众智FlagOS与寒武纪硬件深度适配,打造AI产业开放协同新底座
FlagOS 在支持寒武纪算力过程中,在算子、编译器、分布式通信库和并行框架这四大关键组件上取得了重大技术进展与适配成果。
大模型的快速发展正推动AI算力需求进入爆发式增长阶段。与此同时,不同应用场景对 AI 芯片提出了多样化的挑战,例如在大模型的 Prefill 场景,更需要高算力芯片,而对内存带宽的要求则远低于 Decode 场景;训练场景则不仅要求高算力与大容量内存,还需要更高的互连带宽与大规模集群组网能力。显然,单一的芯片架构已难以满足多元化的业务需求,大模型应用厂商往往需要引入多种不同架构的 AI 芯片,以部署不同类型的业务。然而,这也带来了跨芯片架构间业务代码迁移与维护的负担,尤其是算子的迁移工作,往往耗时数月,成为业务落地流程中的主要瓶颈。
针对行业痛点,北京智源人工智能研究院依托AI算法优化、芯片架构分析、编译器技术和分布式通信领域的多年积累,联手众多社区伙伴共同启动了众智 FlagOS 项目,旨在通过统一软件层解耦 AI 模型与异构硬件,打破不同架构芯片之间的软件生态壁垒,为芯片硬件与上层AI应用之间搭建统一且高效衔接的桥梁,系统性解决“适配难、调优慢、协同弱”三大行业难题,实现“一次开发,处处运行”,致力于为AI产业打造开放协同的创新技术底座。
在推进这一愿景的征程中,FlagOS 与寒武纪展开了深度且富有成效的合作。自2024年初起,双方从联合开发FlagGems(基于Triton的高性能通用AI算子库)开始,逐步将合作拓展至FlagTree(统一多后端的增强版Triton编译器)、FlagCX(统一通信库)及FlagScale(并行训推一体框架)等核心组件的深度适配。至2025年9月,寒武纪已全面完成对众智FlagOS全栈组件的适配与优化。随着“AICC 2025暨首届 FlagOS 开放计算开发者大会”上 FlagOS v1.5 的正式发布,寒武纪产品可通过众智大模型全栈生态基座支撑更广泛的生态伙伴。

寒武纪等芯片厂商是FlagOS重要的社区成员
下文将重点分享 FlagOS 在支持寒武纪算力过程中,在算子、编译器、分布式通信库和并行框架这四大关键组件上取得的技术进展与适配成果。
1. 寒武纪支持FlagGems核心算子206+,绝大性能达到原生算子80%+
FlagGems 是基于 Triton 语言实现的大模型算子库,目标是在多硬件后端上提供高性能的算子实现,并通过基准测试与自适应调优,持续优化性能表现。项目提供了面向不同芯片厂商的后端适配机制、可配置的调优参数体系,以及完整的文档、测试与基准评测入口。
FlagGems的仓地址:https://github.com/flagos-ai/FlagGems
作为 FlagOS 生态的核心算子组件库,FlagGems 以“高复用性、极致性能、架构通用性”为三大设计理念,通过标准化算子模块体系,大幅降低芯片厂商的算子开发与适配成本。作为首批深度参与 FlagGems 生态建设的芯片厂商,寒武纪全程投入算子适配与性能调优验证工作,目前已完成206/209个核心算子的全功能支持,平均性能提升达1.9倍,其中绝大部分算子性能达到原生算子的80%以上。未来,团队将持续探索性能优化边界,针对低效能的凹点算子展开专项攻坚,进一步消除性能瓶颈,实现全算子高性能覆盖。
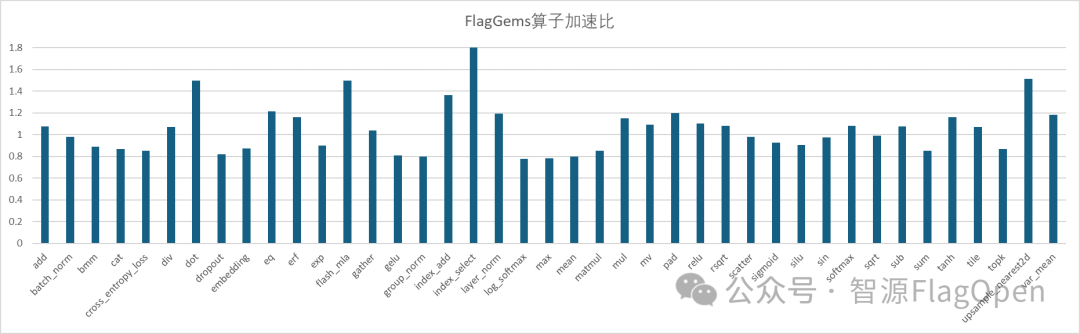
部分常见算子性能加速比
2. 依托FlagTree+FlagGems技术栈,寒武纪版Qwen3-8B性能满足工业需求
FlagTree 是一个面向多种 AI 芯片的开源统一编译器,致力于为多元化的 AI 硬件生态提供统一的编译、适配和优化能力。项目以 Triton 生态为基础,兼容现有主流 AI 芯片后端,统一代码仓库,并快速实现单仓库多后端支持,极大便利了上游模型开发者与下游芯片厂商的协作与创新,促进了 Triton 生态的繁荣和演进,为 AI 芯片生态的协同创新和高效开发提供了坚实基础。
FlagTree的仓地址:https://github.com/flagos-ai/flagtree
在 FlagTree与寒武纪的深度合作中,寒武纪 Triton 已成功合并至 FlagTree 主代码仓库。基于 FlagTree 编译器与 FlagGems 算子库,寒武纪针对 Qwen3-8B 大语言模型开展了全链路适配验证:将模型中的37个核心算子(涵盖矩阵乘法 matmul、层归一化layer_norm、注意力机制 attention 等关键计算单元)替换为 FlagGems 提供的 Triton 优化算子,在寒武纪芯片上进行推理性能测试,整网推理吞吐性能达到原生算子版本的80%,完全满足实时推理场景需求。
这一成果不仅验证了 FlagTree+FlagGems 技术栈的工程稳定性,更彰显了 Triton 框架两大核心优势:算子迭代周期从传统的2周大幅缩短至3天,显著提升开发效率;同时依托其跨架构兼容性,为前沿 LLM 模型的快速工程化落地开辟了高效技术路径。
3. FlagCX与寒武纪CNCL通信库深度集成兼顾统一便利性和极致性能
FlagCX 是一款面向大规模 AI 训练的通信中间件,通过对底层硬件差异进行抽象,使开发者能够在异构硬件环境中无缝开展分布式训练,从而有效提升资源利用效率和训练性能。
FlagCX的仓地址:https://github.com/flagos-ai/FlagCX
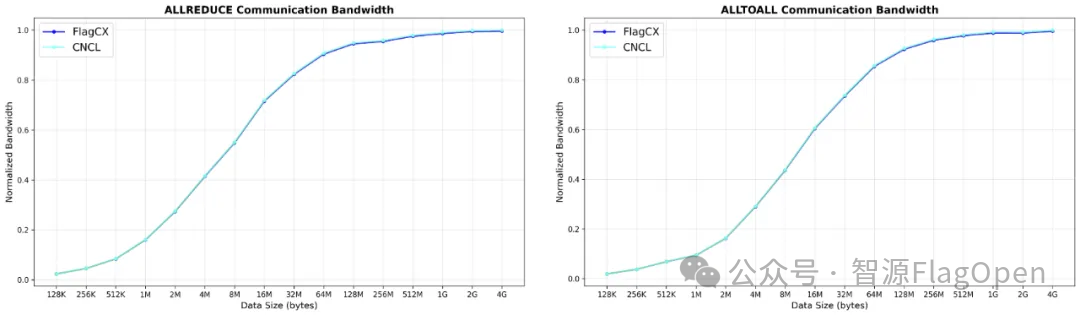
自 FlagCX 开源之后,寒武纪即积极参与共建。从FlagCX v0.1.0 版本开始,寒武纪就实现了绝大部分通信原语的支持,如今已做到对包括 allreduce、reducescatter、allgather、send、recv 在内的通信操作的全面支持。这种支持并非简单的接口对接,而是通过 FlagCX 的统一适配器模块实现了与寒武纪原生 CNCL 通信库的高效、深度集成。
FlagCX 通过其核心层(FlagCX Core)处理异构通信,同时通过适配器无缝兼容包括 CNCL 在内的各大厂商同构通信库。这意味着,当用户在纯寒武纪 MLU 集群上进行同构训练时,FlagCX 能够直接调用经过深度优化的 CNCL 库,确保通信性能与直接使用 CNCL原生库基本持平,几乎无性能损耗。这种技术集成保障了用户在享受 FlagCX 统一接口便利性的同时,获得极致的原生性能体验。
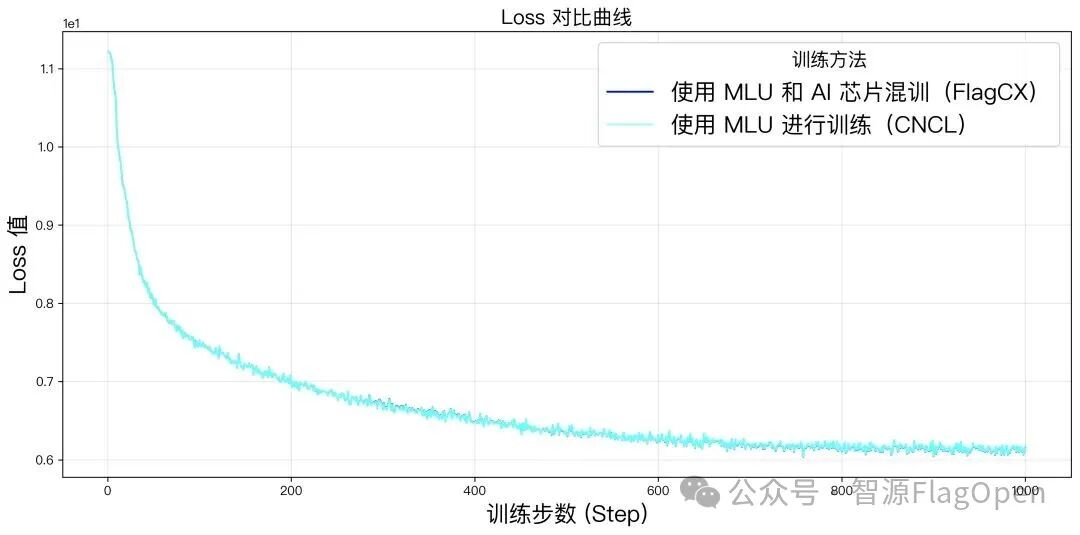
在寒武纪 MLU 与其他 AI 芯片的混合环境中,FlagCX 成功保障了混合训练的模型精度与纯 MLU 独立训练结果完全一致。更重要的是,在如此复杂的异构环境下,平均单卡吞吐量仍能达到 MLU 独立训练的99%以上。这一卓越成绩证明了寒武纪 MLU 与 FlagCX 的结合,不仅能实现精度无损,更能实现效率的极致优化,为用户最大化利用异构算力资源提供了可靠的技术基础。
4. FlagScale 拓展寒武纪 MLU,在大模型训练推理中框架级生态能力
FlagScale 是智源人工智能研究院主导开发的大模型全生命周期工具集,是FlagOS 生态的核心组成部分,致力于构建覆盖模型开发、分布式训练与推理部署的统一技术体系。框架融合了 Megatron-LM、vLLM、SGLang、Verl 等主流开源项目,为大模型提供从训练到推理的一站式解决方案。
FlagScale的仓地址:https://github.com/flagos-ai/FlagScale
在与 FlagScale 的深度合作中,寒武纪基于 MLU 硬件平台完成了对 Megatron-LM 训练框架和 vLLM 推理框架的全面适配与优化。在训练环节,MLU 平台已充分支持智源 Megatron 体系下的多类主流模型,包括 Llama系列、Aquila2系列、Qwen3 系列等,并覆盖从模型并行到混合精度的完整训练流程;在推理环节,MLU 平台对 vLLM 框架实现了完备的兼容支持,可高效运行社区开源的多种大语言模型推理任务。
在完成框架级适配后,结合 MLU 架构特性,寒武纪还围绕通信、算子和内存调度进行了多层次性能优化。通过集成自研 CNCL 通信库、CNNL 高性能算子库及混合精度算子调度机制,可显著提升分布式训练的通信效率与算力利用率;在 vLLM推理中,针对 Attention、LayerNorm、GEMM 等核心算子进行了指令级与内存访问模式优化,为后续性能提升奠定基础。
凭借在 FlagScale 生态中的深度集成与架构适配经验,寒武纪 MLU 平台具备了对未来 FlagScale 开发或开放的新模型进行快速、即时适配的能力。无论是Megatron-LM 体系下的新一代训练模型,还是 vLLM 推理端的最新开源模型,MLU 都能够在框架演进中实现同步更新与性能优化,保持良好的生态兼容性和持续演进能力。
FlagScale 的全面适配与持续优化,使寒武纪 MLU 在大模型训练与推理全链路中具备了统一、高效、可扩展的框架级生态能力。这一进展不仅加速了国产 AI 硬件在开源大模型生态中的融合,也为大模型的工程化和高性能部署提供了有力支撑。
关于FlagOS
为解决不同 AI 芯片大规模落地应用,北京智源研究院联合众多科研机构、芯片企业、系统厂商、算法和软件相关单位等国内外机构共同发起并创立了 FlagOS 开源社区。
FlagOS 社区致力于打造面向多种 AI 芯片的统一、开源的系统软件栈,包括大型算子库、统一AI编译器、并行训推框架、统一通信库等核心开源项目,构建「模型-系统-芯片」三层贯通的开放技术生态,通过“一次开发跨芯迁移”释放硬件计算潜力,打破不同芯片软件栈之间生态隔离,有效降低开发者的迁移成本。FlagOS 社区构建人工智能软硬件生态,突破单一闭源垄断,推动AI硬件技术大范围落地发展,立足中国、拥抱全球合作。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)