Ascend C Tiling 策略核心原理解析:数据切分的艺术与科学
本文深入探讨了AI处理器中Tiling(分块)技术的核心作用与实现方法。作为连接算法与硬件的桥梁,Tiling通过将大规模数据分割为适合片上缓存处理的Tile块,有效解决了"内存墙"问题。文章系统分析了Tiling的数据结构设计原则、数学基础算法(包括均匀切分和负载均衡优化),并详细阐述了其在矩阵乘法、卷积等场景中的应用策略,展示了Tiling如何通过双缓冲、流水线等技术实现计
目录
摘要
Tiling(分块)是连接算法与硬件的桥梁,是Ascend C高性能算子开发的核心技术。本文将从AI处理器的内存层次结构出发,深入解析Tiling的必要性、数据结构设计哲学、负载均衡算法及其与计算流程的协同。通过多级流程图、内存访问示意图和实例代码,揭示Tiling如何将大规模数据转化为适合AI Core高效处理的任务块,实现对硬件资源的极致利用。

(图1:源自您的素材,展示了Tiling的基本概念和在算子开发中的位置)
一、背景介绍:为什么Tiling是性能关键?
现代AI处理器(如昇腾AI Core)的计算能力远超其内存系统的数据供给能力,这种差距被称为"内存墙"。AI Core拥有强大的矩阵计算单元和向量处理单元,可以在一个时钟周期内完成大量运算,但其片上的Unified Buffer(UB)容量有限(通常为几百KB至几MB),而需要处理的数据(如大尺寸特征图、长序列等)往往达到GB级别。
核心矛盾:有限的高速缓存 vs 海量的输入数据
Tiling技术正是解决这一矛盾的关键。它将大规模张量(Tensor)分割成适合在UB中处理的较小数据块(Tile),通过"分而治之"的策略,使计算能够高效进行。没有合理的Tiling策略,再强大的计算单元也会因数据供给不足而处于空闲状态。
二、Tiling的基本概念与设计哲学
2.1 Tiling的本质定义
在Ascend C中,Tiling不是简单的数据分割,而是一个完整的数据调度策略,包含:
-
数据分块:如何将输入/输出张量划分为逻辑上的Tile
-
任务分配:如何将这些Tile映射到不同的AI Core
-
资源规划:如何管理UB、L1 Cache等存储资源
-
依赖管理:处理Tile间的数据依赖关系(如卷积中的重叠)
2.2 Tiling与内存层次结构的协同
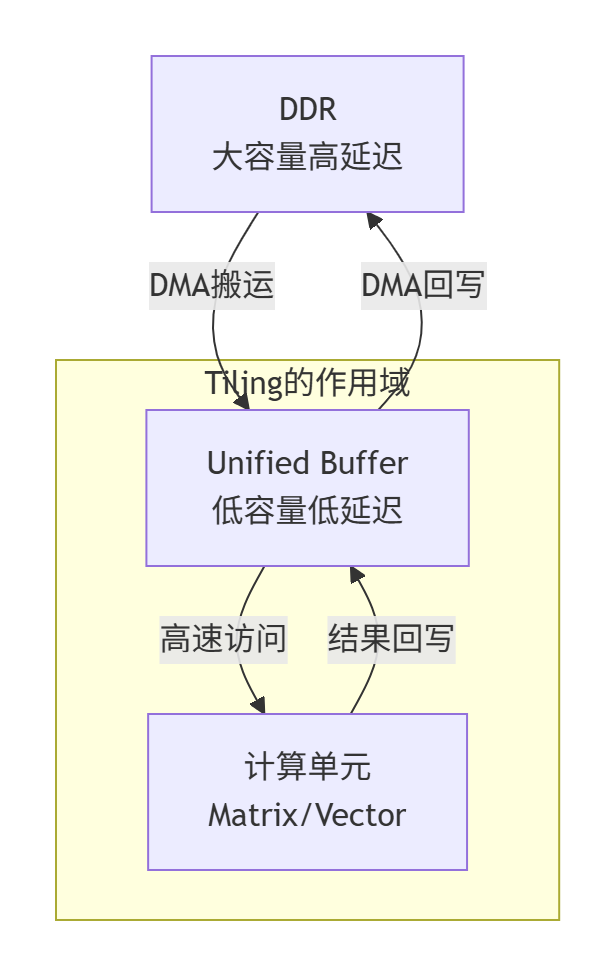
关键洞察:Tiling的目标是让计算尽可能在UB和计算单元之间进行,减少对高延迟DDR的访问。
2.3 Tiling数据结构的设计原则
Tiling数据结构是Host与Device间通信的契约,需要精心设计:
// 典型的Tiling数据结构示例
typedef struct {
// 基础信息
int total_length; // 数据总长度
int tile_num; // 总Tile数
int block_length; // 常规Tile长度
// 边界处理
int last_block_length; // 最后一个Tile的长度
bool has_tail; // 是否有尾块
// 多维信息(适用于矩阵/张量)
int dimM, dimN, dimK; // 各维度大小
int tileM, tileN; // Tile在各维度的划分
// 性能调优参数
int double_buffer_size; // 双缓冲大小
int pipeline_depth; // 流水线深度
} TilingData;设计原则:
-
完整性:包含Device端所需的所有切分信息
-
紧凑性:减少Host-Device通信开销
-
可扩展性:支持未来算法和硬件的演进
-
对齐友好:考虑内存访问的对齐要求
三、Tiling策略的数学基础与算法实现
3.1 基本切分算法
均匀切分算法:
void simple_tiling(TilingData* tiling, int total_length, int num_cores) {
tiling->total_length = total_length;
tiling->tile_num = num_cores;
tiling->block_length = total_length / num_cores;
tiling->last_block_length = total_length - (num_cores - 1) * tiling->block_length;
tiling->has_tail = (total_length % num_cores != 0);
}负载均衡优化算法:
void balanced_tiling(TilingData* tiling, int total_length, int num_cores, int min_tile_size) {
tiling->total_length = total_length;
// 动态计算最优Tile数,考虑最小Tile大小限制
int max_possible_tiles = total_length / min_tile_size;
tiling->tile_num = (max_possible_tiles < num_cores) ? max_possible_tiles : num_cores;
// 确保每个Tile大小接近且不小于最小值
tiling->block_length = total_length / tiling->tile_num;
if (tiling->block_length < min_tile_size) {
tiling->block_length = min_tile_size;
tiling->tile_num = (total_length + min_tile_size - 1) / min_tile_size;
}
tiling->last_block_length = total_length - (tiling->tile_num - 1) * tiling->block_length;
tiling->has_tail = (tiling->last_block_length != tiling->block_length);
}3.2 多维Tiling策略
对于矩阵乘法等复杂运算,需要多维Tiling:
// 矩阵乘法的Tiling数据结构
typedef struct {
int M, N, K; // 全局矩阵维度
int tileM, tileN, tileK; // Tile维度
int numTilesM, numTilesN, numTilesK; // 各维度Tile数
int total_tiles; // 总Tile数
} MatrixTilingData;
void matrix_tiling(MatrixTilingData* tiling, int M, int N, int K,
int ub_capacity, int data_type_size) {
// 基于UB容量计算最优Tile大小
int available_ub = ub_capacity * 0.8; // 保留20%余量
// 估算每个Tile所需存储:A_tile(M×K) + B_tile(K×N) + C_tile(M×N)
// 简化策略:优先保证K维度连续访问
tiling->tileK = K; // 初始假设整个K维度可放入UB
int required_size = (M * K + K * N + M * N) * data_type_size;
while (required_size > available_ub && tiling->tileK > 1) {
tiling->tileK /= 2;
required_size = (M * tiling->tileK + tiling->tileK * N + M * N) * data_type_size;
}
tiling->numTilesK = (K + tiling->tileK - 1) / tiling->tileK;
// ... 类似计算其他维度的切分
}四、Tiling与计算流程的深度融合
4.1 完整的Tiling-aware计算流程
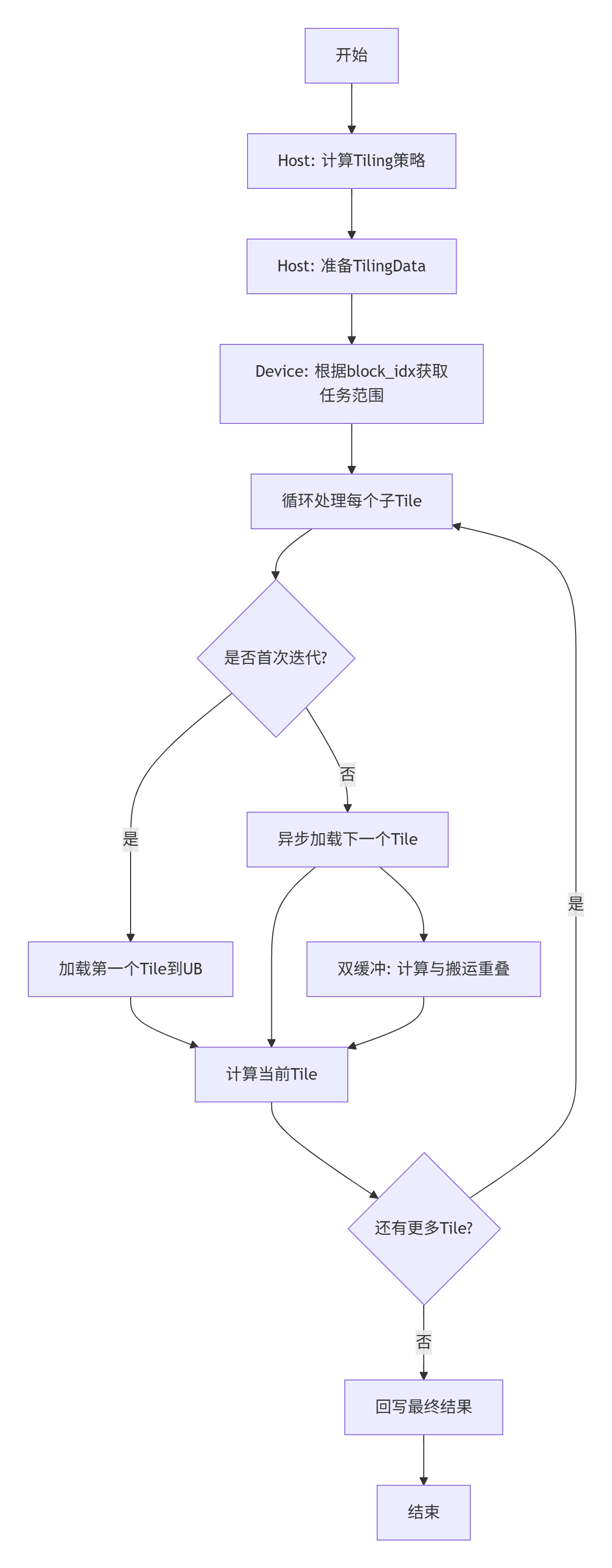
4.2 设备端Kernel中的Tiling处理
__global__ __aicore__ void tiling_aware_kernel(
const float* input, float* output, TilingData tiling) {
int block_idx = get_block_idx();
int block_dim = get_block_dim();
// 1. 基于Tiling数据计算本核的任务范围
int tile_start = block_idx * tiling.block_length;
int tile_size = (block_idx == tiling.tile_num - 1 && tiling.has_tail)
? tiling.last_block_length : tiling.block_length;
// 2. 为双缓冲分配UB空间
__gm__ uint8_t* input_addr = input + tile_start;
__gm__ uint8_t* output_addr = output + tile_start;
// 在UB中分配双缓冲区
uint8_t* ub_buffer[2];
ub_buffer[0] = ub_alloc(tile_size);
ub_buffer[1] = ub_alloc(tile_size);
int current_buffer = 0;
// 3. 流水线处理:计算与数据搬运重叠
for (int i = 0; i < tile_size; i += SUB_TILE_SIZE) {
int current_size = (i + SUB_TILE_SIZE > tile_size) ?
(tile_size - i) : SUB_TILE_SIZE;
// 异步加载下一个子Tile
if (i + SUB_TILE_SIZE < tile_size) {
int next_buffer = 1 - current_buffer;
dma_copy_async(ub_buffer[next_buffer],
input_addr + i + SUB_TILE_SIZE,
current_size);
}
// 处理当前子Tile
process_sub_tile(ub_buffer[current_buffer], current_size);
// 等待当前计算完成,切换缓冲区
current_buffer = 1 - current_buffer;
pipeline_wait();
}
// 4. 回写结果
dma_copy(output_addr, ub_buffer[0], tile_size);
}五、高级Tiling策略与优化技巧
5.1 基于数据复用的Tiling优化
在卷积等具有数据复用特性的算子中,Tiling策略需要特别设计以提升数据局部性:
// 卷积特定的Tiling策略
typedef struct {
int input_h, input_w; // 输入特征图尺寸
int kernel_h, kernel_w; // 卷积核尺寸
int output_h, output_w; // 输出特征图尺寸
int tile_h, tile_w; // 输出Tile的尺寸
int overlap_h, overlap_w; // 输入重叠区域
} ConvTilingData;
void conv_tiling_strategy(ConvTilingData* tiling, int ub_capacity) {
// 考虑输入特征图、权重和输出特征图的存储需求
// 优化目标:最大化输出Tile尺寸,同时最小化输入重复加载
int input_tile_size = (tiling->tile_h + tiling->overlap_h) *
(tiling->tile_w + tiling->overlap_w);
int output_tile_size = tiling->tile_h * tiling->tile_w;
int weight_size = tiling->kernel_h * tiling->kernel_w;
int total_size = (input_tile_size + output_tile_size + weight_size) * sizeof(float);
// 迭代调整Tile尺寸直到满足UB容量约束
while (total_size > ub_capacity && tiling->tile_h > 1) {
tiling->tile_h = max(1, tiling->tile_h / 2);
tiling->tile_w = max(1, tiling->tile_w / 2);
input_tile_size = (tiling->tile_h + tiling->overlap_h) *
(tiling->tile_w + tiling->overlap_w);
output_tile_size = tiling->tile_h * tiling->tile_w;
total_size = (input_tile_size + output_tile_size + weight_size) * sizeof(float);
}
}5.2 动态Tiling与自适应策略
对于动态形状的输入,需要运行时自适应Tiling:
class DynamicTilingManager {
private:
int history_tile_sizes[10]; // 历史Tile大小记录
int performance_metrics[10]; // 性能指标记录
public:
TilingData adaptive_tiling(int total_length, int data_pattern) {
TilingData tiling;
// 基于历史性能数据选择最优策略
int best_size = find_optimal_tile_size(total_length, data_pattern);
// 应用动态调整
if (should_adjust_strategy(total_length, best_size)) {
return create_balanced_tiling(total_length, best_size);
} else {
return create_fixed_tiling(total_length, best_size);
}
}
private:
int find_optimal_tile_size(int length, int pattern) {
// 基于机器学习或启发式规则选择最优Tile大小
// 考虑数据局部性、访问模式等因素
return heuristic_optimizer(length, pattern);
}
};六、性能分析与优化建议
6.1 Tiling策略的性能影响因子
通过建立性能模型,可以量化分析Tiling策略的影响:
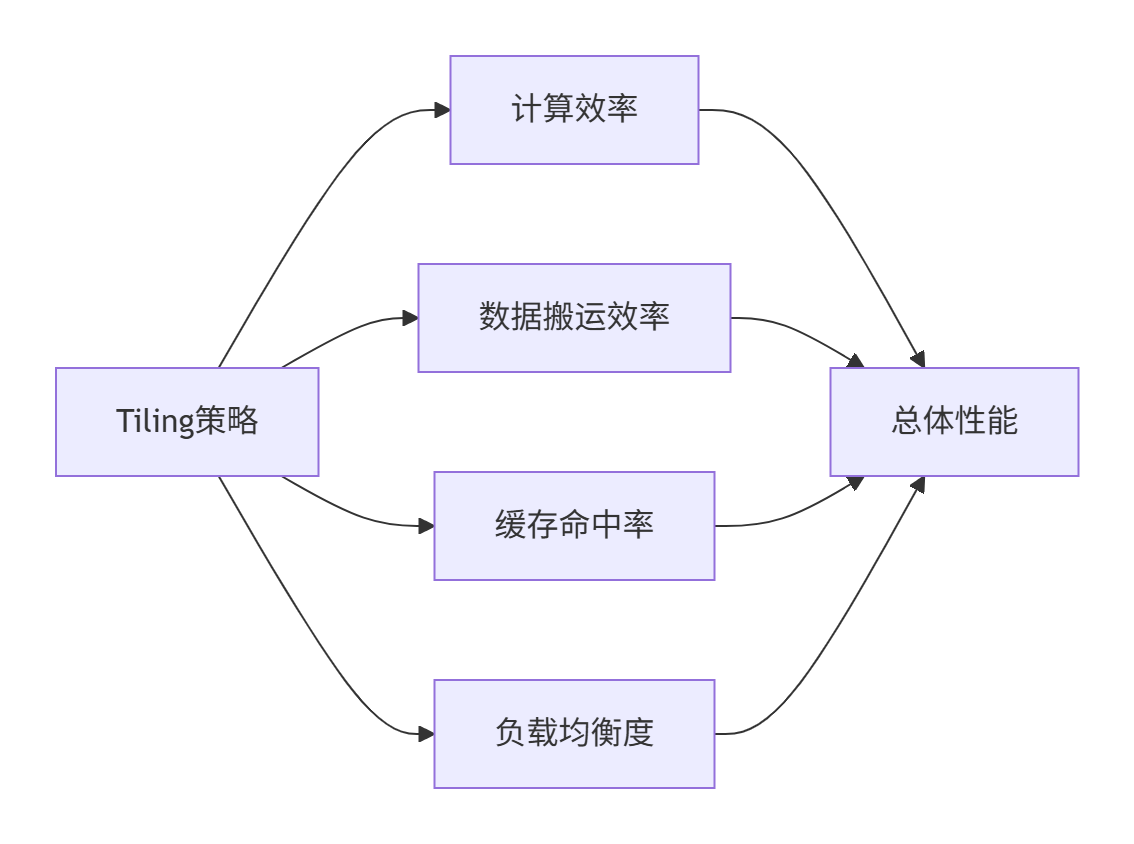
关键性能指标:
-
计算利用率:AI Core实际计算时间占比
-
数据搬运开销:DMA传输时间占比
-
缓存命中率:UB/L1 Cache的有效使用率
-
负载均衡度:各AI Core工作时间方差
6.2 Tiling大小选择的经验法则
基于实际项目经验,提供以下实用建议:
|
数据特征 |
推荐Tiling策略 |
理论依据 |
|---|---|---|
|
大尺寸稠密张量 |
中等Tile大小(UB容量的50-70%) |
平衡计算并行性与数据局部性 |
|
小尺寸多次调用 |
一次性处理完整数据 |
减少内核启动开销 |
|
不规则访问模式 |
较小Tile大小+数据预取 |
隐藏内存访问延迟 |
|
数据依赖性强 |
重叠区域Tiling |
处理边界依赖关系 |
七、总结与讨论
核心要点归纳:
-
Tiling是算法-硬件协同的关键:优秀的Tiling策略需要同时考虑算法特性和硬件约束
-
多层次优化视角:从数据分割到任务调度,Tiling影响整个计算流水线
-
动态适应性很重要:固定策略难以应对多样化的实际场景,需要一定的自适应能力
讨论问题:
-
您的实际项目中,遇到的最复杂的Tiling场景是什么?是如何解决的?
-
对于动态形状的神经网络算子,如何设计既高效又通用的Tiling策略?
-
随着AI硬件的发展(如更大的片上存储、更复杂的内存层次),您认为Tiling技术会如何演进?
八、参考链接
-
昇腾官方文档:Ascend C Tiling编程指南
-
学术参考:《Optimizing Memory Efficiency in Deep Learning Accelerators》- IEEE Micro
-
相关论文:《A Data-Centric Approach to Extreme-Scale Deep Learning》
-
最佳实践:华为ModelZoo中的算子实现样例
官方文档
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)