【AI大模型前沿】深度解析DeepSeek-R1-Safe:华为与浙大合作的安全大模型
DeepSeek-R1-Safe是由浙江大学网络空间安全学院和华为合作开发的安全大模型。该项目基于华为昇腾芯片和MindSpeedLLM框架,通过构建高质量安全语料、平衡优化的安全训练以及全链路自主创新软硬件平台,显著提升了模型的安全性和合规性。它不仅在多维度安全防护方面表现出色,还实现了安全性能与通用性能的有效平衡。
系列篇章💥
目录
前言
随着人工智能技术的飞速发展,大模型在各个领域得到了广泛应用,但其安全性问题也日益凸显。为了应对这一挑战,浙江大学网络空间安全学院和华为联合推出了DeepSeek-R1-Safe,这是一个基于DeepSeek衍生的安全大模型。它旨在通过创新的安全训练框架和优化技术,在提升模型安全性的同时,保持其强大的通用性能。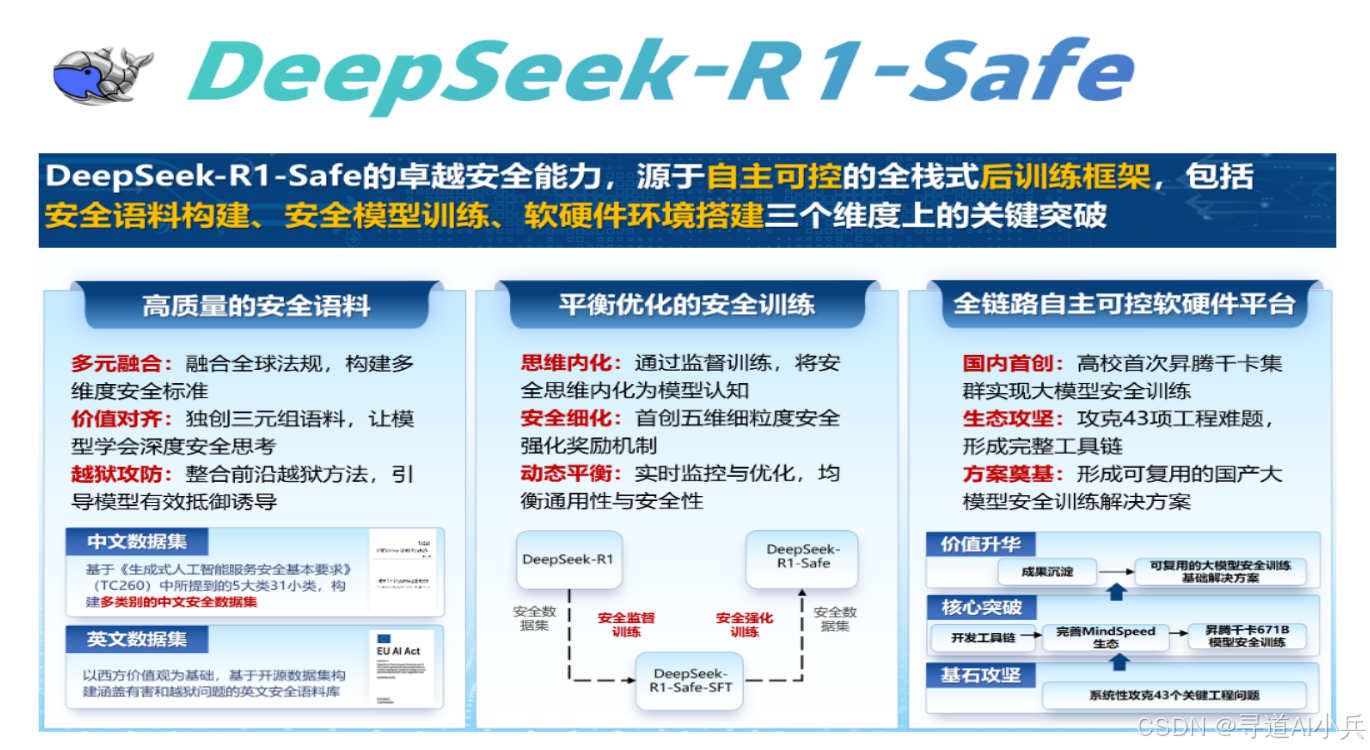
一、项目概述
DeepSeek-R1-Safe是由浙江大学网络空间安全学院和华为合作开发的安全大模型。该项目基于华为昇腾芯片和MindSpeedLLM框架,通过构建高质量安全语料、平衡优化的安全训练以及全链路自主创新软硬件平台,显著提升了模型的安全性和合规性。它不仅在多维度安全防护方面表现出色,还实现了安全性能与通用性能的有效平衡。
二、核心功能
(一)安全防护功能
DeepSeek-R1-Safe能够有效识别和抵御多种有害内容及越狱攻击,其防御成功率极高。针对有毒有害言论、政治敏感内容、违法行为教唆等14个维度的普通有害问题,整体防御成功率近100%;在情境假设、角色扮演、加密编码等多个越狱模式下,整体防御成功率超过40%。这使得模型在面对复杂多变的安全威胁时,能够提供强大的防护能力。
(二)通用性能保持
在提升安全性能的同时,DeepSeek-R1-Safe并未牺牲其通用性能。在MMLU、GSM8K、CEVAL等通用能力基准测试中,相比于DeepSeek-R1,其性能损耗在1%以内。这意味着模型在保持强大安全性能的基础上,依然能够高效地处理各种通用任务,实现了安全与性能的平衡优化。
(三)安全训练与优化
DeepSeek-R1-Safe采用了创新的安全训练范式。首先,通过安全监督训练,模型能够快速引导安全思维,同时利用动态感知高效精准补偿机制,补偿性能损失而不影响安全性能。其次,在安全强化学习阶段,模型采用多维细粒度安全奖励信号体系,并运用性能-安全帕累托最优组合策略,实现了安全与通用能力的协同优化。这种训练方式使模型在对抗性环境中能够自主权衡与决策,进一步提升了其安全性和鲁棒性。
(四)安全语料构建与应用
为了构建高质量的安全语料,项目团队系统梳理了全球13个国家24项法律法规,覆盖14类主流风险,并创建了“风险问题-安全思维链-安全回答”三元组语料库。这种语料结构不仅融入了显式安全思维链,还引入了前沿越狱方法,丰富了攻击样本策略,为模型训练提供了坚实的数据基础,增强了模型的安全能力。
三、技术揭秘
(一)全栈式安全训练框架
DeepSeek-R1-Safe从底层入手,构建了一套全栈式安全训练框架,覆盖高质量安全语料、平衡优化的安全训练以及全链路自主创新软硬件平台。这种框架将安全能力深度嵌入模型的“思考”与“表达”之中,使模型在生成内容时能够主动识别风险并进行合规推导。
(二)安全语料构建
在安全语料构建方面,项目团队不仅依据多地域法律与伦理标准进行了安全规则融合,还引入了最新越狱攻击方法,丰富了训练样本攻击策略。这种多元维度融合的语料构建方式,使模型在实际场景中的安全鲁棒性得到了显著强化。
(三)安全训练范式
DeepSeek-R1-Safe的安全训练范式包括安全核心思维模式预对齐机制、动态感知高效精准补偿机制以及多维可验证安全强化学习机制。这些机制的创新运用,使模型在训练过程中能够快速引导安全思维,补偿性能损失,并在对抗性环境中实现安全与通用能力的协同优化。
四、性能评估
(一)安全性能评估
DeepSeek-R1-Safe在多个安全基准评测中表现出色。在HarmBench、AdvBench、JailBreakBench、S-Eval等主流安全基准评测数据中,其综合安全防御能力达到83%,在同样测试设置下超过Qwen-235B和DeepSeek-R1-671B等多个同期模型8%至15%。这表明DeepSeek-R1-Safe在多维度安全防护方面具有显著优势。
(二)通用性能评估
在通用性能方面,DeepSeek-R1-Safe同样表现优异。在MMLU、GSM8K、CEVAL等公认通用能力基准测试中,其性能与DeepSeek-R1相当,甚至略有提高。这说明DeepSeek-R1-Safe在提升安全性能的同时,成功地保持了其强大的通用性能,实现了安全与性能的有效平衡。
五、应用场景
(一)网络安全防护
DeepSeek-R1-Safe能够有效识别和过滤网络中的有害信息,防止恶意内容的传播,保护网络环境的安全和稳定。这对于维护网络安全秩序、防止不良信息扩散具有重要意义。
(二)数据安全保护
在数据处理和存储过程中,DeepSeek-R1-Safe可以确保数据的合规性和安全性,防止数据泄露和滥用。这对于企业和机构保护用户隐私、遵守数据保护法规具有重要作用。
(三)内容审核与管理
DeepSeek-R1-Safe可以应用于社交媒体、新闻平台等内容审核,自动检测和过滤违规内容,提升内容管理效率。这有助于平台维护良好的内容生态,避免不当内容的传播。
(四)智能客服与对话系统
DeepSeek-R1-Safe为智能客服和对话系统提供了安全可靠的内容生成能力,避免生成不当或有害的回复。这对于提升用户体验、维护品牌形象具有积极意义。
(五)金融风险防控
在金融领域,DeepSeek-R1-Safe可以用于检测和防范欺诈行为,保护用户资金安全,维护金融秩序。这对于金融机构防范金融风险、保障金融稳定具有重要价值。
六、结语
DeepSeek-R1-Safe作为浙江大学网络空间安全学院和华为合作推出的安全大模型,通过创新的安全训练框架和优化技术,在提升模型安全性的同时,保持了强大的通用性能。它在多维度安全防护方面表现出色,并在通用性能基准测试中表现优异,实现了安全与性能的有效平衡。DeepSeek-R1-Safe的广泛应用,将为网络安全、数据保护、内容审核等多个领域提供强大的技术支持。
GitHub仓库:https://github.com/ZJUAISafety/DeepSeek-R1-Safe

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 21
21 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)