Who Wrote This? —— 用语法错误一招识破大模型生成文本(GECSCORE 解读)
这篇论文解决了什么问题?在大模型时代,我们越来越需要区分“人写的”还是“模型写的”文本。传统零样本检测方法大多需要访问“源模型的 logits”(白盒),或者依赖大量训练数据(监督式分类器)。这篇论文提出的GECSCORE在完全黑盒、零样本的条件下,仅凭一个语法纠错模型,就能高精度识别 LLM 生成文本。有什么历史意义和性能突破?
1. 论文基本信息
标题:Who Wrote This? The Key to Zero-Shot LLM-Generated Text Detection Is GECSCORE
作者:Junchao Wu, Runzhe Zhan, Derek F. Wong, Shu Yang, Xuebo Liu, Lidia S. Chao, Min Zhang
年份:2025
领域关键词:LLM 生成文本检测、零样本(zero-shot)、黑盒检测、语法错误纠正(GEC)、ROUGE、鲁棒性、对抗攻击
2. 前言:为什么读这篇论文?
-
这篇论文解决了什么问题?
在大模型时代,我们越来越需要区分“人写的”还是“模型写的”文本。传统零样本检测方法大多需要访问“源模型的 logits”(白盒),或者依赖大量训练数据(监督式分类器)。这篇论文提出的 GECSCORE 想要解决的是:在完全黑盒、零样本的条件下,仅凭一个语法纠错模型,就能高精度识别 LLM 生成文本。 -
有什么历史意义和性能突破?
作者在两个典型数据集 XSum(新闻)和 Writing Prompts(小说创作)上,对 GPT-3.5、PaLM-2、GPT-4o、Claude-3.5、Llama-3-70B 五个模型生成的文本做检测,平均 AUROC 达到 98.62% 左右,在多数设置上超过当前最强的零样本方法 Fast-DetectGPT,也大幅超过 RoBERTa 等监督式检测器。更重要的是,在跨领域、跨模型以及改写(paraphrase)攻击下,性能下降很小,鲁棒性非常强。 -
为什么值得写一篇博客解读?
第一,它的思路非常“反直觉但简单”:靠“语法错误多少”而不是复杂曲率或 logits。第二,它是真正贴近实际场景的 黑盒 + 零样本 方案,和我们日常只拿到一段可疑文本、却无法访问对方模型的情况高度一致。第三,这个方法工程上也很友好:核心流程就是“先纠错,再算相似度,再跟阈值比一比”,非常适合落地和复现。
3. 基础概念铺垫
在进入方法细节前,先把几个关键概念讲清楚,用上手级别的语言说一遍。
LLM 生成文本检测:就是判断一段文本是人写的还是大模型写的。可以是监督式(训练一个分类器),也可以是零样本式(不训练,只利用统计特征)。
白盒 vs 黑盒:
-
白盒检测认为:我可以用“同一个模型”或“一个替代模型”去算这段文本的 token 概率、perplexity、rank 等,然后根据这些分布特征来判断是不是模型写的。
-
黑盒检测则更现实:我完全不知道文本是从哪个模型出来的,也拿不到它的 logits,只能借助其他模型或特征(比如语法错误、风格特征)来做判断。
零样本(zero-shot):这里指的是不需要拿“人写 / 机写标注数据”去训练一个新的分类器,而是依赖两类文本在“某种天然特征上的系统性差异”。只要确定好一个阈值,这种方法就可以迁移到新模型、新领域。
GEC(Grammar Error Correction)语法错误纠正:可以理解为一个“智能改作文”的模型:给它一段原文,它返回一段语法更正确、表达更规范的版本。GEC 模型本身可以是大模型(比如 GPT-4o-mini),也可以是专门的 Seq2Seq 模型(比如 COEDIT-L)。
相似度打分:当我们有“原文”和“纠错后文本”两段内容时,需要一个指标衡量它们“有多像”。可以用 ROUGE、BLEU、chrF、BERTScore、BLEURT 等。作者最后发现 ROUGE-2(二元词组级别的重叠)效果最好。
有了这些概念,再看 GECSCORE 的思路就会自然很多:先让一个 GEC 模型“出手改一改”,再看它改得多还是少——改得少,更像是 LLM 自己写的;改得多,更像是人写的。
4. 历史背景与前置技术:从 MT 检测到 DetectGPT
大模型文本检测并不是 ChatGPT 出现之后才有的事。最早的工作其实来自机器翻译(MT)检测——研究者希望区分一句话是人类翻译的还是机器翻译的,会用到各种语法、词法、句子长度等语言学特征。
随着预训练语言模型的发展,研究重心逐渐迁移到 LLM 生成文本检测,主要形成了两条技术路线:
4.1 白盒零样本检测:围绕 “logits” 做文章
这条线的典型代表包括:
-
Log-Likelihood / Perplexity:直接用语言模型对文本计算平均 log 概率或 perplexity。大致直觉是:模型“自己写的”文本在它自己眼里往往更“顺口”。
-
Rank / Log-Rank / LRR:不仅看概率,还看“这个 token 在所有候选词中的排名”。Log-Rank 做了对 rank 的对数变换,LRR 则把 Log-Likelihood 与 Log-Rank 的信息组合成一个 ratio,性能更好。
-
DetectGPT / Fast-DetectGPT:这是很火的一条线。DetectGPT 的核心是:
-
对原文本做轻微扰动(比如用 T5 改写几遍);
-
用目标 LLM 计算这些变体的 log 概率曲率;
-
发现模型自己生成的文本,在被微调后 log 概率下降得更一致、更明显。
不过 DetectGPT 需要大量“扰动 + 计算”,代价非常高。Fast-DetectGPT 用采样替代扰动,大幅加速,但仍然需要访问 LLM 的 logits。
-
这条路线的共同痛点在于:
-
需要访问模型内部 logits(白盒);
-
对 paraphrase 攻击比较脆弱,只要人再改写一遍,特征就被洗掉很多;
-
在未知模型、未知领域上泛化能力有限。
4.2 黑盒检测:训练一个分类器,或者用“修订行为”
另一条路线是黑盒检测,典型做法是:
-
监督式分类器:拿 RoBERTa、BERT、XLNet 等预训练模型,喂入大量“人写 / 机写”样本,微调出一个二分类器。实践中,这类方法在同分布数据上性能很高,但一旦换数据集、换生成模型,性能会明显掉线。
-
Revise-Detect:更接近本文的思路。它的操作是:
-
用 ChatGPT 把文本“润色”一遍;
-
再用像 BARTScore 这样的相似度指标评估改前与改后的差异;
-
发现 ChatGPT 对自己风格的文本改动往往更小。
它也是零样本 + 黑盒,但只利用了“改写偏好”这一维度。
-
GECSCORE 就是在这种背景下提出的:既不要访问源 LLM 的 logits,也不要训练新的分类器,而是利用一个通用 GEC 模型,通过“语法错误差异 + 修正偏好”这两个维度来做检测。
5. 论文核心贡献
这篇论文最核心的贡献可以用一句话概括:从 LLM 的视角看,人类写的文本语法错误显著更多,因此“纠错前后相似度”本身就是一个极强的检测信号。
具体来说,作者做了几件事:
首先,他们提出并验证了一个非常朴素但扎实的假设:在一系列主流大模型(GPT-3.5、PaLM-2、Claude-3.5、Llama-3 等)下,人类文本的语法错误数量普遍比 LLM 生成文本高很多,不论是新闻式的正式文本(XSum),还是创作向的非正式文本(Writing Prompts)。
其次,在这个假设之上,他们提出了 GECSCORE 框架:对文本做语法纠错,再用一个相似度指标(最终选 ROUGE-2)来衡量“纠前 / 纠后”的接近程度,最后和一个阈值比较,从而判断文本是 LLM 生成还是人写。 这个流程不依赖任何训练数据,只需要一批“无标签样本”来估计阈值。
第三,他们系统地和十个基线方法比较,包括 Log-Likelihood、LRR、DetectGPT、Fast-DetectGPT、Revise-Detect,以及两个 RoBERTa 检测器。结果显示:在黑盒零样本设定下,GECSCORE 一般能拿到最好的 AUROC 和 F1,且在跨领域、跨模型以及 paraphrase 攻击场景中都非常稳。
最后,他们还做了比较细致的消融实验:探索了不同相似度指标、不同 GEC 模型(GPT-4o-mini vs COEDIT-L)、不同文本长度对性能的影响,证明了 “语法错误差异”是主要驱动力,而“大模型的纠错偏好”则带来了额外增益。
6. 方法详解:GECSCORE 到底是怎么工作的?
6.1 整体架构:三步走的黑盒零样本检测器
GECSCORE 的整体架构非常清爽,可以用一句话概括:GEC 一次,打分一次,跟阈值比一次。
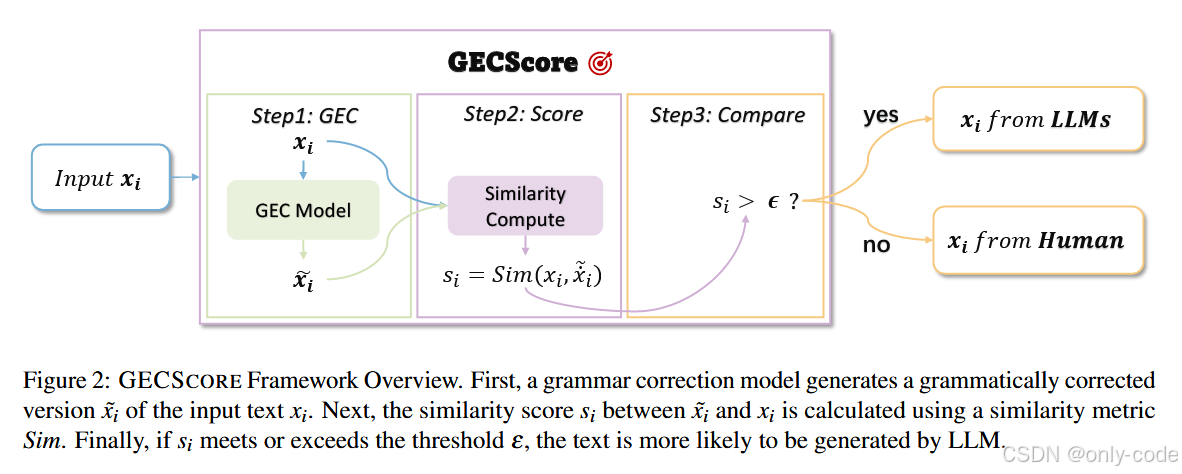
【插图:GECSCORE 框架总览(输入文本 → GEC 模型 → 相似度计算 → 与阈值比较 → 判为 LLM/人类)】
形式化一点来说:
-
输入是一段待检测文本
。
-
有一个语法纠错模型
,可以是 GPT-4o-mini,也可以是 COEDIT-L。
-
有一个相似度函数
,论文里主推 ROUGE-2。
-
GEC 模型生成纠错后的文本
。
-
计算相似度分数
。
-
再和一个预先估计好的阈值
比:
-
若
,认为文本更可能是 LLM 生成;
-
否则,认为是人类写的。
-
从工程视角看,就是一次 GEC 推理 + 一次相似度计算,比很多需要 10~100 次扰动的方案实在太轻量了。

【插图:算法 1 GECSCORE 伪代码】
6.2 核心假设:人类更容易犯语法错误,LLM 更“看不惯”人类文本
作者的假设分成两部分:
-
人类文本语法错误更多
写作是一种复杂的认知任务,涉及工作记忆、信息组织、语法规则检索等。人脑在写作时更倾向于保证“语义流畅”和“故事连贯”,而不是逐字逐句检查语法,因此漏掉拼写、主谓不一致、时态错用等问题非常常见。论文中还引用了工作记忆理论、语言干扰(二语影响一语)、注意力分散和认知负荷等心理学研究来支撑这一点。 -
LLM 对人类文本更“挑剔”
LLM 在海量语料上学习到的是某种“标准化”的语言统计分布,同时它对自己或同类 LLM 生成的文本非常熟悉。
于是当它给人类文本做语法纠错时,往往会觉得“这里也怪,那里也怪”,会改写更多内容;而面对 LLM 生成的文本,它反而会觉得“还行”,只做细微调整。
这两个因素叠加,就导致一个现象:
从一个强 GEC 模型的视角看,人类文本被“改动得多”,LLM 文本被“改动得少”。
6.3 假设验证:语法错误统计 + 编辑操作类型
为了不是“拍脑袋”,作者专门做了一组统计实验:
-
用 GPT-4o 给 XSum 和 Writing Prompts 的人类文本、以及 GPT-3.5、PaLM-2、Claude-3.5、Llama-3-70B 生成的文本标注语法错误数量;
-
统计每篇文章被标记的错误数量分布,以及纠错所需的编辑操作(增加、删除、替换)。
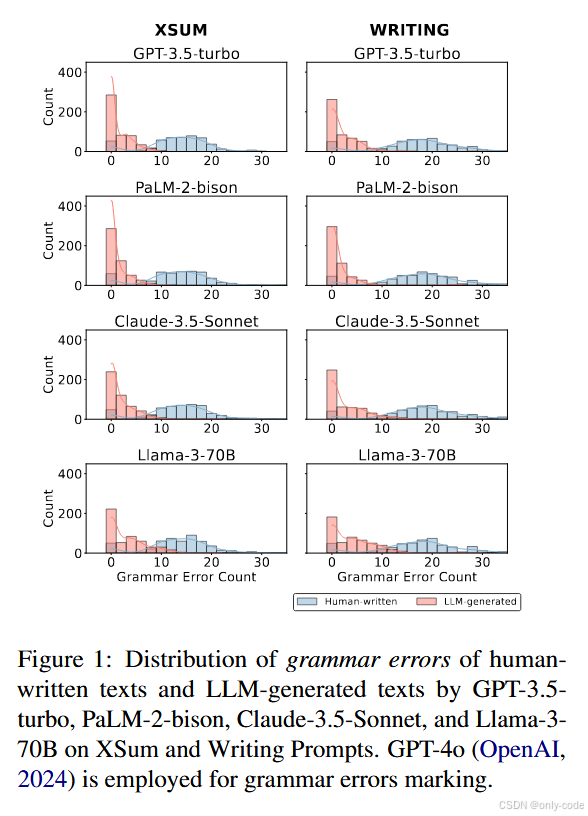
【插图:不同模型生成文本 vs 人类文本的语法错误数量分布(XSum & Writing Prompts)】
结果非常清晰:
-
人类文本一般需要 10~30 个 语法修正,而 LLM 生成文本大多在 0~10 个,且大量样本接近 0。
-
这个现象在新闻和创作两个领域都成立,只是新闻文本整体错误少一些。

【插图:三种编辑操作(增加 / 删除 / 替换)的平均次数对比】
进一步分析编辑类型可以看到:
-
LLM 文本需要的增删操作更少,说明它们整体结构更合理,句子边界更清晰;
-
人类文本更常见的是“多余 / 缺失”信息,需要通过增加和删除来调整;
-
在词汇替换上,人类文本也更容易出现“用词不当、搭配不自然”等问题。
这些统计图给了 GECSCORE 非常坚实的经验基础——语法错误差异是真实存在且显著的。
6.4 正式算法:如何用一批样本估计阈值?
GECSCORE 仍然需要一个“校准过程”来确定阈值 ,但这批样本不需要标签。作者沿用零样本检测的常规设定:先准备一个“预备样本集”
,然后在加入待检测样本
后一起处理。
完整流程(对应 Algorithm 1)可以拆成:
-
准备样本集
把待检测样本 (x_i) 与已有的无标签样本集合并,得到。
-
用 GEC 模型生成纠错版本
对每个,用
,组成集合
。
-
计算相似度分数
对每对计算相似度
,形成分数集合 (S)。
作者实验发现 使用 ROUGE-2 F1 作为 Sim,平均效果最好。 -
用样本集合估计阈值
在实际实现中,作者假设这批样本来自“人类和机器混合”的总体,然后在不同候选阈值下计算真正率 TPR 与假正率 FPR,选择使 TPR + (1 − FPR) 最大的阈值(本质上类似于最大化 Youden’s J 指数)。 -
对目标样本做最终判断
拿到后:
-
若
-
否则更像人类文本。
-
实验也表明:只要用几十到几百条样本来估计阈值,性能就已经很稳定了(见后面的样本数消融)。
6.5 GEC 模型与相似度指标:两个关键选择
作者主要尝试了两类 GEC 模型:
-
GPT-4o-mini:
作为一个轻量版的 GPT-4o,它支持多语言、有不错的理解和纠错能力。GEC 提示很简单:“Correct the grammar errors in the following text: Corrected text:”。
用这个模型做 GEC,GECSCORE 在各项实验中表现最好。 -
COEDIT-L:
这是一个基于 Flan-T5-Large 的 Seq2Seq 文本编辑模型,专门为 GEC 等编辑任务做了微调。它不具备大模型那样广泛的“纠错偏好”,但在语法纠错上足够强。
在相似度指标上,作者实验了包括 BLEU、TER、chrF、ROUGE-1/2/L、METEOR、BERTScore、BLEURT、BARTScore、GLEU 等一大堆指标。整体结论是:
-
ROUGE-2 在 GPT-4o-mini 场景下表现最佳,平均 AUROC 接近 97.9%;
-
用 COEDIT-L 时,ROUGE-2 也是第二好的指标;
-
兼顾语义和较长 n-gram 的指标(ROUGE-L、METEOR、BARTScore)也表现不错;
-
仅做字符级编辑距离的指标(Edit Distance)或者部分神经指标(如未针对任务精调的 BERTScore、BLEURT),在细粒度语法变化上不够敏感,表现不稳定。
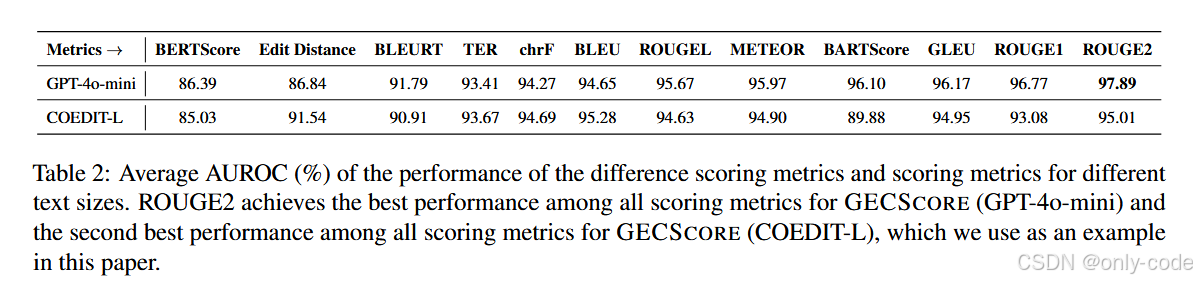
【表2——不同相似度指标 + 不同 GEC 模型下的平均 AUROC,对比 ROUGE-2、BLEU、chrF 等】
6.6 文本长度的影响
一个常见疑问是:短文本能不能检测? 作者通过“滑动窗口切句”的方式,构造了不同长度区间的样本(比如 100、200、300、400 词),然后分别评估 GECSCORE 的 AUROC。
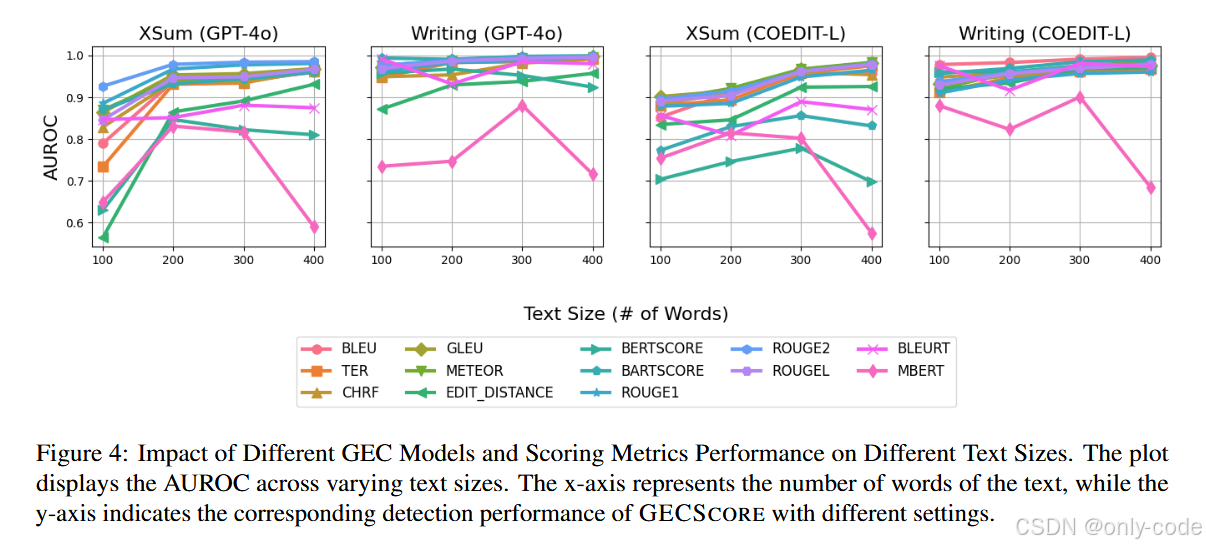
【图4——在不同文本长度下,使用 GPT-4o-mini / COEDIT-L + 不同指标时 AUROC 的变化曲线】
结论:
-
文本越长,GECSCORE 整体越稳定、越强,200 词以上效果就已经很不错,300 词以上几乎是“无脑稳”;
-
对于 100 词左右的短文本,GPT-4o-mini + ROUGE-2 仍能保持不错的性能,但一些指标会出现波动;
-
COEDIT-L 在 XSum 上要到 300 词以后才能和 GPT-4o-mini 持平,说明在更正式、简短的新闻文本上,大模型做 GEC 还是更有优势。
7. 实验结果与性能分析
7.1 实验设置:数据集、生成模型与对比方法
任务设定是标准的 黑盒零样本 LLM 文本检测:
-
数据集:
-
XSum:新闻摘要数据,风格正式、精炼;
-
Writing Prompts:创作型小说故事,叙事自由、风格多变。
每个数据集选取 500 篇人类文本,分别用各个 LLM 生成 500 篇机写文本,文本长度不少于 300 词。
-
-
生成模型:
-
GPT-3.5-turbo
-
PaLM-2-bison
-
GPT-4o
-
Claude-3.5-Sonnet
-
Llama-3-70B
-
-
对比方法(共 10 个):
-
零样本白盒:Log-Likelihood, Rank, Log-Rank, LRR, NPR, DetectGPT, Fast-DetectGPT
-
零样本黑盒:Revise-Detect
-
监督式:RoBERTa-base / RoBERTa-large 检测器(OpenAI 官方发布)
-
-
评价指标:AUROC、F1,且人类 / 机写样本数量始终平衡。
7.2 主结果:GECSCORE 的整体优势
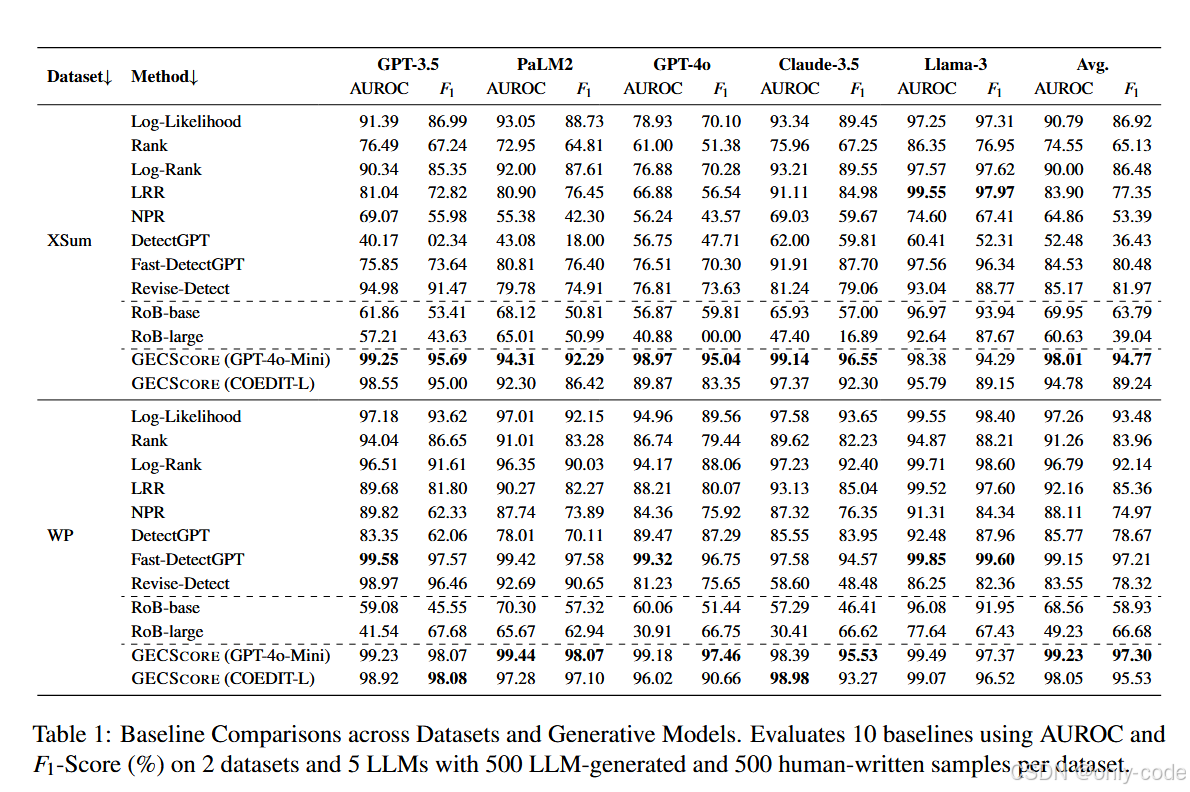
【表1——在 XSum & Writing Prompts 上,10 个基线方法与 GECSCORE 的 AUROC / F1 汇总表】
-
在 XSum 上:
GECSCORE(GPT-4o-mini)对五个生成模型的平均 AUROC 为 98.01%,平均 F1 为 94.77%,普遍优于 Fast-DetectGPT 和 Revise-Detect 等基线。
在 Llama-3-70B 上,LRR 的 AUROC 略高,但 GECSCORE 依然保持非常接近的表现。 -
在 Writing Prompts 上:
Fast-DetectGPT 的表现本来就很强(平均 AUROC 99.15%),但 GECSCORE(GPT-4o-mini)的平均 AUROC 也达到了 99.23%,F1 为 97.30%,几乎不相上下。 -
对比监督式 RoBERTa 检测器:
RoBERTa-base / large 在跨模型、跨领域时 AUROC 常常在 40%~70% 摇摆,F1 更低。相比之下,GECSCORE 平均 AUROC 提升约 29 个百分点,F1 提升 30+ 个百分点,证明零样本特征法在 OOD 场景下反而更可靠。
简单说:在不训练、不看 logits 的前提下,GECSCORE 和最强白盒方法打成平手甚至更好,还比多数监督式方法更稳。
7.3 特征贡献分析:语法错误差异 vs 纠错偏好
作者把“语法错误差异”和“LLM 纠错偏好差异”两部分拆开来看:
-
用 COEDIT-L 作为 GEC 模型时:
它是一个纯粹的 GEC 模型,没有特别的“LLM 风格偏好”。但 GECSCORE(COEDIT-L)在 Writing Prompts 上仍然达到 98.05% AUROC,在 XSum 上也有 94.78%,已经稳稳超过 Fast-DetectGPT 等 SOTA 方法。 -
用 GPT-4o-mini 时:
在上述结果基础上,平均 AUROC 又进一步提升几个百分点,尤其是在 XSum 上由 94.78% 提升到 98.01%。这部分增益可以理解为:大模型的“改错偏好”对人类文本更苛刻,为区分提供了额外信号。
所以一个非常重要的结论是:
单靠“人类语法错误比 LLM 多”这一点,就已经足够构建一个很强的检测器;如果再利用 LLM 的纠错偏好,效果会更上一层楼。
7.4 消融实验:指标、GEC 模型与文本大小
这一部分主要回答三个问题:换指标行不行?换 GEC 行不行?短文本行不行?
-
相似度指标:
综合来看,ROUGE-2 是最稳的一项,GPT-4o-mini 下平均 AUROC 约 97.89%,COEDIT-L 下也有 95.01%。chrF、BLEU、TER、ROUGE-L 等也表现良好,但稳定性略逊。 -
GEC 模型:
GPT-4o-mini 整体略强,尤其是在 150~300 词长度区间;COEDIT-L 在长文本上表现提升明显,是一个无需 API 调用、成本更低的可行替代方案。 -
文本长度:
随着长度增加,大多数指标的 AUROC 会提升或稳定,200~300 词以上即可获得非常可靠的检测效果。
【插图:图4 + 表2——不同文本长度和不同指标下的 AUROC 曲线与平均表现】
7.5 “在野外”的可靠性:跨领域、跨模型与改写攻击
7.5.1 跨领域(Cross-Domain)
作者用 XSum 的样本估计阈值,在 Writing Prompts 上测试,以及反过来的组合,来模拟“训练和部署领域不一致”的情况。
【插图:表3——在 XSum→WP 和 WP→XSum 跨领域场景下的 AUROC 变化】
结果显示:
-
GECSCORE(GPT-4o-mini)
-
XSum→WP:AUROC 97.60%(只掉了 1.63 个点);
-
WP→XSum:AUROC 94.10%(掉了 5.15 个点);
-
-
Fast-DetectGPT 平均掉了 8 个点以上;
-
其他方法有的甚至跌到 50% 附近。
这说明:GECSCORE 的阈值具有很强的可迁移性,语法错误这一信号跨领域依然稳定。
7.5.2 跨生成模型(Cross-Generator)
类似地,作者用 GPT-3.5 生成的数据估计阈值,在 Claude-3.5 上测试,反之亦然。
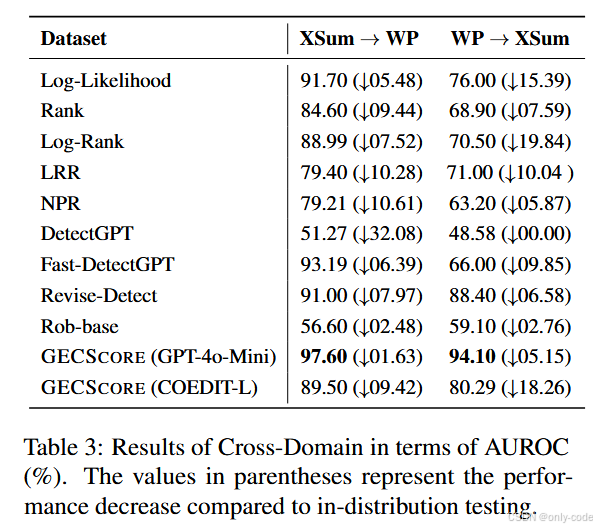
【表3——GPT↔Claude 跨模型泛化时的 AUROC 变化】
GECSCORE(GPT-4o-mini)在这两个方向上的 AUROC 仍然保持在 95%+,平均只掉 3.6 个百分点,而不少基线方法下降在 10 个点左右。
7.5.3 改写攻击(Paraphrase Attack)
最后是最关键的一组实验:把 LLM 生成的文本先喂给一个 T5 改写模型做 paraphrase,再看检测器还能不能识别出来。
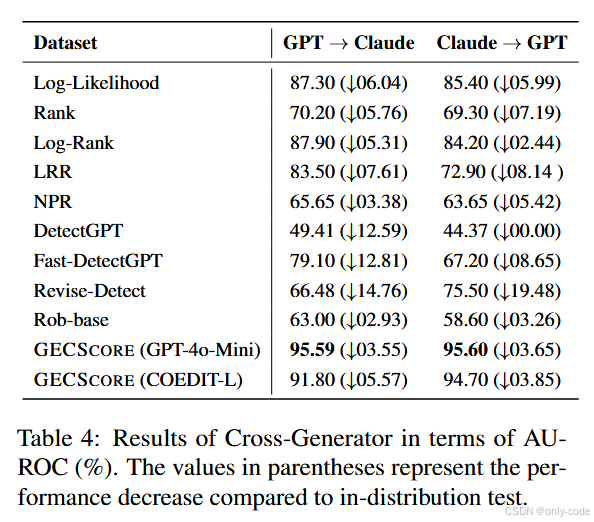
【表4——在 paraphrase 攻击下,各方法在 XSum & Writing Prompts 上的 AUROC 对比】
结论非常现实:
-
几乎所有零样本检测器 AUROC 平均掉 12.9 个百分点左右;
-
DetectGPT / Fast-DetectGPT 这类靠曲率特征的方法在改写后尤其容易失效;
-
GECSCORE 虽然也有下降,但仍然保持在一个相对靠前的水平,整体性能最为稳健。
作者没有做非常具体的错误案例分析,但从结果可以看出:只要 paraphrase 模型不刻意“改坏语法”,GECSCORE 仍然能抓住 residual 的语法差异和纠错偏好。
8. 亮点与创新点总结
如果要用叙述的方式记住这篇论文的几个“亮点”,我会这样说:
第一,问题设定非常现实。作者没有停留在“有 logits、有训练数据”的理想世界,而是直面现实:源模型不可见、标注数据稀缺。在这样的设定下能做到接近甚至超过白盒方法,非常难得。
第二,核心思路极其朴素但扎实:
“从 LLM 的视角看,人类写作更容易犯语法错误,因此‘纠错前后相似度’就是一个强信号。”
第三,方法结构极简,可复现性强。
没有复杂的对抗训练、没有多模型互相博弈,只是:GEC 一次,算分一次,阈值比较一次。任何有 GEC 模型和文本相似度工具链的团队,都可以很快复现并接到自己业务上。
第四,鲁棒性很强:
-
跨领域、跨模型时 AUROC 仍能保持在 94%~97% 之间;
-
在 paraphrase 攻击下仍是表现最好的方法之一;
-
文本长度变化时性能曲线也比较平滑。
第五,从思想上看,GECSCORE 把**“用 LLM 做任务”升级为“用 LLM 对人类写作做 meta 评价”**,有点“让模型做语文老师”那种味道。这种利用“纠错行为 / 修订行为本身当作特征”的思路,很有可能被后续工作大规模借鉴扩展到更多任务(比如风格检测、情感偏差检测等)。
9. 局限性与不足
论文最后单独写了“Limitations”,加上我们结合结果做一些延伸,可以看到 GECSCORE 仍然有不少边界条件。
(1)对文本完整性非常敏感
作者明确指出,如果输入是一段不完整的句子或残缺片段,GEC 模型很容易“顺手帮你补完”,从而混入大量风格化改写,破坏原本基于语法错误的信号。这时 GECSCORE 可能会误判。
在实际系统中,这意味着:
-
更适合用于篇章级、完整段落级检测;
-
对标题、短句、对话碎片,可能需要额外的策略(例如聚合多句一起检测)。
(2)可以被“刻意注入语法错误”的攻击绕过
从理论上讲,攻击者可以在 LLM 生成的文本里刻意加入大量语法错误,让它看起来更像人类写的,从而欺骗 GECSCORE。作者也承认这是一个潜在攻击方式,只是这类攻击会严重损害文本可读性,对正规使用者来说不太现实。
但如果攻击者本来就不在乎可读性(比如垃圾内容、刷量、恶意灌水),这种攻击方式仍然存在空间。
(3)对 GEC 模型质量和语言范围高度依赖
目前实验基本都在英文上进行,且依赖 GPT-4o-mini 或 COEDIT-L 这样的较强 GEC 模型。对于低资源语言、本地小模型,语法纠错质量下降时,GECSCORE 的优势可能会被削弱。
另外,调用 GPT 作为 GEC 也意味着:
-
成本和延迟不完全可控;
-
若部署在隐私敏感场景,还要考虑文本传输的合规问题。
(4)需要足够长的文本
从消融实验看,100 词以内的短文本上性能并不完美,很多指标波动明显。现实使用中如果只拿到短评论、短标题,单次 GECSCORE 可能不够稳,需要:
-
聚合多个短文本一起检测;
-
或者与其他信号(风格、词汇分布、元数据)结合。
(5)潜在的公平性问题(延伸思考)
论文没有展开这一点,但从语法错误角度来看,对非母语写作者可能存在偏置——他们本身语法错误更频繁,可能更容易被判定为“像 LLM 写的”或者“更异常”。如果未来 GECSCORE 应用到教育、考试等敏感场景,如何避免对特定群体不公平会是一个必须考虑的问题。
10. 全文总结
这篇论文试图在一个非常现实的设定中回答一个简单问题:“我能不能在不知道源模型、也没有标注数据的情况下,把 LLM 生成文本揪出来?”
作者提出的 GECSCORE 给出的答案是:**可以,而且还挺好用。**他们基于一个被数据验证过的假设——人类文本在语法上比 LLM 文本更“脏乱差”——构建了一个极其简单的黑盒零样本检测器:
用 GEC 模型先把文本改一遍,再用 ROUGE-2 看“改前改后有多像”,相似度越高越像 LLM 写的,越低越像人写的。
在 XSum 和 Writing Prompts 两个数据集,以及 GPT-3.5、PaLM-2、GPT-4o、Claude-3.5、Llama-3-70B 五个模型上,GECSCORE 的平均 AUROC 接近 98.6%,全面领先或持平于 Log-Likelihood、LRR、DetectGPT、Fast-DetectGPT 等强基线,也明显优于 RoBERTa 等监督式检测器。更难能可贵的是,它在跨领域、跨生成模型和 paraphrase 攻击下依然保持了很好的性能和稳定性。
当然,这个方法并非银弹:它依赖高质量 GEC 模型、需要足够长的文本,对刻意注入语法错误的攻击仍然有风险。不过作为一种简单、通用、可复现、贴近现实的黑盒零样本检测方案,GECSCORE 提供了一个非常有启发性的方向——有时候,最有效的特征可能不是复杂的概率曲率,而是“人类写作那些看似不起眼的小错误”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)