清华大学时序算法模型Timer部署训练预测
首先,时序算法模型在市面上的分类如下图所示,transformer架构在其中的作用非常好,清华大学基于transformer创建了时间序列的模型以及大模型,不需要重新训练即可在多个领域获得很好的效果,基于先前数据推理出预测数据,再根据预测数据进行下一个预测数据的推理。同时timer可以对缺失数据值和异常数据值进行检测,也需要自己编写整套项目,这篇将编写关于预测算法的部署推理项目构建。
首先,时序算法模型在市面上的分类如下图所示,transformer架构在其中的作用非常好,清华大学基于transformer创建了时间序列的模型以及大模型,不需要重新训练即可在多个领域获得很好的效果,基于先前数据推理出预测数据,再根据预测数据进行下一个预测数据的推理。同时timer可以对缺失数据值和异常数据值进行检测,也需要自己编写整套项目,这篇将编写关于预测算法的部署推理项目构建。

在时序算法大场景下,市面上不仅有比较前沿的timer,还有比较成熟的paddlepaddle,如果有想使用paddlets的可以对比一下这两个算法架构,我后续也会出paddlets架构下的时序微调。
|
特性 |
PaddleTS |
Timer |
|
本质 |
时序建模工具库 |
时序基础模型 |
|
类比 |
PyTorch或TensorFlow |
BERT或GPT |
|
核心内容 |
提供构建和训练时序模型所需的组件、模型架构和流程 |
提供一个已经预训练好的、强大的通用模型 |
|
技术范畴 |
涵盖传统、机器学习、深度学习等多种时序模型 |
属于基于Transformer的预训练大模型 |
|
使用方式 |
你需要自己选择模型、准备数据、进行训练 |
你可以直接调用预训练模型,或少量微调以适应你的任务 |
|
目标用户 |
时序算法工程师、研究者,需要灵活定制模型 |
需要快速解决实际时序问题的开发者、希望探索时序基础模型能力的研究者 |
|
关系 |
PaddleTS这样的工具库可以用于开发像Timer这样的基础模型。 |
Timer可以作为PaddleTS工具库中的一个高级组件或预训练模型被集成和使用。 |
Timer的能力
少样本泛化以及多任务适配能力

在不同预训练数据集上的效果对比:
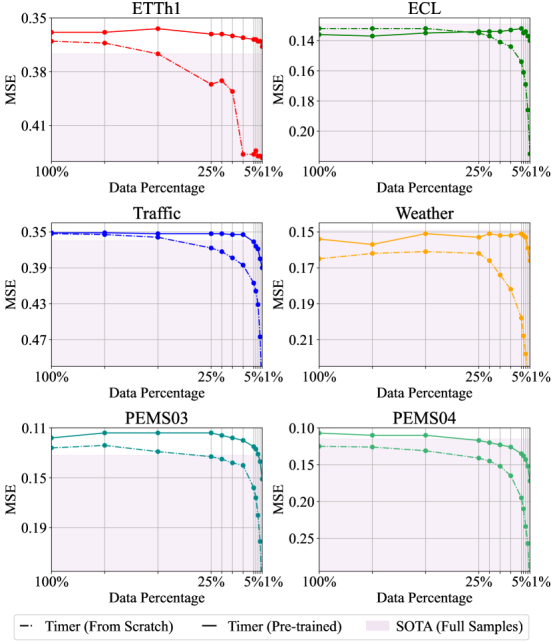
横坐标为不同数据稀缺性,实线为预训练模型,虚线为从头训练模型
项目分析知乎博主:AI论文速读 | 2024[ICML]计时器(Timer):用于大规模时间序列分析的Transformer - 知乎
环境部署
# 创建一个新的 conda 环境,指定 Python 版本(根据 Timer 要求)
conda create -n timer-env python=3.9 -y
# 激活环境
conda activate timer-env
#针对时间序列,安装适配版本的工具和库文件
pip install numpy==1.21.6 pandas==1.3.5 scikit-learn==1.0.2 torch==1.13.1 transformers==4.26.1
#下载文件
git clone https://github.com/thuml/Timer.git
创建预测训练推理项目
创建数据集,这里我使用的自己生成的虚拟数据集,油温预测csv文件,数据集生成代码:
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
import os
def create_correct_ett_format():
"""创建符合Timer项目要求的ETT数据集格式"""
# 创建数据目录
os.makedirs('./data/ETT/', exist_ok=True)
# ETT数据集的特征名称(固定7个特征)
ett_features = ['HUFL', 'HULL', 'MUFL', 'MULL', 'LUFL', 'LULL', 'OT']
def create_ettm1_data():
"""创建ETTm1数据集(15分钟频率)"""
print("创建ETTm1数据集(15分钟频率)...")
# 时间范围:2016-07-01 到 2018-06-30,每15分钟
start_date = datetime(2016, 7, 1, 0, 0, 0)
end_date = datetime(2018, 6, 30, 23, 45, 0)
dates = pd.date_range(start=start_date, end=end_date, freq='15T')
print(f"生成 {len(dates)} 个数据点...")
np.random.seed(42)
n_points = len(dates)
t = np.arange(n_points)
# 时间序列参数
daily_period = 24 * 4 # 每天96个点
weekly_period = 7 * 24 * 4 # 每周672个点
data = {'date': dates}
for i, feature in enumerate(ett_features):
# 创建具有季节性的时间序列
seasonal = (
2.0 * np.sin(2 * np.pi * t / daily_period + i * 0.5) +
1.0 * np.sin(2 * np.pi * t / weekly_period + i) +
0.5 * np.cos(2 * np.pi * t / (daily_period * 30) + i * 1.5)
)
# 趋势成分
trend = 0.002 * t + i * 0.1
# 噪声
noise = np.random.normal(0, 0.2, n_points)
# 组合所有成分
values = seasonal + trend + noise
# 对OT特征(油温)进行特殊处理
if feature == 'OT':
values = values + 25 # 温度基准
data[feature] = values
df = pd.DataFrame(data)
return df
def create_etth1_data():
"""创建ETTh1数据集(1小时频率)"""
print("创建ETTh1数据集(1小时频率)...")
# 时间范围:2016-07-01 到 2018-06-30,每小时
start_date = datetime(2016, 7, 1, 0, 0, 0)
end_date = datetime(2018, 6, 30, 23, 0, 0)
dates = pd.date_range(start=start_date, end=end_date, freq='H')
print(f"生成 {len(dates)} 个数据点...")
np.random.seed(42)
n_points = len(dates)
t = np.arange(n_points)
# 时间序列参数
daily_period = 24 # 每天24个点
weekly_period = 7 * 24 # 每周168个点
data = {'date': dates}
for i, feature in enumerate(ett_features):
seasonal = (
2.0 * np.sin(2 * np.pi * t / daily_period + i * 0.5) +
1.0 * np.sin(2 * np.pi * t / weekly_period + i) +
0.5 * np.cos(2 * np.pi * t / (daily_period * 30) + i * 1.5)
)
trend = 0.001 * t + i * 0.1
noise = np.random.normal(0, 0.2, n_points)
values = seasonal + trend + noise
if feature == 'OT':
values = values + 25
data[feature] = values
df = pd.DataFrame(data)
return df
# 创建并保存数据集
print("开始创建ETT数据集...")
ettm1_df = create_ettm1_data()
ettm1_df.to_csv('./data/ETT/ETTm1.csv', index=False)
print(f"ETTm1保存完成: {ettm1_df.shape}")
etth1_df = create_etth1_data()
etth1_df.to_csv('./data/ETT/ETTh1.csv', index=False)
print(f"ETTh1保存完成: {etth1_df.shape}")
# 验证数据格式
print("\n数据格式验证:")
print("ETTm1前3行:")
print(ettm1_df.head(3))
print(f"\nETTm1列名: {list(ettm1_df.columns)}")
print(f"ETTm1日期范围: {ettm1_df['date'].min()} 到 {ettm1_df['date'].max()}")
return True
if __name__ == "__main__":
success = create_correct_ett_format()
if success:
print("\n🎉 ETT数据集创建成功!格式符合Timer项目要求。")
else:
print("\n❌ 数据创建失败!")之后进行数据清洗:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
def data_cleaning():
"""ETTm1数据集清洗和预处理函数"""
# 检查文件是否存在
if not os.path.exists('data.csv'):
print("错误: 找不到 data.csv 文件")
print("请将ETTm1.csv文件重命名为data.csv或修改脚本中的文件名")
return None
try:
# 1. 读取数据
print("正在读取ETTm1数据文件...")
df = pd.read_csv('data.csv', parse_dates=['date'])
print("数据读取成功!")
print(f"数据形状: {df.shape}")
print("列名:", df.columns.tolist())
print("\n前5行数据:")
print(df.head())
# 2. 设置日期为索引
df.set_index('date', inplace=True)
print(f"\n时间范围: {df.index.min()} 到 {df.index.max()}")
print(f"数据频率: {pd.infer_freq(df.index)}")
# 3. 数据质量检查
print("\n=== 数据质量检查 ===")
print(f"总数据点数: {len(df)}")
print(f"缺失值统计:")
missing_stats = df.isnull().sum()
print(missing_stats)
# 4. 处理缺失值
missing_total = missing_stats.sum()
if missing_total > 0:
print(f"\n发现 {missing_total} 个缺失值,进行处理...")
# 使用前向填充处理缺失值
df = df.ffill().bfill() # 先向前填充,再向后填充
missing_after = df.isnull().sum().sum()
print(f"处理后缺失值: {missing_after}")
else:
print("没有缺失值,数据完整!")
# 5. 数据统计
print("\n=== 数据统计 ===")
print(df.describe())
# 6. 检查数据异常
print("\n=== 数据异常检查 ===")
for col in df.columns:
col_data = df[col]
print(f"{col}: 范围 [{col_data.min():.2f}, {col_data.max():.2f}], "
f"均值 {col_data.mean():.2f}, 标准差 {col_data.std():.2f}")
# 7. 保存清洗后的数据
output_file = 'cleaned_ETTm1.csv'
df.to_csv(output_file)
print(f"\n清洗后的数据已保存为: {output_file}")
# 8. 数据可视化
print("\n=== 生成数据可视化 ===")
plt.figure(figsize=(15, 10))
# 绘制所有变量的时间序列
for i, col in enumerate(df.columns, 1):
plt.subplot(3, 3, i)
plt.plot(df.index, df[col])
plt.title(f'{col} 时间序列')
plt.xlabel('日期')
plt.ylabel(col)
plt.xticks(rotation=45)
plt.grid(True)
plt.tight_layout()
plt.savefig('ETTm1_data_preview.png', dpi=300, bbox_inches='tight')
print("数据预览图已保存为: ETTm1_data_preview.png")
plt.show()
# 9. 绘制相关性热力图
plt.figure(figsize=(10, 8))
correlation_matrix = df.corr()
plt.imshow(correlation_matrix, cmap='coolwarm', aspect='auto')
plt.colorbar()
plt.xticks(range(len(df.columns)), df.columns, rotation=45)
plt.yticks(range(len(df.columns)), df.columns)
plt.title('变量相关性热力图')
# 添加相关系数值
for i in range(len(df.columns)):
for j in range(len(df.columns)):
plt.text(j, i, f'{correlation_matrix.iloc[i, j]:.2f}',
ha='center', va='center', fontsize=10)
plt.tight_layout()
plt.savefig('ETTm1_correlation.png', dpi=300, bbox_inches='tight')
print("相关性热力图已保存为: ETTm1_correlation.png")
plt.show()
return df
except Exception as e:
print(f"处理数据时出错: {e}")
import traceback
traceback.print_exc()
return None
def prepare_timer_data(df, seq_len=24, pred_len=8, test_ratio=0.2):
"""为Timer模型准备数据格式"""
print("\n=== 为Timer模型准备数据 ===")
# 确保数据按时间排序
df = df.sort_index()
# 划分训练集和测试集
split_idx = int(len(df) * (1 - test_ratio))
train_data = df.iloc[:split_idx]
test_data = df.iloc[split_idx:]
print(f"训练集: {len(train_data)} 条记录")
print(f"测试集: {len(test_data)} 条记录")
# 保存为Timer可用的格式
train_data.to_csv('ETTm1_train.csv')
test_data.to_csv('ETTm1_test.csv')
print("训练集已保存为: ETTm1_train.csv")
print("测试集已保存为: ETTm1_test.csv")
return train_data, test_data
if __name__ == "__main__":
# 执行数据清洗
cleaned_data = data_cleaning()
if cleaned_data is not None:
print("\n=== 数据清洗完成 ===")
print(f"最终数据形状: {cleaned_data.shape}")
print("\n前5行数据:")
print(cleaned_data.head())
# 为Timer模型准备数据
train_data, test_data = prepare_timer_data(cleaned_data)
print("\n数据准备完成,可以用于Timer模型训练!")
else:
print("数据清洗失败")此项目需要自行开发,我这里做的架构设置:
私有化部署请联系小企鹅(1901935655)
F:\gxhs\Timer\
│ train.py predict.py
│ cleaned_data.csv
│
└───timer
│ __init__.py
│ dataset.py
│ model.py
│ trainer.py
__init__.py文件为空
dataset.py:
import torch
from torch.utils.data import Dataset
import numpy as np
class TimeSeriesDataset(Dataset):
def __init__(self, data, seq_len=100, pred_len=1):
"""
时间序列数据集类
Args:
data: 时间序列数据 (numpy array或list)
seq_len: 输入序列长度
pred_len: 预测长度
"""
self.data = data
self.seq_len = seq_len
self.pred_len = pred_len
def __len__(self):
return len(self.data) - self.seq_len - self.pred_len + 1
def __getitem__(self, idx):
# 输入序列
x = self.data[idx:idx + self.seq_len]
# 目标序列
y = self.data[idx + self.seq_len:idx + self.seq_len + self.pred_len]
# 转换为torch tensor
x = torch.FloatTensor(x).unsqueeze(-1) # 添加特征维度
y = torch.FloatTensor(y).unsqueeze(-1)
return x, ytrainer.py:
import torch
import torch.nn as nn
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
class Trainer:
def __init__(self, model, dataloader, learning_rate=0.001, epochs=10):
"""
训练器类
Args:
model: 模型实例
dataloader: 数据加载器
learning_rate: 学习率
epochs: 训练轮数
"""
self.model = model
self.dataloader = dataloader
self.epochs = epochs
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 将模型移动到设备
self.model.to(self.device)
# 损失函数和优化器
self.criterion = nn.MSELoss()
self.optimizer = torch.optim.Adam(self.model.parameters(), lr=learning_rate)
# 训练历史
self.train_losses = []
def train(self):
"""训练模型"""
print(f"开始训练,使用设备: {self.device}")
self.model.train()
for epoch in range(self.epochs):
total_loss = 0
progress_bar = tqdm(self.dataloader, desc=f'Epoch {epoch+1}/{self.epochs}')
for batch_idx, (data, target) in enumerate(progress_bar):
# 移动数据到设备
data, target = data.to(self.device), target.to(self.device)
# 前向传播
output = self.model(data)
loss = self.criterion(output, target.squeeze(-1))
# 反向传播
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
total_loss += loss.item()
# 更新进度条
progress_bar.set_postfix({'Loss': f'{loss.item():.6f}'})
avg_loss = total_loss / len(self.dataloader)
self.train_losses.append(avg_loss)
print(f'Epoch {epoch+1}/{self.epochs}, Average Loss: {avg_loss:.6f}')
print("训练完成!")
def plot_training_loss(self):
"""绘制训练损失曲线"""
plt.figure(figsize=(10, 6))
plt.plot(self.train_losses)
plt.title('Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.grid(True)
plt.savefig('training_loss.png')
plt.show()
def save_model(self, filepath='timer_model.pth'):
"""保存模型"""
torch.save({
'model_state_dict': self.model.state_dict(),
'optimizer_state_dict': self.optimizer.state_dict(),
'train_losses': self.train_losses
}, filepath)
print(f"模型已保存到: {filepath}")
model.py:
import torch
import torch.nn as nn
class TimerModel(nn.Module):
def __init__(self, input_dim=1, hidden_dim=128, output_dim=1, num_layers=2):
"""
Timer模型 - 基于LSTM的时间序列预测模型
Args:
input_dim: 输入特征维度
hidden_dim: 隐藏层维度
output_dim: 输出维度
num_layers: LSTM层数
"""
super(TimerModel, self).__init__()
self.hidden_dim = hidden_dim
self.num_layers = num_layers
# LSTM层
self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)
# 全连接层
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
# LSTM前向传播
lstm_out, (hn, cn) = self.lstm(x)
# 取最后一个时间步的输出
out = self.fc(lstm_out[:, -1, :])
return out
之后进行微调训练,train.py:
import pandas as pd
import torch
from torch.utils.data import DataLoader
import sys
import os
# 调试信息
print("当前工作目录:", os.getcwd())
print("Python路径:")
for path in sys.path:
print(" ", path)
# 添加当前目录到Python路径
current_dir = os.path.dirname(os.path.abspath(__file__))
sys.path.append(current_dir)
# 检查timer目录
timer_path = os.path.join(current_dir, 'timer')
print("Timer目录存在:", os.path.exists(timer_path))
if os.path.exists(timer_path):
print("Timer目录内容:", os.listdir(timer_path))
# 添加timer目录到Python路径
sys.path.append(timer_path)
# 尝试导入timer模块
try:
from timer.dataset import TimeSeriesDataset
from timer.model import TimerModel
from timer.trainer import Trainer
print("成功导入timer模块")
except ImportError as e:
print(f"导入timer模块失败: {e}")
print("尝试直接导入模块...")
try:
from dataset import TimeSeriesDataset
from model import TimerModel
from trainer import Trainer
print("成功直接导入模块")
except ImportError as e2:
print(f"直接导入也失败: {e2}")
print("请检查项目结构")
exit(1)
def main():
# 检查数据文件
data_file = 'cleaned_data.csv'
if not os.path.exists(data_file):
print(f"错误: 找不到数据文件 {data_file}")
print("请先运行数据清洗脚本生成 cleaned_data.csv")
return
try:
# 加载清洗后的数据
print("正在加载数据...")
df = pd.read_csv(data_file, parse_dates=['date'])
df.set_index('date', inplace=True)
# 使用OT列作为目标变量
if 'OT' in df.columns:
data = df['OT'].values
print(f"使用OT列数据,数据长度: {len(data)}")
else:
# 如果没有OT列,使用第一列数值数据
numeric_cols = df.select_dtypes(include=[np.number]).columns
if len(numeric_cols) > 0:
data = df[numeric_cols[0]].values
print(f"使用{numeric_cols[0]}列数据,数据长度: {len(data)}")
else:
print("错误: 数据文件中没有数值列")
return
print(f"数据范围: {data.min():.2f} to {data.max():.2f}")
# 创建数据集和数据加载器
seq_len = 100
dataset = TimeSeriesDataset(data, seq_len=seq_len)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
print(f"数据集大小: {len(dataset)}")
print(f"批次数量: {len(dataloader)}")
# 初始化模型和训练器
model = TimerModel(input_dim=1, hidden_dim=128, output_dim=1, num_layers=2)
trainer = Trainer(model, dataloader, learning_rate=0.001, epochs=10)
# 开始训练
trainer.train()
# 绘制训练损失
trainer.plot_training_loss()
# 保存模型
trainer.save_model()
print("训练流程完成!")
except Exception as e:
print(f"训练过程中出错: {e}")
import traceback
traceback.print_exc()
if __name__ == "__main__":
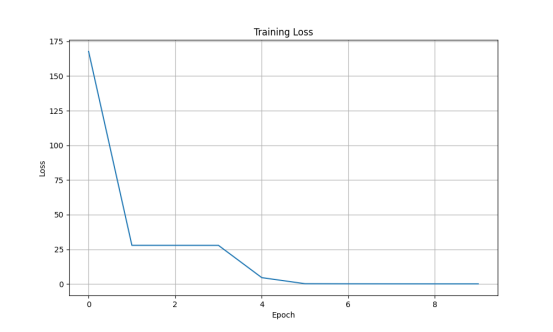
main()训练结果展示:
训练好模型之后进行预测推理测试,predict.py:
import pandas as pd
import torch
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
import sys
import os
# 添加当前目录到Python路径
current_dir = os.path.dirname(os.path.abspath(__file__))
sys.path.append(current_dir)
# 检查timer目录是否存在,如果存在则添加
timer_path = os.path.join(current_dir, 'timer')
if os.path.exists(timer_path):
sys.path.append(timer_path)
# 导入模块
try:
from dataset import TimeSeriesDataset
from model import TimerModel
print("成功导入模块")
except ImportError as e:
print(f"导入模块失败: {e}")
exit(1)
def predict():
"""进行模型预测"""
print("开始模型推理...")
# 检查数据文件
data_file = 'cleaned_data.csv'
if not os.path.exists(data_file):
print(f"错误: 找不到数据文件 {data_file}")
print("请先运行数据清洗脚本生成 cleaned_data.csv")
return
# 检查模型文件
model_file = 'timer_model.pth'
if not os.path.exists(model_file):
print(f"错误: 找不到模型文件 {model_file}")
print("请先运行训练脚本生成模型文件")
return
try:
# 加载数据
print("正在加载数据...")
df = pd.read_csv(data_file, parse_dates=['date'])
df.set_index('date', inplace=True)
# 使用OT列作为目标变量
if 'OT' in df.columns:
data = df['OT'].values
print(f"使用OT列数据,数据长度: {len(data)}")
else:
# 如果没有OT列,使用第一列数值数据
numeric_cols = df.select_dtypes(include=[np.number]).columns
if len(numeric_cols) > 0:
data = df[numeric_cols[0]].values
print(f"使用{numeric_cols[0]}列数据,数据长度: {len(data)}")
else:
print("错误: 数据文件中没有数值列")
return
print(f"数据范围: {data.min():.2f} to {data.max():.2f}")
# 创建数据集和数据加载器
seq_len = 100
dataset = TimeSeriesDataset(data, seq_len=seq_len)
dataloader = DataLoader(dataset, batch_size=32, shuffle=False)
print(f"数据集大小: {len(dataset)}")
# 加载训练好的模型
print("正在加载模型...")
model = TimerModel(input_dim=1, hidden_dim=128, output_dim=1, num_layers=2)
# 加载模型状态
checkpoint = torch.load(model_file, map_location=torch.device('cpu'))
model.load_state_dict(checkpoint['model_state_dict'])
model.eval()
print("模型加载成功!")
# 进行预测
print("开始预测...")
predictions = []
actuals = []
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(dataloader):
outputs = model(inputs)
predictions.extend(outputs.numpy().flatten())
actuals.extend(targets.numpy().flatten())
if batch_idx % 10 == 0:
print(f"已处理批次: {batch_idx}/{len(dataloader)}")
# 处理预测结果对齐问题
# 由于我们使用滑动窗口,预测结果的长度会比原始数据短
# 我们需要将预测结果对齐到正确的时间点
# 创建预测结果DataFrame
# 预测结果对应的时间点是原始数据中从seq_len开始的时间点
pred_dates = df.index[seq_len:seq_len + len(predictions)]
# 创建结果DataFrame
results_df = pd.DataFrame({
'date': pred_dates,
'actual': actuals[:len(pred_dates)],
'predicted': predictions[:len(pred_dates)]
})
# 合并原始数据
results_df.set_index('date', inplace=True)
full_results = df.join(results_df, how='left')
# 保存预测结果
output_file = 'predictions.csv'
full_results.to_csv(output_file)
print(f"预测结果已保存为: {output_file}")
# 计算评估指标
valid_results = full_results.dropna(subset=['actual', 'predicted'])
if len(valid_results) > 0:
mse = np.mean((valid_results['actual'] - valid_results['predicted'])**2)
mae = np.mean(np.abs(valid_results['actual'] - valid_results['predicted']))
rmse = np.sqrt(mse)
print(f"\n=== 预测性能评估 ===")
print(f"MSE: {mse:.6f}")
print(f"MAE: {mae:.6f}")
print(f"RMSE: {rmse:.6f}")
# 可视化预测结果
plt.figure(figsize=(15, 10))
# 绘制完整时间序列
plt.subplot(2, 1, 1)
plt.plot(full_results.index, full_results['OT'], label='实际值', alpha=0.7)
plt.plot(valid_results.index, valid_results['predicted'], label='预测值', alpha=0.8)
plt.title('时间序列预测结果')
plt.xlabel('日期')
plt.ylabel('OT值')
plt.legend()
plt.grid(True)
# 绘制预测误差
plt.subplot(2, 1, 2)
errors = valid_results['actual'] - valid_results['predicted']
plt.plot(valid_results.index, errors, label='预测误差', color='red')
plt.axhline(y=0, color='black', linestyle='--', alpha=0.5)
plt.title('预测误差')
plt.xlabel('日期')
plt.ylabel('误差')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.savefig('prediction_results.png', dpi=300, bbox_inches='tight')
print("预测结果图已保存为: prediction_results.png")
plt.show()
# 保存评估指标
metrics_df = pd.DataFrame({
'Metric': ['MSE', 'MAE', 'RMSE'],
'Value': [mse, mae, rmse]
})
metrics_df.to_csv('prediction_metrics.csv', index=False)
print("评估指标已保存为: prediction_metrics.csv")
print("\n推理完成!")
return full_results
except Exception as e:
print(f"推理过程中出错: {e}")
import traceback
traceback.print_exc()
return None
if __name__ == "__main__":
results = predict()
if results is not None:
print("\n预测结果摘要:")
print(f"总数据点: {len(results)}")
print(f"有效预测点: {len(results.dropna(subset=['predicted']))}")
print("\n前10个预测结果:")
print(results[['OT', 'actual', 'predicted']].head(10))结果展示:
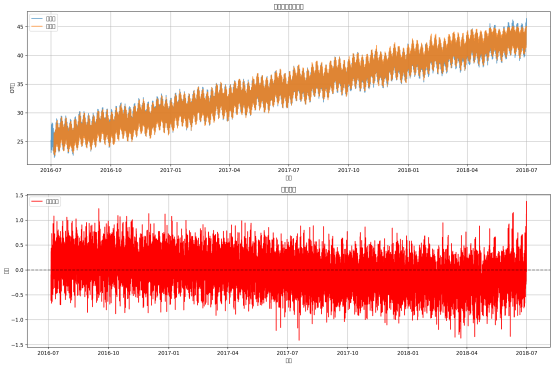
最终生成预测csv和loss文件,预训练10轮即可获得很好的结果

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)