[智能体设计模式] 第8章 记忆管理
智能体的记忆,是其保留并利用过去交互、观察和学习经验的信息能力。这一能力让智能体能够做出明智决策、保持对话上下文连贯性,并持续提升自身性能,是智能体超越基础问答、实现高阶智能行为的关键。当对话过长时,会超出上下文窗口,# 初始化摘要记忆组件(需指定 LLM 用于生成摘要)llm=llm,# 构建链llm=llm,# 模拟长对话print("=== 长对话摘要记忆示例 ===")
一、核心定义:智能体记忆的本质
智能体的记忆,是其保留并利用过去交互、观察和学习经验的信息能力。这一能力让智能体能够做出明智决策、保持对话上下文连贯性,并持续提升自身性能,是智能体超越基础问答、实现高阶智能行为的关键。
二、记忆的两大核心分类(LangChain 视角)
LangChain 中智能体的记忆同样分为短期记忆和长期记忆,二者功能互补,共同支撑智能体的完整信息处理流程:
(一)短期记忆(上下文记忆)
- 核心定位:类似人类的工作记忆,专门保存当前会话中正在处理或最近访问的临时信息。
- 实现形式:依托 LLM 的上下文窗口,通过 LangChain 提供的对话记忆组件,自动存储最近的用户消息、智能体回复、工具调用结果等,直接影响模型的后续响应。
- 关键局限:上下文窗口容量有限,信息仅在当前会话内有效,会话结束后会丢失;完整历史若超出窗口容量,可能导致响应错误或性能下降。
- 优化方式:LangChain 提供多种记忆策略(如摘要记忆、滚动窗口记忆),通过提炼关键信息、丢弃冗余内容,在有限窗口内保留核心上下文。
(二)长期记忆(持久记忆)
- 核心定位:跨会话、长周期的信息仓库,用于存储用户偏好、领域知识、历史交互记录等需要持久化的内容。
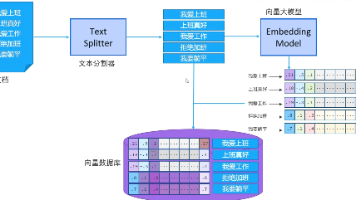
- 存储形式:通过 LangChain 集成的外部存储组件(向量数据库、关系型数据库、文件系统等)实现持久化,其中向量数据库是主流选择,支持语义相似度检索(而非关键词精确匹配),适配自然语言交互场景。
- 工作逻辑:智能体需调用长期记忆时,通过 LangChain 的检索接口查询外部存储,将相关数据加载到短期上下文窗口中,实现新旧知识的融合。
- 核心价值:支持个性化交互、跨会话信息回溯、知识库沉淀,是智能体从“单次对话”升级为“持续服务”的关键。
三、典型应用场景
记忆管理在 LangChain 驱动的智能体场景中不可或缺,核心应用包括:
- 对话式 AI/聊天机器人:短期记忆保障单会话内的对话连贯性,长期记忆存储用户偏好(如“喜欢简洁回复”)、历史问题(如“之前咨询过Python入门”),实现跨会话个性化交互。
- 任务型智能体:短期记忆跟踪多步骤任务进度(如“已完成数据抓取,待进行分析”),长期记忆调取任务相关的历史配置(如“用户上次设置的分析维度”)或领域知识。
- 个性化服务工具:如智能助手、推荐系统,通过长期记忆存储用户行为数据(如“经常查询AI趋势”)、个人信息(如“所在行业为互联网”),生成定制化响应和建议。
- 自学习智能体:将成功的任务执行策略、错误经验、新学习的知识存入长期记忆,持续优化自身性能(如客服智能体记住常见问题的最优回复)。
- 检索增强生成(RAG):长期记忆作为知识库,通过 LangChain 的 RAG 组件,让智能体在回答时检索相关文档/数据,提升回答的准确性和丰富度。
- 多智能体协作:短期记忆共享当前协作进度,长期记忆存储协作历史、角色分工规则,保障跨会话协作的连贯性。
四、LangChain 记忆管理实战代码
LangChain 提供了丰富的记忆组件,涵盖短期上下文管理、长期持久化存储、RAG 集成等场景,以下是核心用法示例:
(一)短期记忆:会话内上下文管理
LangChain 提供多种短期记忆组件,其中 ConversationBufferMemory 适合简单场景(完整保留历史),ConversationSummaryMemory 适合长对话(摘要压缩历史),ConversationBufferWindowMemory 适合控制窗口大小(仅保留最近 N 轮)。
1. 基础示例:ConversationBufferMemory(完整保留历史)
# 安装依赖
# pip install langchain langchain-openai python-dotenv
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder, SystemMessagePromptTemplate, HumanMessagePromptTemplate
# 加载环境变量(需配置 OPENAI_API_KEY)
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# 1. 初始化 LLM
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.3)
# 2. 定义提示模板(包含历史消息占位符)
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template("你是一名友好的智能助手,善于结合历史对话回应用户。"),
MessagesPlaceholder(variable_name="chat_history"), # 存储对话历史的占位符
HumanMessagePromptTemplate.from_template("{question}") # 用户新问题
]
)
# 3. 初始化短期记忆组件(return_messages=True 适配 Chat Model)
memory = ConversationBufferMemory(
memory_key="chat_history", # 与提示模板的 variable_name 对应
return_messages=True # 返回结构化消息对象(而非字符串),提升 Chat Model 效果
)
# 4. 构建链(集成 LLM、提示模板、记忆组件)
conversation_chain = LLMChain(
llm=llm,
prompt=prompt,
memory=memory,
verbose=True # 打印详细日志(可选)
)
# 5. 模拟多轮对话
print("=== 多轮对话示例 ===")
response1 = conversation_chain.predict(question="你好,我是小明,喜欢研究AI工具。")
print(f"助手:{response1}\n")
response2 = conversation_chain.predict(question="我想了解LangChain的记忆功能,能简单介绍下吗?")
print(f"助手:{response2}\n")
response3 = conversation_chain.predict(question="你还记得我叫什么名字、喜欢什么吗?")
print(f"助手:{response3}\n")
# 查看当前记忆中的内容
print("=== 记忆中的对话历史 ===")
print(memory.load_memory_variables({}))
2. 优化示例:ConversationSummaryMemory(摘要压缩历史)
当对话过长时,ConversationBufferMemory 会超出上下文窗口,ConversationSummaryMemory 可自动将早期对话摘要压缩,节省窗口空间:
from langchain.memory import ConversationSummaryMemory
# 初始化摘要记忆组件(需指定 LLM 用于生成摘要)
summary_memory = ConversationSummaryMemory(
llm=llm,
memory_key="chat_history",
return_messages=True
)
# 构建链
summary_chain = LLMChain(
llm=llm,
prompt=prompt,
memory=summary_memory,
verbose=True
)
# 模拟长对话
print("=== 长对话摘要记忆示例 ===")
summary_chain.predict(question="LangChain是一个用于构建LLM应用的框架,支持记忆、工具调用、RAG等功能。")
summary_chain.predict(question="它的记忆组件有很多种,比如ConversationBufferMemory、ConversationSummaryMemory等。")
summary_chain.predict(question="我现在需要开发一个智能助手,需要跨会话记住用户偏好,应该用哪种记忆组件?")
# 查看摘要后的记忆内容
print("\n=== 摘要后的记忆 ===")
print(summary_memory.load_memory_variables({}))
3. 精准控制:ConversationBufferWindowMemory(保留最近 N 轮)
仅保留最近指定轮次的对话,避免历史冗余:
from langchain.memory import ConversationBufferWindowMemory
# 初始化窗口记忆(仅保留最近2轮对话)
window_memory = ConversationBufferWindowMemory(
memory_key="chat_history",
return_messages=True,
k=2 # k 表示保留的轮次
)
# 构建链
window_chain = LLMChain(
llm=llm,
prompt=prompt,
memory=window_memory,
verbose=True
)
# 模拟多轮对话
print("=== 窗口记忆示例 ===")
window_chain.predict(question="第一轮对话:我想问LangChain的安装步骤。")
window_chain.predict(question="第二轮对话:安装完成后如何初始化LLM?")
window_chain.predict(question="第三轮对话:现在我忘了第一轮问的是什么,你还记得吗?")
# 查看记忆内容(仅保留第2、3轮)
print("\n=== 窗口记忆中的内容 ===")
print(window_memory.load_memory_variables({}))
(二)长期记忆:跨会话持久化存储
LangChain 通过 BaseStore 接口集成多种外部存储,实现长期记忆的持久化。以下示例使用 InMemoryStore(本地测试)和 Chroma(向量数据库,生产常用),结合命名空间实现用户级、应用级记忆隔离。
1. 基础示例:InMemoryStore(本地持久化)
from langgraph.store.memory import InMemoryStore
# 定义简单嵌入函数(实际生产用真实嵌入模型,如 OpenAIEmbeddings)
def embed(texts: list[str]) -> list[list[float]]:
"""模拟文本嵌入(生成2维向量)"""
return [[0.1 * i, 0.2 * i] for i in range(len(texts))]
# 1. 初始化长期存储(指定嵌入函数和向量维度)
long_term_store = InMemoryStore(
index={"embed": embed, "dims": 2} # dims 需与嵌入向量维度一致
)
# 2. 定义命名空间(用于隔离不同用户/应用场景,类似文件夹)
user_id = "xiaoming" # 用户名作为命名空间一部分
app_context = "ai_assistant" # 应用场景
namespace = (user_id, app_context) # 命名空间:(用户ID, 应用场景)
# 3. 存储用户长期记忆(如偏好、个人信息)
long_term_store.put(
namespace=namespace,
key="user_preferences", # 记忆唯一标识
value={
"name": "小明",
"interests": ["AI工具", "LangChain", "RAG"],
"preferences": ["回复简洁", "优先推荐官方文档", "避免专业术语堆砌"]
}
)
# 4. 检索长期记忆
retrieved_memory = long_term_store.get(namespace=namespace, key="user_preferences")
print("=== 检索用户长期偏好 ===")
print(retrieved_memory) # 返回 [(key, value)] 格式
# 5. 语义搜索(根据关键词匹配相关记忆)
search_results = long_term_store.search(
namespace=namespace,
query="用户喜欢的AI相关领域", # 自然语言查询
filter={"preferences": "回复简洁"} # 过滤条件(可选)
)
print("\n=== 语义搜索结果 ===")
for result in search_results:
print(f"匹配记忆:{result.value}")
2. 生产级示例:Chroma 向量数据库(持久化+语义检索)
Chroma 是轻量型向量数据库,适合生产环境存储长期记忆,支持高效语义检索:
# 安装依赖
# pip install chromadb langchain-community
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain.schema import Document
# 1. 初始化嵌入模型(真实生产用)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 2. 初始化 Chroma 向量数据库(持久化存储到本地目录)
chroma_db = Chroma(
collection_name="user_long_term_memory", # 集合名(类似表名)
embedding_function=embeddings,
persist_directory="./chroma_db" # 本地存储目录(持久化)
)
# 3. 存储用户长期记忆(以 Document 格式存储)
user_memories = [
Document(
page_content="用户姓名:小明,兴趣:AI工具、LangChain、RAG,偏好:回复简洁、优先推荐官方文档",
metadata={"user_id": "xiaoming", "type": "preferences"}
),
Document(
page_content="用户历史问题:如何安装LangChain?如何实现跨会话记忆?",
metadata={"user_id": "xiaoming", "type": "history_questions"}
)
]
chroma_db.add_documents(documents=user_memories)
# 4. 持久化数据库(确保数据写入磁盘)
chroma_db.persist()
# 5. 语义检索(跨会话调取用户记忆)
query = "小明的兴趣是什么?"
retrieved_docs = chroma_db.similarity_search(
query=query,
k=2, # 返回Top2相似结果
filter={"user_id": "xiaoming"} # 仅检索小明的记忆
)
print("=== Chroma 向量数据库检索结果 ===")
for doc in retrieved_docs:
print(f"内容:{doc.page_content}")
print(f"元数据:{doc.metadata}\n")
# 6. 集成到智能体链(RAG+记忆)
from langchain.chains import RetrievalQAWithSourcesChain
# 构建检索增强链(结合LLM和向量数据库)
rag_chain = RetrievalQAWithSourcesChain.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=chroma_db.as_retriever(),
verbose=True
)
# 提问(智能体从长期记忆中检索答案)
response = rag_chain({"question": "小明喜欢什么样的回复风格?"})
print("\n=== RAG+长期记忆回复 ===")
print(f"答案:{response['answer']}")
print(f"来源:{response['sources']}")
(三)高级应用:短期+长期记忆协同
结合短期上下文记忆和长期持久化记忆,实现“会话内连贯+跨会话个性化”的完整体验:
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.memory import ConversationBufferMemory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# 1. 初始化组件
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.3)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
chroma_db = Chroma(
collection_name="user_long_term_memory",
embedding_function=embeddings,
persist_directory="./chroma_db"
)
retriever = chroma_db.as_retriever()
# 2. 短期记忆(会话内上下文)
short_term_memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True,
output_key="answer" # 与链的输出键对应
)
# 3. 定义融合短期+长期记忆的提示模板
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template("""
你是智能助手,需结合两部分信息回应用户:
1. 短期记忆(chat_history):当前会话的历史对话;
2. 长期记忆(context):用户的长期偏好、历史信息。
回复需自然、个性化,符合用户偏好。
"""),
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("""
问题:{question}
长期记忆参考:{context}
""")
]
)
# 4. 构建协同链
from langchain.chains import SequentialChain
# 第一步:检索长期记忆
retrieval_chain = RetrievalQAWithSourcesChain.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
output_key="context" # 检索结果作为上下文
)
# 第二步:结合短期记忆和长期记忆生成回复
response_chain = LLMChain(
llm=llm,
prompt=prompt,
memory=short_term_memory,
output_key="answer"
)
# 串联两步链
combined_chain = SequentialChain(
chains=[retrieval_chain, response_chain],
input_variables=["question"],
output_variables=["answer", "context"],
verbose=True
)
# 5. 测试协同效果
print("=== 短期+长期记忆协同示例 ===")
response1 = combined_chain.run(question="我想了解LangChain的记忆组件,你能简单介绍下吗?")
print(f"助手:{response1}\n")
response2 = combined_chain.run(question="你还记得我喜欢什么样的回复风格吗?")
print(f"助手:{response2}\n")
response3 = combined_chain.run(question="结合我的偏好,推荐一个适合我的记忆组件吧。")
print(f"助手:{response3}\n")
五、核心总结
LangChain 的记忆管理体系围绕“短期保上下文、长期存知识”构建,核心亮点如下:
- 短期记忆灵活适配:提供
ConversationBufferMemory(完整保留)、ConversationSummaryMemory(摘要压缩)、ConversationBufferWindowMemory(窗口控制)等组件,适配不同对话长度和场景需求。 - 长期记忆持久化:支持 Chroma、FAISS、PostgreSQL 等多种外部存储,通过命名空间实现用户/场景隔离,结合语义检索提升记忆调取效率。
- 协同工作流:短期记忆保障会话内连贯性,长期记忆支撑跨会话个性化,二者可通过链串联实现协同,满足复杂智能体的需求。
实际开发中,需根据场景选择合适的记忆组件:
- 短对话、需完整上下文 →
ConversationBufferMemory; - 长对话、需节省窗口空间 →
ConversationSummaryMemory; - 需精准控制历史范围 →
ConversationBufferWindowMemory; - 跨会话个性化、知识库沉淀 → 向量数据库(Chroma/FAISS)+ 长期记忆存储。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)