yolov10的注意力机制改进:小波域注意力(WaveletDomainAttention)WDA
摘要:文章提出了一种基于小波域注意力(WaveletDomainAttention)的YOLOv10改进方法。该模块采用离散小波变换将特征图分解为四个频带,通过频带注意力机制动态学习各子带权重,再经逆变换重建特征。在YOLOv10中实现了两种改进方案:1) 在骨干网络的C2fCIB和SPPF模块之间插入WDA模块;2) 用新设计的PSA_WDA模块替换原有PSA模块,结合注意力机制降低计算量。详细
一、简介
小波域注意力WaveletDomainAttention模块基于离散小波变换(DWT)原理,将输入特征图分解为低频(LL)和高频(LH、HL、HH)四个子带,以捕捉多尺度频域信息;随后通过频带注意力机制自适应学习各子带的重要性权重,并加权融合后经逆小波变换(IDWT)重建特征。其核心优势在于结合小波分析的频域局部化特性与注意力机制的动态加权能力,能有效增强模型对关键纹理和结构特征的提取,同时通过简化实现保持计算效率,适用于多尺度视觉任务。
二、WaveletDomainAttention的实现代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class WaveletDomainAttention(nn.Module):
def __init__(self, channels, wavelet='haar'):
super().__init__()
self.wavelet = wavelet
# 小波系数注意力
self.freq_attention = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, channels // 2, 1),
nn.ReLU(),
nn.Conv2d(channels // 2, channels, 1),
nn.Sigmoid()
)
def forward(self, x):
# 保存原始尺寸
orig_size = x.size()
# 小波变换分解
LL, LH, HL, HH = self.dwt_2d(x)
# 拼接所有频带
freq_bands = torch.cat([LL, LH, HL, HH], dim=1)
# 频带重要性学习
freq_weights = self.freq_attention(freq_bands)
# 拆分权重并加权
w_LL, w_LH, w_HL, w_HH = torch.chunk(freq_weights, 4, dim=1)
LL_attended = LL * w_LL
LH_attended = LH * w_LH
HL_attended = HL * w_HL
HH_attended = HH * w_HH
# 小波逆变换
out = self.idwt_2d(LL_attended, LH_attended, HL_attended, HH_attended)
# 确保输出尺寸与输入一致
if out.size() != orig_size:
out = F.interpolate(out, size=orig_size[2:], mode='nearest')
return out
def dwt_2d(self, x):
"""2D离散小波变换"""
# 确保尺寸是偶数,避免池化后尺寸不一致
h, w = x.shape[2], x.shape[3]
if h % 2 != 0 or w % 2 != 0:
# 如果是奇数尺寸,先调整到偶数
x = F.interpolate(x, size=(h // 2 * 2, w // 2 * 2), mode='nearest')
# 简化实现,实际可使用pywt库
return torch.chunk(F.avg_pool2d(x, 2, stride=2), 4, dim=1)
def idwt_2d(self, LL, LH, HL, HH):
"""2D离散小波逆变换"""
# 简化实现
return F.interpolate(torch.cat([LL, LH, HL, HH], dim=1),
scale_factor=2, mode='nearest')三、在yolov10中改进
以下改进均在yolov10s.yaml文件中修改
3.1 改进一:
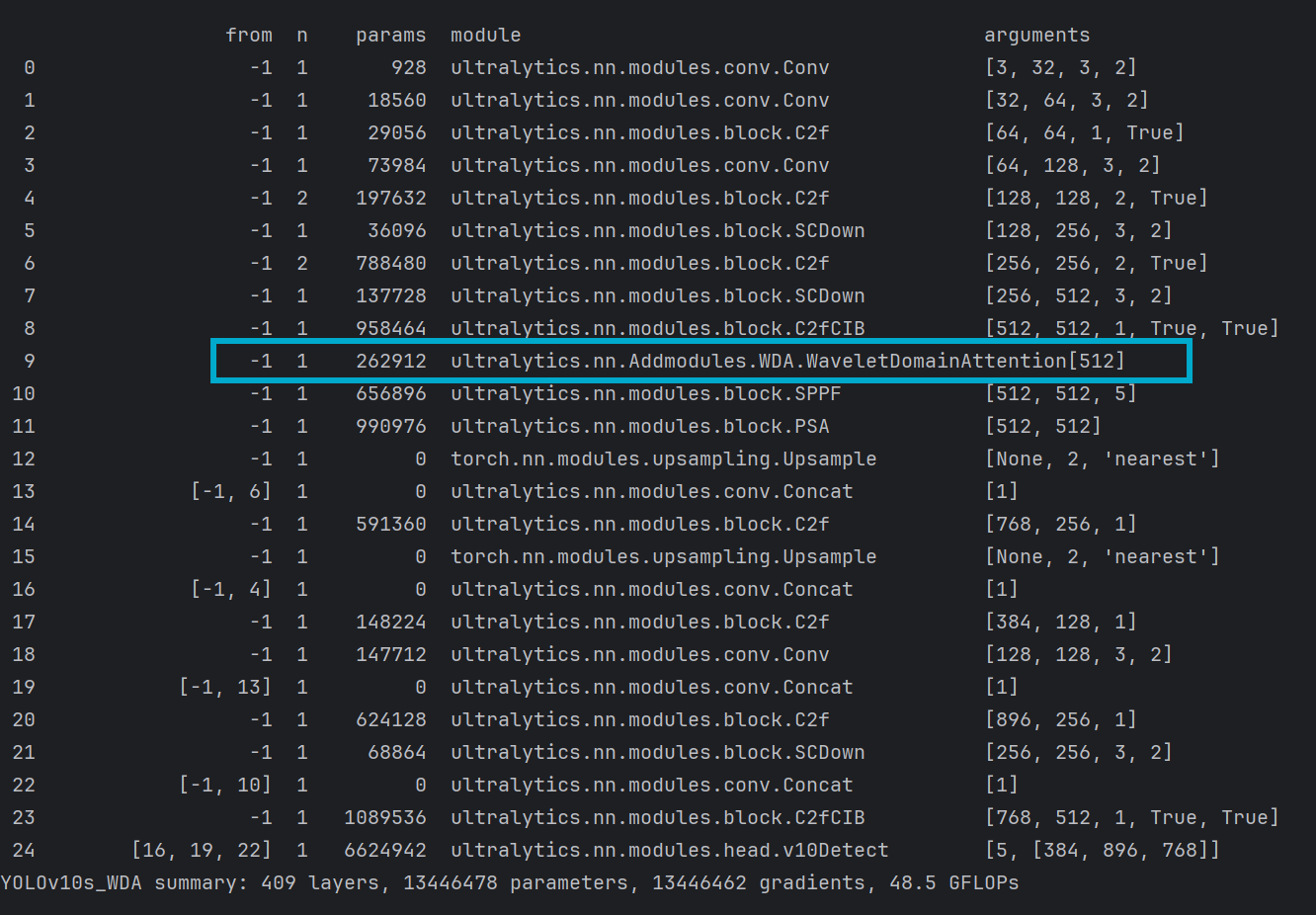
改进方法:直接嵌入到骨干网络(backbone)中,将模块放入到C2fCIB模块和SPPF模块之间,如下:
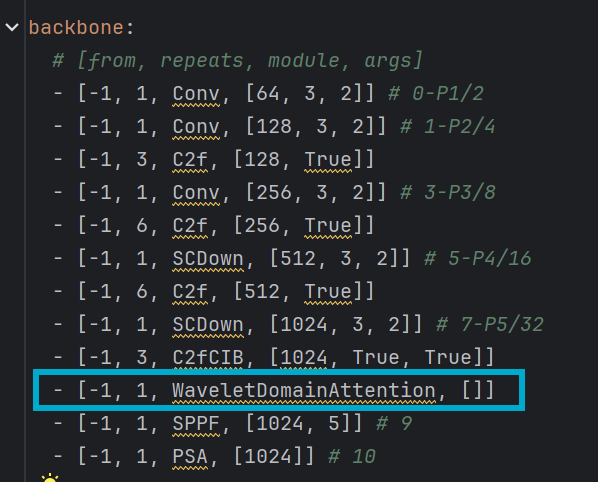
3.2 改进二:
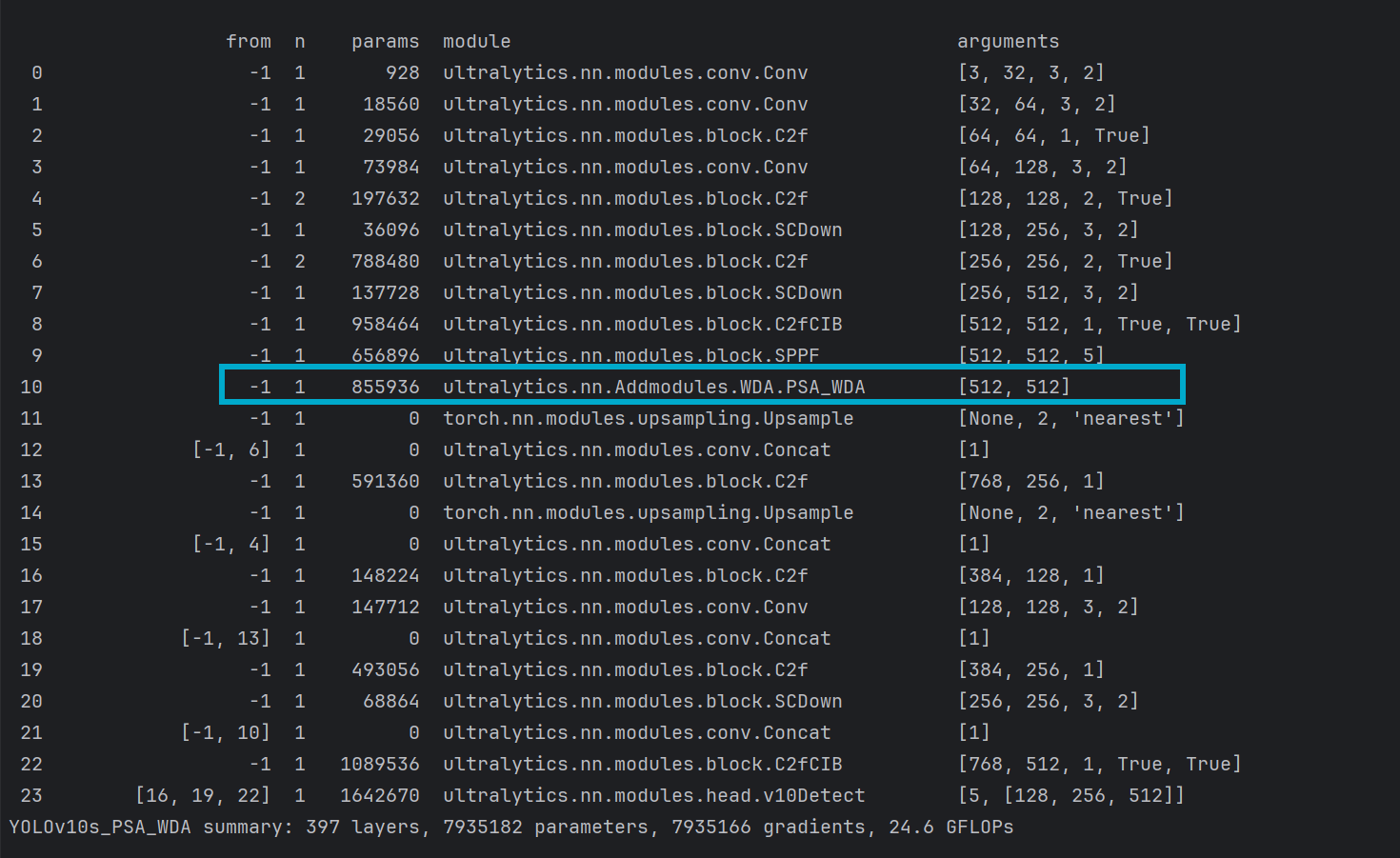
改进方法:对yolov10中的PSA模块进行修改,并替换原有的PSA模块,新模块名为PSA_WDA,选择对PSA改进主要是让计算量更加可控,减少增加的计算量,如下:
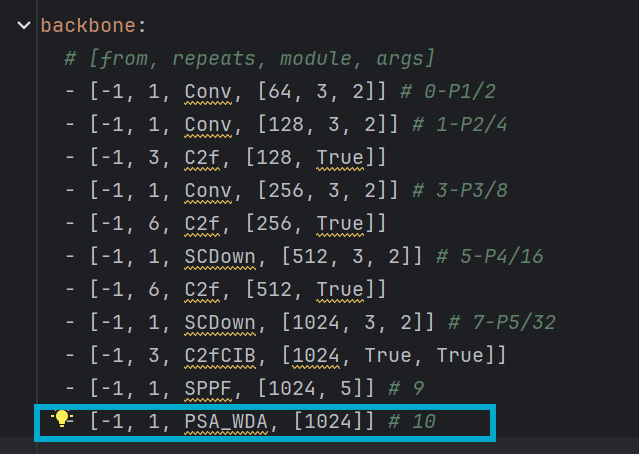
四、修改操作:
4.1 改进一的操作
4.1.1 模块导入
在yolov10的ultralytics/nn目录中新建一个文件夹AddAttention(名字自定义),在AddAttention中建立WDA.py,并将WDA的实现的代码放入其中,然后再在AddAttention中再新建_init_.py,并在该文件中写入:
from .WDA import *用于将模块导出
4.1.2 修改
对模块进行参数设置,在ultralytics/nn/tasks.py的parse_model函数中添加如下代码(在添加代码前,在tasks.py文件中对AddAttention里的模块进行导入,即在task.py文件中写入
from .AddAttention import *
):
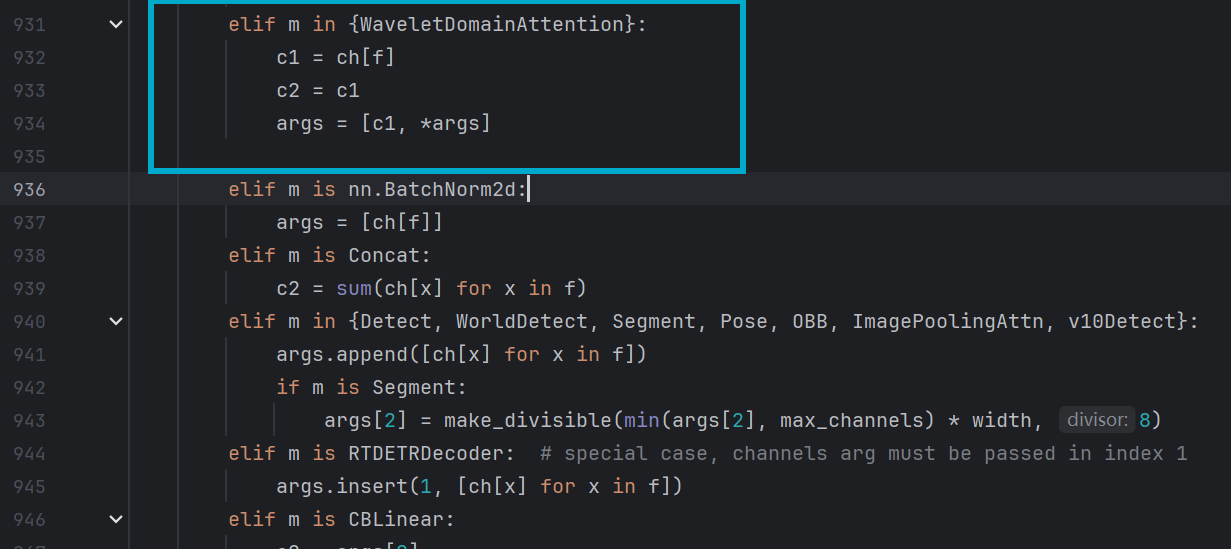
- ch[f]:代表当前CoordAtt层的输入通道数,它从前一层(索引为f)的输出通道数ch[f]中获取,确保了网络中各层间通道数的连贯性
- c2 = c1:c2为输出通道数,设置为和输入通道数一样的通道数
elif m in {WaveletDomainAttention}:
c1 = ch[f]
c2 = c1
args = [c1, *args]位置如图所示:
.1.3 yaml文件的修改
在ultralytics/cfg/models/v10目录下,将该目录下新建yolov10s_WDA.yaml(名字自定义,这里DWA为简写),并将yolov10s.yaml文件中的内容复制过来,并对其进行修改,在SPPF模块和C2FCIB模块之间添加WaveletDomainAttention模块,如图:
4.2 改进二的操作
4.2.1 PSA_WDA模块导入
在4.1.1小节的WaveletDomainAttention.py中添加如下代码(可另建立新的文件,在_init_.py中导出即可):
class Conv(nn.Module):
"""标准卷积层,参数包括:输入通道, 输出通道, 卷积核大小, 步长, 填充, 分组数, 空洞率, 激活函数"""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""初始化卷积层,包含激活函数"""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""应用卷积、批归一化和激活函数"""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""执行融合卷积操作(跳过批归一化)"""
return self.act(self.conv(x))
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class PSA_WDA(nn.Module):
def __init__(self, c1, c2, e=0.5):
super().__init__()
assert (c1 == c2)
self.c = int(c1 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv(2 * self.c, c1, 1)
self.attn = WaveletDomainAttention(self.c)
self.ffn = nn.Sequential(
Conv(self.c, self.c * 2, 1),
Conv(self.c * 2, self.c, 1, act=False)
)
def forward(self, x):
a, b = self.cv1(x).split((self.c, self.c), dim=1)
b = b + self.attn(b)
b = b + self.ffn(b)
return self.cv2(torch.cat((a, b), 1))4.2.2 模块注册
对模块进行注册,在ultralytics/nn/tasks.py的parse_model函数中对PSA_WDA模块进行注册,如图:
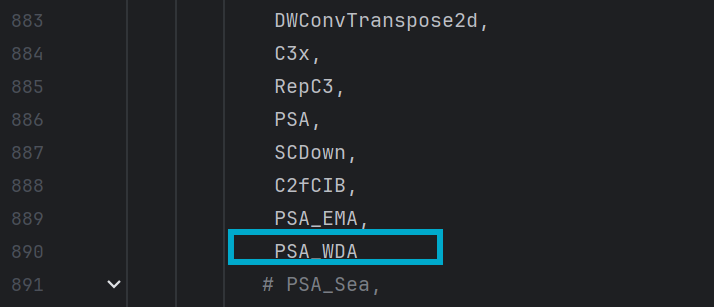
4.2.3 yaml文件的修改
与4.1.3小节类似,只不过将骨干网络的最后的PSA模块进行替换,如图:
五、运行结果
打印网络模型,看到自定义的模块名称出现在网络中即可代表修改成功
5.1 改进一
5.2 改进二

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)