深入了解RUST迭代器 - 惰性、可组合的处理
迭代器 - 深入了解惰性、可组合的处理
在本篇文章中,我们将深入探讨迭代器,尝试展示其处理数据的惰性求值和可组合性。
迭代器是 Rust 最强大的抽象之一,它提供了一种零成本的方式来处理数据序列。
它们结合了函数式编程的优雅和系统编程的效率,理解它们对于编写地道的 Rust 代码至关重要。
The Iterator Trait
Rust 迭代器系统的核心是 Iterator trait,它定义了如何生成一系列值。
这个特性出奇地简单,只需要实现一个方法:

Item 关联的类型指定迭代器生成的值的类型。
这是一种通用关联类型 (GAT,Generic Associated Type) 的形式 ,允许每个迭代器实现定义自己的item类型,而无需使用者显式指定。
next() 方法才是关键所在——它为序列中的每个元素返回 Some(value) , 当迭代器耗尽时返回 None 。
一个简单的自定义迭代器示例可以是 0 到 max 的计数器。
让我们创建结构体并为其实现 Iterator trait。
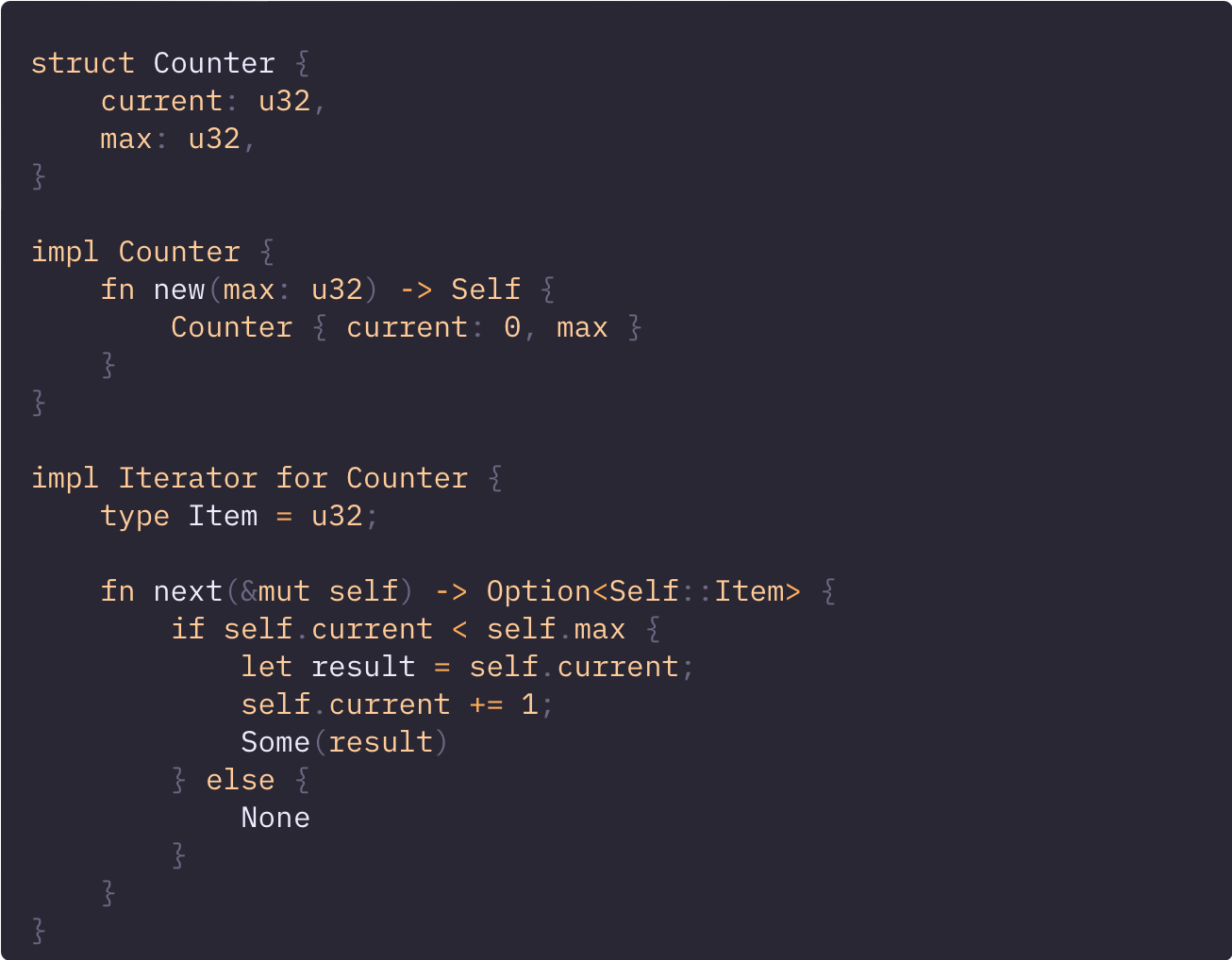
好了,现在开始使用它吧:
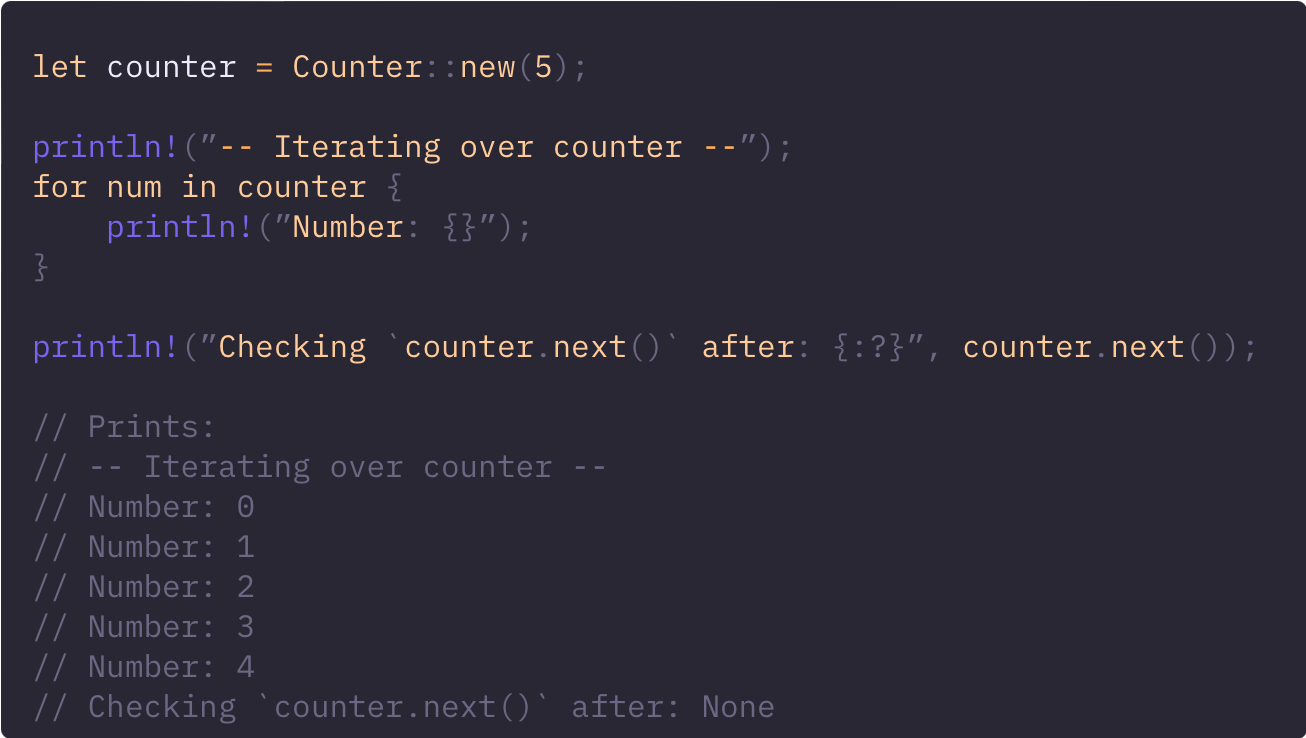
如上图,Iterator 特性是一个强大的抽象,它使我们能够以灵活高效的方式处理数据序列。
现在我们已经了解了 Iterator trait 的基础知识,让我们深入了解 Rust 的迭代器系统。
迭代器有何特殊之处?
Rust 中的迭代器本质上是惰性的——它们在被使用之前什么也不做。
这种惰性使得编译器能够将迭代器链优化成紧凑、高效的循环,其性能可与手写的过程代码相媲美。
当链式调用 map()、filter() 或 fold() 等操作时,Rust 只会对数据进行一次遍历,从而确保高效的处理。
Rust 中的迭代器由 Iterator trait 定义,该 trait 只需要实现一个方法:next()。此方法指定如何推进迭代器并返回下一个元素。
这种简洁性使得任何类型都能轻松实现迭代。它还赋予我们灵活性,可以根据需要指定迭代的内部逻辑,从而将其与面向用户的 API 解耦。
创建迭代器的三种方法
Rust 提供了三种从集合创建迭代器的主要方法,每种方法都提供了不同的所有权语义。
这些方法在处理借用和所有权方面有所不同,可以根据使用情况选择合适的方法。
iter() 方法允许遍历集合,同时将每个元素作为不可变引用借用。
这种方法确保只读访问,防止在遍历过程中意外修改。

into_iter() 方法允许遍历集合,同时 move 每个元素的所有权,这就是
into的语义。这种方法可以高效地使用集合,避免不必要的克隆,因为它直接将元素移动到迭代器中。

iter_mut() 方法允许你遍历集合,同时为每个元素提供可变引用。
这样就可以在迭代过程中直接修改元素,这对于无需创建新集合即可进行就地更新非常有用。

Transforming Iterators (转换迭代器)
Rust 中的迭代器提供了多种转换项的方法,从而实现了强大的数据处理管道。
例如, map(fn) 和 filter(fn) 等方法允许开发人员将函数应用于每个元素或选择性地处理数据,从而简化复杂的操作而无需手动循环。
map(fn) 会生成一个迭代器,该迭代器会将传入的函数应用于每个元素:

filter(fn) 生成一个迭代器,确保只迭代满足谓词(predicate )的元素:

当然,适配器很容易串联起来,从而可以构建更复杂的管道:

Consuming Iterators (消费迭代器)
由于 Rust 中的迭代器具有惰性,因此需要将其转换为特定类型才能产生结果,这通常使用诸如 collect() 之类的内置方法来实现 。
这种方法通过将计算延迟到需要时才进行,从而确保了高效的内存使用。
collect() 将迭代器的元素累加到指定类型或隐式确定的类型中。

fold() 函数使用指定的初始值和累加函数将迭代器的元素转换为累加值。(fold 是折叠的意思,意味着累加)

Iterator trait 包含额外的内置方法,使我们能够避免重新实现基本功能,例如数字的求和或乘积(类似于我们上面使用 fold(initial, fn) 的实现)。

Reshaping Iterators (重塑迭代器)
此外,迭代器还提供了强大的适配器,可以修改数据流本身的结构和顺序。
这些适配器能够实现高效的转换,而不会过早地消耗原始迭代器。
step_by() 函数通过根据指定的步长跳过项目来修改迭代器的遍历方式。
这种方法可以让你高效地处理每第 n 个元素。

rev() 反转迭代器的遍历方向。
这种方法特别有用,因为它不会修改原始集合。

enumerate() 方法通过将每个项目包装在一个元组中来修改遍历,其中项目的索引位于第一个位置。
这样,你就可以在迭代过程中访问索引和值,这对于诸如给集合中的元素编号之类的任务非常有用。

zip(iterator) 将两个迭代器合并成一个元组迭代器,将每个迭代器中的元素配对。(zip 是拉链的意思,意味着把拉链2边的齿配对)
当较短的迭代器耗尽时,该函数停止运行,从而确保不会因长度不匹配而导致 panic。

示例:
最后,让我们来看一个稍微复杂一些的 Deltas 迭代器示例,它可以计算每个元素到其 上次出现位置 的距离。(Delta (Δ, δ) 是希腊字母表中的第四个字母,通常用于表示变化或差异)
了解需求后,我们可以创建一个测试来验证其功能:

之后,我们就可以着手实现 Deltas struct了。
该结构体包装了一个传递给它的迭代器,并通过对其调用 .enumerate() 来修改它 。

现在我们有了 Deltas struct,剩下的唯一一件事就是为其实现 Iterator trait。
next() 方法才是真正发挥作用的地方。在这里,我们会修改迭代器。
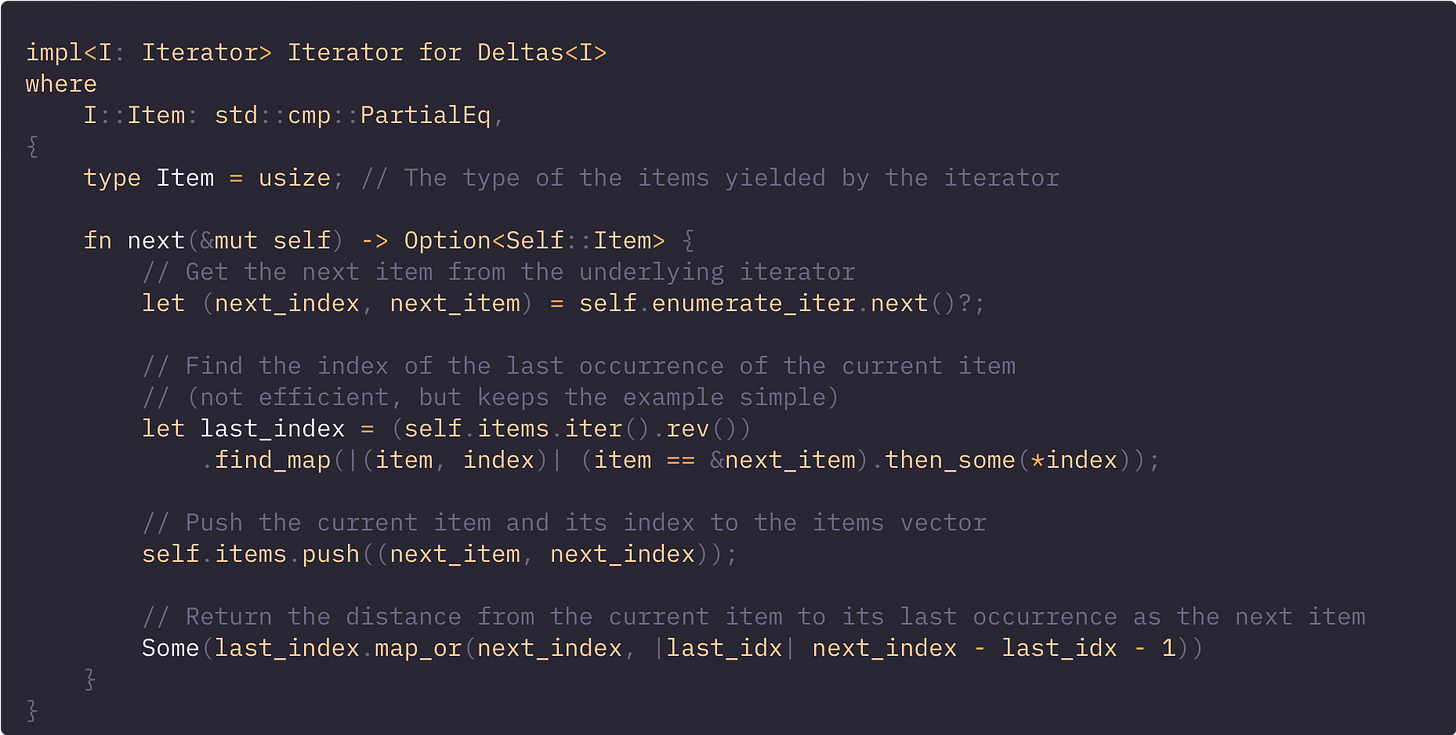
OK!我们实现了一个惰性迭代器,它可以计算每个元素到其上一次出现位置的距离。
我们知道,next() 方法的具体实现对用户是隐藏的。这使得我们可以在不破坏约定的情况下修改底层迭代器。
让我们利用这一点,通过去掉 Vec 而改用 HashMap 来提高迭代器的效率。
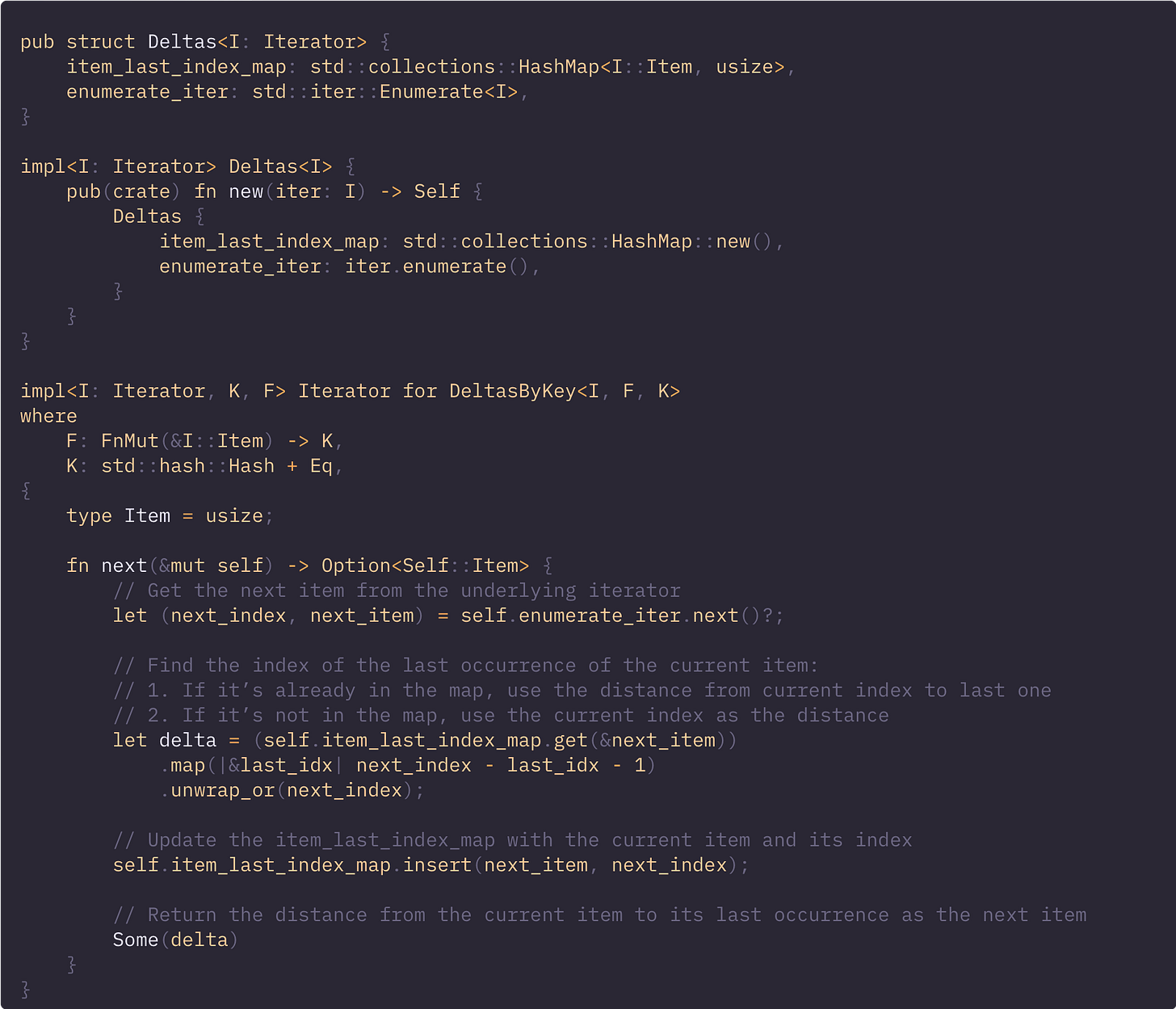
要点总结
Rust 迭代器代表了我们处理序列方式的根本性转变,它将函数式编程的优雅与 系统编程的 性能 结合起来。
它们默认是惰性的 ,可以高效地链接操作,最终编译成最优的机器代码。
理解 iter() 、 into_iter() 和 iter_mut() 之间的区别对于正确管理所有权至关重要。
借助 map() 、 filter() 和 fold() 等迭代器适配器 ,复杂的数据转换变得简洁而富有表现力。
最重要的是,迭代器不仅仅是语法糖——它们是一种零成本的抽象 ,鼓励编写更安全、更易于维护的代码,而不会牺牲性能。
相关文章:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)