论文阅读:NeurIPS 2025 Bits Leaked per Query: Information-Theoretic Bounds on Adversarial Attacks against
想象你是黑客,想让ChatGPT说出它不该说的话,你需要试多少次才能成功?这不仅取决于你的攻击技术,还取决于。对AI安全领域来说,这就像给防御者一把"测量尺",可以精确计算暴露不同信息的风险成本。每多给一点"提示"(信息),游戏难度就呈线性下降!**结果:**实验数据完美符合理论预测!✅ 实用指导(如何平衡透明度和安全性)✅ 理论下界(最少需要多少次查询)✅ 实际验证(7个模型的实验证据)让模型说
总目录 大模型相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
https://arxiv.org/pdf/2510.17000
https://claude.ai/share/a4449ce0-7315-4973-97cc-396e2d999f96
速览
核心问题
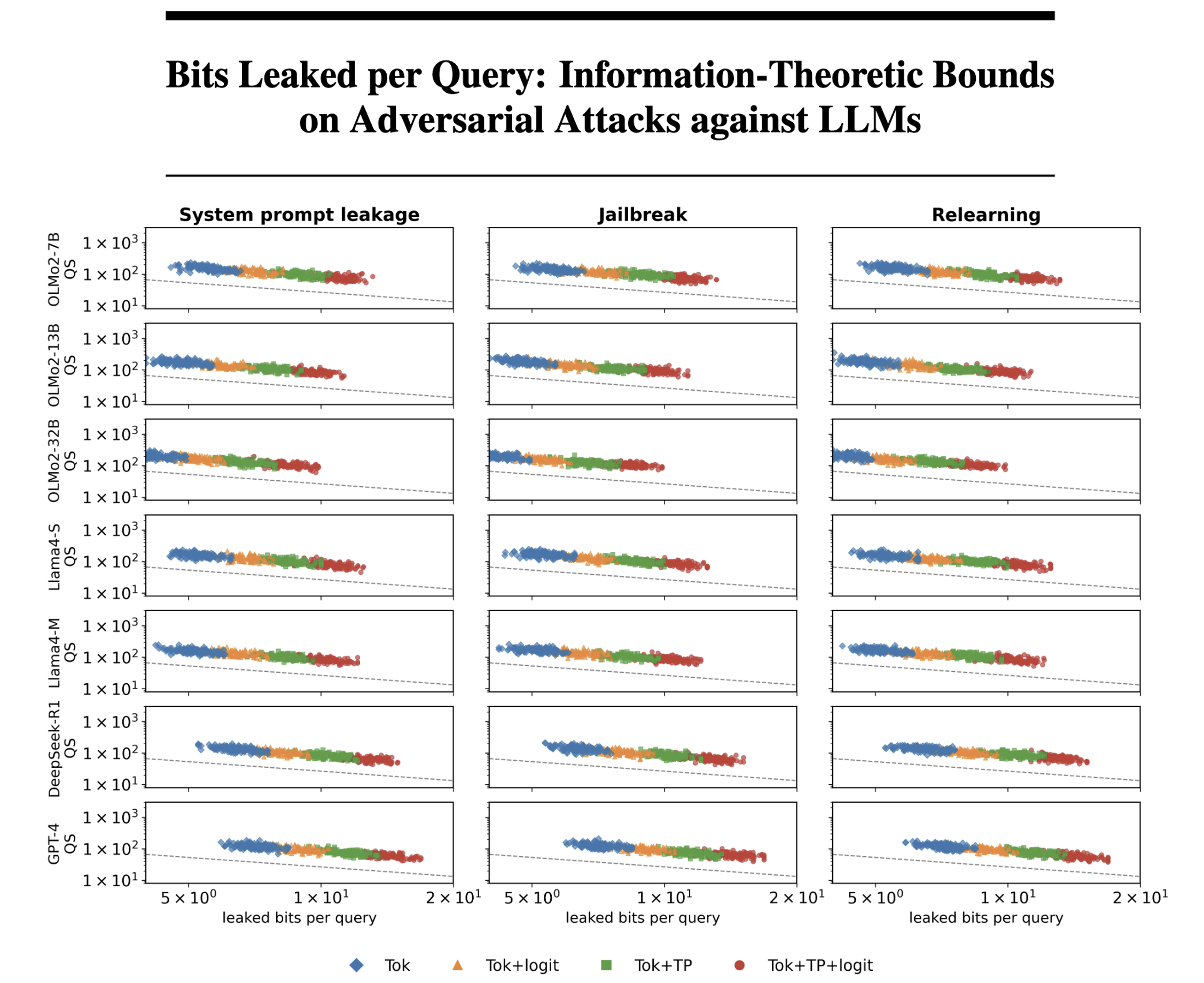
这篇论文研究了一个有趣的问题:攻击大语言模型(LLM)需要多少次尝试?
想象你是黑客,想让ChatGPT说出它不该说的话,你需要试多少次才能成功?这不仅取决于你的攻击技术,还取决于模型每次回复泄露了多少信息。
主要发现
论文用信息论给出了一个数学公式:
所需查询次数 N ≈ log(1/ε) / I(Z;T)
其中:
- ε 是你能容忍的失败率(比如5%)
- I(Z;T) 是"每次查询泄露的信息量"(用比特衡量)
这意味着什么?
-
泄露的信息越多,攻击越容易
- 只暴露答案文本:需要约1000次查询
- 暴露答案+概率值(logits):只需约100次查询
- 暴露完整思维过程:只需几十次查询!
-
呈现"倒数关系"
- 泄露信息翻倍 → 所需查询次数减半
- 这是线性关系,而不是平方关系
实验验证
研究团队在7个模型上测试了3种攻击场景:
1. 系统提示词泄露
让模型说出开发者设定的隐藏指令
2. 越狱攻击
让模型生成有害内容
3. 重学习攻击
恢复模型已经"忘记"的信息
**结果:**实验数据完美符合理论预测!
实际意义
对开发者:
- 透明度与安全的权衡:显示思维过程确实让模型更透明,但也让攻击容易10倍
- 量化风险:现在可以计算"暴露X比特信息会增加Y倍风险"
对攻击者:
- 提供了"理论上限":知道自己的攻击方法离最优还有多远
关键洞察
论文发现两个有趣的细节:
-
自适应攻击 vs 非自适应攻击
- 自适应(根据回复调整策略):完美符合理论
- 非自适应(预先准备问题):效率远低于理论
-
温度参数的影响
- 降低采样温度(让输出更确定) → 泄露减少 → 攻击难度指数级上升
- 但副作用是回复变得更单调
用类比理解
可以把LLM攻击想象成猜数字游戏:
- 传统方法:我随机猜,可能需要猜1000次
- 看到部分logits:你每次告诉我"高了还是低了",我只需猜100次
- 看到完整思维:你直接告诉我"你在想什么范围",我猜10次就够了
每多给一点"提示"(信息),游戏难度就呈线性下降!
论文价值
这是第一个用严格数学框架量化LLM攻防关系的研究,提供了:
✅ 理论下界(最少需要多少次查询)
✅ 实际验证(7个模型的实验证据)
✅ 实用指导(如何平衡透明度和安全性)
对AI安全领域来说,这就像给防御者一把"测量尺",可以精确计算暴露不同信息的风险成本。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献68条内容
已为社区贡献68条内容

所有评论(0)