强化学习中GRPO、PPO的介绍
模型微调可以提供全量更新、LoRA、DPO、KTO、GRPO、PPO等训练方式,开发者可以选择适合自己任务场景的训练模式并进行训练,从而实现理想的模型效果。用户需注意,DPO/KTO的数据与其它微调方式有差异,用户在选择DPO/KTO训练方式的时候,需要提前准备好相应的数据。强化学习(Reinforcement Learning, RL)是一种让智能体通过与环境交互学习最优决策策略的机器学习范式。
大模型开发平台TLM介绍
天纪大模型开发平台整合最新 AI 技术,提供模型广场、数据广场,模型微调、模型部署和模型评测等大模型开发的完整解决方案,为用户提供全套 LLMOPS 工程能力,助力业务快速基于通用模型开发出行业模型并部署服务。
模型训练简介
模型微调可以提供全量更新、LoRA、DPO、KTO、GRPO、PPO等训练方式,开发者可以选择适合自己任务场景的训练模式并进行训练,从而实现理想的模型效果。用户需注意,DPO/KTO的数据与其它微调方式有差异,用户在选择DPO/KTO训练方式的时候,需要提前准备好相应的数据。
强化学习介绍
强化学习(Reinforcement Learning, RL)是一种让智能体通过与环境交互学习最优决策策略的机器学习范式。其核心思想是:智能体在环境中执行动作,通过接收奖励信号(正/负反馈)调整行为,最终学会最大化累积奖励的策略。
与监督学习不同,强化学习无需标注数据,而是通过试错探索(Exploration)和经验利用(Exploitation)的平衡实现学习。典型框架包括策略梯度(如PPO、GRPO)、值函数方法(如Q-Learning)和Actor-Critic混合架构。关键要素包括:智能体(Agent)、环境(Environment)、状态(State)、动作(Action)、奖励(Reward)和策略(Policy)。
强化学习已在游戏(AlphaGo)、机器人控制、自动驾驶、推荐系统等领域取得突破。2024年GRPO算法通过架构简化将大模型RLHF效率提升50%,标志着该领域向更高效、更稳定的方向持续发展。
PPO
PPO(Proximal Policy Optimization,近端策略优化)是OpenAI于2017年提出的强化学习算法,基于Actor-Critic架构,通过同时训练策略网络(Actor)和价值网络(Critic)实现稳定策略优化。其核心创新是裁剪式目标函数:
![]()
通过限制策略更新幅度避免训练发散。
PPO采用广义优势估计(GAE)计算优势值:
![]()
,平衡偏差与方差。作为on-policy算法,PPO基于当前策略采样数据更新,在Atari游戏中较传统策略梯度稳定性提升40%,MuJoCo环境策略更新方差降低35%。但需维护与策略网络同等规模的价值网络,导致70亿参数模型训练时显存需求达48GB,计算资源消耗较高。该算法广泛应用于机器人控制、自动驾驶决策等领域,Waymo自动驾驶系统采用PPO处理复杂交通场景,每千英里脱离次数仅0.09。
GRPO
GRPO(Group Relative Policy Optimization,群组相对策略优化)是DeepSeek团队于2024年提出的强化学习算法,核心创新在于通过“群组相对优势”机制实现轻量级策略优化。与传统PPO算法相比,GRPO移除价值网络(Critic),仅保留策略模型、参考模型和奖励模型,通过同一问题采样G个回答(通常G=4-8),计算组内奖励的均值与标准差进行归一化优势估计:
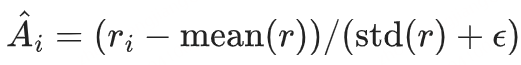
该设计带来显著效率提升:在70亿参数模型训练中减少45%计算资源消耗,A100 GPU吞吐量达128 tokens/秒(较PPO提升44%)。
GRPO采用KL散度约束替代PPO的裁剪机制,通过:
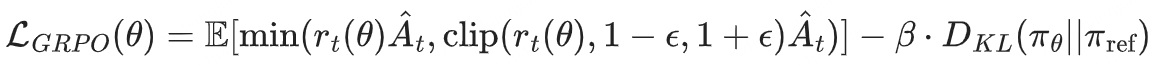
实现稳定更新。在数学推理任务中,GRPO将DeepSeek-R1模型训练效率提升50%,HumanEval代码生成任务计算成本降低42%,成为超大规模语言模型RLHF训练的关键技术。
强化评估器
强化评估器(Reinforcement Evaluator) 是一种结合强化学习思想的自动评估系统,用于对模型输出(如文本、策略、决策等)进行打分、优化或指导。它的核心目标是让模型通过反馈信号不断改进表现。
简单来说:
强化评估器 ≈ “能学会打分并用打分引导模型进步的评估器”。
一个强化评估器通常包括以下几个部分:
-
环境(Environment)
-
定义了任务、输入和可能的输出。
-
模型(或智能体)在环境中产生行为(输出)。
-
-
评估模型 / 奖励模型(Reward Model)
-
用于给模型输出打分。
-
打分可以基于人类偏好、规则或外部信号(如任务成功率)。
-
这是强化评估器的核心模块。
-
-
策略模型(Policy Model)
-
负责生成输出(回答、决策、动作)。
-
它会根据评估器给出的奖励信号调整策略。
-
-
优化器(Optimizer)
-
根据奖励反馈,更新策略模型的参数。
-
常用算法包括 PPO(Proximal Policy Optimization)、REINFORCE 等。
-
强化学习的技术原理
🌟 1、基本概念
强化学习(Reinforcement Learning, RL) 是一种让智能体(agent)通过与环境(environment)互动来学习最佳行为策略的机器学习方法。
它的核心思想是:
“通过试错获得经验,以最大化长期奖励(reward)。”
⚙️ 2、基本原理框架
强化学习由以下几个关键要素组成:
|
要素 |
说明 |
|---|---|
|
Agent(智能体) |
负责决策与学习的主体 |
|
Environment(环境) |
智能体所处的外部世界 |
|
State(状态)s |
描述当前环境的情况 |
|
Action(动作)a |
智能体可选择的行为 |
|
Reward(奖励)r |
环境对行为的反馈(好→正奖励,坏→负奖励) |
智能体通过不断尝试动作,获得奖励反馈,从而学习在不同状态下采取最优动作的策略(policy)。
🎯 3、学习目标
强化学习的目标是找到一个最优策略 π,使得:
π∗=argmaxπE[∑t=0∞γtrt]π^* = \arg\max_{π} \mathbb{E}\left[\sum_{t=0}^{\infty} \gamma^t r_t\right]π∗=argπmaxE[t=0∑∞γtrt]
即最大化长期累积奖励,其中:
-
rtr_trt:第 t 步的奖励
-
γ\gammaγ:折扣因子(控制对未来奖励的重视程度)
🧠 4、核心思想
强化学习的学习过程可以概括为:
-
观察环境状态(State)
-
选择动作(Action)
-
获得奖励(Reward)与新状态(Next State)
-
根据奖励调整策略(Policy Update)
-
重复以上过程,直至策略收敛
🧩 5、常见算法类型
|
类型 |
思路 |
示例 |
|---|---|---|
|
基于值(Value-based) |
学习每个状态或状态-动作的价值 |
Q-Learning、DQN |
|
基于策略(Policy-based) |
直接学习最优策略 |
REINFORCE、PPO |
|
基于模型(Model-based) |
学习环境模型,用于规划 |
Dyna-Q、MuZero |
🚀 6、应用实例
强化学习广泛应用于:
-
🎮 游戏智能体(AlphaGo、Atari)
-
🚗 自动驾驶决策
-
🤖 机器人控制
-
💬 智能对话系统(如 ChatGPT 的 RLHF)
-
📈 金融交易与资源优化
强化学习的平台实践
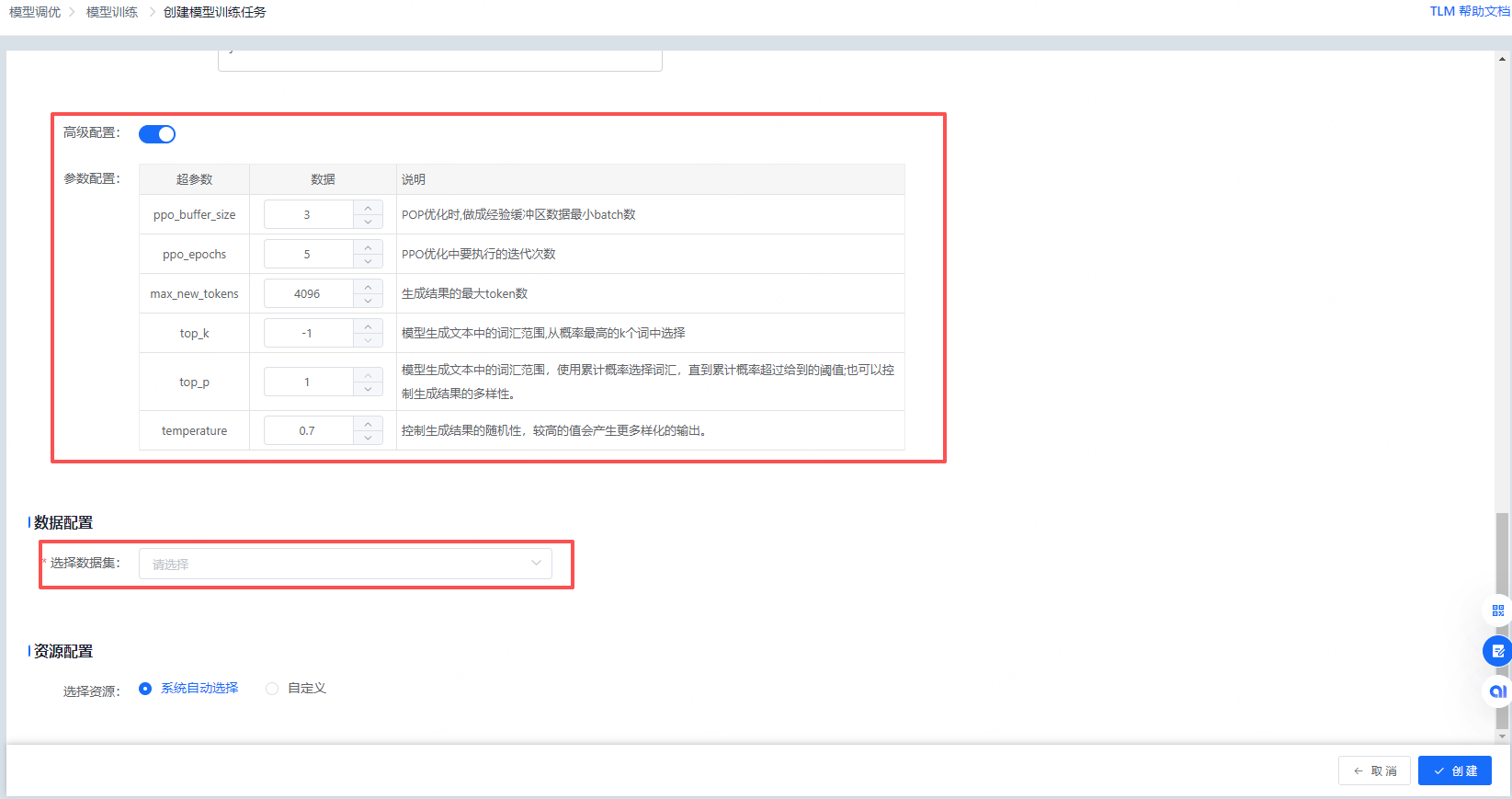
平台目前提供GRPO和PPO的训练方式。用户可在界面上通过直接点击的方式来配置奖励模型的参数。配置好后,页面会展示评估器的json代码,方便用户查看。
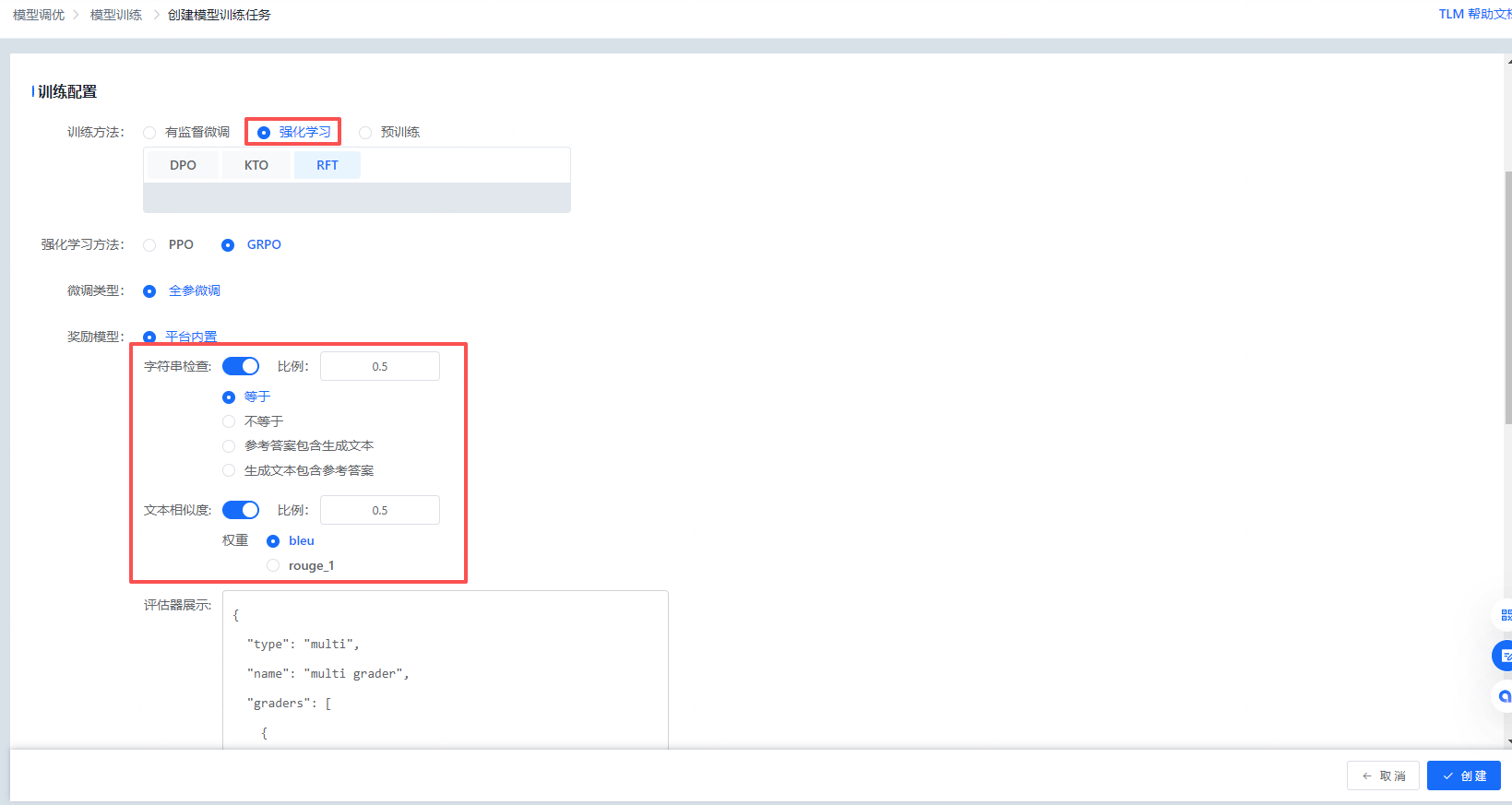

然后乐意设置高级参数,并选择训练的数据集。平台提供自定义的资源选择方式,方便用户选择合适规格的算力资源,同时也可以使用系统自动选择资源的方式(提升用户体验)。点击“创建”按钮,可提交训练任务。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)