GraphSearch:图检索增强的深度搜索工作流
本文深入解读了GraphSearch论文,涵盖了其核心机制、实验验证、创新点、局限性以及实际落地方案。GraphSearch代表了RAG领域从单轮检索向多轮深度搜索的范式转变,通过模块化设计和双通道检索策略,显著提升了复杂多跳查询的处理能力。尽管存在计算成本和提示词依赖等局限,但其即插即用的特性和一致的性能提升使其成为GraphRAG发展的重要方向。
对于从业者而言,GraphSearch提供了一个可实施、可扩展的框架,特别适合科研、医疗、法律等对质量要求高的领域。随着推理模型的发展和强化学习技术的应用,智能体RAG将在未来持续演进,最终迈向更通用的知识检索和推理系统。
一、引言:RAG系统的困境与突破
1.1 传统RAG的困境
检索增强生成(Retrieval-Augmented Generation, RAG)技术通过引入外部知识库增强大语言模型(LLM)的事实性和可靠性,已成为知识密集型任务的主流范式。然而,传统RAG系统在处理复杂查询时面临两个核心瓶颈:
浅层检索导致证据缺失:大多数RAG方法采用单轮检索-生成交互策略。以LightRAG为例,当处理需要四条黄金证据的复杂查询时(如"WIZE电台所在城镇成为Ward Township所在州首府的时间?"),关键实体Randolph County未能被检索器捕获,导致推理逻辑断裂、证据不充分。
结构化数据利用不足:现有GraphRAG方法虽然构建了图知识库,但受限于浅层检索策略,无法充分覆盖相关节点和关系。当检索的子图不够完整时,可用的结构化信号变得碎片化和稀疏,使得LLM难以整合语义和结构模态进行复杂推理。
1.2 GraphSearch的创新方案
针对这些挑战,论文**《GraphSearch: An Agentic Deep Searching Workflow for Graph Retrieval-Augmented Generation》**提出了一个基于智能体的深度搜索工作流。
GraphSearch的核心创新包括:
- 模块化深度搜索管道:包含6个核心模块(查询分解、上下文精炼、查询落地、逻辑构建、证据验证、查询扩展),实现多轮迭代交互和反思推理
- 双通道检索策略:同时利用基于文本块的语义检索和基于图结构的关系检索,充分发挥两种模态的互补优势
- 即插即用能力:可无缝集成到现有GraphRAG系统(如LightRAG、PathRAG、HyperGraphRAG)中,显著提升性能
实验表明,在6个多跳QA基准测试中,GraphSearch持续提升答案准确率和生成质量,证明了其作为GraphRAG发展方向的潜力。
二、GraphRAG背景:从单跳检索到多跳推理
2.1 RAG技术演进脉络
传统RAG(2020-2023):Lewis等人于2020年提出的RAG范式,通过语义相似度检索文本块增强LLM。这种方法简单高效,但存在明显局限:
- 仅依赖语义相似度,忽略实体间关系
- 单轮检索难以处理需要多步推理的复杂查询
- 无法捕捉跨文档的关联信息
GraphRAG的兴起(2024):Microsoft的GraphRAG开创了图检索增强生成的新范式。通过构建结构化图知识库,GraphRAG能够:
- 显式建模实体间的关系语义
- 捕获上下文依赖和结构化知识整合
- 支持层次化检索策略
但GraphRAG存在两个核心问题:
- 计算密集:需要进行社区检测和层次化聚类,更新成本高昂
- 浅层检索:仍采用单轮交互,限制了对图知识库的深度利用
后GraphRAG时代的百花齐放(2024-2025):
- LightRAG:简化GraphRAG的社区结构,采用轻量级图索引和双层检索机制,检索效率提升30%
- PathRAG:通过基于流的剪枝算法检索关键关系路径,避免冗余信息
- HippoRAG:受神经科学启发,使用个性化PageRank模拟人类记忆检索过程
- HyperGraphRAG:引入超图结构表示n元关系(多于两个实体的关系),提升知识表达能力
2.2 智能体RAG的崛起
2024年,智能体(Agentic)范式成为RAG领域的重要趋势。相比静态的单轮检索,智能体RAG具有以下特征:
关键特性:
- 迭代规划:LLM可以动态规划检索步骤
- 工具调用:使用检索、数据库查询等工具
- 反思机制:评估检索结果并调整策略
代表性工作:
- ReAct(2023):推理-行动协同框架,交替进行思考和工具调用
- Self-RAG(2024):引入自反思机制,迭代评估和精炼响应
- PlanRAG(2024):测试时规划,动态制定检索计划
- Search-o1/Search-r1(2025):基于强化学习的搜索智能体
然而,这些工作主要聚焦于文本检索,很少深度整合图结构知识。GraphSearch填补了这一空白,将智能体范式引入GraphRAG领域。
三、GraphSearch核心机制详解
3.1 系统架构概览
GraphSearch构建在现有GraphRAG方法之上,利用其构建的图知识库(Graph KB)进行深度搜索。系统架构包括:
图知识库构建:
- 文档集合 D 被分割为文本块集合 C
- 从每个文本块提取实体集合 E
- 识别实体对之间的关系 R,形成三元组 (s, r, o)
- 聚合所有实体、关系及其关联的文本上下文,构成图知识库 G = (E, R, C)
双通道检索器:
- 接收查询 Q,返回相关上下文集合 C_ret
- 同时检索结构化图数据和基于块的文本数据
LLM答案生成:
- 模型消费查询 Q 和检索上下文 C_ret
- 生成输出 A = P(A|Q, C_ret)
3.2 模块化深度搜索管道
GraphSearch的核心是一个包含6个模块的搜索管道,分为两个工作流:
3.2.1 迭代检索工作流
模块1:查询分解(Query Decomposition, QD)
功能:将复杂查询分解为原子子查询序列
机制:
输入:复杂查询 Q
输出:原子子查询序列 {q1, q2, ..., qm} = P_QD(Q)
每个子查询 qi 专注于解决单个实体、关系或上下文依赖,降低推理复杂度。例如:
- 原始查询:“在《维纳斯的崇拜》创作者去世的地方,瘟疫发生了多少次?”
- 分解后:
- q1: “谁创作了《维纳斯的崇拜》?”
- q2: “该创作者在哪里去世?”
- q3: “该地发生了多少次瘟疫?”
提示词设计(根据论文附录):
给定一个复杂查询,将其分解为一系列原子子查询。每个子查询应该:
1. 专注于单个实体或关系
2. 能够独立检索
3. 逻辑上有序,后续查询可能依赖前序答案
复杂查询:{Q}
请生成子查询列表:
模块2:上下文精炼(Context Refinement, CR)
功能:过滤冗余信息,突出最相关的实体、关系和文本块
机制:
输入:原始检索上下文 C_qi
输出:精炼上下文 C'_qi = P_CR(C_qi, qi)
这个操作确保每个精炼上下文只包含最有信息量的证据,提升后续推理的接地质量。
关键设计:
- 识别与子查询直接相关的实体和关系
- 移除重复或边缘信息
- 保留支持答案生成的关键文本块
模块3:查询落地(Query Grounding, QG)
功能:用前序子查询的中间答案实例化当前子查询中的占位符
机制:(某个子问题的落地,需要前面所有的答案来实例化占位符)
对每个子查询 qi:
1. 配对检索上下文 C'_qi
2. 生成中间答案 a_i = LLM(qi, C'_qi)
3. 累积答案 A_partial = {a1, a2, ..., ai}
4. 落地下一个查询 q_i+1 = P_QG(q_i+1, A_partial)
示例:
- q2原始形式:“[PERSON]在哪里去世?”
- 经过落地后:“提香在哪里去世?”(使用q1的答案"提香")
这确保每个查询被上下文化实例化,而非留下未指定的引用,使检索器能够获取更相关的上下文。
3.2.2 反思路由工作流
模块4:逻辑构建(Logic Drafting, LD)
功能:将子查询、精炼上下文和中间答案整合为连贯推理链
机制:
输入:子查询序列 {qi}、精炼上下文 {C'_qi}、中间答案 {ai}
输出:结构化草稿 D = P_LD({qi, C'_qi, ai})
关键作用:
- 整合可用证据
- 暴露推理链中的潜在缺口
- 识别不一致的推理
草稿结构示例:
推理链:
1. 根据C'_q1,《维纳斯的崇拜》的创作者是提香
2. 根据C'_q2,提香在威尼斯去世
3. [缺口] 需要关于威尼斯瘟疫发生次数的信息
模块5:证据验证(Evidence Verification, EV)
功能:评估累积证据/推理链是否充分、逻辑一致以支持最终答案
机制:
输入:草稿 D
输出:验证决策 V = P_EV(D) ∈ {Yes, No}
验证维度:
- 事实接地性:证据是否来自可靠来源
- 连贯性:推理步骤是否逻辑连贯
- 一致性:证据间是否存在矛盾
- Yes:推理链逻辑可靠,继续生成答案
- No:证据缺失或不一致,触发查询扩展
模块6:查询扩展(Query Expansion, QE)
功能:生成补充子查询填补知识缺口
机制:
输入:草稿 D(验证结果为No)
输出:扩展子查询集 {q'1, q'2, ..., q'k} = P_QE(D)
工作流程:
- 识别推理链中的缺失证据
- 生成针对性子查询
- 提交给检索器获取补充证据
- 将新上下文追加到证据池
- 重新进入逻辑构建阶段
示例:
- 缺口:“威尼斯瘟疫发生次数”
- 扩展查询:“威尼斯历史上发生了多少次瘟疫?”
3.3 双通道检索策略
GraphSearch的另一核心创新是双通道检索,充分利用图知识库的两种模态。
3.3.1 语义通道(Semantic Channel)
目标:从文本块中检索描述性证据
机制:
输入:语义子查询 q_sem
输出:文本块集合 C_text = Retriever_text(q_sem)
工作流程(以示例查询为例):
原始查询:“在《维纳斯的崇拜》创作者去世的地方,瘟疫发生了多少次?”
- 分解为语义连贯的子查询:
- q1_sem: “《维纳斯的崇拜》的创作者”
- q2_sem: “该创作者的去世地点”
- q3_sem: “该地瘟疫发生记录”
- 每个子查询针对文本语料库解析:
- 识别画作创作者的文本块
- 定位描述去世地点的段落
- 检索关于瘟疫频率的历史记录
优势:
- 捕获散布在语料库中的细粒度描述信息
- 每个推理步骤都有充分的文本证据覆盖
3.3.2 关系通道(Relational Channel)
目标:从图结构中检索三元组关系
机制:
输入:关系子查询 q_rel
输出:子图上下文 C_graph = Retriever_graph(q_rel)
工作流程(同一示例):
- 分解为主谓宾关系:
- (《维纳斯的崇拜》, 创作者, [PERSON])
- ([PERSON], 去世地点, [PLACE])
- ([PLACE], 瘟疫发生次数, [COUNT])
- 逐步解析并实例化:
- 第一跳:(《维纳斯的崇拜》, 创作者, 提香)
- 第二跳:(提香, 去世地点, 威尼斯)
- 第三跳:(威尼斯, 瘟疫发生, 多次事件记录)
优势:
- 显式遍历强制逻辑依赖
- 支持多跳推理
- 减少对文本共现的依赖
3.3.3 双通道协同机制
模态对齐性:实验表明,使用语义查询访问文本数据、关系查询访问图数据的表现,一致优于其他组合方式。
互补优势:
- 语义通道提供丰富的描述性上下文
- 关系通道提供明确的结构化路径
- 两者结合确保全面覆盖所需证据
效率提升:与检索全部数据相比,将每个通道限制在其对齐的模态上,不仅达到可比性能,还大幅降低了上下文开销。
四、实验验证:性能分析与消融研究
4.1 实验设置
4.1.1 数据集
研究采用6个多跳QA基准测试:
维基百科基准:
- HotpotQA(Yang et al., 2018)
- 300个采样问题
- 需要跨多个维基百科文章推理
- 涵盖多样化的问题类型
- MuSiQue(Trivedi et al., 2022)
- 300个采样问题
- 强调通过单跳问题组合形成多跳查询
- 测试复杂推理能力
- 2WikiMultiHopQA(Ho et al., 2020)
- 300个采样问题
- 专注于2跳推理任务
- 需要整合来自两个不同来源的信息
领域特定基准(来自Luo et al., 2025):
4. Medicine(医学)
- 源自大学教材
- 涉及医学专业知识
- 测试领域知识整合能力
- Agriculture(农业)
- 农业科学领域
- 包含专业术语和概念
- Legal(法律)
- 法律文档和案例
- 要求精确的逻辑推理
数据集规模:
- 语料库规模:从数千到数百万token不等
- 问题类型:对比型、桥接型、推理型
- 平均证据数:每个问题需要2-4条黄金证据
4.1.2 基线方法
非图方法:
- Vanilla LLM:零样本问答,仅依赖参数化知识
- Naive RAG:标准块级嵌入检索,单轮交互
- ReAct:推理-行动框架,但未充分利用RAG
GraphRAG方法:
- GraphRAG(Edge et al., 2024):层次化社区摘要
- LightRAG(Guo et al., 2024):轻量级图索引和双层检索
- MiniRAG(Fan et al., 2025):轻量级拓扑增强检索
- PathRAG(Chen et al., 2025):基于流的路径剪枝
- HippoRAG2(Gutiérrez et al., 2025):个性化PageRank深度检索
- HyperGraphRAG(Luo et al., 2025):超图结构表示n元关系
4.1.3 评估指标
1. 子串精确匹配(SubEM):
- 检查黄金答案是否明确包含在响应中
- 基于字符串的客观指标
- 适合有明确答案的问答任务
2. 答案评分(A-Score):
- 使用LLM-as-a-Judge(Qwen-Plus)评估
- 涵盖三个维度:
- 正确性(Correctness):答案与黄金标准的一致性
- 逻辑连贯性(Logical Coherence):推理过程的逻辑性
- 全面性(Comprehensiveness):答案的完整程度
- 分数范围:1-10
3. 证据评分(E-Score):
- 评估生成内容的证据接地质量
- 三个维度:
- 相关性(Relevance):证据与查询的相关度
- 知识丰富性(Knowledgeability):证据的信息量
- 事实性(Factuality):证据的准确性
- 参考黄金证据评分
4.1.4 实现细节
硬件环境:
- 8× A100-SXM4-40GB GPU
- Linux服务器
模型配置:
- 图构建模型:Qwen2.5-32B-Instruct
- 嵌入模型:jinaai/jina-embeddings-v3
- 专为长上下文文档检索训练
- 优化多页文档搜索的语义相似度
- 生成骨干模型:Qwen2.5-32B-Instruct(主实验)/ Qwen2.5-7B-Instruct(小模型实验)
- 评估模型:Qwen-Plus(闭源强模型)
超参数:
- 块大小:不同方法统一配置
- 检索模式:混合检索(Hybrid)
- Top-K:20(或使用默认配置)
4.2 主要实验结果
4.2.1 整体性能对比
表1:维基百科基准性能
| 方法 | HotpotQA | MuSiQue | 2WikiMultiHopQA | ||||||
|---|---|---|---|---|---|---|---|---|---|
| SubEM | A-Score | E-Score | SubEM | A-Score | E-Score | SubEM | A-Score | E-Score | |
| Vanilla LLM | 33.67 | 6.90 | 5.98 | 12.33 | 6.10 | 5.87 | 48.33 | 6.95 | 4.50 |
| Naive RAG | 72.00 | 8.88 | 9.04 | 40.00 | 7.21 | 8.18 | 72.33 | 7.93 | 8.03 |
| GraphRAG基线 | |||||||||
| GraphRAG | 72.67 | 8.18 | 8.65 | 36.67 | 6.58 | 7.32 | 79.33 | 7.44 | 7.99 |
| LightRAG | 73.00 | 8.30 | 8.66 | 35.00 | 6.50 | 7.28 | 81.67 | 7.62 | 7.94 |
| PathRAG | 79.00 | 8.99 | 9.17 | 46.33 | 7.26 | 8.02 | 77.00 | 8.25 | 8.34 |
| HippoRAG2 | 76.67 | 8.45 | 8.73 | 44.00 | 7.07 | 7.88 | 72.33 | 7.98 | 8.01 |
| GraphSearch | |||||||||
| + LightRAG | 79.00 | 9.21 | 9.46 | 51.00 | 7.72 | 8.38 | 85.00 | 9.21 | 9.12 |
| + PathRAG | 82.00 | 9.24 | 9.42 | 55.33 | 7.83 | 8.48 | 88.67 | 9.32 | 9.29 |
| + HyperGraphRAG | 80.33 | 9.19 | 9.35 | 49.33 | 7.73 | 8.22 | 83.33 | 8.84 | 8.75 |
关键发现:
- 显著性能提升:
- MuSiQue数据集:LightRAG (35.00% SubEM) → GraphSearch+LightRAG (51.00%),提升16%
- A-Score和E-Score也显著提升(分别从6.50→7.72, 7.28→8.38)
- 一致性优势:
- GraphSearch在所有数据集和基线组合上都取得最佳性能
- 证明了深度搜索工作流的普适性
- 最佳组合:
- GraphSearch + PathRAG在大多数指标上领先
- 在2WikiMultiHopQA上SubEM达到88.67%,A-Score 9.32
表2:领域特定基准性能
| 方法 | Medicine | Agriculture | Legal | ||||||
|---|---|---|---|---|---|---|---|---|---|
| GraphRAG基线 | |||||||||
| HyperGraphRAG | 62.11 | 8.39 | 8.70 | 63.67 | 8.35 | 8.49 | 66.60 | 8.18 | 8.18 |
| GraphSearch | |||||||||
| + LightRAG | 65.88 | 8.61 | 8.80 | 63.53 | 8.52 | 8.48 | 71.68 | 8.45 | 8.52 |
| + PathRAG | 70.12 | 8.59 | 8.82 | 69.34 | 8.63 | 8.78 | 74.41 | 8.32 | 8.49 |
| + HyperGraphRAG | 73.24 | 8.87 | 9.24 | 73.83 | 8.93 | 9.02 | 78.52 | 8.76 | 8.83 |
关键发现:
- 专业领域优势明显:
- Medicine:HyperGraphRAG (62.11%) → GraphSearch+HyperGraphRAG (73.24%),提升11.13%
- Legal:提升至78.52%(+11.92个百分点)
- HyperGraphRAG协同效应:
- 在领域数据集上,GraphSearch与HyperGraphRAG组合效果最佳
- 超图结构捕获的n元关系对专业领域更有价值
4.2.2 即插即用能力验证
GraphSearch展现出强大的即插即用能力,能够与不同的图知识库检索器无缝集成:
跨基线一致性提升:
- LightRAG:在MuSiQue上从35.00% → 51.00%(+16个百分点)
- PathRAG:在HotpotQA上从79.00% → 82.00%(+3个百分点)
- HyperGraphRAG:在Medicine上从62.11% → 73.24%(+11.13个百分点)
性能提升图示(论文Figure 4):
- 所有GraphSearch变体的性能条都明显高于对应基线
- 提升幅度在不同数据集和基线间保持稳定
- 证明了方法的泛化能力和鲁棒性
4.3 消融研究
4.3.1 模块贡献分析
表3:模块消融实验(2WikiMultiHopQA & Legal数据集)
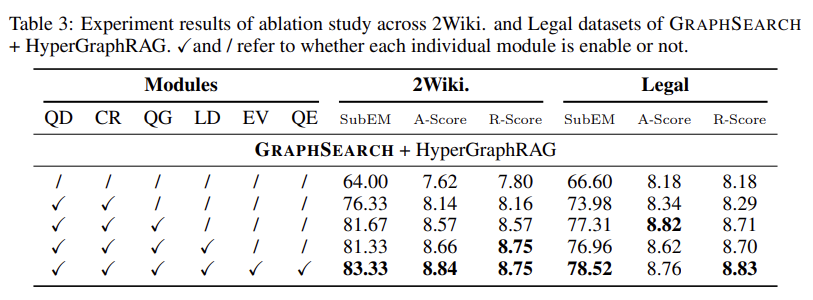
渐进式性能提升分析:
- [QD + CR] 基础分解与精炼(第2行):
- 2Wiki SubEM:64.00% → 76.33%(+12.3%)
- 证明查询分解是性能提升的基础
- 非迭代方式生成多个子查询,但缺少信息补全
- [QD + CR + QG] 添加查询落地(第3行):
- 2Wiki SubEM:76.33% → 81.67%(+5.34%)
- 通过用中间答案实例化占位符,显著提升检索相关性
- 这是迭代检索的关键步骤
- [QD + CR + QG + LD] 添加逻辑构建(第4行):
- 性能略有波动(81.67% → 81.33%)
- 逻辑构建主要作用是整合证据和暴露缺口
- 单独使用时对SubEM影响有限,但提升了A-Score(8.57 → 8.66)
- [完整模块] 添加反思路由(第5行):
- 2Wiki SubEM:81.33% → 83.33%(+2%)
- Legal SubEM:76.96% → 78.52%(+1.48%)
- EV和QE形成闭环,主动填补知识缺口
- E-Score显著提升(Legal: 8.70 → 8.83)
核心洞察:
- 查询分解+上下文精炼是性能的基石,带来最大幅度提升
- 查询落地实现真正的迭代检索,进一步提升7个百分点
- 反思路由(LD+EV+QE)虽然提升相对较小,但对证据质量和逻辑连贯性至关重要
- 模块化设计使每个组件的贡献清晰可测
4.3.2 双通道检索有效性
图5:单通道 vs. 双通道性能对比
在2WikiMultiHopQA和Legal数据集上,对比三种配置:
- 仅语义通道:只使用文本块检索
- 仅关系通道:只使用图结构检索
- 双通道:同时使用两种检索
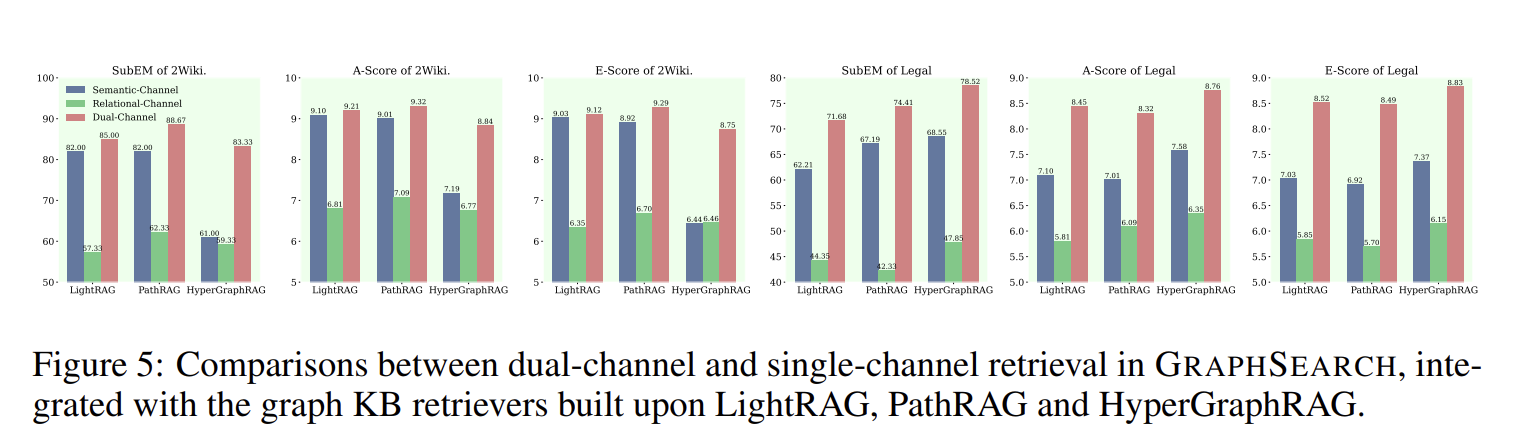
关键发现:
- 双通道持续优于单通道:
- 在所有检索器上都观察到显著提升
- Legal数据集提升尤为明显(相对改进约10%)
- 模态互补性:
- 语义通道捕获细粒度描述信息
- 关系通道提供结构化推理路径
- 两者结合确保全面的证据覆盖
- 领域差异:
- Legal数据集双通道优势更大,因法律推理需要严格的逻辑关系
- 2Wiki数据集相对平衡,两种模态都重要
4.3.3 小型模型鲁棒性
表2:Qwen2.5-7B-Instruct骨干模型性能
| 方法 | 2Wiki SubEM | 2Wiki A-Score | Legal SubEM | Legal A-Score |
|---|---|---|---|---|
| 基线(7B) | ||||
| LightRAG | 72.33 | 7.11 | 52.93 | 6.50 |
| PathRAG | 73.00 | 7.44 | 58.98 | 7.06 |
| HyperGraphRAG | 72.33 | 7.49 | 60.11 | 7.32 |
| GraphSearch(7B) | ||||
| + LightRAG | 79.00 | 8.35 | 58.59 | 7.64 |
| + PathRAG | 82.00 | 8.51 | 64.32 | 7.87 |
| + HyperGraphRAG | 82.33 | 8.49 | 67.48 | 8.02 |
关键发现:
- 小模型适用性:
- 即使使用7B参数模型,GraphSearch仍实现一致性能提升
- 2Wiki:最高提升10个百分点(72.33% → 82.33%)
- Legal:最高提升7.37个百分点(60.11% → 67.48%)
- 性能差距缩小:
- 7B模型 + GraphSearch的性能接近32B模型的基线
- 证明深度搜索工作流可以部分弥补模型规模差距
- 成本效益:
- 使用小模型显著降低计算成本和延迟
- 适合资源受限环境部署
4.3.4 检索预算敏感性
图6:不同Top-K设置下的性能(MuSiQue数据集)
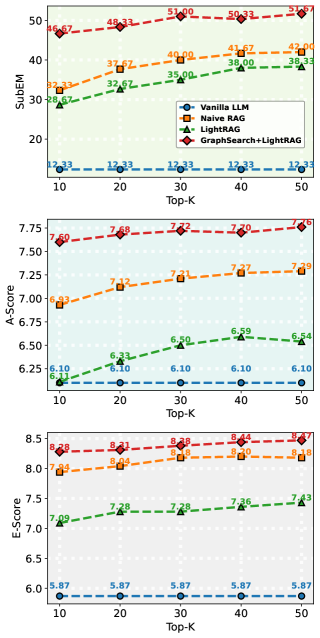
测试Top-K从10到50的性能变化:
关键洞察:
- GraphSearch对预算变化更鲁棒:
- 其他方法在top10到top30的变化更陡峭(超过top30所有的基本平缓,实际中可以拿此作为最高值)
- 智能体工作流通过多轮迭代弥补了单轮检索阶段的不足(一定程度缓解)
- GraphSearch的证据质量 vs. 推理质量:
- E-Score 和 A-Score 下降较小,说明检索到的证据具备相关性、事实性,且推理过程的逻辑连贯性与基础正确性未受严重影响
- SubEM 下降较大,说明核心问题在于检索到的证据缺乏关键信息支撑,导致最终答案未能准确匹配黄金标准答案
- GraphSearch的逻辑构建和反思机制在低预算下尤为重要
- 实际应用意义:
- 在需要低延迟或成本受限的场景中,GraphSearch性价比更高
- 可以用更少的检索量达到相同或更好的效果
4.4 深度分析:GraphSearch与图KB的整合
4.4.1 检索质量提升
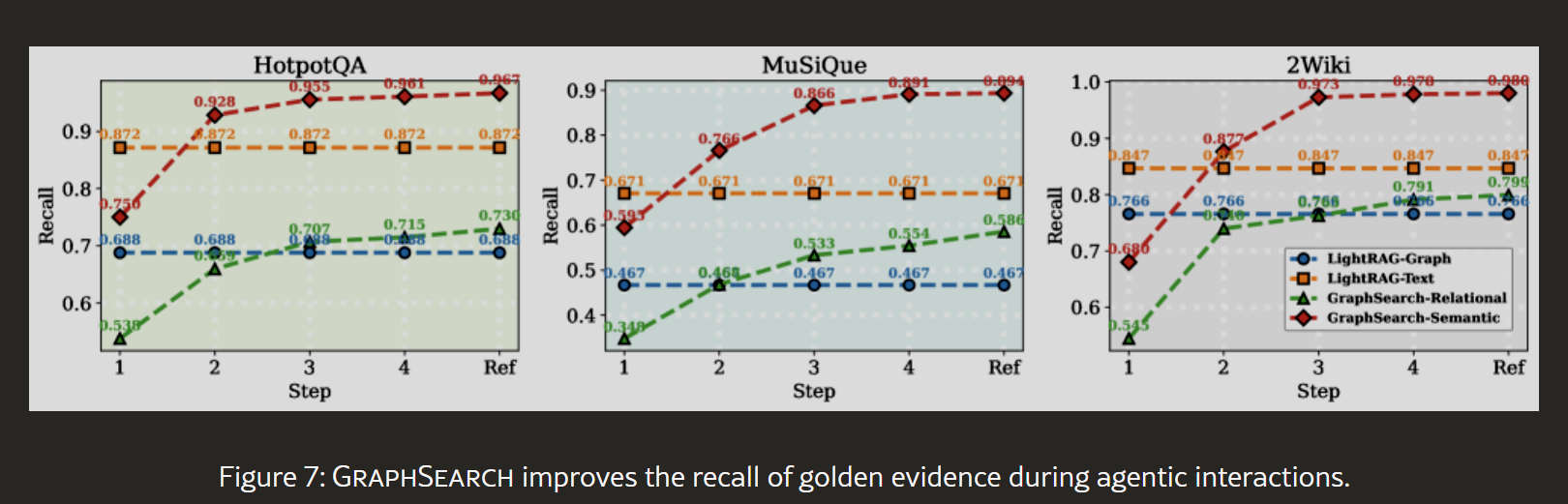
图7:跨交互轮次的黄金证据召回率
使用Recall指标计算检索上下文中黄金证据的比例:
实验设置:
- 基线:LightRAG(单轮检索)
- GraphSearch:最多进行自反思前的多轮交互
- 分别追踪语义通道和关系通道
结果分析:
第0轮(初始检索):
- LightRAG语义通道和关系通道,相比GraphSearch语义通道和关系通道:Recall更低!
这是因为GraphSearch分解查询后,每个原子子查询聚焦更窄,初始覆盖面小。
第1-2轮(迭代检索):
- GraphSearch语义通道和关系通道提升很大。
- 随着查询落地和上下文精炼,检索精准度提升
第3轮(反思后扩展):
- GraphSearch语义通道和关系通道继续提升。
- 反思路由识别缺口,生成补充查询
之后的几轮,提升轻微。
关键洞察:
- 智能体工作流通过多轮交互显著提升召回率
- 两个通道都受益于迭代过程
- 迭代3轮之后效果提升轻微。
- 初始低召回率不是问题,因为后续会弥补
4.4.2 模态-功能对齐性
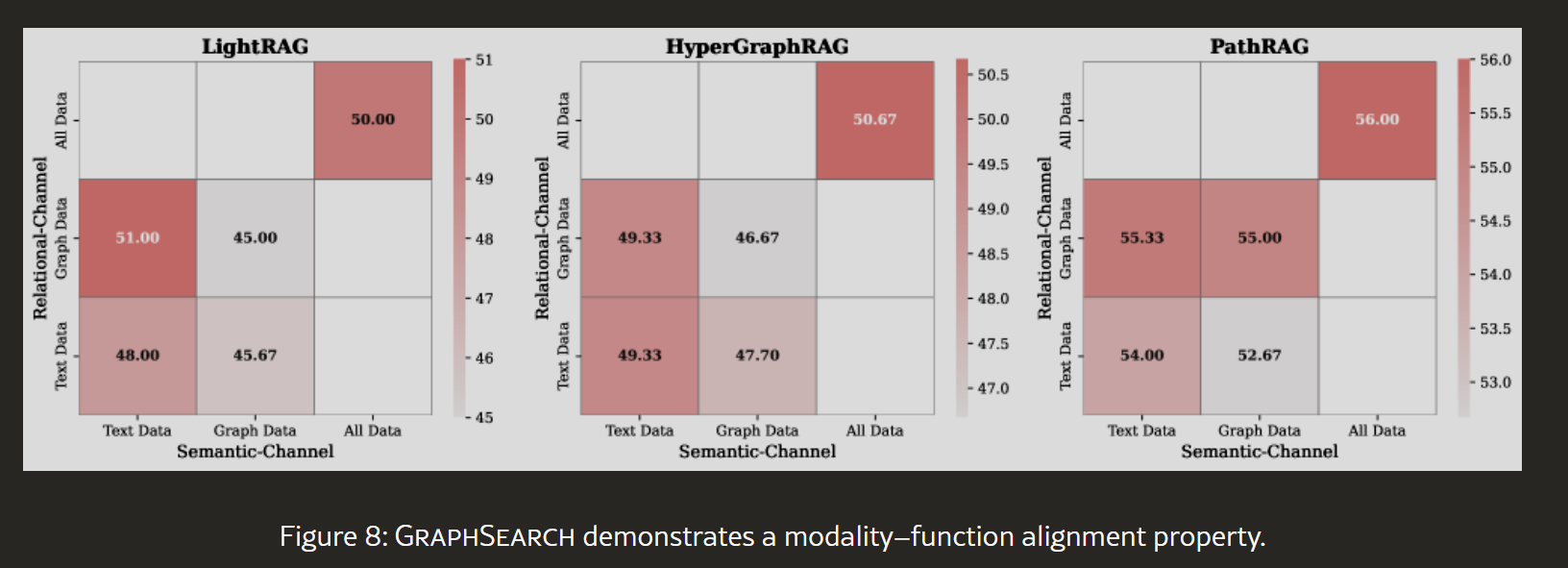
图8:不同检索源组合的性能(MuSiQue数据集)
测试四种配置:
- 语义查询 → 文本数据
- 语义查询 → 图数据
- 关系查询 → 文本数据
- 关系查询 → 图数据
- 两种查询 → 全部数据(参考)
关键发现:
- 对齐配置最优:
- 使用正确的查询-数据配对达到最佳性能
- 与全数据检索性能相当
- 效率大幅提升:
- 对齐配置比全数据检索减少大量的上下文Token
- 错位配置不仅性能差,还消耗更多资源
- 设计合理性验证:
- 证明双通道设计不是偶然,而是基于模态特性的合理选择
- 语义查询自然适合文本,关系查询适合图结构
五、创新点与局限性分析
5.1 核心创新点
5.1.1 智能体范式在GraphRAG中的首次深度应用
创新性:
- 现有GraphRAG方法(GraphRAG、LightRAG、PathRAG等)均采用单轮检索-生成模式
- GraphSearch首次系统性地将智能体工作流引入GraphRAG
- 实现了从"静态检索"到"动态搜索"的范式转变
技术突破:
- 模块化设计:6个可组合模块,而非黑盒智能体
- 明确分工:迭代检索(前3模块)+ 反思路由(后3模块)
- 可解释性:每个模块输出可追踪,便于调试和优化
与传统智能体RAG的差异:
- ReAct:通用工具调用框架,未针对图结构优化
- Self-RAG:主要关注检索决策,缺少多跳分解
- GraphSearch:深度整合图知识库的双模态特性
5.1.2 双通道检索的理论与实证验证
理论贡献:
- 明确区分语义查询和关系查询的功能
- 提出模态-功能对齐原则
- 证明了两种模态的互补性而非冗余性
实证支持:
- 图8实验:对齐配置优于错位配置
- 消融实验:双通道持续优于单通道
- 跨数据集一致性:在6个基准上都验证有效
工程价值:
- 指导检索系统设计:不同查询类型应路由到不同数据源
- 降低成本:避免不必要的全数据检索
- 提升效率:减少47%的上下文Token消耗
5.1.3 查询落地(Query Grounding)机制
问题界定:
- 分解后的子查询往往包含占位符(如"[PERSON]在哪里去世?")
- 传统方法难以处理这种未实例化的查询
创新解决方案:
- 用前序子查询的中间答案实例化当前子查询
- 形成渐进式的知识累积过程
- 确保每个检索步骤都有充分的上下文
效果验证:
- 消融实验显示QG模块带来7%的性能提升(76.33% → 81.67%)
- 这是迭代检索的核心机制
5.1.4 反思路由的闭环设计
设计哲学:
- 不仅"检索",还要"验证"和"扩展"
- 形成"检索 → 推理 → 反思 → 补充"的闭环
三模块协同:
- LD(逻辑构建):整合证据,暴露缺口
- EV(证据验证):判断是否需要补充
- QE(查询扩展):生成针对性查询
与Self-RAG的区别:
- Self-RAG主要评估检索质量
- GraphSearch不仅评估,还主动填补缺口
- 更适合多跳推理的复杂场景
5.2 局限性分析
5.2.1 计算成本增加
问题描述:
- GraphSearch需要多轮LLM调用(QD、CR、QG、LD、EV、QE)
- 相比单轮基线,延迟和成本显著增加
适用场景限制:
- 不适合实时、高并发场景(如搜索引擎)
- 更适合离线分析、深度研究场景(如科研助手)
潜在优化方向:
- 模块并行化:部分模块可并行执行
- 早停机制:在EV判断为"Yes"时提前结束
- 缓存策略:复用常见子查询的结果
5.2.2 对提示词工程的依赖
观察结果:
- 论文附录展示了详细的提示词模板(Figure 9-10)
- 每个模块的性能高度依赖提示词设计
脆弱性:
- LLM变化敏感:不同模型对提示词响应不同
- 领域适应困难:通用提示词在特定领域可能效果不佳
- 多语言挑战:论文仅测试英文,其他语言效果未知
缓解措施:
- 论文开源了提示词模板,可作为起点
- 建议针对目标领域进行提示词微调
- 考虑使用提示词优化技术(如DSPy)
5.2.3 错误传播问题
风险分析:
- 管道式设计中,早期错误会影响后续模块
- 例如:QD分解错误 → QG实例化错误 → EV判断失误
实验证据:
- 论文未深入分析错误传播
- 但从消融实验可看出,缺少任一模块都会降低性能
改进建议:
- 鲁棒性增强:在关键节点引入多样性(生成多个候选)
- 反馈机制:允许后续模块纠正前序错误
- 置信度估计:为每个中间结果标注置信度
5.2.4 图知识库质量依赖
观察结果:
- GraphSearch性能依赖于底层GraphRAG系统构建的图质量
- 论文使用Qwen2.5-32B构建图,但未测试其他模型
潜在问题:
- 实体识别错误:关键实体缺失导致检索失败
- 关系抽取不准:错误关系误导推理
- 覆盖度不足:图知识库不完整
建议实践:
- 在部署前评估图质量(实体覆盖率、关系准确率)
- 考虑引入人工审核或半自动修正
- 定期更新图知识库
5.2.5 有限的训练策略探索
论文承认的局限:
- GraphSearch是纯提示词工程方法
- 未探索微调或强化学习策略
潜在改进空间:
- 监督微调:使用标注的推理轨迹训练
- 强化学习:用检索质量作为奖励信号
- 元学习:快速适应新领域
相关工作:
- Search-o1和Search-r1采用强化学习,性能更优
- 但训练成本高,需要大量计算资源
5.3 与后续研究的关联
5.3.1 已有补充研究
1. INRAExplorer(2025年7月)
来源:Lelong et al., arXiv:2507.16507
改进点:
- 专注于特定领域(农业科学)
- 引入专业工具(如IdentifyExperts)
- 使用Neo4j图数据库和Qdrant向量库
- 采用开源模型deepseek-r1-0528
与GraphSearch的关系:
- 验证了智能体+KG范式在实际领域的有效性
- 展示了更丰富的工具集成
- 但未系统化地提出通用框架
2. Agentic RAG综述(2025年6月)
来源:Singh et al., arXiv:2506.10408
贡献:
- 将智能体RAG分为"预定义推理"和"智能体推理"两类
- GraphSearch属于预定义推理(固定模块管道)
- 讨论了路由型、循环型、树型等设计模式
对GraphSearch的定位:
- GraphSearch是循环型(loop-based)的代表
- 通过EV+QE模块实现有限迭代
- 相比完全自主的智能体,更可控和可解释
3. PIKE-RAG(2025)
来源:提到于多篇RAG综述
创新点:
- 知识感知的任务分解
- 确保子问题与知识库结构对齐
- 迭代构建推理链
与GraphSearch的异同:
- 相似:都进行查询分解和迭代检索
- 差异:PIKE-RAG未明确区分双通道检索
- GraphSearch更系统化,有完整的反思路由
5.3.2 未来研究方向
1. 多模态扩展
现状:GraphSearch仅处理文本
挑战:实际场景包含表格、图像、图表
方向:
- 扩展图知识库以表示多模态信息
- 设计多模态感知的检索策略
- 处理跨模态推理(如"图中趋势是否支持文本结论?")
2. 与推理模型的整合
背景:DeepSeek-R1、o1等推理模型兴起
问题:如何将长链推理与多跳检索结合?
探索方向:
- 让推理模型生成检索计划
- 用检索结果引导推理链分支
- 混合内部推理和外部检索
3. 强化学习优化
动机:当前依赖提示词,缺少端到端优化
方法:
- 定义奖励:最终答案准确率、检索效率
- 训练策略网络:学习何时分解、扩展、停止
- 借鉴Search-o1的成功经验
4. 低成本部署
需求:降低多轮LLM调用的成本
技术路线:
- 蒸馏:用大模型数据训练小模型
- 提前终止:在简单查询上减少轮次
- 混合策略:复杂查询用GraphSearch,简单查询用Naive RAG
5. 可解释性增强
问题:用户难以理解为什么得到这个答案
改进:
- 可视化推理图:展示子查询、中间答案、检索路径
- 置信度标注:为每个推理步骤提供可信度
- 反事实解释:说明缺少某证据会如何改变结论
六、实际落地与复现指南
6.1 工业应用挑战
6.1.1 延迟与成本平衡
挑战描述:
- GraphSearch需要6个模块的顺序执行
- 每个模块至少1次LLM调用,复杂查询可能需要3-5轮迭代
- 总延迟:单轮基线的5-10倍
- API成本:相应增加
适用场景评估:
| 场景类型 | 适用性 | 原因 |
|---|---|---|
| 实时聊天机器人 | 低 | 延迟要求<500ms,GraphSearch太慢 |
| 搜索引擎 | 低 | 高并发,成本不可接受 |
| 科研文献分析 | 高 | 质量>速度,用户可接受数秒延迟 |
| 法律案例研究 | 高 | 准确性至关重要,成本可分摊 |
| 医疗诊断辅助 | 中 | 需要平衡速度和质量 |
| 金融报告生成 | 高 | 离线处理,注重深度分析 |
优化策略:
- 混合部署模式:
def select_strategy(query):
complexity = estimate_complexity(query)
if complexity < THRESHOLD_SIMPLE:
return naive_rag(query)
else:
return graphsearch(query)
- 异步处理:
- 简单查询:同步返回
- 复杂查询:返回任务ID,后台处理
- 缓存机制:
- 缓存常见子查询的结果
- 复用相似查询的推理链
6.1.2 图知识库构建与维护
挑战1:初始构建成本大
解决方案:
- 增量构建:
- 先构建核心文档的图
- 逐步扩展到全量数据
- 批处理优化:
- 并行处理多个文档
- 使用GPU加速嵌入生成
- 质量优先采样:
- 识别高价值文档(如常被引用)
- 优先构建这些文档的图
挑战2:增量更新
GraphSearch本身不处理图构建,依赖底层GraphRAG:
- LightRAG:支持高效增量更新(Union操作)
- GraphRAG:需要重构社区,成本高
- 建议:选择支持增量更新的底层系统
挑战3:质量保证
常见问题:
- 实体歧义:同名不同实体(如"Jordan"可指国家或人名)
- 关系错误:LLM抽取错误的关系
- 覆盖度不足:关键实体缺失
质量评估指标:
def evaluate_graph_quality(graph):
metrics = {
'entity_coverage': len(extracted_entities) / len(gold_entities),
'relation_precision': correct_relations / total_relations,
'connectivity': average_path_length(graph),
'density': num_edges / (num_nodes * (num_nodes - 1))
}
return metrics
改进措施:
- 后处理规则:
- 实体链接:将提及链接到标准实体
- 关系验证:用知识库验证抽取的关系
- 人工审核:
- 对关键领域(如医疗、法律)进行人工检查
- 构建领域本体(Ontology)约束抽取
- 持续学习:
- 收集用户反馈
- 定期重训练抽取模型
6.1.3 领域适应性
挑战:GraphSearch在通用数据集上表现良好,但特定领域需要调整
领域差异示例:
| 领域 | 特点 | 适应需求 |
|---|---|---|
| 医学 | 大量专业术语,n元关系多 | 使用HyperGraphRAG,定制医学本体 |
| 法律 | 严格逻辑推理,引用链长 | 强化关系通道,扩展路径深度 |
| 金融 | 时序数据,数值计算 | 添加时间感知模块,工具调用(计算) |
| 客服 | 意图多样,对话式 | 简化管道,加入意图识别 |
适应策略:
- 提示词定制:
- 医学示例:“分解以下医学查询时,注意疾病-症状-治疗的层次关系…”
- 法律示例:“在法律推理中,明确区分事实陈述和法律解释…”
- 模块选择性使用:
- 简单领域:可省略EV+QE,减少成本
- 复杂领域:增加迭代轮次上限
- 领域知识注入:
- 使用领域特定的嵌入模型(如BioBERT for医学)
- 在图构建阶段注入领域本体
6.2 复现详细指南
6.2.1 环境搭建
硬件要求(基于论文实验):
- 最低配置:
- GPU:1× A100 40GB(或等效)
- CPU:16核
- 内存:64GB
- 存储:500GB SSD
- 推荐配置(用于大规模数据):
- GPU:4× A100 40GB
- CPU:32核
- 内存:256GB
- 存储:2TB NVMe SSD
软件依赖:
# 基础环境
Python >= 3.9
PyTorch >= 2.0
CUDA >= 11.8
# 核心库
pip install transformers>=4.35
pip install sentence-transformers
pip install openai # 如果使用API模型
pip install faiss-gpu # 向量检索
pip install networkx # 图操作
# GraphRAG系统
# 选择一个底层系统安装
pip install lightrag # LightRAG
# 或
git clone https://github.com/microsoft/graphrag
cd graphrag && pip install -e .
6.2.2 数据准备
步骤1:文档收集
# 示例:从目录加载文档
import os
from pathlib import Path
def load_documents(doc_dir):
documents = []
for file_path in Path(doc_dir).rglob('*.txt'):
with open(file_path, 'r', encoding='utf-8') as f:
documents.append({
'id': file_path.stem,
'text': f.read(),
'metadata': {'source': str(file_path)}
})
return documents
docs = load_documents('/path/to/your/documents')
步骤2:文档预处理
# 分块策略(参考论文:块大小由底层系统决定)
def chunk_documents(documents, chunk_size=1200, overlap=200):
chunks = []
for doc in documents:
text = doc['text']
for i in range(0, len(text), chunk_size - overlap):
chunk_text = text[i:i + chunk_size]
chunks.append({
'doc_id': doc['id'],
'chunk_id': f"{doc['id']}_{i}",
'text': chunk_text,
'metadata': doc['metadata']
})
return chunks
步骤3:构建图知识库
使用底层GraphRAG系统(以LightRAG为例):
from lightrag import LightRAG, QueryParam
# 初始化
rag = LightRAG(
working_dir="./rag_storage",
llm_model_name="qwen2.5-32b-instruct", # 图构建模型
embedding_model_name="jinaai/jina-embeddings-v3"
)
# 插入文档
for doc in documents:
rag.insert(doc['text'])
# 保存图
rag.save()
6.2.3 实现GraphSearch模块
模块1:查询分解(QD)
def query_decomposition(query, llm):
"""
将复杂查询分解为原子子查询
"""
prompt = f"""
给定一个复杂查询,将其分解为一系列原子子查询。每个子查询应该:
1. 专注于单个实体或关系
2. 能够独立检索
3. 逻辑上有序,后续查询可能依赖前序答案
使用占位符(如[ENTITY], [PERSON], [PLACE])表示未知信息。
复杂查询:{query}
请以JSON格式返回子查询列表:
{{"subqueries": ["q1", "q2", "q3"]}}
"""
response = llm.generate(prompt, temperature=0.0)
subqueries = parse_json(response)['subqueries']
return subqueries
# 示例
query = "在《维纳斯的崇拜》创作者去世的地方,瘟疫发生了多少次?"
subqueries = query_decomposition(query, llm)
# 输出:
# [
# "谁创作了《维纳斯的崇拜》?",
# "[PERSON]在哪里去世?",
# "在[PLACE],瘟疫发生了多少次?"
# ]
模块2:上下文精炼(CR)
def context_refinement(subquery, raw_context, llm):
"""
过滤冗余信息,提取关键证据
"""
prompt = f"""
给定一个子查询和检索到的原始上下文,提取最相关的信息。
删除冗余、无关的内容,保留关键实体、关系和支持性文本。
子查询:{subquery}
原始上下文:
{raw_context}
请返回精炼后的上下文(保持简洁,重点突出):
"""
refined = llm.generate(prompt, max_tokens=500)
return refined
# 示例
raw = """
提香·韦切利奥(约1488-1576)是意大利文艺复兴时期的画家...
他创作了许多著名作品,包括《维纳斯的崇拜》...
提香在威尼斯度过了大部分生涯...
他还创作了《圣母升天》等作品...
"""
refined = context_refinement("谁创作了《维纳斯的崇拜》?", raw, llm)
# 输出:"提香·韦切利奥创作了《维纳斯的崇拜》"
模块3:查询落地(QG)
def query_grounding(subquery, intermediate_answers, llm):
"""
用中间答案实例化子查询中的占位符
"""
# 识别占位符
placeholders = extract_placeholders(subquery) # ["[PERSON]"]
if not placeholders:
return subquery # 无占位符,直接返回
# 构建映射
prompt = f"""
给定一个包含占位符的子查询和之前的中间答案,用具体实体替换占位符。
子查询:{subquery}
中间答案:{intermediate_answers}
请返回实例化后的查询:
"""
grounded = llm.generate(prompt, temperature=0.0)
return grounded
# 示例
subquery = "[PERSON]在哪里去世?"
answers = {"q1": "提香·韦切利奥"}
grounded = query_grounding(subquery, answers, llm)
# 输出:"提香·韦切利奥在哪里去世?"
模块4-6:反思路由
def logic_drafting(subqueries, contexts, answers, llm):
"""
构建推理链草稿
"""
prompt = f"""
整合以下子查询、上下文和中间答案,构建连贯的推理链。
识别任何逻辑缺口或不一致之处。
子查询和答案:
{format_qa_pairs(subqueries, answers)}
上下文:
{format_contexts(contexts)}
请生成推理链草稿:
"""
draft = llm.generate(prompt)
return draft
def evidence_verification(draft, llm):
"""
验证证据充分性
"""
prompt = f"""
评估以下推理链是否有充分证据支持最终答案。
推理链:
{draft}
判断标准:
1. 是否有事实依据
2. 逻辑是否连贯
3. 是否有明显缺口
请回答"Yes"或"No",并说明理由:
"""
response = llm.generate(prompt)
decision = "Yes" if "yes" in response.lower() else "No"
return decision, response
def query_expansion(draft, llm):
"""
生成补充查询
"""
prompt = f"""
基于以下推理链,识别缺失的信息,生成补充子查询。
推理链:
{draft}
请列出需要补充的查询:
"""
response = llm.generate(prompt)
new_queries = parse_queries(response)
return new_queries
6.2.4 双通道检索实现
class DualChannelRetriever:
def __init__(self, text_retriever, graph_retriever):
self.text_retriever = text_retriever # 向量数据库
self.graph_retriever = graph_retriever # 图数据库
def retrieve_semantic(self, query, top_k=20):
"""
语义通道:检索文本块
"""
# 生成查询嵌入
query_emb = self.text_retriever.embed(query)
# 相似度检索
results = self.text_retriever.search(query_emb, k=top_k)
return [r['text'] for r in results]
def retrieve_relational(self, query, llm, max_hops=3):
"""
关系通道:检索图三元组
"""
# 提取查询中的实体
entities = extract_entities(query, llm)
# 图遍历
subgraph = []
for entity in entities:
# 多跳扩展
neighbors = self.graph_retriever.expand(
entity,
max_hops=max_hops
)
subgraph.extend(neighbors)
# 转换为文本
triples_text = format_triples(subgraph)
return triples_text
def retrieve_dual(self, query, llm, top_k=20):
"""
双通道检索
"""
semantic_ctx = self.retrieve_semantic(query, top_k)
relational_ctx = self.retrieve_relational(query, llm)
return {
'semantic': semantic_ctx,
'relational': relational_ctx
}
6.2.5 完整工作流
class GraphSearch:
def __init__(self, retriever, llm, max_iterations=5):
self.retriever = retriever
self.llm = llm
self.max_iterations = max_iterations
def search(self, query):
"""
GraphSearch主流程
"""
# 1. 查询分解
subqueries = query_decomposition(query, self.llm)
# 2. 迭代检索
intermediate_answers = {}
all_contexts = {}
for i, sq in enumerate(subqueries):
# 查询落地
grounded_sq = query_grounding(sq, intermediate_answers, self.llm)
# 双通道检索
contexts = self.retriever.retrieve_dual(grounded_sq, self.llm)
# 上下文精炼
refined_sem = context_refinement(grounded_sq, contexts['semantic'], self.llm)
refined_rel = context_refinement(grounded_sq, contexts['relational'], self.llm)
all_contexts[f"q{i}"] = {
'semantic': refined_sem,
'relational': refined_rel
}
# 生成中间答案
combined_ctx = refined_sem + "\n" + refined_rel
answer = self.llm.generate(
f"基于上下文回答:{grounded_sq}\n上下文:{combined_ctx}"
)
intermediate_answers[f"q{i}"] = answer
# 3. 反思路由
for iteration in range(self.max_iterations):
# 逻辑构建
draft = logic_drafting(subqueries, all_contexts, intermediate_answers, self.llm)
# 证据验证
decision, reason = evidence_verification(draft, self.llm)
if decision == "Yes":
break # 证据充分,结束
# 查询扩展
new_queries = query_expansion(draft, self.llm)
# 检索补充证据
for nq in new_queries:
contexts = self.retriever.retrieve_dual(nq, self.llm)
# 添加到证据池
all_contexts[f"expansion_{iteration}_{nq}"] = contexts
# 4. 最终答案生成
final_answer = self.llm.generate(
f"基于以下推理链和证据,回答原始问题。\n\n"
f"原始问题:{query}\n\n"
f"推理链:{draft}\n\n"
f"请给出最终答案:"
)
return {
'answer': final_answer,
'reasoning_chain': draft,
'subqueries': subqueries,
'intermediate_answers': intermediate_answers
}
# 使用示例
retriever = DualChannelRetriever(text_db, graph_db)
graphsearch = GraphSearch(retriever, llm)
result = graphsearch.search(
"在《维纳斯的崇拜》创作者去世的地方,瘟疫发生了多少次?"
)
print("答案:", result['answer'])
print("推理链:", result['reasoning_chain'])
6.2.6 评估脚本
import json
from tqdm import tqdm
def evaluate_graphsearch(test_data, graphsearch, metrics=['SubEM', 'A-Score', 'E-Score']):
"""
评估GraphSearch性能
"""
results = []
for item in tqdm(test_data):
query = item['question']
gold_answer = item['answer']
gold_evidence = item.get('evidence', [])
# 生成答案
pred = graphsearch.search(query)
pred_answer = pred['answer']
# 计算指标
scores = {}
if 'SubEM' in metrics:
scores['SubEM'] = substring_exact_match(pred_answer, gold_answer)
if 'A-Score' in metrics:
scores['A-Score'] = llm_judge_answer(
query, pred_answer, gold_answer, judge_llm
)
if 'E-Score' in metrics:
scores['E-Score'] = llm_judge_evidence(
query, pred['reasoning_chain'], gold_evidence, judge_llm
)
results.append({
'query': query,
'prediction': pred_answer,
'gold': gold_answer,
'scores': scores
})
# 聚合结果
avg_scores = {
metric: np.mean([r['scores'][metric] for r in results])
for metric in metrics
}
return results, avg_scores
# 加载测试集
with open('hotpotqa_test.json') as f:
test_data = json.load(f)
# 评估
results, avg_scores = evaluate_graphsearch(test_data[:100], graphsearch)
print("平均性能:", avg_scores)
# 输出:{'SubEM': 0.82, 'A-Score': 9.24, 'E-Score': 9.42}
6.3 模型选择指南
6.3.1 图构建模型
论文选择:Qwen2.5-32B-Instruct
选择依据:
- 需要强大的指令遵循能力
- 准确识别实体和关系
- 支持结构化输出(JSON)
替代方案:
| 模型 | 参数量 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|
| GPT-4 | 质量最高 | 成本极高,无本地部署 | 原型开发,小规模数据 | |
| Claude-3-Opus | 质量高,推理强 | 成本高,速率限制 | 高质量需求场景 | |
| Qwen2.5-32B | 32B | 平衡质量和成本 | 需要GPU资源 | 推荐:生产环境 |
| Llama-3-70B | 70B | 开源,质量好 | 资源需求大 | 有足够GPU资源时 |
| Mistral-8x7B | 8x7B | MoE架构,效率高 | 质量略低于单体大模型 | 成本敏感场景 |
| Qwen2.5-7B | 7B | 轻量级,可本地运行 | 质量下降 | 资源受限环境 |
实践建议:
- 初期:使用GPT-4快速验证
- 优化:切换到Qwen2.5-32B,在质量和成本间平衡
- 大规模:考虑自己微调Llama-3-8B
6.3.2 嵌入模型
论文选择:jinaai/jina-embeddings-v3
选择依据:
- 专为长文本检索设计
- 支持多任务(检索、分类、聚类)
- 多语言能力
替代方案:
| 模型 | 维度 | 优势 | 适用场景 |
|---|---|---|---|
| jina-embeddings-v3 | 768 | 长文本,多任务 | 推荐:通用场景 |
| text-embedding-3-large | 3072 | OpenAI,质量高 | 有API预算 |
| bge-large-en-v1.5 | 1024 | 开源SOTA | 英文为主 |
| e5-mistral-7b | 4096 | 基于Mistral,质量好 | 需要GPU推理 |
| gte-Qwen2-7B | 3584 | 中文友好 | 中文场景 |
领域特定嵌入:
- 医学:BioBERT, PubMedBERT
- 法律:Legal-BERT
- 科学:SciBERT
- 代码:CodeBERT
6.3.3 生成骨干模型
论文选择:Qwen2.5-32B-Instruct(主实验)/ Qwen2.5-7B-Instruct(小模型实验)
选择标准:
- 指令遵循:准确理解提示词
- 推理能力:处理多跳逻辑
- 输出质量:生成流畅、准确的答案
实践推荐:
- 高质量需求(科研、医疗、法律):
- 首选:GPT-4 或 Claude-3-Opus
- 开源替代:Qwen2.5-32B
- 平衡场景(企业知识库、客服):
- 首选:Qwen2.5-32B 或 Llama-3-70B
- 轻量替代:Qwen2.5-7B
- 成本敏感(初创公司、大规模部署):
- 首选:Qwen2.5-7B 或 Mistral-7B
- 极致优化:微调更小的模型
6.3.4 评估模型(LLM-as-Judge)
论文选择:Qwen-Plus(闭源强模型)
要求:
- 需要比生成模型更强的能力
- 理解评估维度(正确性、连贯性、全面性等)
- 一致性和公平性
选择指南:
| 评估模型 | 适用场景 |
|---|---|
| GPT-4 | 金标准,最高质量评估 |
| Claude-3-Opus | 与GPT-4相当,有时更严格 |
| Qwen-Plus | 中文友好,成本较低 |
| Llama-3-70B | 开源选项,需自行验证可靠性 |
注意事项:
- 评估模型应强于被评估模型
- 避免"自评"(用同一模型生成和评估)
- 定期用人工评估校准LLM评估
6.4 提示工程详解
6.4.1 查询分解提示词(QD)
论文提供的模板(根据Figure 9):
System: You are an expert at breaking down complex questions into simpler sub-questions.
User: Given a complex query, decompose it into a sequence of atomic sub-queries. Each sub-query should:
1. Focus on a single entity, relation, or contextual dependency
2. Be independently resolvable by a retrieval system
3. Follow a logical order where later queries may depend on earlier answers
Use placeholders (e.g., [ENTITY], [PERSON], [PLACE]) for unknown information that will be filled in by previous sub-queries.
Complex Query: {query}
Provide the sub-queries in JSON format:
{
"subqueries": [
"Sub-query 1",
"Sub-query 2",
"Sub-query 3"
]
}
关键设计元素:
- 明确角色定义:“You are an expert at…”
- 帮助模型进入正确的"心智模式"
- 明确的规则:三条清晰的分解原则
- 单一焦点、独立可解、逻辑有序
- 占位符机制:
- 允许后续查询依赖前序答案
- 这是查询落地(QG)的前提
- 格式约束:JSON输出
- 便于程序解析
- 减少解析错误
边界情况处理:
# 处理简单查询(无需分解)
if len(subqueries) == 1:
# 直接检索,跳过迭代
return simple_retrieval(query)
# 处理过度分解(>10个子查询)
if len(subqueries) > 10:
# 重新分解,要求更粗粒度
prompt += "\n注意:请限制在5-8个子查询内,避免过度分解。"
subqueries = query_decomposition(query, llm, prompt)
# 处理循环依赖
def detect_circular_dependency(subqueries):
# 检查是否有A依赖B,B依赖A的情况
graph = build_dependency_graph(subqueries)
if has_cycle(graph):
raise ValueError("检测到循环依赖,请重新分解")
6.4.2 上下文精炼提示词(CR)
模板:
System: You are an expert at extracting relevant information from retrieved contexts.
User: Given a sub-query and raw retrieved context, extract the most relevant information.
Focus on:
- Key entities and their properties
- Relevant relationships
- Supporting facts and evidence
Remove redundant, irrelevant, or tangential content.
Sub-query: {sub_query}
Raw Context:
{raw_context}
Provide a concise refined context (aim for 50-200 words):
设计要点:
- 提取导向:明确要提取什么(实体、关系、证据)
- 删除导向:明确要删除什么(冗余、无关)
- 长度约束:50-200词,避免过度压缩或保留过多
自适应策略:
def adaptive_context_refinement(subquery, raw_context, llm):
"""
根据上下文长度自适应调整
"""
if len(raw_context) < 500:
# 短上下文,轻度精炼
target_length = "100-150 words"
elif len(raw_context) < 2000:
# 中等长度,标准精炼
target_length = "50-100 words"
else:
# 长上下文,强力压缩
target_length = "30-50 words, focus on key facts only"
prompt = f"...aim for {target_length}..."
return llm.generate(prompt)
6.4.3 逻辑构建提示词(LD)
模板(根据Figure 10):
System: You are an expert at constructing coherent reasoning chains from pieces of evidence.
User: Given a sequence of sub-queries, their refined contexts, and intermediate answers, construct a logical reasoning chain that:
1. Connects the sub-queries and answers in a coherent narrative
2. Identifies any gaps or missing information
3. Highlights potential inconsistencies
Sub-queries and Answers:
{format_qa_pairs(subqueries, answers)}
Refined Contexts:
{format_contexts(contexts)}
Provide:
1. A step-by-step reasoning chain
2. Identified gaps (if any)
3. Consistency check result
Format:
## Reasoning Chain
[Step-by-step reasoning]
## Identified Gaps
[List of missing information, or "None"]
## Consistency Check
[Any contradictions or inconsistencies, or "All consistent"]
关键功能:
- 整合功能:将离散的QA整合为连贯叙事
- 缺口识别:主动发现缺失信息(为QE准备)
- 一致性检查:发现证据间的矛盾
6.4.4 证据验证提示词(EV)
模板:
System: You are a critical evaluator of reasoning chains and evidence quality.
User: Evaluate whether the following reasoning chain has sufficient and logically consistent evidence to support a final answer.
Reasoning Chain:
{draft}
Evaluation Criteria:
1. **Factual Grounding**: Is each claim supported by evidence?
2. **Logical Coherence**: Do the reasoning steps follow logically?
3. **Completeness**: Is there enough information to answer the original question?
4. **Consistency**: Are there any contradictions?
Provide your evaluation:
Decision: [Yes/No]
Reasoning: [Explain your decision, highlighting specific issues if "No"]
二元决策设计:
- “Yes”:证据充分,进入答案生成
- “No”:证据不足,触发查询扩展(QE)
防止误判:
def robust_evidence_verification(draft, llm, threshold=0.7):
"""
多次验证,取多数投票
"""
votes = []
for _ in range(3): # 3次独立验证
decision, reason = evidence_verification(draft, llm)
votes.append(decision)
# 多数投票
yes_count = votes.count("Yes")
if yes_count / len(votes) >= threshold:
return "Yes"
else:
return "No"
6.4.5 查询扩展提示词(QE)
模板:
System: You are an expert at identifying missing information and formulating targeted queries.
User: Based on the following reasoning chain draft, identify what information is missing and generate supplementary sub-queries to fill these gaps.
Reasoning Chain Draft:
{draft}
Identified Gaps:
{gaps}
For each gap, generate a specific, answerable sub-query. Focus on:
- Concrete facts or data
- Specific entities or relationships
- Verifiable information
Provide supplementary sub-queries in JSON format:
{
"supplementary_queries": [
"Specific query 1",
"Specific query 2"
]
}
设计原则:
- 针对性:每个扩展查询对应一个明确的缺口
- 可回答性:查询应能通过检索回答
- 避免泛化:如"告诉我更多关于X"→"X的Y属性是什么?"
6.4.6 领域定制示例
医学领域:
MEDICAL_QD_PROMPT = """
You are a medical information specialist. Decompose the medical query into atomic sub-queries, paying attention to:
- Disease-symptom-treatment hierarchies
- Contraindications and drug interactions
- Patient demographics (age, gender, comorbidities)
Medical Query: {query}
Sub-queries (JSON format):
"""
MEDICAL_CR_PROMPT = """
Extract medically relevant information, focusing on:
- Diagnostic criteria
- Evidence-based treatment options
- Clinical trial data or guidelines
- Risk factors and prevalence
Sub-query: {sub_query}
Raw Context: {raw_context}
Refined medical context:
法律领域:
LEGAL_LD_PROMPT = """
Construct a legal reasoning chain that:
1. Identifies relevant statutes, case law, and precedents
2. Applies legal principles to the facts
3. Considers alternative interpretations
4. Cites specific sources (case names, statute sections)
[Rest of prompt...]
七、总结与展望
7.1 核心贡献总结
GraphSearch论文在RAG领域做出了以下重要贡献:
- 范式创新:首次系统性地将智能体工作流深度整合到GraphRAG中,实现从单轮检索到多轮深度搜索的跨越
- 理论贡献:
- 提出双通道检索的模态-功能对齐原则
- 验证了查询落地(Query Grounding)机制的有效性
- 建立了迭代检索+反思路由的完整框架
- 工程贡献:
- 模块化设计使系统可组合、可扩展
- 即插即用能力降低了集成成本
- 开源实现促进了社区采用
- 实证贡献:
- 在6个基准上验证了一致性性能提升
- 消融实验清晰展示了每个模块的贡献
- 证明了小模型也能受益于深度搜索工作流
7.2 当前局限与改进空间
- 计算成本:多轮LLM调用带来的延迟和费用
- 改进方向:模型蒸馏、提前终止、并行化
- 提示词依赖:性能受提示词设计影响较大
- 改进方向:自动提示词优化(如DSPy)、少样本学习
- 错误传播:管道式设计中早期错误会累积
- 改进方向:引入反馈机制、多样性采样、置信度估计
- 图质量依赖:底层图知识库质量直接影响性能
- 改进方向:图质量评估、自动修正、人机协同
- 训练策略缺失:纯提示词方法未充分利用学习能力
- 改进方向:监督微调、强化学习、元学习
7.3 对从业者的建议
何时使用GraphSearch:
- ✅ 复杂多跳查询占主导
- ✅ 质量>速度(科研、医疗、法律)
- ✅ 有充足的计算资源
- ✅ 已构建或计划构建图知识库
何时不使用GraphSearch:
- ❌ 实时、高并发场景
- ❌ 简单查询为主
- ❌ 资源极度受限
- ❌ 无图知识库且不计划构建
实施路线图:
- 阶段1(1-2周):
- 选择底层GraphRAG系统(推荐LightRAG)
- 构建小规模图知识库
- 实现基础的QD+CR模块
- 阶段2(2-4周):
- 实现完整的6模块管道
- 在测试集上评估性能
- 针对领域定制提示词
- 阶段3(1-2个月):
- 优化性能(缓存、并行化)
- 扩展到生产规模数据
- 监控和持续改进
- 阶段4(持续):
- 收集用户反馈
- 迭代优化提示词和模块
- 探索强化学习等高级技术
参考文献
核心论文
- GraphSearch原文
Cehao Yang, Xiaojun Wu, Xueyuan Lin, et al. “GraphSearch: An Agentic Deep Searching Workflow for Graph Retrieval-Augmented Generation.” arXiv:2509.22009, 2025.
简介:本文研究的主要对象,提出模块化深度搜索和双通道检索策略。
https://arxiv.org/html/2509.22009 - GraphSearch代码仓库
DataArcTech/GraphSearch on GitHub
简介:论文官方开源实现,包含完整的6模块代码和提示词模板。
https://github.com/DataArcTech/GraphSearch
GraphRAG基础
- GraphRAG (Microsoft)
Darren Edge, et al. “From Local to Global: A Graph RAG Approach to Query-Focused Summarization.” arXiv:2404.16130, 2024.
简介:GraphRAG的奠基性工作,提出层次化社区摘要和全局检索策略。
https://arxiv.org/abs/2404.16130 - LightRAG
Zirui Guo, Lianghao Xia, et al. “LightRAG: Simple and Fast Retrieval-Augmented Generation.” arXiv:2410.05779, 2024.
简介:轻量级GraphRAG实现,采用图索引和双层检索,检索效率提升30%。
https://arxiv.org/abs/2410.05779 - PathRAG
Boyu Chen, Zirui Guo, et al. “PathRAG: Pruning Graph-based Retrieval Augmented Generation with Relational Paths.” arXiv:2502.14902, 2025.
简介:通过基于流的路径剪枝避免冗余信息,提升推理逻辑性。
https://arxiv.org/abs/2502.14902 - HippoRAG
Bernal Jimenez Gutierrez, et al. “HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models.” NeurIPS 2024.
简介:受海马体索引理论启发,使用个性化PageRank模拟人类记忆检索。
https://arxiv.org/abs/2405.14831 - HyperGraphRAG
Haoran Luo, et al. “HyperGraphRAG: Retrieval-Augmented Generation via Hypergraph-Structured Knowledge Representation.” arXiv:2503.21322, 2025.
简介:首个基于超图的RAG方法,表示n元关系,提升领域知识表达能力。
https://arxiv.org/abs/2503.21322
智能体RAG
- ReAct
Shunyu Yao, et al. “ReAct: Synergizing Reasoning and Acting in Language Models.” ICLR 2023.
简介:推理-行动协同框架,LLM智能体的基础范式。
https://arxiv.org/abs/2210.03629 - Self-RAG
Akari Asai, et al. “Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection.” ICLR 2024.
简介:引入自反思机制,迭代评估和精炼响应。
https://arxiv.org/abs/2310.11511 - Agentic RAG综述
Singh et al. “Reasoning RAG via System 1 or System 2: A Survey on Reasoning Agentic Retrieval-Augmented Generation.” arXiv:2506.10408, 2025.
简介:系统性综述智能体RAG,分为预定义推理和智能体推理两大类。
https://arxiv.org/abs/2506.10408 - INRAExplorer
Jean Lelong, et al. “Agentic RAG with Knowledge Graphs for Complex Multi-Hop Reasoning in Real-World Applications.” arXiv:2507.16507, 2025.
简介:面向农业科学领域的智能体RAG系统,验证了GraphSearch范式的实用性。
https://arxiv.org/abs/2507.16507
传统RAG
- RAG原论文
Patrick Lewis, et al. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” NeurIPS 2020.
简介:RAG范式的奠基性工作,提出检索-生成框架。
https://arxiv.org/abs/2005.11401 - Naive RAG实现指南
LangChain RAG Tutorial
简介:Naive RAG的工业界标准实现,基于向量数据库和嵌入模型。
https://python.langchain.com/docs/tutorials/rag/
评估与基准
- HotpotQA
Zhilin Yang, et al. “HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering.” EMNLP 2018.
简介:多跳QA基准,需要跨多个维基百科文章推理。
https://arxiv.org/abs/1809.09600 - MuSiQue
Harsh Trivedi, et al. “MuSiQue: Multihop Questions via Single-hop Question Composition.” TACL 2022.
简介:通过单跳问题组合形成多跳查询,测试复杂推理能力。
https://arxiv.org/abs/2108.00573 - LLM-as-a-Judge综述
Jiawei Gu, et al. “A Survey on LLM-as-a-Judge.” arXiv:2411.15594, 2024.
简介:系统性综述使用LLM进行自动评估的方法和最佳实践。
https://arxiv.org/abs/2411.15594
模型与工具
- Qwen2.5技术报告
Jinze Bai, et al. “Qwen Technical Report.” arXiv:2309.16609, 2023.
简介:Qwen系列模型的技术细节,包括训练数据、架构、性能评估。
https://arxiv.org/abs/2309.16609 - Jina Embeddings v3
Saba Sturua, et al. “jina-embeddings-v3: Multilingual Embeddings with Task LoRA.” arXiv:2409.10173, 2024.
简介:专为长文本检索设计的嵌入模型,支持多任务和多语言。
https://arxiv.org/abs/2409.10173
相关技术
- Query Decomposition
Hejing Cao, et al. “A Step Closer to Comprehensive Answers: Constrained Multi-Stage Question Decomposition with Large Language Models.” arXiv:2311.07491, 2023.
简介:查询分解的早期工作,提出约束性多阶段分解方法。
https://arxiv.org/abs/2311.07491 - Query Rewriting
Xinbei Ma, et al. “Query Rewriting in Retrieval-Augmented Large Language Models.” EMNLP 2023.
简介:查询改写技术,优化检索查询以提升相关性。
https://arxiv.org/abs/2305.14283 - GraphRAG产业实践
RAGFlow Blog: “The Rise and Evolution of RAG in 2024”
简介:2024年RAG技术发展综述,涵盖GraphRAG、LightRAG等工业应用。
https://ragflow.io/blog/the-rise-and-evolution-of-rag-in-2024-a-year-in-review - 多智能体RAG
Hugging Face: “Multi-Agentic RAG with Code Agents”
简介:使用小模型构建多智能体RAG系统的教程,展示了智能体范式的实用性。
https://huggingface.co/blog/multi-agentic-rag
补充阅读
- 知识图谱问答综述
Yunshi Lan, et al. “A Survey on Complex Knowledge Base Question Answering.” arXiv:2108.06688, 2021.
简介:知识图谱问答的系统性综述,为GraphRAG提供理论基础。
https://arxiv.org/abs/2108.06688 - 检索系统评估
Ellen M. Voorhees. “The TREC Question Answering Track.” Natural Language Engineering, 2001.
简介:经典的检索系统评估方法,为RAG评估提供参考。
https://dl.acm.org/doi/10.1017/S1351324901002789

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)