self.analyst.synthesize(facts)
7. RAG 集成与知识增强
7.1 文档摄取与切片
7.1.1 切片与索引
class RAG:
def __init__(self, store: VectorStore):
self.store = store
def ingest(self, text: str, chunk_size: int = 200):
chunks = [text[i:i+chunk_size] for i in range(0, len(text), chunk_size)]
for c in chunks:
self.store.add(c)
def retrieve(self, query: str) -> list:
return self.store.search(query, top_k=3)
7.2 检索与合成
7.2.1 组合输出
将检索片段与当前上下文合成,供模型或分析员综合输出,降低幻觉与提升覆盖率。
8. 部署与接口
8.1 FastAPI 服务化
8.1.1 运行接口
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
memory = Memory()
planner = PlannerExecutor(SimpleDecider(), registry, memory)
class GoalReq(BaseModel):
goal: str
@app.post("/run")
async def run(req: GoalReq):
return {"result": planner.run(req.goal)}
8.2 任务编排与批处理
8.2.1 批量执行
接收批量目标,分解为子任务并并行或串行执行,提升吞吐与可用性。
9. 可观察性与安全治理
9.1 日志与指标
9.1.1 建议
记录每步决策、工具调用参数与结果、耗时与错误;统计成功率、重试率与平均延迟,纳入告警。
9.2 安全与权限
9.2.1 策略
提示词与参数校验、敏感操作确认、工具白名单与沙箱隔离、审计轨迹与回放。
10. 评测与质量保障
10.1 任务集与基准
10.1.1 评测框架
构建任务集、期望输出与判分规则,自动化回归并人工抽检关键流程。
10.2 鲁棒性与演练
10.2.1 建议
在核心工具与场景做故障演练与降级方案,保证异常条件下可用性。
11. 组合示例:从零到跑通的工具增强 Agent
11.1 初始化与依赖
11.1.1 组件初始化
registry = ToolRegistry()
registry.register(search_tool)
registry.register(calc_tool)
memory = Memory(max_turns=12)
planner = PlannerExecutor(SimpleDecider(), registry, memory)
store = VectorStore()
rag = RAG(store)
rag.ingest("Python release notes and docs content")
11.2 运行与协作
11.2.1 示例执行
goal = "search: Python 3.12 features; calc: 1+2*3"
decomposer = Decomposer()
steps = decomposer.split(goal)
results = []
for s in steps:
memory.add("user", s)
results.append(planner.run(s, max_steps=3))
agg = Aggregator().combine(results)
print(agg)
11.3 RAG 增强查询
11.3.1 检索片段
context = rag.retrieve("Python features")
print(context)
12. 总结与扩展
12.1 知识点回顾与扩展
本文系统讲解了 AI Agent 的分层架构、工具调用与函数接口、记忆系统与向量检索、规划与多步执行、多代理协作、RAG 集成、部署与可观察性、安全治理与评测,并以完整代码组合示例跑通原型。扩展方向包括更强规划器、结构化函数调用协议、知识库平台化与治理、跨系统编排与度量。
12.2 更多阅读资料
- ReAct: Synergizing Reasoning and Acting
https://arxiv.org/abs/2210.03629 - Toolformer
https://arxiv.org/abs/2302.04761 - LangChain 文档
https://python.langchain.com - OpenAI Function Calling 指南
https://platform.openai.com/docs/guides/function-calling - FastAPI 文档
https://fastapi.tiangolo.com
12.3 新问题与其它方案
- 如何统一工具协议与安全沙箱以降低风险并提升复用性。
- 是否需要多代理协作与角色治理来提升复杂任务完成率。
- 在强检索场景下,RAG 与规划器协作如何平衡成本与质量。
- 如何构建可重复、可量化的评测体系并纳入 CI/CD。
12.4 号召行动
如果这篇文章对你有帮助,欢迎收藏、点赞并分享给同事与朋友。也欢迎在评论区提出你的思考与问题,我们一起深入讨论与共建高质量的 AI Agent 应用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)