《openGauss:数据库AI时代破局者》
openGauss数据库通过Docker部署测试验证了其基础OLTP能力,包含DDL/DML操作、向量数据库(DataVec)、图数据库(AGEGraph)和全文检索功能测试。作为AI-Native数据库,openGauss创新性地实现"一库四用"架构,支持标量数据、向量检索、知识图谱和全文搜索,特别在RAG场景中展现向量标量融合查询优势。该数据库已形成开源社区与商业发行版并行
目录
三、AI-Native战略核心:向量数据库(DataVec)与RAG
一、基础测试
为了直观体验 openGauss 的易用性,本次评测采用 Docker 容器化部署 openGauss,并验证其基础的 Online Transaction Processing (OLTP) 能力。
1. 部署(Docker方式)
使用 Docker 镜像进行部署是 openGauss 社区推荐的极简方式,方便开发者快速拉起环境进行测试。
通过 wget 命令下载 openGauss 的 Docker 镜像包。

使用 docker load 命令将下载的 .tar 文件导入到本地 Docker 镜像库。
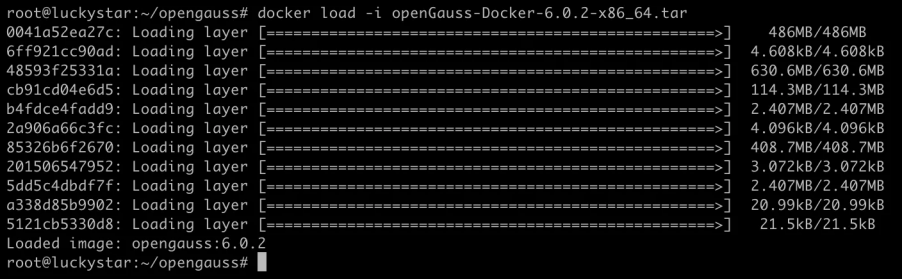
运行 openGauss 容器并映射端口、设置用户名和密码,容器成功运行后使用 docker ps 命令验证容器状态。

验证结果:容器运行成功状态显示为 Up 2 seconds ago,表明 openGauss 数据库实例已在 Docker 环境中启动,通过 8888 端口映射。
2. 基础数据库操作测试(DML/DDL)
连接到 openGauss 实例后验证基础的数据库定义语言(DDL)和数据操作语言(DML)能力。
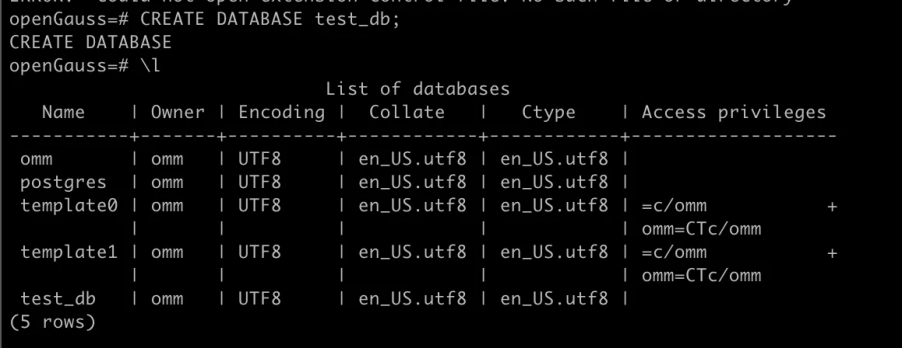
创建新的数据库 test_db并使用 \l 命令查看数据库列表,确认创建成功。
在数据库中创建一个简单的客户表 customer_t1,包含 integer 和 char 等常见数据类型。
CREATE TABLE customer_t1
(
c_customer_sk integer,
c_customer_id char(5),
c_first_name char(6),
c_last_name char(8),
Amount integer
);通过一系列操作,验证了数据的插入(INSERT)、更新(UPDATE)、查询(SELECT)和删除(DELETE)功能。
l插入数据:首次插入时因值长度超过了 c_first_name 字段定义的 char(6) 长度而报错,修正后插入成功。
l查询数据:确认数据插入成功。
l更新数据:将 c_first_name 从 xing 更新为 jack,更新成功。
l删除数据:按主键删除记录删除成功。
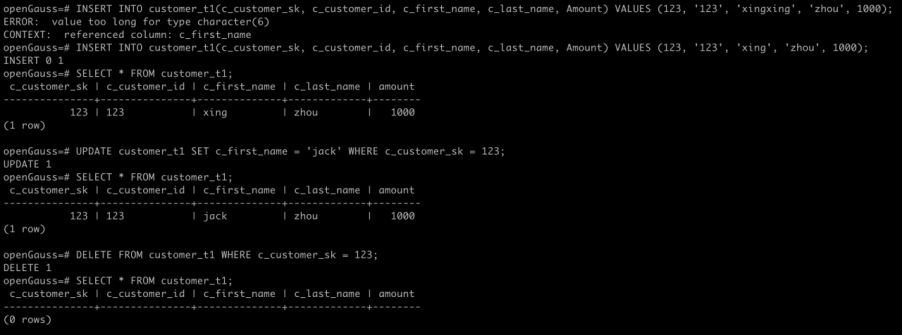
验证小结:openGauss 基础的 SQL 能力兼容性良好,且具备标准的关系型数据库的严格数据类型检查(如字符长度检查),表现稳定可靠。
二、进阶测试
1、SQL操作测试(标量数据)
-- 创建测试数据库
CREATE DATABASE og_demo;
\c og_demo;
-- 创建表
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(50),
age INT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 插入数据
INSERT INTO users (name, age) VALUES ('Alice', 25), ('Bob', 30), ('Carol', 28);
-- 查询数据
SELECT * FROM users;
-- 更新数据
UPDATE users SET age = age + 1 WHERE name = 'Alice';
-- 删除数据
DELETE FROM users WHERE name = 'Carol';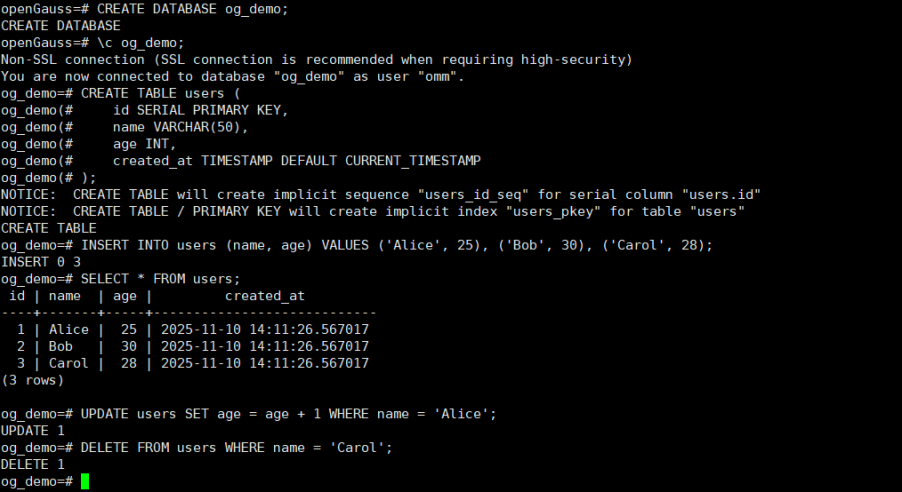
2、向量数据库功能测试(DataVec)
-- 创建向量表(用于 RAG 或相似度检索)
CREATE TABLE vec_demo (
id SERIAL PRIMARY KEY,
embedding VECTOR(4) -- 定义4维向量列
);
-- 插入向量数据
INSERT INTO vec_demo (embedding) VALUES
('[0.1, 0.2, 0.3, 0.4]'),
('[0.9, 0.8, 0.7, 0.6]'),
('[0.11, 0.19, 0.29, 0.39]');
-- 查询所有向量
SELECT * FROM vec_demo;
-- 计算向量相似度(余弦距离示例)
SELECT id, embedding <=> '[0.1, 0.2, 0.3, 0.4]' AS distance
FROM vec_demo
ORDER BY distance
LIMIT 3;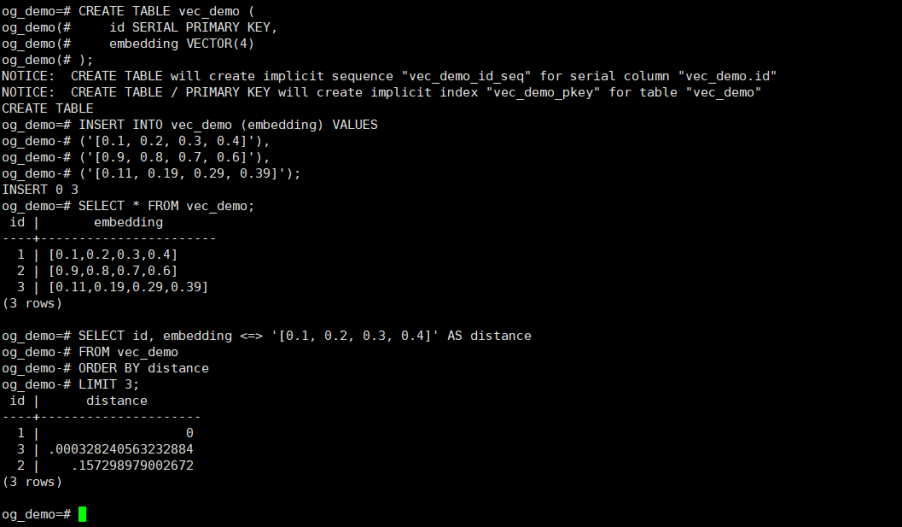
3、图数据库功能测试(AGEGraph)
-- 加载 AGE 扩展
LOAD 'age';
SET search_path = ag_catalog, "$user", public;
-- 创建图并插入节点/关系
SELECT create_graph('demo_graph');
SELECT * FROM cypher('demo_graph', $$ CREATE (a:Person {name:'Alice'})-[:FRIEND]->(b:Person {name:'Bob'}) RETURN a,b $$) AS (a agtype, b agtype);
-- 查询图中节点
SELECT * FROM cypher('demo_graph', $$ MATCH (p:Person) RETURN p.name $$) AS (name agtype);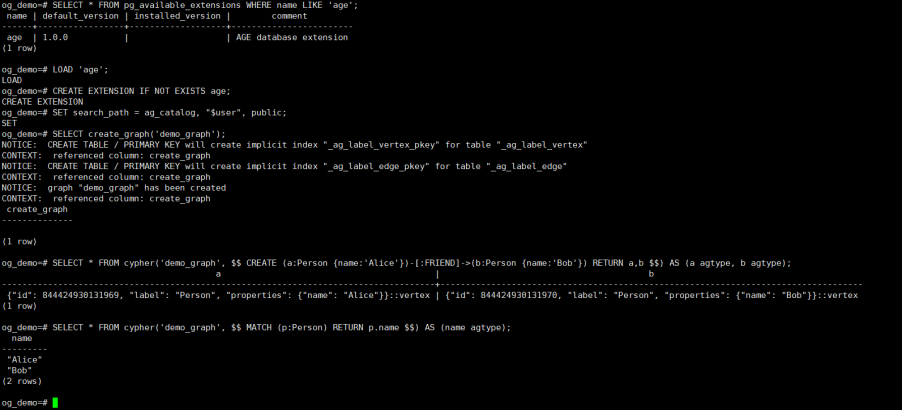
4、全文检索功能测试
-- 创建全文检索表
CREATE TABLE docs (id SERIAL PRIMARY KEY, content TEXT);
-- 插入数据
INSERT INTO docs (content) VALUES ('openGauss 数据库性能卓越'), ('AI 向量检索支持 DataVec 模型');
-- 创建全文索引
CREATE INDEX idx_docs_content ON docs USING gin (to_tsvector('simple', content));
-- 搜索包含“向量”关键词的内容
SELECT * FROM docs WHERE to_tsvector('simple', content) @@ to_tsquery('向量');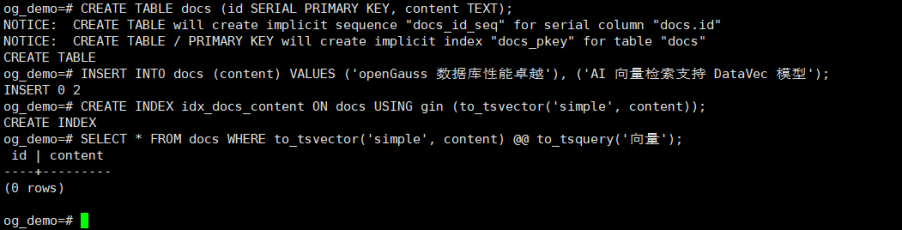
三、AI-Native战略核心:向量数据库(DataVec)与RAG
openGauss 紧跟业界热点,其最大的技术亮点是内置的 DataVec 向量数据库能力,这使其成为数据库中少数具备 AI-Native 特性的选手。
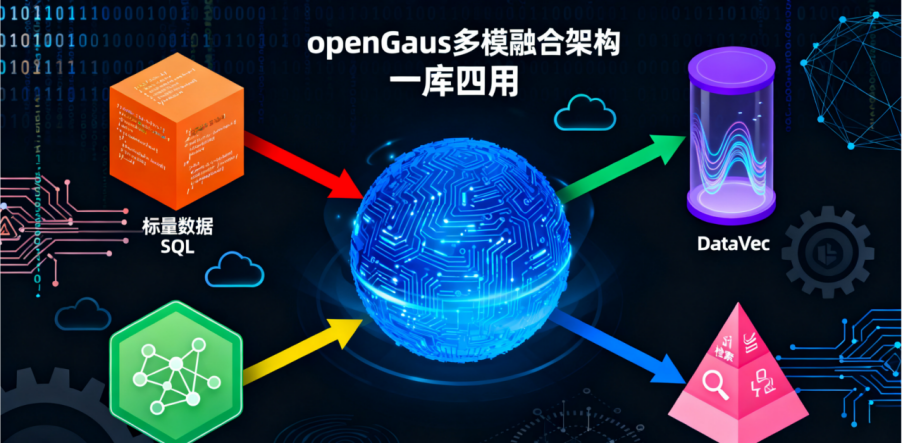
1. DataVec:多模融合的AI底座
openGauss 实现了在一个数据库内核中同时支持:
l标量数据(SQL):传统的增删改查。
l向量数据(DataVec):用于 RAG、相似度搜索。
l知识图谱(AGEGraph):用于复杂关系分析。
l全文检索:用于非结构化文本内容搜索。
这种“一库四用”的架构,解决了 RAG 场景中需要融合结构化和非结构化数据的痛点,大幅降低了企业在 AI 应用中的部署和运维复杂度。
2. RAG场景下的核心优势
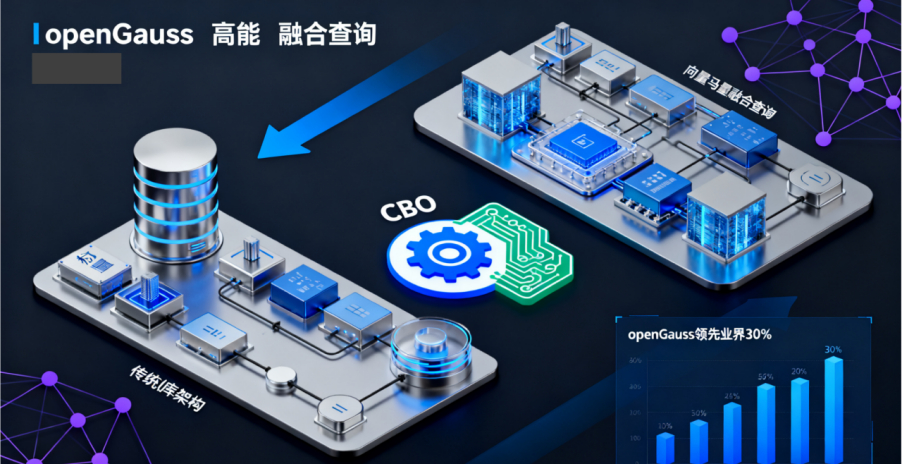
l高性能向量检索:openGauss 通过与硬件(如鲲鹏)的深度协同,利用 BoostKit 加速库和 SIMD 向量化指令,其向量检索性能领先业界主流数据库 30%以上。它支持 HNSW、IVF 等高效索引,并能利用 DiskANN 算法处理十亿级海量数据。
l向量标量融合查询:这是 openGauss 的独有优势。它可以利用 CBO(基于成本的优化器)对向量和标量查询进行融合优化,生成最优执行计划,从而提升 RAG 系统的检索精度和效率。
l高安全性本地部署:对于金融、政务等对数据安全要求极高的行业,openGauss 支持本地化部署 RAG 架构,确保敏感数据不出域,满足化和隐私保护的需求。
四、技术生态与发展趋势:化主力军
1. 繁荣的商业生态
openGauss 成功构建了“开源社区 + 商业发行版”的生态模式:
lDBV 厂商加持:国内主流数据库厂商,如云和恩墨(MogDB)、南大通用(GBase 8c)、海量数据等,均基于 openGauss 内核推出了商业发行版。这不仅为用户提供了多样化的商业服务,也证明了 openGauss 内核的企业级稳定性和可靠性。
l软硬一体化:与华为鲲鹏等计算平台深度融合优化,实现了从芯片、操作系统到数据库的全栈自主可控。
2. 深度行业应用(运营商核心系统)
openGauss 在国内最严苛的电信运营商行业实现了大规模商用,包括中国移动、中国联通等。其应用于:BOSS 系统、计费帐务系统、CRM 系统等核心业务。处理日均数十亿条计费话单和高并发业务。这批用户案例是 openGauss 高可靠性、高性能、高可用性的最好背书,证明其足以承担国家关键信息基础设施的重任。
3. 发展趋势:迈向下一代数据库
openGauss 的发展方向是成为具备 AI 增强能力的新一代数据库。其持续投入的内核技术,如 oGRAC 多写架构和 CSN 事务机制的优化,进一步夯实了其作为企业级核心系统数据库的基础。在 AI 浪潮下,openGauss 以其独特的多模融合和高性能向量能力,正成为数据库在 AI 时代的破局者。
在当今数字化浪潮席卷全球的背景下,数据库作为信息系统核心基石的战略地位日益凸显。过去多年,我国数据库领域长期依赖国外主流产品,存在诸多安全隐忧。2020年6月,华为宣布开源数据库能力,开放openGauss数据库源代码并成立开源社区,标志着数据库进入自主创新新阶段。短短四年多时间,openGauss实现了令人瞩目的跨越式发展。据最新市场报告显示,2024年openGauss在线下集中式关系型数据库新增市场份额达到30.2%,基于openGauss的关系型数据库产品占比达28.5%,超过MySQL和PostgreSQL,成为三大主流开源技术路线之首。这一数据充分证明了openGauss在市场上的广泛认可度。
openGauss的成功源于其卓越的技术特性。作为企业级开源关系型数据库,openGauss通过多核架构性能优化、主备部署高可用性、全密态计算安全机制等创新技术,提供了高性能、高安全、高可用、高智能的数据库解决方案。特别是在安全性方面,openGauss打造了理念领先的全密态数据库,确保数据在传输、计算和存储中全程加密,最大限度保证数据隐私和安全。目前,openGauss已在金融、电信、政府、能源等十大关键行业实现规模化商用,累计装机量达10万以上,成为行业数智化的重要力量。邮储银行、民生银行、中国移动、中国联通、京东等行业头部企业纷纷将其用于核心业务系统,为数据库的创新应用树立了标杆。openGauss社区秉承“共建、共享、共治”原则,已汇聚850余家社区企业成员,7600多名贡献者,覆盖全球1623个城市,累计下载量超过360万次。这种开放式创新生态是openGauss持续进化的不竭动力。2024年,openGauss获得国家工业信息安全发展研究中心颁发的首个通过认证的可规模商用自主创新数据库根社区证书。这一权威认证不仅是对openGauss技术实力的认可,更是对基础软件自主创新道路的重要肯定,为数据库产业发展树立了信心。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)