AI核心技术关键词:机器学习(深度解读)
AI核心技术关键词:机器学习(深度解读)
一、核心概念深度解析 - 什么是机器学习?
首先我们先要对机器学习的基本概念有一个认识。
1. 超越编程范式的定义:
传统编程是:输入数据 + 规则/程序 → 输出答案。
机器学习是:输入数据 + 输出答案 → 学习出规则/模型。
这个根本性的转变是革命性的。它意味着我们不再需要手动编写处理复杂问题(如垃圾邮件识别、语音识别)的每一条规则,而是让计算机从海量数据中自己“归纳”出规律。机器学习本质上是一个从数据中学习和做出决策的过程。
2. 核心三要素:
一个完整的机器学习系统离不开三个核心要素:
- 数据
:机器学习的“燃料”和“教材”。数据的质量、数量和代表性直接决定了模型性能的上限。没有高质量的数据,再先进的算法也是徒劳。
- 模型
:可以理解为一个数学函数,它接收输入数据,经过内部计算,产生一个输出。学习的过程,就是不断调整这个函数的内部参数,使其输出尽可能接近真实答案。
- 算法
:调整模型参数的“学习方法”或“优化策略”。它定义了如何根据模型的“犯错”程度来修正模型,使其下一次能表现得更好。
3. 学习的本质 - 泛化能力:
机器学习的终极目标不是完美复述已经见过的数据,而是要对从未见过的新数据做出准确的预测。这种能力称为“泛化能力”。一个在训练数据上表现完美,但在新数据上表现糟糕的模型,我们称之为“过拟合”,这是机器学习中最核心的挑战之一。
二、机器学习完整知识体系与技术栈
要系统掌握机器学习,需要遵循一个从理论到实践,从基础到应用的完整路径。其知识体系可以概括为下图所示的六个层次:
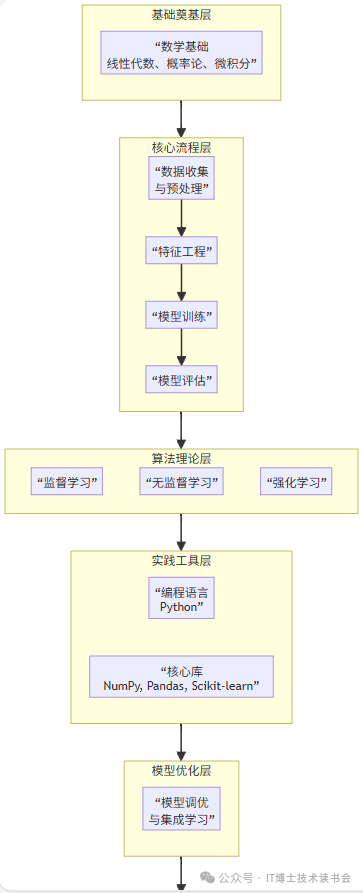
层次一:数学基础
这是理解算法背后原理的基石,无法绕过。
- 线性代数
:模型处理的数据通常是高维表格(矩阵)。理解矩阵、向量、张量及其运算(如矩阵乘法、特征值分解)是理解数据表示和模型运算的基础。
- 概率论与统计学
:机器学习本质是不确定性的推理。需要理解概念如概率分布、条件概率、贝叶斯定理、期望、方差、最大似然估计等,这些是许多模型(如朴素贝叶斯、高斯混合模型)的底层逻辑。
- 微积分
:模型训练的核心算法“梯度下降”依赖于求导。理解导数、偏导数、梯度是理解算法如何“学习”的关键。
层次二:机器学习算法的一般步骤和流程
这是一个端到端的机器学习项目和算法所必须遵循的步骤。
- 数据收集与预处理
-
- 数据收集
:从数据库、API、日志文件、公开数据集中获取原始数据。
- 数据清洗
:处理缺失值(删除、填充)、异常值(检测与处理)、不一致数据。
- 数据集成与转换
:合并多个数据源,进行数据规范化/标准化,将数据转换成适合模型处理的格式。
- 数据收集
- 特征工程
:这是机器学习项目中最耗时、最能体现工程师经验价值的环节。
-
- 特征选择
:从所有特征中筛选出对预测目标最有效的特征,减少冗余和噪声。方法有过滤法、包装法、嵌入法。
- 特征构造
:利用领域知识创造新的特征,以更好地表达数据的内在规律。例如,从日期中提取“是否周末”、“是一年中的第几周”等。
- 特征变换
:对特征进行数值转换,如归一化、离散化、独热编码(处理类别型变量)等。
- 特征选择
- 模型训练
:
-
- 数据集划分
:将数据分为训练集(用于模型学习)、验证集(用于调整超参数和模型选择)和测试集(用于最终评估模型泛化能力)。常用比例如 60-20-20 或 70-15-15。
- 选择算法
:根据问题类型(见下一层次)选择合适的机器学习算法。
- 学习过程
:算法在训练集上运行,通过优化目标(损失函数)自动调整模型参数。
- 数据集划分
- 模型评估
:
-
- 评估指标
:
- 评估指标
-
-
- 分类问题
:准确率、精确率、召回率、F1-Score、ROC曲线与AUC值。
- 回归问题
:均方误差(MSE)、平均绝对误差(MAE)、R-squared。
- 分类问题
-
-
- 评估方法
:除了简单的划分,还常用交叉验证,如k折交叉验证,以更稳健地评估模型性能。
- 评估方法
层次三:算法理论
这是机器学习的核心内容,根据学习范式分为以下几大类:
1. 监督学习
特点:数据带有标签(正确答案)。目标是学习一个从输入到输出的映射关系。
- 线性模型
:
-
- 线性回归
:用于预测连续的数值。原理是找到一条直线(或超平面)使得所有数据点到该直线的距离(误差)最小。
- 逻辑回归
:注意,它用于分类! 它通过一个Sigmoid函数将线性回归的输出映射到[0,1]区间,解释为属于某一类的概率。
- 线性回归
- 非线性模型
:
-
- 决策树
:模拟人类决策过程,通过一系列if-else问题对数据进行划分。非常直观,容易解释。
- 支持向量机(SVM)
:寻找一个能够将不同类别数据点分得最开的“超平面”,尤其擅长处理小样本、高维数据。
- 朴素贝叶斯
:基于贝叶斯定理,并假设特征之间相互独立。虽然“朴素”,但在文本分类等领域非常有效。
- 决策树
- 集成方法
:“三个臭皮匠,顶个诸葛亮”
-
- Bagging
:通过有放回抽样构建多个不同的训练子集,分别训练多个基模型,然后综合它们的预测(如投票或平均)。随机森林 是Bagging的典型代表,它通过引入特征随机性来构建多棵决策树,有效降低过拟合。
- Boosting
:按顺序训练一系列模型,后一个模型重点关注前一个模型预测错误的样本,通过不断修正错误来提升性能。AdaBoost 和 梯度提升树(如GBDT, XGBoost) 是代表。Boosting通常比Bagging能达到更高的精度,但需注意过拟合。
- Bagging
2. 无监督学习
特点:数据没有标签。目标是发现数据内在的结构和模式。
- 聚类分析
:
-
- K-Means
:将数据划分为K个簇,使得同一簇内的数据点尽可能相似,不同簇的数据点尽可能不同。
- 层次聚类
:通过计算数据点间的相似度,构建一个有层次的嵌套聚类树。
- K-Means
- 降维
:
-
- 主成分分析(PCA)
:一种线性降维方法,通过正交变换将原始特征转换为一系列线性不相关的特征(主成分),并按方差大小排序,保留前几个最重要的成分。旨在用更少的特征保留尽可能多的原始信息。
- 主成分分析(PCA)
- 关联规则学习
:
-
- Apriori
:用于发现大规模数据集中项与项之间的有趣关系,经典案例是“购物篮分析”。
- Apriori
3. 强化学习
特点:智能体通过与环境交互,根据获得的奖励或惩罚来学习最优策略。它不同于监督学习的“有标准答案”,也不同于无监督学习的“无答案”,它是一种“试错”学习。经典算法如Q-Learning。
层次四:实战工具
- 编程语言
:Python 是绝对的主流,因其拥有极其丰富的机器学习库和社区生态。
- 核心库
:
-
- NumPy
:提供高性能的多维数组对象和数学函数,是几乎所有其他科学计算库的底层基础。
- Pandas
:提供强大的数据结构和数据分析工具,如DataFrame,是数据预处理的利器。
- Scikit-learn
:机器学习入门和实战的瑞士军刀。它涵盖了从数据预处理、特征工程、到几乎所有经典机器学习算法(监督、无监督),以及模型评估工具。其API设计清晰统一,非常适合学习和快速原型开发。
- Matplotlib/Seaborn
:数据可视化库,用于探索性数据分析和结果展示。
- NumPy
层次五:模型优化
- 超参数调优
:模型在训练开始前需要设定的参数(如KNN中的K值,随机森林中树的棵树)。调优方法有:
-
- 网格搜索
:暴力遍历所有给定的参数组合。
- 随机搜索
:在参数空间中随机采样进行尝试,通常更高效。
- 网格搜索
- 集成学习
:如上文所述,通过组合多个弱模型来构建一个强模型,是提升模型性能的终极武器之一。
层次六:注意事项
- 偏差与方差
:理解模型误差的来源,是解决过拟合和欠拟合问题的理论指导。
- 动手实验
:没有任何一个算法在任何问题上都表现最好。必须通过实验为特定问题选择最合适的算法。
- 作者
: Trevor Hastie, Robert Tibshirani, Jerome Friedman
- 特点
: 这是前述《统计学习导论》的“父辈”,理论深度和广度都达到了很高水平。它详细推导了从线性模型到 boosting、支持向量机等众多算法的数学原理。可以在官网免费下载,是深入理解算法背后“为什么”的终极读物之一。
三、开创性经典论文
以下论文是机器学习各个分支的奠基性或极具影响力的工作。阅读原文可以让你直接领略大师的思维过程。
1. 决策树与模型可解释性
论文标题: Classification and Regression Trees
- 作者
: Leo Breiman, Jerome H. Friedman, Richard A. Olshen, Charles J. Stone
- 年份
: 1984
- 核心思想
: 这本书(通常被视为一篇开创性工作)系统性地提出了CART算法,为决策树在机器学习中的应用奠定了基础。它详细描述了如何通过递归分割来构建树,以及如何剪枝以避免过拟合。虽然是一本书,但其思想影响深远,是理解所有树模型的基础。
- 为何重要
: 它催生了现代所有基于决策树的模型,包括随机森林和梯度提升树。
2. 支持向量机与统计学习理论
论文标题: Support-Vector Networks
- 作者
: Corinna Cortes & Vladimir Vapnik
- 年份
: 1995
- 核心思想
: 这篇论文将Vapnik早先提出的统计学习理论(VC维)付诸实践,提出了软间隔支持向量机。它引入了核技巧,使得SVM可以高效地处理非线性分类问题。
- 为何重要
: SVM在21世纪初的十余年里是机器学习领域最强大的工具之一,这篇论文是将其推向主流的关键。它完美体现了统计学习理论中“最大化间隔”以提升泛化能力的思想。
3. 集成学习 - 随机森林
论文标题: Random Forests
- 作者
: Leo Breiman
- 年份
: 2001
- 核心思想
: 这篇论文正式提出了随机森林算法。它将Bagging思想和决策树训练时的特征随机选择相结合,构建了大量不相关的树,然后通过投票机制进行预测。Breiman在论文中证明了这种方法非常强大,能够有效控制过拟合,并且对噪声和异常值不敏感。
- 为何重要
: 随机森林因其出色的性能、简单的训练过程和良好的可解释性,至今仍是工业界最常用和最可靠的机器学习算法之一。
4. 集成学习 - 梯度提升
论文标题: Greedy Function Approximation: A Gradient Boosting Machine
- 作者
: Jerome H. Friedman
- 年份
: 2001
- 核心思想
: 这篇论文将Boosting思想解释为一个在函数空间上的数值优化问题,并提出了用梯度下降来求解。它奠定了所有现代梯度提升算法(如GBDT, XGBoost, LightGBM, CatBoost)的理论基础。论文中还详细介绍了 shrinkage(学习率)和采样等防止过拟合的技术。
- 为何重要
: 基于梯度提升的模型是当今结构化/表格数据竞赛和业务场景中性能最强大的模型之一。理解了这篇论文,就理解了XGBoost等工具的核心理念。
四、学习路径与方法建议
- 夯实基础
:
-
-
学习Python编程和NumPy, Pandas的基本操作。
-
复习(或学习)线性代数、概率统计的基础知识。
-
- 理论学习与工具入门
:
-
-
系统学习Scikit-learn库。跟着官方文档和教程,将其核心模块(预处理、特征工程、模型、评估)跑一遍。
-
同时学习机器学习的基本概念和流程(本回答的第二部分)。推荐课程:吴恩达的《机器学习》 Coursera 课程。
-
- 动手实践
:
-
-
前往Kaggle等平台,从最简单的比赛(如Titanic)开始,完整地走一遍数据清洗、特征工程、模型训练、调参、集成的流程。
- 关键
:不要只追求使用复杂的模型,要花大量时间在数据探索和特征工程上。尝试用简单的模型(如逻辑回归、决策树)作为基线,再逐步尝试更复杂的模型和集成方法。
-
- 深度钻研
:
-
-
选择一个你感兴趣的算法(如随机森林或SVM),去阅读教材或论文,深入理解其数学原理和工作细节。
-
在项目中,不仅要看最终的准确率,更要学会分析混淆矩阵、学习曲线、特征重要性等,理解模型为什么有效/无效。
-
阅读他人的代码和解决方案(特别是在Kaggle上),学习别人的思维方式和技巧。
-
- 书籍学习
:
-
-
建议从 《统计学习导论》 或 《Python机器学习基础教程》 开始,建立直观感受和实践能力。然后使用 周志华的《机器学习》 进行系统性的理论学习。学有余力时,再挑战Bishop或ESL这类更理论的书籍。
-
- 论文阅读
:初次阅读经典论文可能会很吃力。建议:
-
- 先掌握背景
:在阅读前,先通过书籍或课程了解该算法的基本概念。
- 抓住核心
:不要纠结于每一个数学细节。重点关注论文的引言和结论部分,理解作者要解决什么问题,提出了什么核心思想,以及这个方法的主要优势是什么。
- 结合实践
:在阅读论文的同时,尝试使用Scikit-learn等库实现该算法,加深理解。
- 先掌握背景
五、经典参考书籍
以下书籍按照推荐的学习顺序排列。
1. 入门与直观理解
《统计学习导论:基于R应用》
- 作者
: Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani
- 特点
: 这是机器学习入门的最佳选择之一。它不追求数学上的严密性,而是以直观的方式解释核心概念,并配有丰富的R语言实例。对于希望快速建立概念并能够上手实践的读者来说,这本书是无价之宝。
- 关联书籍
: 其进阶版是 《统计学习要素:数据挖掘、推理与预测》,数学性更强,被誉为“机器学习领域的圣经”,适合在入门后深入钻研。
《Python机器学习基础教程》
- 作者
: Andreas C. Müller & Sarah Guido
- 特点
: 如果你主要使用Python和Scikit-learn库,这本书是完美的实践入门指南。它详细介绍了机器学习的工作流程、Scikit-learn的使用方法以及常见算法的实际应用。它不深入数学,但极其注重工程实践。
2. 全面与系统学习
《机器学习》
- 作者
: 周志华
- 特点
: 中文领域绝对的经典,俗称“西瓜书”。这本书系统、全面地覆盖了机器学习的主要分支,内容组织精良。其叙述方式兼具广度和一定的深度,适合作为高校教材或系统自学的核心读物。书中的数学内容需要一定基础,但讲解非常清晰。建议搭配其“南瓜书”——《机器学习公式详解》一起学习,以化解数学推导的难度。
《模式识别与机器学习》
- 作者
: Christopher M. Bishop
- 特点
: 这是一本从贝叶斯视角贯穿始终的经典著作。数学上非常严谨,涵盖了概率图模型等高级主题。书中的插图(如PRML封面上的“贝叶斯狮子”)非常有名,有助于理解复杂概念。适合在有一定基础后,希望从概率层面深刻理解机器学习的读者。
3. 理论与进阶
《机器学习:一种概率视角》
- 作者
: Kevin P. Murphy
- 特点
: 正如书名所示,这本书完全从概率模型和贝叶斯推断的框架来统一讲解机器学习。内容极其丰富,堪称百科全书。它要求读者具备扎实的数学功底,是攻读博士学位或从事机器学习理论研究人员的必备参考书。
《The Elements of Statistical Learning》
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等
一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等
😝有需要的小伙伴,可以 下方小卡片领取🆓↓↓↓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献248条内容
已为社区贡献248条内容

所有评论(0)