[智能体设计模式] 第14章:知识检索(RAG)
大型语言模型(LLM)擅长生成类人文本,但知识库局限于训练数据,无法访问实时信息、企业内部数据或专业化细节。知识检索(RAG,Retrieval Augmented Generation)通过集成外部、最新、特定场景的信息,解决了这一核心局限,让 LLM 的输出更准确、相关且有事实依据。对于智能体而言,RAG 是关键能力——它让智能体的行为和响应基于实时、可验证的数据,而非仅依赖静态训练内容。智能
大型语言模型(LLM)擅长生成类人文本,但知识库局限于训练数据,无法访问实时信息、企业内部数据或专业化细节。知识检索(RAG,Retrieval Augmented Generation)通过集成外部、最新、特定场景的信息,解决了这一核心局限,让 LLM 的输出更准确、相关且有事实依据。
对于智能体而言,RAG 是关键能力——它让智能体的行为和响应基于实时、可验证的数据,而非仅依赖静态训练内容。智能体可据此完成复杂任务,比如查阅最新公司政策、核查实时库存,从简单对话者升级为高效的数据驱动工具。
RAG 模式核心原理
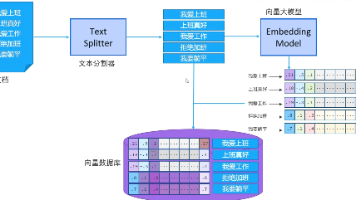
RAG 的核心是“检索增强生成”,让 LLM 在生成响应前先“查找”外部知识,而非仅依赖内部预训练数据,流程如下:
- 用户查询接收:用户提问不直接发送给 LLM。
- 语义检索:先在外部知识库(文档库、数据库、网页等)中进行语义检索,理解用户意图而非仅匹配关键词。
- 信息增强:提取最相关的信息片段(chunk),与原始查询结合,形成增强提示。
- 生成响应:增强提示送入 LLM,结合外部上下文生成流畅且有事实依据的回复。
核心概念
- 嵌入(Embeddings):文本的数值表示(向量),语义相近的文本在向量空间中距离更近,是语义检索的基础。
- 文档分块(Chunking):将大文档拆分为更小的片段,便于 LLM 处理和检索,需保留信息的上下文关联性。
- 语义相似度与距离:语义相似度关注文本核心含义,距离是其反向指标,用于筛选与查询最相关的文档。
- 向量数据库:专为存储和查询嵌入向量设计,支持高效语义检索,主流包括 Weaviate、Chroma DB、Milvus 等。
- 混合检索:结合关键词检索(如 BM25)的精确性和语义检索的灵活性,提升检索准确性。
RAG 的核心优势
- 突破训练数据限制,访问实时、最新信息。
- 降低 LLM“幻觉”风险,响应基于可验证数据。
- 支持企业内部文档、专业 Wiki 等私有知识的利用。
- 可提供信息来源引用,提升响应可信度。
RAG 的主要挑战
- 信息碎片化:答案所需信息可能分散在多个文档块,导致响应不完整。
- 检索质量依赖:分块策略、嵌入模型质量直接影响检索相关性,无关信息会引入噪声。
- 矛盾信息处理:多个文档可能存在冲突,需额外逻辑调和。
- 工程复杂度:需预处理知识库、维护向量数据库,动态内容需定期同步更新。
RAG 的进阶形态
1. GraphRAG(图谱增强 RAG)
GraphRAG 是高级形式,用知识图谱替代简单向量数据库,通过实体(节点)与关系(边)的显式关联检索信息。
核心优势:能整合分散在多个文档的关联信息,回答复杂逻辑问题(如“产品 A 的供应商与产品 B 的客户是否存在合作关系”)。
典型场景:复杂金融分析、企业事件关联、科学研究(如基因与疾病关系挖掘)。
局限:构建和维护高质量知识图谱的成本高、专业要求高,系统灵活性较低,延迟可能高于传统向量检索。
2. 智能体 RAG(Agent-RAG)
智能体 RAG 引入推理和决策层,让 RAG 从“被动数据管道”升级为“主动问题解决框架”,智能体主动参与知识精炼:
- 来源验证与筛选:识别文档时效性和权威性,优先采用最新、最权威的信息(如丢弃 2020 年过时政策,保留 2025 年官方文件)。
- 冲突调和:发现多文档信息矛盾时,选择最可靠来源(如优先采用最终财务报告而非初步方案)。
- 多步推理拆解:将复杂问题拆分为子查询,分别检索后综合答案(如对比自身与竞品的功能定价)。
- 知识空缺补全:检索内部知识库无果时,调用外部工具(如实时 Web 搜索)获取最新信息。
核心优势:大幅提升响应的准确性、深度和完整性,突破静态知识库限制。
局限:系统复杂性和工程成本显著增加,推理过程可能导致延迟上升,智能体本身可能引入推理失误。
典型应用场景
- 企业内部问答:基于 HR 政策、技术手册、产品规格等内部文档,开发员工咨询聊天机器人。
- 客户支持:通过产品手册、FAQ、工单记录,为客户提供精准一致的答复,减少人工介入。
- 个性化推荐:基于用户偏好语义检索相关内容(文章、产品),实现更精准的推荐。
- 新闻与时事摘要:集成实时新闻源,检索最新文章生成摘要,解决 LLM 无法获取实时信息的问题。
- 专业领域问答:在法律、医疗、金融等领域,结合专业文档(如法律条文、医疗指南)提供有依据的解答。
实战代码示例(LangChain)
以下基于 LangChain + LangGraph + Weaviate 实现完整 RAG 流程,包含文档加载、分块、嵌入、向量存储、检索增强生成全链路,注释详细可直接运行。
依赖安装
pip install langchain langchain-openai langchain-community langgraph weaviate-client python-dotenv requests
创建 .env 文件配置密钥:
OPENAI_API_KEY=你的 OpenAI API 密钥
核心代码
"""
LangChain 完整 RAG 实现示例
核心流程:文档加载 → 分块 → 嵌入 → 向量存储 → 语义检索 → 增强生成
技术栈:LangChain(核心框架)+ LangGraph(流程管理)+ Weaviate(向量数据库)+ OpenAI(LLM/嵌入)
"""
import os
import requests
from typing import List, Dict, Any
from dotenv import load_dotenv
from langchain_core.documents import Document
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Weaviate
from langchain.text_splitter import CharacterTextSplitter
from langchain.schema.runnable import RunnablePassthrough
from langgraph.graph import StateGraph, END
# --------------------------
# 1. 初始化环境与依赖组件
# --------------------------
# 加载环境变量
load_dotenv()
# 初始化 OpenAI LLM(用于生成最终响应)
llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
temperature=0 # 低温度保证响应的事实准确性,避免幻觉
)
# 初始化 OpenAI 嵌入模型(用于将文本转为向量)
embedding_model = OpenAIEmbeddings()
# 初始化 Weaviate 向量数据库(嵌入式模式,无需额外部署)
# 嵌入式模式适合测试,生产环境建议使用独立部署的 Weaviate 服务
weaviate_client = weaviate.Client(
embedded_options=weaviate.embedded.EmbeddedOptions()
)
# --------------------------
# 2. 知识库构建:加载 → 分块 → 嵌入 → 存储
# --------------------------
def build_knowledge_base(document_path: str) -> Weaviate:
"""
构建 RAG 知识库
参数:document_path - 本地文本文件路径(知识库源文件)
返回:初始化完成的 Weaviate 向量数据库(含嵌入后的文档块)
"""
# 2.1 加载文档(支持 txt 格式,其他格式可替换为对应 Loader,如 PyPDFLoader 处理 PDF)
print(f"正在加载文档:{document_path}")
loader = TextLoader(document_path, encoding="utf-8")
documents = loader.load()
print(f"文档加载完成,总长度:{len(documents[0].page_content)} 字符")
# 2.2 文档分块:将长文档拆分为小片段(平衡上下文完整性与检索效率)
text_splitter = CharacterTextSplitter(
chunk_size=500, # 每个块的最大字符数
chunk_overlap=50, # 块之间的重叠字符数(保留上下文关联)
separator="\n\n" # 按段落分割,避免拆分完整语义
)
chunks = text_splitter.split_documents(documents)
print(f"文档分块完成,共生成 {len(chunks)} 个文档块")
# 2.3 嵌入与存储:将文档块转为向量并存入 Weaviate
print("正在将文档块嵌入并存储到向量数据库...")
vectorstore = Weaviate.from_documents(
client=weaviate_client,
documents=chunks,
embedding=embedding_model,
by_text=False # 禁用 Weaviate 自带文本索引,仅使用自定义嵌入
)
print("知识库构建完成!")
return vectorstore
# --------------------------
# 3. 定义 RAG 流程状态(LangGraph 用于管理流程数据)
# --------------------------
class RAGGraphState(TypedDict):
"""
RAG 流程状态字典,存储流程中关键数据
- question:用户原始查询
- documents:检索到的相关文档块
- generation:LLM 生成的最终响应
"""
question: str
documents: List[Document]
generation: str
# --------------------------
# 4. 定义 RAG 核心节点(检索 + 生成)
# --------------------------
def retrieve_documents_node(state: RAGGraphState, vectorstore: Weaviate) -> RAGGraphState:
"""
检索节点:根据用户查询从向量数据库中获取相关文档块
参数:
state - 流程状态字典
vectorstore - 已构建的知识库
返回:更新后的状态字典(含检索到的文档块)
"""
question = state["question"]
print(f"\n正在检索相关文档:查询 = {question}")
# 从向量数据库中检索Top5最相关的文档块(similarity_top_k 可调整)
retriever = vectorstore.as_retriever(
search_kwargs={"k": 5} # k 表示返回的相关文档块数量
)
relevant_documents = retriever.invoke(question)
# 打印检索结果摘要
print(f"检索完成,找到 {len(relevant_documents)} 个相关文档块")
for i, doc in enumerate(relevant_documents):
print(f" 文档块 {i+1}:{doc.page_content[:50]}...")
# 更新状态:将检索到的文档块存入 state
return {
"question": question,
"documents": relevant_documents,
"generation": "" # 生成结果暂空
}
def generate_response_node(state: RAGGraphState) -> RAGGraphState:
"""
生成节点:结合用户查询和检索到的文档块,生成最终响应
参数:state - 流程状态字典(含查询和检索到的文档)
返回:更新后的状态字典(含最终生成的响应)
"""
question = state["question"]
documents = state["documents"]
print("\n正在生成最终响应...")
# 构建提示模板:明确要求 LLM 基于检索到的上下文回答,避免编造信息
prompt_template = """
你是一个问答助手,必须基于以下提供的检索上下文回答用户问题。
规则:
1. 仅使用上下文的信息,不要编造未提及的内容。
2. 如果上下文没有相关信息,直接说“抱歉,我没有找到相关答案。”
3. 回答简洁明了,最多用三句话,不要冗余。
用户问题:{question}
检索上下文:{context}
"""
prompt = ChatPromptTemplate.from_template(prompt_template)
# 格式化上下文:将多个文档块拼接为字符串
context_text = "\n\n".join([doc.page_content for doc in documents])
# 构建 RAG 链:提示模板 → LLM → 输出解析器
rag_chain = prompt | llm | StrOutputParser()
# 执行生成:传入查询和上下文
final_response = rag_chain.invoke({
"question": question,
"context": context_text
})
print(f"响应生成完成:{final_response}")
# 更新状态:将生成的响应存入 state
return {
"question": question,
"documents": documents,
"generation": final_response
}
# --------------------------
# 5. 构建 RAG 工作流(LangGraph 管理检索→生成的流程)
# --------------------------
def build_rag_workflow(vectorstore: Weaviate) -> StateGraph:
"""
构建 RAG 工作流
参数:vectorstore - 已构建的知识库
返回:编译后的 LangGraph 工作流
"""
# 初始化状态图
workflow = StateGraph(RAGGraphState)
# 添加节点:检索节点和生成节点
workflow.add_node("retrieve", lambda state: retrieve_documents_node(state, vectorstore))
workflow.add_node("generate", generate_response_node)
# 设置流程入口:从检索节点开始
workflow.set_entry_point("retrieve")
# 连接节点:检索完成后进入生成节点,生成完成后结束
workflow.add_edge("retrieve", "generate")
workflow.add_edge("generate", END)
# 编译工作流(生成可执行的应用)
return workflow.compile()
# --------------------------
# 6. 测试运行:完整 RAG 流程验证
# --------------------------
if __name__ == "__main__":
# 步骤 1:下载示例文档(美国总统国情咨文,作为知识库源文件)
doc_url = "https://github.com/langchain-ai/langchain/blob/master/docs/docs/how_to/state_of_the_union.txt"
doc_path = "state_of_the_union.txt"
if not os.path.exists(doc_path):
print(f"正在下载示例文档:{doc_url}")
response = requests.get(doc_url)
# 注意:实际下载需处理原始文本,此处简化为直接写入响应内容(实际使用时需提取纯文本)
with open(doc_path, "w", encoding="utf-8") as f:
f.write(response.text)
print("文档下载完成")
# 步骤 2:构建知识库
vectorstore = build_knowledge_base(doc_path)
# 步骤 3:构建 RAG 工作流
rag_app = build_rag_workflow(vectorstore)
# 步骤 4:测试查询 1
print("\n=== 测试查询 1 ===")
query1 = "What did the president say about Justice Breyer?"
inputs1 = {"question": query1}
# 运行工作流并输出结果
for step in rag_app.stream(inputs1):
if "generate" in step:
print(f"最终响应:{step['generate']['generation']}")
# 步骤 5:测试查询 2
print("\n=== 测试查询 2 ===")
query2 = "What did the president say about the economy?"
inputs2 = {"question": query2}
for step in rag_app.stream(inputs2):
if "generate" in step:
print(f"最终响应:{step['generate']['generation']}")
# 步骤 6:清理 Weaviate 嵌入式实例(避免占用资源)
weaviate_client.close()
代码核心说明
- 知识库构建:从网络下载示例文档,分块后转为嵌入向量,存入 Weaviate 向量数据库,支持后续语义检索。
- 流程管理:用 LangGraph 定义“检索→生成”的线性流程,节点职责清晰,可灵活扩展(如添加冲突检测、多轮检索节点)。
- 检索逻辑:基于用户查询的语义,从向量库中召回 Top5 相关文档块,确保上下文相关性。
- 生成约束:通过提示模板强制 LLM 仅基于检索到的上下文回答,减少幻觉,保证响应的事实依据。
要不要我帮你整理一份RAG 核心组件选型清单,涵盖向量数据库、嵌入模型、分块策略的主流选项和适用场景?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)