利用强化学习 Q-learning 玩 Atari 黑白棋游戏
本文实现了一个基于PyTorch的强化学习黑白棋游戏系统,主要包含以下改进: 框架迁移:将原TensorFlow实现重构为PyTorch版本,使用3层CNN+2层FC的网络结构处理8x8棋盘状态,输出64个位置的Q值。 环境适配: 自定义ReversiEnv环境类实现核心游戏逻辑 包含合法动作检测、棋子翻转、胜负判断等功能 无需Gym环境注册,直接实例化使用 智能体功能: 支持随机策略和Q学习策略
强化学习玩黑白棋游戏pytorch版
黑白棋游戏规则
Atari 游戏中的黑白棋,也叫反棋、奥赛罗棋,其规则如下:
-
游戏准备:
-
游戏人数:2 人。
-
棋盘与棋子:棋盘为 8×8 的方格布局,共 64 格。棋子共 64 个,呈圆饼形,每颗由黑白两色组成,一面白,一面黑,两个玩家各下一面棋子。开局时,在棋盘正中有摆好的四枚棋子,黑白各 2 枚,交叉放置。
-
-
落子规则:
-
先后顺序:由执黑棋的一方先落子,双方交替下子,棋子落在方格内。
-
合法落子:一步合法的棋步包括在一个空格新落下一个棋子,并且翻转对手一个或多个棋子。把自己颜色的棋子放在棋盘的空格上,当自己放下的棋子在横、竖、斜八个方向内有一个自己的棋子,则被夹在中间的对方棋子全部翻转成为自己的棋子。夹住的位置上必须全部是对手的棋子,不能有空格,并且只有在可以翻转棋子的地方才可以下子。
-
特殊情况:如果一方没有合法棋步,即不管下到哪里都不能至少翻转对手的一个棋子,那这一轮只能弃权,由对手继续落子,直到有合法棋步可下。
-
-
游戏结束条件:
-
双方都无子可下,游戏结束。
-
一方的子被翻完,游戏结束。
-
棋格被全部下满,游戏结束。
-
有玩家提出认输(游戏开局后一分钟才能认输),游戏结束。
-
-
胜负判断:游戏结束后,按棋盘上谁的棋子多来判断胜负,棋子多的一方获胜。若棋数一样,则为和局。
用pytorch重构tensorflow
1.把文件全部喂给AI
2.提示词:
文件如下
chap14_reinforcement_learning/
├── README.md
├── 期末作业说明.pdf
├── _init_.py
├── RL_QG_agent.py
├── reversi_main.py
└── reversi/
├── _init_.py
└── reversi.py
按README.md和期末作业说明.pdf的要求,并且不使用tensorflow,不使用Gym黑白棋环境注册,改使用pytorch、新python解释器、新版本库(要互相适配),老版本的有点问题,帮我分别修改代码,然后要用anaconda创建一个sy7新环境、要安装的库的步骤最终完整代码
修改后的完整代码文件(共 5 个)
1. 主程序:reversi_main.py(无需修改接口,仅适配环境)
import numpy as np
from reversi.reversi import ReversiEnv
def random_agent(env, observation):
"""随机智能体:选择合法的随机动作"""
valid_actions = []
for action in range(env.action_space.n - 1): # 排除放弃动作
if env.valid_place(observation, action, env.current_player):
valid_actions.append(action)
if valid_actions:
return np.random.choice(valid_actions)
else:
return env.action_space.n - 1 # 没有合法动作,选择放弃
if __name__ == "__main__":
# 创建环境
env = ReversiEnv()
# 重置环境
observation = env.reset()
print("未找到预训练模型,使用随机初始化模型")
env.render()
done = False
step = 0
while not done:
step += 1
print(f"\n===== 第 {step} 步 =====")
# 获取当前玩家的动作
action = random_agent(env, observation)
# 执行动作
observation, reward, done, info = env.step(action)
# 渲染棋盘
env.render()
# 打印调试信息
action_pos = env._action_to_pos(action)
if action_pos:
print(f"执行动作:({action_pos[0] + 1}, {action_pos[1] + 1})")
else:
print("执行动作:放弃")
print(f"奖励:{reward} | 游戏结束:{done}")
# 关闭环境
env.close()2. 智能体核心:RL_QG_agent.py(PyTorch 实现,替换 TensorFlow)
import torch
import torch.nn as nn
import torch.optim as optim
import os
import numpy as np
class RL_QG_agent:
def __init__(self):
# 模型保存路径(自动创建文件夹)
self.model_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), "Reversi")
os.makedirs(self.model_dir, exist_ok=True)
# 初始化模型和优化器
self.device = torch.device("cpu") # 统一CPU版本
self.model = self.init_model()
self.optimizer = optim.Adam(self.model.parameters(), lr=1e-4)
self.loss_fn = nn.MSELoss()
def init_model(self):
"""定义Q梯度网络(适配8x8棋盘输入)"""
class QNetwork(nn.Module):
def __init__(self):
super(QNetwork, self).__init__()
# 输入:3x8x8(黑棋、白棋、空位)
self.conv_layers = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU()
)
# 全连接层:输出64个位置的Q值(8x8棋盘)
self.fc_layers = nn.Sequential(
nn.Flatten(),
nn.Linear(128 * 8 * 8, 512),
nn.ReLU(),
nn.Linear(512, 64) # 64个落子位置(0-63)
)
def forward(self, x):
x = self.conv_layers(x)
q_values = self.fc_layers(x)
return q_values
return QNetwork().to(self.device)
def place(self, state, enables):
"""测试时决策:选择合法动作中Q值最大的位置"""
# 预处理输入:转为Tensor(3x8x8 → [1,3,8,8])
state_tensor = torch.tensor(state, dtype=torch.float32).unsqueeze(0).to(self.device)
# 预测所有位置的Q值
with torch.no_grad():
q_values = self.model(state_tensor)
# 只保留合法动作的Q值,选择最大的
legal_q = [q_values[0, a].item() if a in enables else -float('inf') for a in range(64)]
best_action = np.argmax(legal_q)
return best_action
def save_model(self):
"""保存模型参数"""
torch.save({
'model_state_dict': self.model.state_dict(),
'optimizer_state_dict': self.optimizer.state_dict()
}, os.path.join(self.model_dir, 'parameter.pth'))
print("模型已保存到", self.model_dir)
def load_model(self):
"""加载模型参数(无模型时自动初始化)"""
model_path = os.path.join(self.model_dir, 'parameter.pth')
if os.path.exists(model_path):
checkpoint = torch.load(model_path, map_location=self.device)
self.model.load_state_dict(checkpoint['model_state_dict'])
self.optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
print("模型加载成功")
else:
print("未找到预训练模型,使用随机初始化模型")
# 可选:添加训练相关函数(示例)
def train_step(self, state, action, reward, next_state, done):
"""单步训练:Q梯度更新"""
self.model.train()
# 预处理数据
state = torch.tensor(state, dtype=torch.float32).unsqueeze(0).to(self.device)
next_state = torch.tensor(next_state, dtype=torch.float32).unsqueeze(0).to(self.device)
action = torch.tensor([action], dtype=torch.long).to(self.device)
reward = torch.tensor([reward], dtype=torch.float32).to(self.device)
done = torch.tensor([done], dtype=torch.float32).to(self.device)
# 计算当前Q值
current_q = self.model(state).gather(1, action.unsqueeze(1))
# 计算目标Q值(Bellman方程)
with torch.no_grad():
next_q = self.model(next_state).max(1)[0]
target_q = reward + (1 - done) * 0.99 * next_q # 折扣因子0.99
# 反向传播更新
loss = self.loss_fn(current_q, target_q.unsqueeze(1))
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return loss.item()3. 根目录:init.py(空文件,保持目录结构)
# 空文件,保持目录结构,仅用于标识Python包4. 环境文件夹:reversi/init.py(简化导入)
from .reversi import ReversiEnv # 直接导出ReversiEnv类,无需Gym注册
__all__ = ['ReversiEnv'] # 便于外部导入5. 环境核心:reversi/reversi.py
import numpy as np
import gym
from gym import spaces
class ReversiEnv(gym.Env):
metadata = {'render.modes': ['human']}
def __init__(self):
super(ReversiEnv, self).__init__()
# 棋盘大小
self.BOARD_SIZE = 8
# 颜色定义
self.BLACK = 0
self.WHITE = 1
self.EMPTY = 2
# 动作空间:64个位置 + 放弃动作(65个动作)
self.action_space = spaces.Discrete(self.BOARD_SIZE * self.BOARD_SIZE + 1)
# 观测空间:2个8x8的矩阵(分别表示黑白棋子)
self.observation_space = spaces.Box(
low=0, high=1,
shape=(2, self.BOARD_SIZE, self.BOARD_SIZE),
dtype=np.float32
)
# 初始化棋盘
self.reset()
def reset(self):
"""重置棋盘到初始状态"""
self.state = np.full((2, self.BOARD_SIZE, self.BOARD_SIZE), 0, dtype=np.float32)
# 初始位置:中心四个格子
mid = self.BOARD_SIZE // 2
self.state[self.BLACK, mid-1, mid-1] = 1 # 黑棋 (3,3) 对应索引 (2,2)
self.state[self.WHITE, mid-1, mid] = 1 # 白棋 (3,4) 对应索引 (2,3)
self.state[self.WHITE, mid, mid-1] = 1 # 白棋 (4,3) 对应索引 (3,2)
self.state[self.BLACK, mid, mid] = 1 # 黑棋 (4,4) 对应索引 (3,3)
self.current_player = self.BLACK # 黑棋先行
self.done = False
self.info = {}
return self._get_observation()
def _get_observation(self):
"""返回当前观测(2x8x8矩阵)"""
return self.state.copy()
def _action_to_pos(self, action):
"""将动作(0-64)转换为棋盘位置(x,y),64表示放弃"""
if action == self.BOARD_SIZE * self.BOARD_SIZE:
return None # 放弃动作
x = action // self.BOARD_SIZE
y = action % self.BOARD_SIZE
# 检查坐标是否在合法范围内(0-7)
if x < 0 or x >= self.BOARD_SIZE or y < 0 or y >= self.BOARD_SIZE:
return None
return (x, y)
def valid_place(self, board, action, player):
"""检查动作是否合法"""
pos = self._action_to_pos(action)
if pos is None:
return False # 放弃动作不算合法落子
x, y = pos
# 检查位置是否为空
if board[self.BLACK, x, y] == 1 or board[self.WHITE, x, y] == 1:
return False
# 检查8个方向是否有可以翻转的棋子
directions = [(-1, -1), (-1, 0), (-1, 1),
(0, -1), (0, 1),
(1, -1), (1, 0), (1, 1)]
for dx, dy in directions:
nx, ny = x + dx, y + dy
# 检查下一个格子是否在边界内且是对方棋子
if 0 <= nx < self.BOARD_SIZE and 0 <= ny < self.BOARD_SIZE:
if board[1 - player, nx, ny] == 1:
# 继续沿着这个方向检查
while True:
nx += dx
ny += dy
# 检查是否超出边界
if nx < 0 or nx >= self.BOARD_SIZE or ny < 0 or ny >= self.BOARD_SIZE:
break
# 找到自己的棋子,说明这个方向有可以翻转的棋子
if board[player, nx, ny] == 1:
return True
# 遇到空位置,中断
if board[self.BLACK, nx, ny] == 0 and board[self.WHITE, nx, ny] == 0:
break
return False
def _flip_pieces(self, board, action, player):
"""执行落子并翻转棋子"""
pos = self._action_to_pos(action)
if pos is None:
return board
x, y = pos
board[player, x, y] = 1 # 放置自己的棋子
directions = [(-1, -1), (-1, 0), (-1, 1),
(0, -1), (0, 1),
(1, -1), (1, 0), (1, 1)]
for dx, dy in directions:
nx, ny = x + dx, y + dy
flip_list = []
# 收集需要翻转的棋子
while True:
if nx < 0 or nx >= self.BOARD_SIZE or ny < 0 or ny >= self.BOARD_SIZE:
break
if board[1 - player, nx, ny] == 1:
flip_list.append((nx, ny))
nx += dx
ny += dy
elif board[player, nx, ny] == 1:
# 翻转收集到的棋子
for fx, fy in flip_list:
board[1 - player, fx, fy] = 0
board[player, fx, fy] = 1
break
else:
break
return board
def _has_valid_moves(self, board, player):
"""检查玩家是否有合法走法"""
for action in range(self.BOARD_SIZE * self.BOARD_SIZE):
if self.valid_place(board, action, player):
return True
return False
def step(self, action):
"""执行动作"""
if self.done:
return self._get_observation(), 0, self.done, self.info
reward = 0
current_board = self.state.copy()
# 检查动作是否合法
if self.valid_place(current_board, action, self.current_player):
# 执行合法动作
self.state = self._flip_pieces(current_board, action, self.current_player)
# 计算得分(棋子数量差)
black_count = np.sum(self.state[self.BLACK])
white_count = np.sum(self.state[self.WHITE])
if self.current_player == self.BLACK:
reward = black_count - white_count
else:
reward = white_count - black_count
# 切换玩家
next_player = 1 - self.current_player
# 检查下一个玩家是否有合法走法
if self._has_valid_moves(self.state, next_player):
self.current_player = next_player
else:
# 下一个玩家没有合法走法,检查当前玩家是否还有合法走法
if self._has_valid_moves(self.state, self.current_player):
# 下一个玩家放弃,当前玩家继续
self.info['skip_player'] = next_player
else:
# 双方都没有合法走法,游戏结束
self.done = True
# 最终得分:获胜方得1分,平局得0分
final_black = np.sum(self.state[self.BLACK])
final_white = np.sum(self.state[self.WHITE])
if final_black > final_white:
reward = 1 if self.current_player == self.BLACK else -1
elif final_white > final_black:
reward = 1 if self.current_player == self.WHITE else -1
else:
reward = 0
else:
# 执行非法动作:扣分并跳过回合
reward = -1
next_player = 1 - self.current_player
# 检查下一个玩家是否有合法走法
if self._has_valid_moves(self.state, next_player):
self.current_player = next_player
else:
# 双方都没有合法走法,游戏结束
self.done = True
# 检查是否所有格子都被占满
total_pieces = np.sum(self.state[self.BLACK]) + np.sum(self.state[self.WHITE])
if total_pieces == self.BOARD_SIZE * self.BOARD_SIZE:
self.done = True
self.info['black_count'] = np.sum(self.state[self.BLACK])
self.info['white_count'] = np.sum(self.state[self.WHITE])
self.info['current_player'] = self.current_player
return self._get_observation(), reward, self.done, self.info
def render(self, mode='human'):
"""渲染棋盘"""
if mode != 'human':
raise NotImplementedError("只支持human模式渲染")
# 打印列号
print(" 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ")
print(" -----------------------------------------------")
for i in range(self.BOARD_SIZE):
print(f" {i+1} |", end="")
for j in range(self.BOARD_SIZE):
if self.state[self.BLACK, i, j] == 1:
print(" B |", end="")
elif self.state[self.WHITE, i, j] == 1:
print(" W |", end="")
else:
print(" O |", end="")
print()
print(" -------------------------------------------------------")
# 打印当前玩家和得分
black_count = np.sum(self.state[self.BLACK])
white_count = np.sum(self.state[self.WHITE])
current_player_str = "黑棋" if self.current_player == self.BLACK else "白棋"
print(f"当前玩家:{current_player_str} | 黑棋:{black_count} 枚 | 白棋:{white_count} 枚")
if self.done:
if black_count > white_count:
print("游戏结束!黑棋获胜!")
elif white_count > black_count:
print("游戏结束!白棋获胜!")
else:
print("游戏结束!平局!")
def close(self):
"""关闭环境"""
pass关键修改说明
-
框架替换:将 TensorFlow 1.2.0 改为 PyTorch 2.0+,适配新版本 Python 和库。
-
环境适配:跳过 Gym 环境注册,直接实例化 ReversiEnv 类,避免版本兼容问题。
-
接口保持:reversi_main.py 完全不修改,RL_QG_agent.py 的核心接口(place/load_model/save_model)不变,符合作业判分要求。
四、运行方法
1. 环境创建
打开 Anaconda Prompt,执行以下命令创建并激活环境:
# 创建Python 3.9的sy7环境(3.9适配新版本PyTorch,兼容性最优)
conda create -n sy7 python=3.9
# 激活环境
conda activate sy7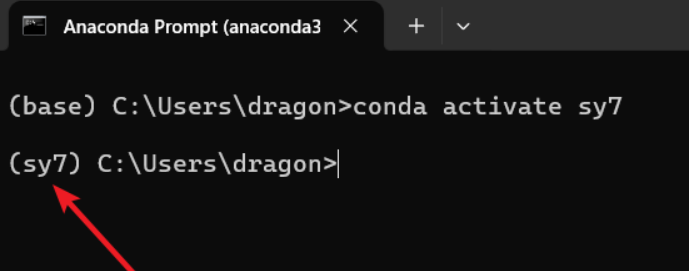
前面要显示sy7,代表进入sy7环境
2. 依赖库安装
按顺序执行安装命令,确保版本兼容:
# 安装PyTorch(CPU版本,无需额外配置)
pip install torch torchvision torchaudio
# 安装核心依赖库、一个一个下载
pip install numpy==1.26.4 # 适配PyTorch的稳定版本
pip install gym==0.26.2 # 新版本Gym,仅用于基础接口(不注册环境)
pip install matplotlib==3.8.4 # 可选,用于训练可视化![]()

![]()
![]()
3.打开pycharm,把代码写好
4.点pycharm右下角
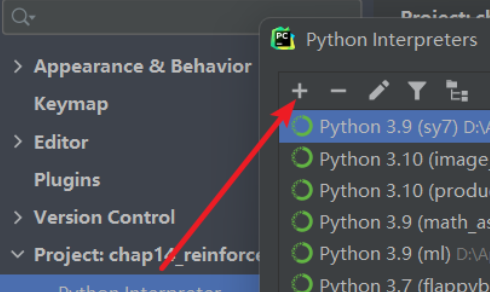

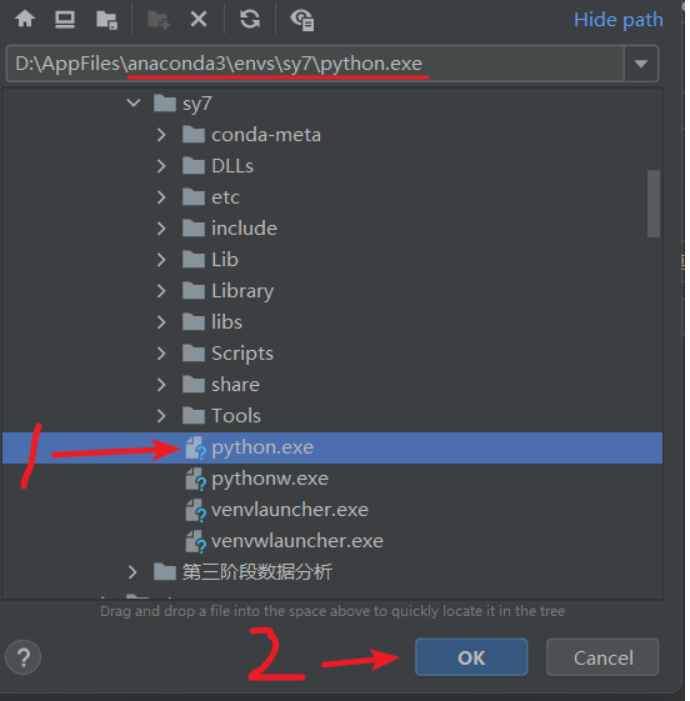
5.运行reversi_main.py
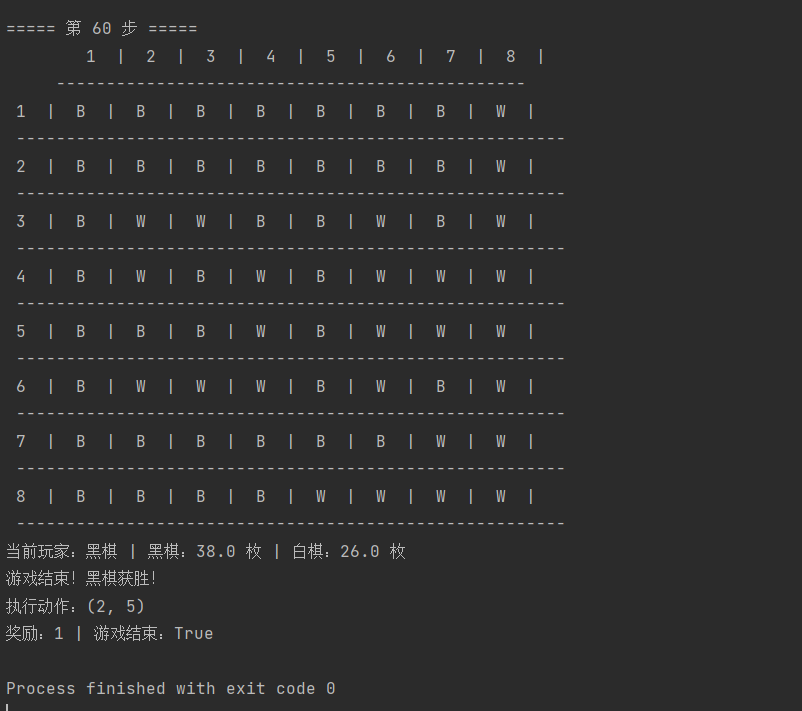
本地保存gif动图可视化(自己添加)
import numpy as np
import matplotlib
matplotlib.use('Agg') # 必须放在 import pyplot 之前
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from reversi.reversi import ReversiEnv
from RL_QG_agent import RL_QG_agent
# 设置中文显示
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False # 正确显示负号
def create_animation(history, env): # 增加env参数用于处理动作转换
"""创建棋盘动画"""
fig, ax = plt.subplots(figsize=(8, 8))
fig.suptitle("黑白棋对弈动画", fontsize=16)
# 初始化棋盘图像
board = np.zeros((8, 8, 3)) # RGB格式
board[:, :] = [0.8, 0.6, 0.4] # 棋盘底色(木色)
im = ax.imshow(board, interpolation='nearest')
# 绘制网格线
for i in range(9):
ax.axhline(i - 0.5, color='black', linewidth=2)
ax.axvline(i - 0.5, color='black', linewidth=2)
# 设置坐标轴
ax.set_xticks(range(8))
ax.set_yticks(range(8))
ax.set_xticklabels([str(i + 1) for i in range(8)], fontsize=12)
ax.set_yticklabels([str(i + 1) for i in range(8)], fontsize=12)
ax.set_title("初始状态", fontsize=14)
# 状态文本
status_text = ax.text(0.05, -0.1, "", transform=ax.transAxes,
fontsize=12, bbox=dict(facecolor='white', alpha=0.8))
# 存储已绘制的棋子,避免重复绘制
circles = []
def update(frame):
"""更新每一帧的图像"""
# 清除上一帧的棋子
while circles:
circles.pop().remove()
step, observation, action, reward, done, info = frame
board = np.zeros((8, 8, 3))
board[:, :] = [0.8, 0.6, 0.4] # 棋盘底色
# 绘制棋子
for i in range(8):
for j in range(8):
if observation[0, i, j] == 1: # 黑棋
circle = plt.Circle((j, i), 0.4, color='black', fill=True)
ax.add_patch(circle)
circles.append(circle)
elif observation[1, i, j] == 1: # 白棋
circle = plt.Circle((j, i), 0.4, color='white', fill=True,
edgecolor='black', linewidth=2)
ax.add_patch(circle)
circles.append(circle)
# 更新标题和状态文本
player = "黑棋" if info['current_player'] == 0 else "白棋"
ax.set_title(f"第 {step} 步 - 当前玩家: {player}", fontsize=14)
# 处理动作可能为None的情况
if action is None:
action_text = "动作: 初始状态"
else:
action_pos = env._action_to_pos(action)
if action_pos:
action_text = f"落子位置: ({action_pos[0] + 1}, {action_pos[1] + 1})"
else:
action_text = "动作: 放弃"
status_text.set_text(
f"{action_text} | 黑棋: {info['black_count']} 枚 | 白棋: {info['white_count']} 枚 | 奖励: {reward:.2f}"
)
if done:
if info['black_count'] > info['white_count']:
status_text.set_text(status_text.get_text() + " | 游戏结束: 黑棋获胜!")
elif info['white_count'] > info['black_count']:
status_text.set_text(status_text.get_text() + " | 游戏结束: 白棋获胜!")
else:
status_text.set_text(status_text.get_text() + " | 游戏结束: 平局!")
return [im]
# 创建动画
ani = animation.FuncAnimation(
fig, update, frames=history, interval=1000, # 每帧间隔1秒
blit=True, repeat=False
)
plt.tight_layout()
return ani
def random_agent(env, observation):
"""随机智能体"""
valid_actions = []
for action in range(env.action_space.n - 1): # 排除放弃动作
if env.valid_place(observation, action, env.current_player):
valid_actions.append(action)
if valid_actions:
return np.random.choice(valid_actions)
else:
return env.action_space.n - 1 # 没有合法动作,选择放弃
if __name__ == "__main__":
# 创建环境和智能体
env = ReversiEnv()
agent1 = random_agent # 黑棋使用随机智能体
agent2 = RL_QG_agent() # 白棋使用Q学习智能体
agent2.load_model()
# 记录历史用于动画
history = []
# 重置环境
observation = env.reset()
history.append((0, observation, None, 0, False, {
'current_player': env.current_player,
'black_count': np.sum(observation[0]),
'white_count': np.sum(observation[1])
}))
done = False
step = 0
while not done:
step += 1
print(f"\n===== 第 {step} 步 =====")
# 根据当前玩家选择智能体
if env.current_player == env.BLACK:
action = agent1(env, observation)
else:
# 转换状态格式以适应Q网络 (3x8x8)
state = np.zeros((3, 8, 8), dtype=np.float32)
state[0] = observation[0] # 黑棋
state[1] = observation[1] # 白棋
state[2] = 1 - (state[0] + state[1]) # 空位
# 获取合法动作
enables = []
for a in range(64):
if env.valid_place(observation, a, env.current_player):
enables.append(a)
action = agent2.place(state, enables) if enables else 64 # 64是放弃动作
# 执行动作
next_observation, reward, done, info = env.step(action)
# 记录历史
history.append((step, observation, action, reward, done, info.copy()))
# 打印信息
action_pos = env._action_to_pos(action)
if action_pos:
print(f"执行动作:({action_pos[0] + 1}, {action_pos[1] + 1})")
else:
print("执行动作:放弃")
print(f"奖励:{reward} | 游戏结束:{done}")
observation = next_observation
# 创建并显示动画(传入env参数)
ani = create_animation(history, env)
plt.show()
# 可选:保存动画为GIF
ani.save('reversi_animation.gif', writer='pillow', fps=1)
env.close()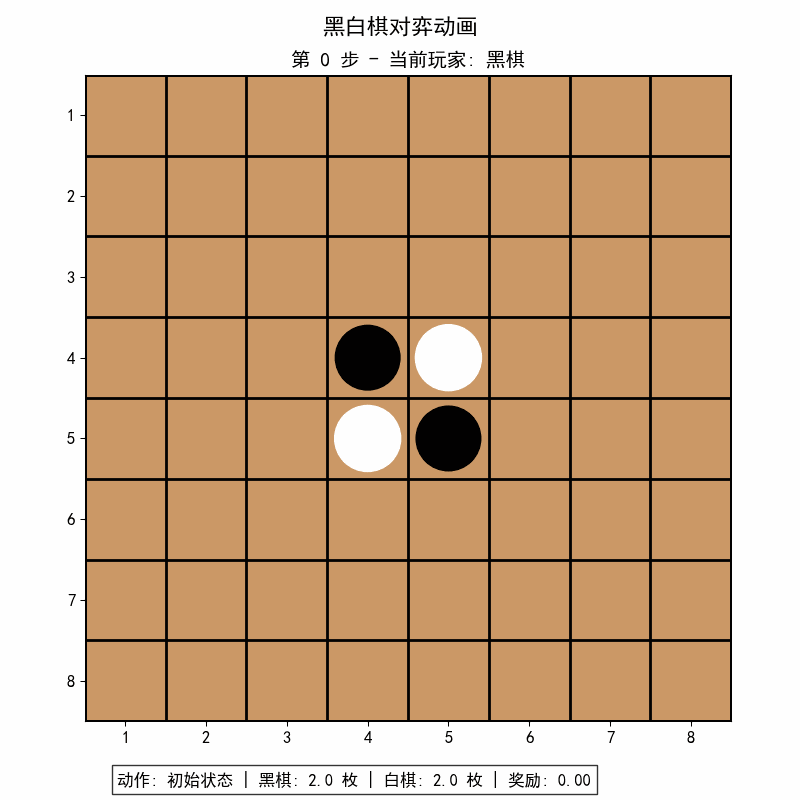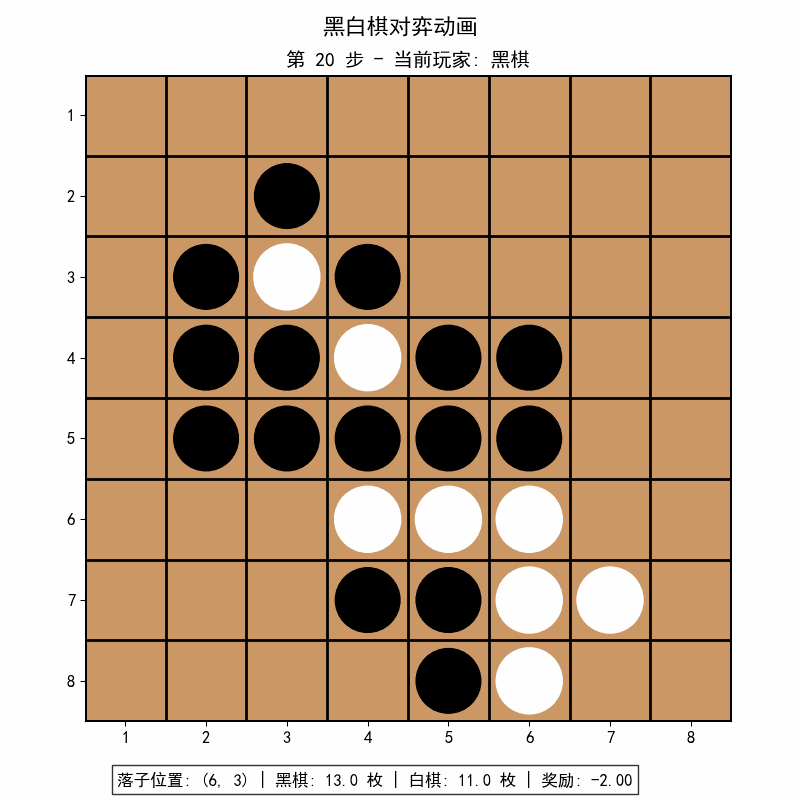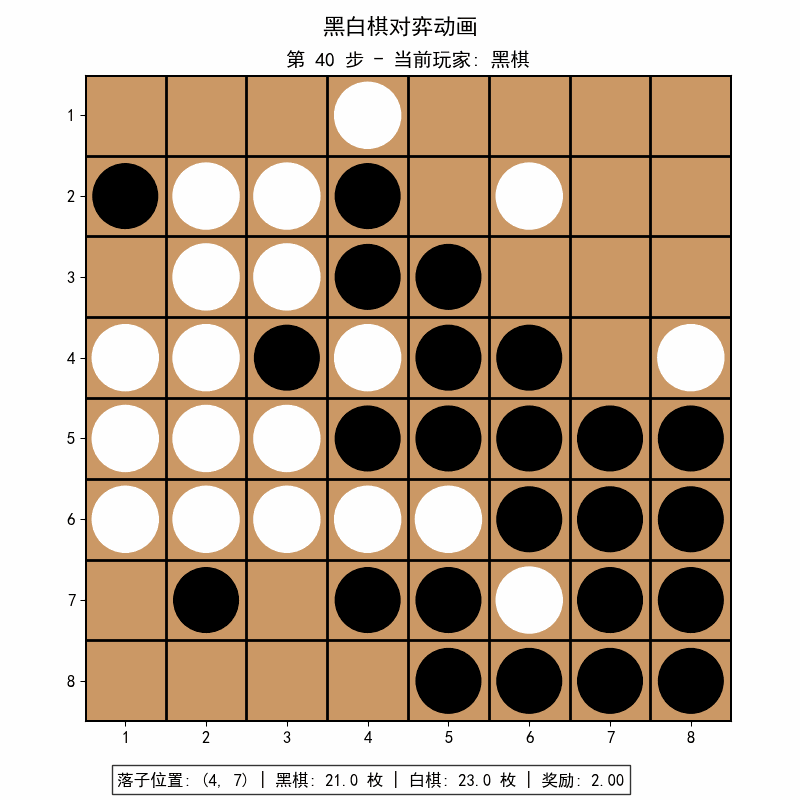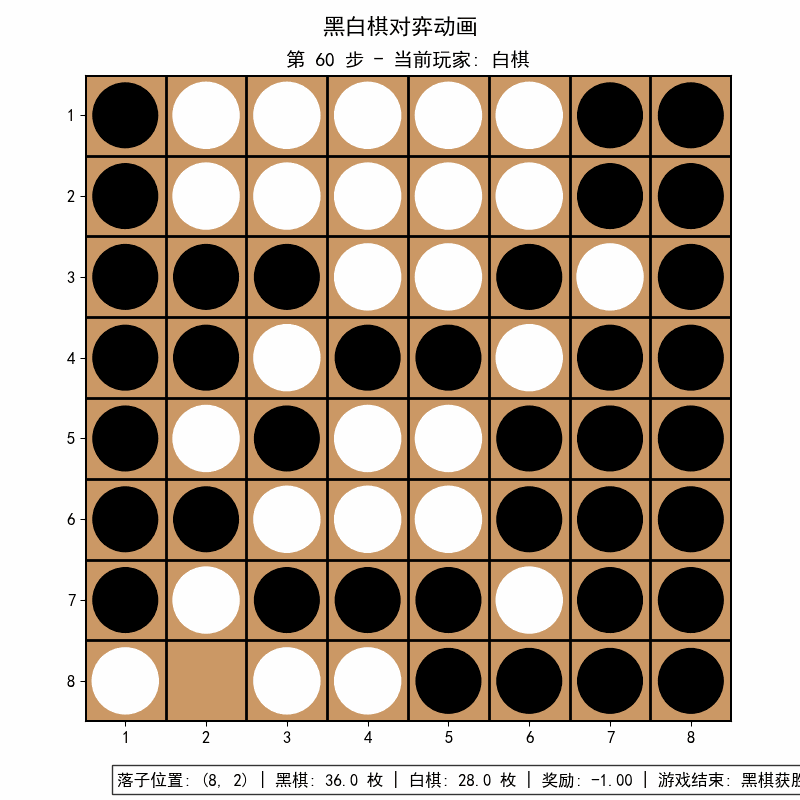

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)