大模型核心技术与应用场景全解析,建议收藏学习!
大模型是参数规模超亿级的深度学习模型,基于Transformer架构,通过海量数据预训练实现多任务学习。核心技术包括分布式训练、模型压缩和优化策略,应用于自然语言处理、多模态学习和科学研究等领域。当前面临计算资源消耗、数据偏差和可解释性等挑战,未来将向高效化、多模态融合和环境友好方向发展。
引言
- 大模型(Large Models)是人工智能发展的里程碑,特别是基于深度学习的预训练模型(如 GPT、BERT)。
- 随着模型参数规模的指数级增长,大模型在自然语言处理(NLP)、计算机视觉(CV)等领域取得了突破性成果。
- 本文将深入解析大模型的核心技术、应用场景、优化策略及未来挑战。
大模型的背景与定义
1.1 什么是大模型
- 大模型指的是参数规模超过亿级甚至千亿级的深度学习模型。
- 特点:
- 高容量:能够捕捉复杂模式和分布。
- 通用性:支持多任务、多模态(如文本、图像、音频)学习。
- 可扩展性:在预训练基础上,通过少量样本(Few-shot)或无监督微调(Zero-shot)完成特定任务。
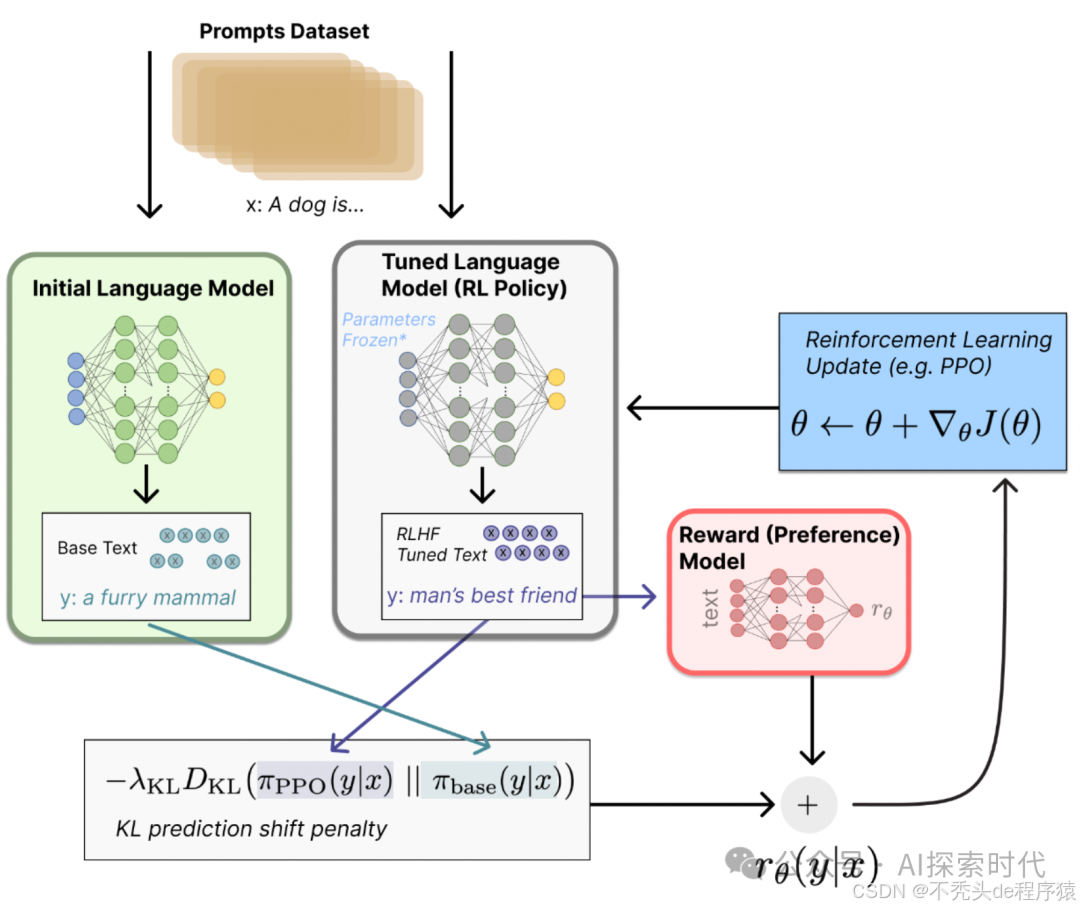
1.2 大模型发展的阶段
- 1.0 传统机器学习模型:如 SVM、决策树。
- 2.0 深度学习模型:如 CNN、RNN。
- 3.0 预训练模型:BERT、GPT。
- 4.0 多模态模型:如 OpenAI 的 CLIP,DeepMind 的 Gato。
1.3 参数规模的增长
- 参数规模从早期的百万级(如 LSTM)发展到百亿级(如 GPT-3)再到万亿级(如 GPT-4、PaLM)。
- 参数规模增长的驱动力:
-
更强的硬件支持(GPU/TPU)。
-
更高效的分布式训练算法。
-
海量标注与非标注数据的积累。
2. 大模型的核心技术
2.1 模型架构
- Transformer 架构:
- 基于注意力机制(Attention Mechanism),实现更好的全局信息捕获。
- Self-Attention 的时间复杂度为 O(n2)O(n2),适合并行化训练。
- 改进的 Transformer:
- Sparse Attention(稀疏注意力):降低计算复杂度。
- Longformer:处理长文本输入。
2.2 数据处理与预训练
- 数据处理:
- 使用海量数据(如文本、代码、图像)进行去噪和清洗。
- 多模态融合技术,将图像与文本联合编码。
- 预训练目标:
- 自回归(Auto-Regressive):预测下一个 token(如 GPT)。
- 自编码(Auto-Encoding):掩盖部分输入并恢复原始内容(如 BERT)。
2.3 模型训练与优化
- 分布式训练:
- 数据并行(Data Parallelism):多个设备共享模型权重,不同设备处理不同数据。
- 模型并行(Model Parallelism):将模型切分为多个部分,分布到不同设备。
- 优化技术:
- 混合精度训练(Mixed Precision Training):提升训练速度,降低显存占用。
- 大批量训练(Large Batch Training):结合学习率调度策略。
2.4 模型压缩
-
模型蒸馏(Knowledge Distillation):用大模型指导小模型训练。
-
参数量化(Quantization):减少模型权重的精度(如 32-bit 到 8-bit)。
-
稀疏化(Sparsification):去除冗余参数。
3. 大模型的应用场景
3.1 自然语言处理
- 文本生成:如 ChatGPT、Bard。
- 机器翻译:如 Google Translate。
- 文本摘要:从长文档中提取核心信息。
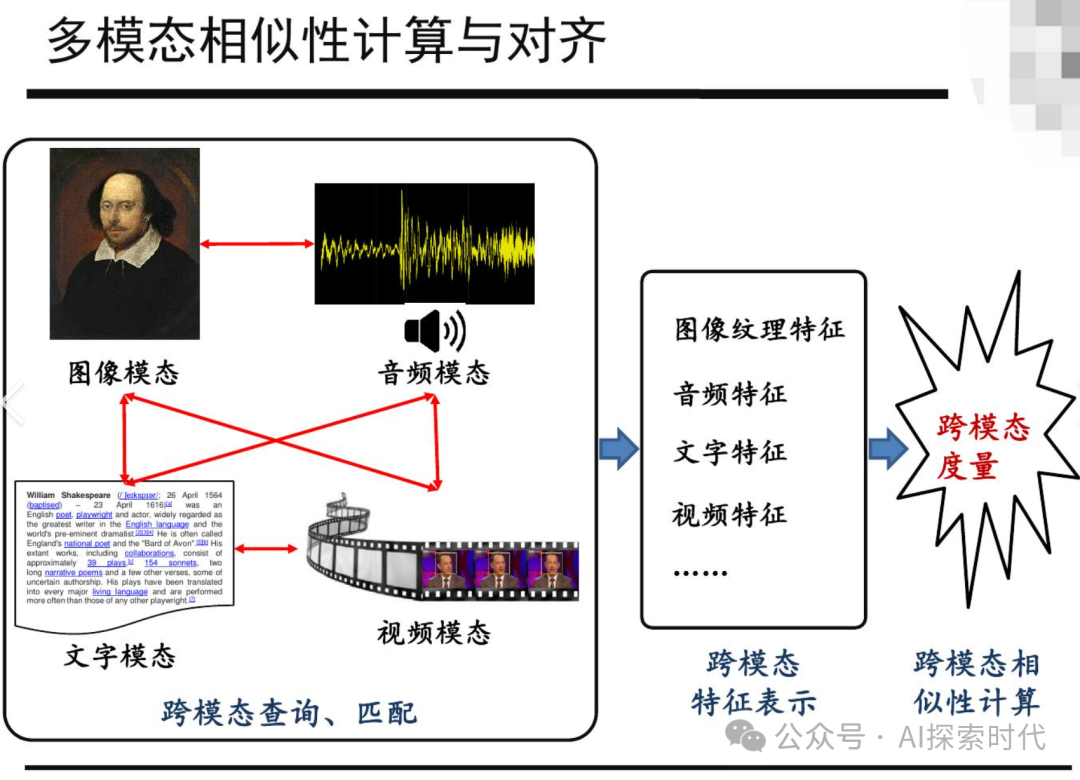
3.2 多模态学习
- 图像与文本结合:如 OpenAI 的 DALL·E,通过文本生成图像。
- 视频理解:如 DeepMind 的 Flamingo,支持跨模态推理。
- 医学影像分析:结合文本描述辅助诊断。
3.3 科学研究
- 蛋白质折叠预测:如 DeepMind 的 AlphaFold。
- 化学反应模拟:利用大模型加速新材料发现。
4. 大模型的挑战
4.1 计算资源与成本
- 训练大模型需要大量计算资源(如数千张 GPU),成本高昂。
- 推理效率仍是瓶颈,特别是在边缘设备上。
4.2 数据质量与偏差
- 大模型对数据高度依赖,低质量数据可能导致偏差。
- 隐私和伦理问题:如训练数据中包含敏感信息。
4.3 可解释性
- 大模型通常被视为“黑盒”,其决策过程难以理解。
- 需要开发更好的模型可视化和解释技术。
4.4 通用性与专用性
- 通用大模型在某些领域表现优异,但专用领域可能需要针对性优化。
5. 大模型的未来
5.1 模型设计的创新
- 向高效化、稀疏化方向发展,如 Modular Transformer。
- 探索生物启发的架构(如脑启发计算)。
5.2 更好的多模态集成
- 实现真正的“通用智能”(AGI),支持跨模态任务协作。
5.3 环境友好型 AI
- 开发绿色 AI 技术,降低碳排放。
- 通过知识重用减少训练次数。
5.4 开放与合作
- 开源大模型(如 Meta 的 LLaMA)促进了研究社区的合作。
- 更多跨学科应用,如金融、医学、物理等。
结论
大模型是当前 AI 技术的核心驱动力,从技术架构到实际应用都带来了深远影响。然而,随着模型规模的持续扩大,也暴露出资源消耗、伦理风险等挑战。未来,优化模型效率、提升可解释性、推动多模态融合将成为关键研究方向。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献225条内容
已为社区贡献225条内容

所有评论(0)