MICCAI | Semi-supervised medical segmentation(一)
摘要:本文提出Text-SemiSeg框架,通过文本信息增强半监督3D医学图像分割性能。方法包含:1)文本增强多平面表示(TMR),将3D特征分解为三个2D平面与文本交互;2)类别感知语义对齐(CSA)模块,通过MSE正则化约束文本-视觉特征对齐;3)动态认知增强(DCA)模块,混合标注/未标注数据前景区域以缩小分布差异。实验表明,在胰腺和BraTS数据集上Dice系数分别提升1.15%和1.12
论文:Text-driven Multiplanar Visual Interaction for Semi-supervised Medical Image Segmentation
地址:https://arxiv.org/abs/2507.12382
背景
半监督医学图像分割是降低数据标注高成本的关键方法。当标注数据有限时,文本信息可提供额外上下文,以增强视觉语义理解。然而,目前探索利用文本数据提升三维医学影像任务中视觉语义嵌入的研究仍十分稀缺。
近年来,基于视觉-语言大模型的研究,如对比语言-图像预训练(CLIP),通过对比学习将图像与其对应的文本描述精准对齐,取得了令人瞩目的成果。在医学影像领域,Liu等人率先将CLIP应用于三维医学成像任务,证明了文本信息能够为基于体素的视觉特征提供额外的语义上下文支持。此外,VCLIPSeg 则进一步将CLIP拓展至半监督的三维医学分割任务中。然而,VCLIPSeg仅简单地复制文本信息以匹配三维数据的维度,这与CLIP原本面向二维训练的范式并不契合。更为关键的是,CLIP本身缺乏可学习的参数,难以适应从二维到三维这一跨维度的操作需求。因此,如何设计一种半监督的文本-视觉模型,以更好地适应三维医学图像分割任务?
方案
为此,我们提出了一种新颖的Text-SemiSeg框架,该框架将文本信息融入到半监督的三维医学图像分割中。具体而言,我们提出了文本增强的多平面表示(TMR)策略,充分利用CLIP模型在大量二维图像上预训练所具备的文本与视觉对齐能力,从而强化视觉特征的语义表达。此外,我们还设计了一个类别感知的语义对齐模块(CSA),通过将视觉嵌入与文本特征进行对齐,进一步提升模型对类别语义的敏感度。为进一步缓解半监督任务中常见于标注数据与未标注数据之间的分布差异问题,我们创新性地提出了动态认知增强模块(DCA)。这一方法有效缩小了两类数据间的分布差距,显著提升了模型的鲁棒性。
我们的主要贡献如下:
- 提出了一种新颖的框架,更适合将CLIP应用于3D半监督医学分割场景,且该框架还可推广至其他半监督网络。
- 提出了TMR和CSA方法,以充分利用文本线索全面增强视觉特征。
- 设计了DCA策略,有效缩小了有标签数据与无标签数据之间的分布差异。
- 在三个3D医学数据集上开展的大量实验表明,我们的模型性能优于当前最先进的半监督方法。
在半监督设定下,数据集包含一个带标签的子集 DL={(xil,yil)}i=1Nl\mathcal{D}^{L}=\{(x_{i}^{l},y_{i}^{l})\}_{i=1}^{N_{l}}DL={(xil,yil)}i=1Nl 和一个不带标签的子集 DU={xiu}i=N+1Nl+Nu\mathcal{D}^{U}=\{x_{i}^{u}\}_{i=N+1}^{N_{l}+N_{u}}DU={xiu}i=N+1Nl+Nu,其中 Nl≪NuN_{l}\ll N_{u}Nl≪Nu。xi∈RH×W×Dx_{i}\in\mathbb{R}^{H\times W\times D}xi∈RH×W×D 代表输入体数据,yi∈{0,1}H×W×Dy_{i}\in\{0,1\}^{H\times W\times D}yi∈{0,1}H×W×D 是对应的真实标注图。
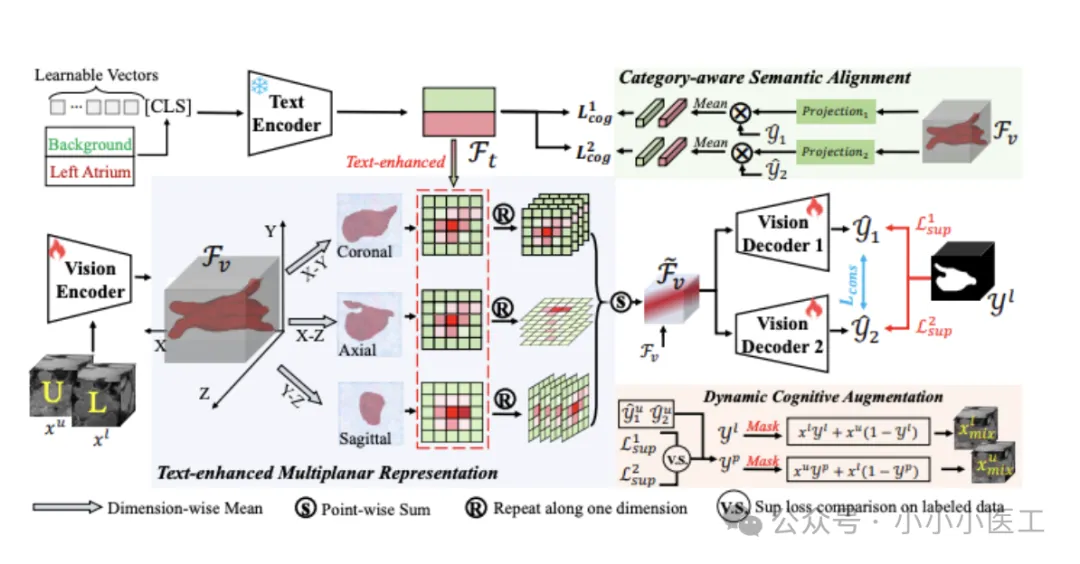
图1展示了我们的Text-SemiSeg框架架构。具体来说,输入体数据 {xil,xiu}\{x_{i}^{l},x_{i}^{u}\}{xil,xiu} 被送入编码器以获得特征嵌入。同时,类别文本以可学习的方式被融入,生成文本特征 Ft∈RK×C\mathcal{F}_{t}\in\mathbb{R}^{K\times C}Ft∈RK×C,其中 KKK 和 CCC 分别代表类别数和通道数。
在TMR模块中,为了与CLIP训练范式对齐,我们从不同平面提取特征嵌入,生成三个二维特征。接着,我们通过融入文本信息来增强每个视角的视觉特征。随后,增强后的特征嵌入被送入两个解码器进行一致性学习。
在CSA模块中,我们利用文本特征与视觉特征的MSE正则化约束,促进文本和视觉特征在表示上的对齐。
最后,我们引入DCA模块,通过混合标注数据与未标注数据的前景区域,动态缩小两者分布差异,增强模型对未标注数据的泛化能力。
效果
- TMR:文本增强多平面表示模块,通过将3D特征分解为三个2D平面特征并与文本特征交互,解决CLIP模型在3D场景中的适配问题,实现跨模态语义增强。
- CSA:类别感知语义对齐模块,通过文本特征与视觉特征的MSE正则化约束,确保模型对不同类别的语义理解一致性,提升分割精度。
- DCA:动态认知增强模块,通过混合标注数据与未标注数据的前景区域,动态缩小两者分布差异,增强模型对未标注数据的泛化能力。
实验结果表明,DCA模块的效果最为显著: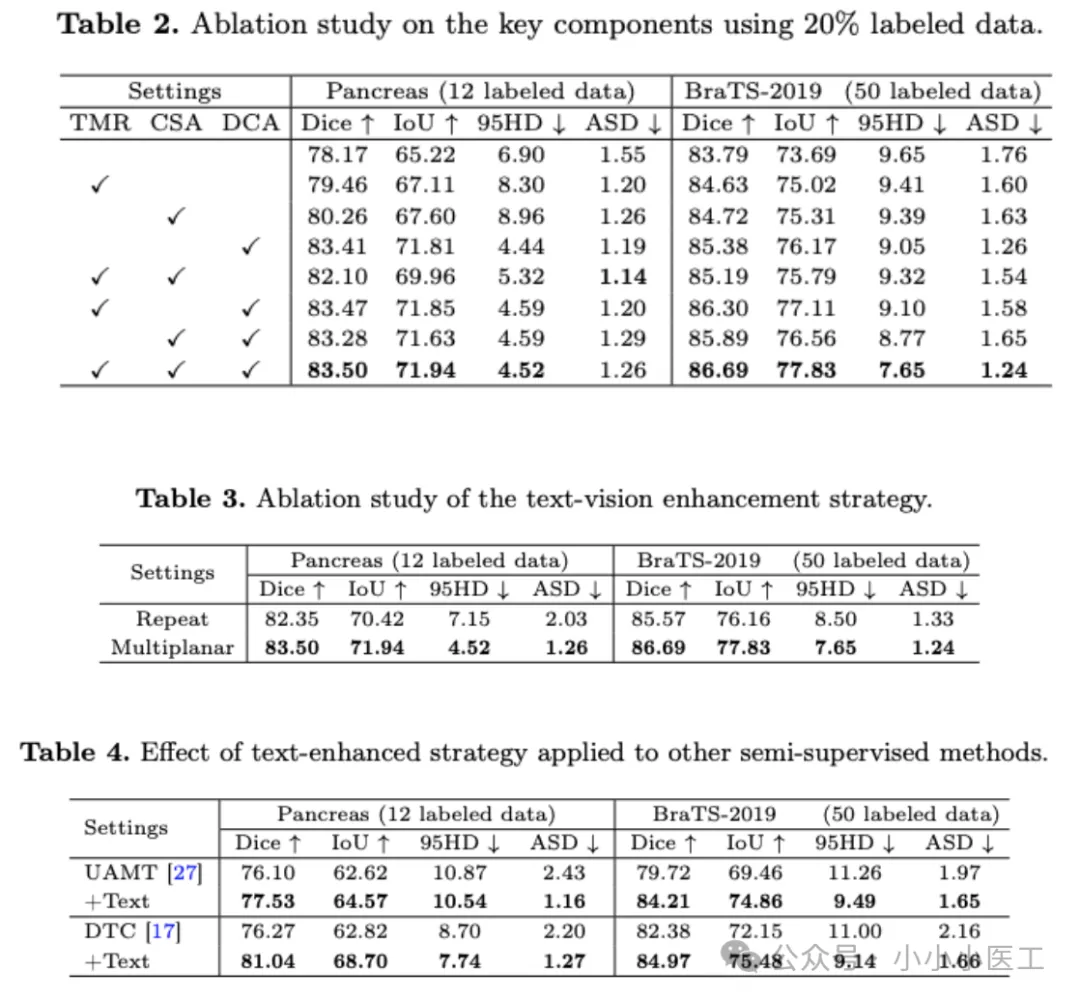
多平面策略的效果
为证明采用多平面策略的有效性,我们将其与VClipSeg所采用的方法进行对比,后者通过复制文本特征以匹配视觉特征的维度。如表3所示,在胰腺数据集和BraTS数据集上,Dice系数分别从82.35%和85.57%提升至83.50%和86.69%。多平面策略具有以下优势:
- 更符合CLIP的训练范式;
- 仅需少量参数即可实现二维平面特征的全局文本-视觉增强。
公平性讨论
目前视觉语言模型在3D场景中的探索仍相当有限。虽然实验中的部分对比方法未依赖文本,但Text-SemiSeg的推理成本与其他半监督方法相当。本工作的核心重点在于探索如何更好地将视觉语言模型应用于下游任务。
表4展示了将文本增强策略融入其他半监督方法后的结果(同时排除DCA等其他策略)。结果明确表明,我们的文本增强策略能有效提升不同方法的分割精度。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)