Meta大一统语音识别新作omnilingual-asr能撼动OpenAI的Whisper吗?一手部署实测
Meta近日开源了其全新的语音识别模型Omnilingual ASR,该模型在语言支持范围上实现了重大突破,能够识别超过1600种语言,远超OpenAI Whisper等现有模型。
前两天,Meta开源了全新的语音识别(ASR)模型omnilingual-asr(后面简称omni),亮点是支持1600多种语言!甚至包括粤语、闽南语等中国方言。而Whisper-V3才支持129种语言。
在使用语音进行人机交互时,第一步是将语音转换为文字,ASR可以说是人机交互的接口。正好最近在调研整合这方面的一些东西,就部署比较了下Meta的omni,OpenAI的Whisper以及阿里的SenseVoice。
具体的,比较了omni-CTC-small(300M),omni-LLM-small(300M),Whisper-small(244M),Whisper-large(1550M)和SenseVoice-small(234M)。其中,CTC和LLM是两种技术路径。
原文:这一次参与的作品都非常精彩。嗯,那我自己印象很深刻的也有很多部。那其中还包括了像植物学家呃,一个非常我觉得它好像回到了一种不忘初心的那种感觉。然后呃整体非常的纯粹,可是会深入人心。那整个拍摄的它的摄影的美术,我觉得非常的强。
因为传不了原始音频,要听原始音频的欢迎关注公号"下班折腾啥":

-
omni-CTC-small转录错误内容:
-
它好像回到->他好像回到
-
不忘初心->不望出心
-
然后呃->然后吧
-
整个拍摄的->整拍摄的
-
它的摄影->他的摄影
转录耗时:0.1秒
-
omni-LLM-small转录错误内容:
-
它好像回到->他好像回到
-
不忘初心->不望出心
-
整个拍摄的->整拍摄的
-
它的摄影->他的摄影
转录耗时:3.3秒
-
SenseVoice-small转录错误内容:
-
它好像回到->他好像回到
-
那整个拍摄的->那整个拍摄呃
-
它的摄影->他的摄影
转录耗时:0.6秒
Whisper-large和Whisper-small都转录成了繁体字。另外,它可能自动去除了口语中的一些无实意的字,像“那”,“嗯”,“呃”这种。
-
Whisper-small转录错误内容:
-
它好像回到->他好像回到
-
深入人心->深入人形
-
它的摄影->他的摄影
转录耗时:0.5秒
-
Whisper-large
除了“漏字”,无其他错误,转录原文如下:
這一次參與的作品都非常精采,我自己印象很深刻的也有很多部,其中還包括了像植物學家。嗯,一個非常我覺得它好像回到了一種不忘初心的那種感覺,然後整體非常的純粹,可是會深入人心。那整個拍攝,他的摄影的美术,我觉得非常的强。
转录耗时:10.4秒
原文:郭大哥被拐了24年的儿子,在公安机关的努力底下,终于跟父母团圆。首先我透过这个镜头,希望跟郭大哥说,我佩服你的坚持。
-
omni-CTC-small转录错误内容:
-
团圆->团员
转录耗时:0.06秒
-
omni-LLM-small无转录错误:
转录耗时:2.2秒
-
SenseVoice-small转录错误内容:
-
郭大哥->郭达哥
转录耗时:0.5秒
-
Whisper-small无转录错误:
转录耗时:0.6秒
-
Whisper-large转录错误内容:
-
郭大哥->郭达克
转录耗时:8.3秒
原文:祁老太爷什么也不怕,只怕庆不了八十大寿。在他的壮年,他亲眼看见八国联军怎样攻进北京城。后来,他看见了清朝的皇帝怎样退位,和接续不断的内战;一会儿九城的城门紧闭,枪声与炮声日夜不绝;一会儿城门开了,马路上又飞驰着得胜的军阀的高车大马。战争没有吓倒他,和平使他高兴。逢节他要过节,遇年他要祭祖,他是个安分守己的公民,只求消消停停的过着不至于愁吃愁穿的日子。即使赶上兵荒马乱,他也自有办法:最值得说的是他的家里老存着全家够吃三个月的粮食与咸菜。这样,即使炮弹在空中飞,兵在街上乱跑,他也会关上大门,再用装满石头的破缸顶上,便足以消灾避难。
-
omni-asr转录失败
目前仅支持40s的音频。
-
SenseVoice-small转录错误内容:
-
吓倒->吓到
-
逢节->冯杰
-
遇年->翌年
-
兵在街上乱跑->冰在街上乱跑
-
破缸顶上->破钢顶上
转录耗时:0.7秒
-
Whisper-small这里也转录成繁体,转录错误内容:
-
怎样->怎么样
-
怎样->怎么
-
日夜不绝->日也不绝
-
得胜->德胜
-
兵在街上乱跑->冰在街上乱跑
转录耗时:0.5秒
-
Whisper-large转录错误内容:
-
九城->九成
-
遇年->玉年
-
即使->及时
-
再用->在用
-
破缸顶上->破钢顶上
转录耗时:25.3秒
原文:他们说,我注定不配拥有什么,注定要背负那些沉重的枷锁,活在他们的期望里。每天都得做那些他们安排好的事,像个没有自由的傀儡,根本没法活成自己。这个世界、这些人,真的一点也不值得我去在乎。
-
omni-CTC-small转录错误内容:
-
拥有->有有
-
注定->朱定
-
枷锁->家所
-
傀儡->??来
-
值得->知得
-
在乎->在爱活
转录耗时:0.05秒
-
其他几个模型均没有转录错误
omni-LLM-small转录耗时:2.6秒
SenseVoice转录耗时:0.5秒
Whisper-small转录耗时:0.5秒
Whisper-large转录耗时:10.4秒
一般场景下的结论:
-
omni-CTC-small转录速度遥遥领先,但准确性相对偏低;
-
omni-LLM-small准确性上和SenseVoice-small和Whisper-small接近,未经优化的omni-LLM-small推理速度相对后两者较慢;
-
考虑到omni-LLM-small能识别1600多种语言,但模型大小和SenseVoice-small以及Whisper-small一样,还是很强悍的;
-
Whisper-large在一般场景下未显示出优势,小模型够用;
另外,测试发现,要实现更加精确的转录,方便的方式是:可以在后处理上接大语言模型,通过合适的prompt工程修正可能的错误。
最后,放一些官方数据供参考:
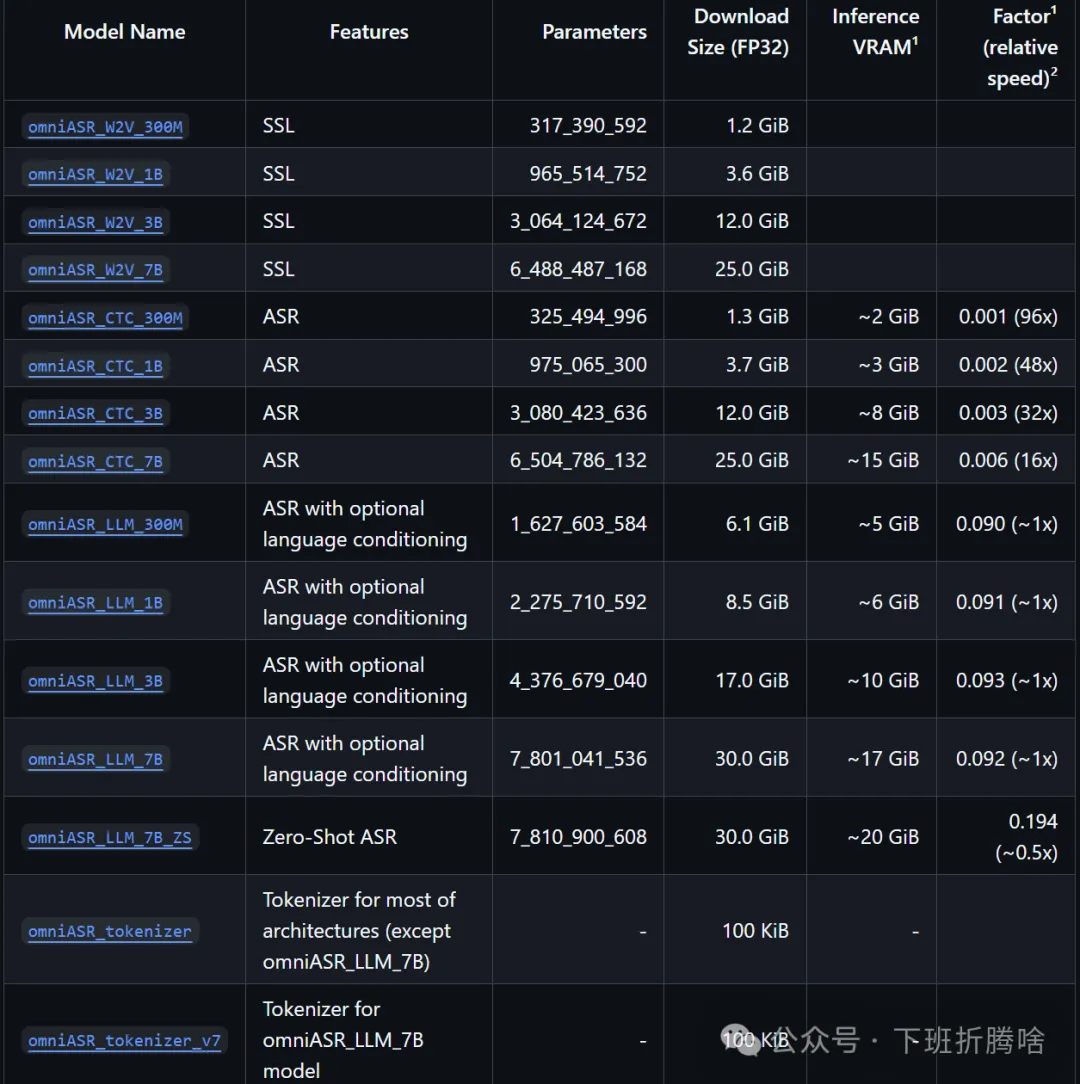
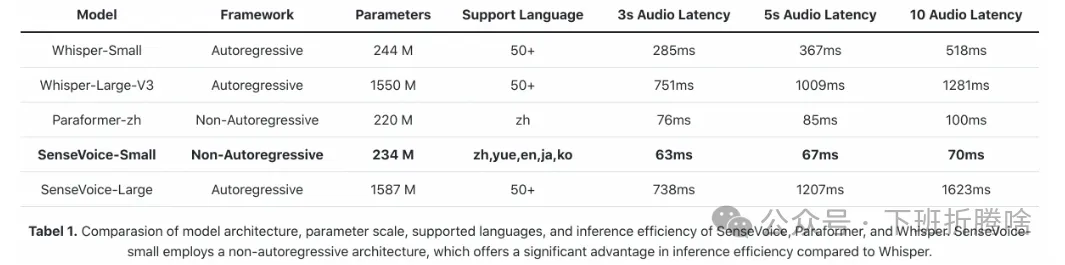

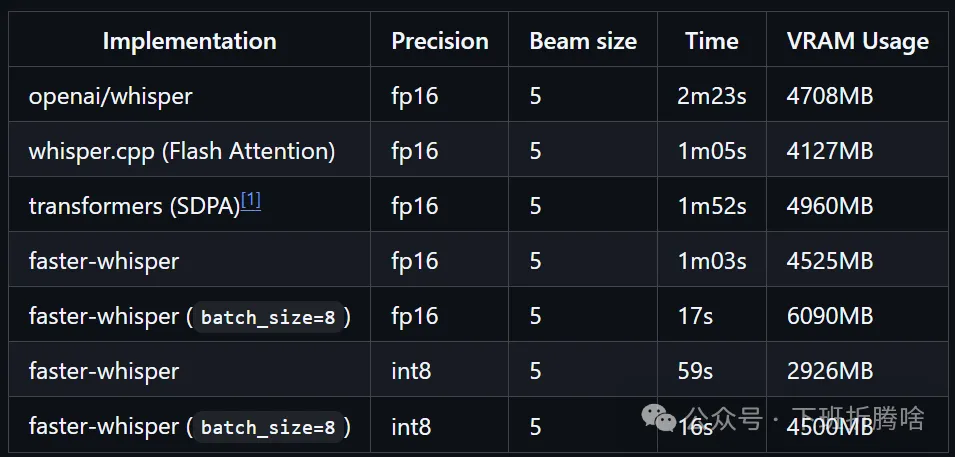
omnilingual-asr代码地址:
https://github.com/facebookresearch/omnilingual-asr
SenseVoice代码地址:
https://github.com/modelscope/FunASR
Whisper代码地址:
https://github.com/openai/whisper
faster-whisper代码地址:
https://github.com/SYSTRAN/faster-whisper

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)