LLM 幻觉现象及 RAG 解决方案
RAG(检索增强生成)结合了外部知识检索与大语言模型生成能力,有效解决LLM的幻觉、知识局限性等问题。当用户提问时,系统先检索相关文档片段作为上下文输入LLM,再生成回答,适用于客服、法律咨询等场景。典型流程包括:提问→向量检索→拼接Prompt(指令+上下文+问题)→LLM生成回答。这种方法既保留了LLM的表达能力,又通过外部知识增强了回答的准确性,未来可与Agent结合实现更智能的AI助理。
1. RAG 简介
RAG, 检索增强生成 (Retrieval-Augmented Generation).
将 外部知识检索 与 LLM 生成 结合起来。当用户提问时,系统先从一个外部知识库中检索相关文档片段,然后将这些片段作为“ 上下文” 输入给 LLM,再回答。
应用场景有
- 企业智能客服(基于产品手册、FAQ)
- 法律/医疗咨询助手(基于法规条文、临床指南)
- 内部知识库问答系统
2. LLM 的幻觉等局限性
LLM 的局限性:
- 幻觉(Hallucination):一些回答看似合理但有事实性错误。
- 缺乏新知识: 如 GPT-4 知识截止于 2023 年,无法获取之后的新信息。
- 无法访问私有数据:比如想给些例子作 few-shot, 能检索专有样例会更好.
这些即 RAG 的必要性.
其中 幻觉 (hallucination) 问题比较重要, 即回答中有编造成分或错误.
- 例子: 比如问 “tensorflow 1.12 版本有 xxx 这个api 么”, 模型回答 “有”, 其实没有.
- 原因
- 训练语料质量低, 本身有错误答案存在.
- LLM 的训练并不关注 “事实是否正确”, 自然不能保证生成答案一定符合事实.
- 推断期间引入错误,
3. RAG 方案
LLM 有表达力,但不可信;单纯查数据库,又太死板,无法理解自然语言;RAG 恰好填补了这道鸿沟。
步骤为:
用户提问(Query)
检索:用向量搜索 / 关键词搜索,从知识库里找到 Top-K 条相关内容(Chunks)
合成 Prompt:把原有系统提示 + 用户输入 + 检索到的知识拼成一个新的输入
送给 LLM 输出答案
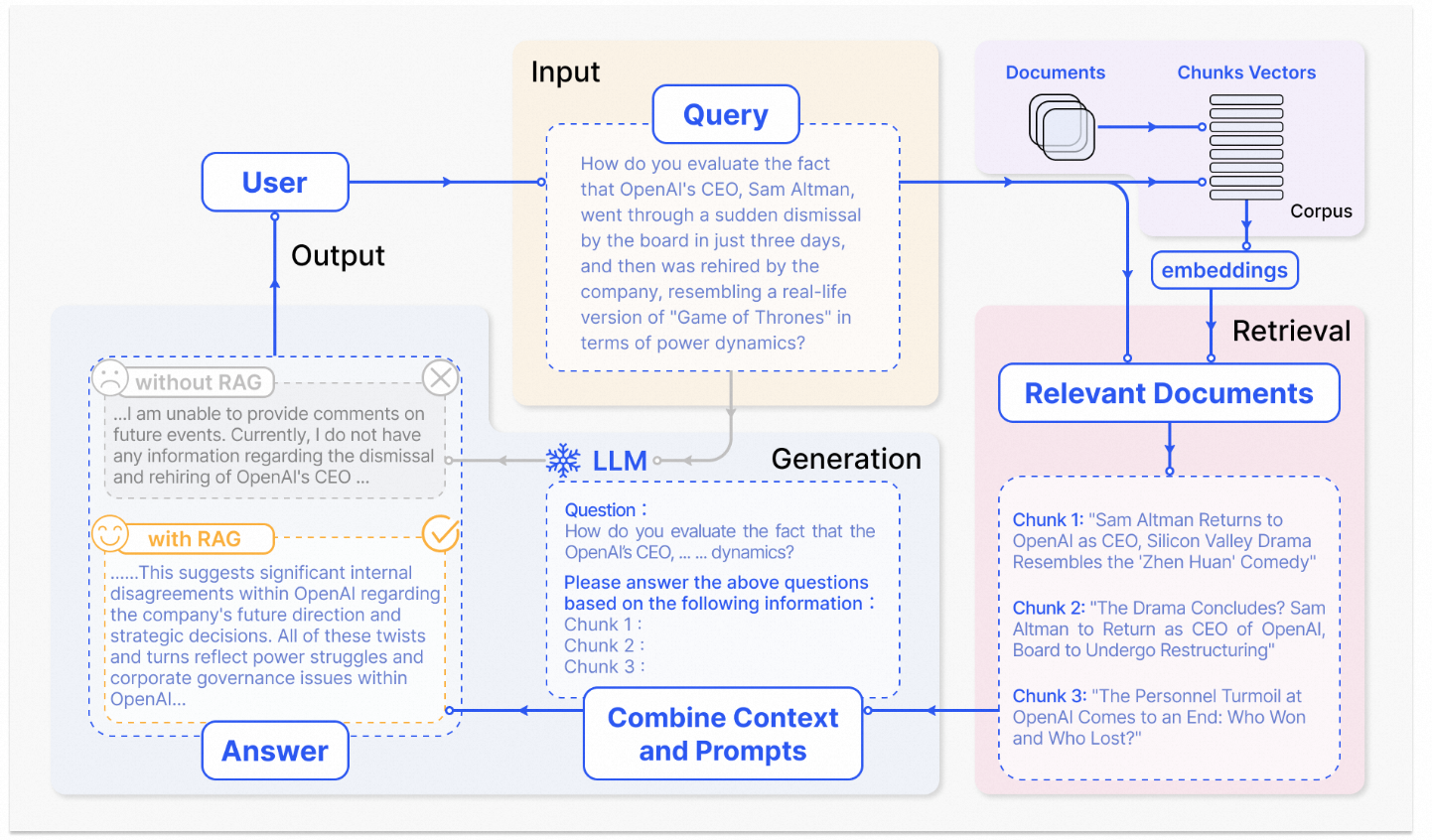
流程简介:将文本分块,然后使用一些 Transformer Encoder 模型将这些块嵌入到向量中,将所有向量放入索引中,最后创建一个 LLM 提示,告诉模型根据我们在搜索步骤中找到的上下文回答用户的查询。
未来趋势:与 Agent 结合:RAG + LLM + 工具调用 = 真正的“AI 助理”
3.1 索引构建
[原始文档]
↓
📄 分块(Chunking) → 将大文档切分为小段落(如每段 256 token)
↓
🧠 向量化(Embedding) → 用嵌入模型将每个文本块转为向量(vector)
↓
🗄️ 存入向量数据库(Vector DB) → 建立可搜索的索引
分块 Text Chunking
最简单的是固定长度分块. 推荐使用 LangChain 中的 RecursiveCharacterTextSplitter,支持智能断句。
向量化(Embedding)
使用预训练的语言模型将文本转换为高维向量(通常是 384~1024 维),使得语义相似的文本在向量空间中距离更近。
比如 “苹果公司发布了新 iPhone” 和 “Apple 发布了新款手机” 虽然字面不同,但在向量空间中会很接近。
向量数据库(Vector Database)
存储所有文本块的向量,并支持高效的近似最近邻搜索(Approximate Nearest Neighbor, ANN)。
常见的有 Chroma, FAISS 等.
3.2 索引查询
🔍 用户提问 → 同样用相同模型向量化问题
↓
📏 相似度匹配 → 在向量空间中找最近邻(k-NN)
↓
✅ 返回 top-k 最相关文本片段 → 输入给 LLM 生成答案
相似匹配通常用 余弦相似度.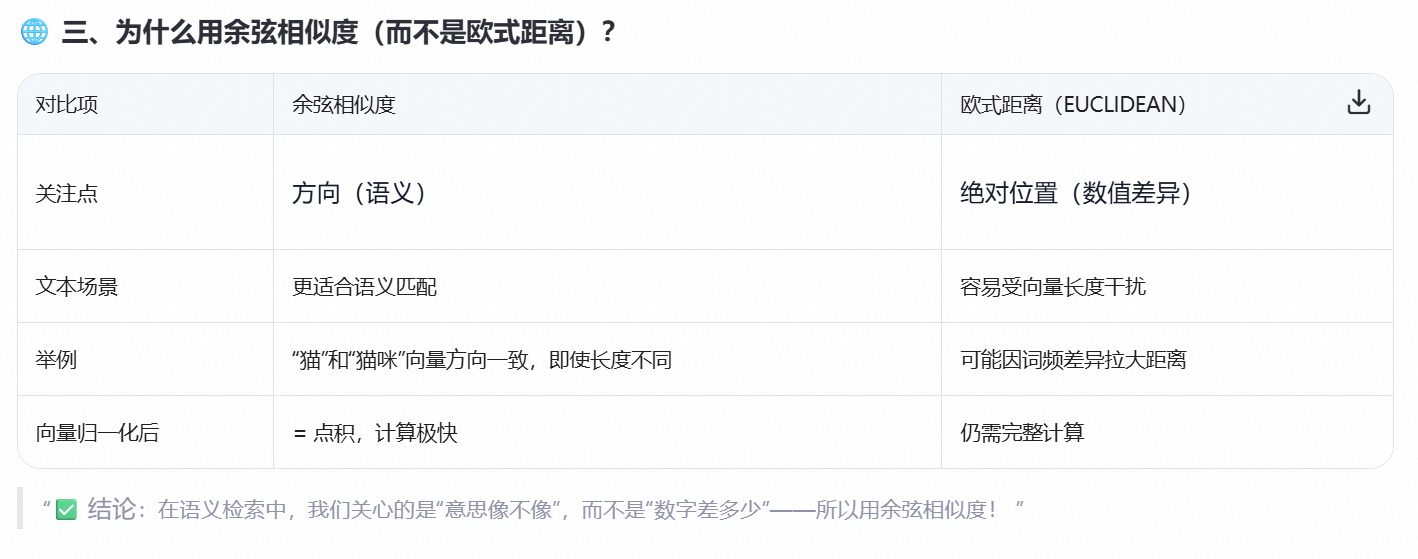
4. 检索结果 回写 prompt
Prompt = 指令 + 上下文(检索结果)+ 问题
一个典型的 RAG 增强后的 Prompt 结构如下:
【系统指令】
你是一个智能助手。请根据以下提供的参考资料回答问题。如果信息不足以回答,请说“无法确定”。
【参考资料】
1. {检索到的文本片段1}
2. {检索到的文本片段2}
3. {检索到的文本片段3}
【问题】
{用户提问}
【回答】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)