Coze开源实践!一站式 AI 开发流水线
Coze开源AI开发平台技术实践解析 本文详细介绍了Coze开源AI开发平台的技术实现与应用实践。首先分析了当前AI开发的痛点及Coze的一站式解决方案,提供了完整的部署指南。通过项目结构解析,展示了基于DDD架构的后端设计,重点介绍了字节跳动的Hertz微服务框架和Eino AI开发框架。文章深入演示了RAG和Agent开发场景,包括知识检索、工具调用等核心功能实现。最后展望了多语言AI框架发展
目录
一、前言
当前 AI 应用开发中,技术门槛高、工具分散、流程繁琐是普遍问题,开发者需掌握大模型调用、向量检索等技术,还得在多平台间切换完成部署与调试,影响开发效率。Coze 作为当前一个比较流行的一站式 AI 智能体开发平台,受到了很多从业者的喜爱,而在最近coze开源了其核心的coze-studio以及coze-loop两部分,接下来我们将探索coze在AI应用开发等方面进行了那些最佳实践。
二、部署
参考文档 https://github.com/coze-dev/coze-studio?tab=readme-ov-file#quickstart
1.前期准备
模型准备,官方建议准备火山方舟的账号接入LLM,其中项目中集成了一些现成的模版方便快速配置模型,接下来按照官方的文档准备火山方舟的账号准备接入doubao-seed-1.6,其中如果想体验一个较为完整的AI开发流程建议同事开通embedding等小模型的权限,用来支持知识库的构建等。
其中大模型部分使用火山方舟提供的doubao-seed-1.6,embeding模型则使用本地启动的bge
2.拉取项目
# Clone code
git clone https://github.com/coze-dev/coze-studio.git3.设置模型
进入目录backend/conf/template中找到对应的模型的模版这里我使用的是doubao-seed-1.6,所以选择model_template_ark_doubao-seed-1.6.yaml,这里需要按照对应的平台和模型选择使用的模版文件,完整的模版文件列表如下
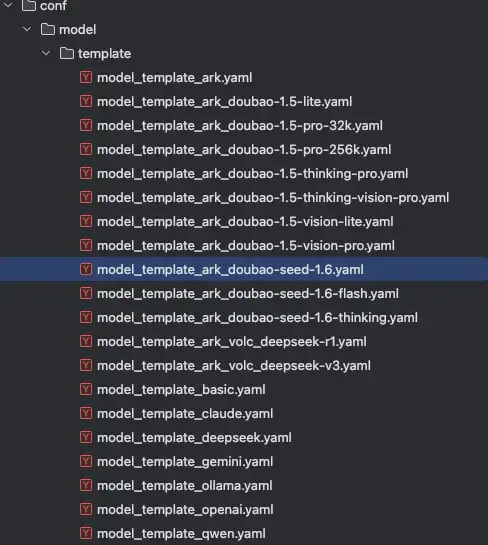
然后将对应的模版文件拷贝到backend/conf/model目录下,然后修改对应配置,这里使用方舟平台的模型不进行额外的模型参数配置,直接修改对应的base_url,api_key,和model3个字段,这3个字段均可以在方舟平台中查询到其中model字段对应的是模型的id
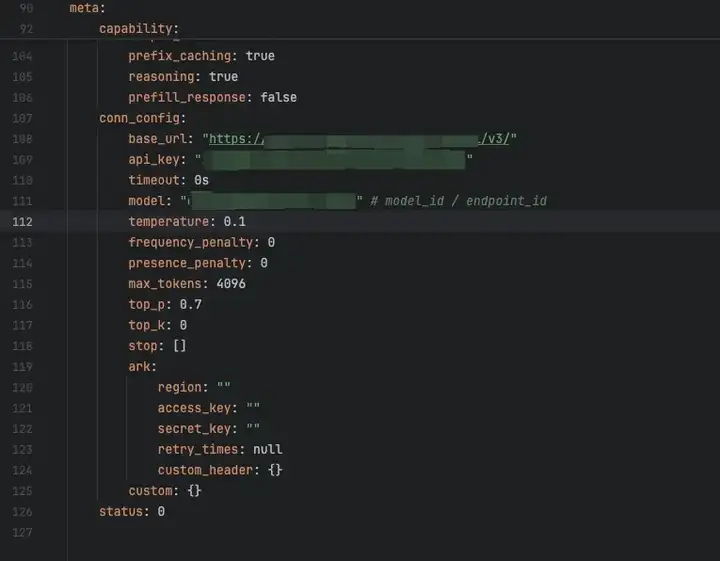
cp backend/conf/template/model_template_ark_doubao-seed-1.6.yaml backend/conf/model
# 修改文件配置
vi backend/conf/model/model_template_ark_doubao-seed-1.6.yaml4.配置embedding模型(可选)
这里按照配置ollama的embeding模型为例,首先使用ollama启动embeding模型,这里选择使用bge-m3,这里因为bge-m3的维度为1024,所以dim写1024,model写模型名称

# ollama部署embedding模型
ollama pull bge-m3
# ollama在面对小模型的时候不能像大模型一样通过run命令直接去运行,而是在调用对应接口的时候直接加载返回结果
# 这里测试一下
curl http://localhost:11434/api/embed -d '{
"model": "bge-m3",
"input": "Does Ollama support embedding models?"
}'
curl http://localhost:11434/api/embed \
-d '{
"query": "What is the capital of France?",
"documents": [
"Paris is the capital and most populous city of France.",
"The Eiffel Tower is a wrought-iron lattice tower on the Champ de Mars in Paris, France.",
"France is a country in Western Europe.",
"The largest city in France is Marseille.",
"Berlin is the capital of Germany."
]
}'
# 配置
vi docker/.env5.启动容器
# 启动服务cd docker
cp .env.example .env
docker compose up -d6.访问页面
至此coze的基础安装部署就可以了,当然其中还有很多部分功能需要一些额外的配置,详细的内容可以查看coze的wiki手册进行配置 https://github.com/coze-dev/coze-studio/wiki
三、项目分析
首先因为我本人主要是后端开发,所以更多项目分析则主要是分析后端的代码实现以及结构部分,所以接下来内容主要是分析后端的设计以及各个模块的功能
结构分析(设计)
根据Coze的项目代码来看Coze的项目设计应该是按照DDD的方式去设计的,这里从整体项目中的backend中的domain目录可以看的出来,在一个在项目的README中可以看到Coze本身使用了字节内部已经积累的很多框架,比如微服务的web框架Hertz,以及GO语言的AI开发框架Eino,以及一个前端的画布框架FlowGram,由此可以可以知道coze本身项目前端和后端代码均包含在其中,这一点可以从目录backend和frontend中看出。
目录解析
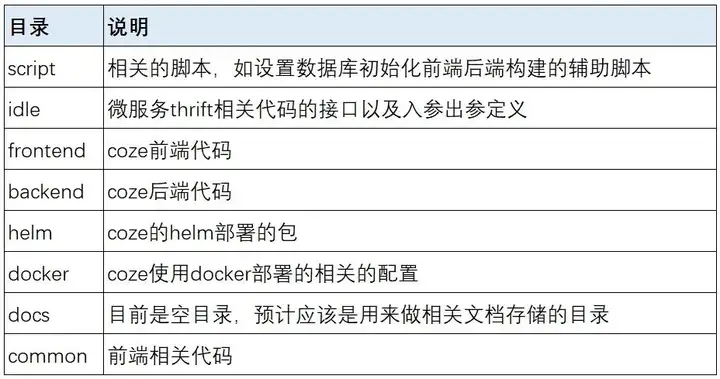
其中部分代码使用Hertz的代码生成工具hz进行生成,包含了代码路由定义部分
▪backend/api: 主要实现了web接口的主题业务逻辑。其中router部分主要定义了对应的web接口的对应的路由地址,其中的coze.go和register.go则为hz工具根据thrift文件生成的对应的go文件;
其中middleware.go则定义了web相关的中间件方法;其中的model部分则是有hz工具生成的thrift文件中定义的对象也就是web接口中的入参出参的对应,而同级的middleware目录则是定义了真正的web中间件。
handler中定义了对于不同的接口的web实现的方法,其中的方法则最终会调用到application中定义的不同的逻辑实现函数中。
▪ backend/doamin:这个目录中主要对应的是DDD中的domain领域层的实现,包含真正的业务逻辑在其中,其中每个领域按照entiry实体,internal网络,repository仓库层和service服务层,其中repository定了这个领域服务的全部接口,service则实现了这个领域服务中的对应的接口的,而entiry则定义了每个领域服务中接口的入参出参的对象,intelnal则定义了对象与gorm中的对象,以及对象的转换等相关代码
▪ backend/conf:这个目录中则定义了相关的模型,插件提示词等配置文件以及相关的模版
▪ backend/infra:这个目录中定义了依赖的基础组件的接口定义和对应的实现,如定义了db相关的接口和对应db接口的实现,cache的接口和实现,以及es的接口和实现等,其中接口定义部分在contract,对应的接口实现则在impl中
▪ backend/intelnal:这个目录中的文件主要是由MockGen工具生成的mock数据以及单元测试代码
▪ backend/pkg:这个包中主要定了对应的公共方法以及工具方法和类
▪ backend/script:其中主要定义了辅助的shell脚本
▪ backend/typs:这个包中主要包含了常量的定义,ddl代码以及对应的错误定义
四、AI开发框架
概述
Eino是一个基于Golang的AI应用开发框架。
Eino 旨在提供使用 Go 语言构建的 AI 应用开发框架。Eino 参考了开源社区中众多优秀的 AI 应用开发框架,例如 LangChain、LangGraph、LlamaIndex 等,并提供了更加符合 Golang 编程习惯的 AI 应用开发框架。
Eino提供了原子组件、集成组件、组件编排、切面扩展等丰富的辅助AI应用开发的能力,可以帮助开发者更加简单便捷地开发架构清晰、易于维护、高可用的AI应用。
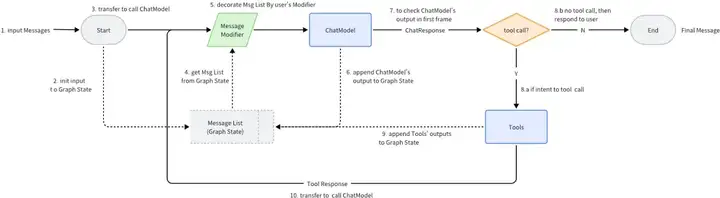
以ReactAgent为例:
▪ 提供ChatModel、ToolNode、PromptTemplate等常用组件,业务可定制扩展。
▪ 可以基于现有组件进行灵活的编排,生成集成组件用于业务服务。
核心组件
在Eino框架中将整个AI开发过程中使用的工具部分统一抽象为组件(component),而每个组件的具体实现则放置于eino-ext中,在eino中已经定义了7种组件,包含了AI应用开发过程中所需的几种主要使用的组件类型其中分别为,document,embedding,indexer,model,prompt/mcp,retriever以及tools。
其中document则可以理解为AI应用开发过程中的知识库构建的原始文档的定义,embedding则为其中向量化的过程,indexer则为文件索引,方便后续召回时文件的召回的速度,model则为LLM的定义,prompt/mcp则为提示词框架的定义,retriever则为RAG中的检索增强部分,tools则为工具调用部分的定义等。
安装
go get -u github.com/cloudwego/eino
go get -u github.com/cloudwego/eino-ext
# 依赖设置
# 要求GO在1.18以上版本,还有为了兼容GO1.18版本,官方将github.com/getkin/kin-openapi包更新到了v0.133.0版本
# 但是我在实际使用的时候会显示类型转换的错误,需要手动将这个包的版本更改为v0.118.0典型场景
这里为了模型对应场景所以这里的向量检索以及rerank重排序使用了一个假的方法模型检索完的内容以及重排序完的内容
模拟向量检索
func fakeSearchVectorDB(query string) []string {
// 这里模拟向向量数据库查询,并返回相关内容
// 在实际应用中,你需要实现真正的向量数据库查询逻辑
return []string{
"昨天没喝水,因为我一直在忙着工作,完全忘记了时间,直到晚上才意识到自己一整天都没有喝水。",
"你是谁?能不能详细介绍一下你自己,包括你的名字、职业、兴趣爱好以及你目前在做的事情?",
"他很好,他不仅在工作上表现出色,而且在生活中也是一个非常善良和乐于助人的人,大家都很喜欢他。",
"今天天气不错,阳光明媚,微风习习,正是出去散步或者进行户外活动的好时机。",
"我喜欢编程,因为编程不仅能让我解决实际问题,还能让我创造出各种有趣的应用和工具。",
"你去哪里了?我找了你很久,打了好几个电话你都没有接,是不是发生了什么事情?",
"我们一起去看电影吧,这部新上映的电影评价很高,剧情也很吸引人,我觉得你一定会喜欢。",
"这道题很难,我已经尝试了好几种方法都没有解出来,你能不能帮我看看问题出在哪里?",
"你喜欢什么运动?我最近开始跑步,感觉对身体很有好处,你有没有兴趣一起参加?",
"明天有空吗?我们可以一起去逛街,顺便吃个饭,聊聊最近的生活和工作。",
}
}模拟重排序
func fakeRerankContents(contents []string, query string, topk int) []string {
// 这里模拟对内容进行排序
// 在实际应用中,你可以实现更复杂的排序逻辑
return []string{"我喜欢编程,因为编程不仅能让我解决实际问题,还能让我创造出各种有趣的应用和工具。"}
}
1. RAG
以下代码模拟了RAG中当用户提问后进行知识检索,重排序,当然这里是我写死的,仅仅是为了模拟RAG的过程,
最终大模型根据上下文中的内容进行回答。
package main
import (
"context"
"log"
"github.com/cloudwego/eino-ext/components/model/ollama"
"github.com/cloudwego/eino/components/model"
"github.com/cloudwego/eino/components/prompt"
"github.com/cloudwego/eino/schema"
)
func fakeSearchVectorDB(query string) []string {
// 这里模拟向向量数据库查询,并返回相关内容
// 在实际应用中,你需要实现真正的向量数据库查询逻辑
return []string{
"昨天没喝水,因为我一直在忙着工作,完全忘记了时间,直到晚上才意识到自己一整天都没有喝水。",
"你是谁?能不能详细介绍一下你自己,包括你的名字、职业、兴趣爱好以及你目前在做的事情?",
"他很好,他不仅在工作上表现出色,而且在生活中也是一个非常善良和乐于助人的人,大家都很喜欢他。",
"今天天气不错,阳光明媚,微风习习,正是出去散步或者进行户外活动的好时机。",
"我喜欢编程,因为编程不仅能让我解决实际问题,还能让我创造出各种有趣的应用和工具。",
"你去哪里了?我找了你很久,打了好几个电话你都没有接,是不是发生了什么事情?",
"我们一起去看电影吧,这部新上映的电影评价很高,剧情也很吸引人,我觉得你一定会喜欢。",
"这道题很难,我已经尝试了好几种方法都没有解出来,你能不能帮我看看问题出在哪里?",
"你喜欢什么运动?我最近开始跑步,感觉对身体很有好处,你有没有兴趣一起参加?",
"明天有空吗?我们可以一起去逛街,顺便吃个饭,聊聊最近的生活和工作。",
}
}
func fakeRerankContents(contents []string, query string, topk int) []string {
// 这里模拟对内容进行排序
// 在实际应用中,你可以实现更复杂的排序逻辑
return []string{"我喜欢编程,因为编程不仅能让我解决实际问题,还能让我创造出各种有趣的应用和工具。"}
}
func createOllamaChatModel(ctx context.Context) model.ToolCallingChatModel {
chatModel, err := ollama.NewChatModel(ctx, &ollama.ChatModelConfig{
BaseURL: "http://localhost:11434", // Ollama 服务地址
Model: "qwen2.5:7b", // 模型名称
})
if err != nil {
log.Fatalf("create ollama chat model failed: %v", err)
}
return chatModel
}
func main() {
ctx := context.Background()
// 创建 Ollama 聊天模型
chatModel := createOllamaChatModel(ctx)
// 用户输入的问题
userQuestion := "你猜我最喜欢什么?"
// 第一步:检索相关内容
retrievedContents := fakeSearchVectorDB(userQuestion)
// 第二步:排序内容
sortedContents := fakeRerankContents(retrievedContents, userQuestion, 1)
template := prompt.FromMessages(schema.FString,
// 系统消息模板
schema.SystemMessage("你是一个{role}。你需要用{style}的语气回答问题。你的目标是帮助用户保持积极乐观的心态。"+
"并且你需要按照上下文中的内容进行回答,对于上下文中没有提到的内容不要进行自主回答,如果上下文中没有提到则请回复不知道。检索到的上下文内容为{context}"),
// 用户消息模板
schema.UserMessage("问题: {question}"),
)
// 使用模板生成消息
messages, err := template.Format(context.Background(), map[string]any{
"role": "小助手",
"style": "积极、温暖且专业",
"question": userQuestion,
"context": sortedContents,
})
if err != nil {
log.Fatalf("format template failed: %v\n", err)
}
log.Printf("===llm generate===\n")
result, err := chatModel.Generate(ctx, messages)
if err != nil {
log.Fatalf("llm generate failed: %v", err)
}
log.Printf("result: %+v\n\n", result)
}最终通过模拟检索,大模型最终回答我喜欢的内容是编程。

当然这里是进行一个简单的浅尝辄止,这里并没有模拟RAG中的知识进入向量数据库的入库部分,以及对应的知识检索和重排序部分的代码,如果大家感兴趣的可以尝试补充完整的代码。
2. Agent
提到智能体这个场景,那么一定少不了的就是工具的定义以及定义,在eino中一共定义了4种工具的构建方式,其中最简单的方式就是通过NewTools方法构建
import (
"context"
"github.com/cloudwego/eino/components/tool"
"github.com/cloudwego/eino/components/tool/utils"
"github.com/cloudwego/eino/schema"
)
// Handling function
func AddTodoFunc(_ context.Context, params *TodoAddParams) (string, error) {
// Mock processing logic
return`{"msg": "add todo success"}`, nil
}
func getAddTodoTool() tool.InvokableTool {
// Tool information
info := &schema.ToolInfo{
Name: "add_todo",
Desc: "Add a todo item",
ParamsOneOf: schema.NewParamsOneOfByParams(map[string]*schema.ParameterInfo{
"content": {
Desc: "The content of the todo item",
Type: schema.String,
Required: true,
},
"started_at": {
Desc: "The started time of the todo item, in unix timestamp",
Type: schema.Integer,
},
"deadline": {
Desc: "The deadline of the todo item, in unix timestamp",
Type: schema.Integer,
},
}),
}
// Use NewTool to create the tool
return utils.NewTool(info, AddTodoFunc)
}这种方式构建需要把工具的调用方式和每个字段的类型以及描述进行定义,这种方式有一个明显的缺点:参数信息(ParamsOneOf)需要手动定义在 ToolInfo 中,与实际的参数结构体(TodoAddParams)是分开的。这不仅会造成代码冗余,而且参数变更时需要同时修改两处,容易导致不一致,增加维护的负担。
第二种方式则是使用InferTool
import (
"context"
"github.com/cloudwego/eino/components/tool/utils"
)
// Parameter struct
type TodoUpdateParams struct {
ID string`json:"id" jsonschema:"description=id of the todo"`
Content *string`json:"content,omitempty" jsonschema:"description=content of the todo"`
StartedAt *int64`json:"started_at,omitempty" jsonschema:"description=start time in unix timestamp"`
Deadline *int64`json:"deadline,omitempty" jsonschema:"description=deadline of the todo in unix timestamp"`
Done *bool `json:"done,omitempty" jsonschema:"description=done status"`
}
// Handler function
func UpdateTodoFunc(_ context.Context, params *TodoUpdateParams) (string, error) {
// Mock processing logic
return`{"msg": "update todo success"}`, nil
}
// Create tool using InferTool
updateTool, err := utils.InferTool(
"update_todo", // tool name
"Update a todo item, eg: content, deadline...", // tool description
UpdateTodoFunc)第三种则是使用实现工具接口的方式定义工具,对于需要更多自定义逻辑的场景,可以通过实现Tool接口来创建
import (
"context"
"github.com/cloudwego/eino/components/tool"
"github.com/cloudwego/eino/schema"
)
type ListTodoTool struct {}
func (lt *ListTodoTool) Info(ctx context.Context) (*schema.ToolInfo, error) {
return &schema.ToolInfo{
Name: "list_todo",
Desc: "List all todo items",
ParamsOneOf: schema.NewParamsOneOfByParams(map[string]*schema.ParameterInfo{
"finished": {
Desc: "filter todo items if finished",
Type: schema.Boolean,
Required: false,
},
}),
}, nil
}
func (lt *ListTodoTool) InvokableRun(ctx context.Context, argumentsInJSON string, opts ...tool.Option) (string, error) {
// Mock invocation logic
return`{"todos": [{"id": "1", "content": "Prepare the Eino project presentation by December 10, 2024", "started_at": 1717401600, "deadline": 1717488000, "done": false}]}`, nil
}
第四种则是使用官方已经集成的工具,除了自己实现的工具外,官方还提供许多现成的工具。这些工具经过全面测试和优化,可以直接集成到代理中。例如,以 duckduckgo 搜索工具为例:
import (
"github.com/cloudwego/eino-ext/components/tool/duckduckgo"
)
// Create the duckduckgo Search tool
searchTool, err := duckduckgo.NewTool(ctx, &duckduckgo.Config{})这里就对工具有了一个大致的了解,接下来使用一个简单的demo来进行试用,比如我现在有2个工具分别是1.获取当前用户的用户积分,2.判断当前输入的积分可以兑换那些小礼品。
这里我们预制2个用户分别是小a和小b,分别有50分和100分,小礼品则定义5种分别是苹果(5分),月饼(20分),鼠标(50分),pad(100分),电脑(200分),最终实现当用户输入自己的用户名时判断可以兑换那些礼品
package main
import (
"context"
"encoding/json"
"errors"
"fmt"
"io"
"log"
"github.com/cloudwego/eino-ext/components/model/ollama"
"github.com/cloudwego/eino/callbacks"
"github.com/cloudwego/eino/components/model"
"github.com/cloudwego/eino/components/tool"
"github.com/cloudwego/eino/components/tool/utils"
"github.com/cloudwego/eino/compose"
"github.com/cloudwego/eino/flow/agent"
"github.com/cloudwego/eino/flow/agent/react"
"github.com/cloudwego/eino/schema"
)
var userScore map[string]int = map[string]int{
"小a": 50,
"小b": 100,
}
var giftScore map[string]int = map[string]int{
"苹果": 5,
"月饼": 20,
"鼠标": 50,
"pad": 100,
"电脑": 200,
}
// Parameter struct
type GetUserScoreParams struct {
Name string`json:"id" jsonschema:"description=用户名"`
}
// Handler function
func GetUserScore(_ context.Context, params *GetUserScoreParams) (int, error) {
// Mock processing logic
return userScore[params.Name], nil
}
// Parameter struct
type CanExchangeGiftsParams struct {
Score int`json:"score" jsonschema:"description=当前拥有的积分"`
}
// Handler function
func CanExchangeGifts(_ context.Context, params *CanExchangeGiftsParams) ([]string, error) {
// Mock processing logic
var result []string
for giftName, score := range giftScore {
if score <= params.Score {
result = append(result, giftName)
}
}
return result, nil
}
func main() {
ctx := context.Background()
getUsersocre, err := utils.InferTool(
"获取用户积分", // tool name
"获取用户的积分,需要传入用户的name,返回用户当前拥有的积分", // tool description
GetUserScore)
if err != nil {
panic(err)
}
canExchangeGift, err := utils.InferTool(
"积分能够兑换的礼物", // tool name
"获取当前用户积分能够兑换的礼物,返回能够兑换的礼物的列表", // tool description
CanExchangeGifts)
if err != nil {
panic(err)
}
Tools := []tool.BaseTool{
getUsersocre,
canExchangeGift,
}
chatModel := createOllamaChatModel(ctx)
var toolsInfo []*schema.ToolInfo
for _, tools := range Tools {
info, err := tools.Info(ctx)
if err != nil {
log.Fatalf("get tool info failed: %v", err)
}
toolsInfo = append(toolsInfo, info)
}
ragent, err := react.NewAgent(ctx, &react.AgentConfig{
ToolCallingModel: chatModel,
ToolsConfig: compose.ToolsNodeConfig{
Tools: Tools,
},
// StreamToolCallChecker: toolCallChecker, // uncomment it to replace the default tool call checker with custom one
})
if err != nil {
panic(err)
}
opt := []agent.AgentOption{
agent.WithComposeOptions(compose.WithCallbacks(&LoggerCallback{})),
//react.WithChatModelOptions(ark.WithCache(cacheOption)),
}
persona := `# Character:
你是积分管理助手,根据用户的需要,通过工具查询用户当前的积分或者通过工具获取用户可以兑换的礼物。请严格根据实际的查询进行回答不要编造信息。
`
message, err := ragent.Generate(ctx, []*schema.Message{
{
Role: schema.System,
Content: persona,
},
{
Role: schema.User,
Content: "我是小a,我现在知道我有多少积分,能够兑换那些礼物",
},
}, opt...)
if err != nil {
log.Fatalf("failed to stream: %v", err)
return
}
log.Printf("%v", message)
log.Printf("\n\n===== finished =====\n")
}
func createOllamaChatModel(ctx context.Context) model.ToolCallingChatModel {
chatModel, err := ollama.NewChatModel(ctx, &ollama.ChatModelConfig{
BaseURL: "http://localhost:11434", // Ollama 服务地址
Model: "qwen2.5:7b", // 模型名称
})
if err != nil {
log.Fatalf("create ollama chat model failed: %v", err)
}
return chatModel
}
type LoggerCallback struct {
callbacks.HandlerBuilder // 可以用 callbacks.HandlerBuilder 来辅助实现 callback
}
func (cb *LoggerCallback) OnStart(ctx context.Context, info *callbacks.RunInfo, input callbacks.CallbackInput) context.Context {
fmt.Println("==================")
inputStr, _ := json.MarshalIndent(input, "", " ")
fmt.Printf("[OnStart] %s\n", string(inputStr))
return ctx
}
func (cb *LoggerCallback) OnEnd(ctx context.Context, info *callbacks.RunInfo, output callbacks.CallbackOutput) context.Context {
fmt.Println("=========[OnEnd]=========")
outputStr, _ := json.MarshalIndent(output, "", " ")
fmt.Println(string(outputStr))
return ctx
}
func (cb *LoggerCallback) OnError(ctx context.Context, info *callbacks.RunInfo, err error) context.Context {
fmt.Println("=========[OnError]=========")
fmt.Println(err)
return ctx
}
func (cb *LoggerCallback) OnEndWithStreamOutput(ctx context.Context, info *callbacks.RunInfo,
output *schema.StreamReader[callbacks.CallbackOutput]) context.Context {
var graphInfoName = react.GraphName
gofunc() {
deferfunc() {
if err := recover(); err != nil {
fmt.Println("[OnEndStream] panic err:", err)
}
}()
defer output.Close() // remember to close the stream in defer
fmt.Println("=========[OnEndStream]=========")
for {
frame, err := output.Recv()
if errors.Is(err, io.EOF) {
// finish
break
}
if err != nil {
fmt.Printf("internal error: %s\n", err)
return
}
s, err := json.Marshal(frame)
if err != nil {
fmt.Printf("internal error: %s\n", err)
return
}
if info.Name == graphInfoName { // 仅打印 graph 的输出, 否则每个 stream 节点的输出都会打印一遍
fmt.Printf("%s: %s\n", info.Name, string(s))
}
}
}()
return ctx
}
func (cb *LoggerCallback) OnStartWithStreamInput(ctx context.Context, info *callbacks.RunInfo,
input *schema.StreamReader[callbacks.CallbackInput]) context.Context {
defer input.Close()
return ctx
}

这里最终可以看到获取到了当前用户小a能够兑换的礼物和积分,以及当我是小b的时候能够兑换的礼物
五、未来展望
可以预见,在未来我们可以看到更多的语言的AI开发框架诞生,不仅仅限制某几个语言上,这将更大程度的降低AI相关开发的门槛,也能够吸引更多的开发者进入AI的浪潮中。
其次像Coze以及Eino的开源也能够给AI从业者提供更多的选择,并且相信他们能够吸收更多其他好的AI开发框架的优点未来能够做的更好。
版权声明:本文由神州数码云基地团队整理撰写,若转载请注明出处。
公众号搜索神州数码云基地,回复【AI】进入AI社群讨论。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 31
31 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)