AI开发者必备:上下文工程2.0:超越Prompt Engineering的系统框架
本文系统介绍了上下文工程的演进与核心框架。上下文工程已发展二十余年,旨在弥合人类模糊意图与机器结构化指令间的鸿沟。文章提出四阶段演化模型:从"人适应机器"的1.0时代到"机器启发人"的4.0时代。三大支柱包括上下文的收集与存储、管理和使用,强调系统化设计而非零散技巧。随着AI能力提升,人类"翻译成本"逐渐降低,未来将实现"上下文的语义操作系统",让AI真正理解并服务于人类需求。
Context Engineering 2.0: The Context of Context Engineering
今天我们要探讨一篇非常有前瞻性和系统性的论文:《上下文工程2.0:上下文工程的“上下文”》(Context Engineering 2.0: The Context of Context Engineering)。现在都在玩各种大模型、AI Agent,天天都在说“Prompt Engineering”,感觉这是个很新的东西。
但这篇论文告诉我们,我们可能只看到了冰山一角。它把我们的视野从当下的“技术热点”拉到了一个更宏大、更深刻的“历史演进”和“理论框架”的层面。
第一部分:“上下文工程”不是新事物
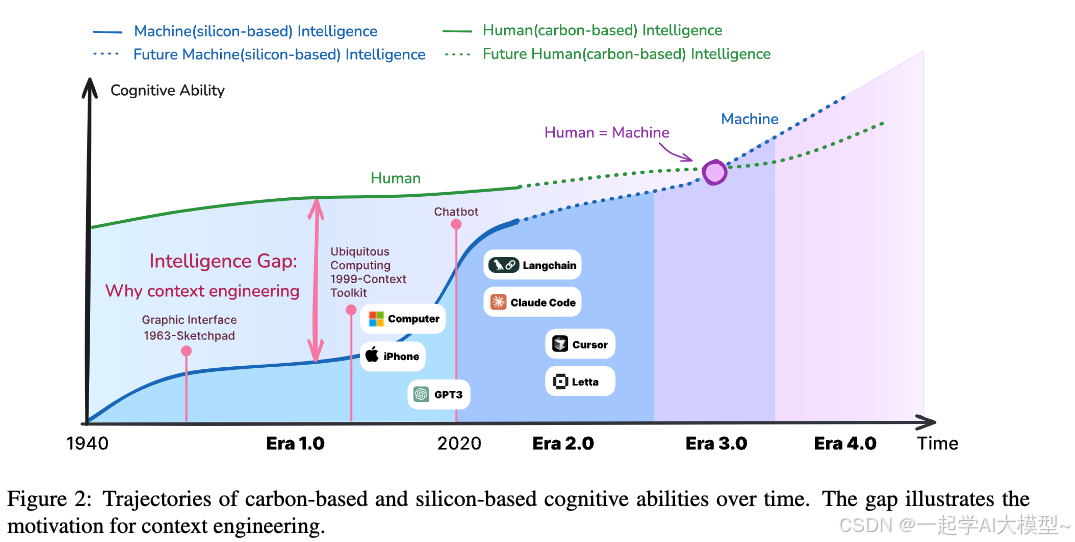
这篇论文的核心论点:上下文工程(Context Engineering)并非诞生于LLM时代,而是一门已经发展了二十多年的、伴随机器智能水平不断演进的学科。
我们现在做的所谓“提示词工程”、“RAG(检索增强生成)”等等,都只是“上下文工程”在当前这个时代(也就是论文定义的2.0时代)的具体实践形式。
那到底什么是“上下文工程”呢?
-
- 什么是“上下文”(Context)?
论文给出了一个非常经典且宽泛的定义:“任何可以用来描述‘实体’(人、地点、物体)状况的信息,只要这些实体与用户和应用的交互相关,都算上下文。”
这个定义非常重要。不要把“上下文”狭隘地理解为对话历史记录。你当前所在的文件夹路径、你的操作系统、你正在使用的软件、甚至你过往的偏好、外部可调用的API工具……这些都是上下文。它是情境的总和。
-
- 什么是“上下文工程”(Context Engineering)?
它是指系统性地设计、收集、存储、管理和使用上下文信息,以增强机器对人类意图的理解和任务执行能力的过程。关键词是“系统性地”。
它不是零敲碎打的技巧,而是一整套方法论。它的根本目的始终没变:弥合人类的高熵、模糊意图与机器所能理解的低熵、结构化指令之间的鸿沟。
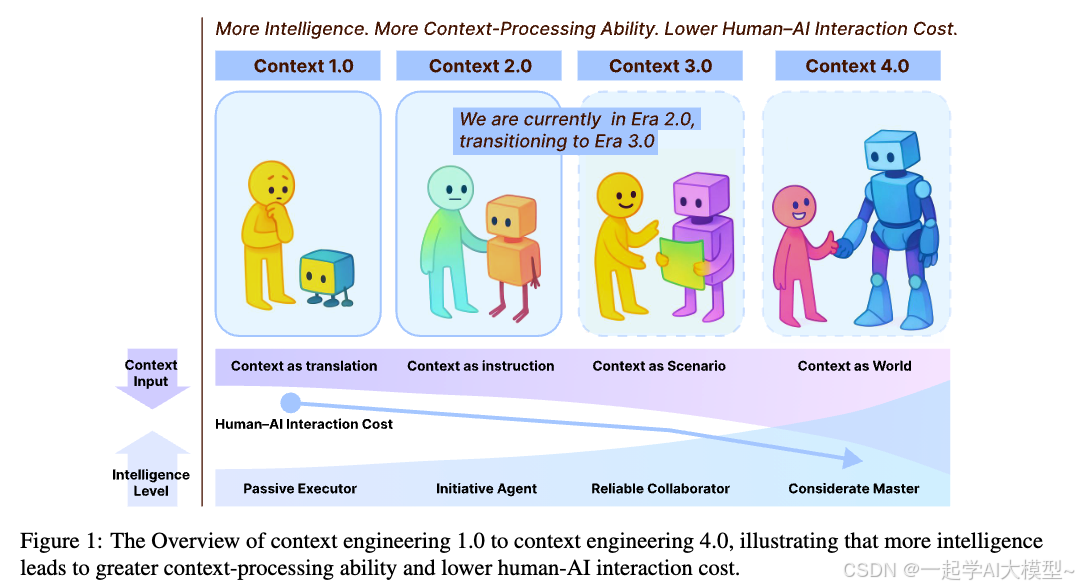
第二部分:上下文工程的四个时代
这篇论文最具洞见的地方,就是提出了一个“四阶段”的演化模型,把上下文工程的发展和机器智能的等级牢牢绑定在了一起。
- • 1.0 时代:原始计算时代 (1990s - 2020)
- • 特征:机器智能水平低,只能理解结构化、低熵的输入。
- • 人机关系:“人适应机器”。
- • 实践:我们用图形界面(GUI)的菜单、按钮,或者早期的环境感知计算(比如手机进入会议室自动静音),这些都是把复杂的意图“翻译”成机器能懂的简单指令。设计师是“意图翻译官”。
- • 2.0 时代:智能体时代 (2020 -至今)
- • 特征:以LLM为代表,机器开始具备理解自然语言和处理模糊信息的能力。
- • 人机关系:“机器开始适应人”。
- • 实践:这就是我们现在所处的时代。我们用自然语言写Prompt,用RAG给模型“喂”知识,设计复杂的Agent工作流。上下文变成了给一个有能力的“智能体”下达的指令(Instruction)。
- • 3.0 时代:人类水平智能时代 (未来)
- • 特征:AI达到与人类相当的推理和理解能力。
- • 人机关系:人机成为真正的协作者(Collaborator)。
- • 畅想:AI能像人一样感知社交氛围、情绪状态等高熵信息。交互会变得极其自然,不再需要费尽心思地“设计”上下文,AI能自己“领悟”。
- • 4.0 时代:超人类智能时代 (畅想)
- • 特征:机器智能超越人类。
- • 人机关系:发生反转,机器成为启发者(Master)。
- • 畅想:AI不再是被动地理解我们给它的上下文,而是能主动为我们构建全新的上下文,揭示我们自己都未曾意识到的深层需求。就像AlphaGo下出了人类棋手从未想过的棋路一样。
可以看到,从1.0到4.0,机器的智能水平越高,处理上下文的能力越强,我们人类需要付出的“翻译成本”就越低。这就是整个演进的核心驱动力。
第三部分:上下文工程的三大支柱
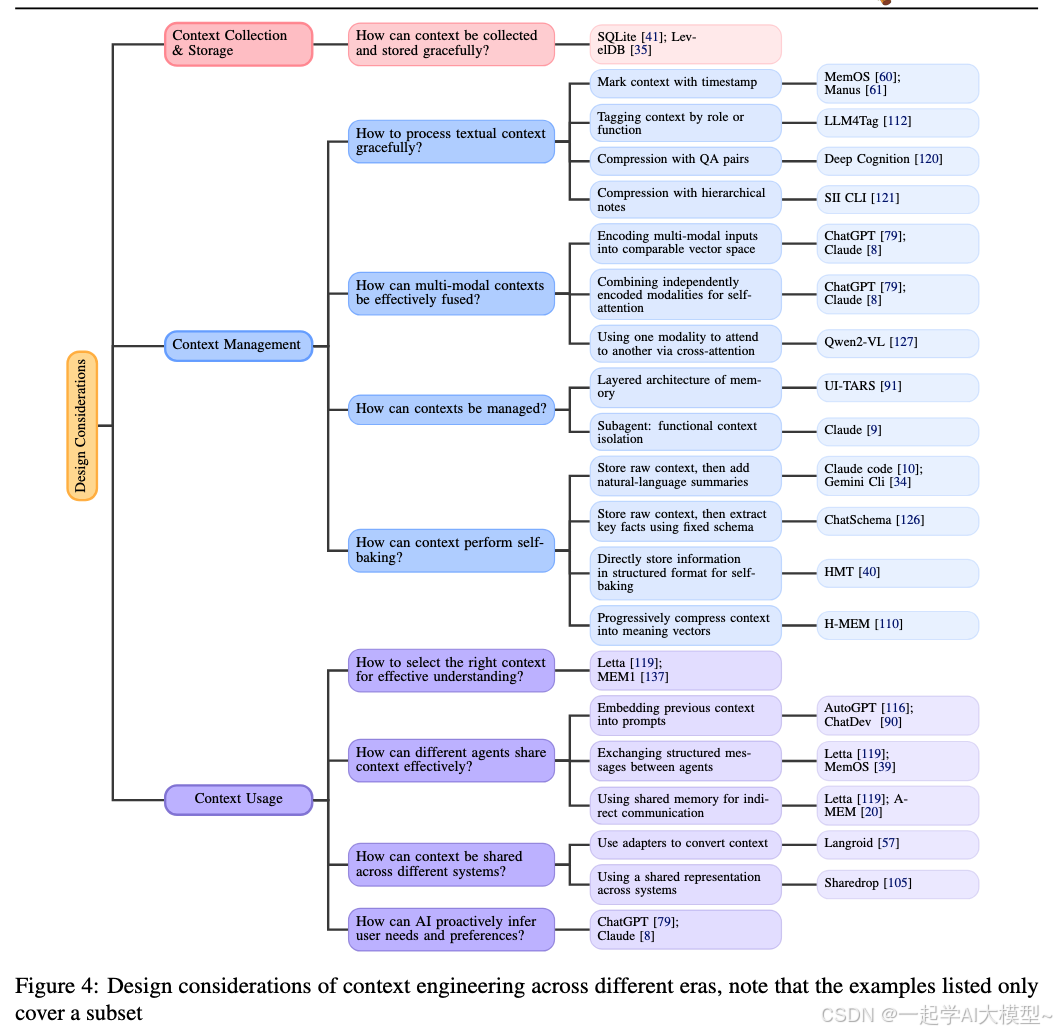
讲完了宏观历史,我们来看看具体的“工程实践”。论文从三个维度系统地梳理了上下文工程的技术要点,这部分对大家做实际项目非常有指导意义。
1. 上下文的收集与存储 (Context Collection & Storage)
- • 怎么收集? 从1.0时代的GPS、时钟等简单传感器,进化到2.0时代的多模态、多设备(手机、可穿戴设备、IoT)的持续信息流。
- • 怎么存储? 从1.0时代的本地日志文件,进化到2.0时代的分层存储架构。这很像我们计算机的存储体系:
- • 短期内存(RAM):对应模型的上下文窗口,快速但有限。
- • 长期内存(硬盘):对应外部数据库(向量数据库、SQLite等),持久且海量。
2. 上下文的管理 (Context Management)
这是整个工程的“大脑”,也是最复杂、最核心的部分。如何把原始、杂乱的上下文变得井井有条、易于使用?
- • 上下文的组织:
- • 分层记忆架构:明确区分短期记忆和长期记忆。重要的、反复使用的信息,要从短暂的上下文窗口沉淀到长期的知识库里。
- • 上下文隔离 (Context Isolation):这个思想非常巧妙。比如论文提到的子智能体(Subagent)。让一个主Agent负责统筹,把特定任务(如代码分析、文件读写)交给拥有独立上下文的子Agent处理。这样做的好处是,防止不同任务的上下文互相“污染”,也让系统更加模块化、稳定可靠。
- • 上下文的抽象,或者叫“自我烘焙” (Self-Baking)
- • 这是一个非常形象的比喻。Agent不能只是被动地存储信息,它必须能主动地“消化”和“吸收”自己的经历,把原始上下文“烘焙”成更紧凑、更结构化的知识。这才是从“记忆”到“学习”的关键。
- • 方法1:自然语言总结。定期让模型自己写个工作小结,总结最近发生了什么。简单直接,但不够结构化。
- • 方法2:固定模式提取。将关键信息提取到一个预设的结构(Schema)里,比如任务树、实体关系图。这让信息变得可查询、可推理。
- • 方法3:渐进式向量压缩。把信息编码成向量(Embedding),并随着时间推移,将旧的向量融合成更抽象的、更高层次的语义记忆。
3. 上下文的使用 (Context Usage)
管理好的上下文,最终要为任务服务。
- • 上下文的选择:上下文窗口是宝贵的资源,不能什么都往里塞。必须有一套有效的筛选机制,论文称之为“注意力之前的注意力”。你需要根据语义相关性、逻辑依赖性、新近度等因素,动态地选择最关键的信息放入窗口。
- • 上下文的共享:
- • 系统内共享:多个Agent如何协作?可以通过Prompt传递、结构化消息交换,或者一个共享的“黑板”(Shared Memory)来通信。
- • 跨系统共享:你的AI助手如何与Office套件协同?需要通过适配器(Adapter)或者统一的上下文表示协议来实现。
- • 主动的用户需求推理:最高级的用法是,系统能通过分析长期上下文,主动预测你的潜在需求。比如,发现你总是在下午搜索咖啡店,就主动在下午推荐附近的优惠。
最后,论文指出了当前面临的挑战:比如长上下文处理的性能瓶颈、上下文收集的效率低下、模型对复杂逻辑的理解不足等。
并提出了一个非常宏大的终极构想——“上下文的语义操作系统”(Semantic Operating System for Context)。
这是什么概念?想象一下,未来会有一个系统,它能管理一个人一生的数字痕迹(对话、决策、行为),像一个动态的、有生命的个人知识库。它能实现真正的长期记忆、持续学习、甚至具备遗忘机制。到那时,我们的“数字孪生”或者说“数字存在”,将不再是科幻,而是由我们一生的上下文所定义的现实。、
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献256条内容
已为社区贡献256条内容

所有评论(0)