大模型介绍
大模型相关内容的介绍,让你不在困惑
前言
在我上大学后,AI的热度逐渐提高。开始我不屑一顾,但是后来跟一些比较厉害的人交流后,发现我真的落后很多。别人在聊什么RAG,LLM,我:"?"。
其实我也希望大家多去了解一些这些的新的东西,国外的大模型什么的该用用,花点钱什么关系的,以后都会赚回来的。
本篇文章对一些大模型常见的术语进行总结,看完至少能知道别人在聊的是个什么东西。
另外,本篇文章会一直进行补充,我学了什么,就会补充什么。
一.模型
模型可以理解成一个从数据中学习规律的程序。你给它出了海量例子,并告诉它该怎么做。它通过这些例子可以自己总结出一些规则,学会了完成某个特定的任务。
模型的三个特点:
| 特定任务,一个模型通常只擅长一件事 |
| 需要标注数据,训练模型需要大量的标准答案 |
| 参数较少 |
二.大语言模型
1.介绍
大语言模型,LLM(Large Language Model)是指基于大规模神经网络(参数规模通常达数十亿至万亿级别,例如GPT-3包含1750亿参数),通过自监督或半监督方式,对海量文本进行训练的语言模型。
下面对一些专业属于进行解释:
1)神经网络
神经网络就是模仿人脑的工作模式。
它由大量虚拟的“神经元”(也就是参数)和连接组成。每个神经元都像⼀个小处理单元,负责处理一点点信息。无数个神经元分成很多层,前一层的输出作为后一层的输入。
通过海量数据的训练,这个网络会自己调整每个“神经元”的重要性(即参数的值),最终形成一个非常复杂的“判断流水线”。比如,一个识别猫的神经网络,某些参数可能专门负责识别猫的眼睛,另⼀些参数专门负责识别猫的轮廓。
简单说:神经网络就是⼀个通过数据训练出来的、由大量参数组成的复杂决策系统。
2)自监督学习
自己训练自己,从数据本身找规律
3)半监督学习
师傅领进门,修行在个人。用少量带标签的数据引模型入门,掌握一些基本规律,然后再根据这些规律,从海量数据中训练自己
4)语言模型
预测下一个词,判断接下来会说什么
2.词元(Tokens)
词元是大语言模型 (LLM) 处理文本时的最小语义单位。用于将文本拆解为模型可理解的离散单元。
词元通过分词器将文本拆分而来,不同模型的分词规则不同,同一个词在不同模型中可能被拆分成不同词元。
模型的上下文窗口(如128K)实际是词元数量限制,API收费通常按词元数计费(词元=金钱),词元数越多,计算耗时和内存占用越高。
三.嵌入模型
1.介绍
大语言模型(LLM)是生成式模型。它理解输入并生成新的文本(回答问题、写文章)。它内部实际上也使用嵌入技术来理解输入,但最终目标是“创造”。
而嵌入模型(Embedding Model)是表示型模型。它的目标不是生成文本,而是为输入的文本创建一个最佳的、富含语义的数值表示(向量)。
由于计算机天生擅长处理数字,但不理解文字、图片的含义。嵌入(Embedding)的核心思想就是将人类世界的符号(如单词、句子、产品、图片)转换为计算机能够理解的数值形式(即向量,本质上是一个数字列表),并且要求这种转换能够保留原始符号的语义和关系,也就是度量语义。
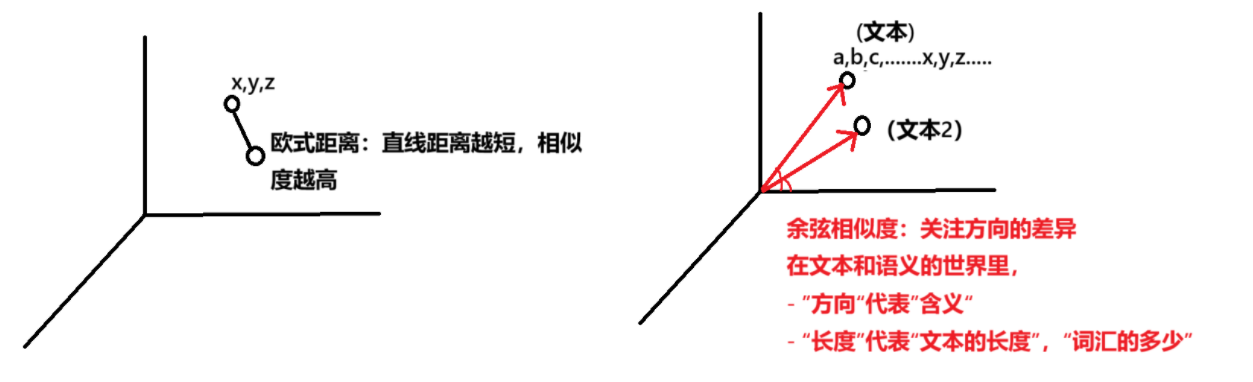
用数学度量语义主要有两种方式:欧式距离和余弦相似度
2.应用场景
从上面介绍可知,嵌入模型最根本的特点就是将文本(图片等等)转化为数值向量,并让这个向量包含其语义信息,根据这个特点,嵌入模型有下面的应用场景。
1)语义搜索(Semantic Search)
传统搜索:依赖关键词匹配(搜 “苹果” ,只能找到包含 “苹果” 这个词的文档)。
语义搜索:则能将查询和文档都转换为向量,通过计算向量间的相似度来找到相关内容,即使文档中没有查询的确切词汇也能被检索到。(搜“苹果”,能找到其他包含水果的文档)。
2)检索增强生成(Retrieval-Augmented Generation, RAG)
这是当前大语言模型应用的核心模式。当用户向 LLM 提问时,系统首先使用嵌入模型在知识库(如公司内部文档)中进行语义搜索,找到最相关的内容,然后将这些内容和问题一起交给 LLM 来生成答案。这极大地提高了答案的准确性和时效性。
嵌入模型主要负责“检索部分”,而将问题与答案整合是“增强(提示词)”部分,打包一起发给LLM最终生成结果的流程则是“生成”部分,整个流程被成为检索增强生成。
3)推荐系统(Recommendation Systems)
将用户(根据其历史行为、偏好)和物品(商品、电影、新闻)都转换为向量。喜欢相似物品的用户,其向量会接近;相似的物品,其向量也会接近。通过计算用户和物品向量的相似度,就可以进行精准推荐。
4)异常检测(Anomaly Detection)
正常数据的向量通常会聚集在一起。如果一个新数据的向量远离大多数向量的聚集区,它就可能是一个异常点(如垃圾邮件、欺诈交易)。
四.提示词编写
提示词的编写相当重要,对于同一个模型,写好提示词跟没写好差距很大。就算你使用了目前最先进的大模型,写的提示词依托,等于没用。
还有,我们现在使用的大模型多是国内的,比如说DeepSeek、豆包啥的,都是免费的。但是,当我们调用API的时候就要花钱,每个字都是钱,因此减少不必要的沟通,减少不必要的输出是至关重要的。
写提示词的宗旨是:将你的问题限定范围,让 AI 知道你要的答案具体要包含什么,提示词效果会大幅提升。
如果想要了解更多:提示工程指南 | Prompt Engineering Guide
1.提示词要素
高质量提示词的背后,是⼀套可拆解、可复用的结构化要素。经过多年实践与研究,业界总结出提示词是由一些要素组成的。提示词可以包含以下任意要素,也就是说,这些提示词要素并非必需项。
1)目标(Objective)--你要做什么?
这是提问词的灵魂,也就是你需要明确你希望AI做的具体事情。
2)背景(Context)--发生在什么场景下?
提供上下文,帮助 AI 理解任务背后的逻辑和前提,避免歧义,提升相关性。
3)受众(Audience)--给谁看/听/用?
不同的读者需要不同的表达方式。告诉 AI 内容的受众是谁,能显著优化语言风格和信息密度。
4)风格(Style)--用什么方式表达
定义内容的问题或写作类型,控制整体风格,比如:新闻体、故事化、学术风、口语化、诗歌风等。
5)语气(Tone)--带着什么情绪说话
语气决定情感色彩,影响读者感受。
| 语气类型 | 适用场景 |
| 正式严谨 | 商业报告、法律文书 |
| 轻松幽默 | 社交媒体、科普内容 |
| 激励鼓舞 | 演讲稿、团队动员 |
| 客观中立 | 新闻报道、数据分析 |
6)格式(Response Format) -- 输出长什么样?
以什么样的结构输出结果,便于后续使用或自动化处理,比如集成到工作流,网页,APP或者数据库中等。
常见的输出格式有:
| 用Markdown,表格,JSON的形式 |
| 字数限制(不超过300字) |
| 固定结构 (如"标题 + 引言 + 三个要点 + 结尾") |
7)约束条件(Constraints)-- 不能做什么?
除了"要什么",还要说明"不要什么",防止 AI 跑偏,比如不要出现政治敏感内容,不要超过500字,不要虚构数据等。
2.提示词技巧
1)CO-STAR 框架
在目标设定和问题解决的场景下,清晰性和结构性是至关重要的。
CO-STAR 并不是一个全新的概念集合,而是对已有提示词要素的一次逻辑重组与流程优化。它像一张"检查清单+导航图",引导我们一步步构建完整、清晰、可执行的指令,尤其适合复杂任务或团队标准化使用。如果说提示词要素是砖瓦,那么 CO-STAR 框架就是图纸。
CO-STAR 可以拆解为六个维度。
| 模块 | 说明 | 示例 |
| Context | 任务背景与上下文 | “你是电商客服,需解答用户关于iPhone 17的咨询,知识库包含最新价格和库存” |
| Objective | 核心目标 | “准确回答价格、发货时间,推荐适配配件” |
| Steps | 执行步骤 | “1. 识别用户问题类型;2. 检索知识库;3. 用亲切语气整理回复” |
| Tone | 语言风格 | “口语化,避免专业术语,使用‘亲~’‘呢’等语⽓词” |
| Audience | 目标用户 | “20-35岁年轻消费者,对价格敏感,关注性价比” |
| Response | 输出格式 | “价格:XXX元\n库存:XXX件\n推荐配件:XXX(链接)” |
上面的六个维度也不难理解,我们再写提示词的时候也比较容易去遵守。
2)少样本提示 / 多示例提示
这种方式通过给 AI 提供一两个 输入-输出 的例子,让它“照葫芦画瓢”。
核心思想:你不是在给它下指令,而是在“教”它你想要的格式、风格和逻辑。
适用场景:格式固定、风格独特、逻辑复杂的任务,如风格仿写、数据提取、复杂格式生成。
3)思维链提示
常用的思维链提示有两种:少样本思维链(Few-shot-CoT)和零样本思维链(Zero-shot-CoT)。
零样本思维链(Zero-shot-CoT)的核心思想是通过指令 “请⼀步步进行推理并得出结论” ,强制 AI 在给出答案前先进行内部推理。像我们国内的一些模型的深度思考能力其实就是基于思维链构建的一个系统级特性。
少样本思维链(Few-shot-CoT)的核心思想是要求 AI “展示其工作过程”,而不是直接给出最终答案。这模仿了人类解决问题时的思考方式。
4)自我批判与迭代
要求 AI 在生成答案后,从特定角度对自己的答案进行审查和优化。
核心思想:将“生成”和“评审”两个步骤分离,利用 AI 的批判性思维来提升内容质量。
适用场景:代码审查、文案优化、论证强化、安全检查。
在实际应用中,这些技巧常常是组合适用的。例如,我们可以:使用 CO-STAR 框架设定基本结构和角色。在框架的“Steps”或“Response”部分,融入思维链指令。对于格式复杂的输出,在最后附上少样本示例。最后,要求 AI 进行自我审查。
5)自我一致性
你有没有遇到过这种情况:同一个问题问两遍,AI 给出两个不同的答案?
尤其在处理数学题、逻辑判断或数据分析类任务时,大模型虽然强大,但有时会"灵光一闪",有时又"掉链子"。这种输出不稳定的现象,也是提示工程中需要攻克的挑战之一。
研究人员发现了一种简单却极其有效的增强方法,就是:自我一致性(Self-Consistency,SC)。
自我一致性 (Self-Consistency) 是一种基于 思维链 (Chain-of-Thought) 的改进型推理策略。它的核心思想是:
| 让 AI 对同一个问题生成多条不同的推理路径 |
| 然后从这些路径中找出出现频率最高或逻辑最连贯的答案 |
| 最终输出这个"共识性结论" |
给个例子:
请从不同角度独立思考以下问题三次,每次采用不同的表达方式或拆解顺序,展示完整推理过程。然后比较三个答案,选择最合理且一致的结果作为最终输出。
问题:
小明有 60 张游戏卡牌,他每天卖出 5 张。第 3 天结束后,他休息了 2 天没卖,之后继续每天卖 5 张。问他一共用了多少天才卖完?
要求:
1. 每次推理必须独立,不能复制前面的内容
2. 最终输出格式为:
→ 第⼀次推理:...
→ 第⼆次推理:...
→ 第三次推理:...
→ 综合判断与最终答案:...

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 36
36 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)