【Agent零基础入门课程】手搓AI智能体:30行代码带你玩转ReAct、Plan-and-Solve与Reflection
看完这三段代码,是不是觉得Agent也没那么神秘?ReAct:适合需要实时探索、调用外部工具的动态任务。:适合步骤清晰、逻辑复杂的长任务。Reflection:适合对输出质量要求极高的创作型任务。真正的高手,往往不局限于某一种范式,而是根据业务场景,将它们像乐高一样组合起来。现在,你已经掌握了乐高的基础积木,接下来能搭出什么摩天大楼,就看你的想象力了!觉得有帮助?
本文目录标题
【Agent零基础入门课程】手搓AI智能体:30行代码带你玩转ReAct、Plan-and-Solve与Reflection
本文系Datawhale 11月组队学习的学习笔记,笔记内容参考自Datawhale组队学习——Agent零基础入门课程
引言
现在的AI圈子,张口闭口就是Agent(智能体)。市面上有LangChain、AutoGPT这些现成的框架,就像预制菜一样方便。但作为一个有追求的开发者,你不想知道后厨到底是怎么炒菜的吗?
如果不理解底层的“思维范式”,调包不仅容易报错,还很难优化。今天,咱们就抛开繁重的框架,从零开始(From Scratch),用最纯粹的Python代码复现AI智能体的三种核心流派。
相信我,理解了这三种模式,你对LLM的掌控力将直接跃升一个台阶。
一、 准备工作:大脑与双手
在开始之前,我们需要两个基础组件,具体也可参考前文【Agent零基础入门课程】解构未来:亲手编写你的第一个AI智能体,但这不是我们此次的重点:
- 大脑(LLM):负责思考。这里我们假设你有一个简单的
get_completion(prompt)函数。 - 双手(Tools):负责干活。比如一个简单的搜索工具。
# 模拟一个简单的LLM调用
def get_completion(prompt):
# 这里接入你的OpenAI/DeepSeek/Yi API
return client.chat.completions.create(...)
# 模拟一个工具
def search(query):
return f"搜索结果:{query} 的最新相关信息..."
搞定基础,咱们直接进入正题。
二、 ReAct范式:边想边做的“行动派”
ReAct (Reasoning + Acting) 是目前最经典的智能体模式。它的逻辑很像人类解决陌生问题:思考 -> 行动 -> 观察 -> 再思考。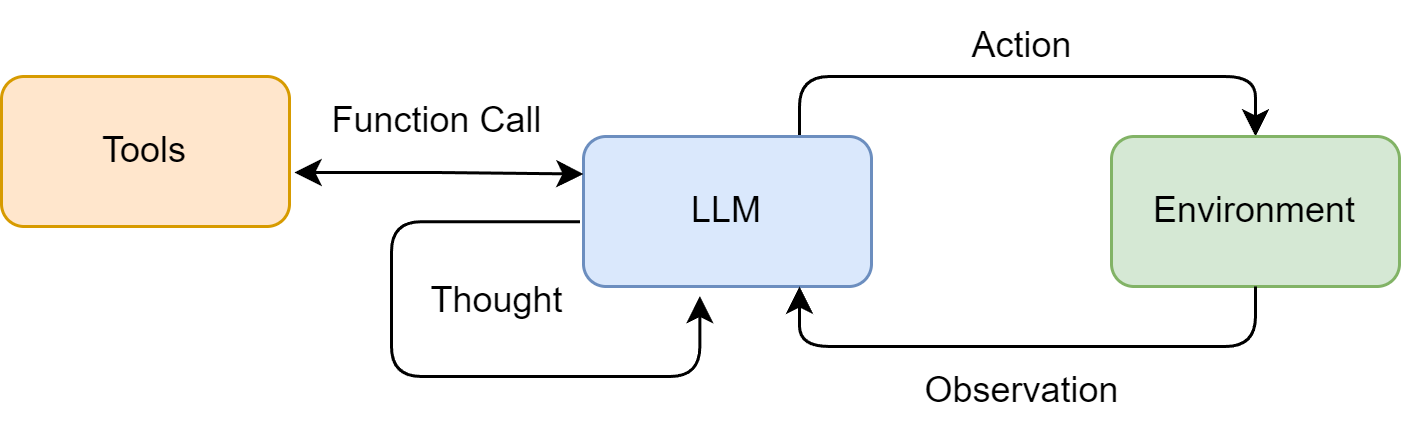
图片来自Hello-Agents
核心Prompt设计
ReAct的灵魂在于Prompt,你必须教会它“按格式说话”:
REACT_PROMPT = """
尽你所能回答以下问题。你可以使用以下工具:
[Search]: 用于搜索未知信息
请严格遵循以下格式:
Question: 需要回答的问题
Thought: 你现在的思考过程
Action: [Search]
Action Input: 搜索的关键词
Observation: 工具返回的结果
... (重复 Thought/Action/Observation)
Final Answer: 最终答案
"""
它不是一次性把事做完,而是像走迷宫一样,一步步试探。
核心代码逻辑
这就是ReAct的“引擎”部分,一个简单的while循环就能实现:
def react_agent(question):
prompt = REACT_PROMPT + f"\nQuestion: {question}"
while True:
# 1. 让LLM思考并决定行动
response = get_completion(prompt)
# 2. 如果LLM决定结束,直接返回
if "Final Answer:" in response:
return response.split("Final Answer:")[-1]
# 3. 解析LLM想调用的工具和参数
action, action_input = parse_action(response) # 简单的正则提取
# 4. 执行工具(Hands)
observation = search(action_input)
# 5. 将执行结果反馈给LLM(闭环关键!)
prompt += f"\n{response}\nObservation: {observation}"
点评: ReAct最强的地方在于容错。如果第一步搜错了,LLM看到Observation不对,会在下一轮Thought里自我纠正。
三、 Plan-and-Solve范式:运筹帷幄的“战略家”
ReAct虽然灵活,但在处理复杂庞大的任务时容易“迷路”。这时候就需要 Plan-and-Solve(计划与执行)范式。
它的逻辑是:先把大象装冰箱分几步,列好清单,然后照单全收。 这种模式非常适合写代码或长逻辑推理。
图片来自Hello-Agents
核心代码逻辑
这里我们将任务拆解为两个LLM角色:Planner(规划师) 和 Solver(执行者)。
def plan_and_solve_agent(question):
# 第一步:规划 (Planner)
plan_prompt = f"""
请为解决以下问题制定一个详细的步骤计划,不要执行,只列计划:
问题:{question}
"""
plan = get_completion(plan_prompt)
print(f"制定计划:\n{plan}")
# 第二步:执行 (Solver)
solve_prompt = f"""
请根据以下计划解决问题:
问题:{question}
计划:
{plan}
请逐步执行并给出最终结论。
"""
result = get_completion(solve_prompt)
return result
点评: 这种模式虽然牺牲了灵活性(一旦计划错了很难回头),但在处理数学题或生成长篇报告时,稳定性极高,不容易发生逻辑跳跃。
四、 Reflection范式:吾日三省吾身的“完美主义者”
如果你想让AI写出高质量的代码或文章,单次生成往往不够。Reflection(反思) 范式引入了“自我批评”机制。
它就像一个严格的编辑,不断地审视初稿,提出修改意见。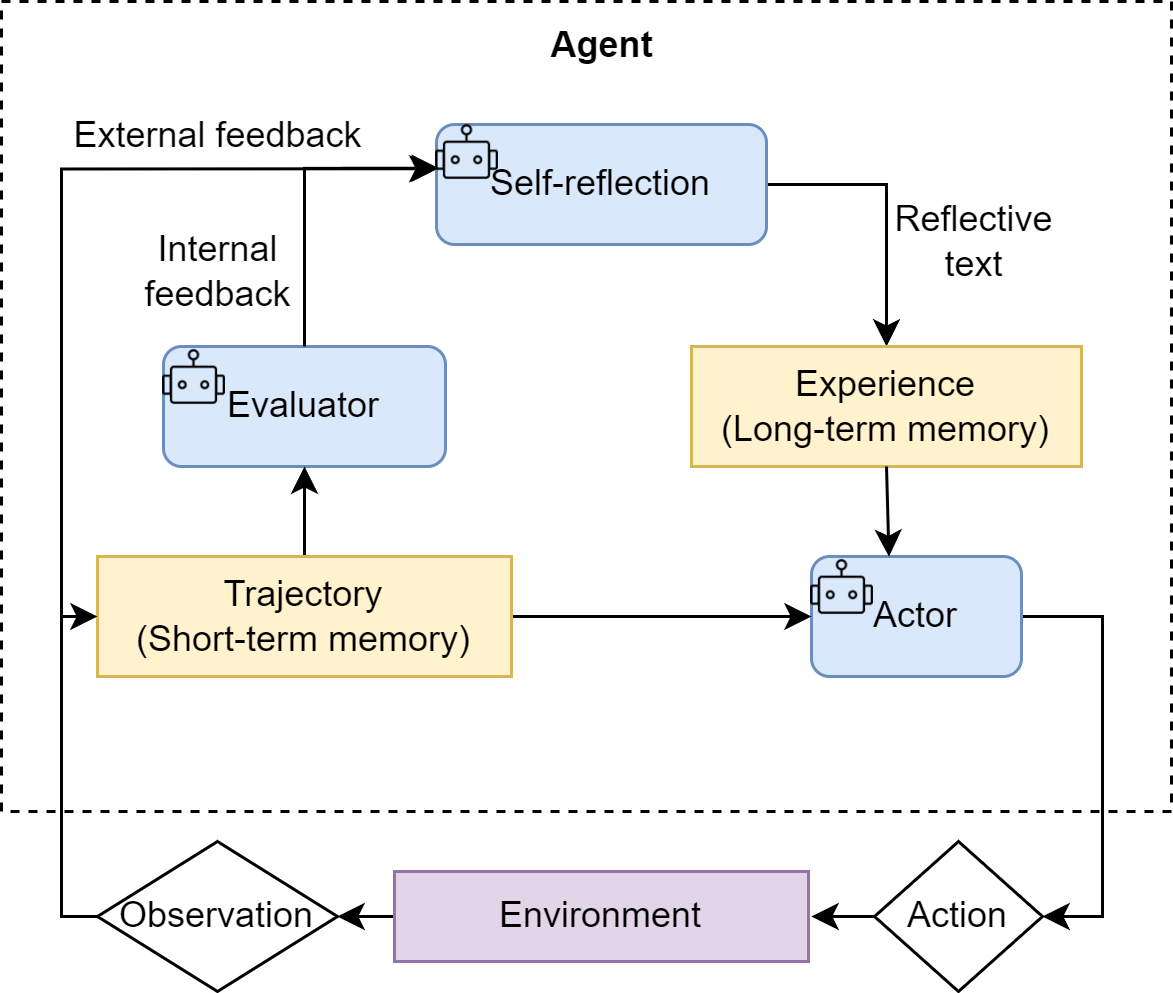
图片来自Hello-Agents
核心代码逻辑
这是一个 生成 -> 评价 -> 修正 的循环:
def reflection_agent(task):
# 1. 初稿生成
draft = get_completion(f"请完成任务:{task}")
# 循环优化(例如优化2轮)
for i in range(2):
# 2. 自我反思 (Reflector)
reflection = get_completion(f"""
请检查以下内容的错误、漏洞或改进空间:
{draft}
""")
# 3. 依据反思进行修正 (Improver)
draft = get_completion(f"""
原始内容:{draft}
改进建议:{reflection}
请根据建议重写内容,使其更加完美。
""")
return draft
点评: 很多时候,GPT-4之所以比GPT-3.5强,不仅仅是因为参数大,更是因为在复杂的Agent工作流中,加入了类似的Scaling Test-Time Compute(推理时计算)机制。多思考几轮,效果自然好。
总结
看完这三段代码,是不是觉得Agent也没那么神秘?
- ReAct:适合需要实时探索、调用外部工具的动态任务。
- Plan-and-Solve:适合步骤清晰、逻辑复杂的长任务。
- Reflection:适合对输出质量要求极高的创作型任务。
真正的高手,往往不局限于某一种范式,而是根据业务场景,将它们像乐高一样组合起来。现在,你已经掌握了乐高的基础积木,接下来能搭出什么摩天大楼,就看你的想象力了!
觉得有帮助?点个赞收藏一下,下次写Agent卡壳时,随时拿出来翻翻!
附录:可完整运行的 Python 示例代码
为了方便你亲手实践,这里提供了包含所有依赖和辅助函数的完整代码。
准备工作:
- 安装 OpenAI Python 库:
pip install openai - 获取你的 API Key (来自 OpenAI或其他服务商)。
重要: 将你的 API Key 设置为环境变量 OPENAI_API_KEY,不要硬编码在代码中。
# 完整示例代码 (full_agents_example.py)
import os
import re
from openai import OpenAI
# --- 1. 基础设置:LLM客户端 ---
# 建议从环境变量加载 API Key
# Mac/Linux: export OPENAI_API_KEY='your_key_here'
# Windows: set OPENAI_API_KEY='your_key_here'
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("请设置 OPENAI_API_KEY 环境变量")
client = OpenAI(api_key=api_key)
def get_completion(prompt, model="gpt-3.5-turbo"):
"""一个简单的LLM调用函数"""
try:
completion = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
return completion.choices[0].message.content
except Exception as e:
return f"API 调用失败: {e}"
# --- 2. 工具定义 & 辅助函数 ---
def search(query: str) -> str:
"""一个模拟的搜索工具"""
print(f"--- 调用搜索工具,关键词: {query} ---")
# 在真实场景中,这里会接入Google Search API等
return f"关于 '{query}' 的搜索结果:这是一个模拟的搜索返回,说明了最新进展和相关信息。"
def parse_action(text: str) -> tuple[str, str]:
"""从LLM的输出中解析出Action和Action Input"""
match = re.search(r"Action:.*?\[(.*?)\]\nAction Input: (.*)", text, re.DOTALL)
if match:
action = match.group(1).strip()
action_input = match.group(2).strip()
return action, action_input
return None, None
# --- 3. Agent 核心实现 ---
# 3.1 ReAct Agent
REACT_PROMPT = """
尽你所能回答以下问题。你可以使用以下工具:
[Search]: 用于搜索未知信息
请严格遵循以下格式:
Question: 需要回答的问题
Thought: 你现在的思考过程
Action: [Search]
Action Input: 搜索的关键词
Observation: 工具返回的结果
... (重复 Thought/Action/Observation)
Thought: 我现在知道了最终答案
Final Answer: 最终答案
"""
def react_agent(question, max_steps=5):
prompt = REACT_PROMPT + f"\nQuestion: {question}"
for _ in range(max_steps):
print(f"--- 当前Prompt ---\n{prompt}\n")
response_text = get_completion(prompt)
print(f"--- LLM响应 ---\n{response_text}\n")
if "Final Answer:" in response_text:
return response_text.split("Final Answer:")[-1].strip()
action, action_input = parse_action(response_text)
if action and action_input:
if action.lower() == "search":
observation = search(action_input)
prompt += f"\n{response_text}\nObservation: {observation}"
else:
prompt += f"\nObservation: 未知工具 '{action}'"
else:
# 如果LLM没有按格式输出,将它的回复作为下一步的思考材料
prompt += f"\nThought: 我似乎没有正确使用工具,我需要重新思考。我的上一条回复是 '{response_text}'"
return "Agent 未能在限定步数内找到答案。"
# 3.2 Plan-and-Solve Agent
def plan_and_solve_agent(question):
# 规划
plan_prompt = f"请为解决以下问题制定一个详细的步骤计划,不要执行,只列计划:\n问题:{question}"
plan = get_completion(plan_prompt)
print(f"--- 制定计划 ---\n{plan}\n")
# 执行
solve_prompt = f"请根据以下计划解决问题:\n问题:{question}\n\n计划:\n{plan}\n\n请逐步执行并给出最终结论。"
result = get_completion(solve_prompt)
return result
# 3.3 Reflection Agent
def reflection_agent(task, max_iterations=2):
# 初稿
draft = get_completion(f"请完成任务:{task}")
print(f"--- 初稿 ---\n{draft}\n")
for i in range(max_iterations):
print(f"--- 第 {i+1} 轮反思 ---")
# 反思
reflection = get_completion(f"请检查以下内容的错误、漏洞或改进空间,并给出具体的修改建议:\n\n{draft}")
print(f"反思意见:\n{reflection}\n")
# 修正
draft = get_completion(f"原始内容:\n{draft}\n\n改进建议:\n{reflection}\n\n请根据建议重写内容,使其更加完美。")
print(f"--- 第 {i+1} 轮修订稿 ---\n{draft}\n")
return draft
# --- 4. 主函数:运行示例 ---
if __name__ == "__main__":
print("="*50)
print("### 1. 测试 ReAct Agent ###")
react_question = "英伟达最新发布的AI芯片是什么型号?"
react_result = react_agent(react_question)
print(f"\n>>> ReAct Agent 最终答案:\n{react_result}")
print("="*50)
print("\n### 2. 测试 Plan-and-Solve Agent ###")
ps_question = "一个水果店周一卖了15个苹果,周二销量是周一的两倍,周三比周二少卖了5个。三天一共卖了多少个苹果?"
ps_result = plan_and_solve_agent(ps_question)
print(f"\n>>> Plan-and-Solve Agent 最终答案:\n{ps_result}")
print("="*50)
print("\n### 3. 测试 Reflection Agent ###")
reflection_task = "写一个Python函数,用于计算斐波那契数列的第n项,要求考虑效率问题。"
reflection_result = reflection_agent(reflection_task, max_iterations=1) # 迭代1次做演示
print(f"\n>>> Reflection Agent 最终答案:\n{reflection_result}")
print("="*50)
```

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)