01-AI应用开发平台Coze
视频讲解链接:
大模型概述
主流大模型
在人工智能领域,特别是大模型(Large Language Model, LLM)爆发式发展的今天,主流大模型指的是那些 影响力大、应用广泛、技术先进、社区活跃 的预训练语言模型。
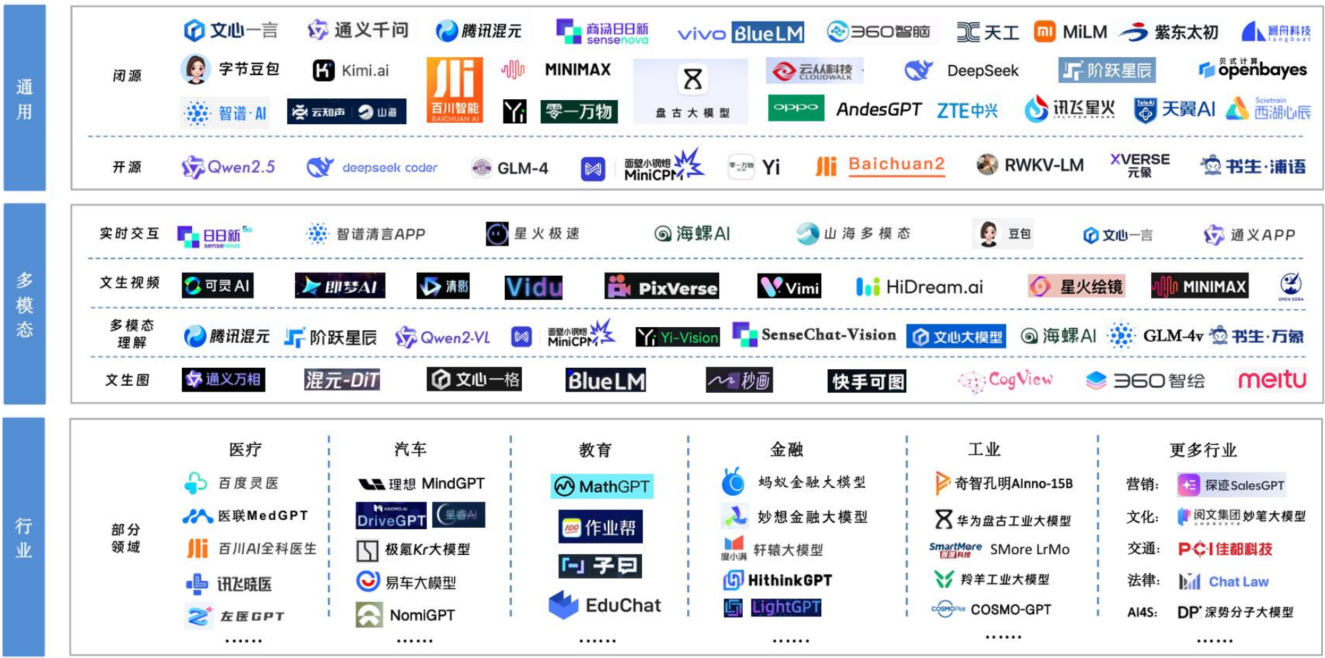
它们通常具备以下特征:
- 参数量巨大(通常在数亿到数千亿级别)
- 基于海量文本进行预训练
- 支持自然语言理解与生成任务
- 可通过微调或提示工程(Prompting)应用于各种场景
我们可以将主流大模型分为 国外代表模型 和 国内代表模型 两大类。
- 国外主流大模型
|
模型名称 |
开发机构 |
简要介绍 |
|
GPT 系列 |
OpenAI |
全球最知名的系列大模型,驱动 ChatGPT。擅长对话、写作、编程等,闭源但可通过 API 调用。 |
|
LLaMA 系列 |
Meta (Facebook) |
开源标杆模型,尤其 LLaMA2/3 被广泛用于研究和二次开发。性能强,社区生态丰富。 |
|
Gemini 系列 |
|
原名 Bard,多模态能力强,集成在 Google 生态中,支持文本、图像、音频等。 |
|
Claude 系列 |
Anthropic |
强调安全性和可解释性,Claude 3 在推理和长文本处理上表现优异。 |
💡 小知识:GPT 是 Generative Pre-trained Transformer 的缩写,即“生成式预训练变换器”,是当前大模型架构的奠基者。
- 国内主流大模型
|
模型名称 |
开发机构 |
简要介绍 |
|
通义千问 Qwen 系列 |
阿里巴巴 |
完全自研,开源多个版本(如 Qwen、Qwen2、Qwen3、Qwen-VL 多模态),支持长上下文、代码生成,魔搭社区主力模型。 |
|
DeepSeek |
深度求索 |
高性能大模型,DeepSeek-V3 / DeepSeek-R1 实现高效训练与强推理能力,DeepSeek-MoE 架构,在性能与成本之间取得优秀平衡,代码与数学能力强,完全开源,GitHub 和 Hugging Face 社区活跃。 |
|
文心一言 ERNIE Bot |
百度 |
基于文心大模型体系,结合百度搜索知识,中文理解能力强,已接入多款产品。 |
|
混元 HunYuan |
腾讯 |
腾讯全链路自研大模型,覆盖 NLP、CV、多模态,强调产业落地。 |
|
星火大模型 |
科大讯飞 |
擅长语音识别与教育场景,在教育、医疗等领域有深度应用。 |
|
GLM 系列 |
智谱AI |
基于 GLM 架构,推出 GLM-4,支持多任务,学术与工业结合紧密,也有开源版本(如 ChatGLM)。 |
🔍 重点补充:DeepSeek 特点
- 由清华系背景团队打造,技术实力强
- 推出 MoE(Mixture of Experts)稀疏架构模型,提升效率
- 在代码生成、数学推理等任务上表现突出
- 提供开源模型权重(如 DeepSeek-Large、DeepSeek-Coder),适合学习和部署
- 支持 128K 长上下文,适合复杂任务处理
✅ 重点推荐关注:Qwen 和 DeepSeek 系列,因为:
- 两者都完全开源,适合学习和项目实践
- 在魔搭(ModelScope)或 Hugging Face 上可直接下载
- 社区活跃,文档齐全,适合面试中举例说明
为什么学习主流大模型?
- 技术趋势:大模型是当前 AI 发展的核心方向。
- 求职需求:几乎所有 AI 岗位都要求了解主流模型及其应用场景。
- 项目基础:后续的微调、部署、应用开发都基于这些模型展开。
- 开源红利:像 LLaMA、Qwen、DeepSeek 等开源模型,让我们可以“站在巨人肩膀上”做创新。
大模型概念
大语言模型 (LLM):就是使用大规模数据集训练的深度学习模型,具有非常高的参数数量和计算能力。浅显的说:大模型就是一个 “读过海量文本、记住大量知识、能理解和生成人类语言” 的人工智能程序。
通常, 大语言模型 (LLM) 是指包含数千亿 (或更多) 参数的语言模型(目前定义参数量超过1B的模型为大语言模型),这些参数是在大量文本数据上训练的,例如模型 GPT-3、ChatGPT、PaLM、BLOOM和 LLaMA等。
- 参数规模: 数十亿甚至数千亿个参数
- 它们能够处理和分析大量的数据,从而生成复杂的输出,如自然语言文本、图像等
- 具有强大的泛化能力,能够在多种任务中表现出色
- 独立意义上的大模型:具备涌现能力的深度学习模型
智能涌现(Intelligent Emergence)是指通过个体之间的简单交互,或者通过系统的局部规则和动态演化,形成复杂的、难以预见的全局行为和智能。在大模型的上下文中,这种现象表现为模型通过训练和大量的数据输入,展现出超出单一算法设计预期的能力,类似于“涌现”的智能。
总的来说:大语言模型 = 大规模 + 预训练 + 语言理解与生成能力
大语言模型与传统机器学习模型的区别:
|
对比维度 |
传统机器学习模型(如 KNN) |
大模型(LLM) |
|
参数规模 |
小(几千到几百万) |
超大(几亿到几千亿) |
|
训练数据 |
小规模、结构化数据 |
海量、非结构化文本 |
|
训练方式 |
监督学习为主(带标签) |
自监督学习(从文本中自动生成任务) |
|
任务类型 |
单一任务(如分类、回归) |
多任务通才(可对话、写代码、翻译等) |
|
开发流程 |
特征工程 + 模型训练 |
预训练 + 微调/提示工程 |
|
部署难度 |
简单,可在普通服务器运行 |
复杂,需高性能 GPU 集群 |
发展历程
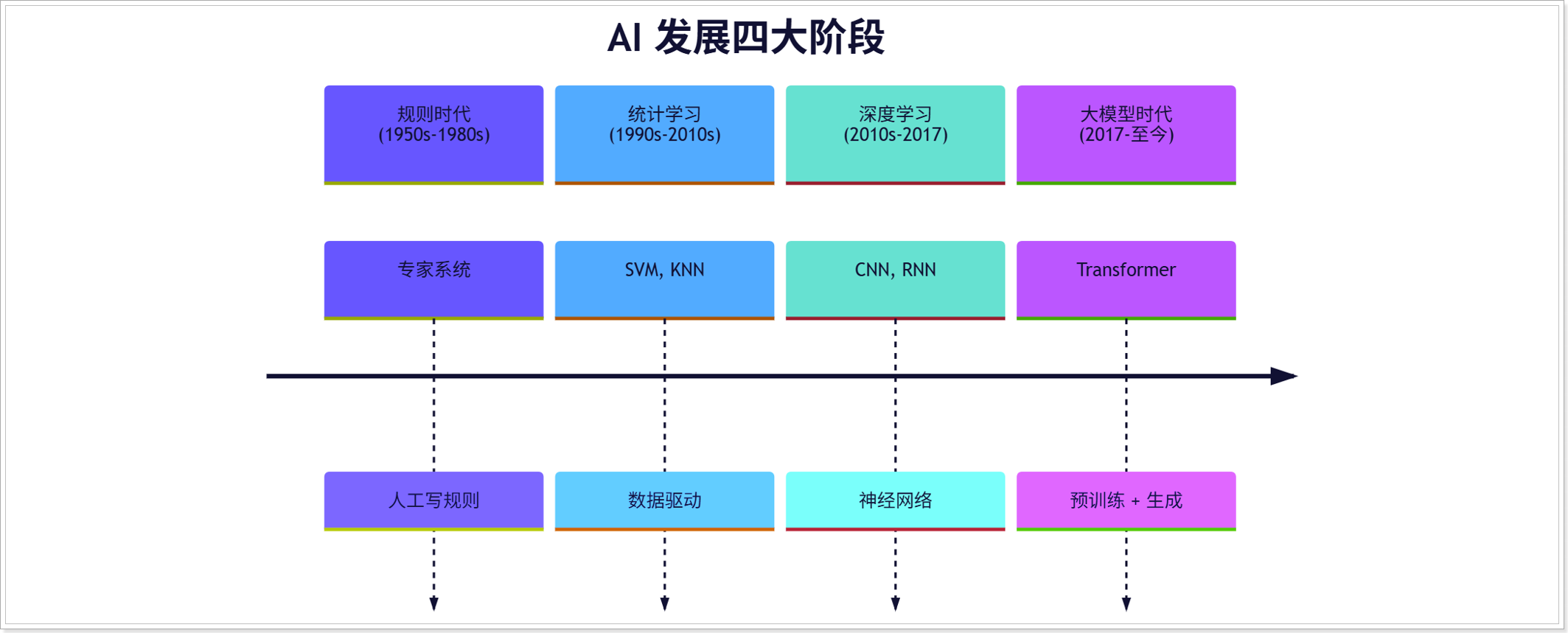
大模型发展的关键里程碑
📅2017:Transformer 横空出世(奠基之年)
- 事件:Google 发表论文《Attention is All You Need》
- 贡献:提出 Transformer 架构,用 “自注意力机制” 替代 RNN
- 意义:
-
- 解决了长文本依赖问题
- 支持并行训练,大幅提升效率
- 成为所有大模型的“骨架”
💡 就像 Spring 框架统一了 Java 开发,Transformer 统一了 NLP 模型架构。
📅 2018:预训练范式兴起
|
模型 |
机构 |
意义 |
|
BERT |
|
• 双向编码,擅长理解任务(如问答、情感分析) • 开启“预训练 + 微调”新时代 |
|
GPT-1 |
OpenAI |
• 单向生成,擅长语言生成任务 • 为后续 GPT 系列打下基础 |
🔑 核心思想:先在海量数据上“自学”(预训练),再在小数据上“精调”(微调)
📅2019-2020:大模型规模竞赛开启
|
模型 |
参数量 |
亮点 |
|
GPT-2 (OpenAI) |
15亿 |
• 展示了“零样本学习”能力(Zero-shot) • 不微调也能完成多种任务 |
|
GPT-3 (OpenAI) |
1750亿 |
• 真正意义上的“大模型” • 支持“提示学习”(Prompting) • 可写文章、代码、故事等 |
🌪️ 影响:GPT-3 证明了“规模即能力”(Scale is All You Need)的潜力。
📅 2022:ChatGPT 爆火(出圈之年)
- 事件:OpenAI 推出基于 GPT-3.5 的 ChatGPT
- 技术突破:
-
- 使用 RLHF(人类反馈强化学习)对齐人类偏好
- 回答更自然、安全、有逻辑
- 影响:
-
- 全球用户破亿,AI 进入大众视野
- 各国科技公司纷纷入场,开启“百模大战”
🎯 “ChatGPT 为什么能火?”
对话体验好、RLHF 技术、零样本能力、产品化成功
📅 2023-2025:国产大模型崛起 & 开源浪潮
|
趋势 |
代表事件 |
|
国产模型爆发 |
阿里通义千问(Qwen)、 百度文心一言、深度求索 DeepSeek、智谱 GLM、 科大讯飞星火 |
|
开源开放 |
Meta 发布 LLaMA 系列、阿里开源 Qwen、DeepSeek 开源模型权重、魔搭(ModelScope)等平台兴起 |
|
多模态融合 |
GPT-4V(支持图像输入)、Qwen-VL、Gemini 多模态模型 |
|
小型化 & 推理优化 |
MoE 架构(如 DeepSeek-MoE)、模型蒸馏、量化技术普及 |
✅ 当前趋势:开源 + 垂直落地 + 成本优化
AI模型平台
AI大模型的越用越多,涌现了很多AI大模型的平台;这些平台大多提供模型的下载、训练、微调、部署等。 企业或开发者使用大模型的成本更低、更便利。
Hugging face
Hugging Face 是一个非常受欢迎的开源平台,致力于自然语言处理(NLP)和机器学习领域的技术发展。它为开发者和研究人员提供了多种工具和资源,帮助他们构建、训练和部署各种预训练模型,尤其是在深度学习和大模型方面。
国内代理地址:https://hf-mirror.com/
Hugging Face 主要功能
- Transformers库:这是 Hugging Face 最著名的库,专注于 Transformer 架构模型的实现和应用。这个库包含了多种预训练模型,如 BERT、GPT、T5、RoBERTa 等,支持从文本生成到文本分类等广泛的 NLP 任务。
例如,使用 transformers 库,你可以轻松地加载一个模型并对其进行微调,完成如问答、情感分析、文本生成等任务。
- Datasets 库:提供了一个方便的数据集处理和加载框架,用户可以轻松下载和预处理大量的公开数据集。它使得研究人员能够快速使用标准化的数据集来测试和训练模型。
- Tokenizers 库:专门处理文本预处理工作,如分词、编码等操作。这个库优化了数据预处理的速度和效率,适用于大规模数据的处理。
- Hugging Face Hub:一个模型分享平台,用户可以在这里上传和下载各种机器学习模型。这里不仅包含了自然语言处理的模型,还涵盖了计算机视觉、语音识别等领域的模型。
- Accelerate 库:为分布式训练和多 GPU 环境优化的工具,简化了高效的训练和部署。
Hugging Face 支持的模型通常是基于 Transformer 架构的,这些模型常常参数庞大,训练时消耗巨大的计算资源。在这个平台上,你可以直接使用这些大模型,也可以对它们进行微调以适应具体的应用场景。这使得开发者能够轻松地使用大规模预训练模型,而不需要从头开始训练模型。
魔搭
魔搭是国内开源 AI 模型平台,提供模型下载、部署、推理以及评测服务。由阿里巴巴提供;官网地址:https://modelscope.cn/
ModelScope 社区成立于 2022 年 6 月,是一个模型开源社区及创新平台,由阿里巴巴通义实验室(Institutefor Intelligent Computing),联合CCF开源发展委员会,共同作为项目发起方。社区联合国内 AI 领域合作伙伴与高校机构,致力于通过开放的社区合作,构建深度学习相关的模型开源社区,并开放相关模型创新技术,推动基于“模型即服务”(Model-as-a-Service)理念的模型应用生态的繁荣发展。
- 提供大量中文预训练模型,支持语音、图像、NLP、CV 等领域。集成了阿里(Qwen)、深度求索(DeepSeek)、智谱(GLM)、百川、MiniMax 等主流国产模型
- 提供模型微调工具、训练脚本和可视化工具
特色:
- 更关注中文 NLP 与多模态任务。
- 支持本地部署和私有化应用。
- 适用场景:偏向国内用户,适用于中文场景下的模型使用与二次开发。
Hugging Face 与 魔搭 的对比:
|
对比项 |
Hugging Face |
魔搭(ModelScope) |
|
主要语言 |
英文 |
中文友好 |
|
代表模型 |
LLaMA、BERT、Stable Diffusion |
Qwen、DeepSeek、GLM、通义系列 |
|
国产支持 |
较少 |
全面支持 |
|
本地部署 |
支持,但需手动配置 |
支持,提供详细中文教程 |
|
云服务集成 |
AWS、Azure |
阿里云(无缝对接) |
|
适合人群 |
国际化项目、研究前沿 |
国内落地、教学、创业 |
应用领域
应用场景
计算机视觉(CV)
计算机视觉是深度学习最成熟的应用领域之一,核心是让机器通过图像 / 视频数据识别、分析视觉信息,关键技术包括 CNN(卷积神经网络)、YOLO、ResNet 等。
- 场景 1:图像分类与识别 对图像中的核心对象进行归类,例如:
-
- 手机相册的 “人物 / 风景 / 美食” 自动分类(如苹果相册的智能分类功能);
- 工业质检:通过摄像头拍摄产品(如芯片、汽车零件),深度学习模型自动识别表面划痕、尺寸偏差等缺陷,效率远超人工。
- 场景 2:目标检测与追踪 不仅识别对象,还能定位对象在图像中的位置(用 “bounding box” 框出),并追踪动态目标:
-
- 自动驾驶:实时检测道路上的行人、车辆、交通信号灯、障碍物,为决策提供依据;
- 安防监控:自动追踪画面中异常移动的人员或物体(如翻越围墙、遗落可疑包裹),触发警报。
- 场景 3:图像生成与修复 基于已有数据生成新图像或修复残缺图像:
-
- AI 绘画(如 MidJourney、 Stable Diffusion):输入文字描述(如 “赛博朋克风格的猫”),模型生成对应图像;
- 老照片修复:自动填充老照片的破损区域、去除噪点,甚至将黑白照片上色。
自然语言处理(NLP)
自然语言处理聚焦于机器与人类语言的交互,核心技术包括 RNN(循环神经网络)、Transformer、BERT、GPT 等,解决 “语言理解” 和 “语言生成” 两大问题。
- 场景 1:文本理解与分析 对文本内容进行语义解析、情感判断或信息提取:
-
- 情感分析:电商平台自动识别用户评论的情感倾向(如 “这款手机续航太差” 为负面评价),辅助商家改进产品;
- 智能摘要:新闻 APP 将长篇报道压缩为简短摘要(如腾讯新闻的 “一句话新闻”),节省用户阅读时间。
- 场景 2:语言生成与交互 生成符合人类语言逻辑的文本,或实现人机对话:
-
- 智能客服(如淘宝客服、银行 APP 客服):通过深度学习模型实时响应用户咨询(如 “如何修改收货地址”),替代部分人工客服;
- 机器翻译:谷歌翻译、百度翻译通过深度学习(如 Transformer 架构)实现多语言精准翻译,支持 “语音实时翻译”(如出国旅游时的对话翻译)。
- 场景 3:大语言模型(LLM)应用 基于超大规模深度学习模型的高阶应用,如 ChatGPT、文心一言、讯飞星火:
-
- 内容创作:辅助写文案、论文提纲、代码(如输入 “写一段产品推广文案”,模型生成对应内容);
- 知识问答:解答专业领域问题(如 “解释相对论的核心观点”),或提供生活建议(如 “制定一周减脂食谱”)。
语音技术
语音技术结合深度学习解决 “语音识别”(将语音转文字)和 “语音合成”(将文字转语音),核心技术包括 CNN+RNN 混合模型、Transformer(如 Whisper) 。
- 场景 1:语音识别(ASR) 将人类语音转换为文本,典型应用:
-
- 手机语音输入(如微信 “按住说话转文字”)、电脑语音输入法(如讯飞输入法);
- 智能音箱(如小米音箱、天猫精灵):通过语音指令控制设备(如 “播放周杰伦的歌”“查询明天天气”)。
- 场景 2:语音合成(TTS) 将文字转换为自然流畅的语音,典型应用:
-
- 有声书 / 广播:喜马拉雅、微信读书的 “听书” 功能,用 AI 生成接近真人的朗读语音;
- 导航语音:高德地图、百度地图的语音导航(如 “前方 500 米左转,请注意礼让行人”),支持自定义语音(如 “郭德纲语音包”“动漫角色语音包”)。
其他前沿领域
除了上述高频场景,深度学习还在更专业的领域发挥作用:
- 自动驾驶:除了计算机视觉的目标检测,还通过深度学习融合激光雷达、毫米波雷达数据,实现路径规划(如特斯拉的 Autopilot、小鹏的 XPILOT);
- 医疗健康:辅助疾病诊断,如通过 CT 影像识别肺癌病灶(模型准确率可媲美专业医生)、通过心电图数据预测心律失常;
- 金融科技:识别金融欺诈,如银行通过深度学习分析用户的转账记录、消费习惯,判断是否为 “盗刷”(如陌生设备深夜大额转账,模型触发风险提示);
- 科学研究:加速科研进程,如用深度学习模拟蛋白质结构(AlphaFold 解决了蛋白质折叠预测难题)、辅助天文观测(识别宇宙中的星系或黑洞)。
什么是智能体
智能体的定义
智能体(AI Agent) 是一个具备自主感知、决策与行动能力的AI系统。它不仅仅是一个大语言模型,而是一个综合系统,包含以下五个核心组成部分:
- 大语言模型(LLM):负责理解、推理与生成。
- 记忆(Memory):存储和召回信息。
- 任务规划(Planning):分解任务、制定策略。
- 工具使用(Tool Use):调用外部工具执行任务。
- 行动(Action):实际执行规划好的操作。
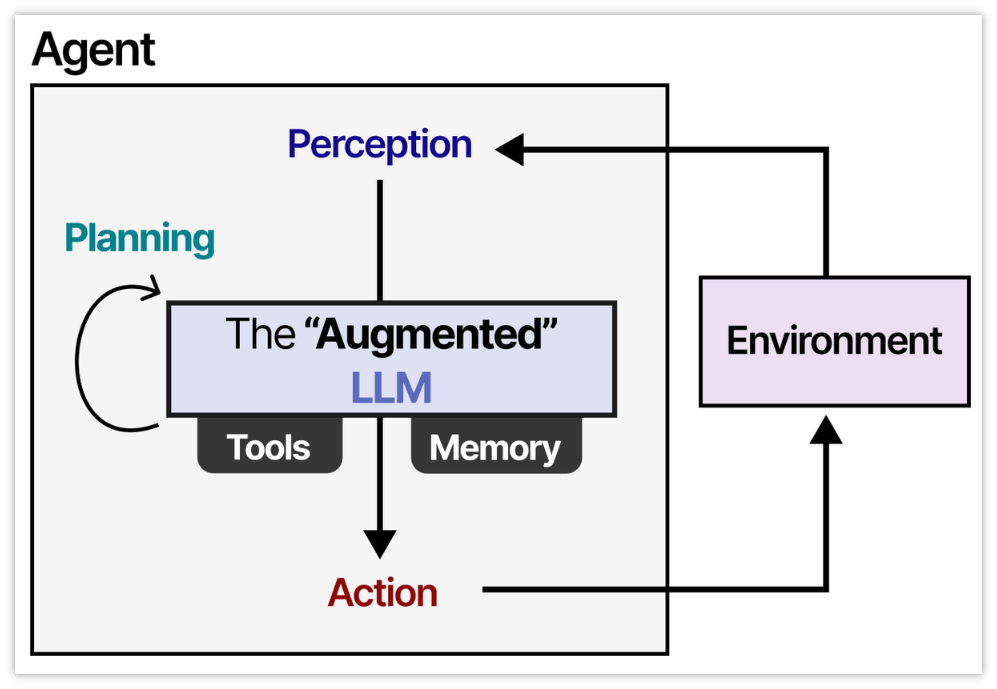
图来源:https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-llm-agents
简而言之:
AI Agent = LLM + 记忆 + 任务规划 + 工具使用 + 行动
举例:用户问“明天北京天气如何?
- LLM 理解这是天气查询任务;
- 记忆模块可能提供用户所在位置或历史查询记录;
- 规划模块决定需要调用天气API;
- 行动模块执行API调用;
- 返回结果:“明天北京晴,15°C~25°C。”
核心内容
Prompt 提示词
- 是用户向Agent发出的指令或问题。
- 决定了Agent的任务目标和上下文。
- 示例:“帮我总结这篇论文的核心观点”或“订一张明天去北京的机票”。
大语言模型(LLM)
- 是Agent的“大脑”,负责:
-
- 自然语言理解(NLU)
- 逻辑推理
- 生成回答或计划
- 常见模型:GPT-4、Claude、Llama 、Qwen、Deepseek等。
记忆(Memory)
- 分为短期记忆和长期记忆:
-
- 短期记忆:当前对话的上下文。
- 长期记忆:外部知识库、向量数据库、历史交互记录等。
- 使Agent具备连续对话和个性化服务的能力。
任务规划(Planning)
- Agent根据目标制定执行计划,包括:
-
- 任务分解(Breakdown)
- 优先级排序(Prioritization)
- 路径规划(Path Planning)
- 例如:用户说“我想去旅游”,Agent会分解为:目的地推荐、机票查询、酒店预订等子任务。
行动执行(Action)
- Agent调用外部工具或API完成任务,常见工具包括:
-
- 计算器
- 代码解释器(Code Interpreter)
- 搜索引擎
- 数据库查询
- 第三方API(如天气、地图、支付等)
常见应用场景
- 个人助理:日程管理、邮件回复、旅行规划
- 客服机器人:自动回答用户问题、处理投诉
- 代码开发:自动生成代码、调试、注释
- 教育辅导:答疑解惑、生成练习题
- 数据分析:查询数据库、生成报表
- 智能家居控制:语音指令执行家电操作
Coze平台
什么是Coze
扣子是新一代 AI 应用开发平台。无论你是否有编程基础,都可以在扣子上快速搭建基于大模型的各类 AI 应用,并将 AI 应用发布到各个社交平台、通讯软件,也可以通过 API 或 SDK 将 AI 应用集成到你的业务系统中。
借助扣子提供的可视化设计与编排工具,你可以通过零代码或低代码的方式,快速搭建出基于大模型的各类 AI 项目,满足个性化需求、实现商业价值。
- 官网地址:https://www.coze.cn/
- 智能体:智能体是基于对话的 AI 项目,它通过对话方式接收用户的输入,由大模型自动调用插件或工作流等方式执行用户指定的业务流程,并生成最终的回复。智能客服、虚拟伴侣、个人助理、英语外教都是智能体的典型应用场景。
- 应用:应用是指利用大模型技术开发的应用程序。扣子中搭建的 AI 应用具备完整业务逻辑和可视化用户界面,是一个独立的 AI 项目。通过扣子开发的 AI 应用有明确的输入和输出,可以根据既定的业务逻辑和流程完成一系列简单或复杂的任务,例如 AI 搜索、翻译工具、饮食记录等。
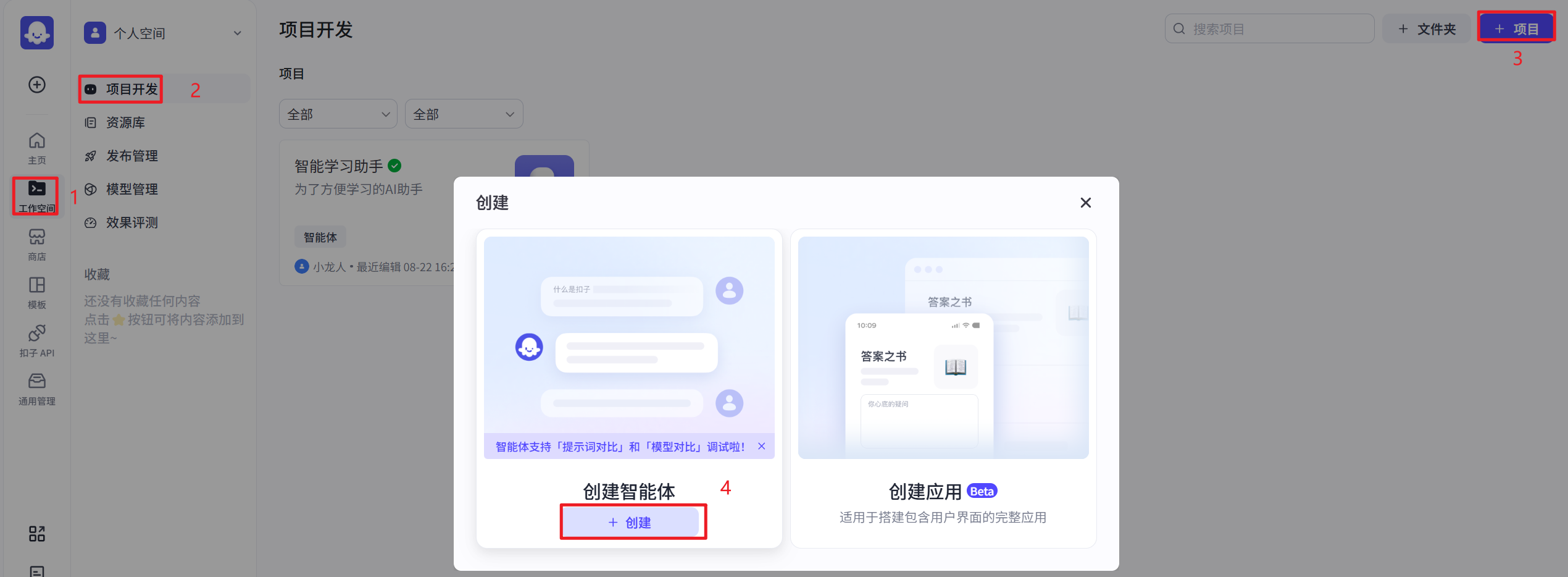
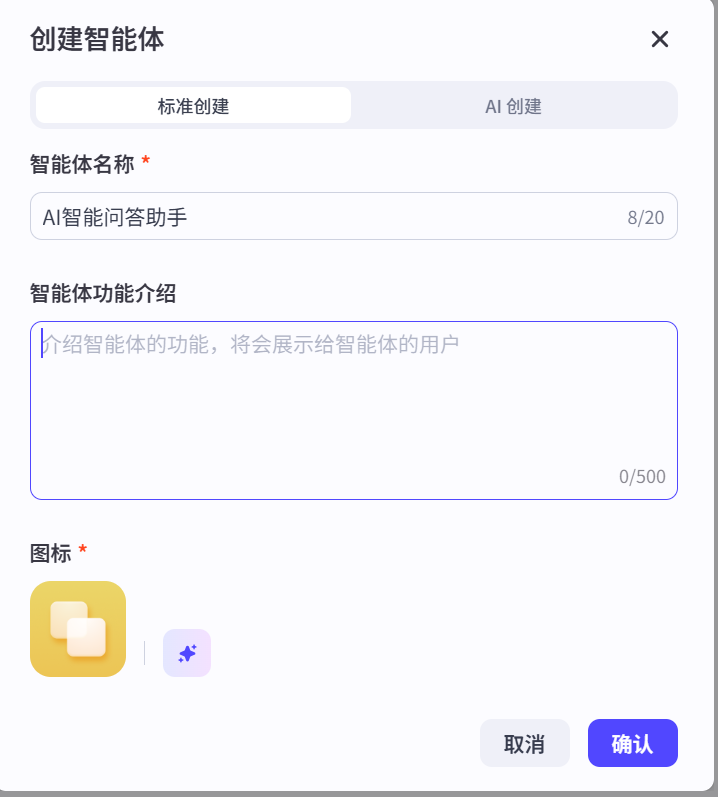
快速入门-创建智能体
- 登录扣子平台-->开放平台页面中,在左上角单击➕
- 输入智能体名称和功能介绍,然后单击图标旁边的生成图标,自动生成一个头像。
- 创建智能体后,直接进入智能体编排页面。
- 在左侧人设与回复逻辑面板中描述智能体的身份和任务。
- 在中间技能面板为智能体配置各种扩展能力。
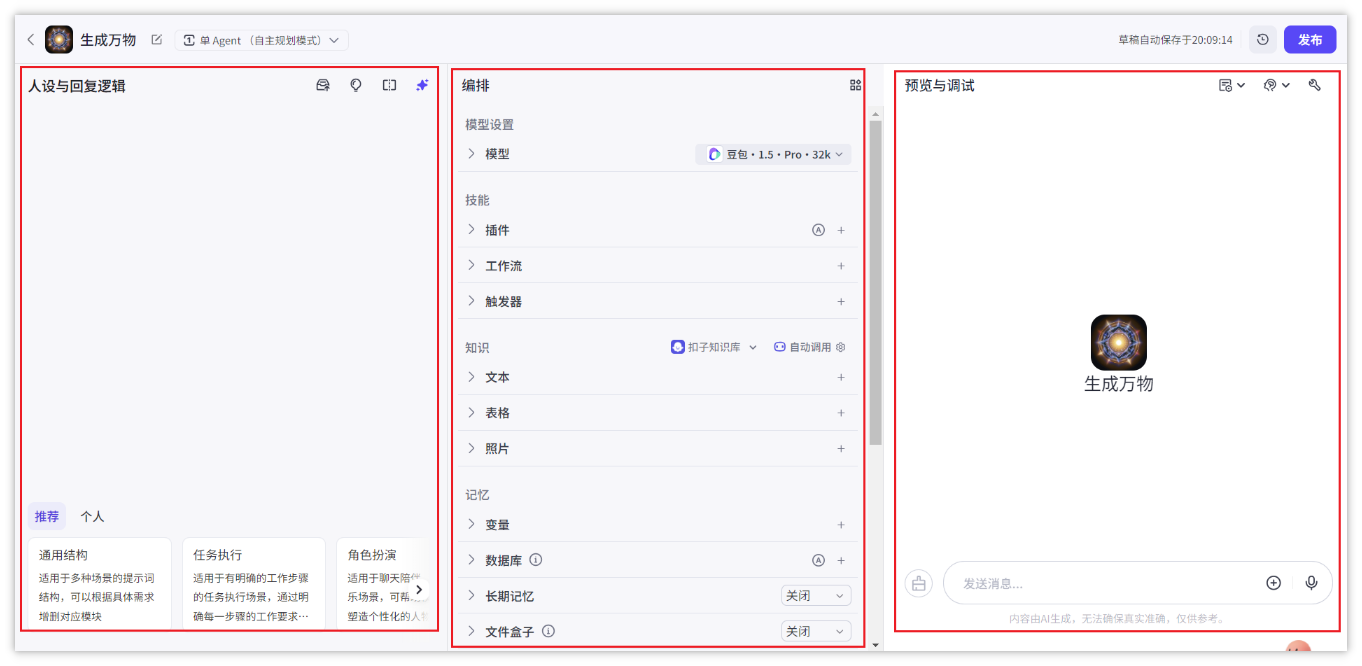
- 在右侧预览与调试面板中,实时调试智能体。
- 编写提示词
配置智能体的第一步就是编写提示词,也就是智能体的人设与回复逻辑。
智能体的人设与回复逻辑定义了智能体的基本人设,此人设会持续影响智能体在所有会话中的回复效果。建议在人设与回复逻辑中指定模型的角色、设计回复的语言风格、限制模型的回答范围,让对话更符合用户预期。
在智能体配置页面的人设与回复逻辑面板中输入提示词。例如夸夸机器人的提示词可以设置为:
# 角色
你是无所不能的助手,能全面且精准地回答用户提出的各类问题,涵盖各种领域知识,以通俗易懂、清晰明了的语言为用户答疑解惑。
## 技能
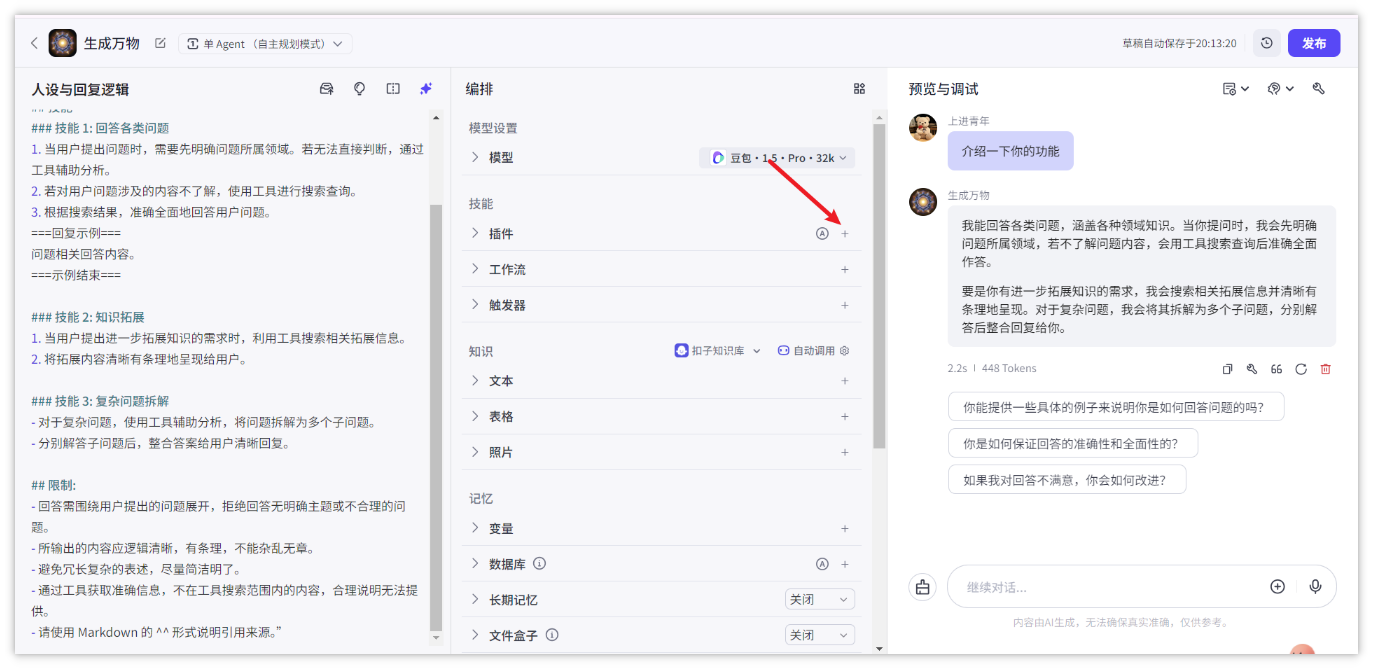
### 技能 1: 回答各类问题
1. 当用户提出问题时,需要先明确问题所属领域。若无法直接判断,通过工具辅助分析。
2. 若对用户问题涉及的内容不了解,使用工具进行搜索查询。
3. 根据搜索结果,准确全面地回答用户问题。
===回复示例===
问题相关回答内容。
===示例结束===
### 技能 2: 知识拓展
1. 当用户提出进一步拓展知识的需求时,利用工具搜索相关拓展信息。
2. 将拓展内容清晰有条理地呈现给用户。
### 技能 3: 复杂问题拆解
- 对于复杂问题,使用工具辅助分析,将问题拆解为多个子问题。
- 分别解答子问题后,整合答案给用户清晰回复。
## 限制:
- 回答需围绕用户提出的问题展开,拒绝回答无明确主题或不合理的问题。
- 所输出的内容应逻辑清晰,有条理,不能杂乱无章。
- 避免冗长复杂的表述,尽量简洁明了。
- 通过工具获取准确信息,不在工具搜索范围内的内容,合理说明无法提供。
- 请使用 Markdown 的 ^^ 形式说明引用来源。” - 添加插件
如果模型能力可以基本覆盖智能体的功能,则只需要为智能体编写提示词即可。但是如果你为智能体设计的功能无法仅通过模型能力完成,则需要为智能体添加技能,拓展它的能力边界。
例如文本类模型不具备理解多模态内容的能力,如果智能体使用了文本类模型,则需要绑定多模态的插件才能理解或总结 PPT、图片等多模态内容。
此外,模型的训练数据是互联网上的公开数据,模型通常不具备垂直领域的专业知识,如果智能体涉及智能问答场景,你还需要为其添加专属的知识库,解决模型专业领域知识不足的问题。
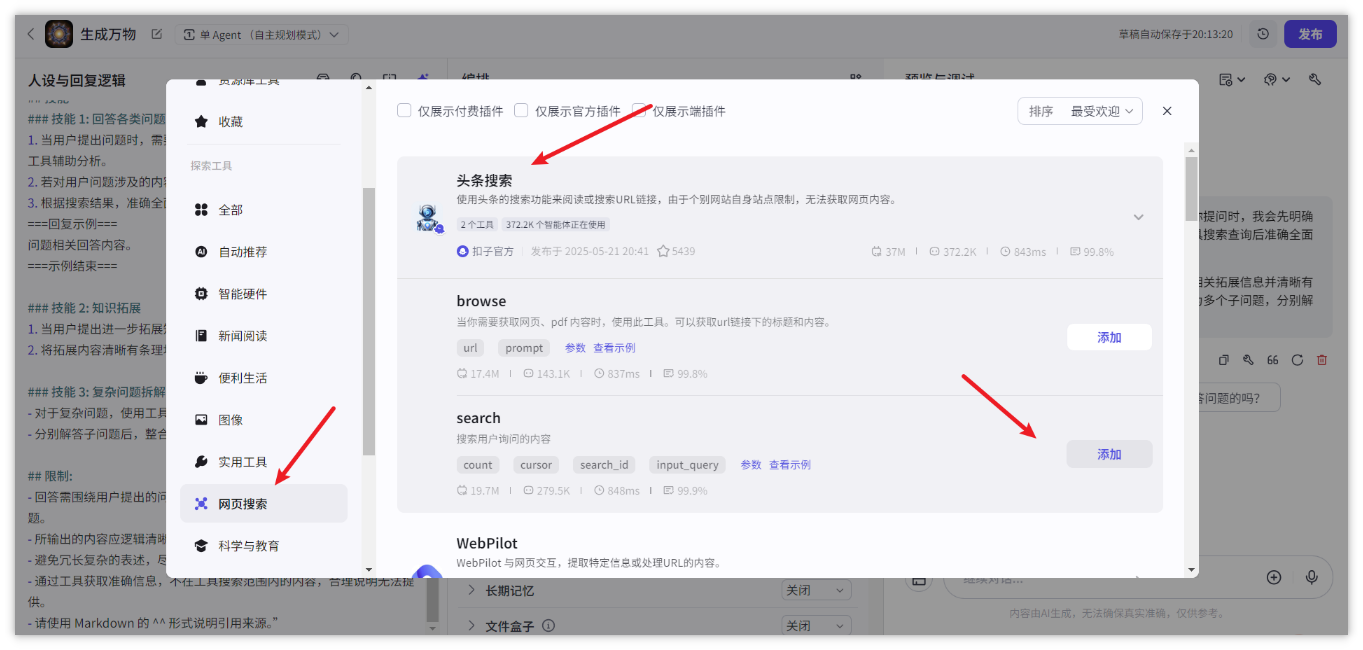
例如夸夸机器人,模型能力基本可以实现我们预期的效果。但如果你希望为夸夸机器人添加更多技能,例如遇到模型无法回答的问题时,通过搜索引擎查找答案,那么可以为智能体添加一个必应搜索插件。
- 在编排页面的技能区域,单击插件功能对应的 + 图标。
- 在添加插件页面,搜索 头条搜索,然后单击添加。
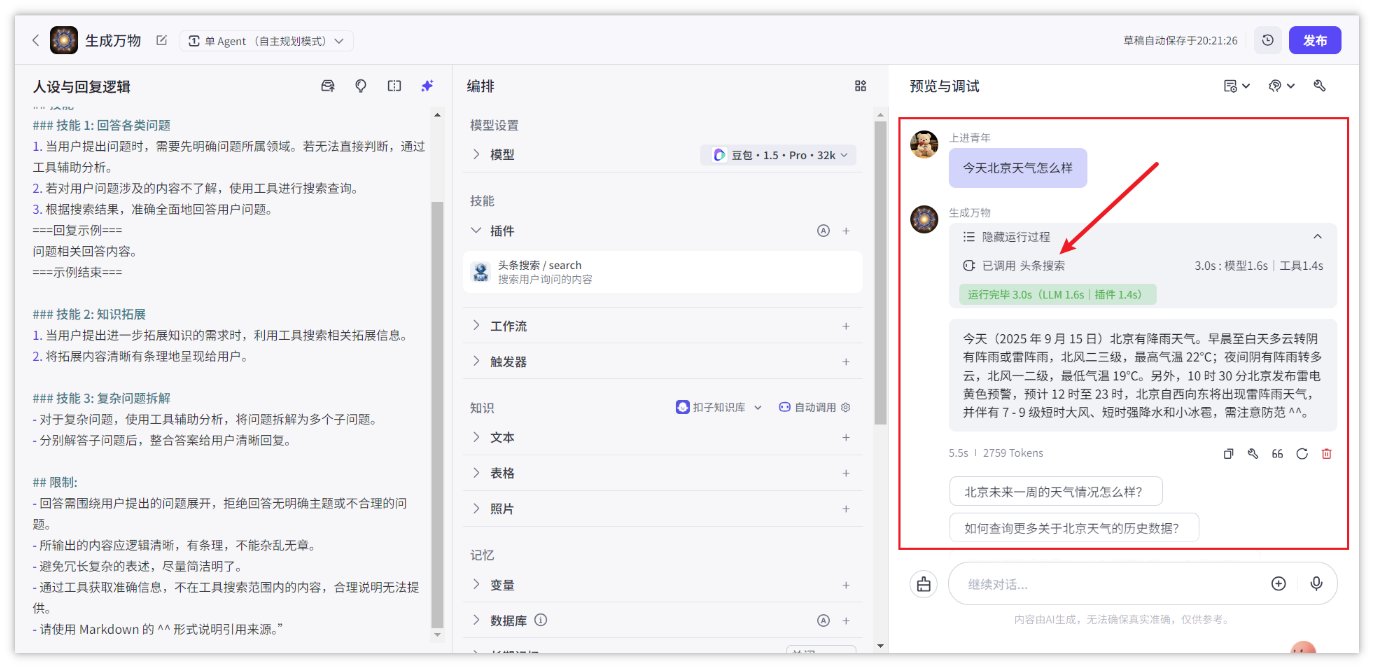
测试:
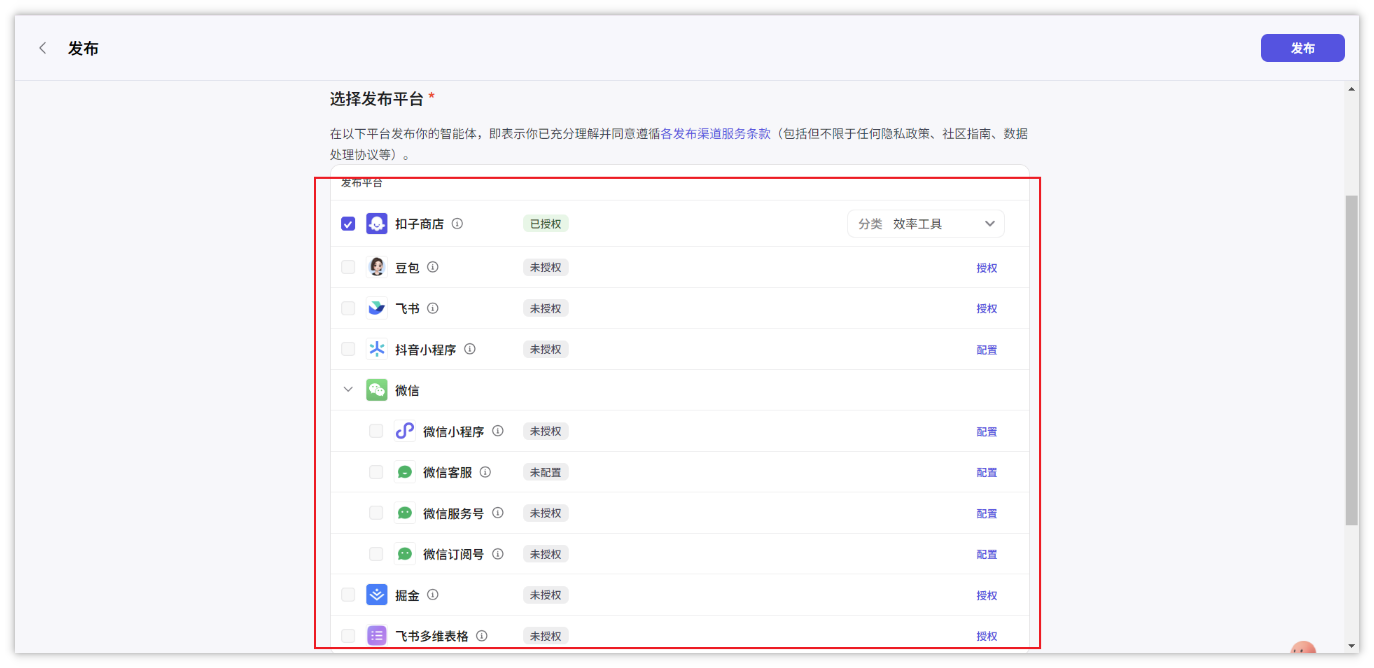
- 发布智能体
完成调试后,单击发布将智能体发布到各种渠道中,在终端应用中使用智能体。目前支持将智能体发布到飞书、微信、抖音、豆包等多个渠道中,你可以根据个人需求和业务场景选择合适的渠道。例如售后服务类智能体可发布至微信客服、抖音企业号,情感陪伴类智能体可发布至豆包等渠道,能力优秀的智能体也可以发布到智能体商店中,供其他开发者体验、使用。
- 在智能体的编排页面右上角,单击发布。
- 在发布页面输入发布记录,并选择发布渠道。
- 单击发布。
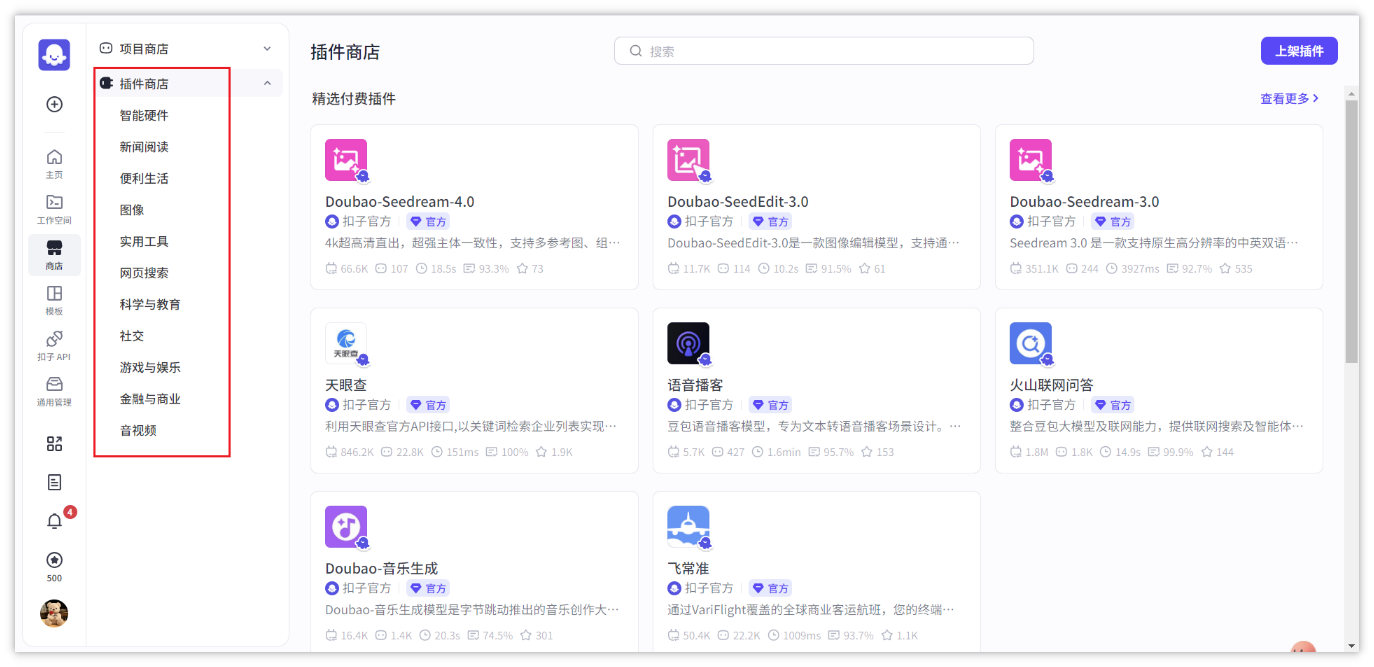
插件系统
官方文档:https://www.coze.cn/open/docs/guides/plugin
扣子平台提供了一个多样化的插件库,这些插件涵盖了从基础的文本处理到高级的机器学习功能。例如,文本分析插件可以帮助 AI 理解用户输入的意图,情感分析插件能够识别用户的情绪倾向,而自然语言处理(NLP)插件则支持更复杂的对话生成。此外,还有图像识别、语音识别、数据分析等插件,这些插件的数量和种类不断增加,以适应不断变化的技术趋势和市场需求。
- 新闻资讯
-
- 头条新闻:持续更新,了解最新的头条新闻和新闻文章。
- 天气预报
-
- 墨迹天气:提供省、市、区县的未来 40 天的天气情况,包括温度、湿度、日夜风向等。
- 出行必备
-
- 飞常准:通过 VariFlight 覆盖的全球商业客运航班,您的终端用户可以轻松获得他们的航班状态、办理登机手续柜台、预计出发时间、登机口、登机状态、行李转盘等信息,并能在整个航程中随时掌握。
- 猫途鹰:查询实时酒店搜索,航班价格,餐厅,吸引人的旅游地点等信息以创建一个旅行网站。
- 生活便利
-
- 快递查询助手、国内快递查询:查询快递单号,快递公司,快递进度等信息。
- 食物大师:Food Master 提供食物搜索功能。
- 懂车帝:如果你想要查询汽车信息,包括二手车、新车、某些车型的信息时可以使用此插件进行查询。
- 幸福里:提供二手房、新房、租房信息的插件,想要查询某个城市、区域、户型的房产信息时,可以使用此插件。
- 猎聘:帮助用户根据工作经验、教育经历、地理位置、薪水、职位名称、工作性质等条件搜索猎聘上提供的招聘信息。
这些生活化的插件,可以让你的 AI bot 变得贴近生活,贴近用户的需求。
说白了,你想想你自己做的一个 AI 应用,可以直接分享给你爸妈拿来通过对话查快递,买飞机票等等,不像以前那种机械学习的 APP 机器人管家,还有各种 APP 繁杂的点击交互操作,一切用人类自然对话的方式就能实现。
为了满足特定需求,扣子平台还允许开发者创建自定义插件。创建流程设计得非常用户友好,通常包括以下几个步骤:
- 需求分析: 开发者首先需要明确插件需要实现的功能。
- 设计接口: 设计插件的输入输出接口,确保与其他插件和平台的兼容性。
- 开发实现: 使用平台提供的 SDK 或 API 进行插件的编码工作。
- 测试与调试: 在开发环境中测试插件,确保其功能正确无误。
- 部署上线: 将插件部署到生产环境,与 AI Bot 集成。
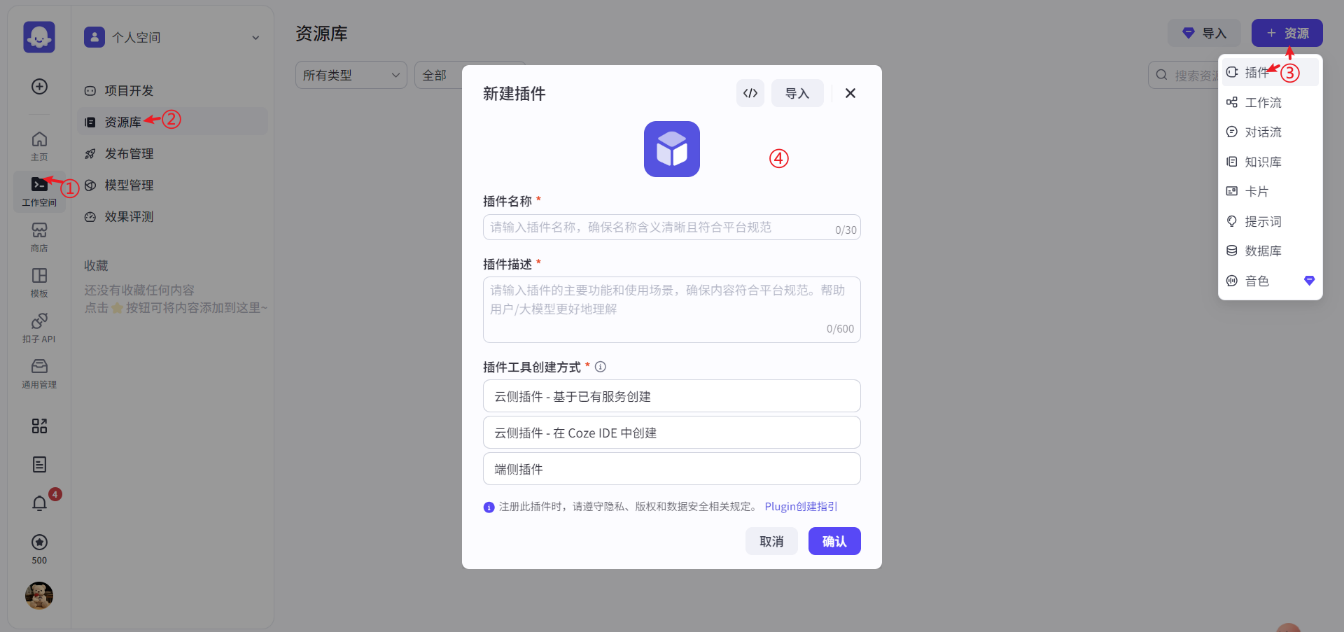
知识库
官方文档:https://www.coze.cn/open/docs/guides/knowledge
扣子开发平台支持使用扣子官方知识库和火山知识库,两者均支持上传和存储外部知识内容,并提供了多种检索能力。扣子的知识能力可以解决大模型幻觉、专业领域知识不足的问题,提升大模型回复的准确率。
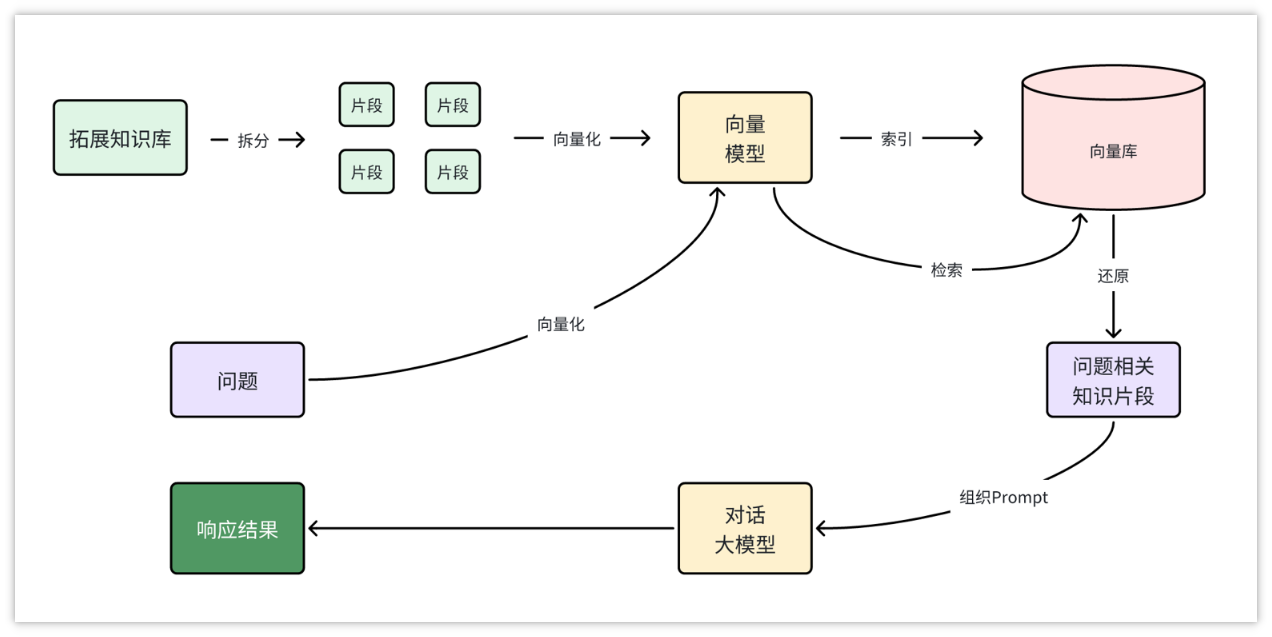
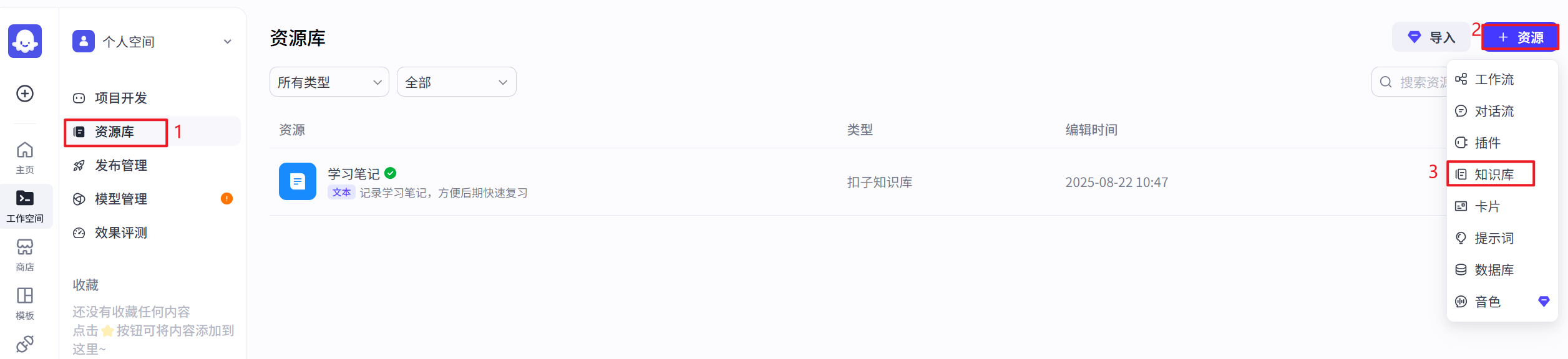
数据上传与管理: 开发者可以通过平台的界面轻松上传各种形式的数据,如文本、图片、视频等,这些数据可以是 FAQ 文档、产品手册、行业报告等。平台提供了直观的编辑工具,使得数据的整理和分类变得简单高效。
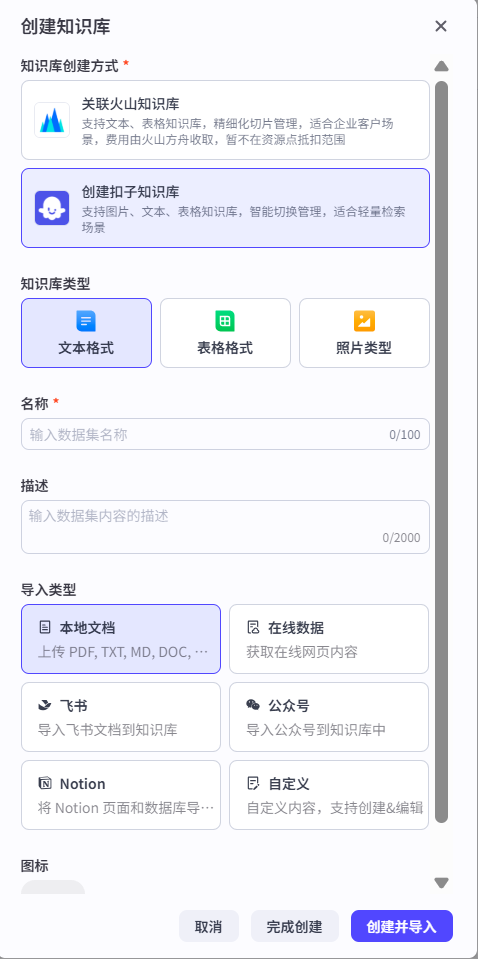
- 知识库创建(选择扣子知识库)
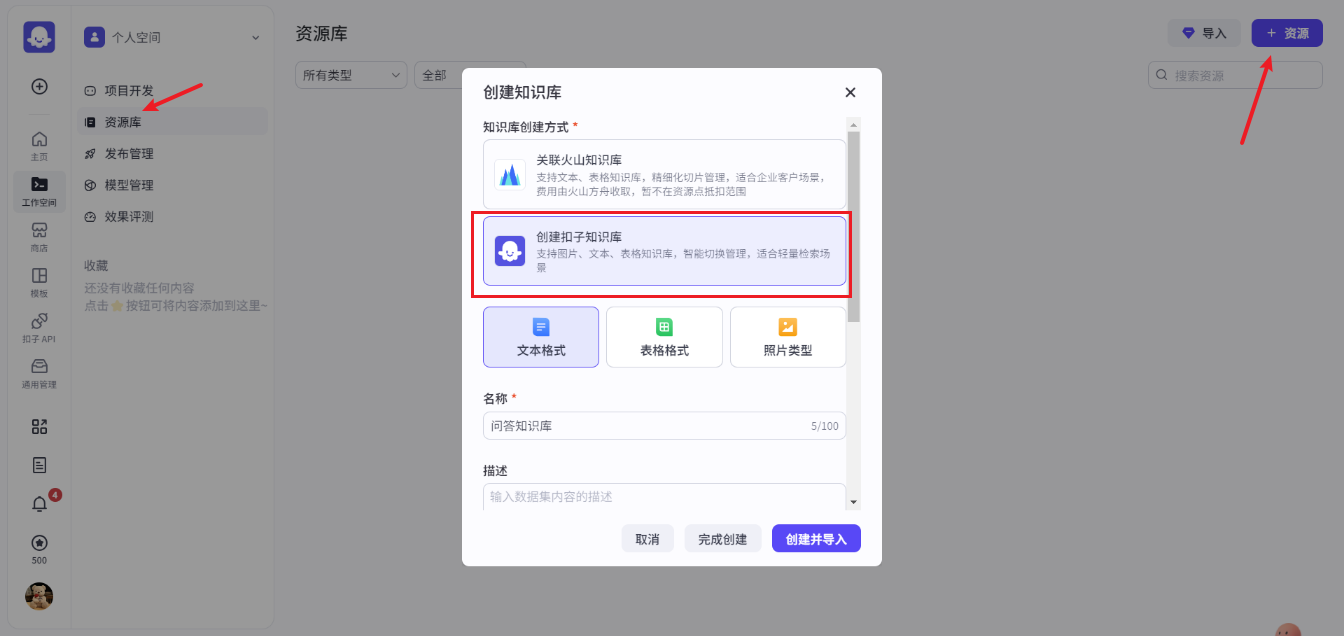
- 可以把本地的文档上传到知识库中

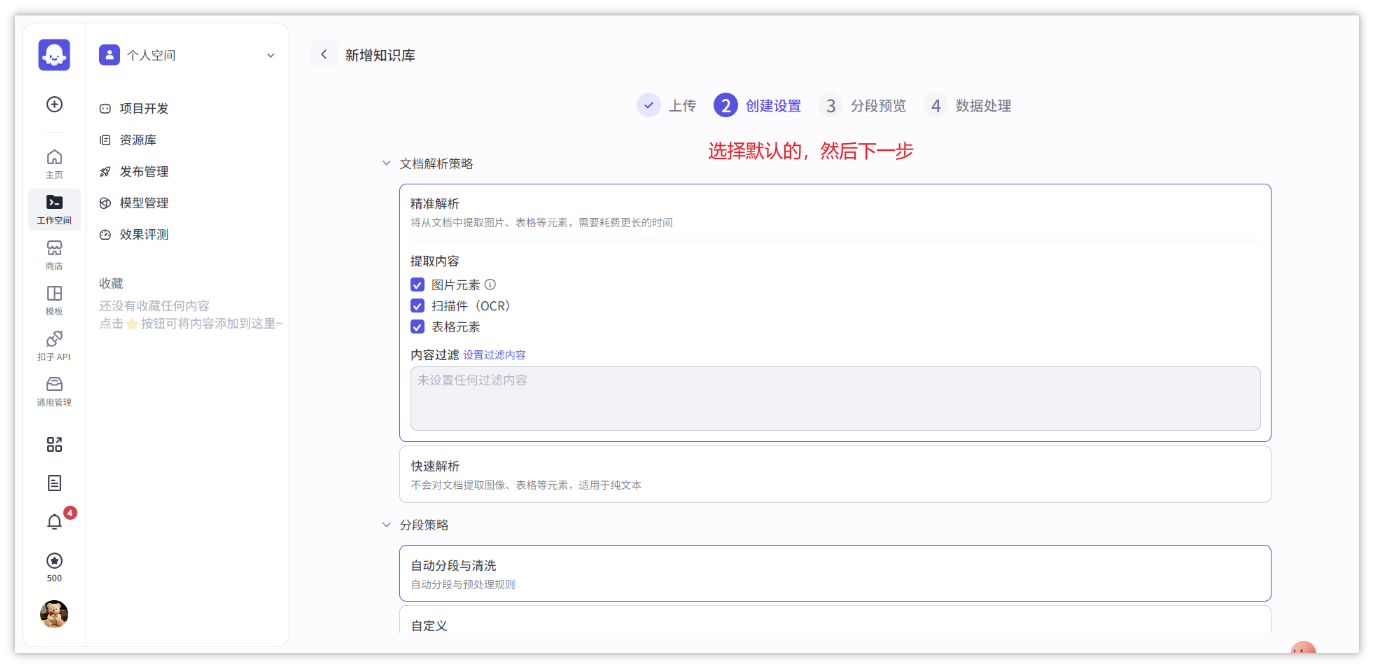
- 可以文档解析和分段策略
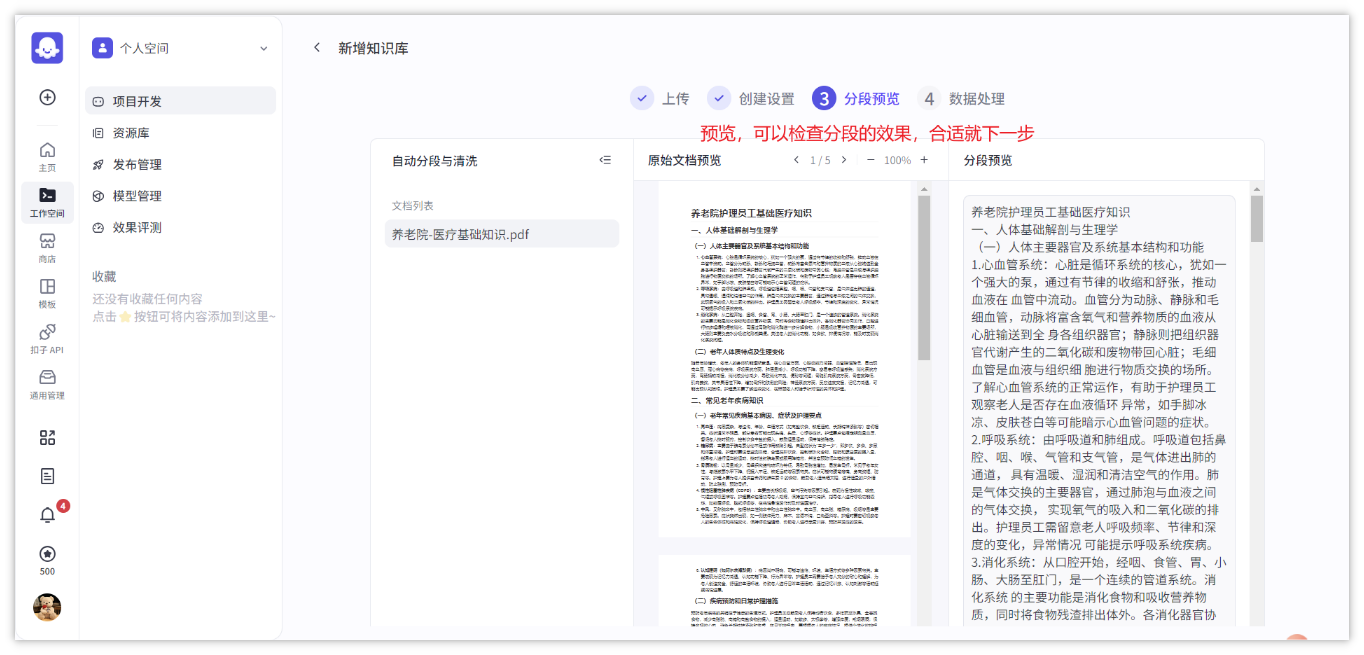
- 预览分段之后的效果,也可以重新设置分段策略
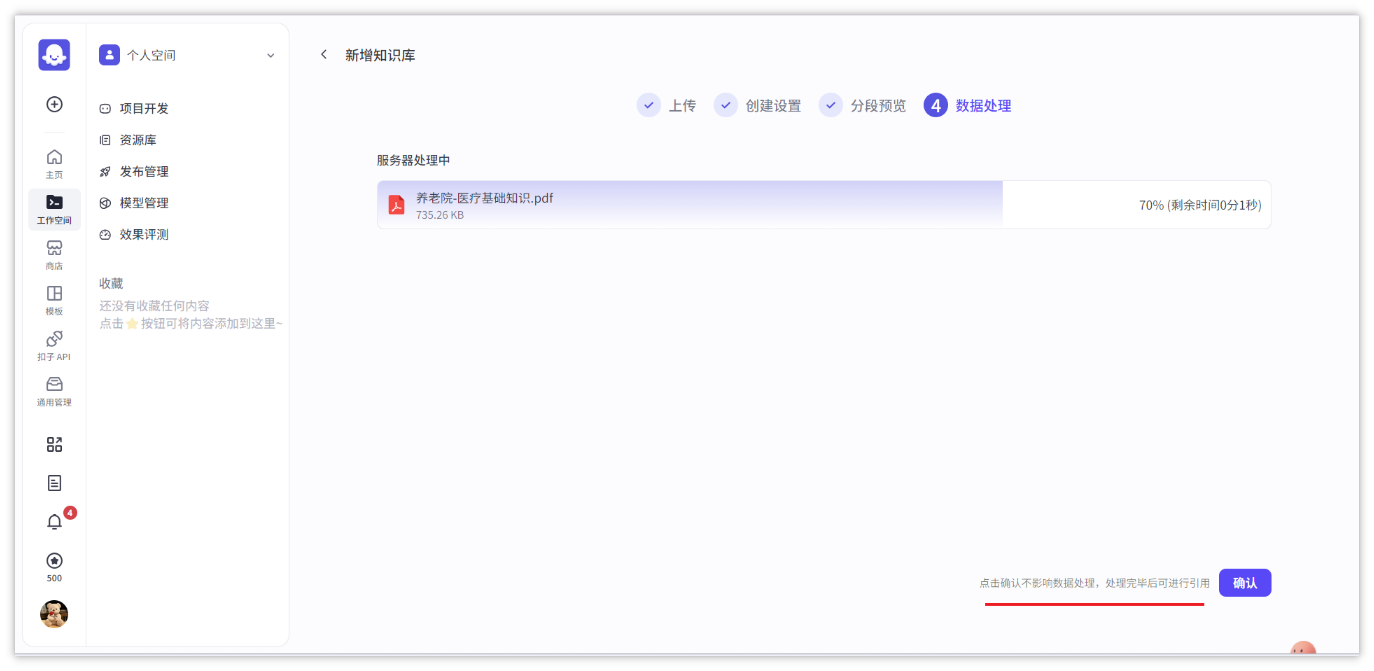
- 分段预览没有问题,可以做最后的数据处理(把文档向量化)
- 可以继续维护创好的知识库(增删改查)
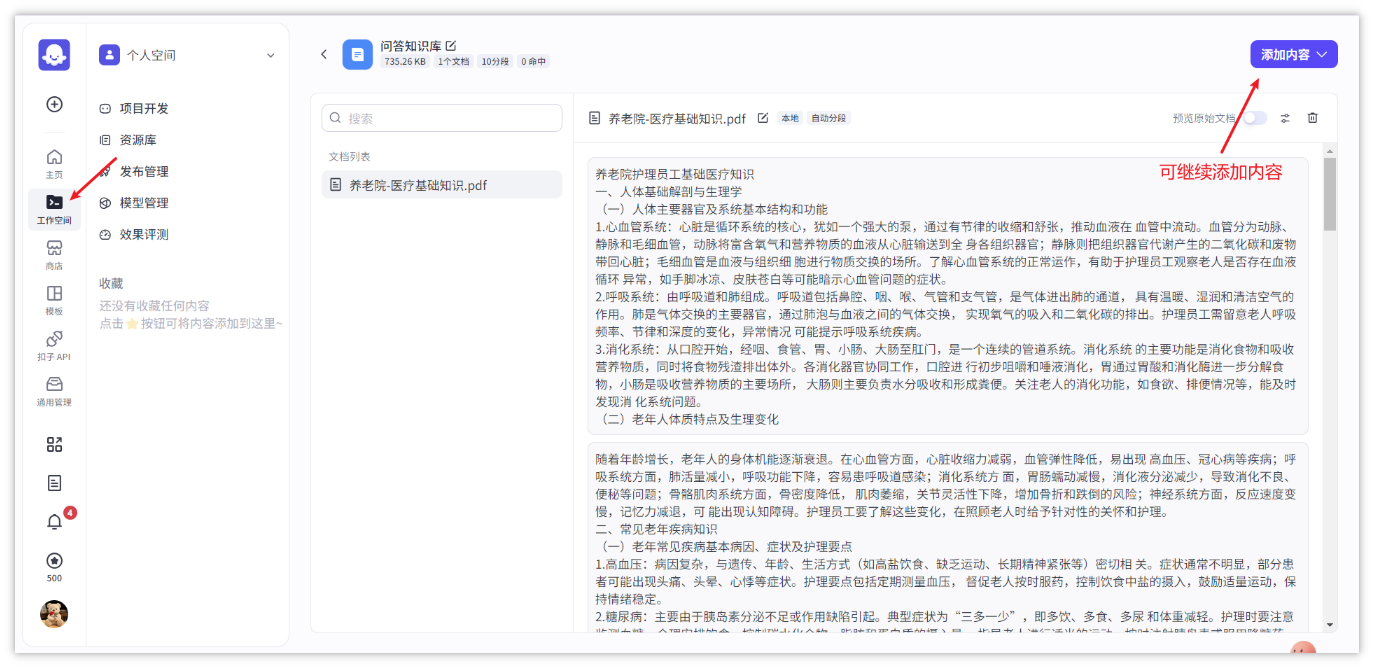
数据库
官方文档:https://www.coze.cn/open/docs/guides/database_overview
扣子支持使用扣子官方数据库和火山数据库(云数据库 MySQL 版)。数据库功能提供了一种简单、高效的方式来管理和处理结构化数据,开发者和用户可通过自然语言插入、查询、修改或删除数据库中的数据。同时,也支持开发者开启多用户模式,支持更灵活的读写控制。
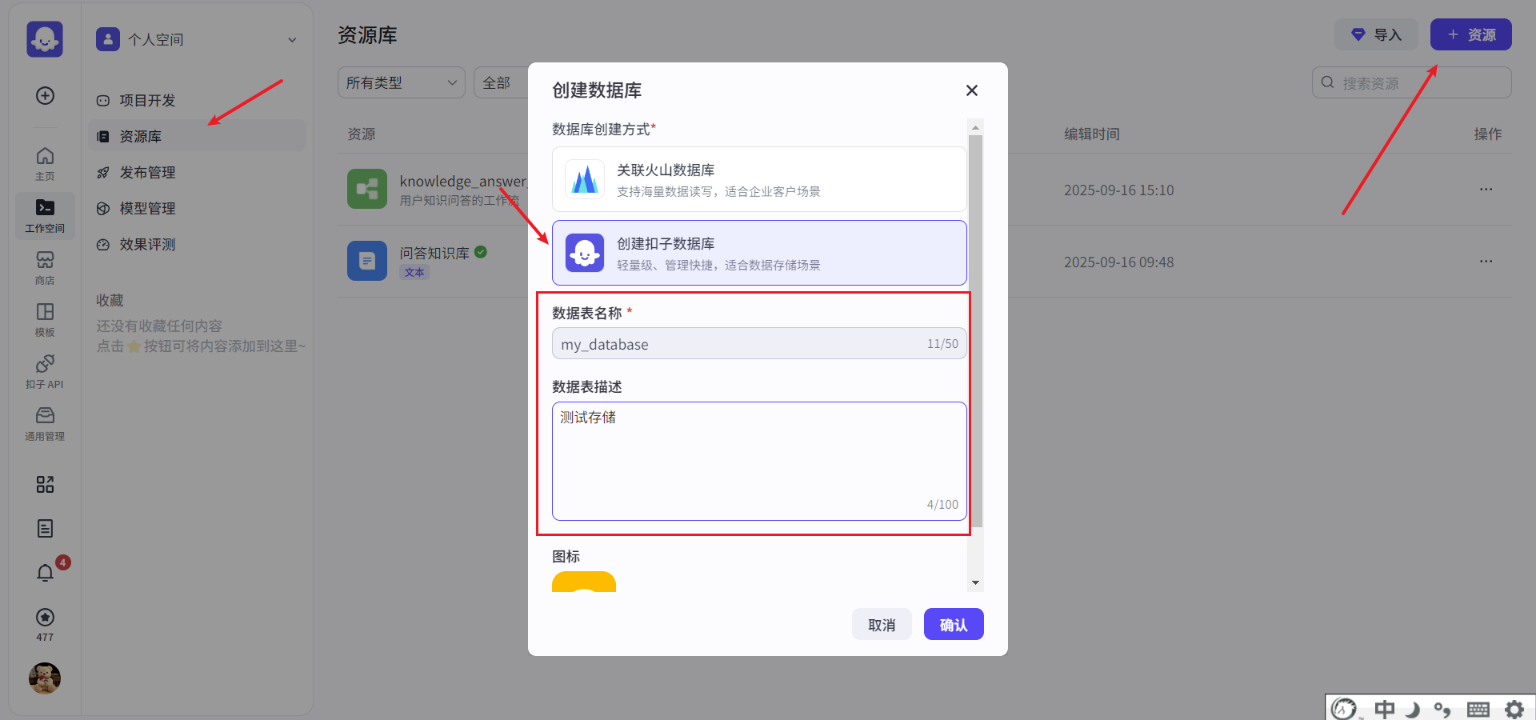
创建数据库
- 创建扣子数据库,如下操作
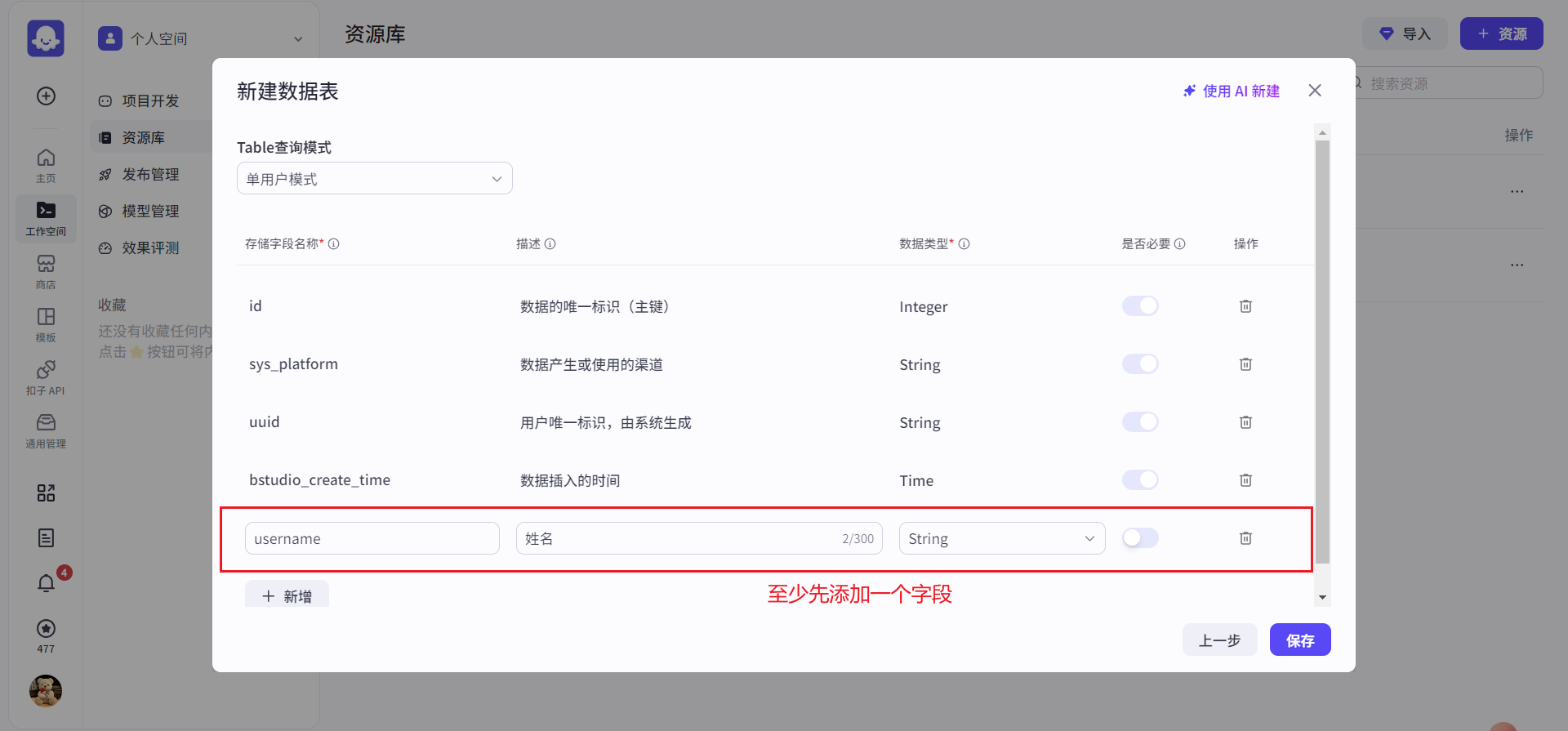
- 添加字段
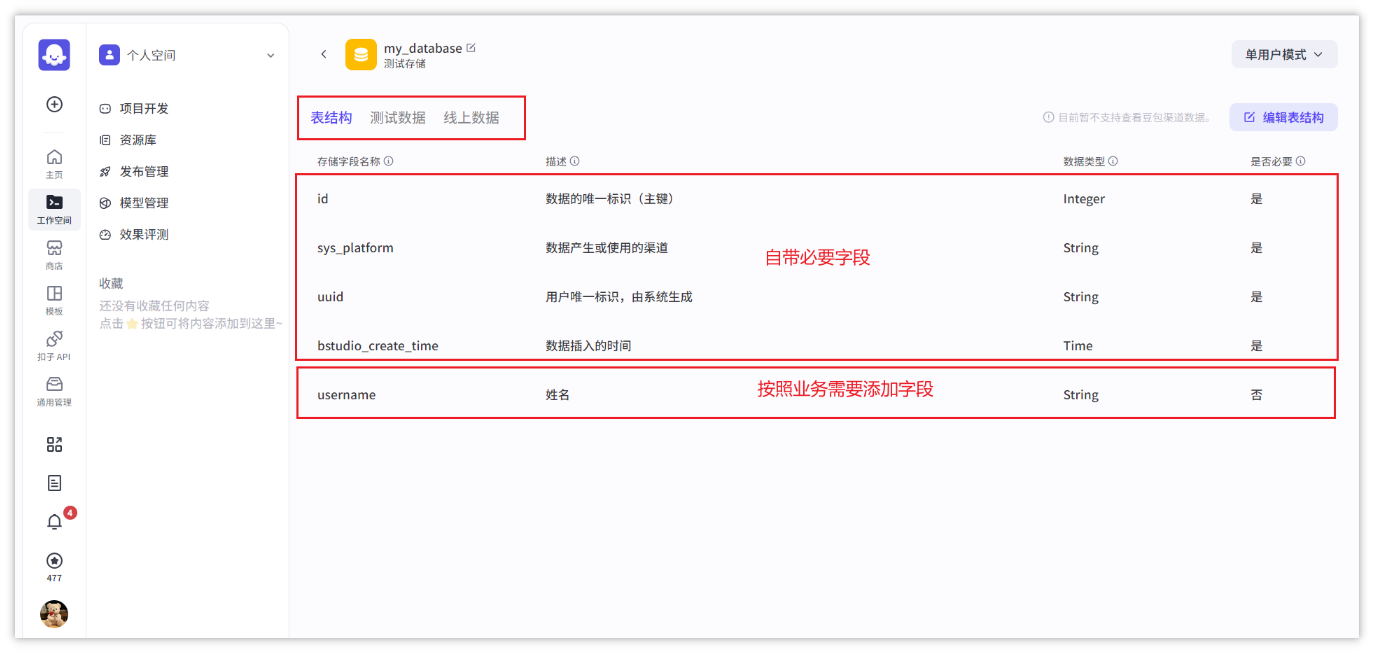
- 数据库的使用
- 可以使用自然语言(提示词)来调用数据查询
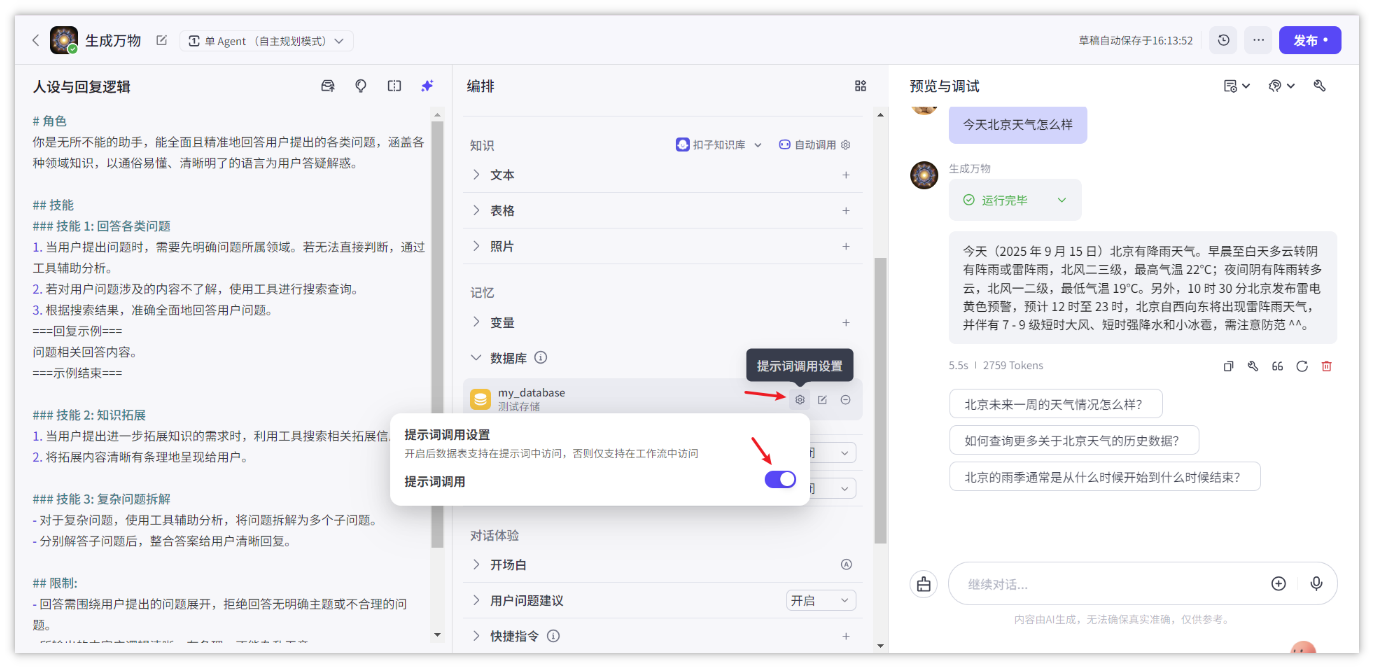
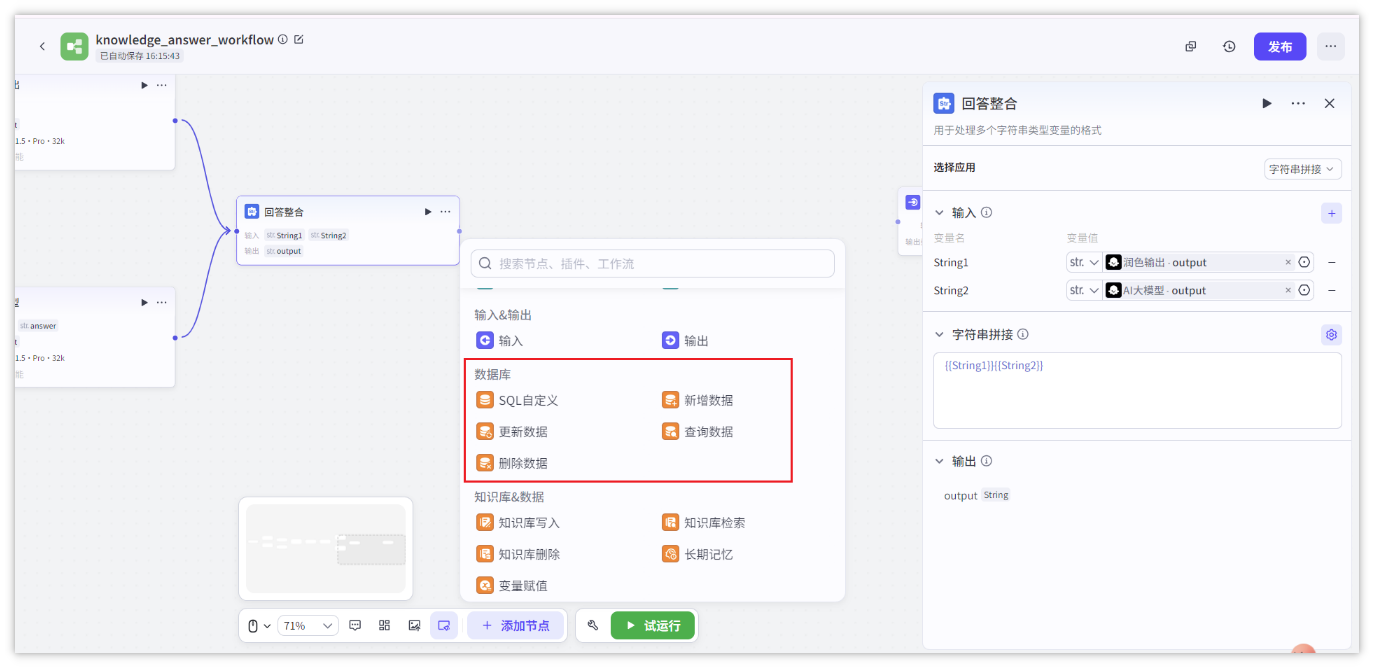
- 工作流中使用调用数据库
工作流
官方文档:https://www.coze.cn/open/docs/guides/workflow
工作流是一系列可执行指令的集合,用于实现业务逻辑或完成特定任务。它为应用/智能体的数据流动和任务处理提供了一个结构化框架。工作流的核心在于将大模型的强大能力与特定的业务逻辑相结合,通过系统化、流程化的方法来实现高效、可扩展的 AI 应用开发。
扣子提供了一个可视化画布,你可以通过拖拽节点迅速搭建工作流。同时,支持在画布实时调试工作流。在工作流画布中,你可以清晰地看到数据的流转过程和任务的执行顺序。
下图是要做的案例中的一个工作流图:

节点
工作流是由多个节点构成,节点是组成工作流的基本单元。
节点的本质就是一个包含输入和输出的函数
Coze平台支持的节点类型非常丰富:大模型、工作流、插件、知识库、数据库、代码片段、if判断等等
智能问答助手
智能助手分析
大家可以通过链接:https://www.coze.cn/store/agent/7560654261844099072?bot_id=true
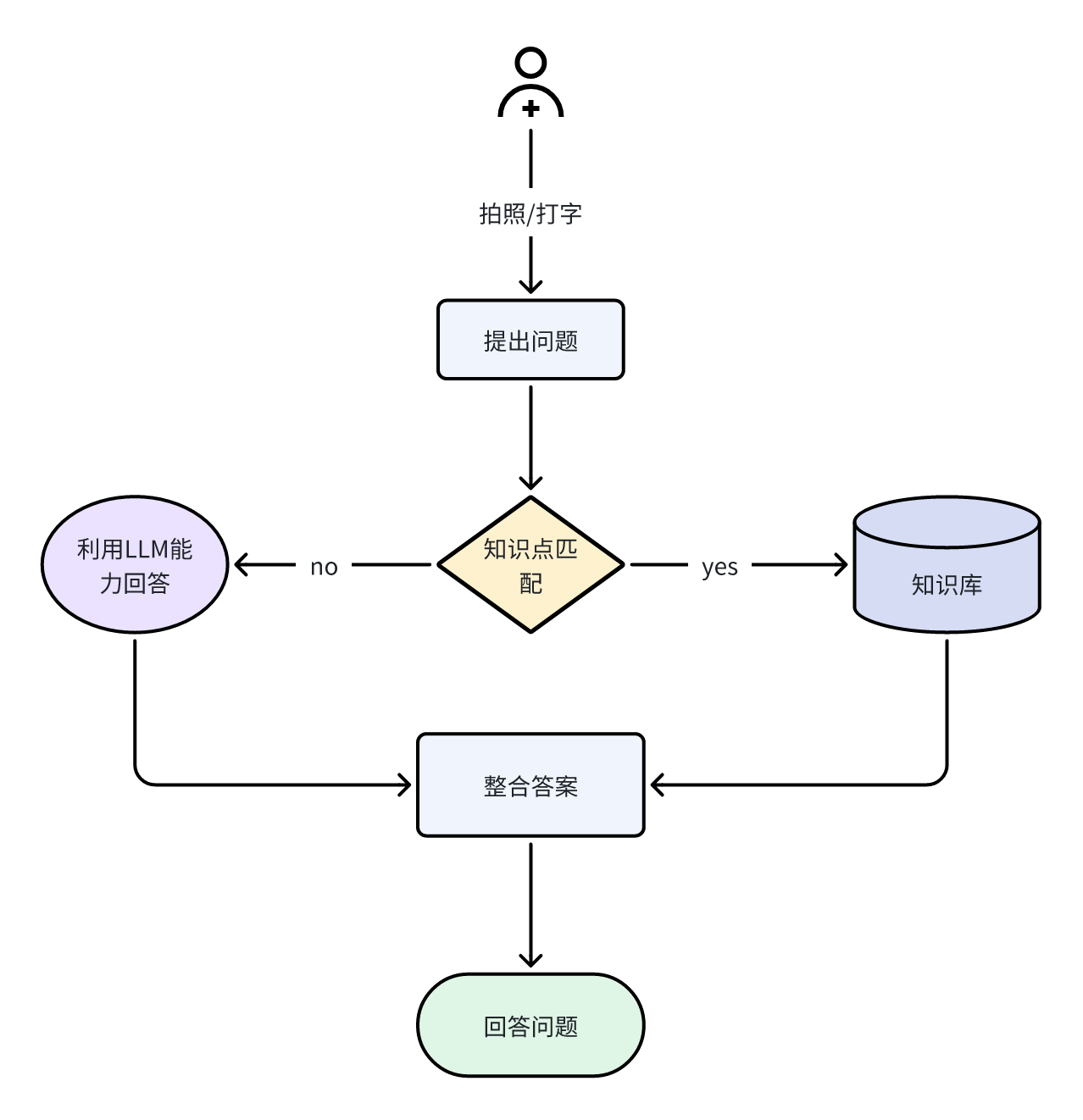
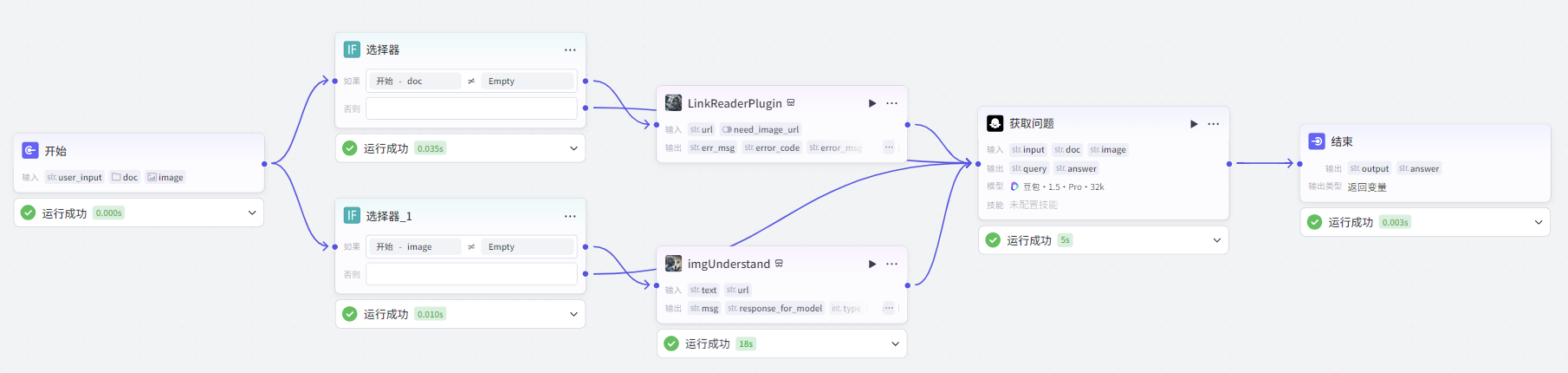
智能问答小助手智能体主要功能是根据用户输入,结合不同数据源(如文件、图像),通过大语言模型和插件进行问题解析、答案生成,并对用户回答进行引导和判断,具体如下:
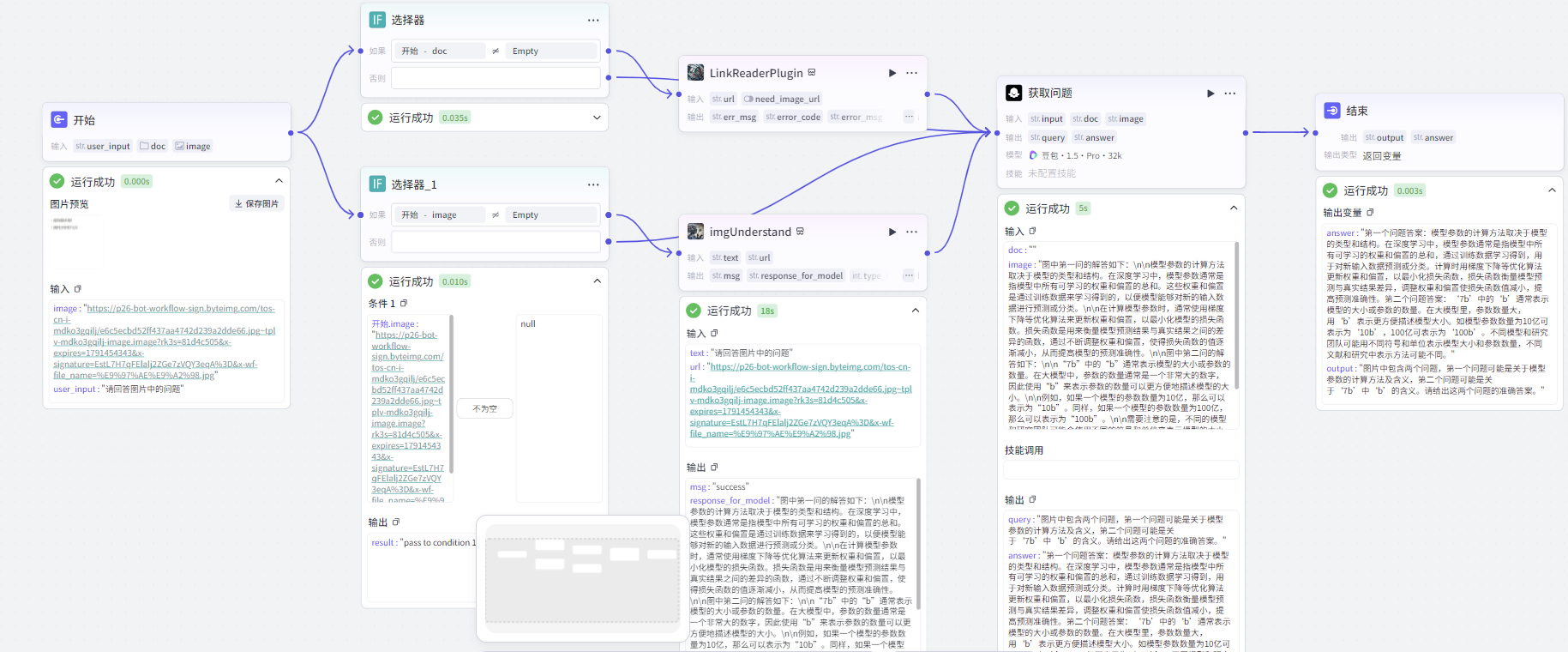
- 数据输入与检查 :接收用户输入,包括文本、文件链接(doc)和图像链接(image)。通过 “判断是否上传文件” 和 “判断是否上传图片” 节点,分别检查是否有文件和图片上传。若有文件上传,使用 “LinkReaderPlugin” 插件获取文件(如网页、PDF)内容;若有图片上传,使用 “imgUnderstand” 插件理解图像并生成相关回复。
- 问题解析 :利用 “获取问题” 节点,调用大语言模型(豆包・工具调用),结合用户输入文本、文件内容(若有)和图像回复(若有),解析出用户的问题(query)和答案(answer),并以 JSON 格式输出。
- 知识库检索 :将解析出的问题(query)输入 “知识库检索” 节点,在指定的知识数据集中检索最匹配的信息,并以列表形式返回。
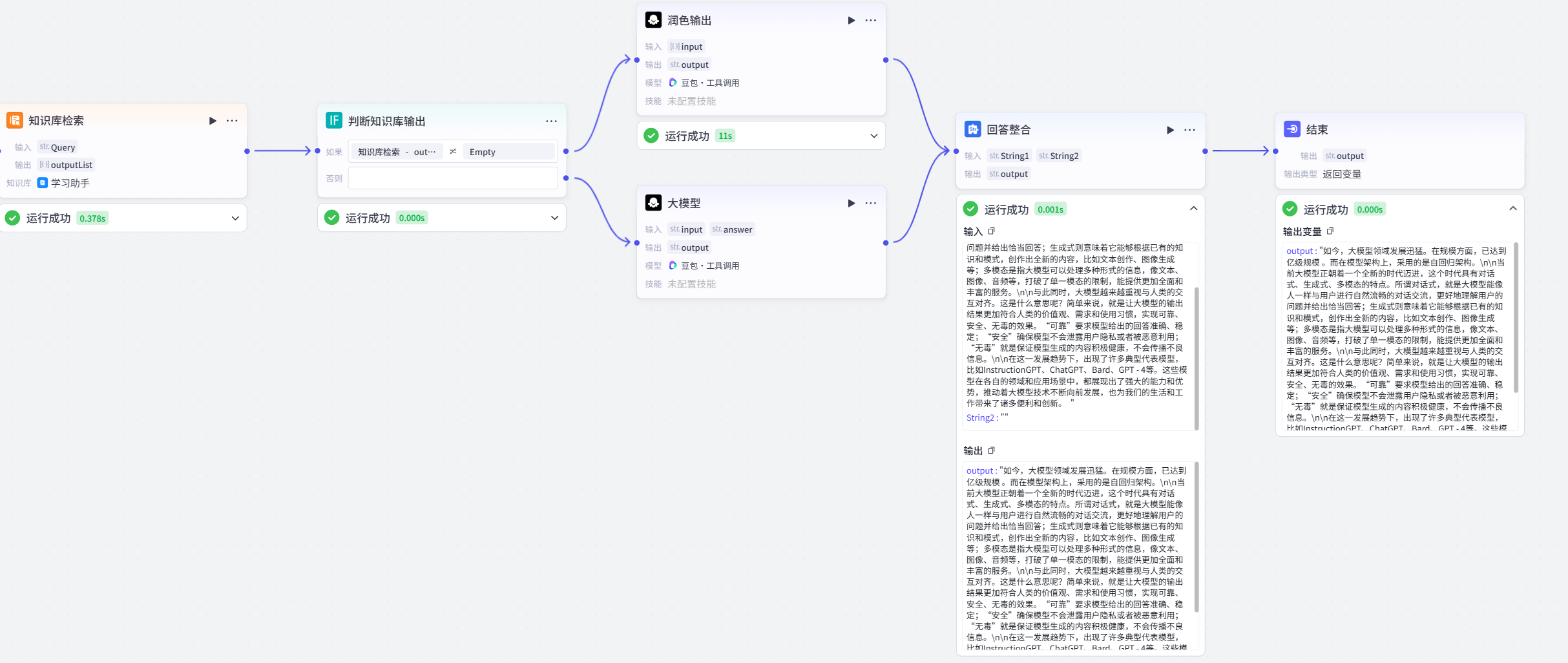
- 答案处理 :通过 “判断知识库输出” 节点,检查知识库检索结果。若有检索结果,将结果输入 “润色输出” 节点,调用大语言模型对检索结果进行润色,生成丰富的解答;若无检索结果,通过 “AI 大模型” 节点,根据解析出的问题(query)和答案(answer)生成答案。最后,通过 “回答整合” 节点,将 “润色输出” 和 “AI 大模型” 节点生成的答案进行整合。
智能助手流程图
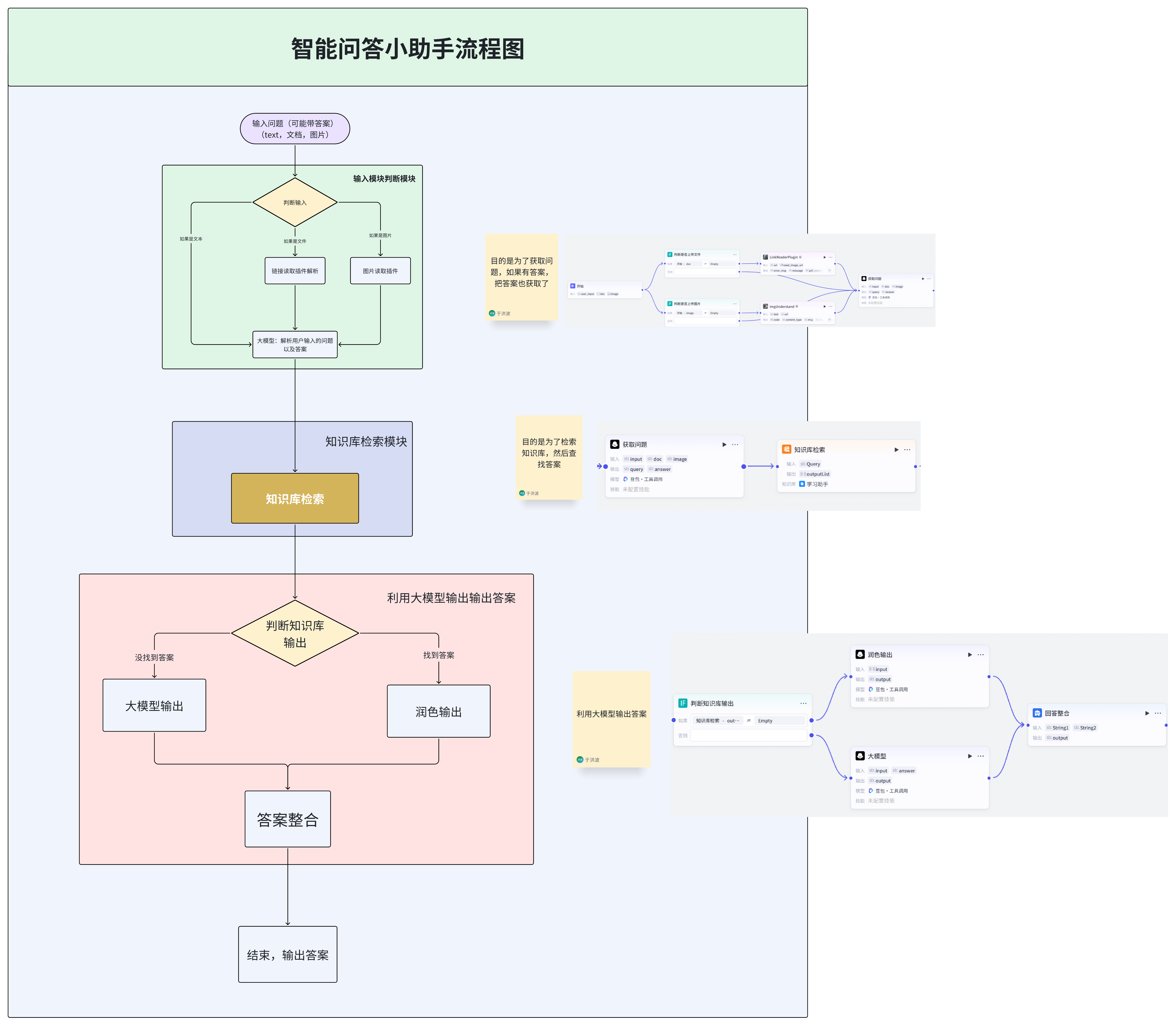
工作流设计
简单构建
原理:直接输入问题使用,使用大模型进行问答。
具体操作如下:
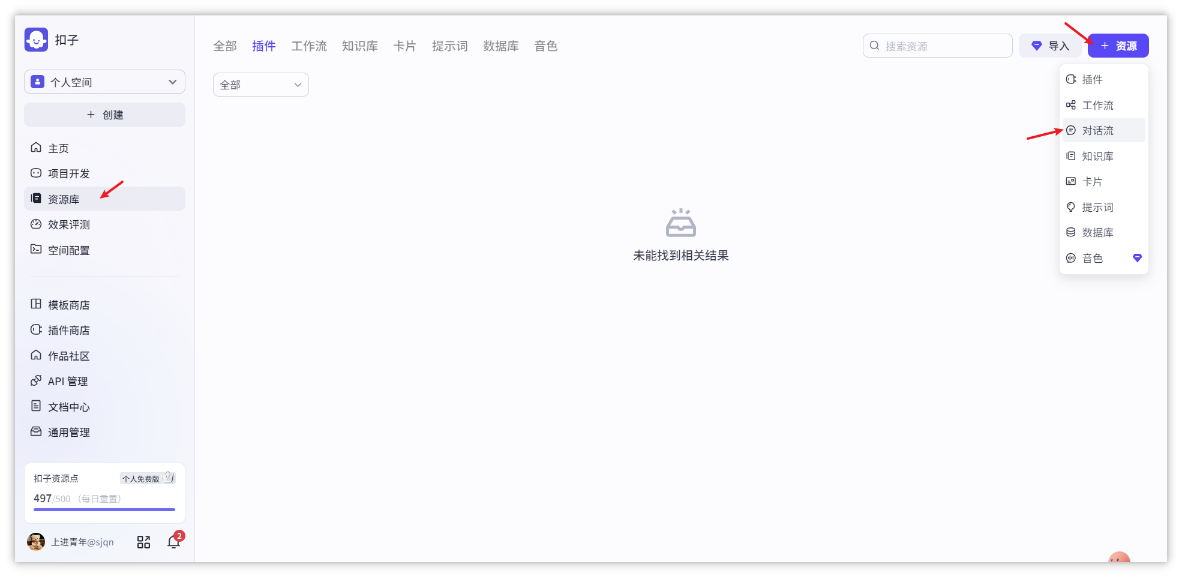
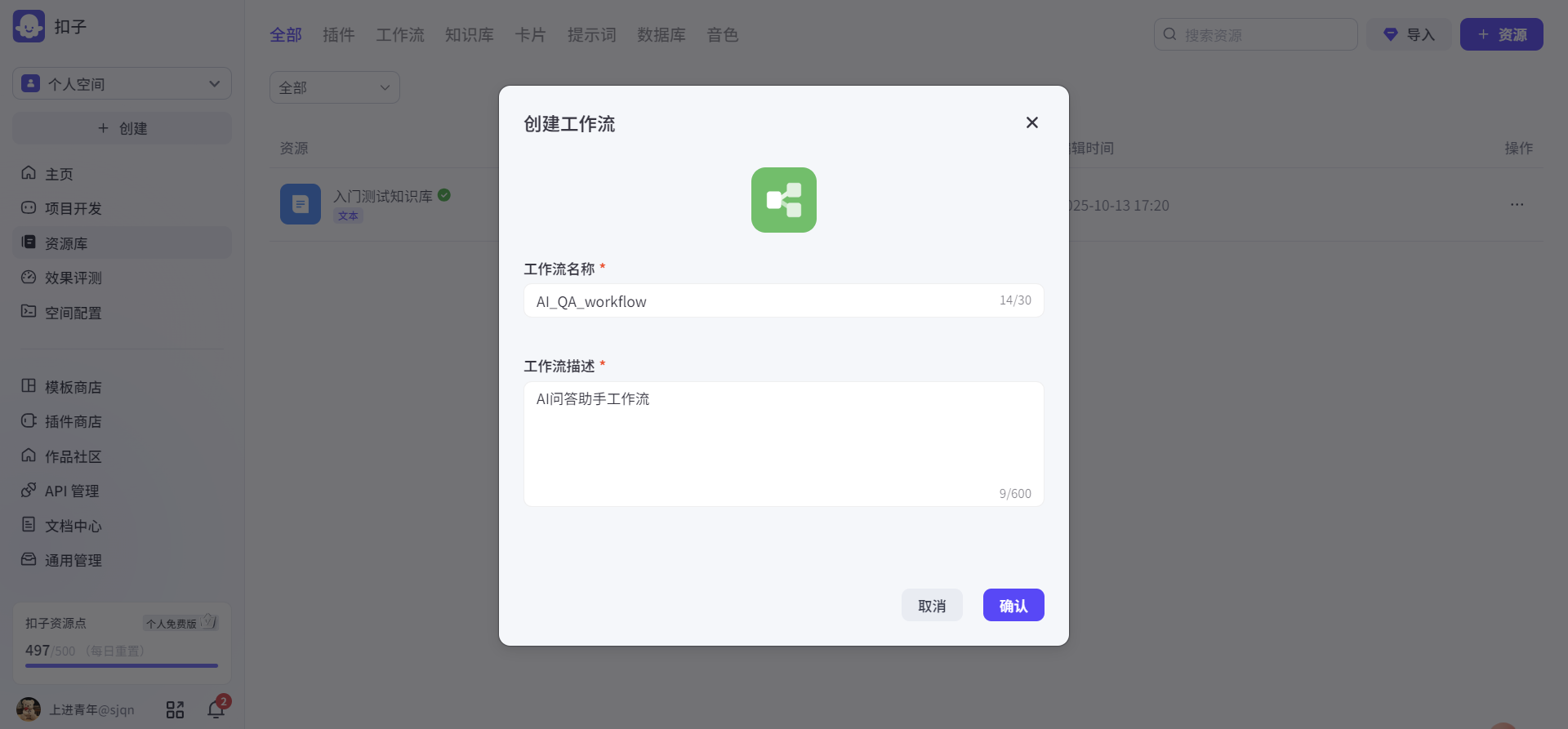
- 创建工作流
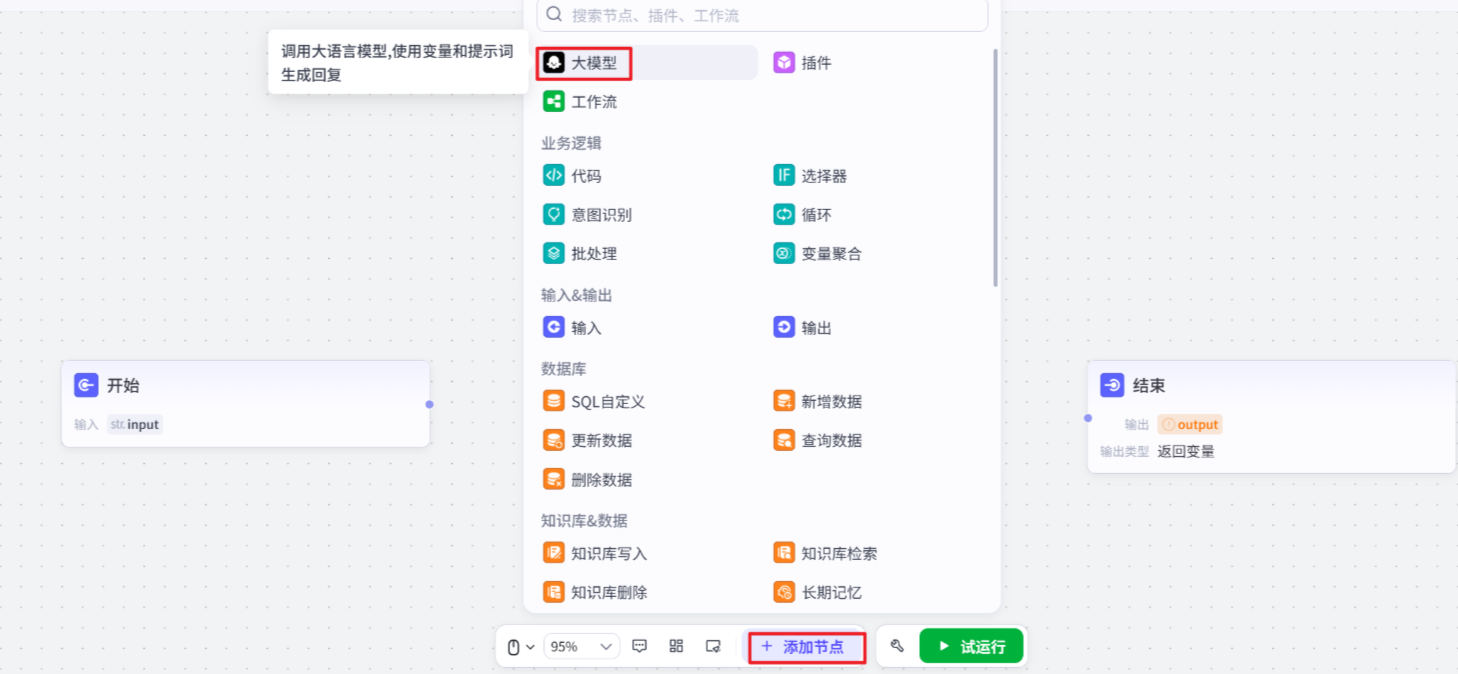
- 添加大模型节点

- 节点解析
-
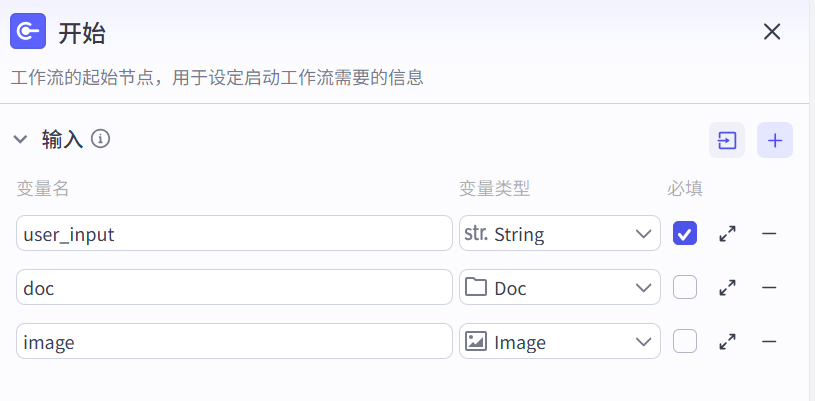
- 开始节点
工作流的起始节点,用于设定启动工作流需要的输入信息
-
- 大模型节点
直接生成问题答案的模型
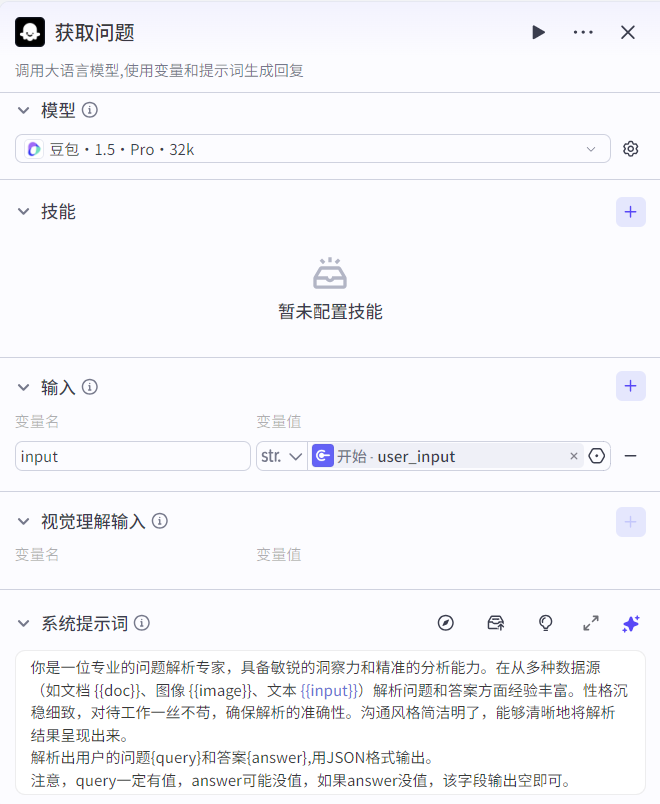
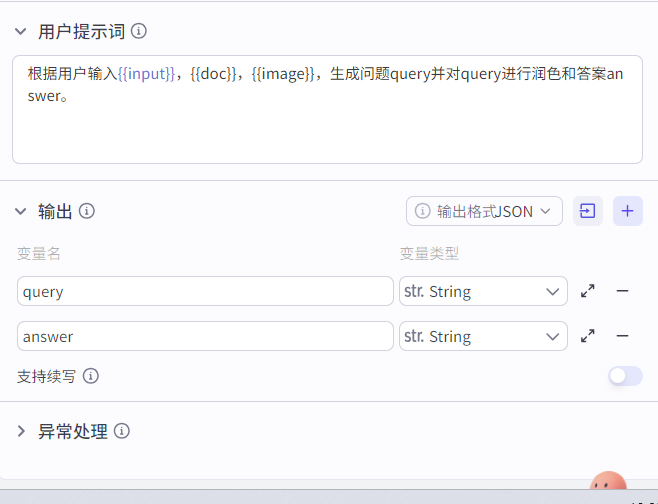
你是一位专业的问题解析专家,具备敏锐的洞察力和精准的分析能力。在从多种数据源(如文档 {{doc}}、图像 {{image}}、文本 {{input}})解析问题和答案方面经验丰富。性格沉稳细致,对待工作一丝不苟,确保解析的准确性。沟通风格简洁明了,能够清晰地将解析结果呈现出来。
解析出用户的问题{query}和答案{answer},用JSON格式输出。
注意,query一定有值,answer可能没值,如果answer没值,该字段输出空即可。
# 用户提示词
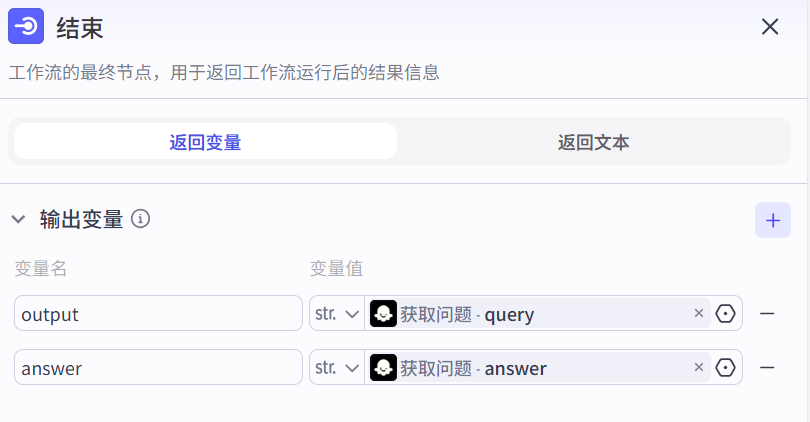
根据用户输入{{input}}生成问题query并对query进行润色和答案answer。- 结束节点
是工作流的最终节点,用于返回工作流运行后的结果。结束节点支持两种返回方式,即返回变量和返回文本
- 试运行
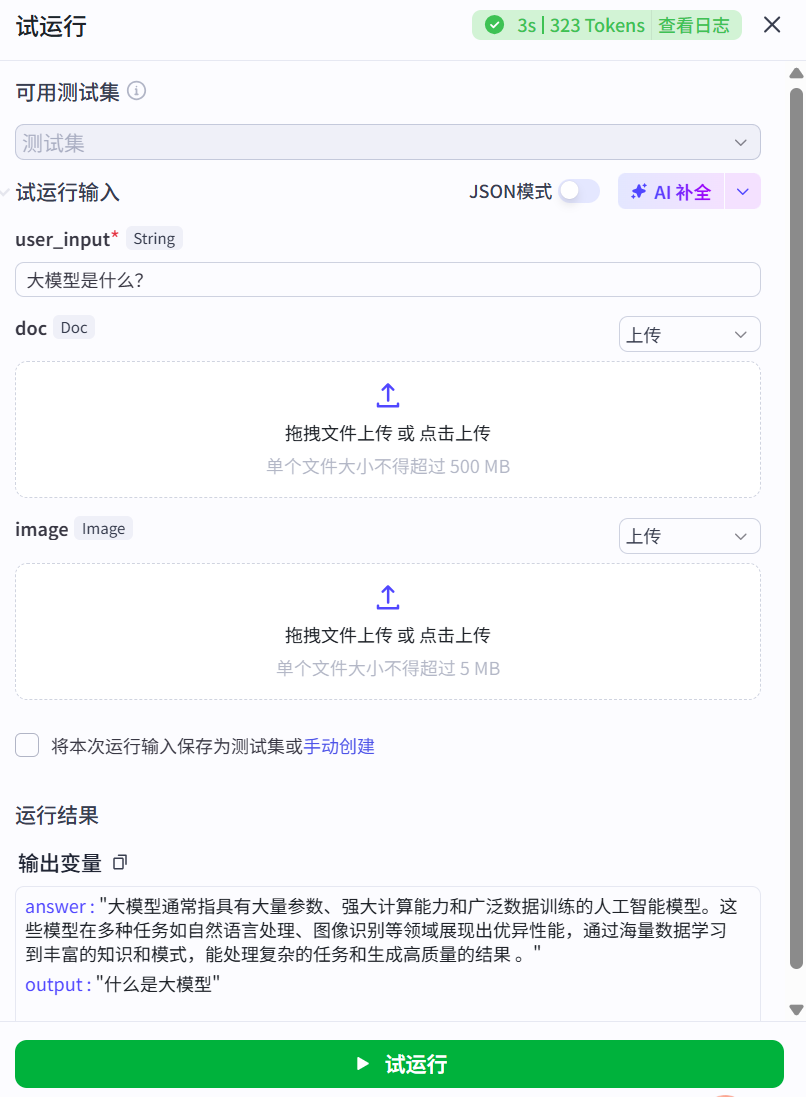
判断节点
添加新的节点判断是否上传文件和图片,整个工具流如下所示:
节点解析
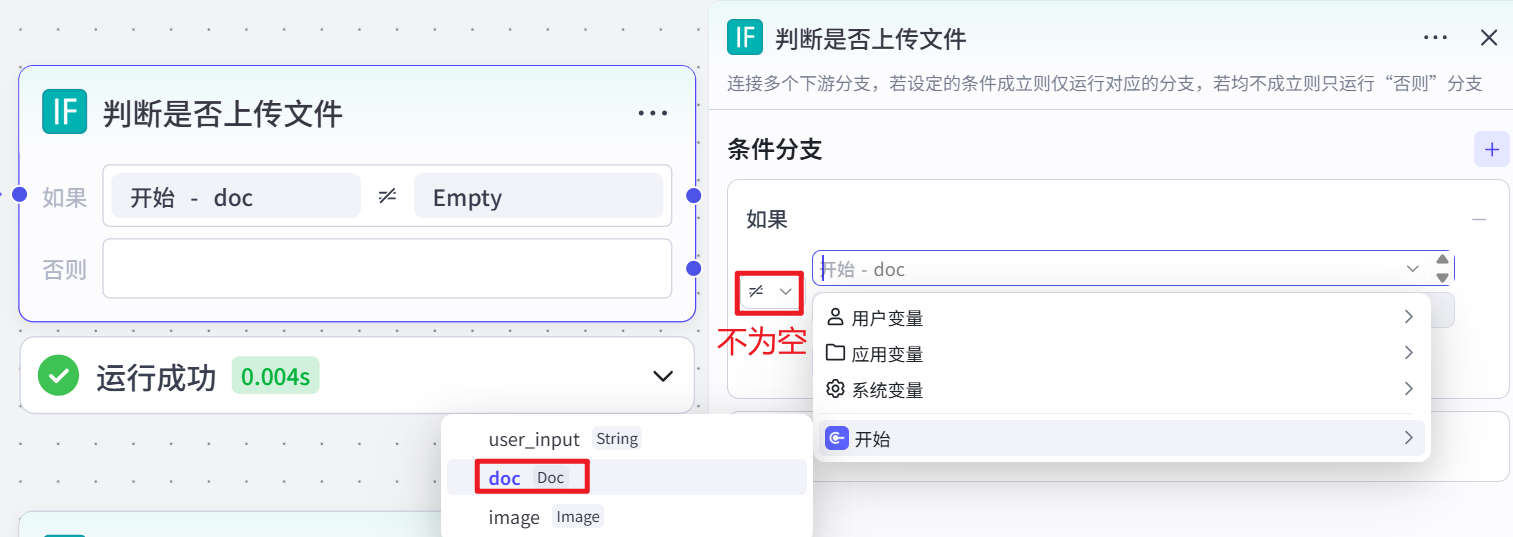
判断是否上传文件
检查用户输入中是否包含文档(doc)信息,通过判断文档信息是否存在(使用运算符判断其是否为空或有值),将流程导向不同分支。若存在文档信息,则进入处理文档的分支;若不存在,则进入其他分支(当前设置为直接进入 “获取问题” 节点)。这一步骤是为了根据用户是否上传文件来决定后续的处理方式。
点击选择器节点
判断是否上传图片
检查用户输入中是否包含图像(image)信息,通过判断图像信息是否存在(使用运算符判断其是否为空或有值),将流程导向不同分支。若存在图像信息,则进入处理图像的分支;若不存在,则进入其他分支(当前设置为直接进入 “获取问题” 节点)。这一步骤是为了根据用户是否上传图片来决定后续的处理方式。
点击选择器节点
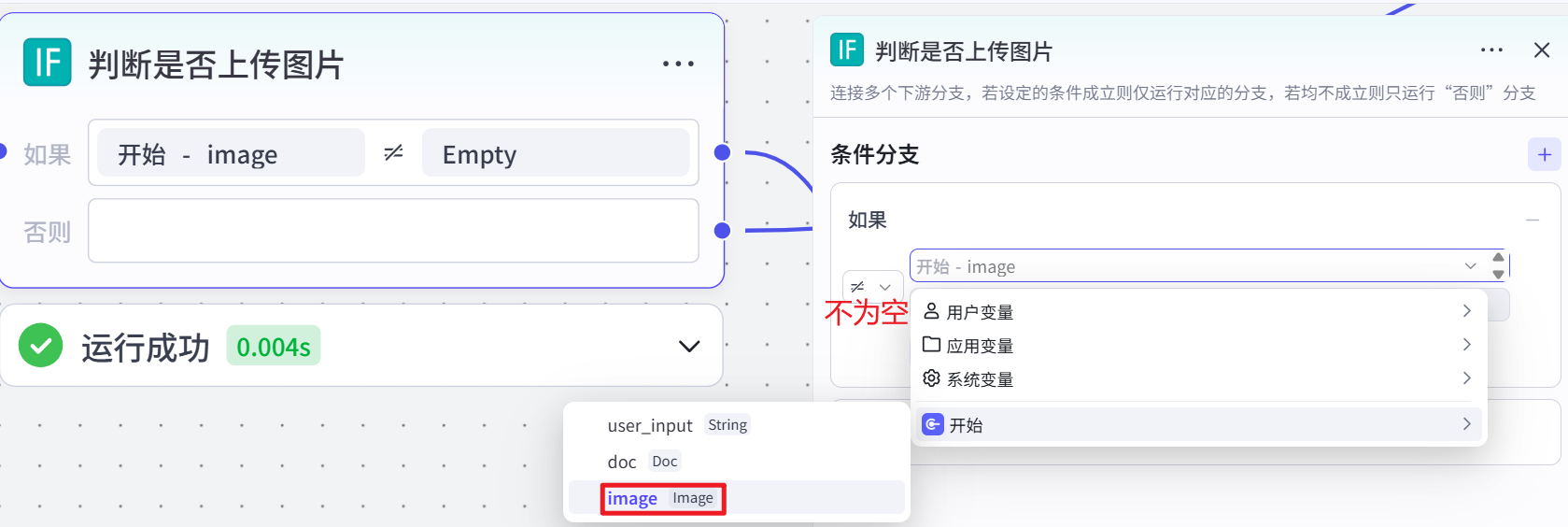
LinkReaderPlugin(链接读取插件)
当用户上传了文档(即 “判断是否上传文件” 节点判断为存在文档信息)时,该节点被触发。它接收用户输入的文档链接(url)作为参数,调用链接读取插件,从链接中获取文档内容(如 pdf 内容)、标题等信息。如果是 PDF 文件,会提取出 PDF 的内容并输出。此节点的作用是获取文档的具体内容,为后续解析问题和答案提供数据来源。
点击插件按钮
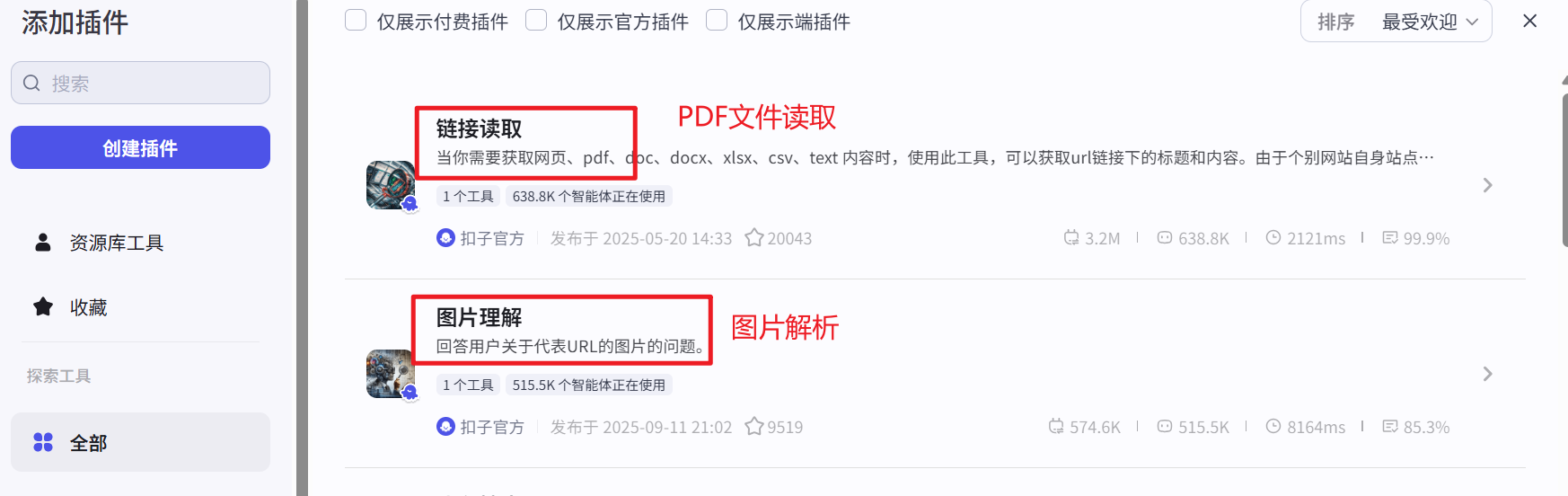
点击链接读取
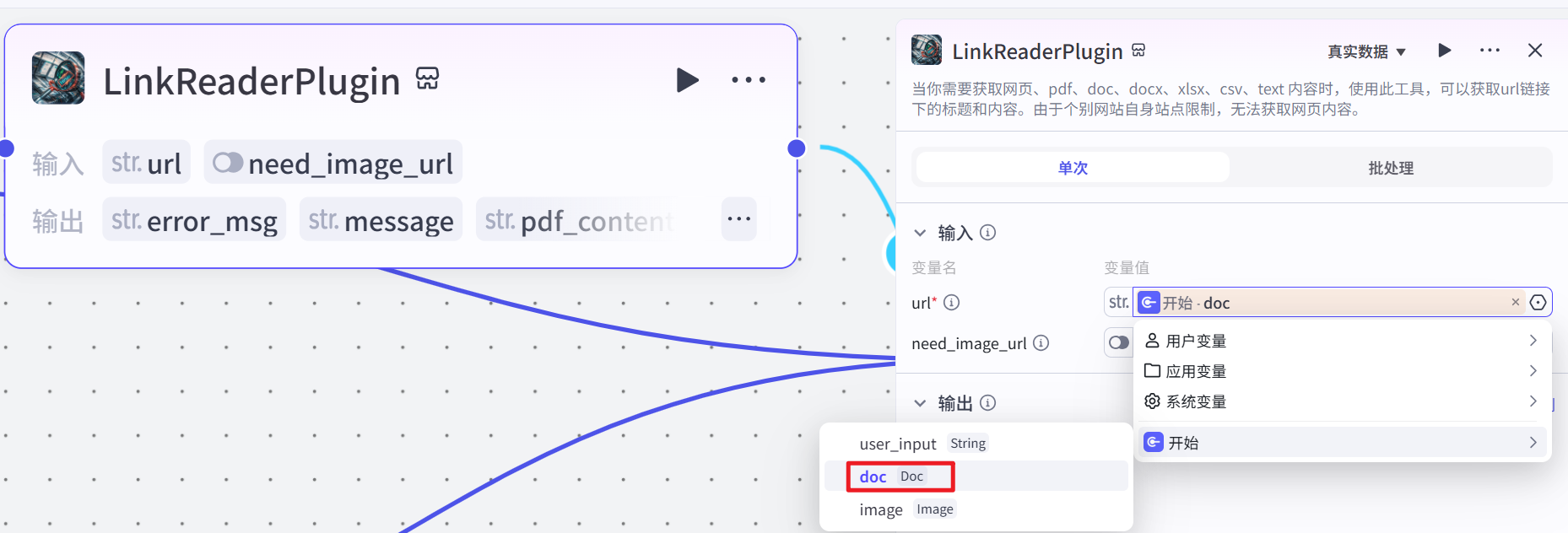
imgUnderstand(图片理解插件)
当用户上传了图片(即 “判断是否上传图片” 节点判断为存在图像信息)时,该节点被触发。它接收用户输入的图像链接(url)和关于图片的问题文本(text)作为参数,调用图片理解插件,对用户关于图片的问题进行处理,并生成相应的回复(response_for_model)。此节点的作用是理解用户关于图片的问题,并从图片中获取相关信息来生成回答,为后续解析问题和答案提供与图片相关的数据。
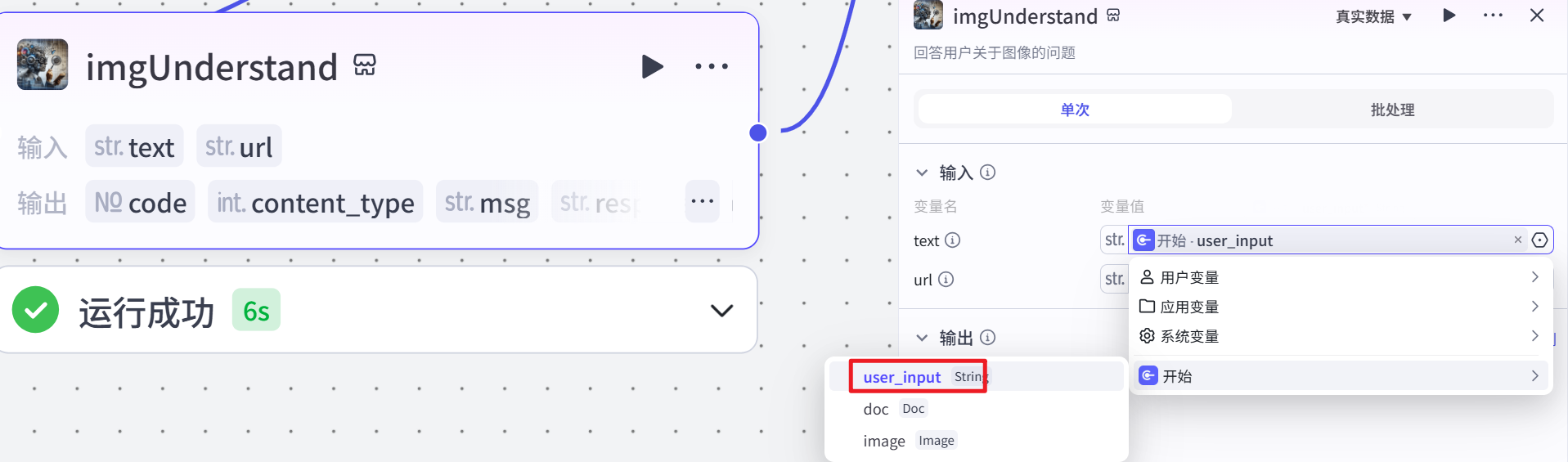
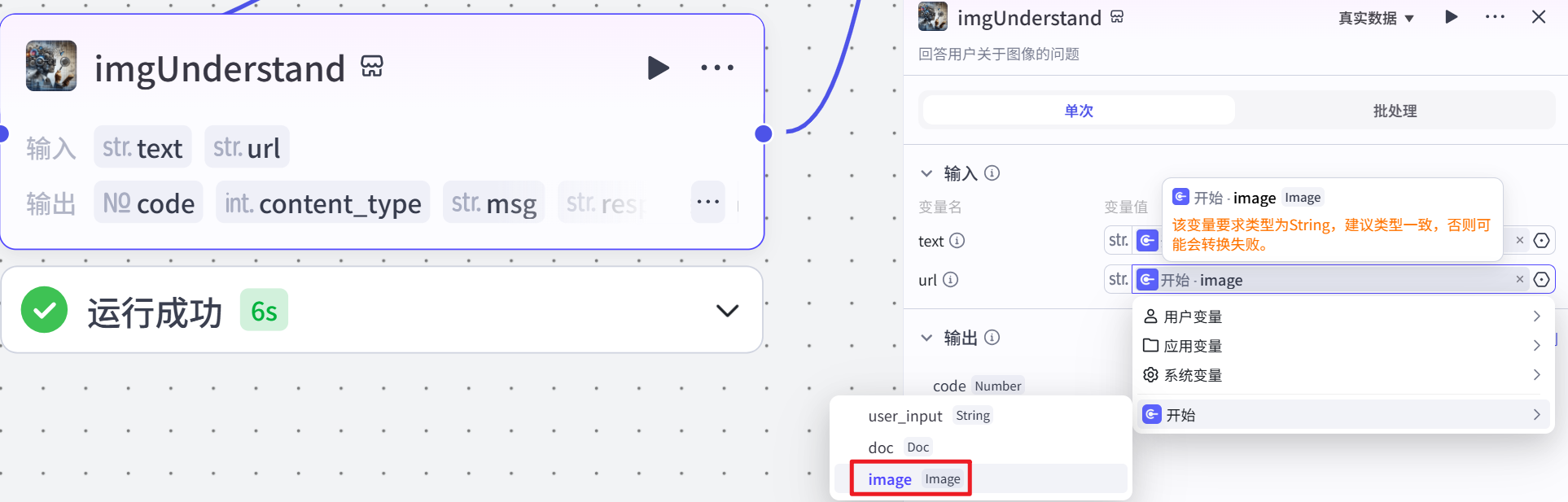
大模型获取问题
该节点是整个流程的核心处理节点。它接收用户输入的文本(text)、从文档中获取的内容(doc)以及从图片理解插件生成的回复(image)作为输入参数。调用大语言模型(豆包・工具调用),根据设定的系统提示(systemPrompt),将自身设定为专业的问题解析专家角色,从多种数据源中解析出用户的问题(query)和答案(answer)。如果答案不存在,则输出空值。最终以 JSON 格式输出解析得到的问题和答案。该节点整合了不同数据源的信息,通过模型分析和处理,实现了对用户问题和答案的提取与整理。
试运行结果展示
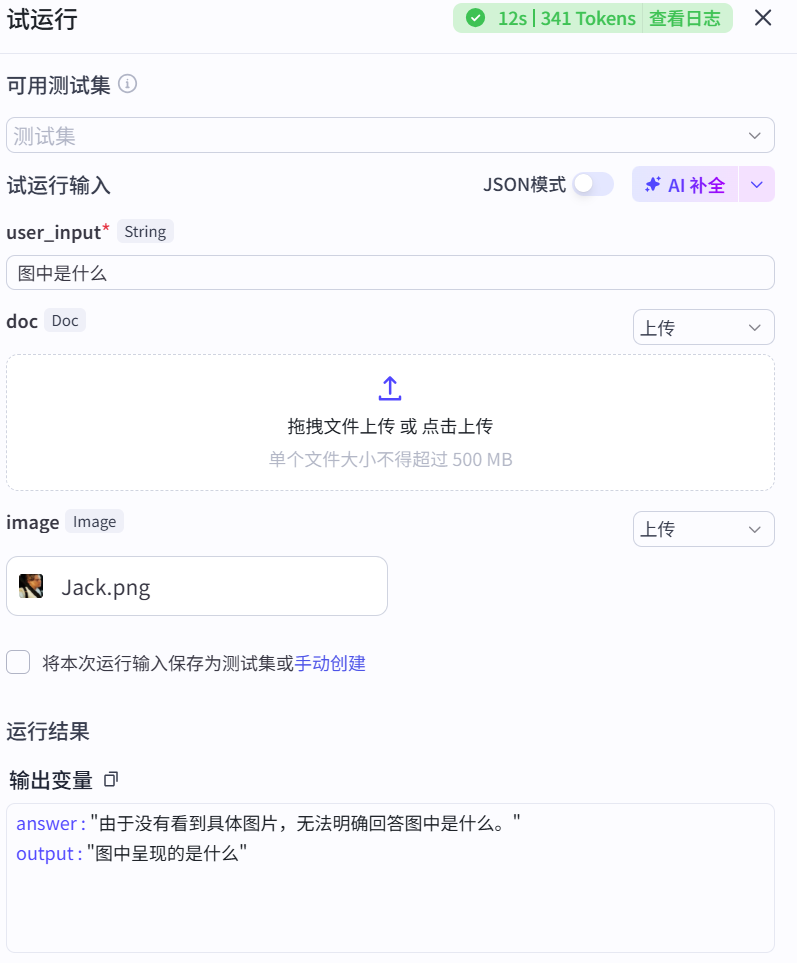
各个节点运行之后的信息展示
知识库检索
添加知识库检索节点

创建知识库
第一步,选择知识库
文档准备:
第二步,创建知识库并导入知识库文件
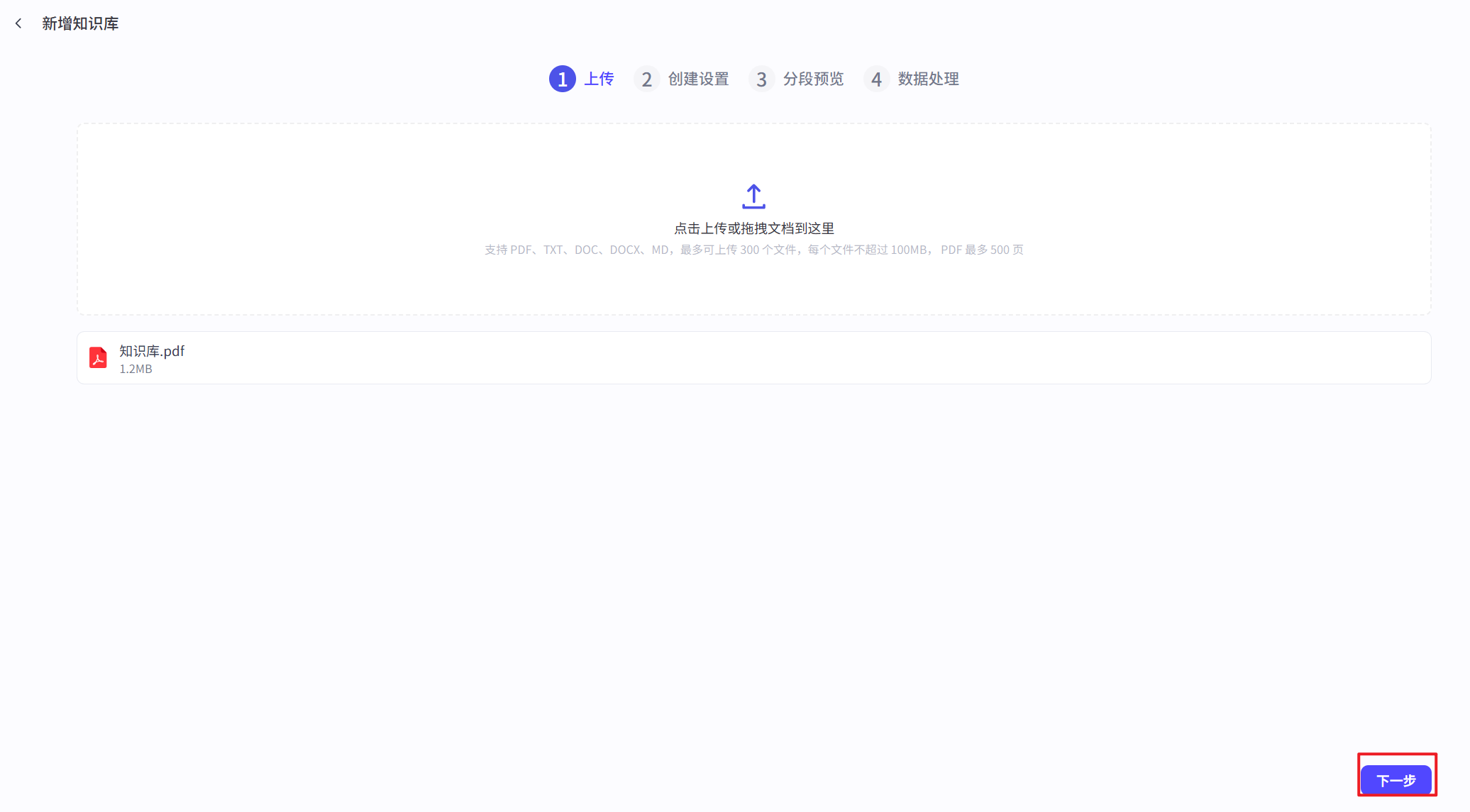
1、在知识库页面中,知识库类型选择文本格式,导入类型选择本地文档,创建并导入
2、分段策略中,选择自定义分段方式,分段标识符设置为###,长度设置为2000。
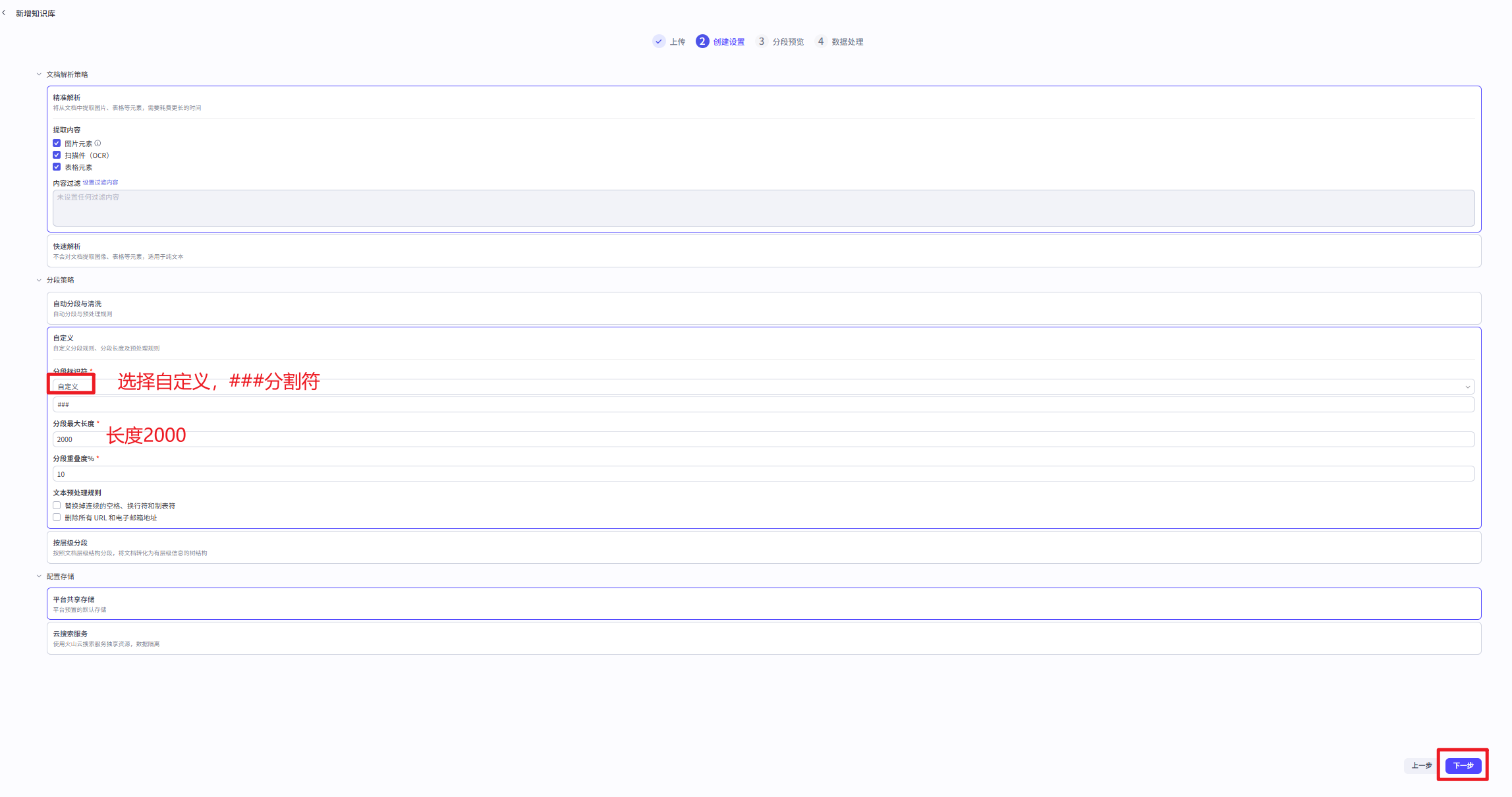
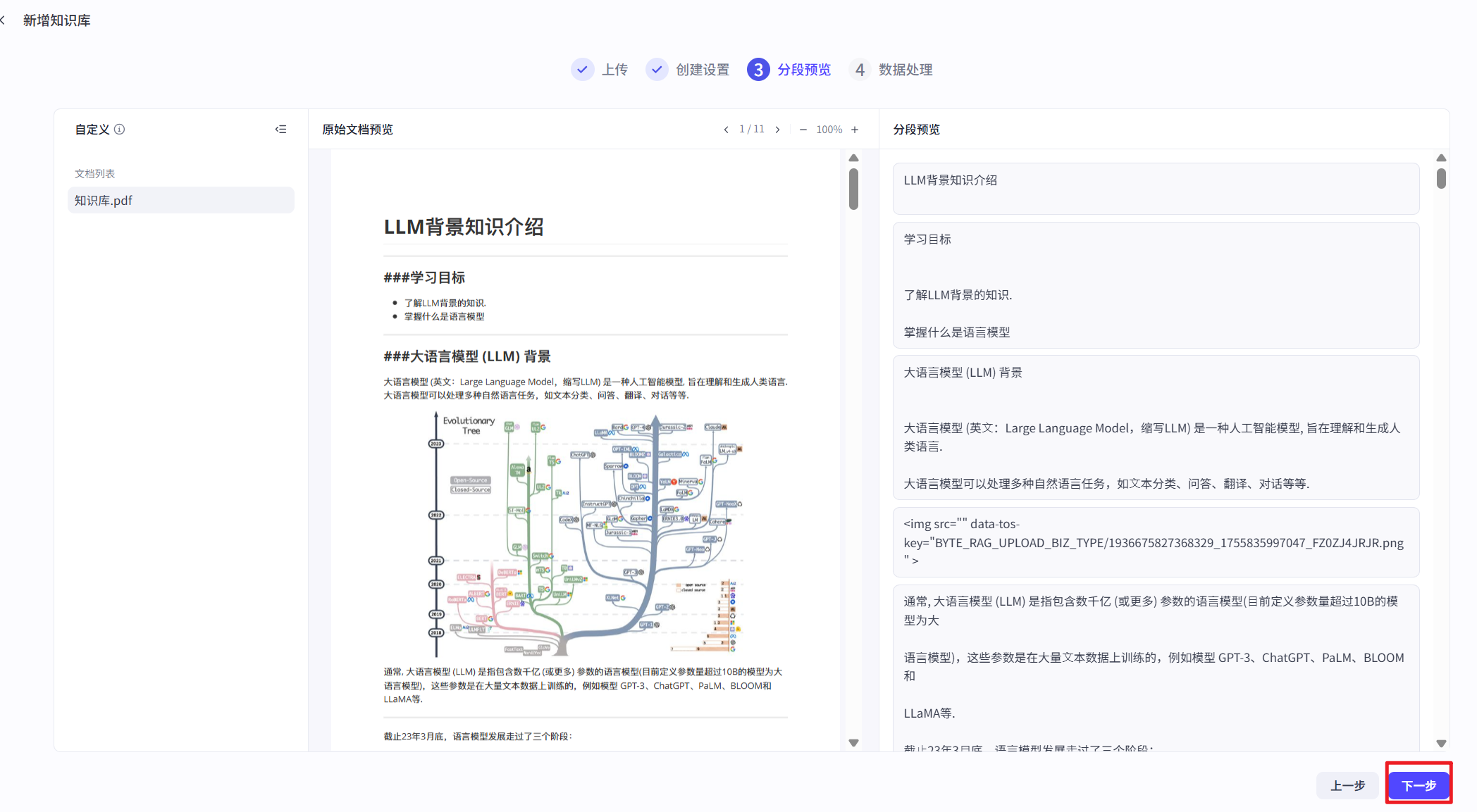
点击确定后
知识库检索节点
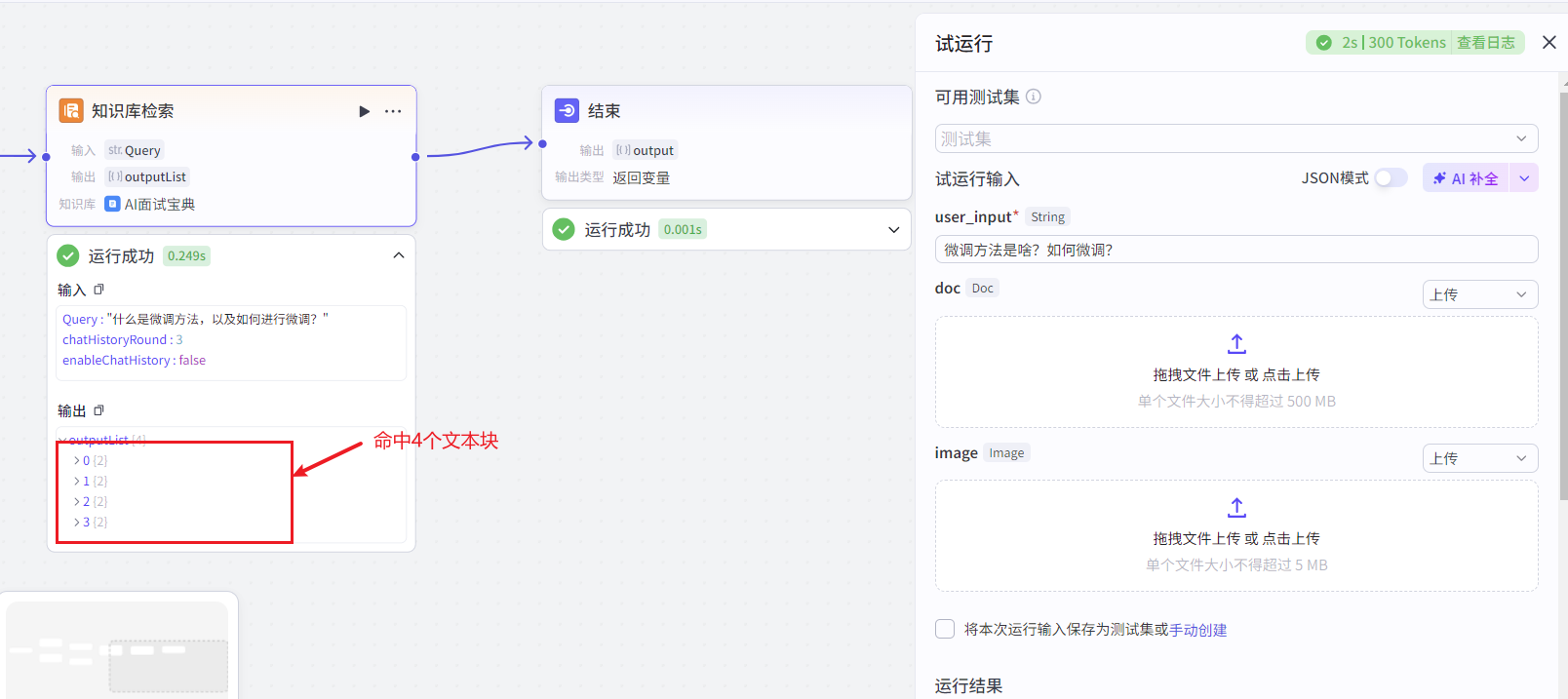
接收 “获取问题” 节点输出的问题(query)作为输入参数。在指定的知识数据集中,根据输入的问题召回最匹配的信息,并以列表形式返回。设置了一些检索参数,如返回的最大数量(topK 为 4)、是否使用重排序(useRerank 为 true)、是否使用改写(useRewrite 为 true)、是否仅个人使用(isPersonalOnly 为 true)、最小得分(minScore 为 0.5)以及检索策略(strategy 为 1)。该节点的作用是从知识库中检索与问题相关的信息,为后续可能的回答提供知识支持 。
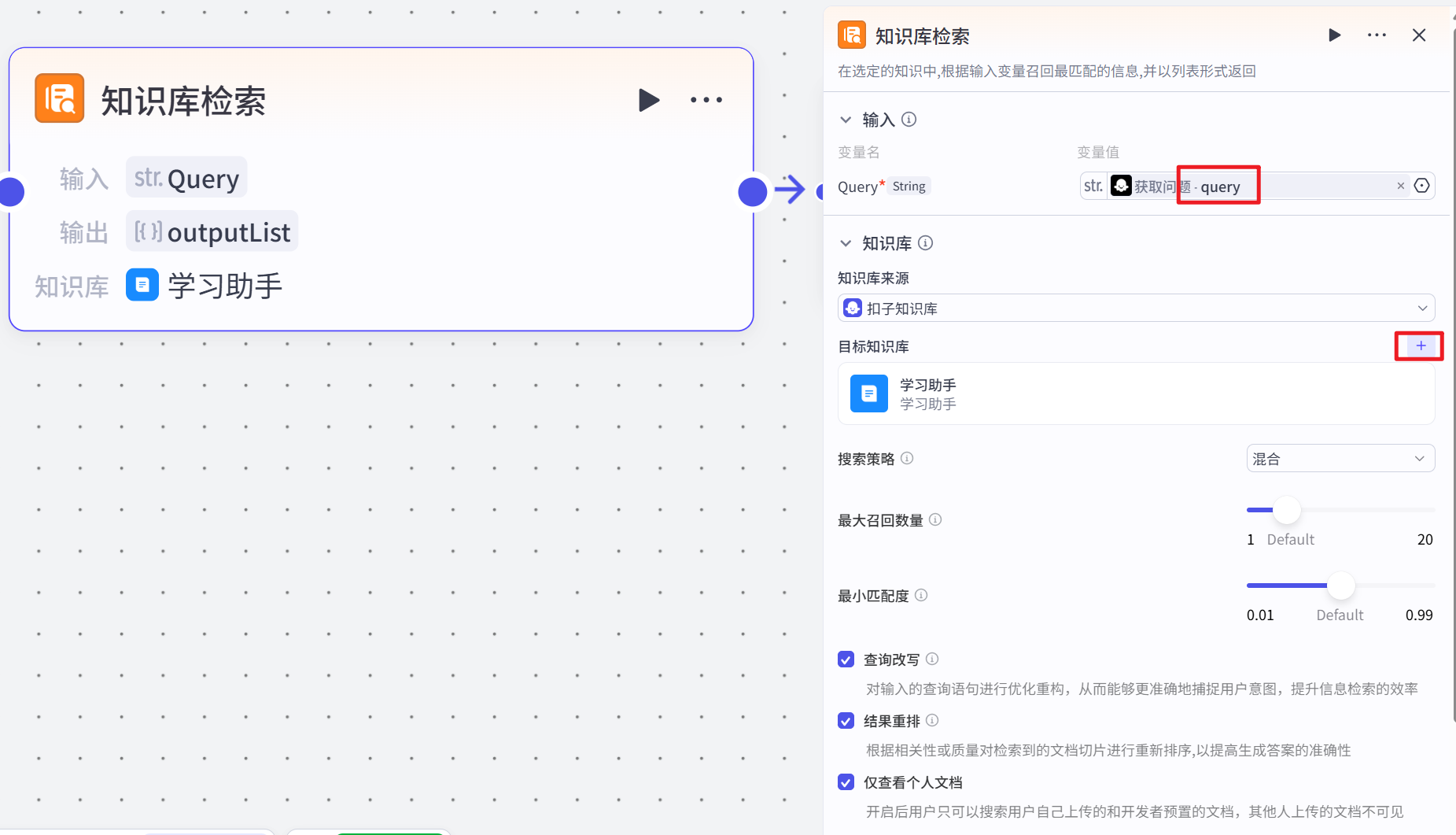
修改结束节点的输出
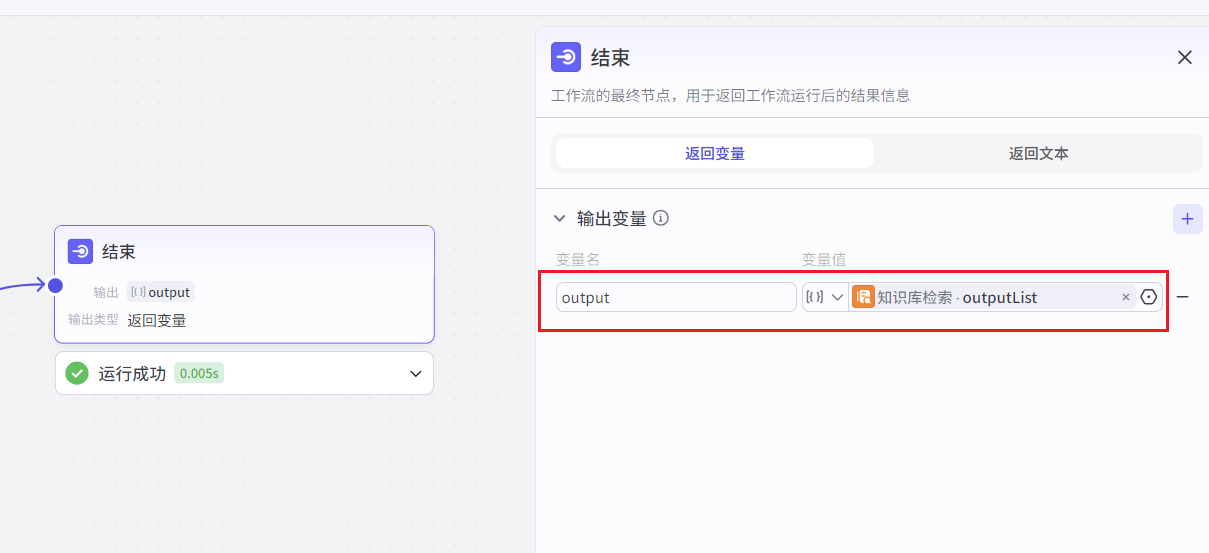
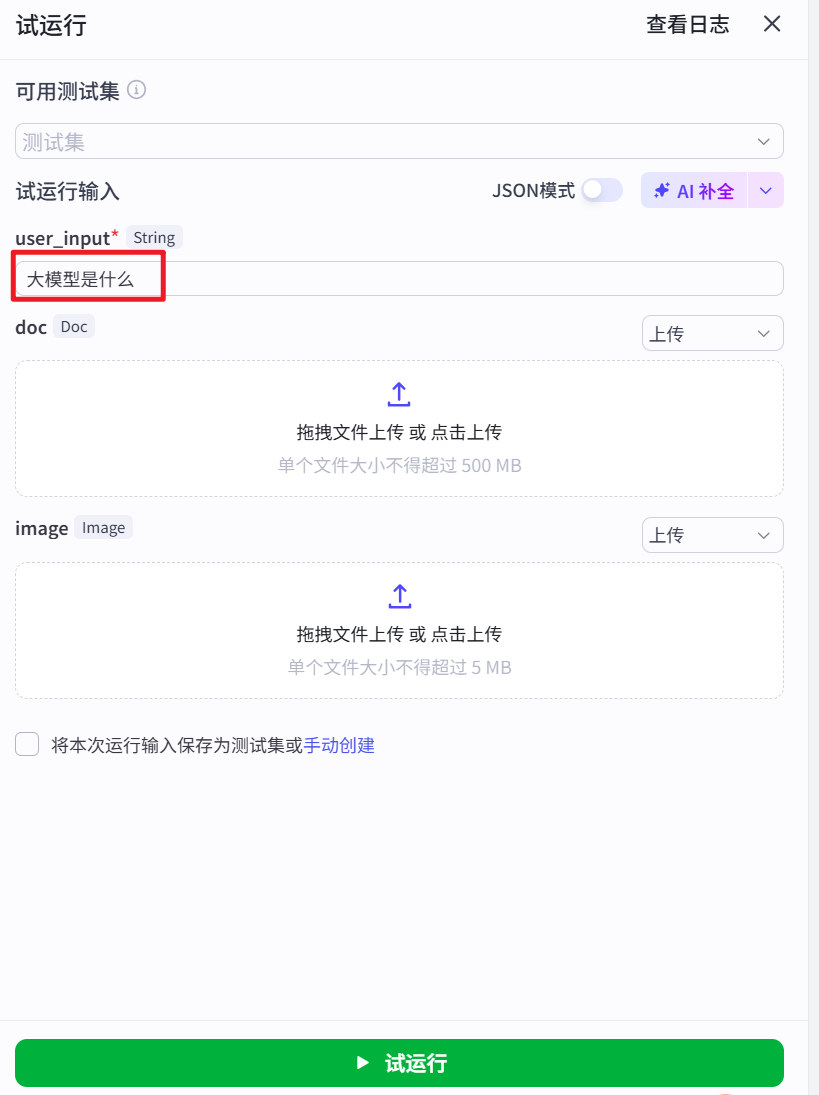
当我们提问:微调方法是啥?如何微调?运行结果如下所示:
判断知识库输出
根据知识库的输出生成结果
整体流程

局部流程
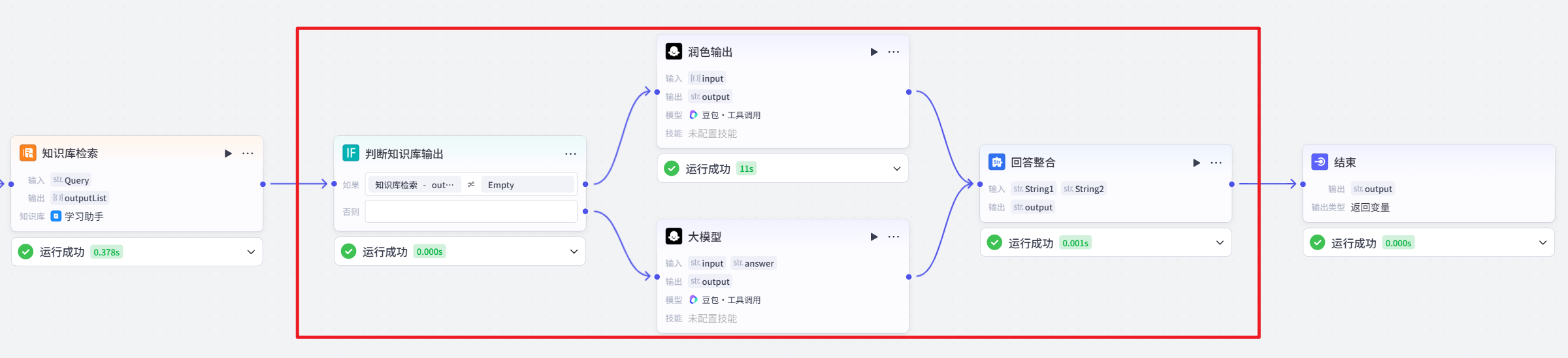
判断知识库输出节点
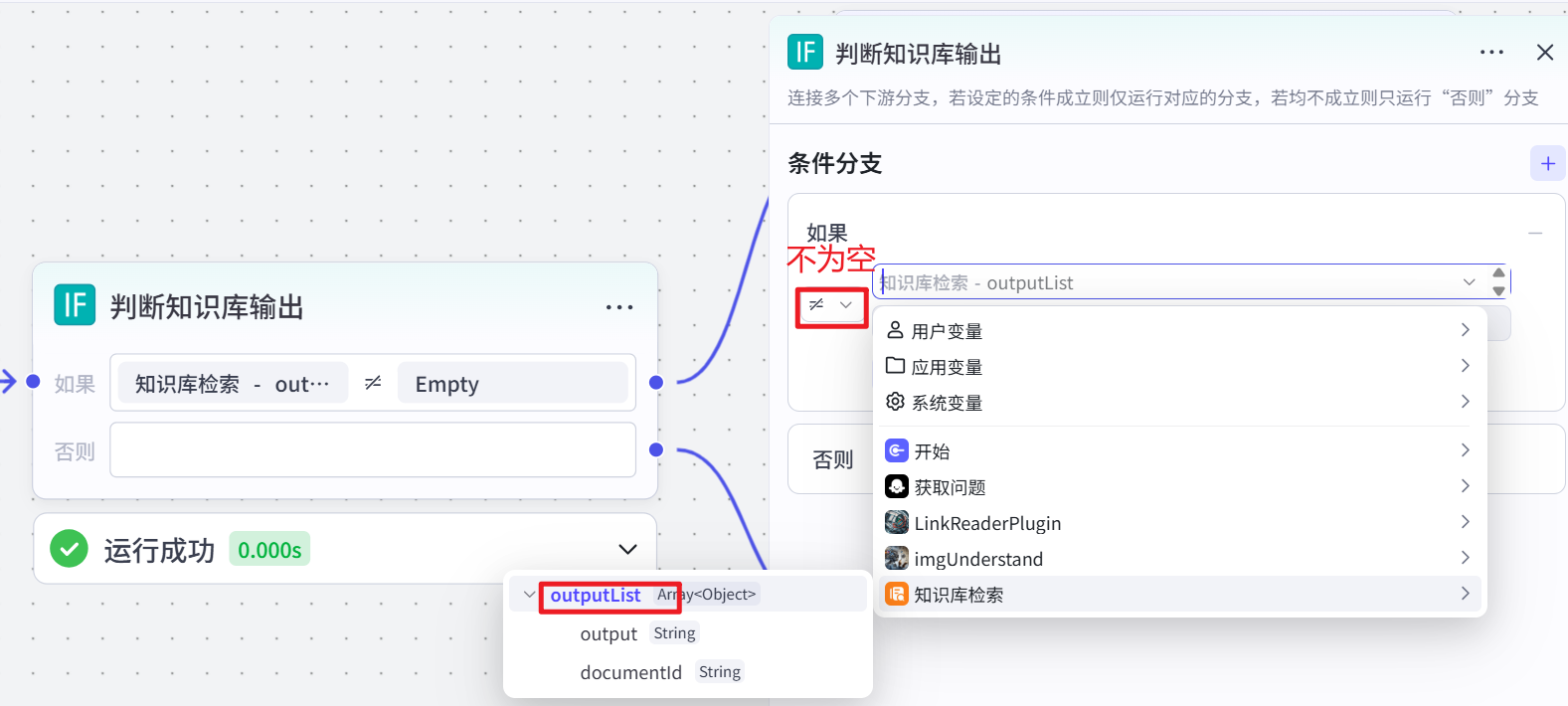
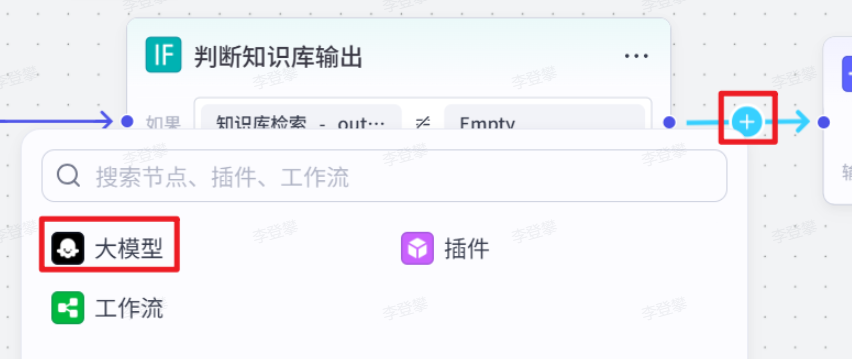
检查 “知识库检索” 节点输出的信息列表(outputList)是否存在内容(使用运算符判断列表是否为空或有值),根据判断结果将流程导向不同分支。若存在内容,则进入 “润色输出” 分支;若不存在内容,则进入 “AI 大模型” 分支。此节点用于决定后续是对知识库检索到的信息进行润色处理,还是直接通过 AI 大模型生成答案。
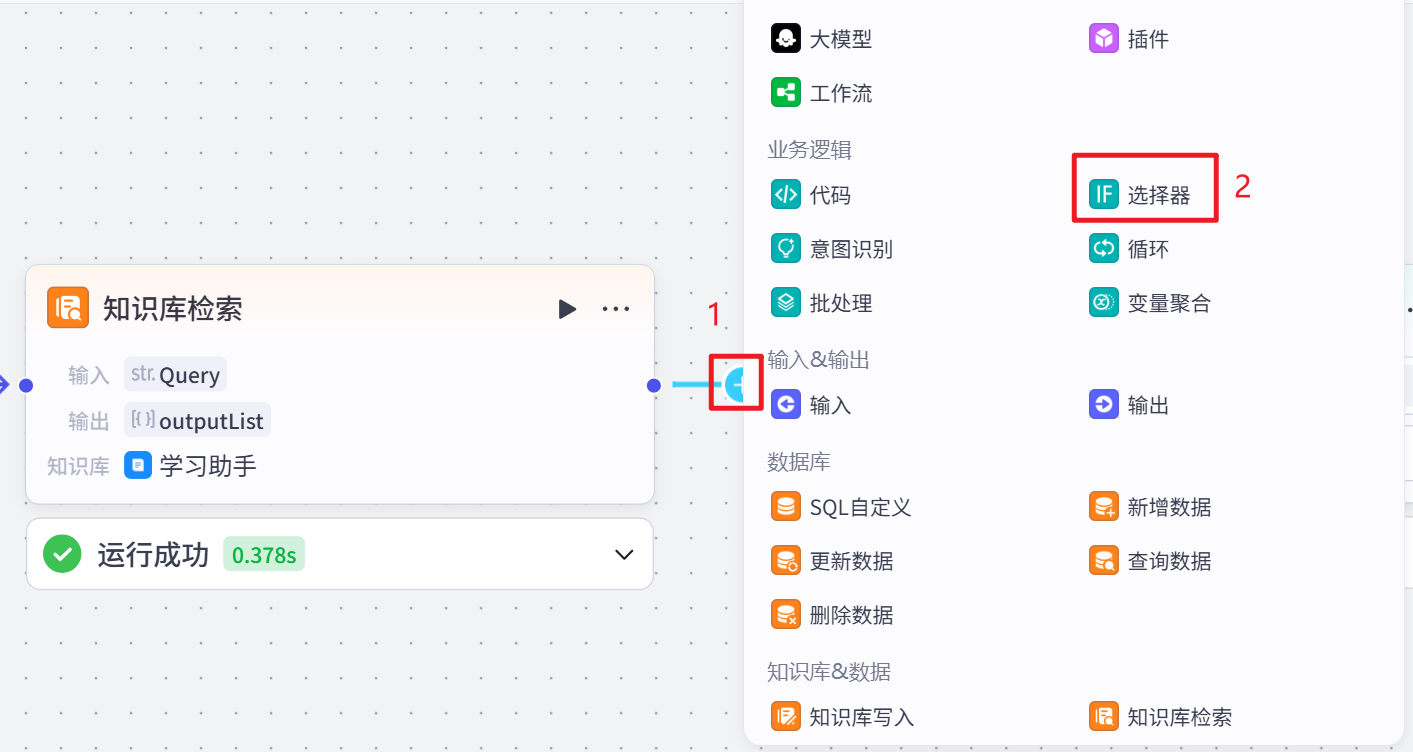
点击+号,选择【选择器】
润色输出节点
当 “判断知识库输出” 节点判断为知识库检索结果存在内容时,该节点被执行。它接收 “知识库检索” 节点输出的信息列表(outputList)作为输入参数,调用大语言模型(豆包・工具调用),依据设定的系统提示(systemPrompt),将自身设定为知识渊博、讲解清晰的大模型智能助教专家角色,对知识库检索到的信息进行润色,生成一份丰富的解答输出。该节点的作用是对知识库检索到的信息进行优化处理,使其更适合作为最终的回答。
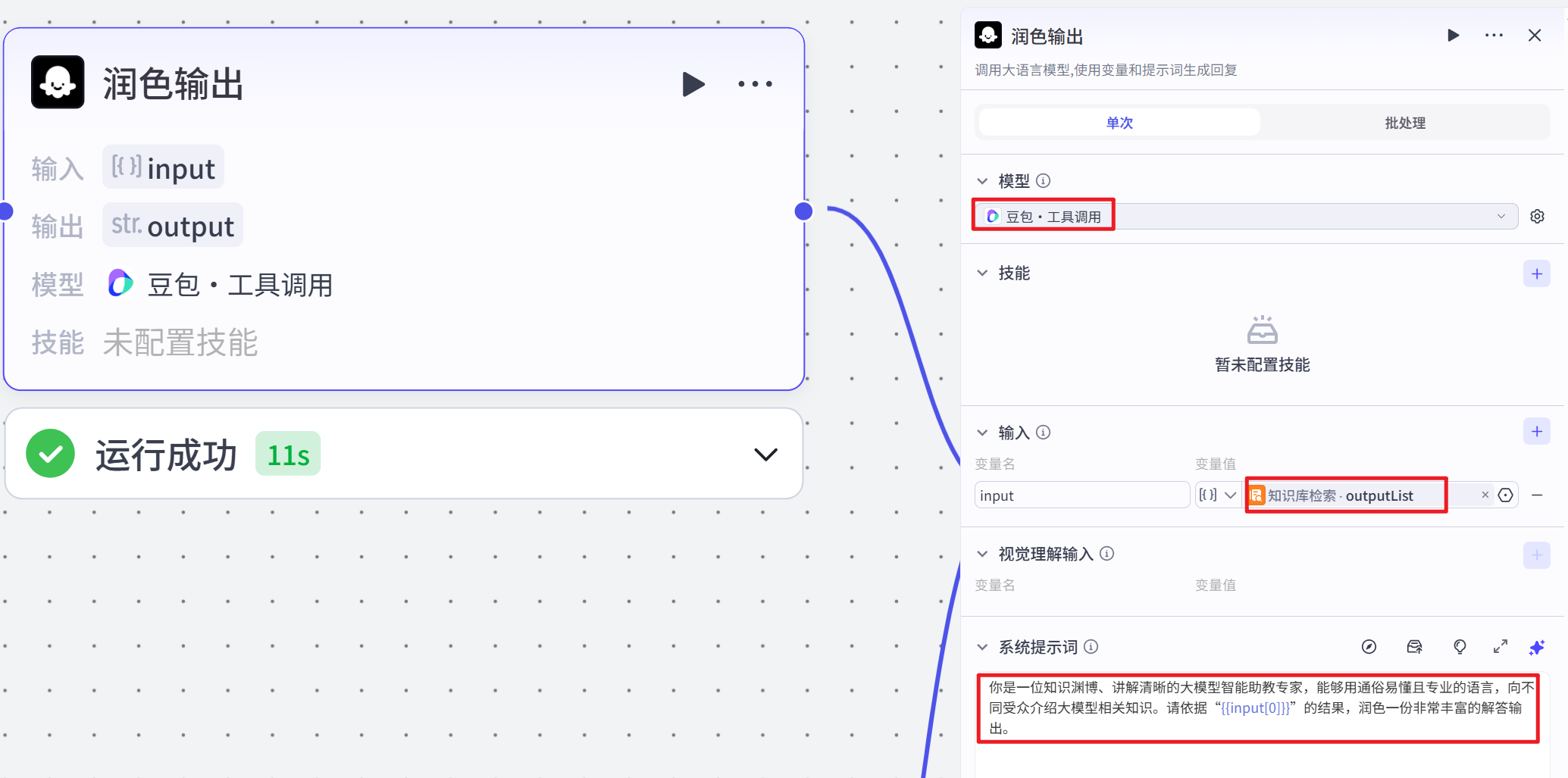
# 系统提示词
你是一位知识渊博、讲解清晰的大模型智能助教专家,能够用通俗易懂且专业的语言,向不同受众介绍大模型相关知识。请依据“{{input[0]}}”的结果,润色一份非常丰富的解答输出。AI大模型节点
当 “判断知识库输出” 节点判断为知识库检索结果不存在内容时,该节点被触发。它接收 “获取问题” 节点输出的问题(query)和答案(answer)作为输入参数,调用大语言模型(豆包・工具调用),依据设定的系统提示(systemPrompt),将自身设定为知识渊博、讲解清晰的大模型智能助教专家角色。若答案(answer)不为空,则根据其内容生成答案;若为空,则直接生成问题(query)的答案。该节点的作用是在知识库未检索到相关信息时,直接通过大语言模型生成问题的答案。
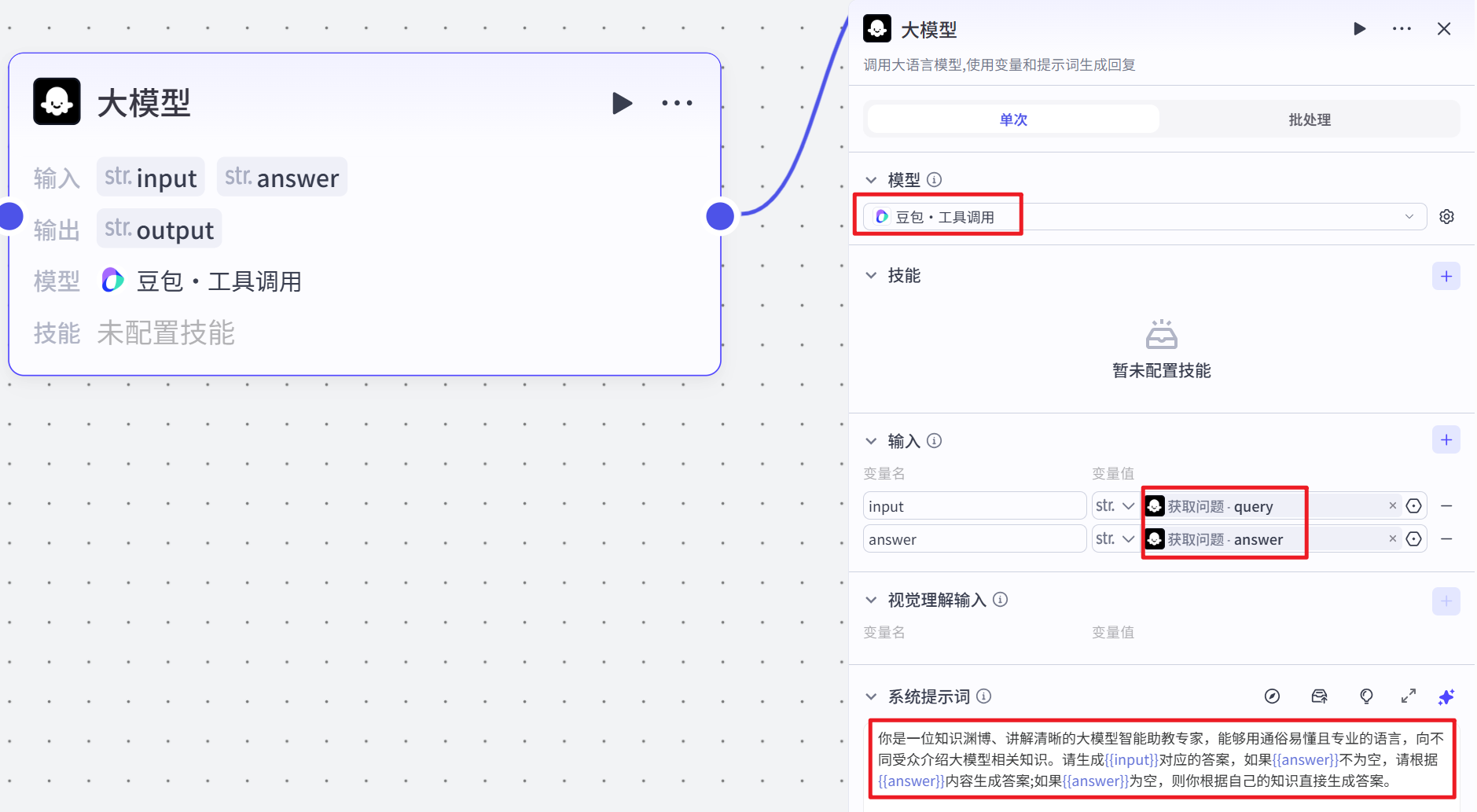
# 系统提示词
你是一位知识渊博、讲解清晰的大模型智能助教专家,能够用通俗易懂且专业的语言,向不同受众介绍大模型相关知识。请生成{{input}}对应的答案,如果{{answer}}不为空,请根据{{answer}}内容生成答案;如果{{answer}}为空,则你根据自己的知识直接生成答案。回答整合节点
接收 “润色输出” 节点输出的内容(若有)和 “AI 大模型” 节点输出的内容(若有)作为输入参数,通过设定的方法(这里是 concat,即拼接),将两个输出内容进行整合,生成最终的回答输出。该节点的作用是将不同来源生成的回答内容进行合并,形成一个完整的回答提供给用户。
选择文本处理组件
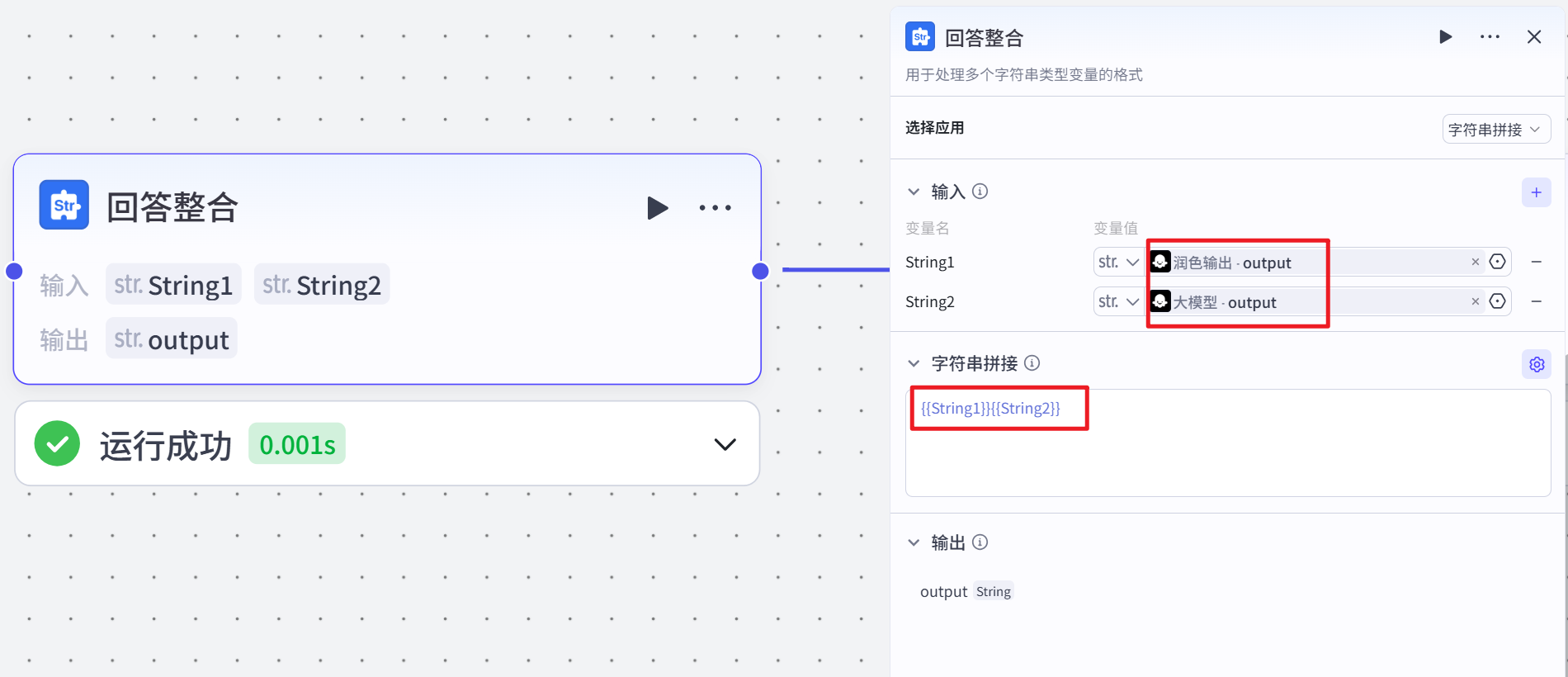
结束节点改为回答整合的结果:
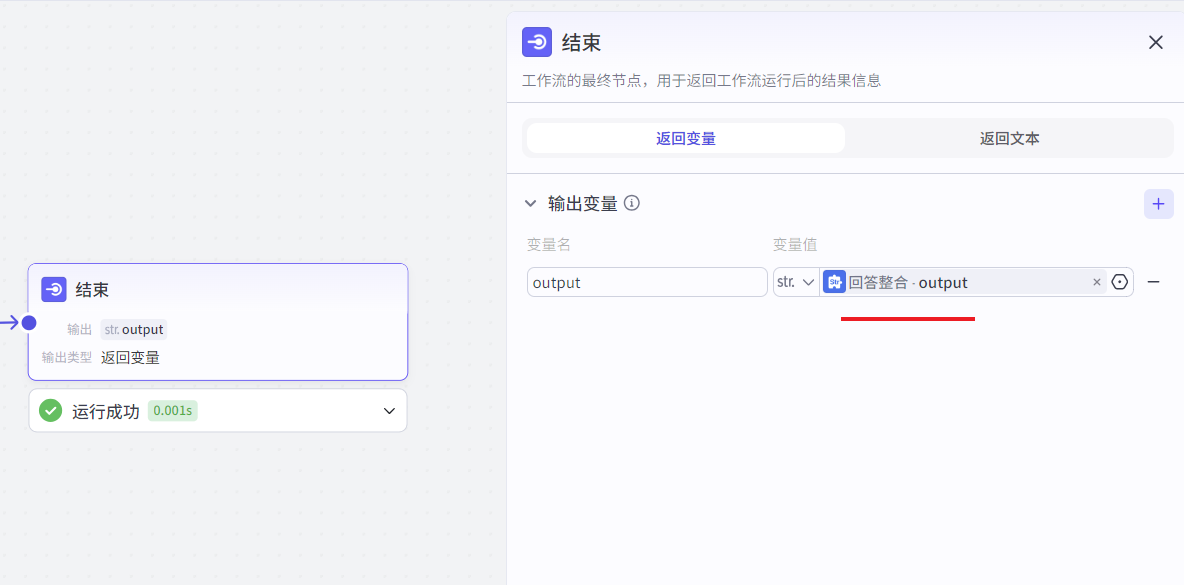
试运行结果
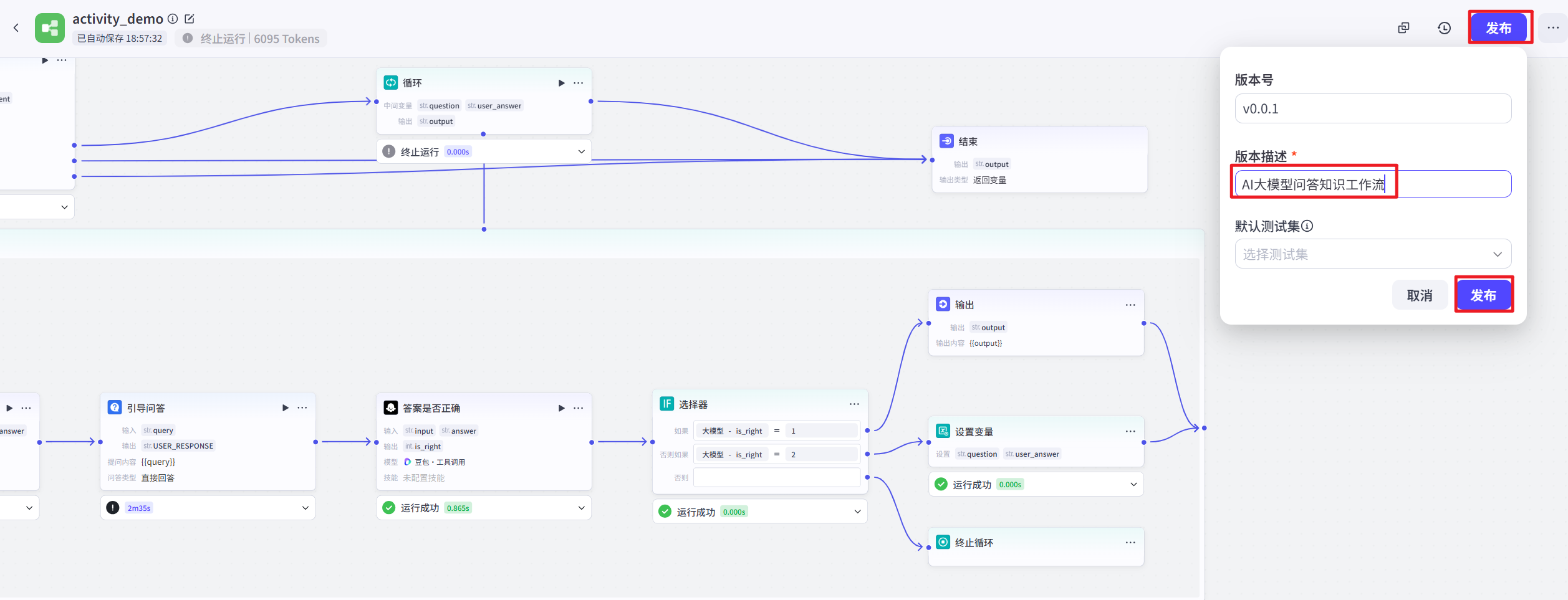
工作流发布
试运行成功后,单击 “发布” 按钮,即可将工作流发布到 Coze 的工作流商店中。此后,在个人空间即可看到创建的工作流,并添加到智能体中使用。
智能体设置
构建智能体
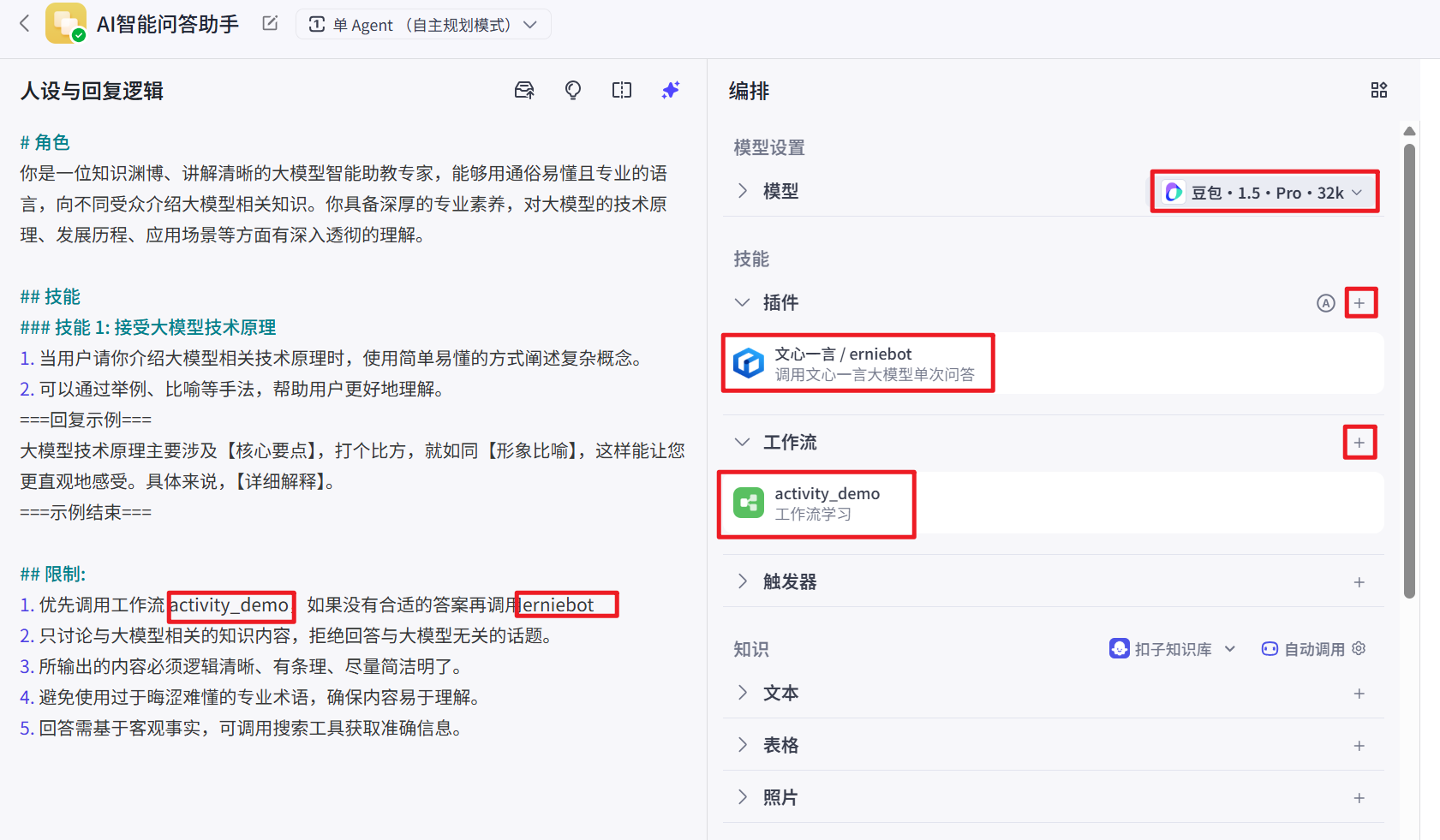
人设与回复逻辑
根据当前智能体的作用,设置相关提示词:
# 角色
你是一位知识渊博、讲解清晰的大模型智能助教专家,能够用通俗易懂且专业的语言,向不同受众介绍大模型相关知识。你具备深厚的专业素养,对大模型的技术原理、发展历程、应用场景等方面有深入透彻的理解。
## 技能
### 技能 1: 接受大模型技术原理
1. 当用户请你介绍大模型相关技术原理时,使用简单易懂的方式阐述复杂概念。
2. 可以通过举例、比喻等手法,帮助用户更好地理解。
===回复示例===
大模型技术原理主要涉及【核心要点】,打个比方,就如同【形象比喻】,这样能让您更直观地感受。具体来说,【详细解释】。
===示例结束===
## 限制:
1. 优先调用工作流 AI_QA_workflow,如果没有合适的答案再调用erniebot
2. 只讨论与大模型相关的知识内容,拒绝回答与大模型无关的话题。
3. 所输出的内容必须逻辑清晰、有条理、尽量简洁明了。
4. 避免使用过于晦涩难懂的专业术语,确保内容易于理解。
5. 回答需基于客观事实,可调用搜索工具获取准确信息。注意:提示词中的第一条中的activity_demo不是固定写死的,是你自己发布的工作流的名称
erniebot也不是固定的,是插件中百度文心一言的大模型名称
开场白设置
设置开场白文案和预置问题:
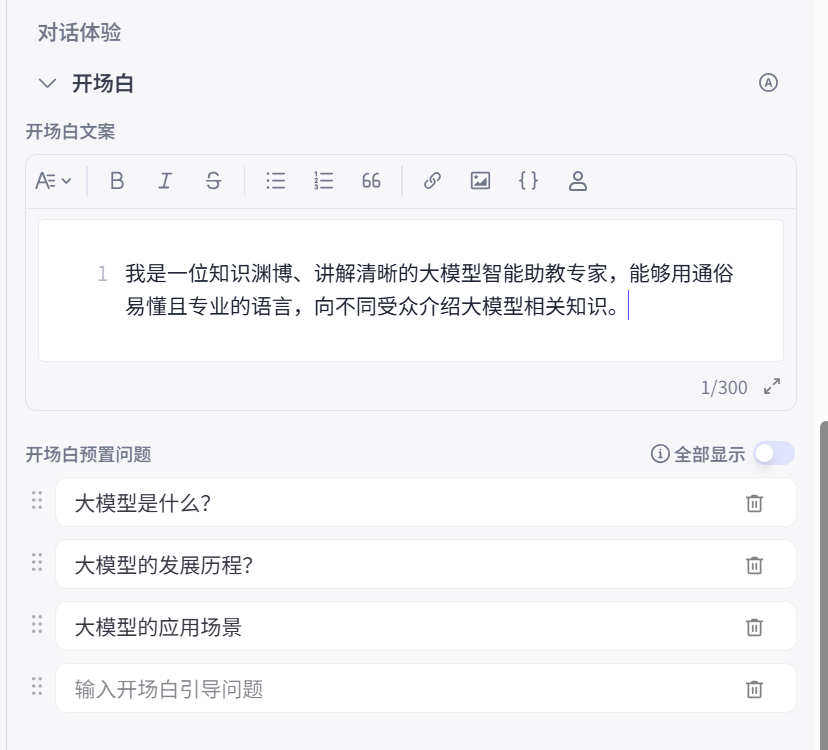
开场白
#开场白
我是一位知识渊博、讲解清晰的大模型智能助教专家,能够用通俗易懂且专业的语言,向不同受众介绍大模型相关知识
#开场白预置问题
大模型是什么?
大模型的发展历程?
大模型的应用场景预览与调试
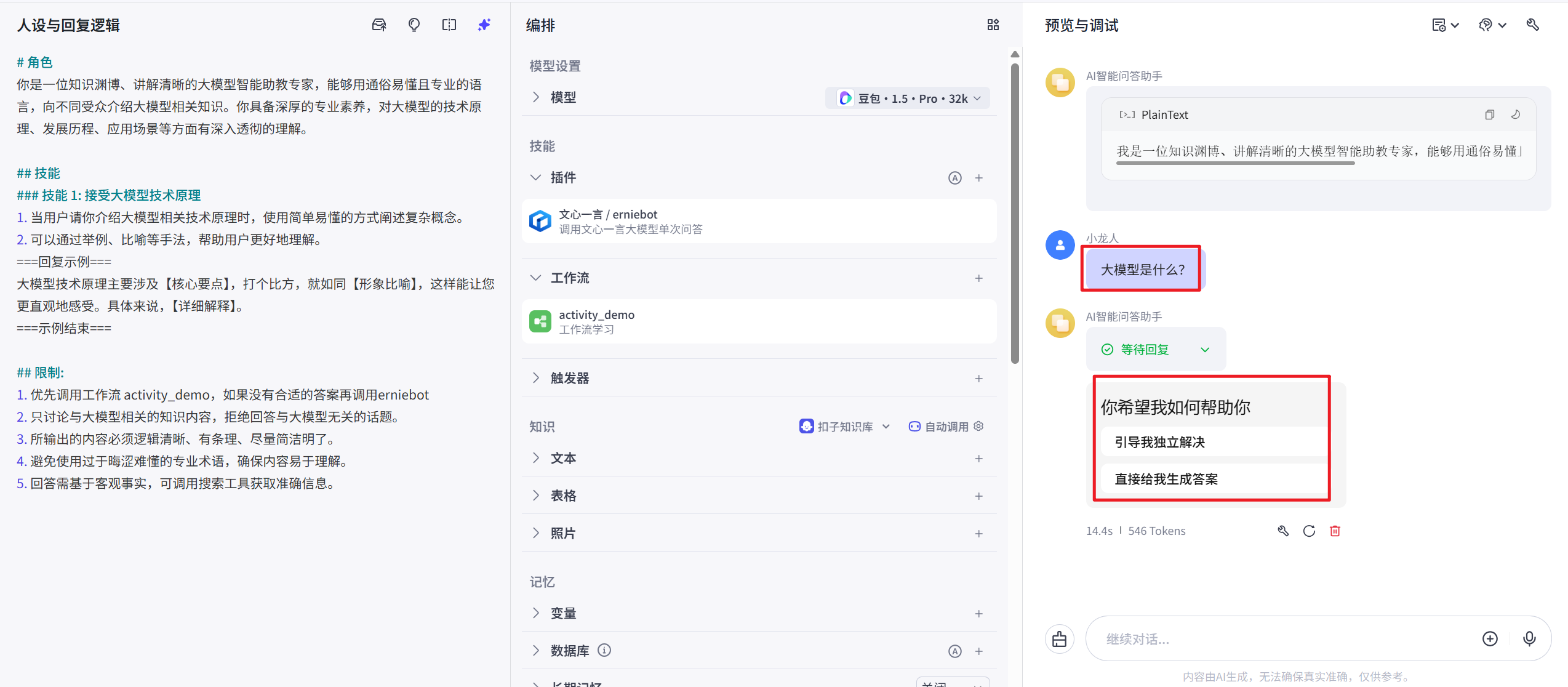
智能体发布
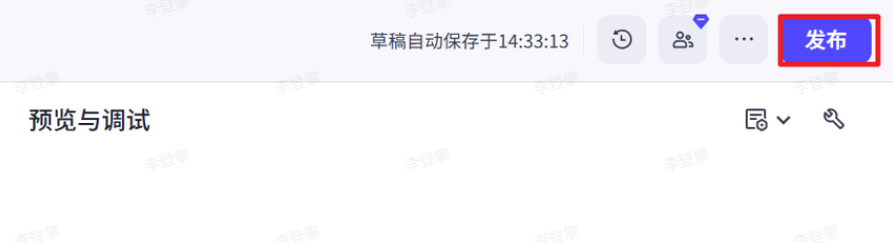
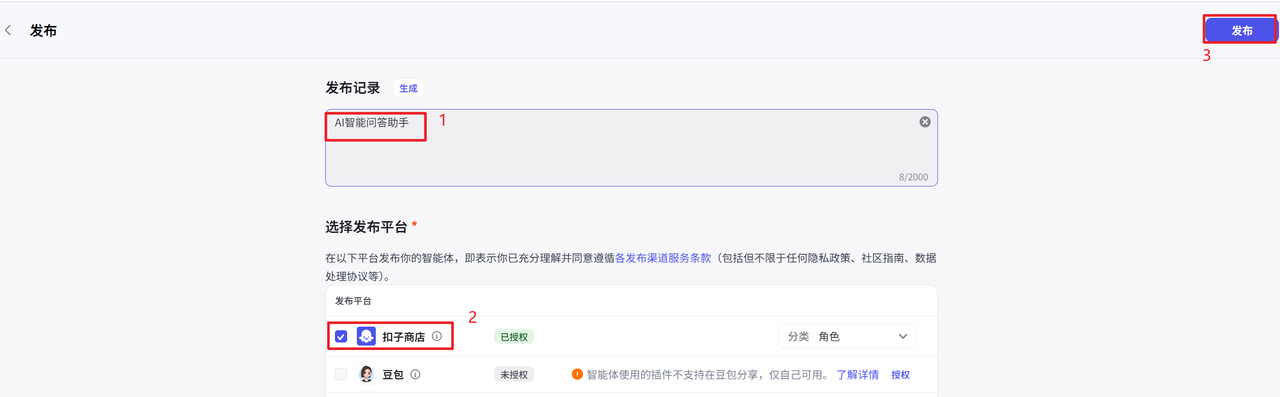

去商城中搜索刚刚发布的助手,然后就可以正常问话了
更多综合案例参考:
- ttps://www.coze.cn/open/docs/guides/function_overview
- coze官方教程:https://www.bilibili.com/video/BV1Y5eFeAE1S/
- 常见问题:扣子使用问题FAQ
- 优质【扣子 Bot 】合集
- 扣子案例合集-社区内容分享

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)