小杰-大模型(seven)——RAG与Agent设计——RAG介绍
留连戏蝶时时舞,自在娇莺恰恰啼。
RAG的介绍
RAG(Retrieval-Augmented Generation,检索增强生成)是一种将检索与生成结合的自然语言处理技术,主要应用于大规模语言模型(如GPT)与信息检索系统(如搜索引擎)的集成。它的核心思想是通过检索外部知识来增强生成式模型的输出,特别是在处理需要外部知识的任务时具有显著优势。 RAG 模型通常包括两个主要组件:
●检索器(Retriever): 检索器负责从大型外部知识库中找到与当前任务或问题相关的文档。它通常使用诸如 Elasticsearch 或基于嵌入的向量搜索(例如,FAISS)来检索最相关的信息。知识库可以是任何形式的文本库,包括维基百科、公司内部文档、技术文档等。
●生成器(Generator): 生成器是基于预训练的大规模语言模型(如GPT),负责根据检索到的信息生成自然语言的回答或文本。生成器不仅依赖于模型本身的内部知识(即在训练过程中学到的知识),还结合了从检索器获得的外部信息来生成最后的答案。
1.1.1 RAG的工作流程
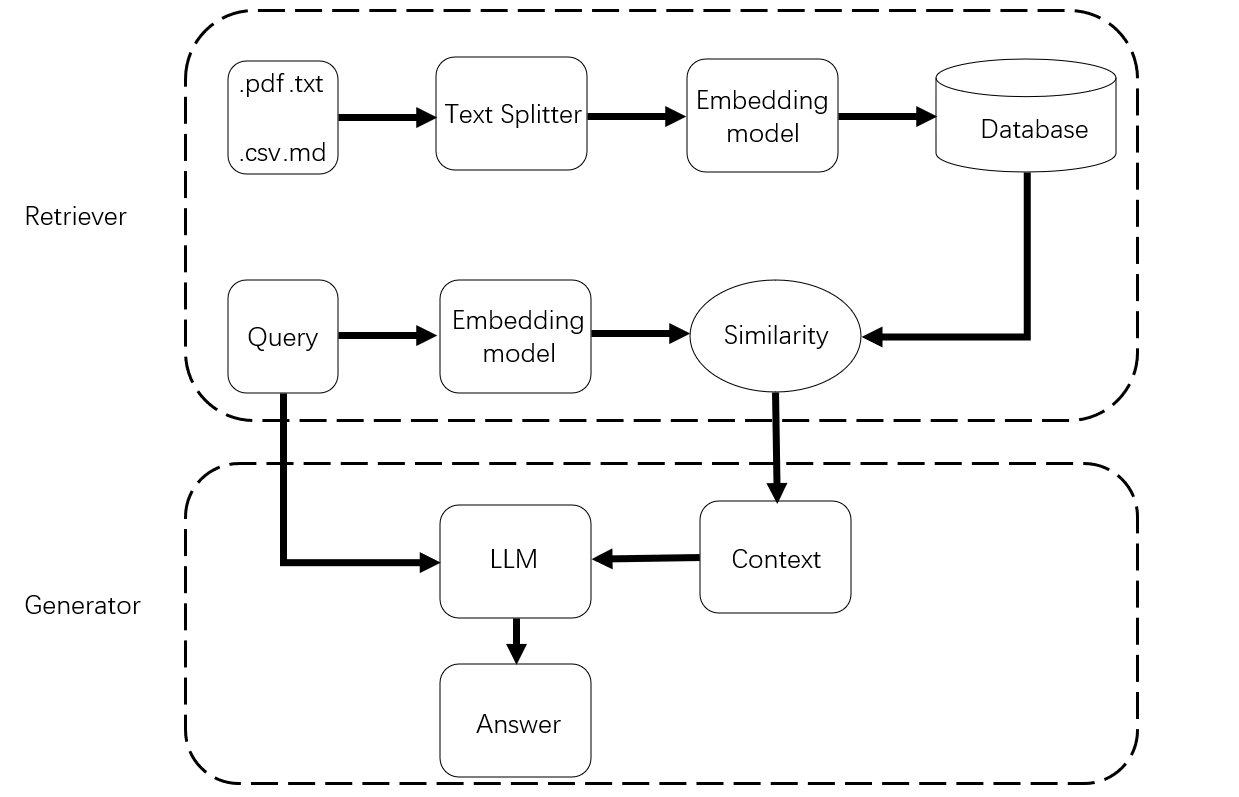
当用户输入一个问题或请求时,RAG(检索增强生成)模型会启动两部分的协同工作来生成答案:检索器负责从外部知识库中查找相关信息,生成器则基于这些信息生成最终的回答。
首先,检索器会分析用户输入的内容,通常是通过自然语言处理技术来理解问题的语义。这个阶段可以通过将用户问题转换为一个嵌入向量来实现,嵌入向量是一种高维的数值表示,它能够捕捉问题的语义特征。然后,检索器会使用这个嵌入向量在向量数据库中搜索最相似的文档片段。向量数据库中的文档数据已经提前经过分割和向量化处理,分割的目的是将整个知识库分成更小的、可管理的片段,向量化则是将每个片段转换为数值表示,便于高效检索。
检索器的搜索结果通常是一组与用户问题最相关的文档片段。这些片段可能来自多个来源,可能涵盖不同方面的内容,但都与用户问题紧密相关。检索的过程本质上是通过在高维空间中进行向量相似性搜索,从而找到这些相关片段。这个步骤通常还能依赖高效的近似最近邻(ANN)搜索算法,如 FAISS、HNSW 等,以便能够在大规模数据库中快速找到相似度高的内容。
接下来,生成器会结合检索到的文档片段来生成答案。生成器通常是基于大规模预训练的语言模型(例如 GPT 系列模型),这些模型本身已经具备一定的生成能力和知识储备。生成器不仅会依赖于其在训练过程中学到的知识,还会将从检索器获取到的外部信息整合到最终的答案中。整合过程可以是直接将检索到的文档片段输入模型作为附加上下文,生成器会将这些片段与内部的生成机制结合,确保生成的答案与问题高度相关且准确。
这种方式让生成器能够应对各种需要具体或领域知识的复杂问题。即使生成器本身在训练时并没有接触到相关的领域或细节问题,依靠检索到的外部信息,它仍然能够生成高质量的回答。例如,当用户提出一个涉及最新科技或专业术语的问题时,生成器可以利用从外部知识库中提取的相关资料,生成更符合上下文、更加专业的答案。
此外,生成器在生成过程中通常会根据上下文判断信息的重要性,将最相关的部分突出表达,而略去与当前问题不相关的内容。这使得输出的答案既简洁又具备信息深度,符合用户的预期。
这个过程的好处在于,它能够动态地扩展模型的知识库,而不局限于生成器在预训练时所学到的内容。通过实时检索和动态生成,RAG 模型能够为用户提供更精确、全面的答案,尤其适用于需要实时更新知识的任务场景。
代码实现
魔搭社区下载嵌入模型
from modelscope.hub.snapshot_download import snapshot_download
emb_model_dir = snapshot_download('AI-ModelScope/bge-large-zh-v1.5',cache_dir='models')
from langchain_huggingface import HuggingFaceEmbeddings
# 导入文本加载器
from langchain_community.document_loaders import TextLoader
# 导入递归字符文本分割器
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 导入ChatOpenAI模型
from langchain_openai import ChatOpenAI
# 使用 OpenAI API 的 ChatOpenAI 模型
chat_model = ChatOpenAI(
openai_api_key="sk-bhpqpryfyiszcqwugbmjgvvccultcovcgbfbvauxnbbfkcdo", # 替换为你的实际API密钥
base_url="https://api.siliconflow.cn/v1",
model="Qwen/Qwen2.5-7B-Instruct"
)
loader=TextLoader("黑悟空.txt",encoding='utf-8')
docs=loader.load()
# print(docs)
# 把文本分割成 200 字一组的切片,每组之间有 20 字重叠
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200,chunk_overlap=50)
# 将文档分割成多个小块
chunks = text_splitter.split_documents(docs)
# print(chunks)
# 初始化嵌入模型,使用预训练的语言模型 'bge-large-zh-v1.5'
embedding =HuggingFaceEmbeddings(model_name="./models/AI-ModelScope/bge-large-zh-v1.5")
print(embedding)
# 导入FAISS向量存储库
from langchain_community.vectorstores import FAISS
# 构建 FAISS 向量存储和对应的 retriever
# 将文本块转换为向量并存储在FAISS中(chunks你的文档数据,embedding表示使用模型转成向量)
vs = FAISS.from_documents(chunks,embedding)
# 创建一个检索器(retriever),它可以从向量数据库中获取相关文档
# 创建一个检索器用于从向量存储中获取相关信息
retriever=vs.as_retriever()
# 使用检索器来查找相关文档,并利用这些文档来生成回答:
#导入RetrievalQA链
from langchain.chains import RetrievalQA
#导入提示库
from langchain.prompts import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
# 创建一个系统消息,用于定义机器人的角色
system_message = SystemMessagePromptTemplate.from_template(
"根据以下已知信息回答用户问题。\n 已知信息{context}"
)
# 创建一个人类消息,用于接收用户的输入
human_message = HumanMessagePromptTemplate.from_template(
"用户问题:{question}"
)
# 将这些模板结合成一个完整的聊天提示
chat_prompt = ChatPromptTemplate.from_messages([
system_message,
human_message,
])
#定义链的类型参数,包括使用的提示模板
chain_type_kwargs={"prompt":chat_prompt}
# 创建一个问答链,将语言模型、检索器和提示模板结合起来
# chat_model:生成回答的语言模型,
# stuff:所有检索到的文档内容合并成一个大的文本块,然后传递给语言模型。
# retriever: 之前创建的一个 FAISS 检索器实例。它的作是从 FAISS 向量存储用中找到与用户问题最相关的文档或文本块。这些相关的文档会被传递给语言模型以生成回答。
#retriever: 通过检索获得和输入相关的上下文信息
# chain_type_kwargs 是一个字典,包含了用于配置问答链的一些关键参数。
qa=RetrievalQA.from_chain_type(llm=chat_model,
chain_type="stuff",
retriever=retriever,
chain_type_kwargs=chain_type_kwargs)
user_question='黄风大圣是谁?'
result=qa.invoke(user_question)
print("回答:", result["result"])
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)