yolov10的注意力机制改进:高效多头自注意力(EfficientMultiheadAttention)
本文提出了一种结合小波变换与注意力机制的新型模块WaveletDomainAttention(WDA),通过离散小波变换将输入特征分解为多频带分量,利用注意力机制自适应加权各频带信息后重建特征。该模块具有频域局部化和动态加权的优势,能有效增强纹理特征提取。研究详细介绍了在YOLOv10中的两种改进方案:一是在骨干网络中直接嵌入WDA模块,二是构建PSA_WDA模块替代原有PSA结构以控制计算量。实
一、简介
高效多头自注意力(EfficientMultiheadAttention)是一种专为计算机视觉设计的轻量级注意力机制。其通过通道维度的下采样 - 上采样操作优化计算开销:首先使用 1×1 卷积将输入通道数 C 按缩减比率 r(如 4 倍)压缩至 C/r,在降维后的特征空间执行多头自注意力计算,最后通过 1×1 卷积上采样恢复原始通道维度 C。该设计将计算复杂度从标准自注意力的 O ((HW)²・C) 降至 O ((HW)²・(C/r)),同时保留有效的全局依赖建模能力。EfficientMultiheadAttention的多头注意力架构,将降维特征均匀划分为多个头,使每个头独立学习不同子空间的注意力模式,并行捕获多样化特征交互。
二、EfficientMultiheadAttention的实现代码
import torch.nn as nn
import torch
class EfficientMultiheadAttention(nn.Module):
def __init__(self, channels, heads=8, reduction_ratio=4):
super().__init__()
self.heads = heads
self.reduction_ratio = reduction_ratio
# 下采样减少计算量
self.downsample = nn.Conv2d(channels, channels//reduction_ratio, 1)
self.attention = nn.MultiheadAttention(
embed_dim=channels//reduction_ratio,
num_heads=heads,
batch_first=True
)
self.upsample = nn.Conv2d(channels//reduction_ratio, channels, 1)
def forward(self, x):
batch, C, H, W = x.shape
# 下采样
x_down = self.downsample(x)
# 重塑为序列格式 (B, C, H*W) -> (B, H*W, C)
x_flat = x_down.view(batch, -1, H*W).transpose(1, 2)
# 自注意力
attended, _ = self.attention(x_flat, x_flat, x_flat)
# 恢复空间维度
attended = attended.transpose(1, 2).view(batch, -1, H, W)
# 上采样
out = self.upsample(attended)
return out三、在yolov10中改进
以下改进均在yolov10s.yaml文件中修改
3.1 改进一:
改进方法:直接嵌入到骨干网络(backbone)中,将模块放入到C2fCIB模块和SPPF模块之间,选择该位置原因:相比浅层,此时特征图更小,计算量更加可控,且深层特征包含更加丰富的语义信息,对于自注意力机制来说能更好的进行关系建模,如下:
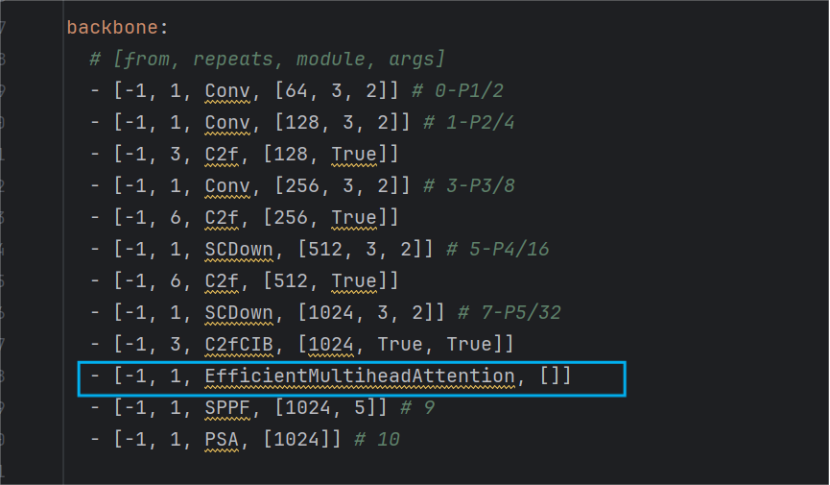
3.2 改进二:
改进方法:对yolov10中的PSA模块进行修改,并替换原有的PSA模块,新模块名为PSA_EMA,如下:
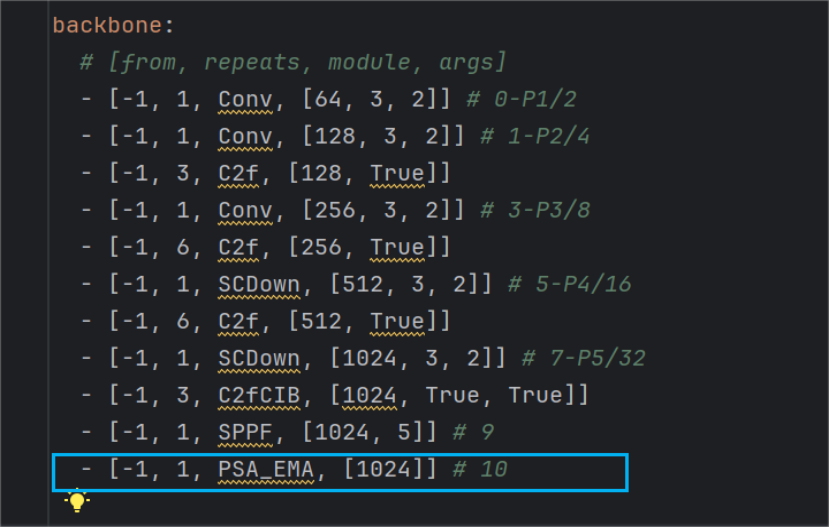
四、修改操作:
4.1 改进一的操作
4.1.1 模块导入
在yolov10的ultralytics/nn目录中新建一个文件夹AddAttention(名字自定义),在AddAttention中建立EfficientMultiheadAttention.py,并将EfficientMultiheadAttention的实现的代码放入其中,然后再在AddAttention中再新建_init_.py,并在该文件中写入:
from .EfficientMultiheadAttention import *用于将模块导出,如图:
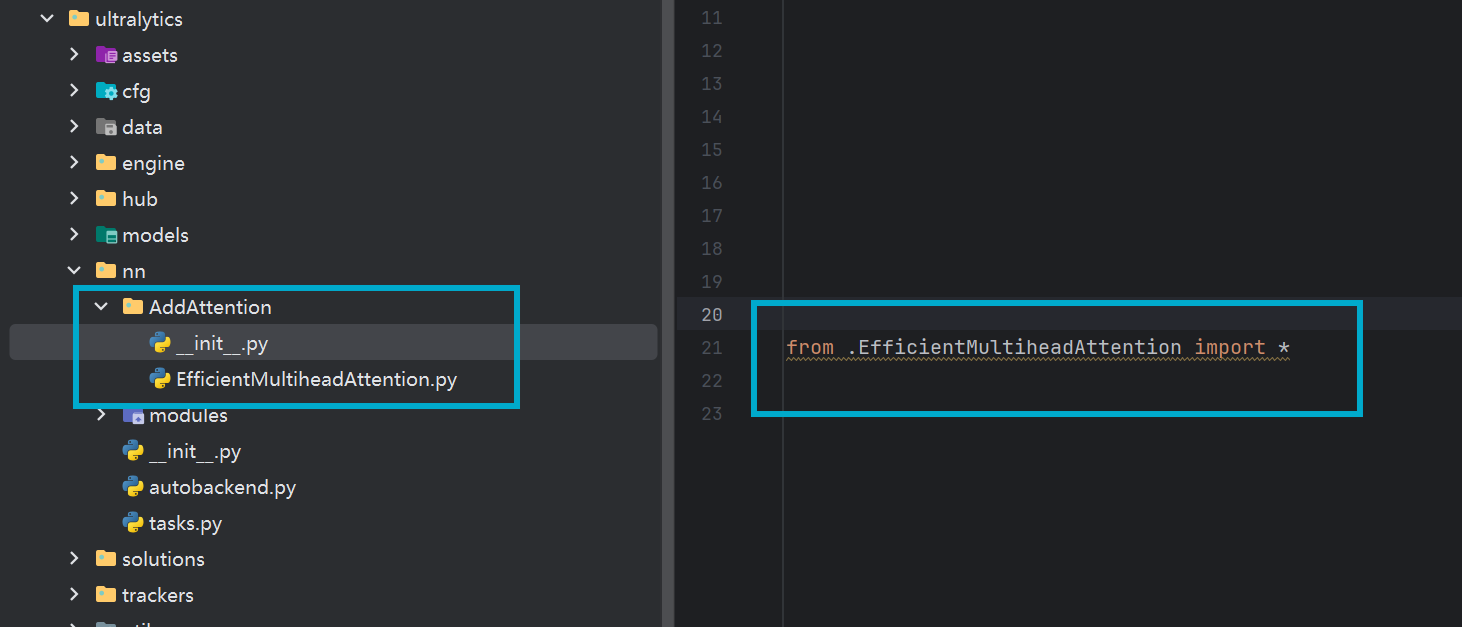
4.1.2 修改
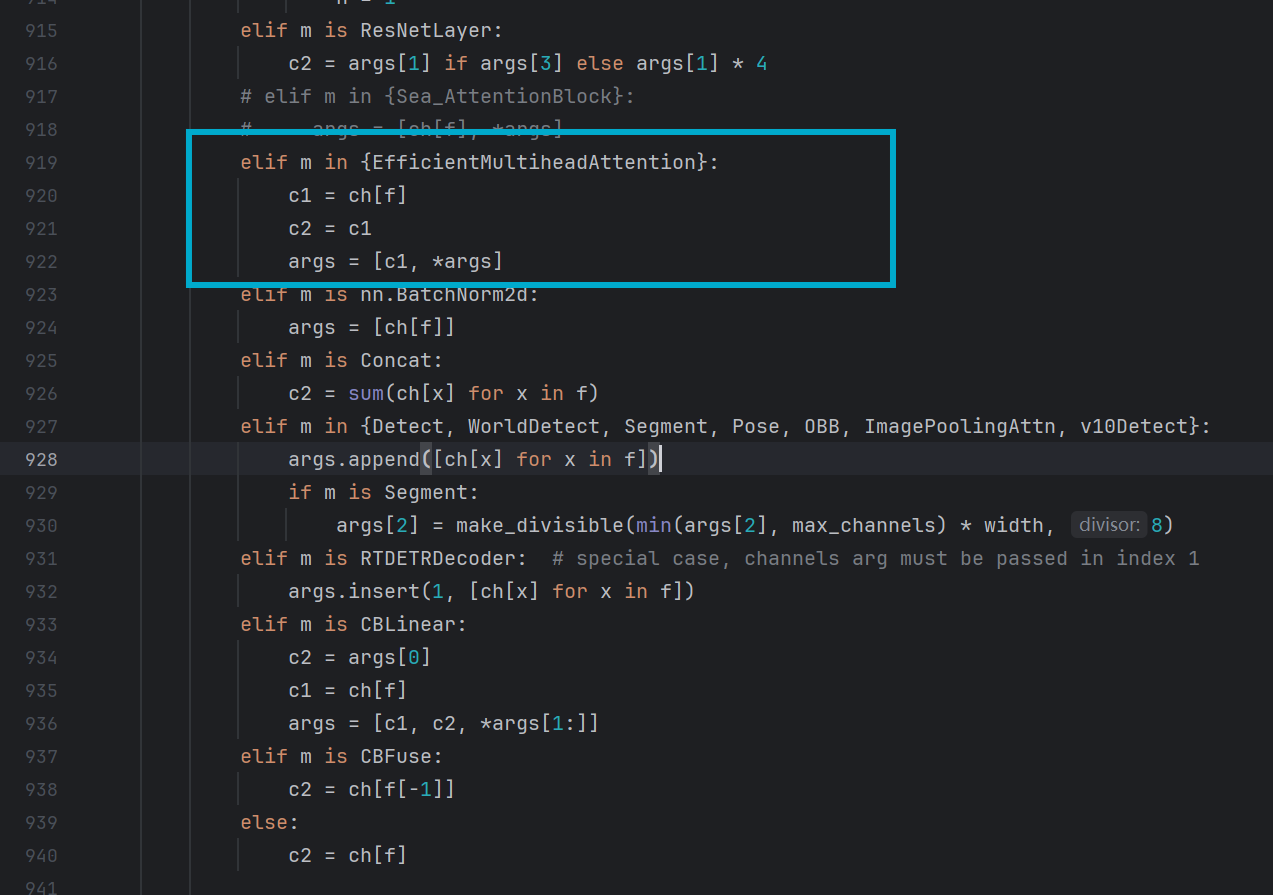
对模块进行参数设置,在ultralytics/nn/tasks.py的parse_model函数中添加如下代码(ch[f]代表当前层的输入通道数,c2代表输出通道数,在添加代码前,在tasks.py文件中对AddAttention里的模块进行导入,即在task.py文件中写入
from .AddAttention import *
):
elif m in {EfficientMultiheadAttention}:
c1 = ch[f]
c2 = c1
args = [c1, *args]位置如图所示:
4.1.3 yaml文件的修改
在ultralytics/cfg/models/v10目录下,将该目录下新建yolov10s_EMA.yaml(名字自定义,这里EMA为简写),并将yolov10s.yaml文件中的内容复制过来,并对其进行修改,在SPPF模块和C2FCIB模块之间添加EfficientMultiheadAttention模块,如图:
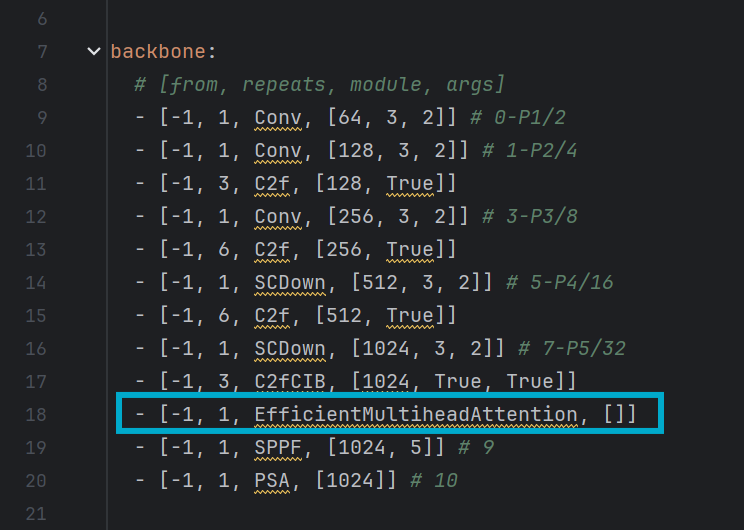
4.2 改进二的操作
4.2.1 PSA_EMA模块导入
在4.1.1小节的EfficientMultiheadAttention.py中添加如下代码(可另建立新的文件,在_init_.py中导出即可):
class Conv(nn.Module):
"""标准卷积层,参数包括:输入通道, 输出通道, 卷积核大小, 步长, 填充, 分组数, 空洞率, 激活函数"""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""初始化卷积层,包含激活函数"""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""应用卷积、批归一化和激活函数"""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""执行融合卷积操作(跳过批归一化)"""
return self.act(self.conv(x))
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class PSA_EMA(nn.Module):
def __init__(self, c1, c2, e=0.5):
super().__init__()
assert (c1 == c2)
self.c = int(c1 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv(2 * self.c, c1, 1)
self.attn = EfficientMultiheadAttention(self.c)
self.ffn = nn.Sequential(
Conv(self.c, self.c * 2, 1),
Conv(self.c * 2, self.c, 1, act=False)
)
def forward(self, x):
a, b = self.cv1(x).split((self.c, self.c), dim=1)
b = b + self.attn(b)
b = b + self.ffn(b)
return self.cv2(torch.cat((a, b), 1))4.2.2 模块注册
对模块进行注册,在ultralytics/nn/tasks.py的parse_model函数中对PSA_EMA模块进行注册,如图:
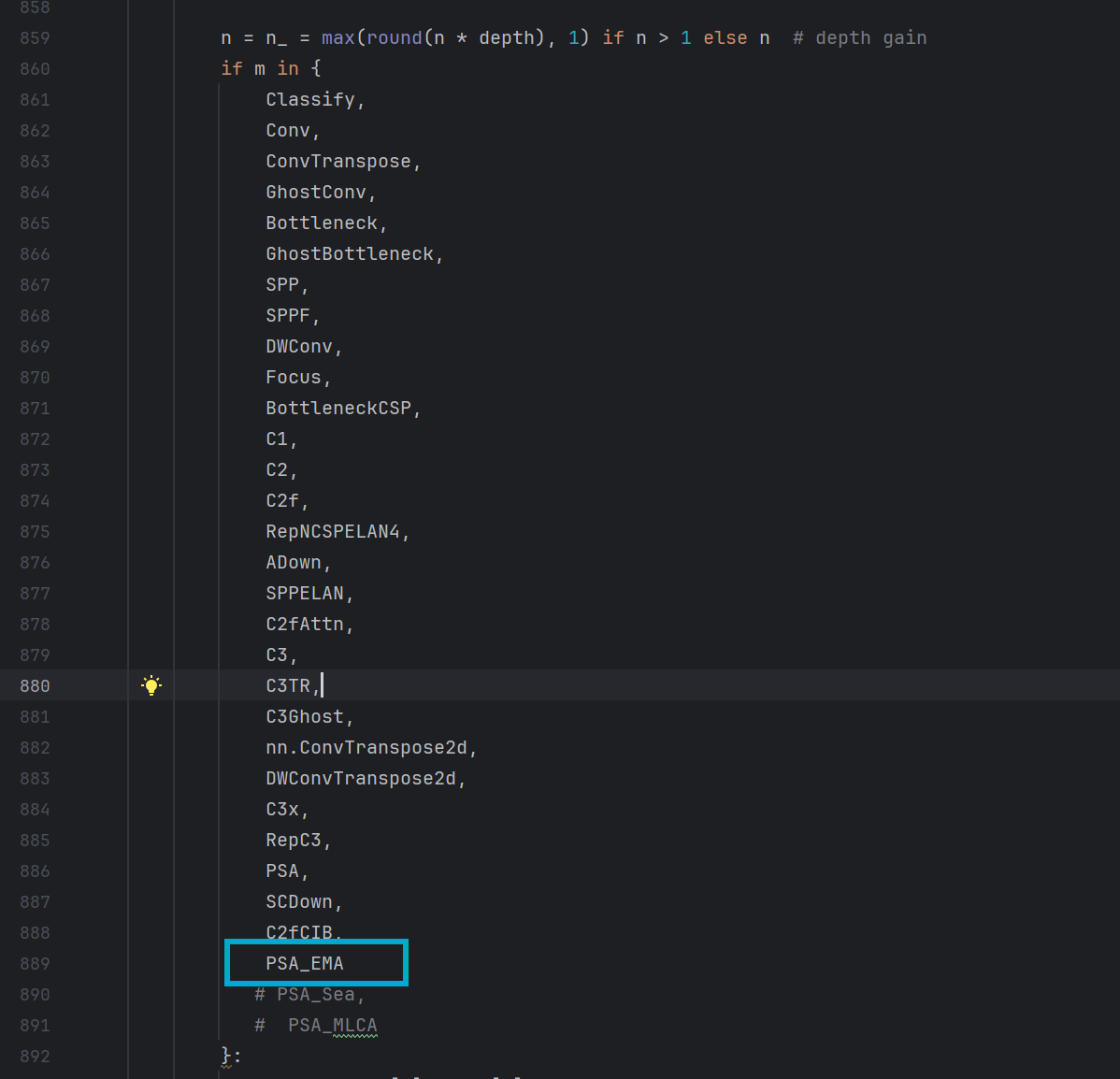
4.2.3 yaml文件的修改
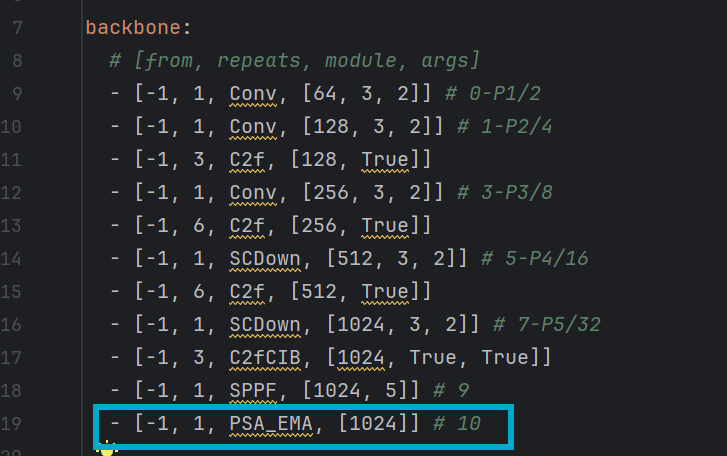
与4.1.3小节类似,只不过将骨干网络的最后的PSA模块进行替换,如图:
五、运行结果
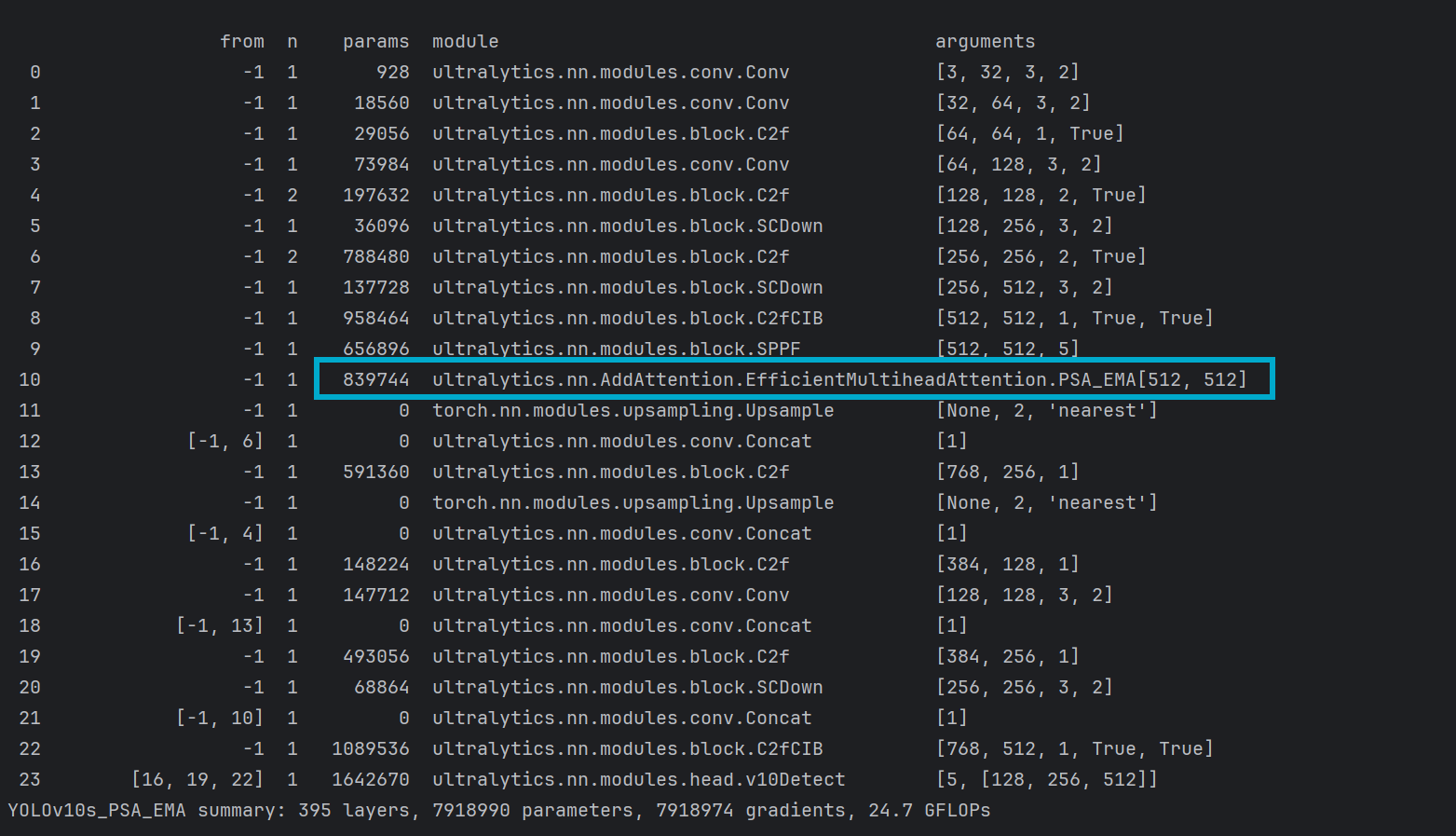
打印网络模型,看到自定义的模块名称出现在网络中即可代表修改成功
5.1 改进一
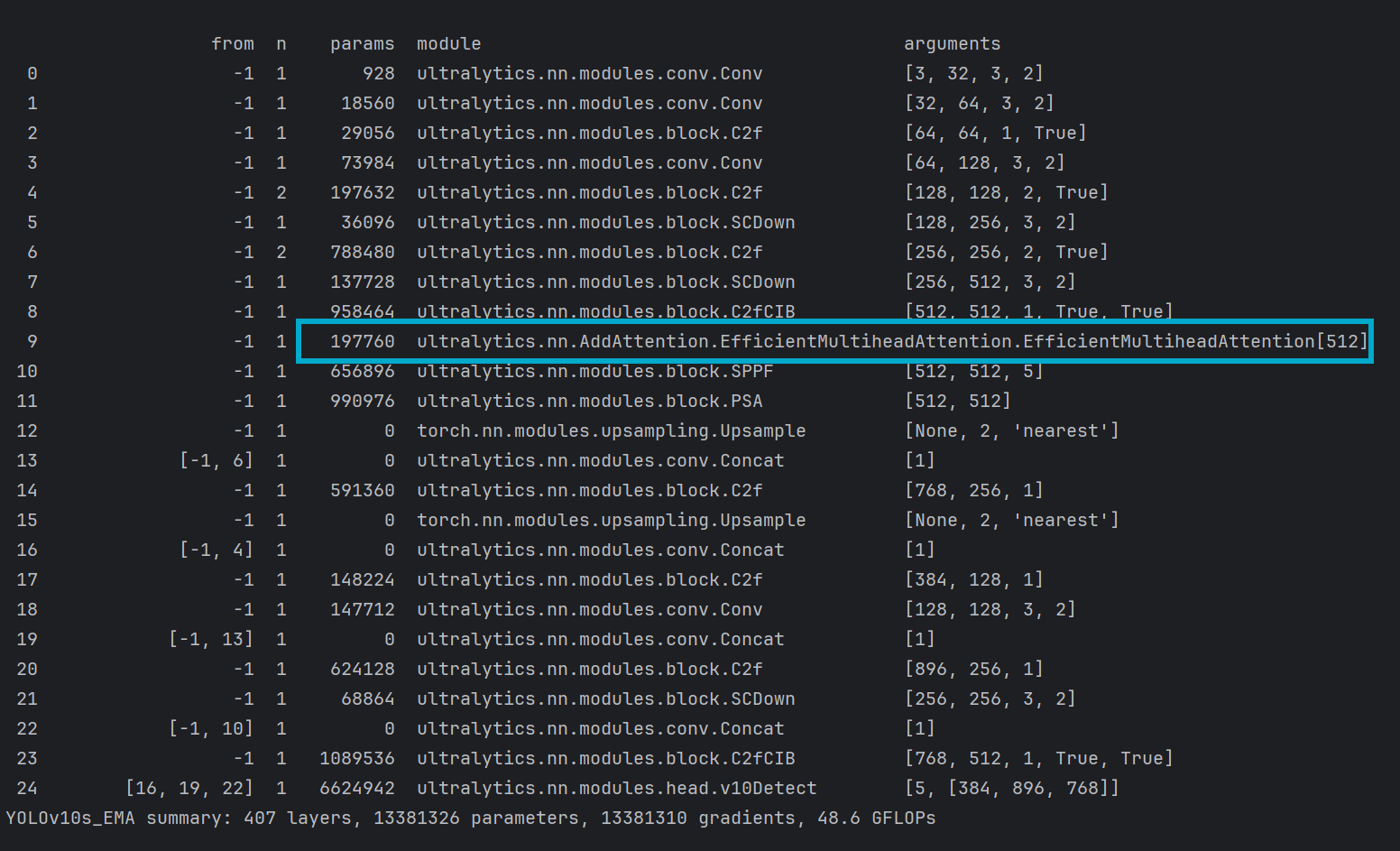
5.2 改进二

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)