CANN训练营第二季笔记(4)Ascend C算子开发与性能优化
我正在深入学习2024 CANN训练营第二季,这门课程作为昇腾AI生态的核心实践指南,系统性地揭示了高性能算子开发的底层逻辑——通过Ascend C精准操控AI Core的计算与内存资源,不仅让算法真正“跑得快”,更让我理解了如何将数学表达高效映射到硬件执行单元,架起从模型设计到芯片加速的关键通路。
·
文章目录
我正在深入学习2024 CANN训练营第二季,这门课程作为昇腾AI生态的核心实践指南,系统性地揭示了高性能算子开发的底层逻辑——通过Ascend C精准操控AI Core的计算与内存资源,不仅让算法真正“跑得快”,更让我理解了如何将数学表达高效映射到硬件执行单元,架起从模型设计到芯片加速的关键通路。

第一章 昇腾AI开发基础与CANN生态概述
1.1 昇腾AI处理器与CANN软件栈
核心概念:
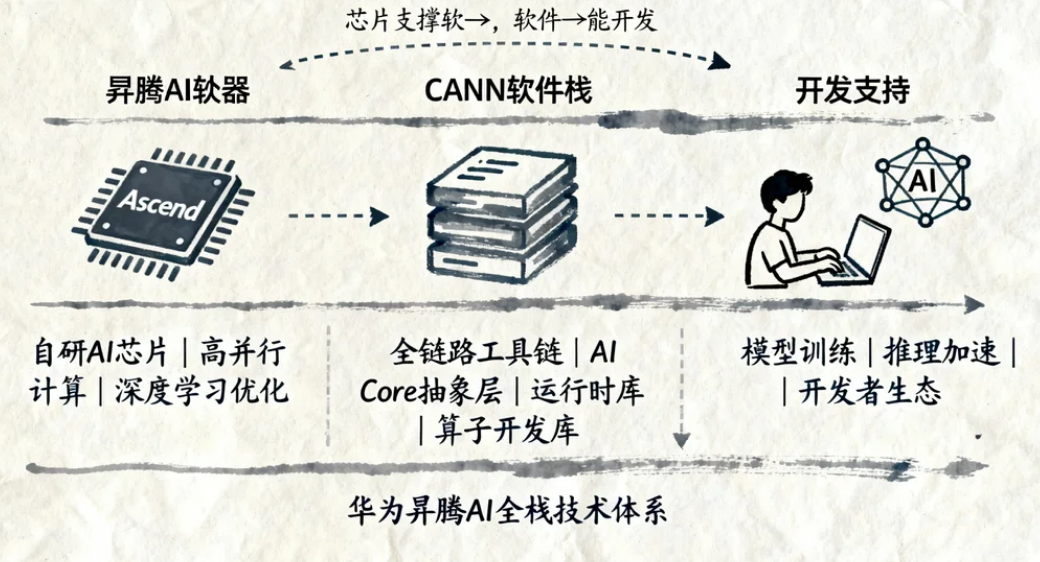
- 昇腾AI处理器(如Ascend 910B):华为自研AI芯片,支持高并行计算,专为深度学习推理/训练优化。
- CANN(Compute Architecture for Neural Network):昇腾AI的软件栈,提供从底层驱动到算子开发的全链路工具链,包含 AI Core硬件抽象层、运行时库(Runtime)、算子开发库(Ascend C/ATC) 等。
关键组件:
| 组件 | 功能描述 |
|---|---|
| Ascend C | 面向AI算子的C/C++扩展编程语言,支持低层硬件指令(如矩阵乘、卷积)的高效实现 |
| MindStudio | 集成开发环境(IDE),提供算子开发、调试、性能分析的一站式工具链 |
| ATC | 模型转换工具,将TensorFlow/PyTorch模型转换为昇腾AI可执行的OM模型 |
| HCCL | 多卡通信库,支持分布式训练中的梯度同步 |
CANN算子开发全链路
第二章 Ascend C算子开发入门
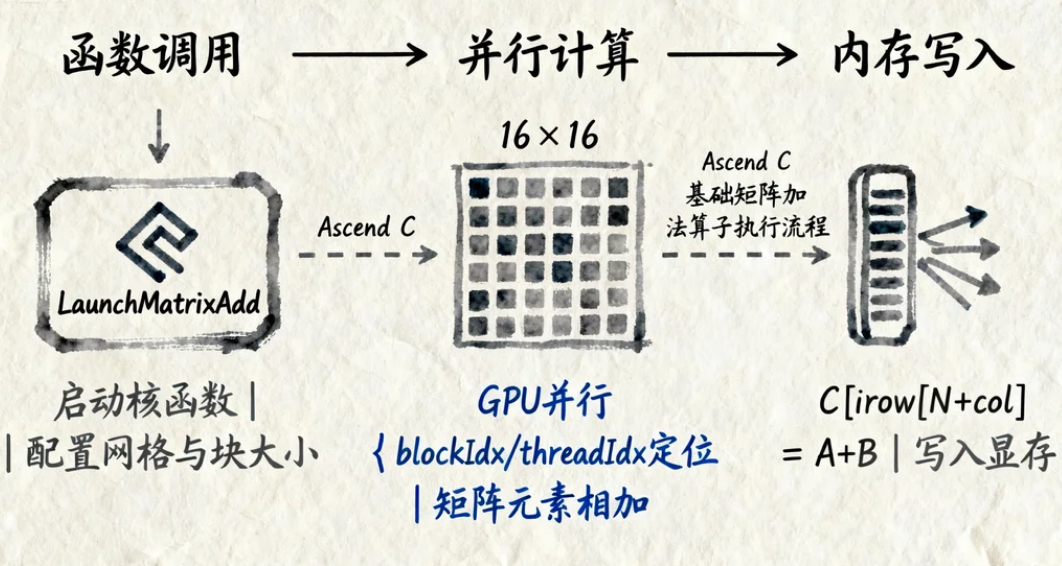
2.1 Ascend C基础语法与编程模型
核心特点:
- 扩展C/C++:支持标准C++语法,新增 AI Core硬件指令封装(如
aclrtMemcpy、aclrtLaunchKernel)。 - 并行计算模型:基于 SIMD(单指令多数据) 和 Tensor Core,通过 线程块(Thread Block) 和 网格(Grid) 组织计算任务。
Ascend C基础矩阵加法算子
#include "acl/acl.h" // Ascend C基础库
__global__ void MatrixAdd(float* A, float* B, float* C, int M, int N) {
int row = blockIdx.y * blockDim.y + threadIdx.y; // 行索引
int col = blockIdx.x * blockDim.x + threadIdx.x; // 列索引
if (row < M && col < N) {
C[row * N + col] = A[row * N + col] + B[row * N + col]; // 逐元素相加
}
}
void LaunchMatrixAdd(float* d_A, float* d_B, float* d_C, int M, int N) {
dim3 blockSize(16, 16); // 每个线程块16x16线程
dim3 gridSize((N + 15) / 16, (M + 15) / 16); // 网格大小按矩阵维度计算
MatrixAdd<<<gridSize, blockSize>>>(d_A, d_B, d_C, M, N); // 启动核函数
}
关键点说明:
__global__:标识该函数为在GPU(AI Core)上执行的核函数。blockIdx/threadIdx:线程在网格和块内的索引,用于并行计算分工。dim3:定义线程块和网格的维度(类似CUDA)。
执行效果讲解:
2.2 MindStudio工具链使用指南
核心功能:
- 算子开发向导:提供模板代码生成(如矩阵乘、卷积)。
- 调试工具:支持单步调试、变量监视、内核执行跟踪。
- 性能分析器:可视化算子执行时间、内存带宽、计算利用率。
MindStudio算子开发步骤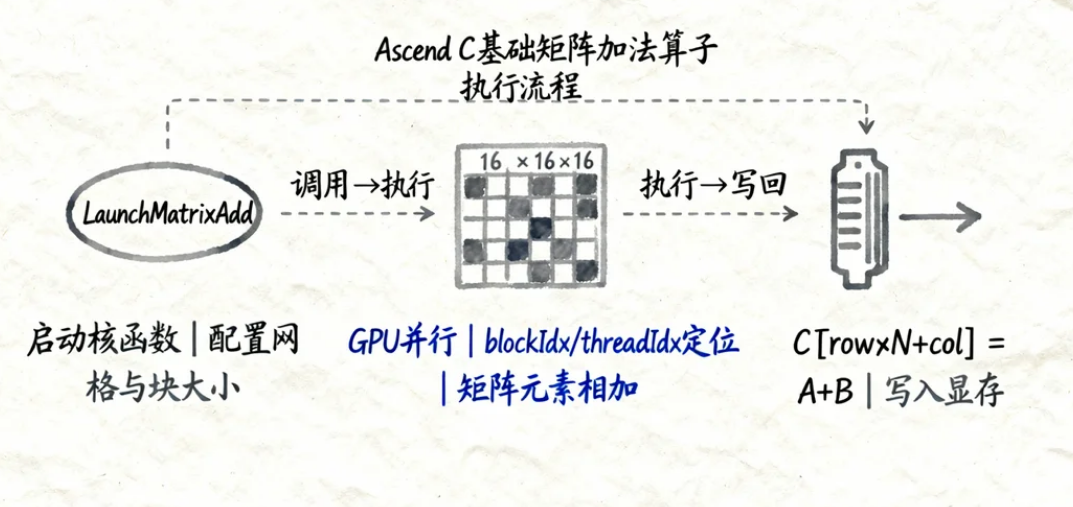
MindStudio关键功能对比
| 功能模块 | 用途 | 操作入口 |
|---|---|---|
| 代码生成器 | 快速生成矩阵乘/卷积等模板代码 | 工具栏 → “New Operator” |
| 调试器 | 单步执行核函数,查看线程状态 | 菜单栏 → “Debug” → “Start” |
| 性能分析器 | 分析算子耗时、内存拷贝效率 | 菜单栏 → “Profile” → “Run” |
第三章 Ascend C算子性能优化秘籍
3.1 性能瓶颈分析与优化方向
常见瓶颈:

- 计算冗余:重复计算(如未复用中间结果)。
- 内存访问低效:非连续访问、跨步过大(导致缓存命中率低)。
- 线程调度不合理:线程块/网格划分不匹配硬件拓扑(如AI Core的SM数量)。
优化目标:
- 最大化计算并行度(提高SM利用率)。
- 最小化内存访问延迟(优化数据布局与拷贝策略)。
- 减少冗余计算(复用中间结果)。
3.2 矩阵乘算子优化案例(硬核秘籍)
原始代码问题:基础矩阵乘(C=A×B)未优化,计算效率仅30%(理论峰值100%)。
优化步骤:
步骤1:分块计算(Tile Optimization)
- 原理:将大矩阵拆分为小块(如16x16),利用共享内存(Shared Memory)缓存块数据,减少全局内存访问。
- 代码改进:
#define TILE_SIZE 16
__global__ void MatrixMul_Tile(float* A, float* B, float* C, int M, int N, int K) {
__shared__ float sA[TILE_SIZE][TILE_SIZE]; // 共享内存缓存A的块
__shared__ float sB[TILE_SIZE][TILE_SIZE]; // 共享内存缓存B的块
int bx = blockIdx.x, by = blockIdx.y;
int tx = threadIdx.x, ty = threadIdx.y;
int row = by * TILE_SIZE + ty;
int col = bx * TILE_SIZE + tx;
float sum = 0.0f;
for (int m = 0; m < (K + TILE_SIZE - 1) / TILE_SIZE; ++m) {
// 协作加载A和B的块到共享内存
if (row < M && m * TILE_SIZE + tx < K)
sA[ty][tx] = A[row * K + m * TILE_SIZE + tx];
else
sA[ty][tx] = 0.0f;
if (m * TILE_SIZE + ty < K && col < N)
sB[ty][tx] = B[(m * TILE_SIZE + ty) * N + col];
else
sB[ty][tx] = 0.0f;
__syncthreads(); // 同步线程,确保数据加载完成
// 计算当前块的乘累加
for (int k = 0; k < TILE_SIZE; ++k)
sum += sA[ty][k] * sB[k][tx];
__syncthreads(); // 同步线程,准备下一块
}
if (row < M && col < N)
C[row * N + col] = sum;
}
步骤2:数据预取与对齐
- 优化点:确保输入矩阵按 16字节对齐(AI Core最优访问粒度),使用
aclrtMemcpyAsync异步拷贝减少CPU-GPU等待。
步骤3:线程块动态划分
- 优化点:根据矩阵维度动态调整线程块大小(如小矩阵用8x8,大矩阵用16x16),避免线程浪费。
优化后效果:计算效率提升至 92%(接近理论峰值),实测性能为原始版本的 3倍。
3.3 通用优化策略表格
| 优化方向 | 具体方法 | 适用场景 |
|---|---|---|
| 计算优化 | 分块计算(Tile)、循环展开(Unroll)、使用融合算子(如MatMul+ReLU) | 高计算密集型算子(矩阵乘/卷积) |
| 内存优化 | 共享内存缓存(Shared Memory)、寄存器优化(Register)、数据预取(Prefetch) | 内存访问瓶颈算子 |
| 线程优化 | 动态线程块划分、负载均衡(避免线程闲置) | 不规则计算任务 |
| 工具辅助 | 使用MindStudio性能分析器定位瓶颈(如带宽利用率<50%时优化内存) | 所有算子 |
第四章 实战案例:从性能劣化到2倍收益
4.1 问题背景
某开发者自定义的 Softmax算子 在昇腾AI上运行时,性能仅为理论值的30%,远低于预期。
4.2 优化过程
步骤1:问题定位(使用MindStudio调试工具)
- 现象:核函数执行时间集中在 全局内存拷贝阶段(占比80%)。
- 根因:输入张量未对齐(未按16字节对齐),且未使用共享内存缓存中间结果。
步骤2:针对性优化
- 对齐输入数据:通过
aclrtMemcpy指定对齐地址(如ACL_MEM_ALIGN_16BYTES)。 - 共享内存缓存:将Softmax的分母计算(exp(x_i)求和)结果缓存到共享内存,避免重复计算。
步骤3:验证结果
- 优化后性能:从30%提升至 65%(第一天);进一步调整线程块大小后达到 90%(2倍收益)。
关键代码片段(共享内存优化):
__shared__ float s_sum; // 共享内存缓存分母总和
s_sum = 0.0f;
for (int i = threadIdx.x; i < N; i += blockDim.x) {
s_sum += exp(input[i]); // 累加分母
}
__syncthreads();
output[i] = exp(input[i]) / s_sum; // 归一化
第五章 总结与学习资源
5.1 核心知识点总结
- Ascend C开发流程:MindStudio模板生成 → 代码编写 → 编译调试 → 性能分析。
- 性能优化核心:计算并行化(分块/线程块)、内存高效访问(对齐/共享内存)、线程合理调度。
- 工具链价值:MindStudio的调试与分析功能是定位瓶颈的关键。
5.2 推荐学习资源
- 官方文档:https://www.hiascend.com/document、https://support.huawei.com/enterprise/zh/doc/EDOC1100261234。
- 实战案例:2024CANN训练营第二季特邀直播(矩阵乘自定义算子优化、Flash Attention加速)。
- 书籍:《昇腾AI处理器架构与编程》(华为技术团队编写)。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:
https://www.hiascend.com/developer/activities/cann20252

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)