【大语言模型】最近流行LLM模型核心结构优化拆解
前言:市面上很多 LLM 博客聚焦 “大模型应用”“基础原理(如 Transformer 入门)”,而这篇文章专门拆解近期流行 “模型结构优化”(如 Norm 层位置、MoE 架构、激活函数选择),还有MoE 架构(Mixtral、GPT4 传闻)、LLaMA2 结构等—— 这些是工程落地、性能调优的关键,能解决 “为什么同样是 Transformer,不同模型速度 / 效果差很多” 的核心问题,对有一定基础的读者极具价值。
目录
近几年LLM模型结构演进全解析:从效率优化到架构创新
随着大模型在各领域的深度应用,架构设计的核心目标逐渐聚焦于“效果提升”与“成本可控”的平衡。本文将从注意力机制、Transformer块结构、归一化策略等七大核心维度,拆解近几年LLM的关键结构变化,帮你理清技术演进脉络。
一、注意力机制:从独立多头到共享优化
注意力机制是LLM捕捉语义关联的核心,其演进主线是在保证效果的前提下降低计算复杂度。
1. 传统BERT的Multi-Head Attention(MHA)
如果你对此没有基础或者想要详细了解,请先阅读链接: BERT的核心原理中的“BERT的self-attention自注意力机制和BERT的Multi-Head(多头机制)”部分。BERT作为曾经的主流,还是值得了解一下结构的。
作为Transformer的经典设计,MHA的核心是“多头独立计算”:
- 输入向量X经3个独立线性层,生成Q(查询)、K(键)、V(值)三个L×H维度矩阵(L为文本长度,H为隐藏层维度);
- 将Q、K、V按头数h切分,得到h组L×(H/h)的子矩阵(如BERT-base中H=768、h=8,单头维度为96);
- 每组子矩阵独立计算注意力分数(Q×K^T),生成h个L×L的注意力矩阵;
- 注意力矩阵与对应V子矩阵加权求和,最后将h组结果拼接,输出L×H的最终向量。
该设计的问题在于多头独立的Q、K、V矩阵导致计算量和内存占用随头数线性增长,训练效率较低。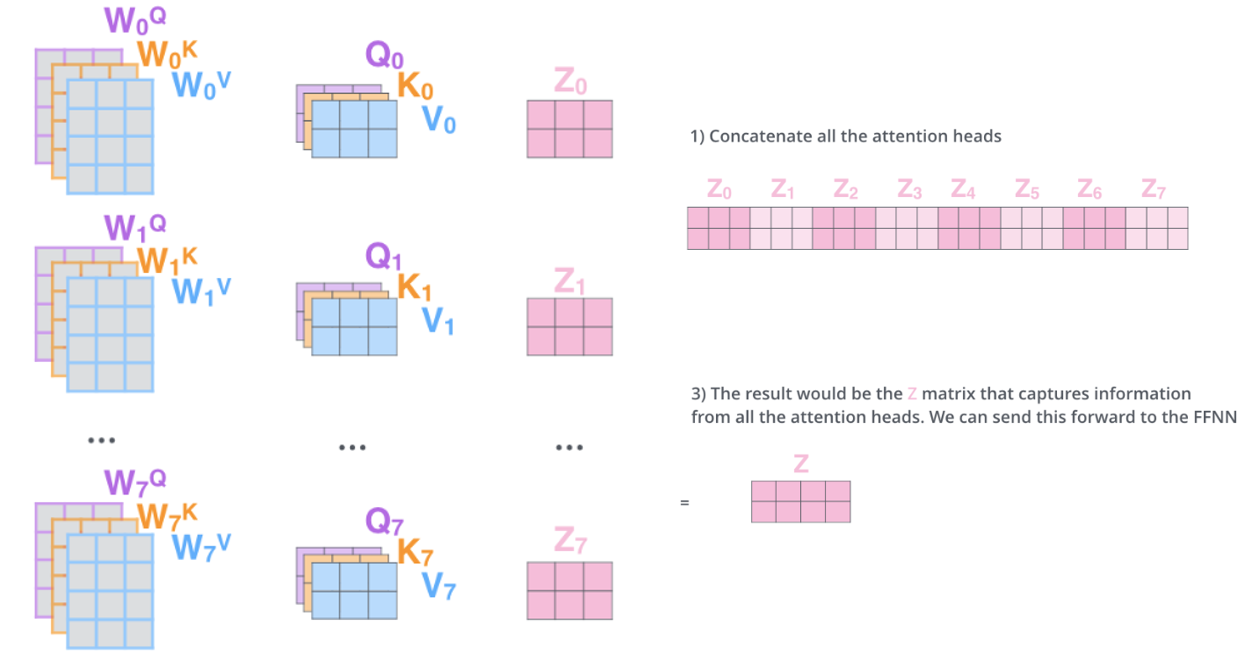
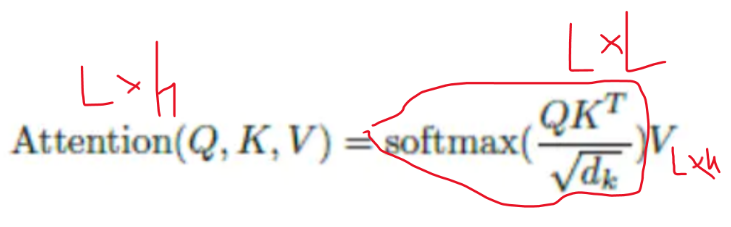
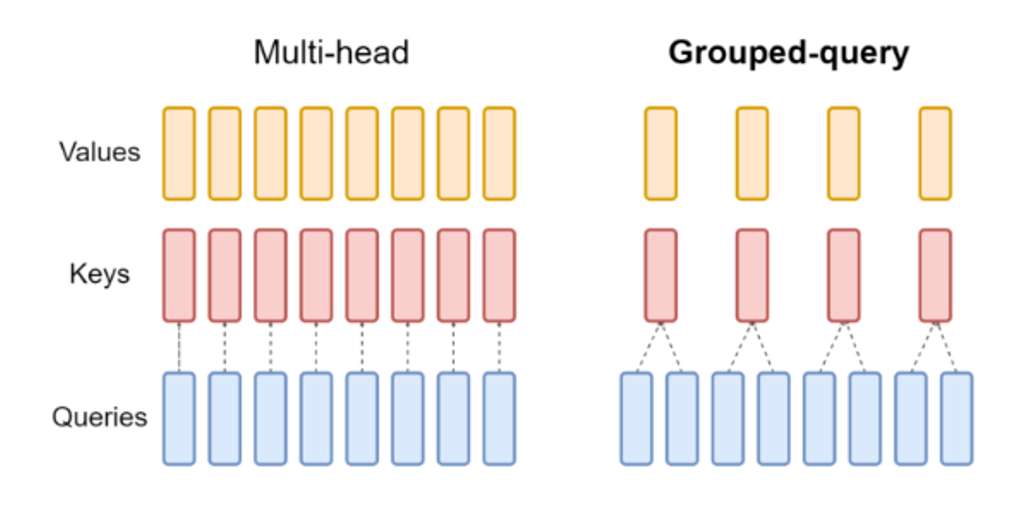
2. 分组查询注意力(Grouped-Query Attention,GQA)
针对MHA的效率问题,GQA采用“多Q共享K/V”的优化,看图片非常直观:
- 核心逻辑:将h个注意力头划分为g组,每组共享一套K和V矩阵,仅Q保持独立(如12个头分为6组,每组2个Q共享1套K/V);
- 维度调整:K/V的总维度从H降至H×(g/h),大幅减少矩阵运算量。
3. 多查询注意力(Multi-Query Attention,MQA)
更极端的共享方案:所有注意力头共享同一套K和V矩阵,仅Q保持多头独立。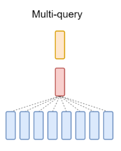
主流方案与效果
目前GQA是行业主流,被GPT-4、LLaMA 3等模型广泛采用。
- 效果平衡:GQA在计算量(较MHA降低30%-50%)和语义捕捉能力之间取得最优平衡,BBH、MMLU等 benchmarks 中效果仅略低于MHA,远优于MQA;
- 适用场景:完美适配长文本处理和大参数量模型训练,兼顾推理速度与效果稳定性。
二、Transformer块结构:从串行到并行的尝试
Transformer块的结构优化聚焦于调整注意力层与前馈网络(FFN)的连接方式,以提升训练效率。
1. 传统BERT的串行结构
如果你想要详细了解BERT全部结构,请先阅读链接: BERT的核心原理。
经典流程遵循“串行+残差+归一化”:
X → Self-Attention → 残差连接(X+Attention输出)→ 归一化 → X1 → FFN → 残差连接(X1+FFN输出)→ 归一化
该结构经过长期验证,效果稳定,但串行执行导致训练迭代速度受限。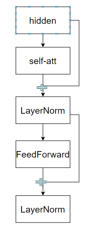
2. GPT-J的并行结构
核心创新是将Attention层与FFN层并行部署,而非串行执行:
- 输入X同时送入Attention层和FFN层,两路输出分别经过残差连接后再融合;
- 代表模型包括MOSS、PaLM等,其优势是减少层间依赖,理论上提升训练速度。
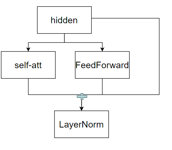
主流方案与效果
目前传统串行结构仍是主流,并行结构因存在语义融合不充分的问题,尚未广泛普及。
- 串行结构的优势在于注意力特征与前馈网络特征的“递进式强化”,深层模型中训练稳定性更优;
- 并行结构仅适用于特定场景(如短文本生成),未成为通用方案。
三、归一化层:位置与结构的双重优化
归一化层的核心作用是稳定模型训练时的梯度分布,演进围绕“位置调整”和“结构简化”展开。
1. 归一化层位置选择
(1)Post-LN(后归一化)
- 位置:归一化层位于残差连接之后(即Attention/FFN输出 → 归一化 → 残差连接);
- 缺点:深层模型中易出现训练不稳定问题(如梯度消失/爆炸),因为残差连接的“原始信息”经过归一化后被过度压制,导致深层特征传递失真。
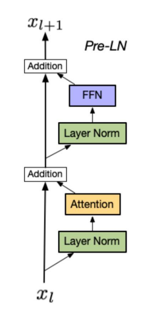
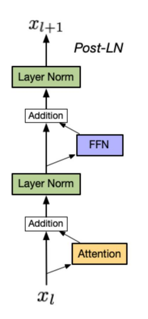 #### (2)Pre-LN(前归一化)
#### (2)Pre-LN(前归一化) - 位置:归一化层位于残差连接之前(即输入X → 归一化 → Attention/FFN → 残差连接);
- 优点:让“原始信息”更直接参与后续计算,缓解深层模型训练不稳定性,支持上百层模型的稳定训练;
- 缺点:相比Post-LN,语义表达能力略有下降(归一化提前导致特征多样性损失)。
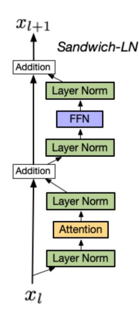
 #### (3)Sandwich-LN(三明治归一化)
#### (3)Sandwich-LN(三明治归一化) - 设计:在Pre-LN基础上额外插入一层归一化;
- 代表模型:CogView,用于避免值爆炸问题;
- 缺点:训练稳定性差,易导致训练崩溃,未成为主流。
2. 归一化层结构优化
(1)传统LayerNorm
- 作用:稳定每层输出分布,缓解梯度消失/爆炸问题;
- 不足:计算复杂度高,尤其在大参数量模型中耗时明显。
 #### (2)RMSNorm
#### (2)RMSNorm - 现状:现代大模型(如LLaMA、GPT-3、DeepSeek系列)的主流选择;
- 优势:简化计算(仅对元素平方后取均方根,再归一化),推理效率提升30%以上,同时保持训练稳定性;
- 代表模型:LLaMA 2、DeepSeek MLA等均采用RMSNorm。

主流方案与效果
目前Pre-LN+RMSNorm是绝对主流。
- 训练效率:支持100层以上模型稳定训练,如LLaMA 2的32层、DeepSeek的64层架构均可高效收敛;
- 推理速度:RMSNorm的轻量化计算让大模型推理延迟降低20%-40%,适配高并发场景。
四、激活函数:从ReLU到SiLU的迭代
激活函数的演进围绕“非线性表达能力”与“计算效率”的平衡展开。
1. 早期ReLU
- 公式:
f(x) = max(0, x); - 优势:计算极快,适配早期小模型;
- 缺点:存在“神经元死亡”问题(负数区域长期无梯度更新),语义表达能力不足。
2. BERT时期的GeLU
- 公式:
f(x) = 0.5x(1 + tanh(√(2/π)(x + 0.044715x³))); - 优势:非线性表达更细腻,大幅提升BERT的语义理解能力;
- 缺点:计算开销比ReLU高3-5倍,训练大模型时耗时明显。
3. 现代大模型的SiLU(Swish变体)
- 公式:
f(x) = x * sigmoid(x); - 优势:兼顾“非线性表达”与“计算效率”,在大模型中性能与GeLU相当,但计算速度提升20%以上;
- 代表模型:LLaMA 2、GPT-4、DeepSeek系列均采用SiLU。
主流方案与效果
SiLU是当前大模型的绝对主流**,几乎所有千亿级模型均采用该激活函数。
- 效果:在MMLU、HumanEval等任务中,SiLU的表现与GeLU持平甚至更优;
- 效率:推理时的计算耗时比GeLU降低20%,是大模型工业化部署的关键优化点。
五、LLaMA 2:工业化大模型的标杆架构
LLaMA 2是当前开源大模型的主流架构之一,其设计围绕“高效训练+高性能推理”展开。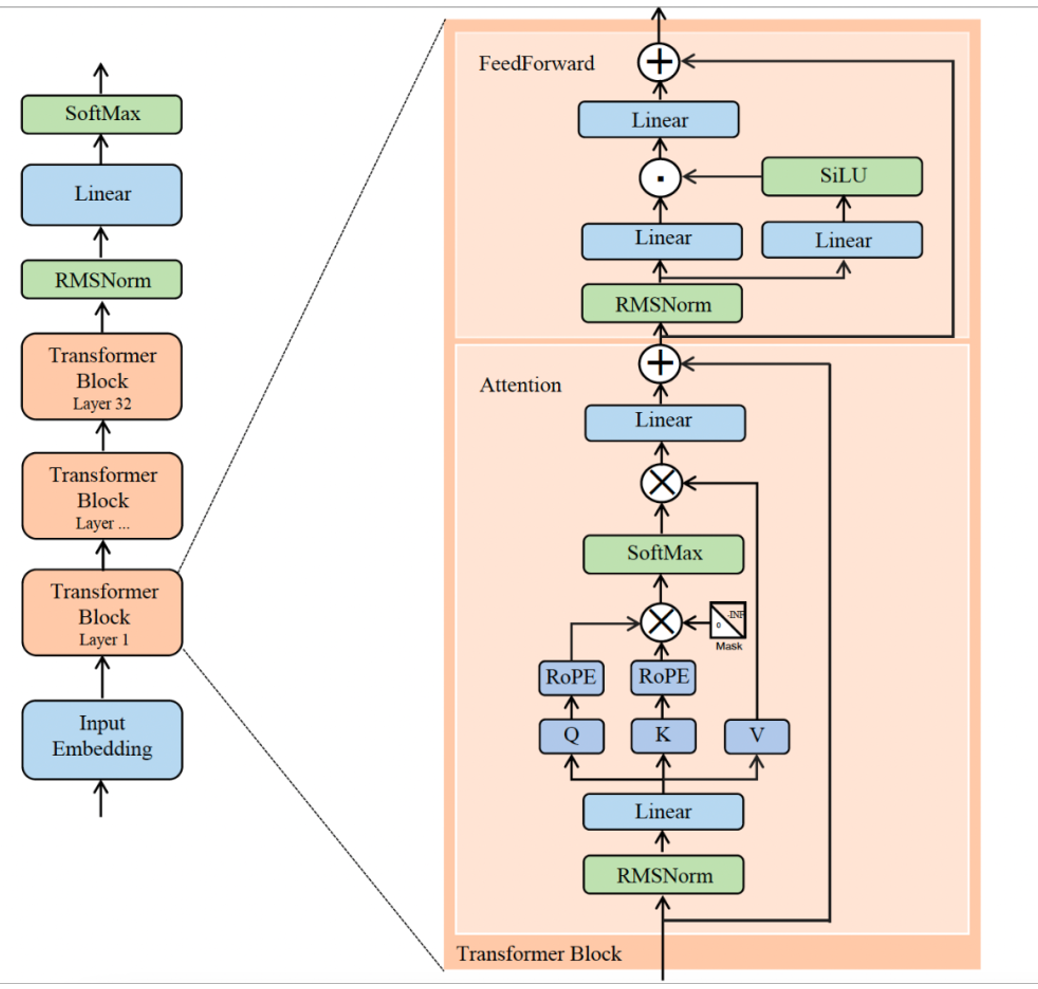
1. 整体流程
输入文本 → Embedding(词向量转换)→ 32层Transformer Block(逐层提取语义)→ RMSNorm(归一化)→ Linear(线性层)→ SoftMax(输出概率)→ 文本生成/理解。
2. Transformer Block细节
(1)Attention模块
- 流程:输入 → RMSNorm → Linear层生成Q、K、V → Q/K引入RoPE(旋转位置编码)→ 计算注意力分数 → 与V加权求和 → Linear层 → 残差连接;
- 核心优化:RoPE位置编码让模型精准感知长文本语序,适配复杂语义理解场景。
(2)FFN模块
- 流程:输入 → RMSNorm → 两路Linear层 → 一路经SiLU激活 → 两路结果融合 → Linear层 → 残差连接;
- 核心优化:SiLU激活+双Linear层设计,强化语义表达的同时控制计算量。
3. 架构优势
- 效率:RMSNorm+SiLU的组合让训练与推理效率提升30%以上;
- 能力:RoPE位置编码+32层堆叠,让LLaMA 2在长文本理解、数学推理等任务中表现突出;
- 稳定性:残差连接的全链路设计,避免深层模型的“信息丢失”,32层架构可稳定收敛。
六、MoE架构:混合专家模型的创新与优化
MoE(Mixture of Experts)的核心是让“不同专家模块”专精于不同任务,通过路由器选择适配专家,实现“效果提升+计算高效”的平衡。
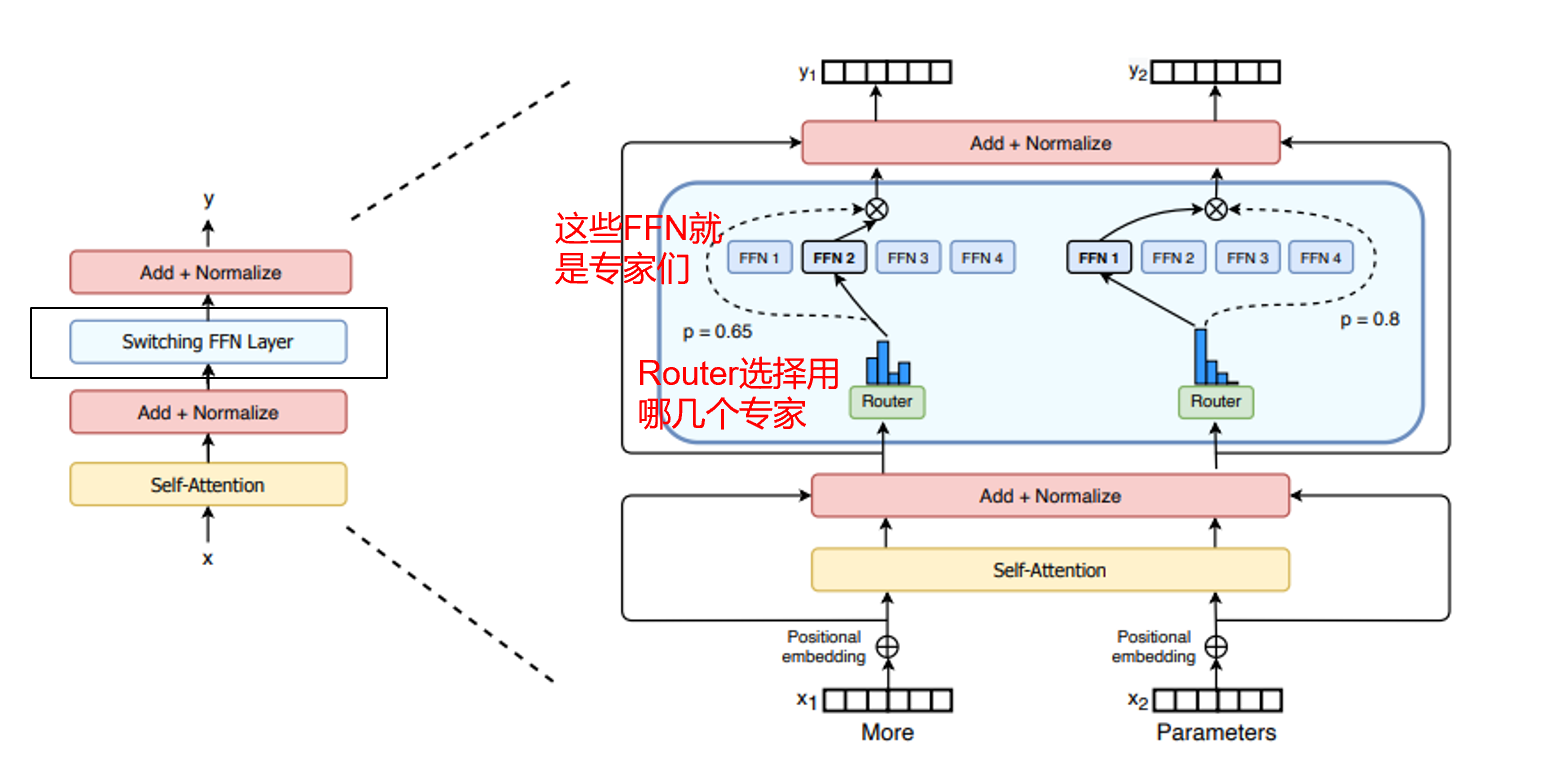
1. 经典MoE架构
- 设计:将FFN层替换为多个“专家子网络”,由路由器根据输入特征选择Top-K专家参与计算;
- 代表模型:Mixtral,网传GPT-4也采用类似设计;
- 缺点:路由器易导致“专家分布不均”(部分专家长期闲置)或“场景覆盖不足”(边缘语义无匹配专家),训练稳定性差。
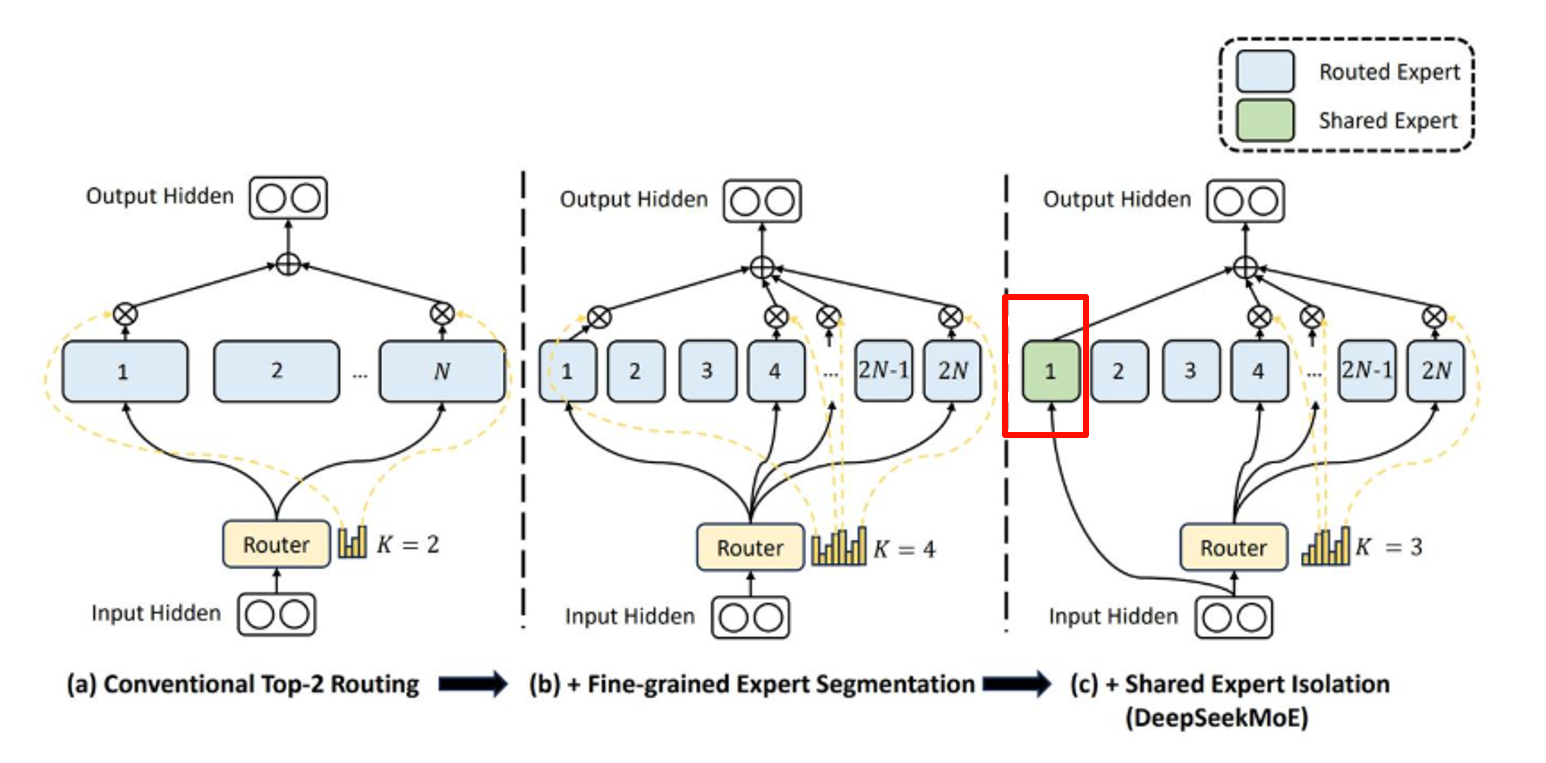
2. DeepSeek MoE:MoE的优化变体
- 创新:在专家集合中加入“共享专家”(强制参与所有计算),其余专家仍由路由器选择;
- 优势:共享专家处理“通用语义”或“边缘场景”,解决传统MoE的覆盖不足问题,同时保留“稀疏激活、成本可控”的优点;
- 代表模型:DeepSeek系列大模型,在代码生成、长文本理解等任务中表现优异。
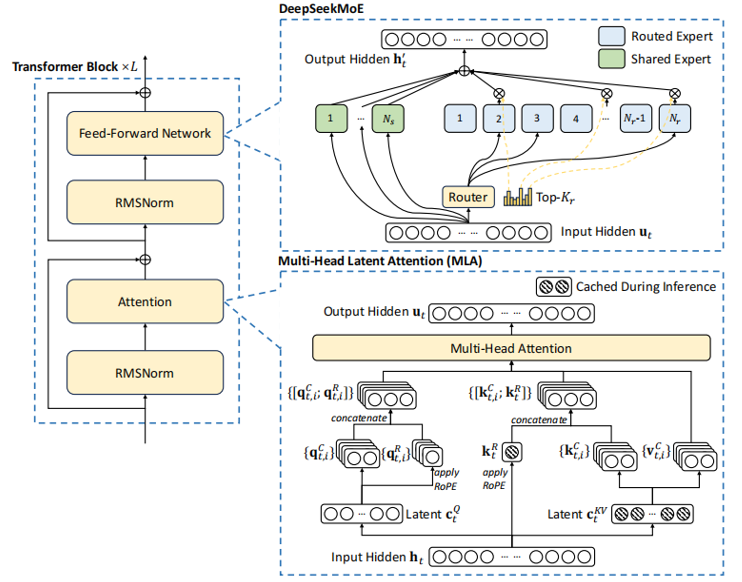
3. DeepSeek MLA(Multi-Head Latent Attention)
- Transformer Block ×L:由RMSNorm、Attention、FFN组成,多层堆叠提取深度特征;
- Multi-Head Latent Attention (MLA):通过“潜在特征(Latent c)+ RoPE”增强长序列建模能力,结合推理缓存提升效率;
- DeepSeek MoE:共享专家+路由专家的混合设计,实现“分领域专精”与“通用场景覆盖”的平衡。
七、总结:LLM架构演进的核心逻辑
近几年LLM结构的变化始终围绕“效率与效果的平衡”展开:
- 计算效率优化:通过GQA、RMSNorm、SiLU等技术,在保证效果的前提下降低训练与推理成本;
- 能力边界拓展:通过MoE、RoPE、MLA等创新,让大模型在长文本、多任务、复杂推理场景中表现更优;
- 工业化落地:所有优化最终指向“大模型能稳定训练、高效推理、适配产业需求”,这也是未来架构演进的核心方向。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)