Stable Diffusion详解
Stable Diffusion是一种基于潜在扩散模型的AI图像生成技术,由Stability AI等团队开发并于2022年开源。它通过扩散过程(加噪/去噪)在潜空间中进行高效运算,大幅降低计算需求。核心组件包括CLIP文本编码器、U-Net去噪网络和VAE解码器,支持文生图、图生图等功能。主要优势包括快速出图(3秒/张)、本地运算保障数据安全、强大的可扩展性(支持110+插件)。该技术在创意设计
Stable Diffusion详解
一、Stable Diffusion 简介
Stable Diffusion(简称 SD)是由 Stability AI、CompVis 和 Runway 团队合作开发的一种潜在扩散模型。它于 2022 年 8 月正式开源,具有出图快、扩展性强、数据安全等特点。
二、Stable Diffusion 的核心概念
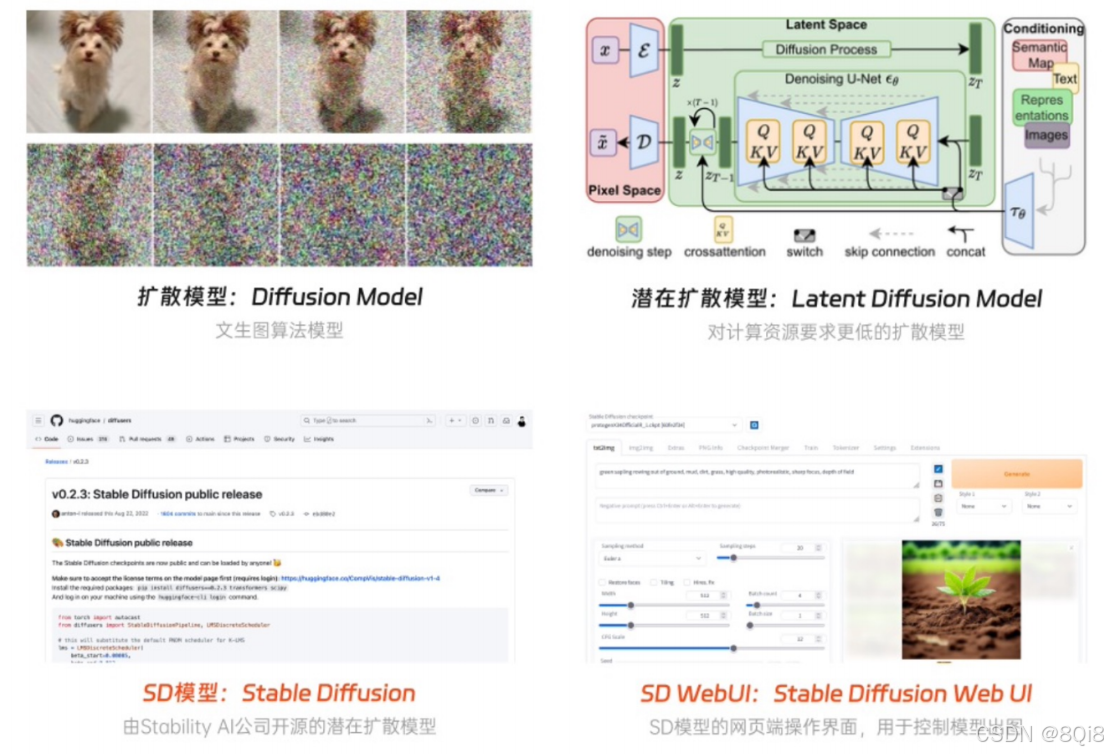
1. 扩散模型(Diffusion Model)
扩散模型是一种生成式模型,其核心思想是:
- 正向过程:对图像逐步添加高斯噪声,直到图像完全变为噪声。
- 反向过程:从噪声中逐步恢复出原始图像。
2. 潜在扩散模型(Latent Diffusion Model)
为了解决扩散模型在像素空间中计算量大的问题,潜在扩散模型先将图像压缩到潜空间,再进行扩散过程,大大减少了计算量和内存需求。
3. Stable Diffusion WebUI
提供了一个图形化界面,用户无需编写代码即可操作模型生成图像。
三、Stable Diffusion 的特点
1. 可拓展性强
- 开源模型与代码,支持自定义学习与创作。
- 集成超过 110 种插件,支持局部重绘、姿势控制、高清修复等功能。
2. 出图速度快
- 本地部署,依赖本地显卡算力,无需排队。
- 支持 3 秒/张 的高效出图。
3. 数据安全
- 所有图像生成过程在本地完成,避免数据上传到云端,保护用户隐私。
四、Stable Diffusion 的工作原理

1. 扩散过程
- 加噪:逐步向图像添加噪声,模拟“墨汁扩散”过程。
- 去噪:逐步从噪声中恢复图像,即逆向降噪。

2. 潜空间运算
Stable Diffusion 在潜空间中进行扩散过程,显著降低了计算复杂度。
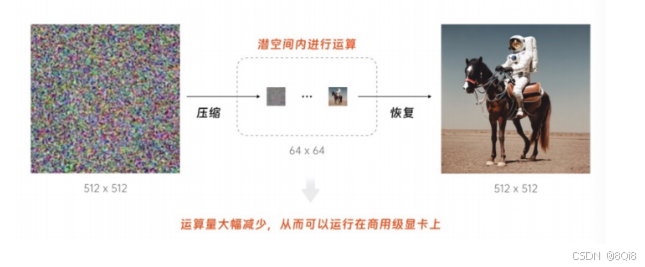
3. 整体运行流程
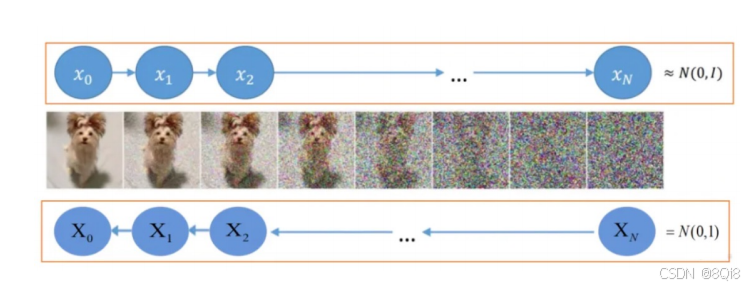
4. Diffusion模型的原理

五、Stable Diffusion 的架构
Stable Diffusion 由三个核心组件构成: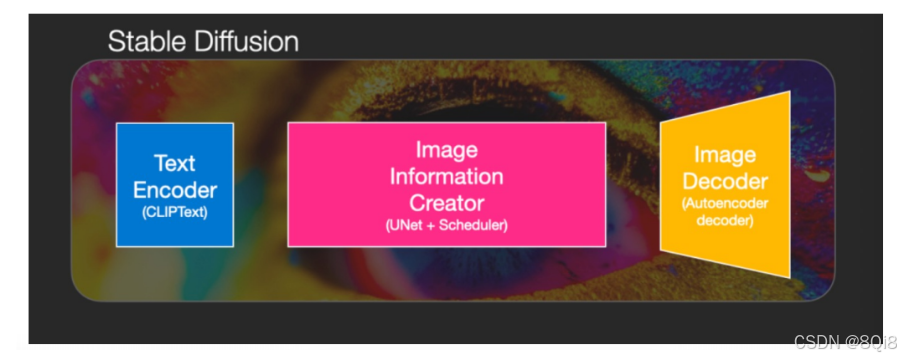
1. CLIP Text Encoder
-
将文本提示词转换为 768 维向量。
-
使用对比学习训练,理解文本与图像的关系。
-
ClipText ⽂本编码器:
首先训练一个处理图像的 CNN 和一个处理文本的Transformer 模型,来预测图像的caption。
对比学习阶段:给定一个 Batch 的 N 个 (图片,文本) 对,图片输入给 Image Encoder 得到表征 I1,I2,…,In,文本输入给 Text Encoder 得到表征 T1,T2,…,Tn,其中 (Ij,Tj)属于是正样本,(Ij,Tk)属于负样本。最大化 N 个正样本的Cosine 相似度,最小化N^2−N个负样本的 Cosine 相似度。
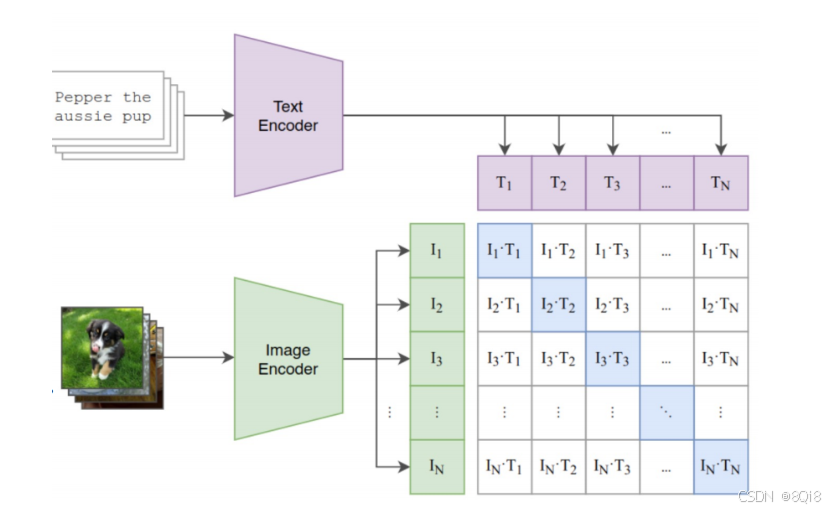
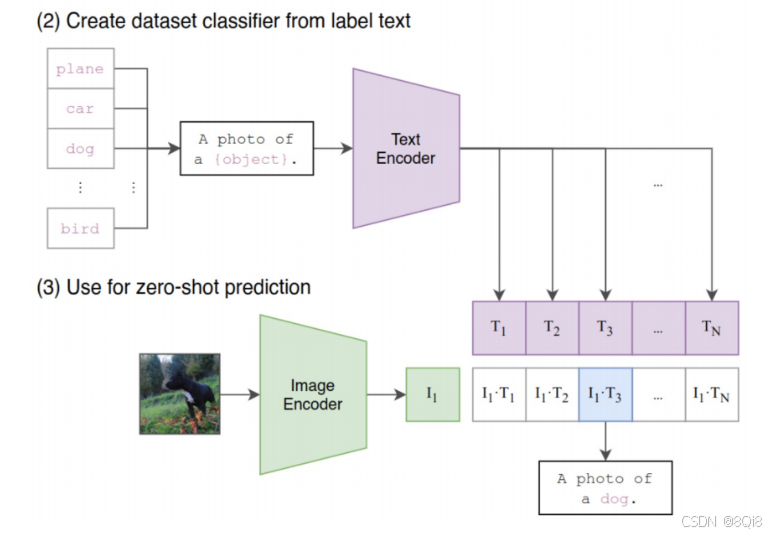
Zero-Shot Transfer:这个阶段是使用 CLIP 的预训练好的 Image Encoder 和 Text Encoder 来做Zero-Shot Transfer。比如来一张 ImageNet-1K 验证集的图片,可以使用CLIP 预训练好的模型能完成这个分类的任务。模型的参数是冻结的,在图像生成过程中参数是不会发生变化的。
2. U-Net + Scheduler(图像信息生成器)
U-Net 原本是用于生物医学图像分割的神经网络模型,因为工作结构像一个 U 型字母,因此被称为 U 型神经网络训练模型。在扩散模型中,U-Net 可以辅助提取并解构训练图像的特征,有了它就能在较少训练样本的情况下获得更加准确多样的数据信息,从而使模型在出图结果上更加精确。

- U-Net:提取图像特征,辅助去噪。
- Scheduler:控制去噪步骤与采样算法。Scheduler 就是用来定义使用哪种算法来运行程序,它可以定义降噪的步骤、是否具备随机性、查找去噪后样本的算法等,因此它又被称为采样算法。
3. VAE 解码器
全称是 Variational Auto Encoder 变分自动编码器。简单来说,它的作用就是将高维数据(像素空间)映射到低维空间(潜空间),从而实现数据的压缩和降维。它由编码器(Encoder)和解码器(Decoder)两部分组成,编码器用于将图像信息降维并传入潜空间中,解码器将潜在数据表示转换回原始图像,而在潜在扩散模型的推理生成过程中我们只需用到 VAE 的解码器部分。

六、Stable Diffusion 的文生图流程
- 生成随机潜空间张量(受随机种子控制)
- U-Net 结合文本提示预测噪声
- 逐步去噪,重复多次(如 50 步)
- VAE 解码器将潜图像转换为最终图像

七、Stable Diffusion 的应用场景
1. 文生图(Text-to-Image)
将文本描述转换为图像,增强视觉表达能力。
2. 图生图(Image-to-Image)
基于原图与提示词进行二次创作,控制生成结果。
3. 图像修复(Inpainting)
替换或填充图像中指定区域,实现自然修复。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)