OpenEMMA-----全新端到端自动驾驶大模型
OpenEMMA:开源的端到端自动驾驶大模型框架 摘要: 本文提出OpenEMMA,一个基于多模态大语言模型(MLLM)的开源端到端自动驾驶框架。该框架通过整合思维链推理过程,将驾驶任务转化为视觉问答问题,生成人类可理解的驾驶决策描述。系统采用两阶段方法:第一阶段进行意图推理和场景描述,第二阶段预测未来速度和曲率以生成轨迹。为解决MLLM在目标检测的局限性,OpenEMMA集成了优化版YOLO3D
0. 简介
自从多模态大型语言模型(MLLMs)出现以来,它们已经在广泛的现实世界应用中产生了重大影响,特别是在自动驾驶(AD)中。他们处理复杂视觉数据和推理复杂驾驶场景的能力为端到端广告系统的新范式铺平了道路。然而,为AD开发端到端模型的进展缓慢,因为现有的微调方法需要大量资源,包括广泛的计算能力、大规模数据集和大量资金。从推理计算的最新进展中得到启发,我们提出了OpenEMMA,一个基于MLLMs的开源端到端框架。通过整合思想链推理过程,OpenEMMA在利用多种多样的MLLMs时,与基线相比实现了显著的改进。此外,OpenEMMA在各种具有挑战性的驾驶场景中展示了有效性、可推广性和鲁棒性,为自动驾驶提供了一种更加高效和有效的方法。相关的代码已经在Github上开源了。
1. 主要贡献
为了解决像EMMA这样闭源模型的局限性,我们引入了OpenEMMA,这是一个开源的端到端自动驾驶框架,旨在使用公共工具和模型复制EMMA的核心功能。OpenEMMA旨在普及这些技术进步,提供一个更广泛的研究和开发平台。与EMMA类似[1],OpenEMMA处理前置摄像头图像和文本形式的历史自车状态作为输入。驾驶任务被框定为视觉问答(VQA)问题,并采用思维链推理的方法,引导模型生成关于关键物体、行为洞察和元驾驶决策的详细描述。这些决策由模型自身直接推导,为路径点生成提供了必要的背景。为了解决已知的多模态大语言模型(MLLM)在目标检测任务中的局限性,OpenEMMA集成了专门优化的YOLO的微调版本,以在自动驾驶场景中进行3D边界框预测,从而显著提高检测准确性。此外,通过利用MLLM的先验世界知识,OpenEMMA能够为场景理解等感知任务生成可解释的人类可读输出,从而提高透明性和可用性。完整的管道和支持的任务如图1所示。 我们将主要贡献总结如下:
- 我们引入了OpenEMMA,这是一个开源的端到端多模态模型,旨在利用现有的开源模块和预训练的多模态大语言模型(MLLM),在轨迹规划和感知方面复制EMMA的功能。
- 然后,我们在nuScenes数据集[21]的验证集上进行了广泛的实验,评估了OpenEMMA在端到端轨迹规划中的表现,展示了它的有效性和适应性。
- 最后,我们完整地发布了用于OpenEMMA的代码库、数据集和模型权重,供研究社区利用、完善和扩展该框架,推动自动驾驶技术的进一步进展。
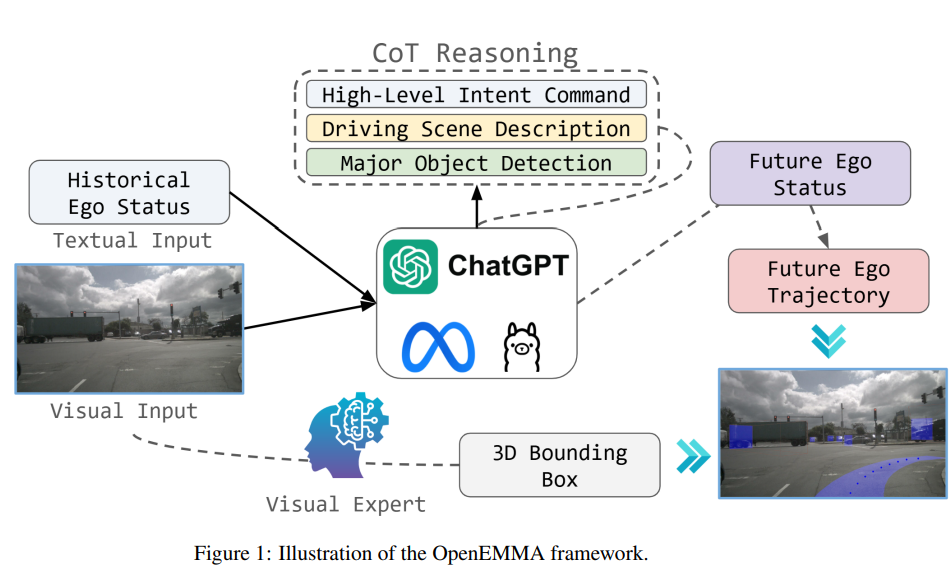
图1:OpenEMMA框架的示意图。
2 基于思维链的端到端规划方法论
我们开发了 OpenEMMA,这是一个计算高效的端到端自动驾驶系统,基于预训练的多模态大语言模型(MLLMs)L,如图1所示。该系统通过历史驾驶状态T和视觉驾驶场景I作为输入,预测未来轨迹P,并检测交通参与者。
利用预训练的多模态大语言模型的强大能力,我们将思维链推理过程整合到端到端轨迹规划过程中,采用类似于文献[1]中的基于指令的方法。由于多模态大语言模型是用人类可解释的知识进行训练的,我们引导这些模型生成同样易于人类理解的信息。因此,与以前直接在局部坐标中生成轨迹的方法不同[11, 3, 26],我们生成了两个中间表示:速度向量 S={st}S={st},表示车辆速度的大小,以及曲率向量 K={kt}K={kt},表示车辆的转弯速率。这些表示旨在反映人类驾驶的方式:速度表示油门应按下多少,而曲率则表示方向盘需转动多少。

2.1 阶段一:推理
最初,我们使用驾驶场景的前置摄像头图像和自我车辆过去5秒的历史数据(速度和曲率)作为输入,传递给预训练的多模态大语言模型(MLLMs)。随后,我们设计特定任务的提示,以引导MLLMs生成对当前自我驾驶场景的全面推理,涵盖以下几个方面: • 意图指令:清晰地表达自我车辆在当前场景下的预期动作,例如它将继续沿车道行驶以左转、右转或直行。此外,还需指明车辆是否应保持当前速度、减速或加速。
• 场景描述:根据交通信号灯、其他车辆或行人的动态以及车道标记,对驾驶场景进行简明描述。
• 主要对象:识别自我驾驶者应关注的道路使用者,并指定他们在驾驶场景图像中的位置。对于每个道路使用者,提供其当前行为的简要描述,并解释其存在对自我车辆决策过程的重要性。
2.2 阶段二:预测
通过结合链式思维推理过程和历史自我状态,MLLMs被提示生成未来T秒内的速度 S={st}t=0TS={st}t=0T 和曲率 C={ct}t=0TC={ct}t=0T(共2T个轨迹点)。这些预测随后被整合以计算最终轨迹 T={xt,yt}t=0TT={xt,yt}t=0T。
3. 通过视觉专家增强的目标检测
自动驾驶(AD)中的一项关键任务是为道路上的物体检测三维边界框。我们观察到,现成的预训练多模态大语言模型(MLLMs)在空间推理方面存在局限性,难以提供高质量的检测。为了解决这一挑战,并在不对MLLM进行额外微调的情况下实现高检测精度,我们将一个外部的视觉专用模型集成到OpenEMMA中,有效地解决了检测任务。
我们提出的OpenEMMA专注于使用前置摄像头进行目标检测,并处理来自单帧的数据,而不是连续帧的序列。这使得该任务处于基于单目摄像头的三维目标检测的范围内。该领域的研究通常分为两类:深度辅助方法[27–29]和仅图像方法[30–33]。深度辅助方法预测深度信息以辅助检测,而仅图像方法则完全依赖RGB数据进行直接预测。在这些方法中,我们选择了YOLO3D[30],因为它结合了可靠的准确性、高质量的开源实现和轻量级架构,能够实现高效的微调和实际集成。
YOLO3D是一种两阶段的三维目标检测方法,它强制执行二维-三维边界框一致性约束。具体而言,它假设每个三维边界框都紧密包围其对应的二维边界框。该方法首先预测二维边界框,然后估计每个检测到的物体的三维尺寸和局部方向。三维边界框的七个参数——中心位置 tx,ty,tztx,ty,tz,尺寸 dx,dy,dzdx,dy,dz,以及偏航角 θθ——是基于二维边界框和三维估计共同计算得出的。

图2:YOLO 3D检测结果。类别与颜色的对应关系为:汽车为灰色,行人为蓝色,交通锥为橙色,卡车和拖车为棕色。蓝色阴影的表面表示物体的朝向。

(a) OpenEMMA在右转场景下的预测示意图。
(b) OpenEMMA在遇到左转车辆时的预测示意图。
(c) OpenEMMA在低光照夜间条件下的预测示意图。
图 3:基于GPT-4o的OpenEMMA预测可视化。
点击链接OpenEMMA-----全新端到端自动驾驶大模型阅读原文

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)